什么是少样本学习?为什么给几个例子就能让AI学会新任务?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
什么是少样本学习?为什么给几个例子就能让AI学会新任务?
by @Laizhuocheng
一、简介
少样本学习(Few-shot Learning)是一种通过提供少量示例(通常3-10个),就能让AI模型快速理解和执行新任务的学习范式。在大语言模型中,这意味着我们可以通过在Prompt中包含几个输入-输出对的例子,引导AI学会处理同类的新问题。
说人话就是: 想象你教一个聪明的孩子学习新技能,你不需要给他成千上万的练习题,只需要展示几个"题目-答案"的例子,他就能举一反三,解决类似的新问题。这就是少样本学习的魅力——用最少的示例,获得最大的学习效果。
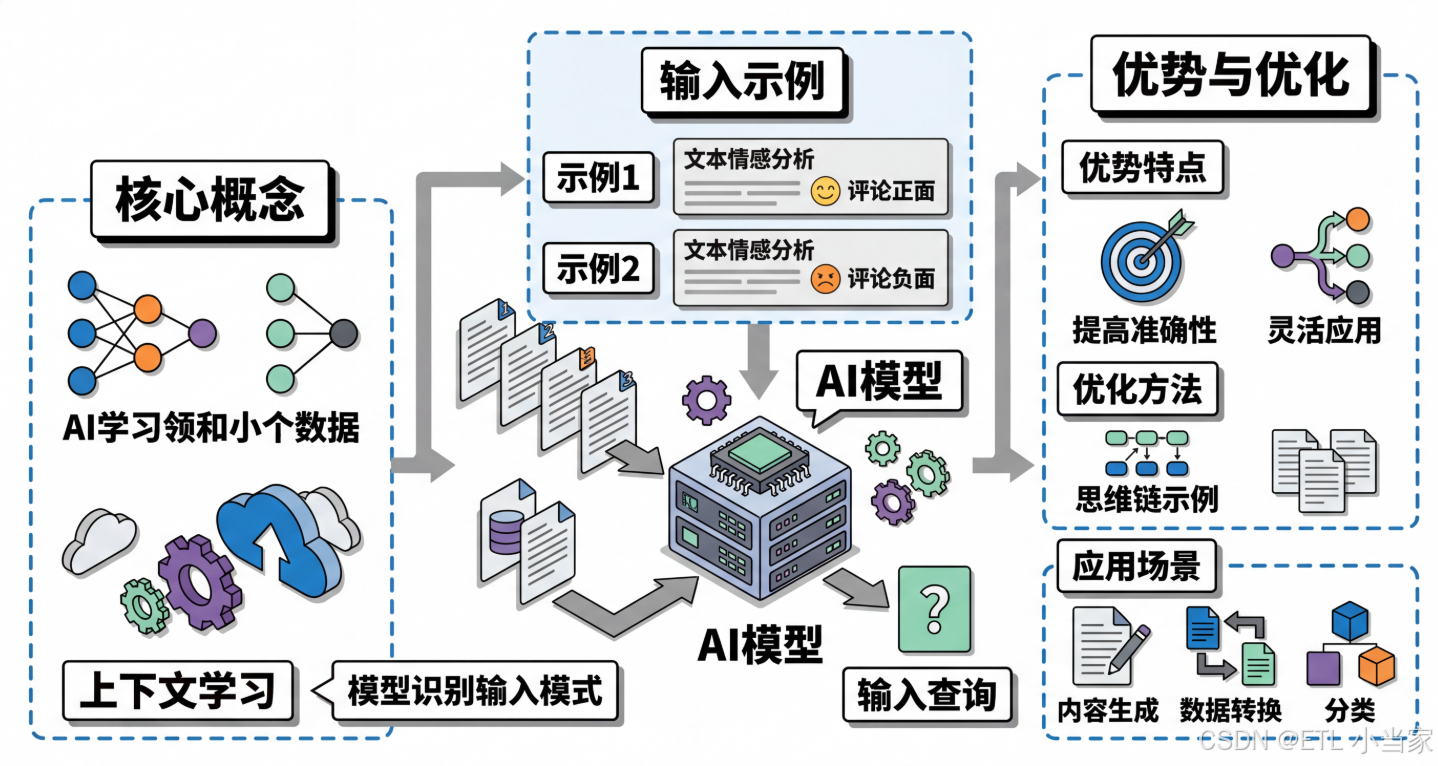
二、为什么需要少样本学习?
