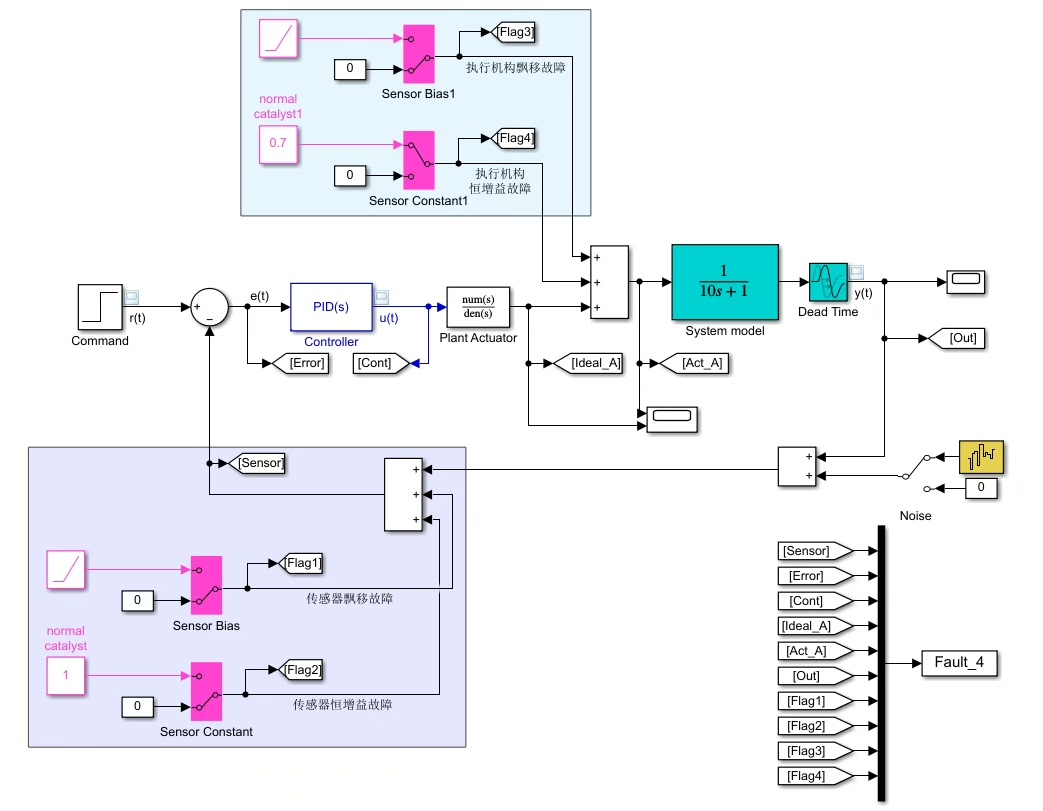
控制系统故障数据仿真模型与诊断程序:带执行机构的Simulink仿真模型及漂移、恒增益故障模拟...
·
【控制系统故障数据仿真模型与诊断程序】 1、 带执行机构的控制器Simulink仿真模型; 2、模拟执行机构、传感器的漂移故障、恒增益故障,以及噪声扰动; 3、诊断程序基于朴素贝叶斯和KNN算法。
本文档将详细介绍基于KNN(K近邻)和朴素贝叶斯算法的控制器故障诊断程序,涵盖核心功能、算法原理、模块构成、运行流程及结果输出,为用户理解和使用程序提供全面指导。
一、程序核心功能
程序以监督学习为基础,针对控制器故障诊断场景,实现两大核心功能,满足不同诊断需求下的精度与效率要求。
- KNN算法故障诊断:通过计算测试样本与训练样本的欧氏距离,选取最近的k个邻居,以多数表决规则判断故障类别,支持k值优化与多次诊断稳定性验证。
- 朴素贝叶斯算法故障诊断:基于属性条件独立性假设,通过高斯或指数概率密度函数建模,先训练模型学习数据分布,再实现故障分类,同时输出诊断精度与计算时间。
二、核心算法原理
2.1 KNN算法
KNN算法是一种惰性学习算法,无需预先训练模型,核心逻辑围绕“物以类聚”展开。
- 计算距离:采用欧氏距离,衡量测试样本与所有训练样本的相似度。
- 选取邻居:确定k值后,筛选出与测试样本距离最近的k个训练样本。
- 分类决策:统计k个邻居的故障类别,以出现次数最多的类别作为测试样本的诊断结果。
- k值影响:k值越小,模型越复杂易过拟合;k值越大,模型越简单易欠拟合,程序通过10-100区间内5的倍数遍历,确定最优k值。
2.2 朴素贝叶斯算法
朴素贝叶斯算法是生成式学习算法,基于贝叶斯定理与属性独立性假设,核心在于概率计算。
- 概率模型:包含两类关键概率,一是各类别先验概率P(Cj),即训练集中每个故障类别的占比;二是属性条件概率P(Ai|Cj),即某故障类别下各属性的分布概率。
