【论文阅读】Ultrasound Report Generation with Cross-Modality Feature Alignment via Unsupervised Guidance
论文链接:https://arxiv.org/pdf/2406.00644
Code: https://github.com/LijunRio/Ultrasound-Report-Generation
摘要:
文章提出了一个用于超声报告自动生成的新颖框架,旨在减轻临床医生的工作负担。该框架的主要内容和贡献可以总结如下:
核心框架和方法:该研究提出了一种结合了无监督学习和有监督学习的方法来生成超声报告。
- 无监督学习的应用:框架利用无监督学习(聚类方法)从超声文本报告中提取潜在知识(prior knowledge)。这些知识被用作先验信息,以指导模型的训练过程,特别是帮助对齐视觉特征和文本特征,从而解决医学图像中固有的特征差异问题。
- 报告生成模块(Report Generator, RG):该模块基于 Transformer 编码器-解码器架构构建,并集成了一个相似性比较机制(Similarity Comparer, SC)。
- 这个机制在训练过程中通过计算预测报告与真实报告之间的整体相似性,来捕捉文本报告的全局语义信息。
- 目的是增强模型生成更全面、更准确、更长报告的能力,使输出更接近真实情况。
框架组成模块:
- 知识提取器(Knowledge Distiller, KD):用于从超声报告中获取先验知识。
- 知识匹配视觉提取器(Knowledge Matched Visual Extractor, KMVE):专注于提取与文本相关的视觉特征,并根据获取的知识来对齐视觉和文本特征。
- 报告生成器(Report Generator, RG):使用对齐后的视觉特征和比较机制来生成超声报告。
1. 引言
医学影像及其挑战:
- 重要性: 医学影像(如超声)能对内部器官、组织和结构提供非侵入性、实时的可视化,对现代医疗诊断至关重要。
- 人工解读的负担: 然而,解读医学图像并撰写报告是一个耗时、知识密集且依赖人工的过程,给临床医生带来了巨大负担。
- 需求增长: 随着医学影像规模的不断扩大,放射科医生和超声科医生难以满足日益增长的患者需求,可能导致诊断和治疗的延迟。
- 解决方案: 为了减轻这种压力,开发自动化医学报告生成算法来辅助医生撰写报告变得越来越重要。
现有自动报告生成技术及其局限性:
- 技术基础: 图像标注(Image Captioning)的成功为医学报告生成奠定了基础,启发研究人员使用相似的架构(主导方法是编码器-解码器结构)来实现报告自动生成。
- 具体实现: 这种结构通常使用卷积神经网络(CNN)从医学图像中提取视觉特征,然后使用循环神经网络(RNN)根据这些特征生成描述性文本。
- 挑战——特征不匹配: 医学图像与自然图像有显著差异,难以对齐视觉和文本特征。
- 医学图像视觉特征相似,非专业人士很难区分细微差别。
- 医学报告更长、更详细,描述了不同身体组织的复杂观察结果。
- 因此,图像和文本之间的特征多样性存在明显不匹配。
- 改进方法及其问题: 为了解决性能下降的问题,研究人员尝试了添加标注的疾病标签或利用医学报告副标题作为图像标签来辅助训练。虽然这些方法在报告生成任务中取得了不错的效果,但它们需要额外的标注数据,这给临床医生带来了额外的负担,并且不适用于所有类型的数据集。
超声报告生成的特殊挑战:
- 研究现状: 大多数现有医学报告生成研究集中在放射学报告(如基于 IU-Xray 和 MIMIC-CXR 等公开数据集),而超声报告生成的研究相对有限。
- 影像差异: 超声图像具有低对比度和伪影等特征,难以准确提取用于文本描述的相关视觉特征。
- 文本复杂性: 相比放射学报告,超声报告往往更长、更详细,通常包含对器官、病变和组织的详尽描述,增加了文本生成的复杂性。
- 现有工作侧重: 当前超声领域的方法倾向于描述生成,这更类似于图像标注,旨在预测用于教育目的的简短标题,而非完整的报告。
提出了一种新颖的报告生成框架,结合了无监督学习和监督学习方法来对齐视觉和文本特征。
结合无监督和监督学习: 这种方法受到医生学习和撰写报告过程的启发。
- 无监督学习提取知识: 框架利用无监督学习(如聚类方法)从文本报告中提取潜在的医学知识或先验知识。这类似于医生从病历中获取知识的过程。
- 指导视觉特征提取: 提取出的知识用于指导视觉特征提取器学习与文本相关的视觉特征。
- 弥合模态差距: 这种方法旨在在视觉和文本模态之间架起桥梁,减轻视觉和文本特征之间的不一致性,而且不需要额外的专家疾病标签,这使得它在大多数数据集中更具可访问性和效率。
报告生成器和相似性比较机制:
- 框架设计了一个报告生成器(Report Generator, RG),它以 Transformer 编码器-解码器架构为基础,并集成了相似性比较机制(Similarity Comparer, SC)。
- 增强报告生成: 为了提高模型学习长而复杂医学报告的全局语义的能力,设计了相似性比较机制来生成更准确、更长的报告。
- 计算相似性: 在训练过程中,该方法计算预测报告与**真实报告(ground truth reports)**之间的整体相似性(包括词级别和全局语义相似性),以捕捉文本报告的全局语义,从而产生更准确、更全面、更贴合真实的输出。
主要贡献:
- 新颖的框架设计: 提出了一个结合无监督和监督学习的框架,用于在不需要额外疾病标签的情况下,从文本报告中提取潜在的医学知识,从而对齐视觉和文本特征,缓解特征差距。
- 生成长而准确的报告: 框架通过采用相似性比较机制来生成长而准确的报告。这种方法结合了全局语义信息,能够生成复杂的句子,与其它方法相比,报告的信息量更高,准确性更高。
- 多器官超声数据集: 收集了三个独立的大规模超声图像-文本数据集,分别涵盖乳腺 (3521例患者)、甲状腺 (2474例患者) 和肝脏 (1395例患者)。据作者所知,这是首次在多器官超声报告数据集上进行评估和测试的研究。
2. 相关工作
2.1 Image caption
现有的Image caption方法可以分为两大类:基于模板/检索的方法和基于生成的方法。
- 基于模板或检索的方法:
- 这类方法涉及使用目标检测模型从图像中检测实体、属性和关系。
- 然后,基于识别出的关系,通过模板填充或从数据库中检索来生成文本句子。
- 基于生成的方法(主流方法):
- 这些方法以编码器-解码器架构为基础结构。
- 它使用视觉编码器从图像中提取视觉特征,然后使用解码器基于这些视觉特征生成描述性句子。
- 然而,基础的编码器-解码器结构的性能往往不足。因此,研究人员提出了各种改进措施,例如增强网络的编码器 或解码器组件。
2.2 放射学报告生成
放射学报告生成的重要性与挑战:
- 主要分支: 放射学报告生成是医学报告生成领域的主要分支,这主要是因为有广泛的放射学数据集可用。
- 基础方法: 该领域现有的大多数方法都采用了Image caption中使用的基于生成的模型(如编码器-解码器架构)。
