《深度学习入门:基于 Python 的理论与实现》
·
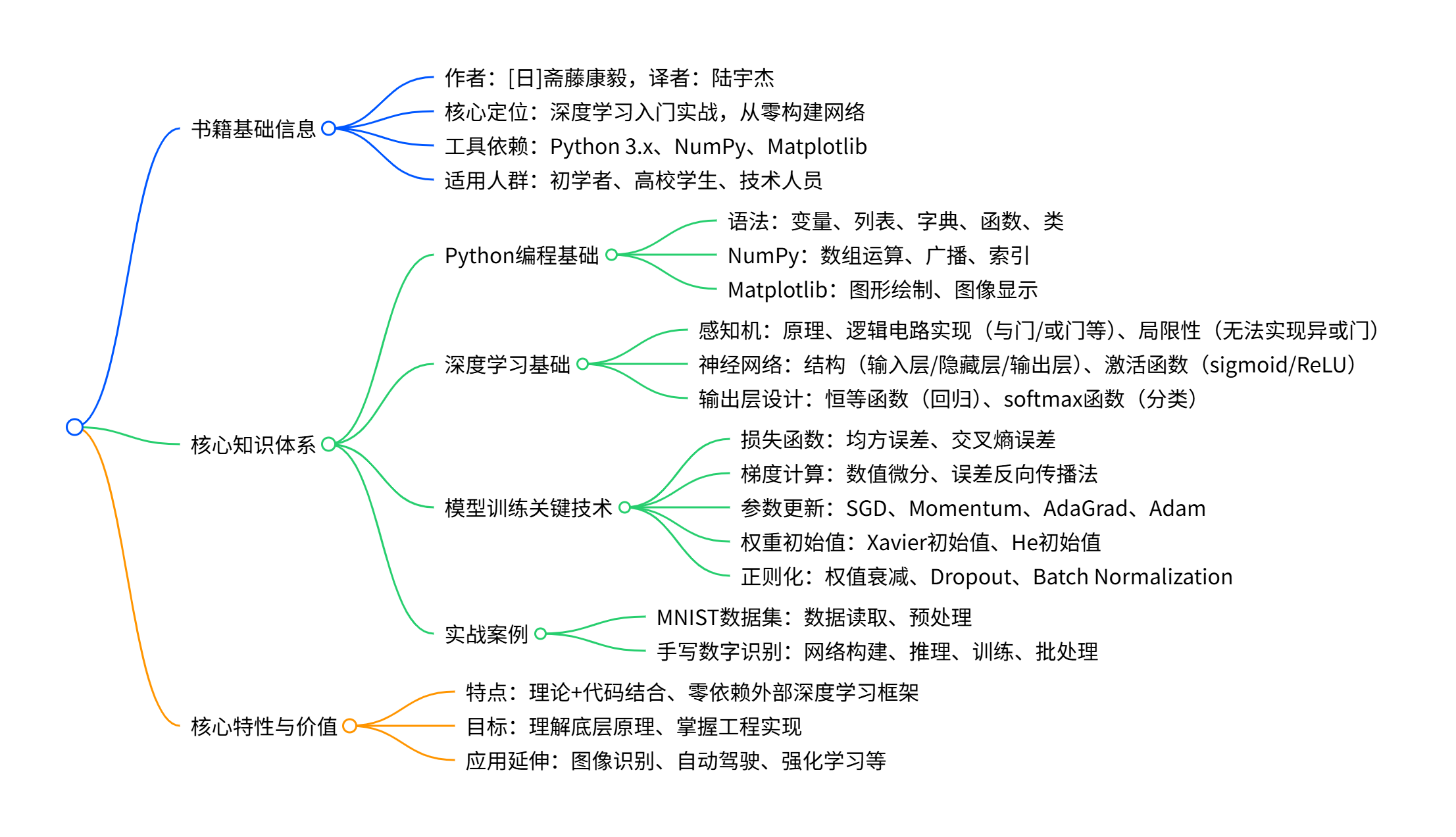
《深度学习入门:基于 Python 的理论与实现》是一本面向深度学习初学者的实战型书籍,以Python 3.x为工具,尽量不依赖外部库(仅使用 NumPy 和 Matplotlib),从零构建经典深度学习网络,核心内容涵盖 Python 编程基础、感知机原理与局限、神经网络结构与激活函数(sigmoid、ReLU 等)、误差反向传播法、参数更新策略(SGD、Momentum 等)、权重初始值选择、正则化(权值衰减、Dropout)等关键技术,同时结合 MNIST 手写数字识别案例,详细讲解模型推理与训练过程,兼具理论深度与工程实践价值,可作为入门教材或自学参考。
3. 详细总结
一、书籍基础信息
| 项目 | 详情 |
|---|---|
| 书名 | 《深度学习入门:基于 Python 的理论与实现》(Deep Learning from Scratch) |
| 作者 / 译者 | 作者:斋藤康毅(日本东京工业大学毕业,机器学习领域研究者);译者:陆宇杰(众安科技 NLP 算法工程师) |
| 出版信息 | 2018 年 7 月第 1 版,人民邮电出版社,ISBN 978-7-115-48558-8,定价 59.00 元 |
| 核心定位 | 从零构建深度学习网络,兼顾理论解析与 Python 实现,适合零基础入门 |
| 工具依赖 | 编程语言:Python 3.x;外部库:NumPy(数值计算)、Matplotlib(可视化) |
二、核心知识模块
(一)Python 编程基础(第 1 章)
- Python 核心语法:算术计算、数据类型(int/float/str/bool)、变量、列表(切片操作)、字典、条件语句(if)、循环语句(for)、函数与类的定义及使用。
- NumPy 关键操作:
- 数组生成(np.array ())、形状查看(shape)、数据类型(dtype)
- 算术运算(元素级运算、广播机制)
- 索引与切片(多维数组访问、布尔索引)
- Matplotlib 应用:绘制函数图形(plt.plot ())、显示图像(plt.imshow ()),用于实验结果可视化。
(二)深度学习基础理论
-
感知机(第 2 章)
- 原理:接收多个输入信号,通过权重加权求和,超过阈值输出 1,否则输出 0(公式:y={01(w1x1+w2x2≤θ)(w1x1+w2x2>θ))。
- 逻辑电路实现:通过调整权重(w)和阈值(θ),可实现与门、或门、与非门(如与门:w1=0.5,w2=0.5,θ=0.7)。
- 局限性:仅能表示线性空间,无法实现异或门(需多层感知机解决)。
- 多层感知机:通过叠加层(输入层→隐藏层→输出层)实现异或门,证明多层结构可表示非线性空间。
-
神经网络(第 3 章)