- 密度函数:支持高斯分布和指数分布两种概率密度函数,用于计算属性条件概率,默认采用高斯分布。
- 分类决策:根据贝叶斯公式计算测试样本属于各故障类别的后验概率,选择概率最大的类别作为诊断结果。
三、程序模块构成
3.1 数据加载与预处理模块
- 数据加载:读取故障与健康数据文件(如FaultHealthData.mat、HEALFREESIG.mat等),包含控制器健康数据、单一故障数据(如传感器飘移、执行机构恒增益)及混合故障数据。
- 数据划分:通过randperm函数随机生成索引,将数据按比例划分为训练集与测试集(如KNN程序中训练集占比约70%,朴素贝叶斯程序中训练集与测试集各占50%),保证数据随机性。
- 标签制定:对不同故障类型进行编码,如健康状态标记为1,传感器飘移标记为2,混合故障标记为5等,生成训练集与测试集对应的标签向量,用于后续精度计算。
3.2 算法核心模块
3.2.1 KNN核心模块
- K值优化子模块:遍历10-100区间内5的倍数的k值,计算每个k值对应的诊断精度,选取距离平均精度最近的k值作为最优k值,存储于K_best变量。
- 诊断计算子模块(KNN_func.m):输入训练数据、训练标签、测试数据及最优k值,计算测试样本与训练样本的欧氏距离,排序后选取k个邻居,统计类别并输出诊断结果。
3.2.2 朴素贝叶斯核心模块
- 模型训练子模块(NaiveBayes.m):通过fit方法训练模型,计算每个故障类别的先验概率、属性均值(mu)与标准差(sigma),存储于模型对象中。
- 诊断预测子模块:通过predict方法,利用训练好的模型计算测试样本的后验概率,输出诊断标签,同时支持通过find方法查看各类别概率排序。
3.3 结果计算与可视化模块
- 精度计算:通过accuracyscore函数或直接对比预测标签与真实标签,计算诊断精度(Accuracy),即正确诊断样本数占总测试样本数的比例,存储精度数据至Accuracylist。