- 挑战: 然而,将这些方法直接迁移到放射学报告生成中,通常无法达到图像字幕生成中可比的结果。
- 造成这种差异的原因在于放射学图像与自然图像之间固有的区别。
- 另一个原因是放射学报告的长度与Image caption的长度存在差异(医学报告通常更长、更详细)。
研究者提出的改进方法:
- 利用外部知识或辅助数据:
- 疾病分类特征: 使用 CNN 对从放射学图像中提取的特征进行分类,促使模型区分疾病类型。
- 知识图谱/图形模型:
- 构建了一个肺部疾病的图形模型来帮助解码器生成长且准确的报告。将这种图形模型用作先验知识来增强模型生成。
- 医学主题词 (MeSH): 利用医学主题词作为额外的知识,以促进模型学习图像和文本之间的关系。
- 局限性: 尽管这些方法增强了模型生成放射学报告的能力,但它们通常需要额外的先验数据,这需要单独收集或手动标注。
- 改进模型结构:
- 双分支竞争模型:设计了一个包含两个相互关联分支的模型,通过竞争方法提高训练效率。
- 基于强化学习的检索策略: 设计了一个基于强化学习的检索策略模块来辅助模型训练。
- 记忆驱动单元: 在 Transformer 中引入了记忆驱动单元,使网络能够基于相似的图像生成报告。
2.3 超声报告生成
超声报告与放射学报告的区别:
- 器官和疾病范围: 放射学报告(如胸片)主要侧重于肺部和心脏的病理描述,涉及的疾病和器官范围相对较窄。然而,超声检查可以用于全身不同的器官和组织。
- 报告风格和格式: 由于超声检查涉及的器官多样性,不同器官的报告在文本风格和格式上可能存在差异。
- 任务性质: 因此,研究者认为放射学报告生成和超声报告生成不应被视为完全相同的任务。
超声图像的特殊性:与 X 射线不同,超声成像本质上是三维的,这为数据处理提供了两种选择:
- 将其作为三维视频处理。
- 将其作为二维图像处理。
超声报告生成领域的现有研究:
- 视频格式的研究(Video Format Studies):现有以视频格式进行的研究主要集中在胎儿筛查方面。
- CNN-LSTM 模型: 研究者提出了一个基于 CNN-LSTM 的超声视频字幕生成模型 ,用于模拟医生在妊娠中期扫描时的口头描述。
- 注视引导网络: 利用医生的**注视图谱(gaze maps)**来引导网络关注图像中的感兴趣区域,从而提高了生成描述的质量。
- 二维图像格式的研究(2D Image Studies)
- 模板方法: 对于二维图像,研究者使用基于模板的方法来生成简短的疾病描述。
3. 方法
该论文提出的超声报告生成框架包含以下三个核心模块:
- 知识蒸馏器 (Knowledge Distiller, KD):从超声报告中获取先验知识(prior knowledge)
- 知识匹配的视觉特征提取器 (Knowledge Matched Visual Extractor, KMVE):提取与文本相关的视觉特征,并基于获取的先验知识来对齐视觉和文本特征
- 报告生成器 (Report Generator, RG):使用对齐后的视觉特征生成超声报告
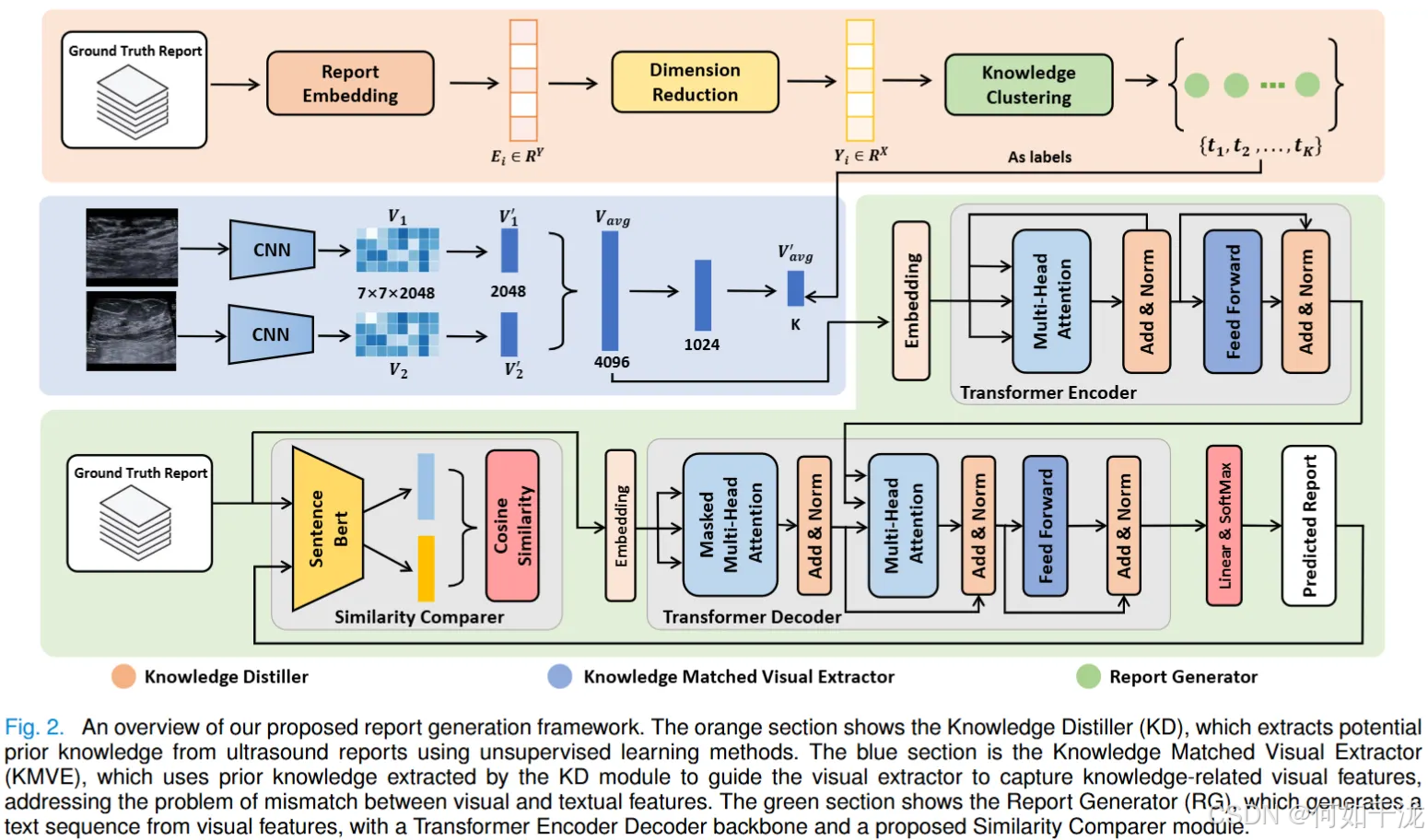
3.1 知识蒸馏器
医生通过学习经验丰富的专家的报告并总结他们的知识来提高专业水平。为了模仿这个过程,我们设计了基于**无监督聚类(unsupervised clustering)**的 知识蒸馏器 (Knowledge Distiller, KD) 模型,从超声报告 R = { R 1 , R 2 , … , R n } R = \{R_1, R_2, \dots, R_n\} R={R1,R2,…,Rn} 中提取先验知识 T = { t 1 , t 2 , … , t K } T = \{t_1, t_2, \dots, t_K\} T={t1,t2,…,tK}。
KD 过程包括三个阶段:报告嵌入(Report Embedding)、降维(Dimension Reduction)和知识聚类(Knowledge Clustering)。
- 报告嵌入 (Report Embedding): 将文本报告 R i R_i Ri 转化为数值特征 E i ∈ R Y E_i \in \mathbb{R}^Y Ei∈RY。这是整个 KD 流程中的关键一步。
- 方法评估: 考虑到超声报告比放射学报告更长、更复杂,为了确保 KD 的性能,系统评估了三种报告嵌入方法:词袋模型 (Bag of Words, BOW)、词频-逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF) 和 Sentence-Bert (S-Bert)。
- BOW:将报告表示为其组成词的集合。
- TF-IDF:根据词在文档中的频率和在语料库中的逆频率来计算每个词在报告中的重要性。
- S-Bert:利用预训练的语言模型将报告嵌入到向量表示中。
- 方法评估: 考虑到超声报告比放射学报告更长、更复杂,为了确保 KD 的性能,系统评估了三种报告嵌入方法:词袋模型 (Bag of Words, BOW)、词频-逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF) 和 Sentence-Bert (S-Bert)。
- 降维 (Dimension Reduction): 减轻高维嵌入向量带来的计算复杂性。
- 使用 均匀流形逼近与投影 (Uniform Manifold Approximation and Projection, UMAP) 方法来降低嵌入向量的维度。
- UMAP 特点: UMAP 是一种基于流形学习的非线性降维算法,能够在保留固有数据结构的同时,将高维数据降到较低维空间。
- 结果: 对于给定的嵌入向量 E i ∈ R Y E_i \in \mathbb{R}^Y Ei∈RY,应用 UMAP 后得到降维向量 Y i = Φ u m a p ( E i ) Y_i = \Phi_{umap}(E_i) Yi=Φumap(Ei),其中 Y i ∈ R X Y_i \in \mathbb{R}^X Yi∈RX 且 X < Y X < Y X<Y。
- 知识聚类 (Knowledge Clustering): 旨在通过将相似的文本报告分组在一起来提取潜在的先验知识。
- 聚类算法: 在降维后的报告嵌入向量集 Y = { y 1 , y 2 , … , y n } Y = \{y_1, y_2, \dots, y_n\} Y={y1,y2,…,yn} 上应用聚类算法,将它们分成 K K K 个簇。
- 具体方法: 使用 K-Means 方法进行聚类。报告向量 y i y_i yi 被分配到簇 t k t_k tk 的依据是最小化 y i y_i yi 与簇质心 m j m_j mj 之间的欧几里得距离。 t k = a r g , m i n j ∣ y i − m j ∣ 2 t_k=arg,min_j∣y_i−m_j∣^2 tk=arg,minj∣yi−mj∣2