- 结构:输入层(如 MNIST 为 784 维)、隐藏层、输出层(分类问题为类别数,如 10 类)。
- 激活函数:
- 阶跃函数:感知机使用,信号急剧切换,导数多为 0,不适合深度学习。
- sigmoid 函数:h(x)=1+exp(−x)1,平滑连续,输出在 0-1 之间。
- ReLU 函数:h(x)={x0(x>0)(x≤0),解决梯度消失问题,应用广泛。
- 输出层设计:
- 回归问题:恒等函数(直接输出加权和)。
- 分类问题:softmax 函数(将输出正规化,输出为概率分布,总和为 1)。
- 实战:MNIST 手写数字识别,输入层 784 维,隐藏层设 50/100 个神经元,输出层 10 维,识别精度达 93.52%(基础模型)。
(三)模型训练关键技术
-
损失函数(第 4 章):衡量模型输出与真实标签的差异,指导参数更新。
- 均方误差:E=21∑k(yk−tk)2,适用于回归问题。
- 交叉熵误差:E=−∑ktklogyk,适用于分类问题,对正确标签的输出敏感。
- mini-batch 学习:从训练数据中随机抽取部分数据(如 100 个)计算损失,提高训练效率。
-
梯度计算与参数更新(第 4-5 章)
- 数值微分:通过微小差分近似计算梯度(h=1e−4),实现简单但速度慢。
- 误差反向传播法:基于计算图和链式法则,高效计算梯度,支持多层网络快速训练。
- 参数更新策略:
表格
方法 核心思想 特点 SGD 沿梯度方向更新参数(W←W−η∂W∂L) 简单但易陷入局部最优,非均向函数效率低 Momentum 模拟动量,积累梯度方向速度 减轻 “之” 字形波动,加速收敛 AdaGrad 自适应学习率,对频繁更新参数减小学习率 适合稀疏数据,后期学习率趋近 0 Adam 融合 Momentum 和 AdaGrad,偏置校正 综合性能优,应用广泛
-
权重初始值与正则化(第 6 章)
- 权重初始值:
- 禁忌:不可设为 0(导致权重对称更新)。
- 推荐:sigmoid/tanh 用 Xavier 初始值(σ=n1);ReLU 用 He 初始值(σ=n2)。
- 正则化(抑制过拟合):
- 权值衰减:损失函数添加权重 L2 范数(21λW2),惩罚大权重。
- Dropout:训练时随机删除部分神经元(如删除比例 0.15),测试时乘删除比例。
- Batch Normalization:对 mini-batch 数据正规化(均值 0、方差 1),加速学习,降低初始值敏感度。
- 权重初始值:
(四)实战案例:MNIST 手写数字识别
- 数据预处理:加载 MNIST 数据集(训练集 60000 张,测试集 10000 张),归一化(像素值 0-1)、展平(28×28→784 维)。
- 网络结构:2 层神经网络(输入层 784→隐藏层 50→输出层 10),激活函数用 sigmoid/ReLU,输出层用 softmax。
