【TMI 2025】破解医学视觉基础模型的“高频盲区”——Frepa预训练框架解码
【TMI 2025破解医学视觉基础模型的“高频盲区”——Frepa预训练框架解码
近年来,随着掩码自编码器(MAE)和对比学习(CLIP)的兴起,视觉基础模型在自然图像领域取得了令人瞩目的成就。然而,当这些模型被直接迁移到医学图像分析时,往往遭遇水土不服。
发布在医学图像分析顶刊IEEE Transactions on Medical Imaging的一篇题为《Improving Representation of High-frequency Components for Medical Visual Foundation Models》的研究,精准定位了当前医学基础模型的缺陷——对低频全局信息的过度依赖,以及对高频细粒度特征的表征缺失。作者据此提出了一种名为 Frepa (Frequency-advanced Representation Autoencoder) 的全新预训练范式。
本文将结合论文原稿与开源代码,从底层数学直觉与工程实现的双重视角,为您深度硬核拆解这项工作。本论文代码开源:https://github.com/Arturia-Pendragon-Iris/Frepa
一、 动机确立:直击基础模型的“高频盲区”
医学图像的诊断极度依赖于高频和细粒度信息(如微小的视网膜血管、早期肺结节的边缘毛刺)。然而,主流的基础模型在预训练时,往往倾向于捕捉容易学习的低频信息(如器官大体轮廓和平滑背景)。
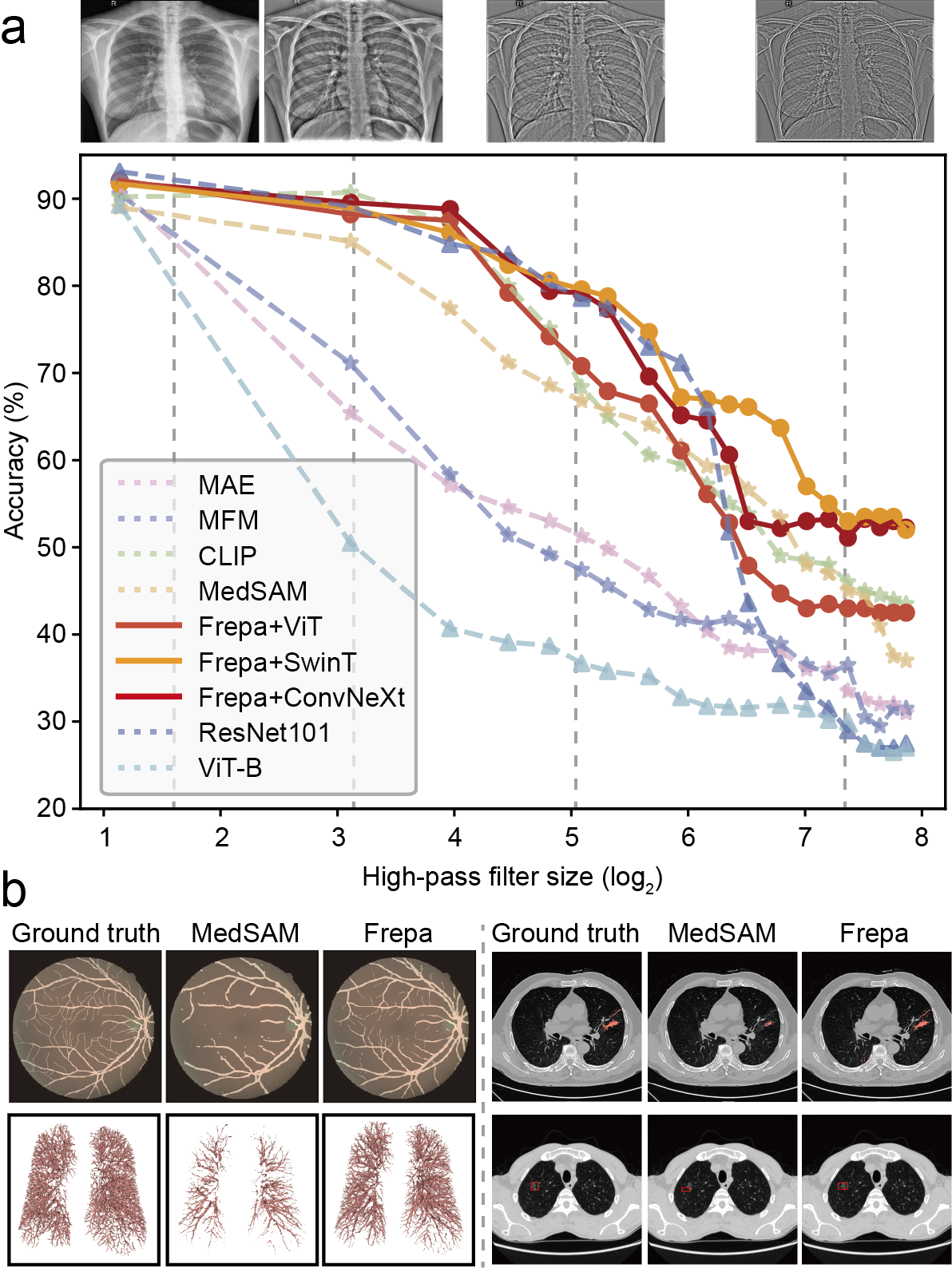
论文在 图 1 (Fig. 1) 中,通过极其巧妙的实验设计揭开了这一问题:
- 定量揭示 (Fig. 1a): 作者对测试集图像施加了尺寸不断增加的高通滤波器(滤除低频,仅保留高频边缘)。结果显示,随着低频信息的剥离,MAE、CLIP 以及专为医学分割微调的 MedSAM,其分类准确率出现了断崖式的急剧下降。这证明了现有模型在高频特征提取上的孱弱。