- 选择 K-Means 的原因: 采用 K-Means 而非 HDBSCAN 方法,是因为 K-Means 具有更低的计算复杂性。评估结果显示,K-Means 更适合中文超声数据集,它提供了有竞争力的性能和更低的计算成本。
- 聚类结果: 知识聚类后,文本报告被组织成 K K K 个组,记为 T = { t 1 , t 2 , … , t K } T = \{t_1, t_2, \dots, t_K\} T={t1,t2,…,tK}。每个组 t i t_i ti 不仅包含医生的书写风格,还蕴含了报告中的潜在知识。
3.2 知识匹配的视觉特征提取器
KMVE模块的核心目标是利用知识蒸馏器获取的先验知识作为伪标签,来促进学习与这些知识相关的视觉特征,从而弥合视觉特征和文本特征之间的差距。
工作流程详解:
- 输入和初始特征提取:
- 给定输入的图像对 I = { i m 1 , i m 2 } I = \{i_{m^1}, i_{m^2}\} I={im1,im2}。每张图像 i m i_m im 都由一个张量 R C × H × W \mathbb {R}^{C \times H \times W} RC×H×W表示,其中 C C C 是通道数, H H H 和 W W W 分别是图像的高度和宽度。
- KMVE 模块首先利用一个共享权重的CNN编码器从超声图像中提取视觉特征。
- 由于超声图像存在的低对比度和伪影挑战,选择在ImageNet上预训练的 ResNet-101 模型作为特征提取的主干网络,因为它在各种医学图像分析任务中表现出色。
- 通过这一操作,图像对被转换为视觉特征集合 { V 1 , V 2 } ∈ R 7 × 7 × 2048 \{V_1, V_2\} \in R^{7 \times 7 \times 2048} {V1,V2}∈R7×7×2048。
- 特征处理和全局特征生成:
- 接下来,使用一个核大小为 7 × 7 7 \times 7 7×7 的卷积层进行平均池化(average pooling),进一步处理特征 { V 1 , V 2 } \{V_1, V_2\} {V1,V2},得到 { V 1 ′ , V 2 ′ } ∈ R 2048 \{V'_1, V'_2\} \in R^{2048} {V1′,V2′}∈R2048。
- 然后,将这两个特征拼接起来,以获得全局平均特征 V a v g ∈ R 4096 V_{avg} \in R^{4096} Vavg∈R4096。
- 知识对齐与损失计算:
- 为了与知识主题 T T T 的大小对齐, V a v g V_{avg} Vavg 被进一步转换为 V a v g ′ ∈ R K V'_{avg} \in R^K Vavg′∈RK( K K K 是知识主题的数量)。
- 这种降维使得KMVE模块能够计算损失函数( L k m v e L_{kmve} Lkmve),公式如下:
L k m v e = − ∑ i = 1 K ( t i × l o g ( S f ( V a v g ′ ) ) ) L_{kmve}=−∑_{i=1}^K(t_i×log(S_f(V_{avg}^′))) Lkmve=−∑i=1K(ti×log(Sf(Vavg′)))
其中, t i t_i ti 代表知识主题 T T T 中的每个聚类(cluster),作为伪标签; S f ( ⋅ ) S_f(\cdot) Sf(⋅) 是SoftMax函数。
- 报告生成器输入: 由于 V a v g V_{avg} Vavg 具有更高的维度,相较于 V a v g ′ V_{avg}^{'} Vavg′*,*它包含更全面的视觉特征细节。因此,选择视觉特征 V a v g V_{avg} Vavg 作为报告生成器(Report Generator)的输入。
3.3 报告生成器
生成器(Report Generator, RG) 模块旨在确保生成的报告在长度和准确性上保持一致,它同时考虑了词语级别(word-level)和全局语义相似性(global semantic similarity)。RG 的核心构建在 Transformer 编码器-解码器架构(Transformer encoder-decoder architecture) 和提出的 相似性比较器(Similarity Comparer, SC) 模块之上。
- Transformer 编码器-解码器 (TF):Transformer 编码器(TE)和Transformer 解码器(TD)。
- Transformer 编码器 (TE):
- 输入处理: 全局视觉特征 V a v g V_{avg} Vavg 首先被转换为查询(Query, Q)、键(Key, K)和值(Value, V)。
- 多头注意力(MHA): 随后应用 MHA 来计算 Q、K 和 V 之间的缩放点积注意力。MHA 包含 n n n 个并行头,用于捕获不同子空间中的细节,并将所有头的结果连接起来以获取不同的空间信息。
- 前馈网络(FFN): MHA 的输出接着通过 FFN。
- 规范化: 重要的是,MHA 和 FFN 之后都跟随**残差连接(residual connection)和层归一化(Layer Normalization, LN)**操作。
- Transformer 解码器 (TD):
- 输入: TE 的输出作为解码器的输入。
- 词嵌入: 当前时间步的输入词嵌入 x t = w t + p t x_t = w_t + p_t xt=wt+pt 也被输入到 TD 中(其中 w t w_t wt 是词嵌入, p t p_t pt 是位置嵌入)。
- 注意力与网络: 类似于 TE 模块,应用 MHA 将输入转换为向量 h m h_m hm。接着,MHA 的输出被送入 FFN 和 LN,表示为 h ′ = L N ( h m + F F N ( h m ) ) h' = LN(h_m + FFN(h_m)) h′=LN(hm+FFN(hm))。
- 词语预测: 最终,使用公式 y t ∼ p t = S f ( h ′ W p + b p ) y_t \sim p_t = S_f (h' W_p + b_p) yt∼pt=Sf(h′Wp+bp) 生成预测词语,其中 W p W_p Wp 和 b p b_p bp 是可学习参数。
- TF 损失函数: TF 损失函数 L T F L_{TF} LTF 的定义如下(用于衡量词语级别的差异):
L T F = − ∑ i = 1 n ( y i ⋅ l o g ( p i ) + ( 1 − y i ) ⋅ l o g ( 1 − p i ) ) L_{TF}=−∑_{i=1}^n(y_i⋅log(p_i)+(1−y_i)⋅log(1−p_i)) LTF=−∑i=1n(yi⋅log(pi)+(1−yi)⋅log(1−pi))
- Transformer 编码器 (TE):
- 相似性比较器 (SC):超声报告通常包含更长、更复杂的句子,需要全面包含所有相关的描述。TF 中的损失函数( L T F L_{TF} LTF)侧重于单个词语之间的差异,缺乏衡量报告整体语义相似性的能力。为了解决这一挑战,作者设计了相似性比较器(SC),它能够比较预测报告 p p p 和真实报告 y y y 之间的全局语义。通过整合 SC 模块,模型能够生成提供更全面描述的报告。