- 训练流程:
- 步骤:mini-batch 抽取→计算梯度(误差反向传播法)→参数更新→重复迭代(如 10000 次)。
- 批处理:每次处理 100 张数据,提高运算效率。
- 性能评估:训练集与测试集识别精度同步提升,无明显过拟合(使用权值衰减 / Dropout 后效果更优)。
三、书籍核心价值
- 理论与实践结合:每个知识点配套 Python 代码,从零实现网络,不依赖 TensorFlow 等框架,深入理解底层原理。
- 循序渐进:从 Python 基础到神经网络训练,层层递进,适合零基础入门。
- 实用导向:涵盖深度学习核心技巧(梯度计算、正则化、超参数调优),可直接应用于实际项目。
4. 关键问题
问题 1:感知机与神经网络的核心区别是什么?为何感知机无法实现异或门而神经网络可以?
答案:核心区别在于激活函数和网络结构。感知机使用阶跃函数(信号急剧切换,仅能表示线性空间),且多为单层结构;神经网络使用 sigmoid/ReLU 等平滑非线性激活函数,支持多层叠加(输入层→隐藏层→输出层)。感知机无法实现异或门的原因是异或门对应的决策边界为非线性空间(需曲线分割),而单层感知机仅能表示线性分割;神经网络通过多层叠加(如 2 层感知机:与非门 + 或门→与门),可拟合非线性空间,从而实现异或门。
问题 2:深度学习中常用的损失函数有哪些?各自适用场景是什么?mini-batch 学习的意义是什么?
答案:常用损失函数及适用场景如下:
- 均方误差:适用于回归问题,计算模型输出与真实标签的平方差均值,对误差敏感但梯度平滑。
- 交叉熵误差:适用于分类问题,通过对数运算放大正确标签输出与 1 的差距,梯度更新更高效,尤其适合 one-hot 标签。mini-batch 学习的意义:① 降低计算成本,避免一次性处理海量训练数据(如 MNIST 60000 张)导致的内存压力;② 引入随机性,减少过拟合风险,使模型泛化能力更强;③ 提高训练效率,通过批量计算加速梯度下降过程。
问题 3:为避免神经网络过拟合,有哪些常用的正则化方法?各自的原理是什么?
答案:常用正则化方法及原理如下:
- 权值衰减:在损失函数中添加权重的 L2 范数(21λW2),惩罚过大的权重参数,迫使模型选择简单的权重组合,减少过拟合。
- Dropout:训练时随机删除部分隐藏层神经元(如删除比例 0.15),使模型不依赖单个神经元的输出,模拟集成学习效果;测试时,所有神经元参与运算,但输出需乘训练时的删除比例,保证输出尺度一致。
- Batch Normalization:在每层激活函数前对 mini-batch 数据进行正规化(均值 0、方差 1),并通过可学习参数(γ、β)调整数据分布,减少内部协变量偏移,加速学习收敛,同时降低对初始值和超参数的敏感度,间接抑制过拟合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)