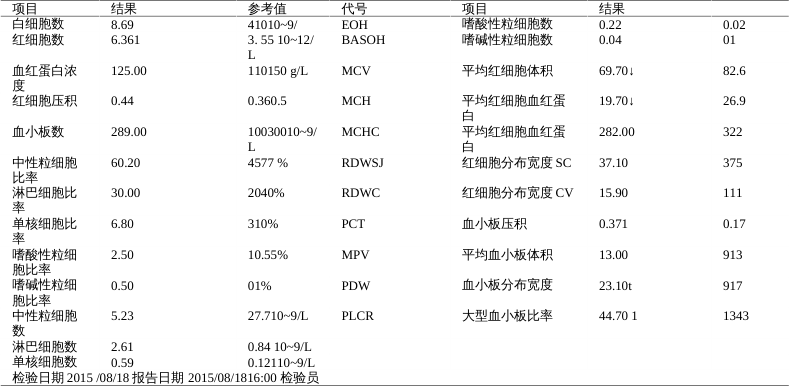
PaddleOCR系列--《表格单元格检测模块》数据集制作
一、概述
表格单元格检测模块是表格识别任务的关键组成部分,负责在表格图像中定位和标记每个单元格区域,该模块的性能直接影响到整个表格识别过程的准确性和效率。表格单元格检测模块通常会输出各个单元格区域的边界框(Bounding Boxes),这些边界框将作为输入传递给表格识别相关产线进行后续处理。
注意:“单元格检测模型”返回的是表格中每个单元格坐标框(包括合并的),与后面的“表格结构识别模型”息息相关,当然也可以自己写算法,自己排列这些坐标框组成完整表格(官方“表格结构识别模型”实在有些一言难尽)
二、支持模型列表
支持“有线表格单元格”检测和“无线表格单元格”检测,两者识别依靠的是“表格分类模块”,会将输入表格分为“有线表格”或“无线表格”,然后调用不同的“单元格检测模型”
有线表格:RT-DETR-L_wired_table_cell_det
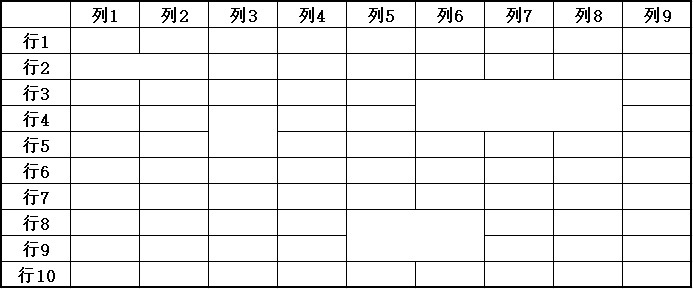
无线表格:RT-DETR-L_wireless_table_cell_det
三、PaddleX环境安装
官方链接:安装PaddlePaddle - PaddleX 文档
参考链接:PaddleX本地安装教程_安装paddlex-CSDN博客
四、数据准备
官方demo数据集:https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cells_det_coco_examples.tar
五、标注工具Labelme
5.1 Labelme标注工具介绍
Labelme 是一个 python 语言编写,带有图形界面的图像标注软件。可用于图像分类,目标检测,图像分割等任务,在目标检测的标注任务中,标签存储为 JSON 文件。
5.2 Labelme 安装
为避免环境冲突,建议在 conda 环境下安装,可以参考:Miniconda安装与使用-CSDN博客
conda create -n labelme python=3.10
conda activate labelme
pip install pyqt5
pip install labelme5.3 Labelme 标注过程
5.3.1 准备待标注数据
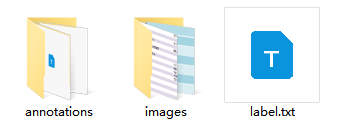
- 创建数据集根目录,如
data。 - 在 data 中创建
images目录(必须为images目录),并将待标注图片存储在images目录下,如下图所示: 
- 在
data文件夹中创建待标注数据集的类别标签文件label.txt,并在label.txt中按行写入待标注数据集的类别。如下图所示: 
5.3.2 启动 Labelme
终端进入到待标注数据集根目录,并启动 Labelme 标注工具:
cd path/to/data
labelme images --labels label.txt --nodata --autosave --output annotations* flags 为图像创建分类标签,传入标签路径。
* nodata 停止将图像数据存储到 JSON文件。
* autosave 自动存储。
* output 标签文件存储路径。
5.3.3 开始图片标注
- 启动
Labelme后如图所示: 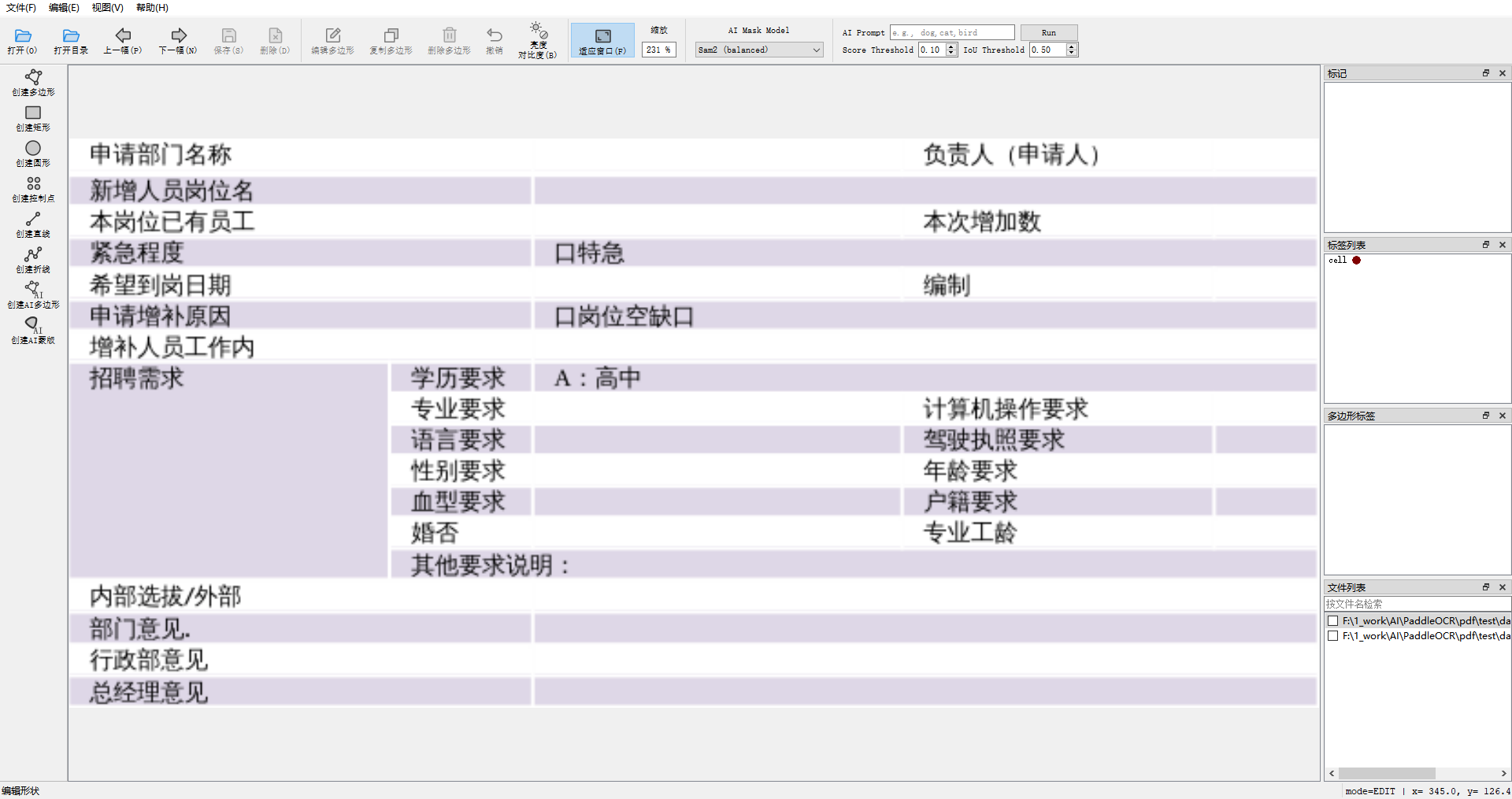
- * 点击"编辑"选择标注类型,选择“创建矩形框”,右键点击再选择也可以
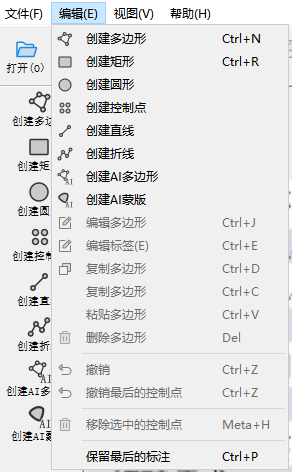
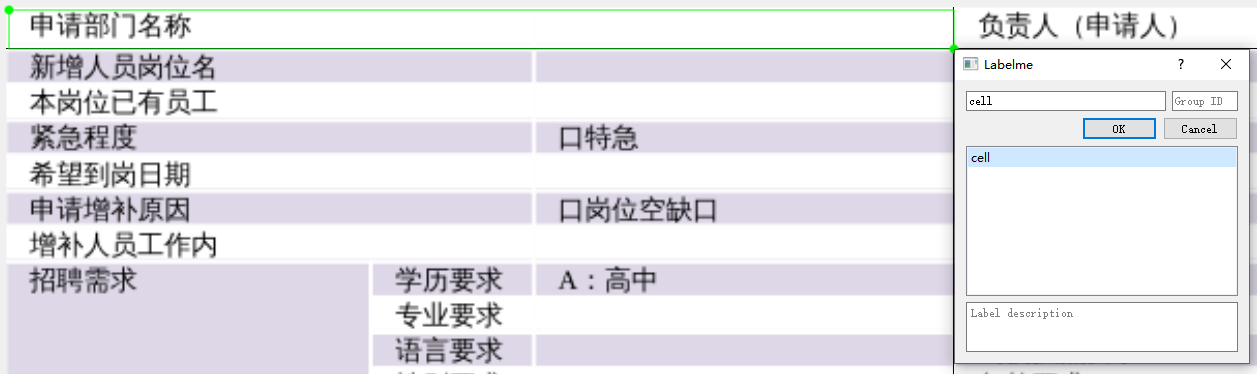
- 在图片上拖动十字框选目标区域,再次点击选择目标框类别
- 标注好后点击存储。(若在启动