- 相似性分数计算:
- 嵌入: 使用 S-Bert 模型对预测报告进行嵌入。
- 向量表示: 真实报告和预测报告分别表示为向量 y e ∈ R 768 y_e \in \mathbb{R}^{768} ye∈R768 和 p e ∈ R 768 p_e \in \mathbb{R}^{768} pe∈R768。
- 余弦相似度: 计算这些向量之间的 余弦相似度(cosine similarity) 来确定相似性分数 S S S。
- 规范化: 应用 RELU 激活函数确保相似性分数 S S S 介于 0 和 1 之间, S = f r e l u ( f c s ( y e , p e ) ) S=f_{relu}(f_{cs}(y_e,p_e)) S=frelu(fcs(ye,pe)),其中 f r e l u f_{relu} frelu 和 f c s f_{cs} fcs 分别代表 RELU 激活函数和余弦相似度函数。
- SC 损失函数: L S C L_{SC} LSC 定义为相似性分数的负对数,并对报告中的所有句子求和 L S C = − ∑ i = 1 N r l o g ( S i ) L_{SC}=−∑_{i=1}^{N_r} log(S_i) LSC=−∑i=1Nrlog(Si)
- 相似性分数计算:
- 训练策略: 在训练阶段,框架结合了三种损失( L K M V E L_{KMVE} LKMVE、 L T F L_{TF} LTF 和 L S C L_{SC} LSC)。训练步骤如下:
- 模型首先计算 L K M V E L_{KMVE} LKMVE 和 L T F L_{TF} LTF 损失。
- 然后,网络被冻结(frozen)以稳定其参数,用于生成完整的预测报告。
- 最后,网络被解冻(unfrozen),以计算真实报告和预测报告之间的 L S C L_{SC} LSC。
4. 实验
4.1 数据集
为了评估框架的性能,研究人员收集了三个独立的超声数据集,分别针对不同的器官:
- 乳腺(Breast): 包含3521名患者。
- 甲状腺(Thyroid): 包含2474名患者。
- 肝脏(Liver): 包含1395名患者。
这些数据集都来自解放军总医院超声科的数据库。
数据预处理:
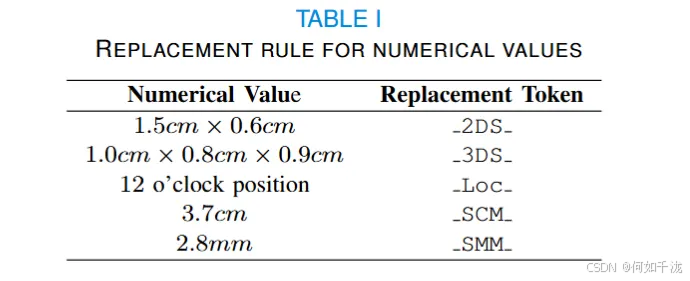
- 对超声报告进行了分词。
- 将文本中的数值(如病灶大小和位置)替换为特殊符号(如2DS、3DS、Loc、SCM、SMM),这是因为生成模型在数值预测的准确性上存在限制。
- 在每份报告的开头和结尾插入了
<start>和<end>标记。 - 每个数据集按7:1:2的比例划分为训练集、验证集和测试集,并确保数据不重叠。
4.2 实验设置
该研究评估预测报告质量采用了三种主要的指标:自然语言生成(NLG)指标、临床效用(CE)指标,以及预测报告与真实报告之间的蕴含关系(entailment)。
- 自然语言生成 (NLG) 指标: 用于综合评估生成报告与真实报告之间的相似性,包括:
- BLEU (Bilingual Evaluation Understudy): 衡量生成文本与真实文本之间的词汇重叠度,包括BLEU-1、BLEU-2、BLEU-3和BLEU-4等不同n-gram级别的重叠度,从而捕捉不同程度的语言相似性。
- ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence): 基于最长公共子序列算法的指标。它考虑句子级别结构的相似性,并识别序列中最长共现的n-grams,有效捕捉生成报告和参考报告之间的整体结构相似性。
- METEOR (Metric for Evaluation of Translation with Explicit Ordering): 通过同时考虑精确率和召回率以及语言特征(如词序和同义词)来评估生成文本的质量。
- 临床效用 (CE) 指标: 旨在关注报告中的关键信息,而不是文本相似性。研究者根据超声医师的建议,为每份报告提取了关键实体(key entities)。
- 评估方法: 任务被转化为多标签分类问题。如果报告中提到了感兴趣的实体 ∗ i ∗ *i* ∗i∗,则标记为1 ( y i = 1 y_i = 1 yi=1);否则标记为0 ( y i = 0 y_i = 0 yi=0)。
- 计算指标: 最终计算准确率(accuracy)、精确率(precision)、召回率(recall)和F1分数。
- 蕴含关系 (Natural Language Inference, NLI): 使用了自然语言推理(NLI)模型来判断预测报告在逻辑上是否符合真实报告。
- 重要性: 在医学领域,准确描述每种病理至关重要,例如,“高回声”和“低回声”都属于“回声”,但它们的解释是截然相反的。
- 实施方法: 研究聚合了每个实体的句子,并使用基于BERT的DeBERTa模型来比较这些聚合的句子与相关的聚合真实报告句子。
该模型的实现细节如下:
- 硬件和框架: 该模型使用PyTorch框架实现,并在两块NVIDIA GeForce RTX 3090 GPU6上进行训练。
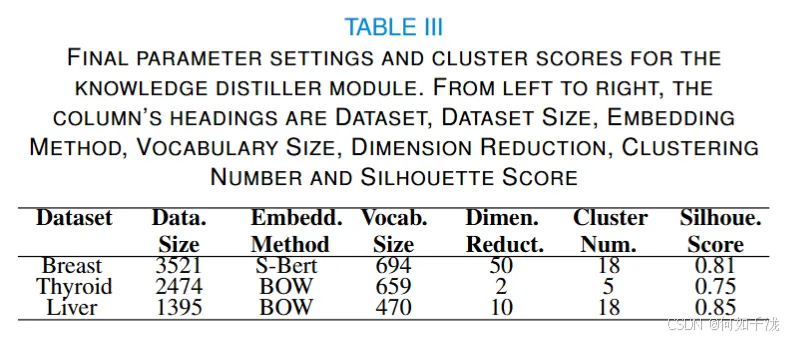
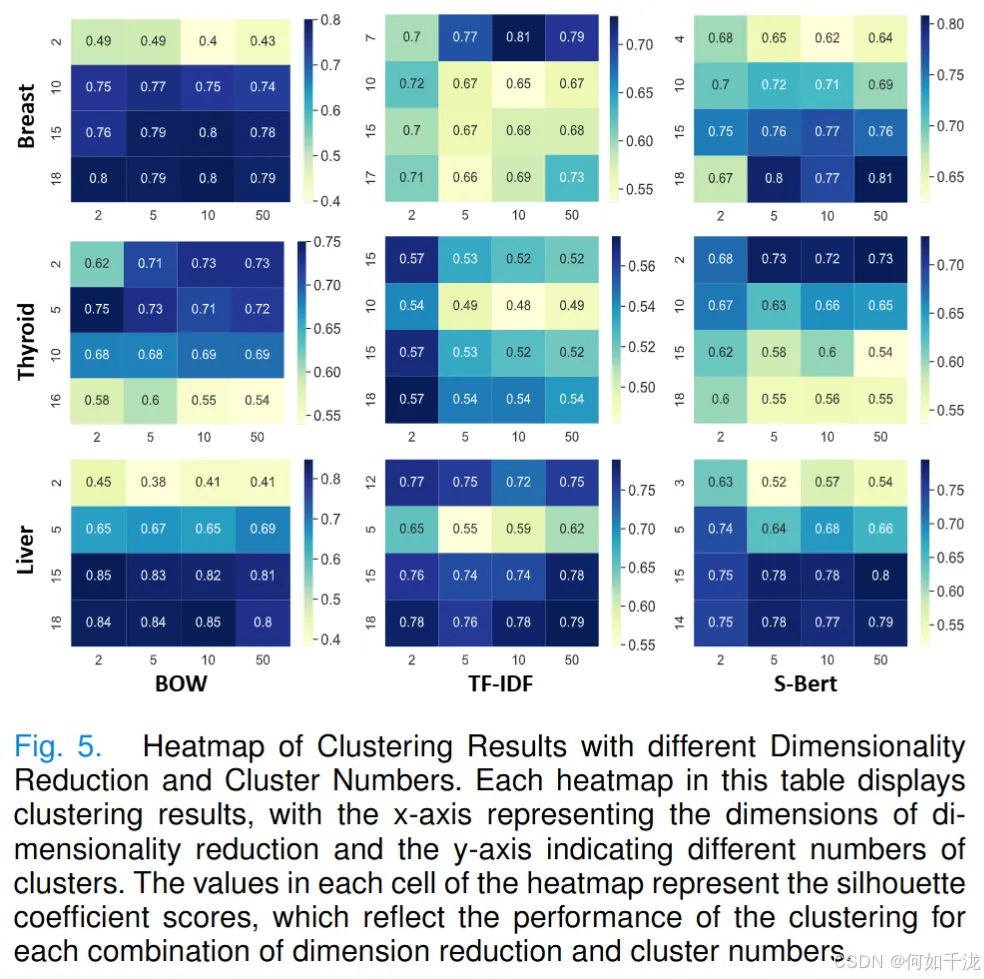
- 模块优化(KD模块):为优化知识蒸馏器(KD)模块,分别在三个不同的数据集(乳腺、甲状腺和肝脏)上进行了实验,以确定嵌入方法、降维和聚类数量的最佳选择。这些优化结果作为框架的先验知识。KD的优化过程包括两个步骤:
- 使用轮廓系数和elbow法则确定不同嵌入方法(词袋法、TF-IDF和S-Bert)的聚类数量的大致范围。
- 通过选择轮廓系数最高的结果来确定最终聚类结果,使用四个常见的降维维度(2、5、10和50)评估性能,并从初始粗略范围7中均匀采样四个聚类数。
- 报告生成器(RG模型)配置:
- Transformer编码器(TE)和Transformer解码器(TD)的层数均设置为3。
- 多头注意力(MHA)的特征维度设置为512,使用8个头。
- 句子生成的最大句子长度设置为150。
- 训练参数:
- 整个网络的最大训练轮数设置为 50。
- 当验证损失在10个训练周期内没有下降时,训练停止(提前停止)。
- 训练过程中的批次大小设置为128。
- 优化器和学习率:
- 使用了ADAM优化器。
- 知识匹配视觉提取器(KMVE)的学习率设置为5e-4。
- 报告生成器(RG)的学习率设置为1e-4。
- 在训练期间,学习率在每个epoch之后衰减0.8倍。
- 平衡权重(损失函数): 平衡权重 λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2 和 λ 3 \lambda_3 λ3 分别设置为 0.4、0.6 和 0.4。这些权重是通过对肝脏数据集中随机选取的10%样本进行参数搜索确定的。