- 时间统计:通过tic-toc函数记录每次诊断的计算时间,统计平均时间与时间波动情况,存储时间数据至toc_list。
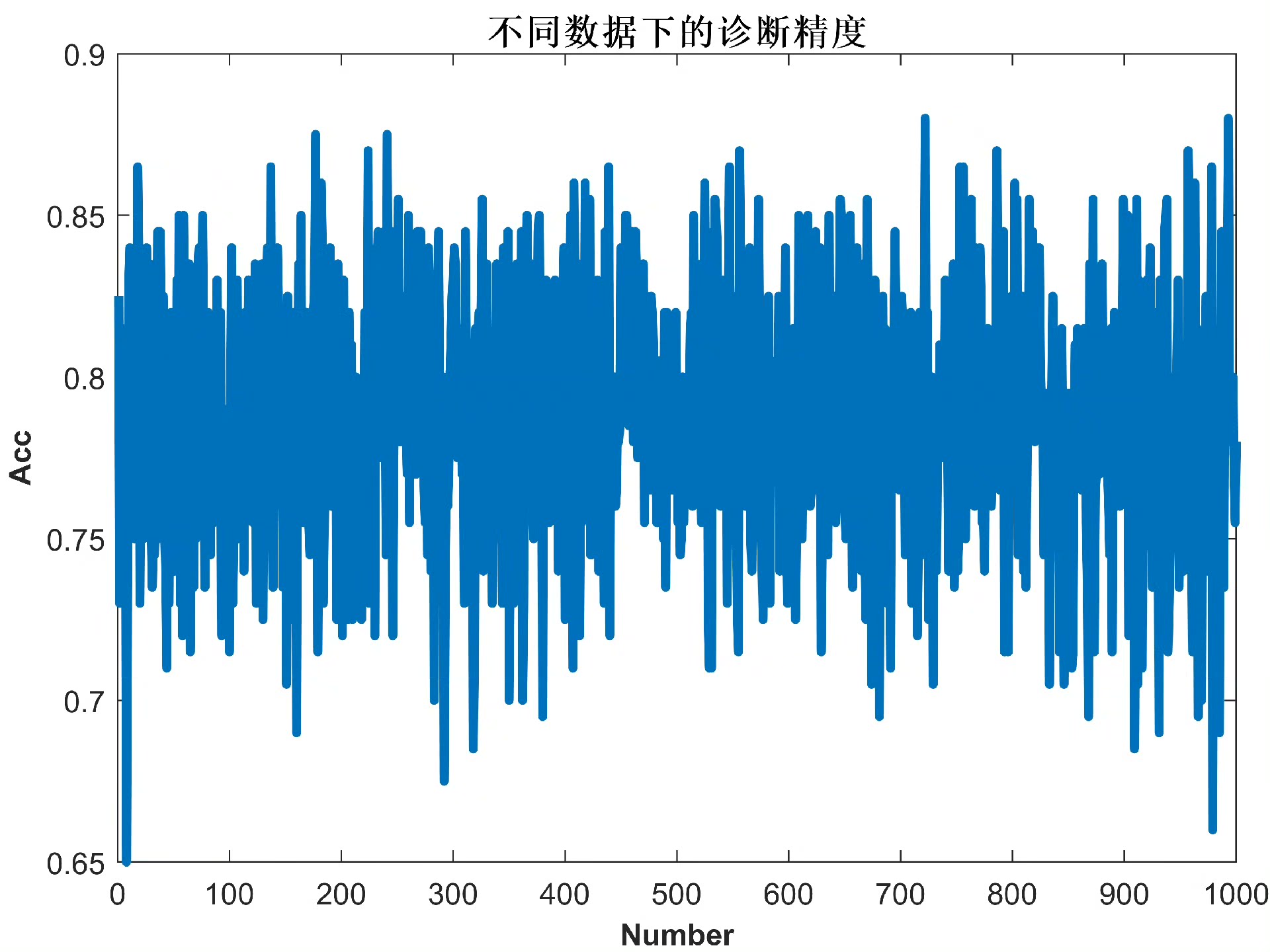
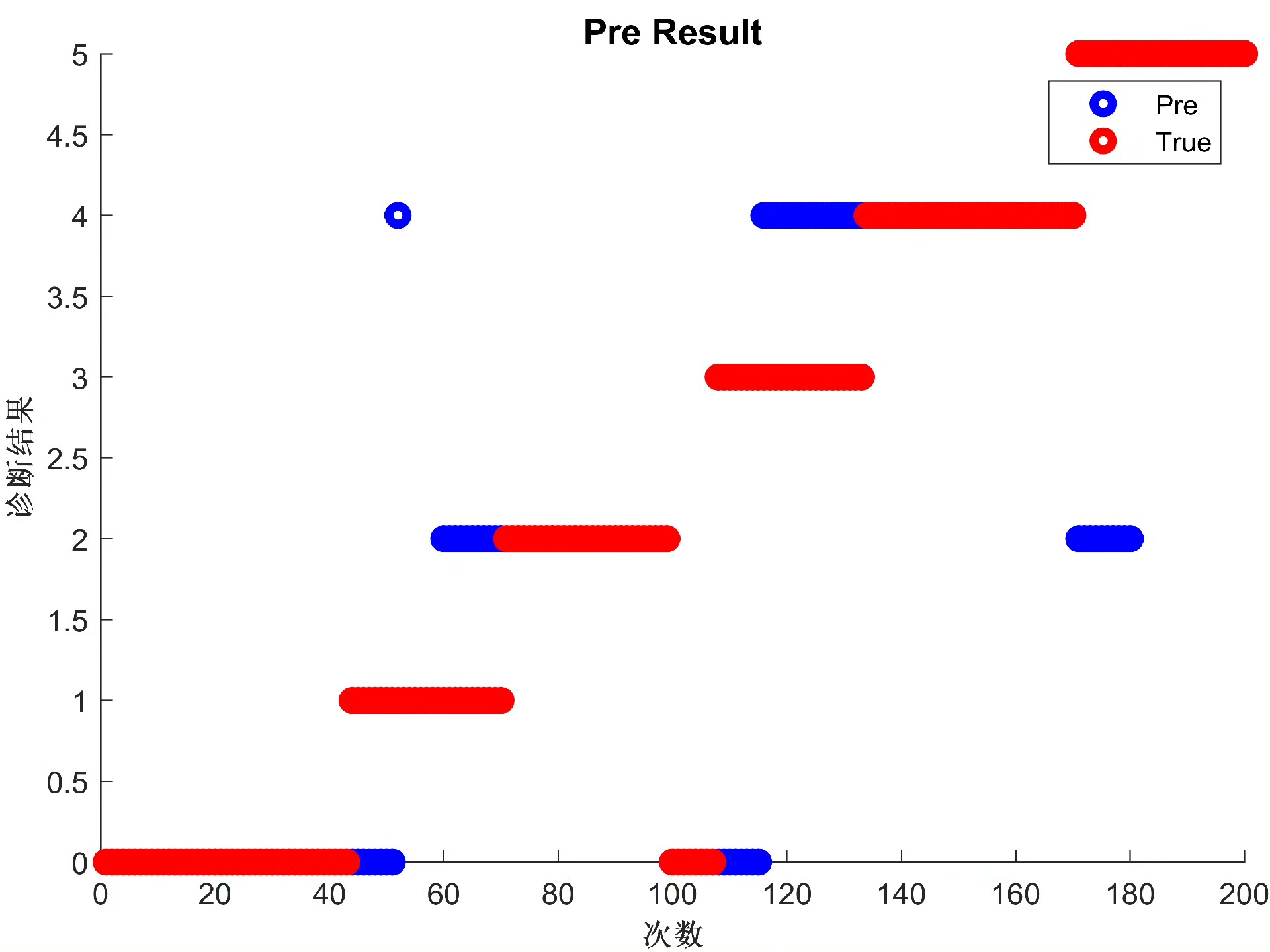
- 可视化输出:生成三类关键图表,一是不同k值诊断精度对比图(K.png),展示k值对KNN算法的影响;二是诊断结果散点图(Pre.png),对比预测标签与真实标签;三是多次诊断精度与时间趋势图(Acc.png、T.png),验证算法稳定性。
四、程序运行流程
4.1 KNN算法运行流程
- 初始化参数:设置循环诊断次数(如1000次)、k值遍历范围(10-100,步长5),创建精度与时间存储列表。
- 数据处理:加载数据,随机划分训练集与测试集,制定标签。
- K值优化:遍历k值,计算各k值精度,确定最优k值。
- 多次诊断:使用最优k值,循环1000次诊断,每次记录精度与时间。
- 结果输出:计算平均精度与平均时间,生成精度、时间趋势图及诊断结果对比图。
4.2 朴素贝叶斯算法运行流程
- 初始化参数:设置循环诊断次数(1000次),创建精度与时间存储列表。
- 数据处理:加载数据,随机划分训练集与测试集,制定标签。
- 模型训练:创建NaiveBayes对象,选择概率密度函数,调用fit方法训练模型。
- 多次诊断:循环1000次,每次使用训练好的模型预测测试集标签,计算精度与时间。
- 结果输出:生成精度趋势图、时间趋势图、诊断结果对比图及混淆矩阵热力图(HM_Bey.png),混淆矩阵展示各类别诊断的正确与错误数量。
五、结果输出与分析
5.1 关键输出指标
- 诊断精度:KNN算法平均诊断精度约0.8486,朴素贝叶斯算法平均诊断精度约0.9329,后者精度更高,提升约9.93%。
- 计算时间:KNN算法平均计算时间约0.1484s,朴素贝叶斯算法平均计算时间约1.2986s,前者效率更高,时间仅为后者的1/7左右。