Labelme时未指定output字段,会在第一次存储时提示选择存储路径,若指定autosave字段使用自动保存,则无需点击存储按钮)。 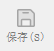
- 然后点击
Next Image进行下一张图片的标注。 
- 最终标注好的标签文件如图所示:
- annotations文件夹内
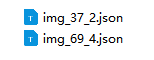
-
*调整目录得到标准Labelme格式数据集,在数据集根目录创建train_anno_list.txt和val_anno_list.txt两个文本文件,并将annotations目录下的全部json文件路径按一定比例分别写入train_anno_list.txt和val_anno_list.txt,也可全部写入到train_anno_list.txt同时创建一个空的val_anno_list.txt文件,使用数据划分功能进行重新划分。
-
数据分割代码:
-
import os import random def split_annotations(annotations_dir, train_txt, val_txt, split_ratio=4): """ 将annotations目录下的JSON文件按照指定比例随机分配到训练集和验证集 Args: annotations_dir (str): 标注文件目录 train_txt (str): 训练集txt文件路径 val_txt (str): 验证集txt文件路径 split_ratio (int): 训练集与验证集的比例,默认为4:1 """ # 获取annotations目录下所有JSON文件 json_files = [] for file in os.listdir(annotations_dir): if file.endswith(".json"): json_files.append(file) # 随机打乱文件列表 random.shuffle(json_files) # 计算分割点 total_files = len(json_files) train_size = int(total_files * split_ratio / (split_ratio + 1)) # 分割文件列表 train_files = json_files[:train_size] val_files = json_files[train_size:] # 构建文件路径(格式:annotations/xxx.json) train_paths = [f"annotations/{file}" for file in train_files] val_paths = [f"annotations/{file}" for file in val_files] # 写入训练集txt文件 with open(train_txt, "w", encoding="utf-8") as f: for path in train_paths: f.write(path + "\n") # 写入验证集txt文件 with open(val_txt, "w", encoding="utf-8") as f: for path in val_paths: f.write(path + "\n") print(f"分割完成!") print(f"训练集文件数: {len(train_files)}") print(f"验证集文件数: {len(val_files)}") print(f"训练集已写入: {train_txt}") print(f"验证集已写入: {val_txt}") if __name__ == "__main__": # 配置路径 annotations_dir = r"E:\xxx\annotations" train_txt = ( r"E:\xxx\train_anno_list.txt" ) val_txt = r"E:\xxx\val_anno_list.txt" # 执行分割 split_annotations(annotations_dir, train_txt, val_txt) -