- 定性灾难 (Fig. 1b): 在视网膜血管等精细分割任务中,MedSAM 输出的血管掩膜呈现出严重的碎片化和断裂。相比之下,本文提出的 Frepa 模型却能精准重构极其细微的末端血管分支,展现出对高频细节的强大掌控力。
二、 Frepa 架构全景
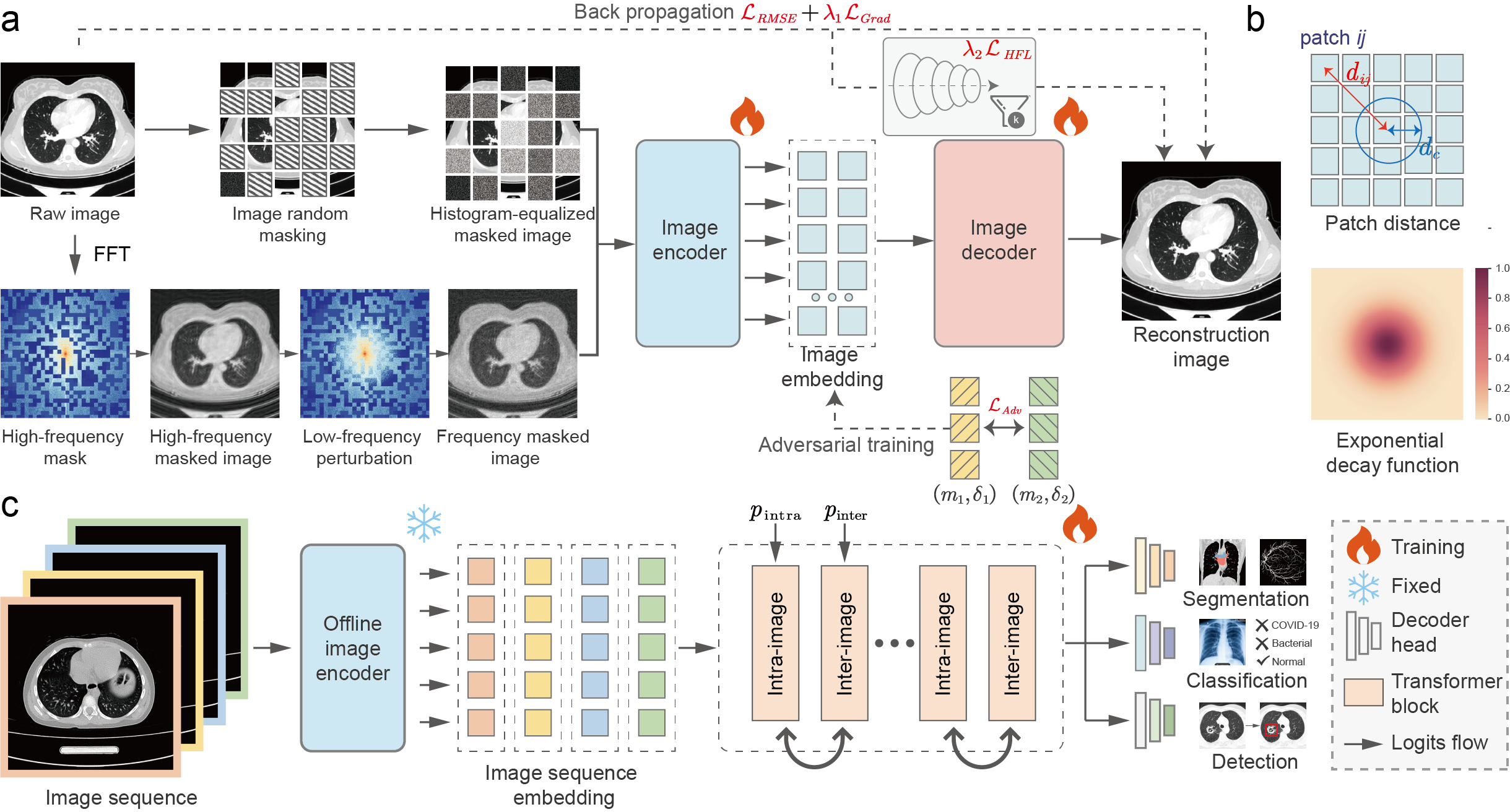
不愧是顶刊论文,无论插图还是实验都做得非常到位,下面先重点解读一下这个最核心的结构图。
图 2(a):核心Pretraining Pipeline
这部分展示了模型在预训练阶段是如何“折磨”输入图像,并强迫网络学习高频特征的。整个流程是一套高度复杂的**“双重掩码 + 联合重构”**机制。两种并行的“图像破坏”策略 (50% 概率随机切换) :
上半路:直方图均衡掩码 (Histogram-equalized masking) 。传统的做法 (如 MAE):把图像切成 Patch,随机丢弃一部分(或者全填成黑色/0)。这种做法会严重破坏图像的全局像素直方图分布(见论文图 3),而且很难用在 CNN 上。Frepa 是选中70%的 Patch 后,不是丢弃它们,而是用具有相同直方图分布(即均值和方差相同)的随机噪声替换它们 。这样既破坏了局部语义,又维持了图像整体的统计学特征。
下半路:频域双组件掩码 (Frequency dual-component masking) 。这是本文的最大亮点。图像首先通过快速傅里叶变换 (FFT) 进入频率域 。 随机遮挡大量的高频区域 。 在低频区域(中心)注入均值为 0 的高斯噪声 。这样极大地破坏模型最容易依赖的低频信息,强迫模型利用残存的高频碎片去反推整张图像 。
编码与重构 (Encoder & Decoder)
被破坏的图像被送入图像编码器 ,这里图上有一个隐藏的细节(结合正文公式 6),为了防止高频特征完全丢失,原始图像的高频边缘(通过 Hessian 滤波器提取)会在通道维度上与破坏后的图像拼接在一起送入网络 。提取出的图像嵌入 (Image embedding) 随后送入解码器 (Image decoder) 尝试恢复原图 。