- λ 1 \lambda_1 λ1对应于KMVE损失( L K M V E L_{KMVE} LKMVE)
- λ 2 \lambda_2 λ2 对应于基本的Transformer损失 ( L T F L_{TF} LTF)
- λ 3 \lambda_3 λ3对应于相似度比较器损失( L S C L_{SC} LSC)
- 将 L T F L_{TF} LTF( λ 2 = 0.6 \lambda_2=0.6 λ2=0.6)的权重设置得相对大于 L K M V E L_{KMVE} LKMVE和 L S C L_{SC} LSC,以维持框架的有效性,因为模型需要先学习逐词生成,再专注于相似度和知识匹配。
- λ 1 \lambda_1 λ1 和 λ 3 \lambda_3 λ3 被设置为相等( λ 1 = λ 3 = 0.4 \lambda_1 = \lambda_3 = 0.4 λ1=λ3=0.4),因为这两个损失被认为对报告生成的贡献相等。
- 总损失的计算公式为: L s u m = λ 1 L K M V E + λ 2 L T F + λ 3 L S C L_{sum} = \lambda_1 L_{KMVE} + \lambda_2 L_{TF} + \lambda_3 L_{SC} Lsum=λ1LKMVE+λ2LTF+λ3LSC。
4.3 知识蒸馏器实验
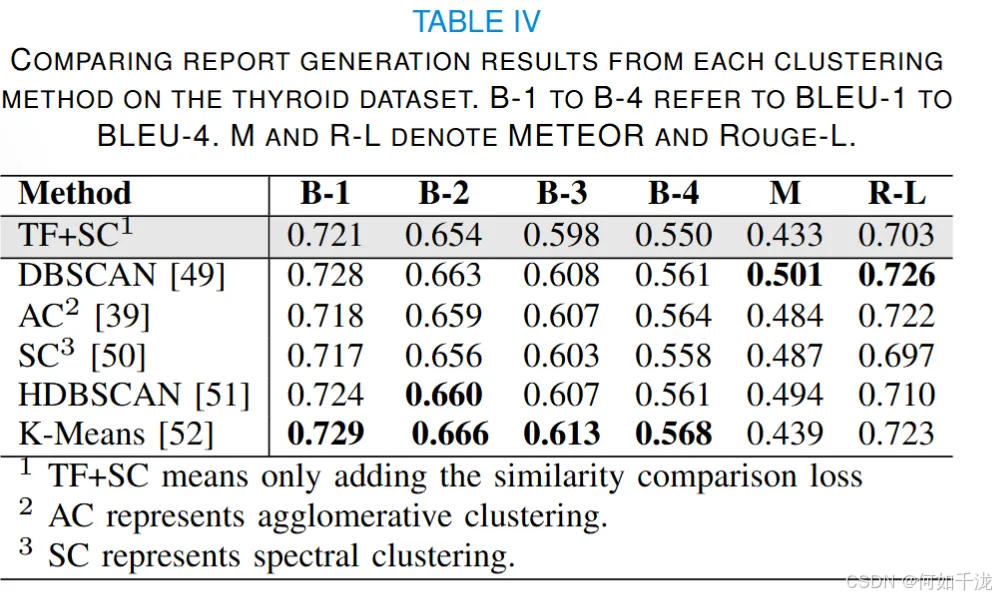
根据表三,S-Bert 在乳腺数据集上表现最佳,而传统 BOW 模型在甲状腺和肝脏数据集上效果显著。这可能是因数据集大小和文本特征不同,乳腺数据集大且文本复杂,简单 BOW 模型处理欠佳;甲状腺和肝脏数据集小且文本多样性低,BOW 模型更优,也表明文本多样性有限时,S-Bert 预训练嵌入优势不明显
4.4 不同聚类方法的实验
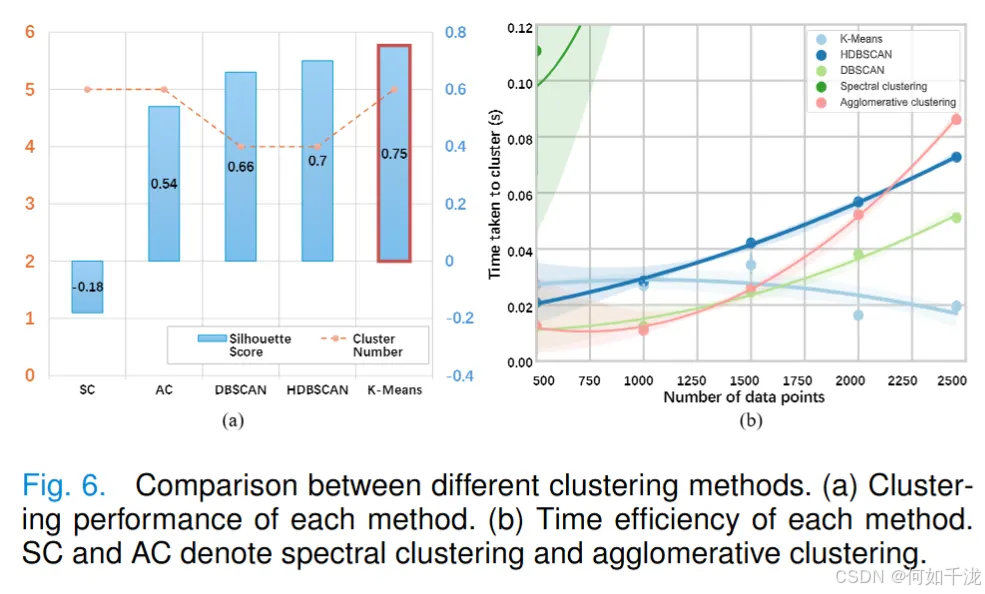
选K - Means算法做知识聚类,因其计算复杂度低且在数据集上性能佳。通过与其他聚类方法对比,在甲状腺数据集上K - Means轮廓系数更高(0.75),处理超2000个数据点时耗时更低。基于聚类结果对最终报告生成的影响评估,K - Means的BLEU分数最高,相比用HDBSCAN的先前工作,它更适合中文超声数据集。虽有些方法在METEOR和ROUGE - L指标上有优势,但K - Means因计算量低更适合大数据集,且所有方法都超无无监督聚类引导的基线“TF+SC”,说明无监督引导能提升无数据标签场景下的报告生成效果。
4.5 定量结果
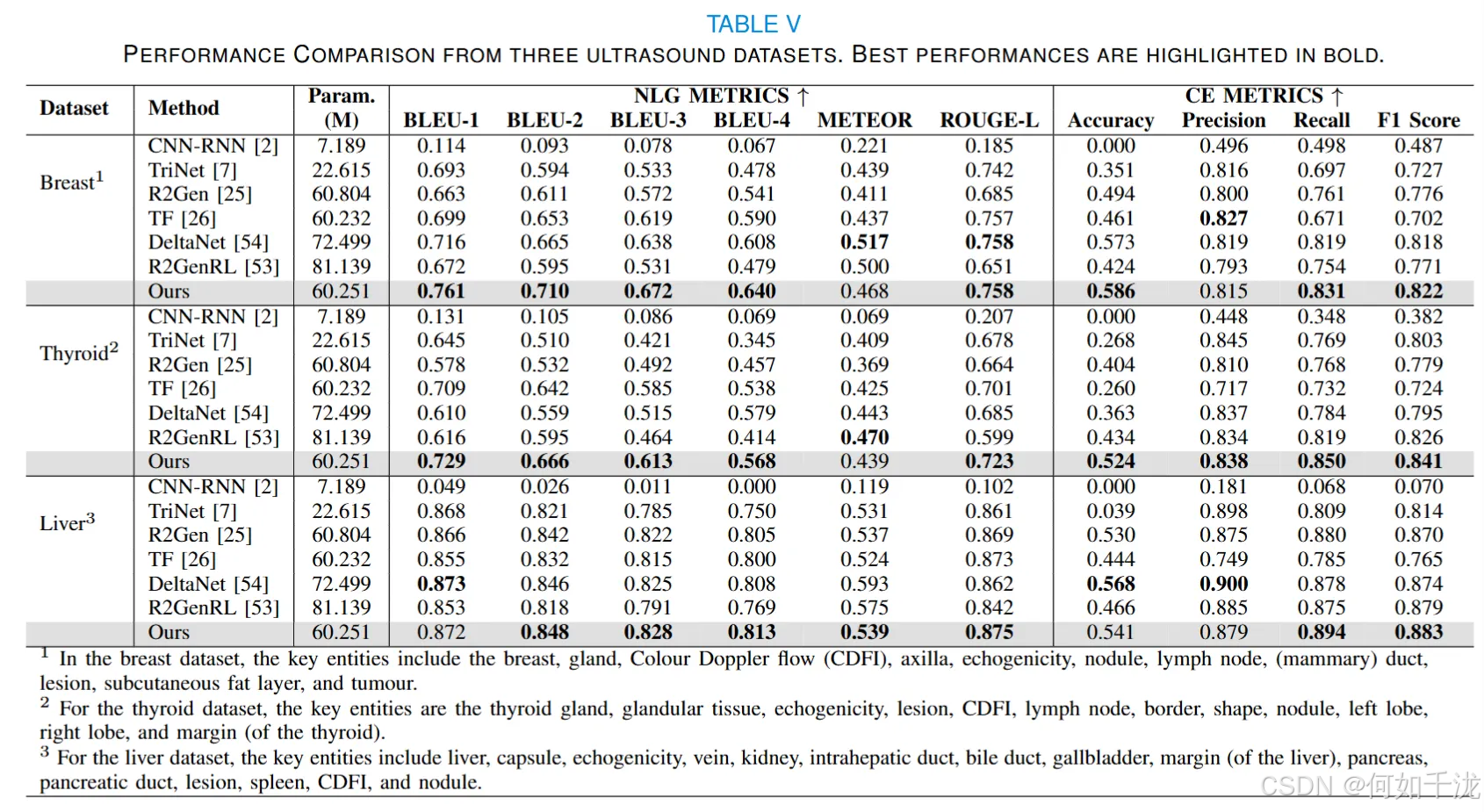
为证明方法有效性,将其与CNN - RNN、TriNet、R2Gen、TF、R2GenRL、DeltaNet六种方法对比。
- 在乳腺数据集,该方法多数指标更优,BLEU - 1至BLEU - 4较DeltaNet分别提升6.3%、6.8%、5.33%、5.26%;
- 甲状腺数据集表现更优,较R2GenRL准确率提高20.74%;
- 肝脏数据集召回率和F1分数最高。
所有数据集召回率均较高,图7显示多数预测实体与原报告相符,如“回声”的蕴含数为359,高于DeltaNet的327。

4.6 消融实验
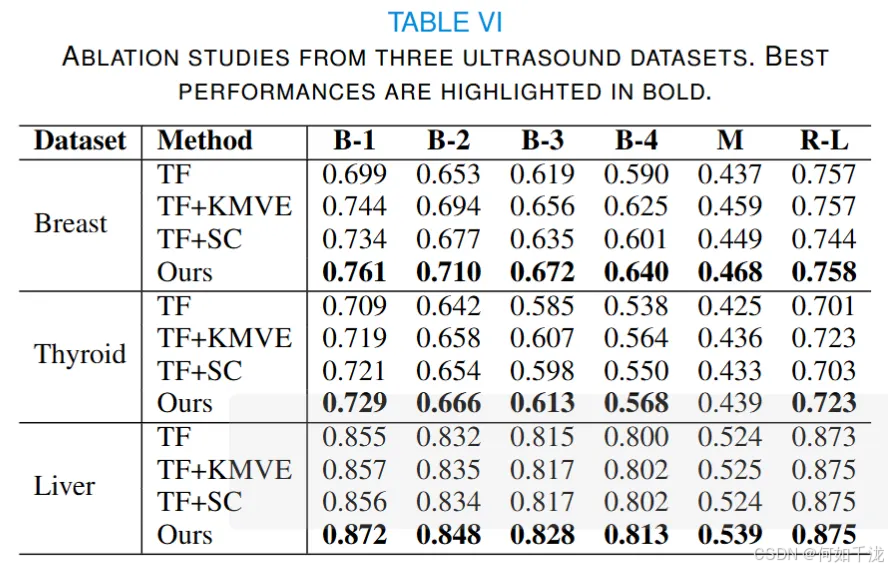
在本节中,我们进行消融实验验证各模块有效性,结果见表格 VI。实验配置包括仅用 Transformer 模型(TF)、加 KMVE 损失(TF+KMVE)、加 SC 损失(TF+SC),我们的方法结合两者。结果显示:
- 训练中加入 KMVE 损失,乳腺数据集 BLEU - 1 提升 4.5%,甲状腺数据集 BLEU - 4 提升 2.6%,肝脏数据集 BLEU - 2 提升 0.3%,表明 KMVE 模块有助于生成更准确报告。
- 加入 SC 损失,多数指标也有提升,但肝脏数据集提升较小,可能因其规模小且基础方法 BLEU - 4 已达 0.80,改进空间小。
总之,实验验证了框架有效性,KMVE 模块提升文本生成质量,SC 模块通过评估语义一致性进一步提升性能。
4.7 可视化结果

上图展示乳腺数据集超声报告生成结果,加粗下划线句子与真实报告语义相同,结果表明该方法生成关键细节能力强,能平衡正常与异常描述,接近真实报告。

上图展示甲状腺和肝脏数据集结果,该方法在甲状腺数据集能捕捉异常结节,与 R2Gen 在肝脏数据集结果差异小。但该方法在确定病变数量和精确位置方面存在挑战,这是超声报告生成领域的常见问题。
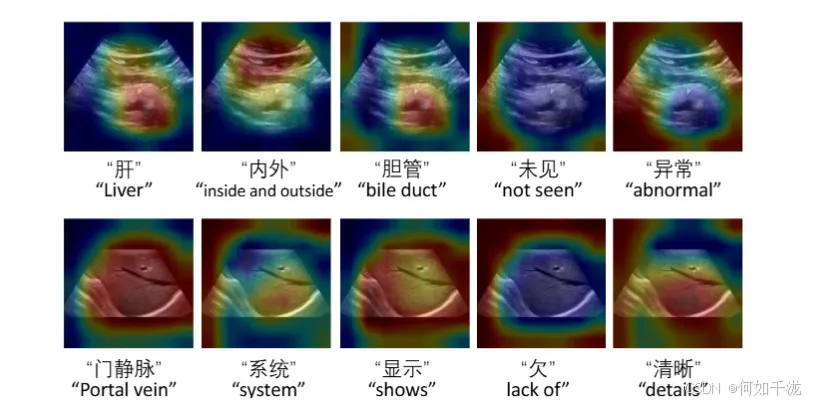
上图展示模型词级注意力图,关键术语受关注多,抽象术语受关注少
5. 结论
在我们的工作中,我们提出了一个新颖的报告生成框架,该框架结合了无监督学习和有监督学习方法,以对齐视觉和文本特征。具体来说,我们利用无监督学习从文本报告中提取潜在的医学知识,而无需额外的疾病标签,从而减轻了医学报告生成过程中视觉和文本之间的差距。此外,我们的框架通过采用相似性比较机制生成准确且较长的报告,该机制结合了全局语义信息以生成复杂的句子。最后,我们收集了三个大型的超声图像文本数据集,分别涵盖了乳房、甲状腺和肝脏,这是首次在多器官超声报告数据集上进行评估和测试的工作。
3.1 知识蒸馏器
医生通过学习经验丰富的专家的报告并总结他们的知识来提高专业水平。为了模仿这个过程,我们设计了基于**无监督聚类(unsupervised clustering)**的 知识蒸馏器 (Knowledge Distiller, KD) 模型,从超声报告 R = { R 1 , R 2 , … , R n } R = \{R_1, R_2, \dots, R_n\} R={R1,R2,…,Rn} 中提取先验知识 T = { t 1 , t 2 , … , t K } T = \{t_1, t_2, \dots, t_K\} T={t1,t2,…,tK}。
KD 过程包括三个阶段:报告嵌入(Report Embedding)、降维(Dimension Reduction)和知识聚类(Knowledge Clustering)。
- **报告嵌入 (Report Embedding):**将文本报告 R i R_i Ri 转化为数值特征 E i ∈ R Y E_i \in \mathbb{R}^Y Ei∈RY。这是整个 KD 流程中的关键一步。
- 方法评估: 考虑到超声报告比放射学报告更长、更复杂,为了确保 KD 的性能,系统评估了三种报告嵌入方法:词袋模型 (Bag of Words, BOW)、词频-逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF) 和 Sentence-Bert (S-Bert)。
- BOW:将报告表示为其组成词的集合。
- TF-IDF:根据词在文档中的频率和在语料库中的逆频率来计算每个词在报告中的重要性。
- S-Bert:利用预训练的语言模型将报告嵌入到向量表示中。