train_anno_list.txt和val_anno_list.txt的具体填写格式如图所示: -

-
经过整理得到的最终目录结构如下:
-
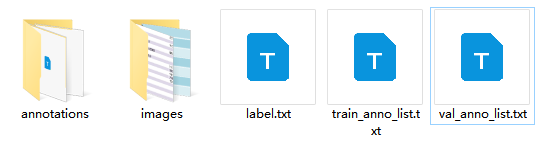
5.3.4 格式转换
使用Labelme标注完成后,需要将数据格式 转换为coco格式。下面给出了按照上述教程使用Lableme标注完成的数据和进行数据格式转换的代码示例:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_labelme_examples.tar -P ./dataset
tar -xf ./dataset/det_labelme_examples.tar -C ./dataset/
python main.py -c paddlex/configs/object_detection/PicoDet-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe转换完会在annotations文件夹下生成instance_train.json和instance_val.json文件
六、数据集快速标注
但是!!!一张表格图片可能有上百个单元格,一个个标简直要疯。所以我选择偷懒。。。
- 先用官方模型推理图片,得到json结果
import os
import json
from tqdm import tqdm
from pathlib import Path
from paddlex import create_model
model = create_model(
model_name="RT-DETR-L_wired_table_cell_det",
# model_dir="/best_model/inference"#你自己模型所在目录或直接不用这个参数
)
pib_path_name = "cell_data" #图片所在文件夹名
image_suffixes = {'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff', '.webp'}
base_img_path = f"/pic/{pib_path_name}" #图片所在文件夹路径
out_base_path = f"/out/TableCellsDetection_X_PIC/{pib_path_name}"#结果输出路径
img_path = []
for item in os.listdir(base_img_path):
if os.path.splitext(item)[1] in image_suffixes:
img_path.append(f"{base_img_path}/{item}")
json_list = [] # 用于收集每个页面的JSON数据
for item in tqdm(img_path):
output = model.predict(
item,
threshold=0.4, #置信度
batch_size=1 #一次加载几张,值越大,消耗越高
)
json_data = {}
for idx, res in enumerate(output):
json_data = res.json["res"]
json_list.append(json_data)
merged_json_path = f"{out_base_path}/cell_all_data.json"
with open(merged_json_path, "w", encoding="utf-8") as f:
# 合并逻辑:将每个页面的JSON数据放在一个列表中,方便查看
json.dump(