损失函数的“三管齐下” (图上方的火焰图标与虚线)
LRMSE\mathcal{L}_{RMSE}LRMSE (均方根误差): 保证基础的像素级重构 。LGrad\mathcal{L}_{Grad}LGrad (梯度损失): 强迫重构图像和原图在边缘和结构梯度上保持一致 。λ2LHFL\lambda_{2}\mathcal{L}_{HFL}λ2LHFL (层次化空频损失): 图中展示了 5 个由小到大的同心圆滤波器图标(代表 5 个不同截止频率的指数高通滤波器),将图像过滤后在空间域计算 L1 误差,极度强化了微小细节的重构 。
对抗/一致性训练 (Adversarial training)
图中下方的绿色/黄色方块展示了这一步。同一张图像使用两种不同的随机掩码策略 (m1,δ1)(m_1, \delta_1)(m1,δ1) 和 (m2,δ2)(m_2, \delta_2)(m2,δ2) 得到两张不同的破坏图,模型要求这两个分支提取出的特征向量(Image embedding)之间的 JS 散度(LCon\mathcal{L}_{Con}LCon)尽可能小 。这保证了表征的鲁棒性。
图 2(b):频域掩码
这部分 (右上角) 解释了下半路频域掩码中概率是如何计算的。 频域图的中心是低频,外围是高频。dijd_{ij}dij 代表某个 Patch 距离频域中心的距离 。 图中展示了一个从中心(深色/0.0)到外围(亮色/1.0)渐变的热力图 。这对应了公式 (2) pij=1−exp(−dij2dc2)p_{ij}=1-exp(-\frac{d_{ij}^{2}}{d_{c}^{2}})pij=1−exp(−dc2dij2) 。越靠近中心(低频),被遮挡的概率越低;越靠近外围(高频),被遮挡的概率极速上升。这就是为什么它被称为“Progressive masking strategy (渐进式掩码)” 。