- 方法评估: 考虑到超声报告比放射学报告更长、更复杂,为了确保 KD 的性能,系统评估了三种报告嵌入方法:词袋模型 (Bag of Words, BOW)、词频-逆文档频率 (Term Frequency-Inverse Document Frequency, TF-IDF) 和 Sentence-Bert (S-Bert)。
- **降维 (Dimension Reduction):**减轻高维嵌入向量带来的计算复杂性。
- 使用 均匀流形逼近与投影 (Uniform Manifold Approximation and Projection, UMAP) 方法来降低嵌入向量的维度。
- UMAP 特点: UMAP 是一种基于流形学习的非线性降维算法,能够在保留固有数据结构的同时,将高维数据降到较低维空间。
- 结果: 对于给定的嵌入向量 E i ∈ R Y E_i \in \mathbb{R}^Y Ei∈RY,应用 UMAP 后得到降维向量 Y i = Φ u m a p ( E i ) Y_i = \Phi_{umap}(E_i) Yi=Φumap(Ei),其中 Y i ∈ R X Y_i \in \mathbb{R}^X Yi∈RX 且 X < Y X < Y X<Y。
- **知识聚类 (Knowledge Clustering):**旨在通过将相似的文本报告分组在一起来提取潜在的先验知识。
- 聚类算法: 在降维后的报告嵌入向量集 Y = { y 1 , y 2 , … , y n } Y = \{y_1, y_2, \dots, y_n\} Y={y1,y2,…,yn} 上应用聚类算法,将它们分成 K K K 个簇。
- 具体方法: 使用 K-Means 方法进行聚类。报告向量 y i y_i yi 被分配到簇 t k t_k tk 的依据是最小化 y i y_i yi 与簇质心 m j m_j mj 之间的欧几里得距离。 t k = a r g , m i n j ∣ y i − m j ∣ 2 t_k=arg,min_j∣y_i−m_j∣^2 tk=arg,minj∣yi−mj∣2
- 选择 K-Means 的原因: 采用 K-Means 而非 HDBSCAN 方法,是因为 K-Means 具有更低的计算复杂性。评估结果显示,K-Means 更适合中文超声数据集,它提供了有竞争力的性能和更低的计算成本。
- 聚类结果: 知识聚类后,文本报告被组织成 K K K 个组,记为 T = { t 1 , t 2 , … , t K } T = \{t_1, t_2, \dots, t_K\} T={t1,t2,…,tK}。每个组 t i t_i ti 不仅包含医生的书写风格,还蕴含了报告中的潜在知识。
3.2 知识匹配的视觉特征提取器
KMVE模块的核心目标是利用知识蒸馏器获取的先验知识作为伪标签,来促进学习与这些知识相关的视觉特征,从而弥合视觉特征和文本特征之间的差距。
工作流程详解:
- 输入和初始特征提取:
- 给定输入的图像对 I = { i m 1 , i m 2 } I = \{i_{m^1}, i_{m^2}\} I={im1,im2}。每张图像 i m i_m im 都由一个张量 R C × H × W \mathbb {R}^{C \times H \times W} RC×H×W表示,其中 C C C 是通道数, H H H 和 W W W 分别是图像的高度和宽度。
- KMVE 模块首先利用一个共享权重的CNN编码器从超声图像中提取视觉特征。
- 由于超声图像存在的低对比度和伪影挑战,选择在ImageNet上预训练的 ResNet-101 模型作为特征提取的主干网络,因为它在各种医学图像分析任务中表现出色。
- 通过这一操作,图像对被转换为视觉特征集合 { V 1 , V 2 } ∈ R 7 × 7 × 2048 \{V_1, V_2\} \in R^{7 \times 7 \times 2048} {V1,V2}∈R7×7×2048。
- 特征处理和全局特征生成:
- 接下来,使用一个核大小为 7 × 7 7 \times 7 7×7 的卷积层进行平均池化(average pooling),进一步处理特征 { V 1 , V 2 } \{V_1, V_2\} {V1,V2},得到 { V 1 ′ , V 2 ′ } ∈ R 2048 \{V'_1, V'_2\} \in R^{2048} {V1′,V2′}∈R2048。
- 然后,将这两个特征拼接起来,以获得全局平均特征 V a v g ∈ R 4096 V_{avg} \in R^{4096} Vavg∈R4096。
- 知识对齐与损失计算:
- 为了与知识主题 T T T 的大小对齐, V a v g V_{avg} Vavg 被进一步转换为 V a v g ′ ∈ R K V'_{avg} \in R^K Vavg′∈RK( K K K 是知识主题的数量)。
- 这种降维使得KMVE模块能够计算损失函数( L k m v e L_{kmve} Lkmve),公式如下:
L k m v e = − ∑ i = 1 K ( t i × l o g ( S f ( V a v g ′ ) ) ) L_{kmve}=−∑_{i=1}^K(t_i×log(S_f(V_{avg}^′))) Lkmve=−∑i=1K(ti×log(Sf(Vavg′)))
其中, t i t_i ti 代表知识主题 T T T 中的每个聚类(cluster),作为伪标签; S f ( ⋅ ) S_f(\cdot) Sf(⋅) 是SoftMax函数。
- **报告生成器输入:**由于 V a v g V_{avg} Vavg 具有更高的维度,相较于 V a v g ′ V_{avg}^{'} Vavg′*,*它包含更全面的视觉特征细节。因此,**选择视觉特征 V a v g V_{avg} Vavg**作为报告生成器(Report Generator)的输入。
3.3 报告生成器
生成器(Report Generator, RG) 模块旨在确保生成的报告在长度和准确性上保持一致,它同时考虑了词语级别(word-level)和全局语义相似性(global semantic similarity)。RG 的核心构建在**Transformer 编码器-解码器架构(Transformer encoder-decoder architecture)和提出的相似性比较器(Similarity Comparer, SC)**模块之上。
- Transformer 编码器-解码器 (TF):Transformer 编码器(TE)和Transformer 解码器(TD)。
- Transformer 编码器 (TE):
- 输入处理: 全局视觉特征 V a v g V_{avg} Vavg 首先被转换为查询(Query, Q)、键(Key, K)和值(Value, V)。
- 多头注意力(MHA): 随后应用 MHA 来计算 Q、K 和 V 之间的缩放点积注意力。MHA 包含 n n n 个并行头,用于捕获不同子空间中的细节,并将所有头的结果连接起来以获取不同的空间信息。