虽然零样本学习很强大,但在面对复杂或模糊的任务时,仅靠自然语言描述往往不够精确。少样本学习填补了这个空白:
少样本学习的优势
- 降低歧义性:示例比文字描述更直观
- 提高准确性:明确展示期望的输出格式和风格
- 处理复杂任务:对于难以用语言精确描述的任务特别有效
- 保持灵活性:无需重新训练模型,只需改变示例
零样本 vs 少样本对比
| 场景 | 零样本效果 | 少样本效果 |
|---|---|---|
| 简单任务(翻译、分类) | ✅ 很好 | ✅ 很好 |
| 复杂格式(特定JSON结构) | ❌ 可能出错 | ✅ 准确 |
| 模糊任务(创意写作) | ⚠️ 结果不稳定 | ✅ 风格一致 |
| 专业领域(法律文书) | ❌ 可能不专业 | ✅ 符合规范 |
少样本学习的核心价值在于在通用性和专业性之间找到平衡点。
三、少样本学习的工作原理
上下文学习(In-context Learning)
大语言模型具有上下文学习能力,这意味着它们能够:
- 从提供的示例中识别模式
- 理解输入和输出之间的映射关系
- 将学到的模式应用到新的输入上
这种能力源于模型在预训练阶段接触过大量"问题-答案"、"指令-响应"的配对数据。
示例设计的最佳实践
1. 示例数量
- 最小有效数量:通常3-5个示例就足够
- 收益递减:超过10个示例后,性能提升有限
- 上下文长度限制:要考虑模型的最大token限制
2. 示例质量
- 多样性:覆盖不同的情况和边界条件
- 一致性:保持相同的格式和风格
- 代表性:反映真实使用场景
3. 示例顺序
- 从简单到复杂:帮助模型逐步理解
- 相关性优先:将最相关的示例放在前面

实际示例演示
文本情感分析:
请分析以下评论的情感倾向:
评论:"服务太差了,等了半个小时都没人理我。"
情感:负面
评论:"食物很美味,服务员也很热情。"
情感:正面
评论:"价格有点贵,但味道还可以。"
情感:中性
评论:"这次体验真的很糟糕,不会再来了。"
情感:
代码生成:
将以下自然语言描述转换为Python函数:
描述:"计算两个数的和"
代码:def add(a, b):
return a + b
描述:"检查一个数是否为偶数"
代码:def is_even(n):
return n % 2 == 0
描述:"计算列表中所有元素的平均值"
代码:
四、实际应用场景
1. 数据格式转换
- JSON ↔ XML ↔ CSV 转换
- 不同API格式之间的适配
- 日志格式标准化
2. 内容生成
- 广告文案生成(基于品牌调性示例)
- 邮件模板个性化
- 社交媒体内容创作
3. 信息提取
- 从非结构化文本中提取结构化信息
- 发票信息识别
- 简历关键信息抽取
4. 文本分类
- 自定义分类标签
- 多级分类体系
- 情感细粒度分析
5. 代码辅助
- 编程语言转换
- 代码片段生成
- 错误修复建议
五、少样本学习的优化技巧
1. 思维链(Chain-of-Thought)示例
在示例中展示思考过程,而不仅仅是最终答案:
问题:小明有5个苹果,小红给了他3个,他又吃了2个,现在有几个苹果?
思考:开始有5个,加3个得到8个,减2个得到6个。
答案:6
问题:一个披萨被切成8片,小华吃了3片,小李吃了2片,还剩几片?
思考:
2. 角色扮演示例
在示例中体现特定角色的专业性:
你是一位专业的营养师,请为以下食材组合提供健康建议:
食材:鸡胸肉、西兰花、糙米
建议:这是一个优质的高蛋白低碳水组合,适合健身人群...
食材:三文鱼、菠菜、藜麦
建议:
3. 多样化示例设计
确保示例覆盖各种边界情况:
- 正常情况
- 异常情况
- 边界值
- 特殊格式
4. 渐进式复杂度
从简单示例开始,逐步增加复杂度:
示例1(简单):提取姓名
输入:"张三,电话138****1234"
输出:"张三"
示例2(中等):提取姓名和电话
输入:"张三,电话138****1234"
输出:{"name": "张三", "phone": "138****1234"}
示例3(复杂):提取完整联系信息
输入:"张三,电话138****1234,邮箱zhangsan@email.com"
输出:
六、少样本学习的局限性
1. 上下文长度限制
- 模型有最大token限制
- 大量示例会占用宝贵的上下文空间
- 可能影响对新输入的理解
2. 示例质量依赖
- 低质量示例会导致错误学习
- 不一致的示例会造成混淆
- 偏向性示例会产生偏见结果
3. 泛化能力有限
- 对于与示例差异很大的新输入,效果可能不佳
- 难以处理完全未知的概念
- 可能过度拟合示例模式
4. 成本考虑
- 更长的Prompt意味着更高的计算成本
- 需要在效果和成本之间权衡
七、少样本 vs 其他学习范式
| 方法 | 示例数量 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|---|
| 零样本 | 0 | 简单、标准任务 | 最灵活、成本最低 | 复杂任务效果有限 |
| 少样本 | 3-10 | 中等复杂度任务 | 平衡灵活性和准确性 | 需要设计好的示例 |
| 监督微调 | 100+ | 高精度生产环境 | 性能最佳、最稳定 | 需要大量标注数据 |
| 指令微调 | 1000+ | 通用指令跟随 | 提升零样本能力 | 训练成本高 |
少样本学习最适合需要快速部署且对准确性有一定要求的场景,是连接零样本和全监督学习的重要桥梁。
结语
少样本学习展现了大语言模型令人惊叹的模式识别和泛化能力。它让我们能够以极低的成本,快速地将通用AI模型适配到特定任务上。
然而,少样本学习的成功很大程度上取决于示例设计的艺术。好的示例就像精心设计的教学材料,能够引导AI快速掌握任务的本质;而随意的示例则可能导致AI学到错误的模式。
掌握少样本学习的关键在于理解:示例不仅是数据,更是教学策略。我们需要像优秀的教师一样,选择最具代表性的例子,以最清晰的方式展示任务的核心模式,这样才能真正发挥少样本学习的威力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 25
25 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)