图 2©:从 2D 到 3D 模态的扩展 (Extending to 3D Volume)
这部分展示了 Frepa 非常强大的工程泛化能力:如何把训练好的 2D 编码器,不经过重新预训练 (Zero-shot),直接应用到 3D 医疗数据(如 CT/MRI 序列)上 。 带雪花图标代表参数被冻结。3D 序列被拆分成一张张 2D 切片,每张切片独立通过 2D 编码器,提取出序列特征图 (Image sequence embedding) 。加上帧内位置编码 pintrap_{intra}pintra,模型先学习单张切片内部的空间关系 。 加上帧间位置编码 pinterp_{inter}pinter,模型接着学习切片与切片之间的 Z 轴上下文关系(比如结节在上下切片中的连续性) 。 最后将融合了 3D 时空信息的特征送入不同的任务头,执行 3D 肿瘤分割 (Segmentation)、疾病分类 (Classification) 或病灶检测 (Detection) 。
三、“双重掩码”机制
为强迫模型学习高频特征,Frepa 提出了一套高度复杂的“双重掩码 + 联合重构”管线(见上面 图 2 (Fig. 2) 架构图)。输入图像会以 50% 的概率随机进入两种不同的“破坏”策略,这里在上面的基础上再详细解释。
1. 直方图均衡掩码 (Histogram-equalized masking)
传统的 MAE 会将图像切分为 Patch 并直接丢弃(或置零)。但 Frepa 采用了一种保留统计特性的策略。
-
底层代码分析: 论文称使用了与原 Patch 具有相同直方图分布的噪声进行替换。在实际的开源代码 (
utils.py) 中,作者采用了一个极其高效的工程近似:首先计算出被选中 Patch 在 RGB 三个通道上的均值 (mu) 和标准差 (sigma),随后直接使用 Numpy 的正态分布函数np.random.normal(loc=mu, scale=sigma)生成一块全新的高斯噪声来替换原位置。 -