- 稳定性:两种算法1000次循环诊断中,精度波动较小,无明显异常值,说明算法稳定性良好,可适应不同数据分布。
5.2 可视化结果解读
- 精度对比图:KNN算法的k值优化图中,精度随k值增大先上升后平稳,最优k值附近精度波动小;朴素贝叶斯精度趋势图中,精度始终维持在较高水平,无明显下降。
- 诊断结果图:散点图中蓝色点(预测标签)与红色点(真实标签)重合度高,说明诊断结果准确,仅少数混合故障样本存在误判。
- 混淆矩阵图:朴素贝叶斯算法的混淆矩阵中,对角线元素(正确诊断数)占比高,非对角线元素(误判数)少,进一步验证算法分类准确性。
六、程序使用说明
- 环境准备:确保安装MATLAB,版本支持randperm、normpdf、heatmap等函数,将所有程序文件(.m)与数据文件(.mat)放入同一目录。
- 参数调整:打开主程序(如MainofDiagnosisKNN.m、MainofDiagnosisBey.m),可调整循环诊断次数(num)、k值遍历范围、训练集与测试集划分比例等参数。
- 运行程序:在MATLAB命令行中输入主程序文件名,如“MainofDiagnosis_KNN”,程序自动执行数据处理、算法诊断与结果输出,生成的图表存储于当前目录。
- 结果查看:查看生成的.png图表,获取诊断精度、时间及结果对比;查看工作区变量(如Accuracylist、Kbest),获取详细数据。
要不要我帮你整理一份程序常见问题排查指南?包含数据加载失败、精度异常、图表生成错误等问题的解决方案,帮助你快速解决程序运行中的问题。
【控制系统故障数据仿真模型与诊断程序】 1、 带执行机构的控制器Simulink仿真模型; 2、模拟执行机构、传感器的漂移故障、恒增益故障,以及噪声扰动; 3、诊断程序基于朴素贝叶斯和KNN算法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)