- 前馈网络(FFN): MHA 的输出接着通过 FFN。
- 规范化: 重要的是,MHA 和 FFN 之后都跟随**残差连接(residual connection)和层归一化(Layer Normalization, LN)**操作。
- Transformer 解码器 (TD):
- 输入: TE 的输出作为解码器的输入。
- 词嵌入: 当前时间步的输入词嵌入 x t = w t + p t x_t = w_t + p_t xt=wt+pt 也被输入到 TD 中(其中 w t w_t wt 是词嵌入, p t p_t pt 是位置嵌入)。
- 注意力与网络: 类似于 TE 模块,应用 MHA 将输入转换为向量 h m h_m hm。接着,MHA 的输出被送入 FFN 和 LN,表示为 h ′ = L N ( h m + F F N ( h m ) ) h' = LN(h_m + FFN(h_m)) h′=LN(hm+FFN(hm))。
- 词语预测: 最终,使用公式 y t ∼ p t = S f ( h ′ W p + b p ) y_t \sim p_t = S_f (h' W_p + b_p) yt∼pt=Sf(h′Wp+bp) 生成预测词语,其中 W p W_p Wp 和 b p b_p bp 是可学习参数。
- TF 损失函数: TF 损失函数 L T F L_{TF} LTF 的定义如下(用于衡量词语级别的差异):
L T F = − ∑ i = 1 n ( y i ⋅ l o g ( p i ) + ( 1 − y i ) ⋅ l o g ( 1 − p i ) ) L_{TF}=−∑_{i=1}^n(y_i⋅log(p_i)+(1−y_i)⋅log(1−p_i)) LTF=−∑i=1n(yi⋅log(pi)+(1−yi)⋅log(1−pi))
- Transformer 编码器 (TE):
- 相似性比较器 (SC):超声报告通常包含更长、更复杂的句子,需要全面包含所有相关的描述。TF 中的损失函数( L T F L_{TF} LTF)侧重于单个词语之间的差异,缺乏衡量报告整体语义相似性的能力。为了解决这一挑战,作者设计了相似性比较器(SC),它能够比较预测报告 p p p 和真实报告 y y y 之间的全局语义。通过整合 SC 模块,模型能够生成提供更全面描述的报告。
- 相似性分数计算:
- 嵌入: 使用 S-Bert 模型对预测报告进行嵌入。
- 向量表示: 真实报告和预测报告分别表示为向量 y e ∈ R 768 y_e \in \mathbb{R}^{768} ye∈R768 和 p e ∈ R 768 p_e \in \mathbb{R}^{768} pe∈R768。
- 余弦相似度: 计算这些向量之间的**余弦相似度(cosine similarity)**来确定相似性分数 S S S。
- 规范化: 应用 RELU 激活函数确保相似性分数 S S S 介于 0 和 1 之间, S = f r e l u ( f c s ( y e , p e ) ) S=f_{relu}(f_{cs}(y_e,p_e)) S=frelu(fcs(ye,pe)),其中 f r e l u f_{relu} frelu 和 f c s f_{cs} fcs 分别代表 RELU 激活函数和余弦相似度函数。
- SC 损失函数: L S C L_{SC} LSC 定义为相似性分数的负对数,并对报告中的所有句子求和 L S C = − ∑ i = 1 N r l o g ( S i ) L_{SC}=−∑_{i=1}^{N_r} log(S_i) LSC=−∑i=1Nrlog(Si)
- 相似性分数计算:
- **训练策略:**在训练阶段,框架结合了三种损失( L K M V E L_{KMVE} LKMVE、 L T F L_{TF} LTF 和 L S C L_{SC} LSC)。训练步骤如下:
- 模型首先计算 L K M V E L_{KMVE} LKMVE 和 L T F L_{TF} LTF 损失。
- 然后,网络被冻结(frozen)以稳定其参数,用于生成完整的预测报告。
- 最后,网络被解冻(unfrozen),以计算真实报告和预测报告之间的 L S C L_{SC} LSC。
4. 实验
4.1 数据集
为了评估框架的性能,研究人员收集了三个独立的超声数据集,分别针对不同的器官:
- 乳腺(Breast): 包含3521名患者。
- 甲状腺(Thyroid): 包含2474名患者。
- 肝脏(Liver): 包含1395名患者。
这些数据集都来自解放军总医院超声科的数据库。
数据预处理:
- 对超声报告进行了分词。
- 将文本中的数值(如病灶大小和位置)替换为特殊符号(如2DS、3DS、Loc、SCM、SMM),这是因为生成模型在数值预测的准确性上存在限制。
- 在每份报告的开头和结尾插入了
<start>和<end>标记。 - 每个数据集按7:1:2的比例划分为训练集、验证集和测试集,并确保数据不重叠。

4.2 实验设置
该研究评估预测报告质量采用了三种主要的指标:自然语言生成(NLG)指标、临床效用(CE)指标,以及预测报告与真实报告之间的蕴含关系(entailment)。
- **自然语言生成 (NLG) 指标:**用于综合评估生成报告与真实报告之间的相似性,包括:
- BLEU (Bilingual Evaluation Understudy): 衡量生成文本与真实文本之间的词汇重叠度,包括BLEU-1、BLEU-2、BLEU-3和BLEU-4等不同n-gram级别的重叠度,从而捕捉不同程度的语言相似性。
- ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence): 基于最长公共子序列算法的指标。它考虑句子级别结构的相似性,并识别序列中最长共现的n-grams,有效捕捉生成报告和参考报告之间的整体结构相似性。
- METEOR (Metric for Evaluation of Translation with Explicit Ordering): 通过同时考虑精确率和召回率以及语言特征(如词序和同义词)来评估生成文本的质量。
- **临床效用 (CE) 指标:**旨在关注报告中的关键信息,而不是文本相似性。研究者根据超声医师的建议,为每份报告提取了关键实体(key entities)。
- 评估方法: 任务被转化为多标签分类问题。如果报告中提到了感兴趣的实体 ∗ i ∗ *i* ∗i∗,则标记为1 ( y i = 1 y_i = 1 yi=1);否则标记为0 ( y i = 0 y_i = 0 yi=0)。
- 计算指标: 最终计算准确率(accuracy)、精确率(precision)、召回率(recall)和F1分数。
- **蕴含关系 (Natural Language Inference, NLI):**使用了自然语言推理(NLI)模型来判断预测报告在逻辑上是否符合真实报告。