{"data": json_list},
f,
ensure_ascii=False, # 支持中文显示
indent=2 # 格式化输出,便于阅读
)
- 然后用脚本转成Labelme所用数据格式,再用Labelme打开修改调整,重复
5.3 Labelme 标注过程

import json
import os
from PIL import Image # 导入PIL库用于读取图片实际尺寸
def convert_to_labelme_json(input_json_path, output_dir, img_root_dir=""):
"""
将给定的单元格标注JSON转换为labelme格式的JSON文件
:param input_json_path: 输入标注JSON文件路径
:param output_dir: 输出labelme格式JSON文件的目录
:param img_root_dir: 图片文件根目录(用于读取真实尺寸)
"""
# 1. 读取并解析输入JSON文件
try:
with open(input_json_path, "r", encoding="utf-8") as f:
input_data = json.load(f)
# 提取核心data列表,做容错处理
data_list = input_data.get("data", [])
if not isinstance(data_list, list):
raise ValueError("输入JSON的data字段不是有效列表")
except FileNotFoundError:
raise FileNotFoundError(f"输入JSON文件不存在:{input_json_path}")
except json.JSONDecodeError as e:
raise ValueError(f"JSON解析失败,格式错误:{e}")
except Exception as e:
raise Exception(f"读取输入文件异常:{e}")
# 2. 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 3. 处理每条数据,生成对应的labelme格式JSON文件
processed_count = 0
for data_item in data_list:
# 3.1 提取并处理文件名(从完整input_path中提取文件名)
input_path = data_item.get("input_path", "")
if not input_path:
continue
# 提取文件名(如AAA.png、BBB.png)
filename = os.path.basename(input_path)
# 生成输出JSON文件名(将.png或.jpg替换为.json)
base_name = os.path.splitext(filename)[0]
output_json_filename = f"{base_name}.json"
output_json_path = os.path.join(output_dir, output_json_filename)
# 3.2 提取boxes列表,做容错处理
boxes = data_item.get("boxes", [])
if not isinstance(boxes, list):
continue
# 3.3 构建labelme格式的shapes列表
shapes = []
for box in boxes:
# 提取坐标信息,做容错处理
coordinate = box.get("coordinate", [])
if len(coordinate) != 4:
continue # 跳过无效坐标(要求左、上、右、下四个值)
# 解析坐标:[x1, y1, x2, y2]
x1, y1, x2, y2 = coordinate