- 重要性: 在医学领域,准确描述每种病理至关重要,例如,“高回声”和“低回声”都属于“回声”,但它们的解释是截然相反的。
- 实施方法: 研究聚合了每个实体的句子,并使用基于BERT的DeBERTa模型来比较这些聚合的句子与相关的聚合真实报告句子。
该模型的实现细节如下:
- **硬件和框架:**该模型使用PyTorch框架实现,并在两块NVIDIA GeForce RTX 3090 GPU6上进行训练。
- 模块优化(KD模块):为优化知识蒸馏器(KD)模块,分别在三个不同的数据集(乳腺、甲状腺和肝脏)上进行了实验,以确定嵌入方法、降维和聚类数量的最佳选择。这些优化结果作为框架的先验知识。KD的优化过程包括两个步骤:
- 使用轮廓系数和elbow法则确定不同嵌入方法(词袋法、TF-IDF和S-Bert)的聚类数量的大致范围。
- 通过选择轮廓系数最高的结果来确定最终聚类结果,使用四个常见的降维维度(2、5、10和50)评估性能,并从初始粗略范围7中均匀采样四个聚类数。
- 报告生成器(RG模型)配置:
- Transformer编码器(TE)和Transformer解码器(TD)的层数均设置为3。
- 多头注意力(MHA)的特征维度设置为512,使用8个头。
- 句子生成的最大句子长度设置为150。
- 训练参数:
- 整个网络的最大训练轮数设置为 50。
- 当验证损失在10个训练周期内没有下降时,训练停止(提前停止)。
- 训练过程中的批次大小设置为128。
- 优化器和学习率:
- 使用了ADAM优化器。
- 知识匹配视觉提取器(KMVE)的学习率设置为5e-4。
- 报告生成器(RG)的学习率设置为1e-4。
- 在训练期间,学习率在每个epoch之后衰减0.8倍。
- **平衡权重(损失函数):**平衡权重 λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2 和 λ 3 \lambda_3 λ3 分别设置为 0.4、0.6 和 0.4。这些权重是通过对肝脏数据集中随机选取的10%样本进行参数搜索确定的。
- λ 1 \lambda_1 λ1对应于KMVE损失( L K M V E L_{KMVE} LKMVE)
- λ 2 \lambda_2 λ2 对应于基本的Transformer损失 ( L T F L_{TF} LTF)
- λ 3 \lambda_3 λ3对应于相似度比较器损失( L S C L_{SC} LSC)
- 将 L T F L_{TF} LTF( λ 2 = 0.6 \lambda_2=0.6 λ2=0.6)的权重设置得相对大于 L K M V E L_{KMVE} LKMVE和 L S C L_{SC} LSC,以维持框架的有效性,因为模型需要先学习逐词生成,再专注于相似度和知识匹配。
- λ 1 \lambda_1 λ1 和 λ 3 \lambda_3 λ3 被设置为相等( λ 1 = λ 3 = 0.4 \lambda_1 = \lambda_3 = 0.4 λ1=λ3=0.4),因为这两个损失被认为对报告生成的贡献相等。
- 总损失的计算公式为: L s u m = λ 1 L K M V E + λ 2 L T F + λ 3 L S C L_{sum} = \lambda_1 L_{KMVE} + \lambda_2 L_{TF} + \lambda_3 L_{SC} Lsum=λ1LKMVE+λ2LTF+λ3LSC。
4.3 知识蒸馏器实验
根据表三,S-Bert 在乳腺数据集上表现最佳,而传统 BOW 模型在甲状腺和肝脏数据集上效果显著。这可能是因数据集大小和文本特征不同,乳腺数据集大且文本复杂,简单 BOW 模型处理欠佳;甲状腺和肝脏数据集小且文本多样性低,BOW 模型更优,也表明文本多样性有限时,S-Bert 预训练嵌入优势不明显


4.4 不同聚类方法的实验
选K - Means算法做知识聚类,因其计算复杂度低且在数据集上性能佳。通过与其他聚类方法对比,在甲状腺数据集上K - Means轮廓系数更高(0.75),处理超2000个数据点时耗时更低。基于聚类结果对最终报告生成的影响评估,K - Means的BLEU分数最高,相比用HDBSCAN的先前工作,它更适合中文超声数据集。虽有些方法在METEOR和ROUGE - L指标上有优势,但K - Means因计算量低更适合大数据集,且所有方法都超无无监督聚类引导的基线“TF+SC”,说明无监督引导能提升无数据标签场景下的报告生成效果。


4.5 定量结果
为证明方法有效性,将其与CNN - RNN、TriNet、R2Gen、TF、R2GenRL、DeltaNet六种方法对比。
- 在乳腺数据集,该方法多数指标更优,BLEU - 1至BLEU - 4较DeltaNet分别提升6.3%、6.8%、5.33%、5.26%;
- 甲状腺数据集表现更优,较R2GenRL准确率提高20.74%;
- 肝脏数据集召回率和F1分数最高。
所有数据集召回率均较高,图7显示多数预测实体与原报告相符,如“回声”的蕴含数为359,高于DeltaNet的327。


4.6 消融实验
在本节中,我们进行消融实验验证各模块有效性,结果见表格 VI。实验配置包括仅用 Transformer 模型(TF)、加 KMVE 损失(TF+KMVE)、加 SC 损失(TF+SC),我们的方法结合两者。结果显示:
- 训练中加入 KMVE 损失,乳腺数据集 BLEU - 1 提升 4.5%,甲状腺数据集 BLEU - 4 提升 2.6%,肝脏数据集 BLEU - 2 提升 0.3%,表明 KMVE 模块有助于生成更准确报告。
- 加入 SC 损失,多数指标也有提升,但肝脏数据集提升较小,可能因其规模小且基础方法 BLEU - 4 已达 0.80,改进空间小。
总之,实验验证了框架有效性,KMVE 模块提升文本生成质量,SC 模块通过评估语义一致性进一步提升性能。

4.7 可视化结果

上图展示乳腺数据集超声报告生成结果,加粗下划线句子与真实报告语义相同,结果表明该方法生成关键细节能力强,能平衡正常与异常描述,接近真实报告。

上图展示甲状腺和肝脏数据集结果,该方法在甲状腺数据集能捕捉异常结节,与 R2Gen 在肝脏数据集结果差异小。但该方法在确定病变数量和精确位置方面存在挑战,这是超声报告生成领域的常见问题。

上图展示模型词级注意力图,关键术语受关注多,抽象术语受关注少
5. 结论
在我们的工作中,我们提出了一个新颖的报告生成框架,该框架结合了无监督学习和有监督学习方法,以对齐视觉和文本特征。具体来说,我们利用无监督学习从文本报告中提取潜在的医学知识,而无需额外的疾病标签,从而减轻了医学报告生成过程中视觉和文本之间的差距。此外,我们的框架通过采用相似性比较机制生成准确且较长的报告,该机制结合了全局语义信息以生成复杂的句子。最后,我们收集了三个大型的超声图像文本数据集,分别涵盖了乳房、甲状腺和肝脏,这是首次在多器官超声报告数据集上进行评估和测试的工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)