# 构建labelme格式的shape
shape = {
"label": "cell",
"points": [[float(x1), float(y1)], [float(x2), float(y2)]],
"group_id": None,
"description": "",
"shape_type": "rectangle",
"flags": {},
"mask": None,
}
shapes.append(shape)
if not shapes: # 无有效标注的图像跳过
print(f"警告:{filename}无有效单元格标注,已跳过")
continue
# 3.4 读取图片实际宽高
img_width = 300
img_height = 200
try:
# 拼接完整图片路径
if img_root_dir:
img_full_path = os.path.join(img_root_dir, filename)
else:
img_full_path = input_path # 若未指定根目录,使用原始文件路径
# 打开图片并获取真实尺寸
with Image.open(img_full_path) as img:
img_width, img_height = img.size
print(f"成功读取{filename}真实尺寸:{img_width}×{img_height}")
except FileNotFoundError:
print(f"警告:图片文件不存在({img_full_path}),将使用默认尺寸")
except Exception as e:
print(f"警告:读取图片尺寸失败({e}),将使用默认尺寸")
# 3.5 构建labelme格式JSON数据
labelme_data = {
"version": "5.10.1",
"flags": {},
"shapes": shapes,
"imagePath": f"../images/{filename}", # 相对路径,可根据实际情况调整
"imageData": None,
"imageHeight": img_height,
"imageWidth": img_width,
}
# 3.6 将结果写入输出JSON文件
try:
with open(output_json_path, "w", encoding="utf-8") as f:
json.dump(labelme_data, f, ensure_ascii=False, indent=2)
print(f"已生成:{output_json_path}")
processed_count += 1
except Exception as e:
print(f"警告:写入{output_json_filename}失败:{e},已跳过")
continue
print(f"\n转换完成!共处理{processed_count}张图像")
# 示例使用(可直接运行,修改输入输出路径即可)
if __name__ == "__main__":
# 配置输入JSON路径、输出目录annotations
INPUT_JSON_PATH = r"E:\data\cell_all_data.json"
OUTPUT_DIR = r"E:\data\annotations"
# 关键配置:图片文件根目录(你的图片存放的文件夹)
# 示例:如果图片存放在 gt_to_coco/images 下,填写该路径
IMG_ROOT_DIR = r"F:\data\images" # 请修改为你的实际图片根目录
# 执行转换
convert_to_labelme_json(INPUT_JSON_PATH, OUTPUT_DIR, img_root_dir=IMG_ROOT_DIR)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)