图 3 (Fig. 3) 的降维打击: 论文图 3 对比了不同掩码策略的像素直方图分布。MAE 的直接置零法会在像素值为 0 处产生一个极其夸张的巨大尖峰,彻底破坏了医学图像原本的物理灰度分布,导致网络容易学习到“识别黑块”的捷径。而 Frepa 的高斯噪声替换法,其破坏后的直方图曲线与原始图像几乎完美重合。模型无法再走捷径,必须依靠周围的纹理去推断马赛克下的高频细节。
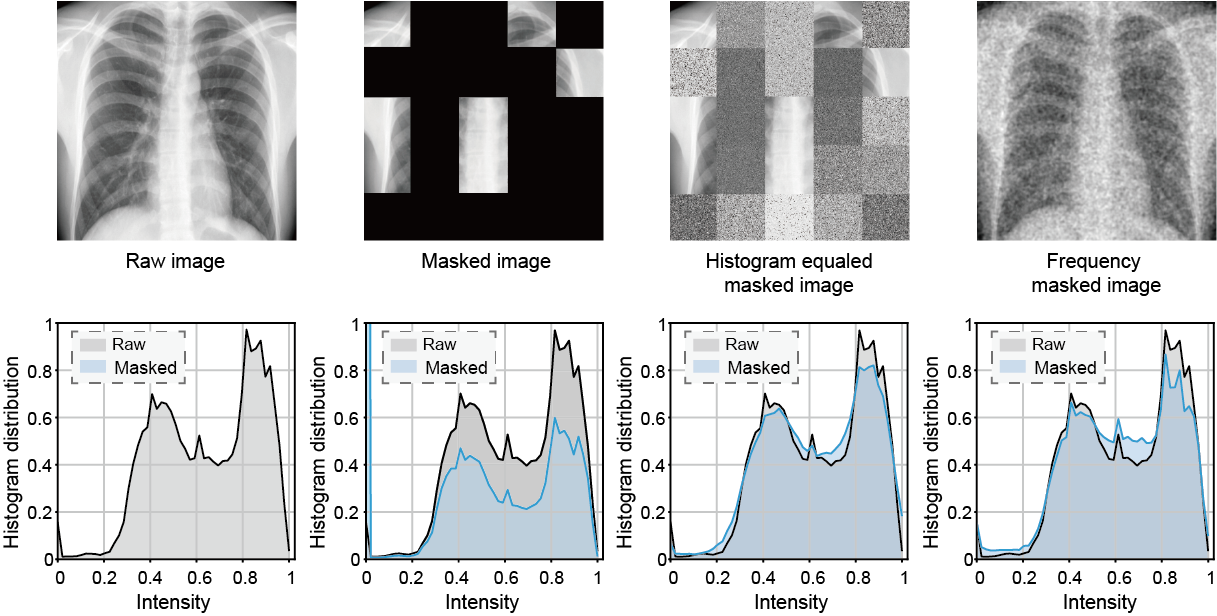
2. 频域双组件掩码 (Frequency dual-component masking)
该策略在频率域对图像进行极致的破坏:遮挡高频区域,并在低频区域注入扰动,迫使模型利用残存的高频碎片反推全图。
- 中心定位与衰减控制: 在代码中,图像经过
np.fft.fft2变换后,紧接着使用了fftshift将零频分量(DC分量,代表整体亮度)强制移动到矩阵的正中心(坐标256, 256)。低频扰动并非硬性覆盖,而是基于公式 1−exp(−dij2/dc2)1-exp(-d_{ij}^2 / d_c^2)1−exp(−dij2/dc2) 生成了一个中心扰动最强、向外围指数级平滑衰减的二维高斯曲面掩码。 - 隐秘的工程技巧: 在源码中存在一行极其不起眼但至关重要的代码:
disturb[:, 256, 256] = 0。作者强制将最中心点的扰动噪声清零。这是因为如果改变了 DC 分量,逆变换回来的图像整体亮度会发生剧烈闪烁。这一神来之笔完美保证了扰动只破坏低频结构,而绝对不改变图像的整体亮度均值(这同样在图 3 的直方图重合度中得到了印证)。
三、 损失函数设计:规避频域过拟合的“曲线救国”
为了指导高频细节的重构,论文引入了层次化空频损失 (HFL, Hierarchical frequency-to-spatial loss)。在此之前,学界常用的方法是焦点频率损失 (FFL),即直接在频率谱上计算误差。
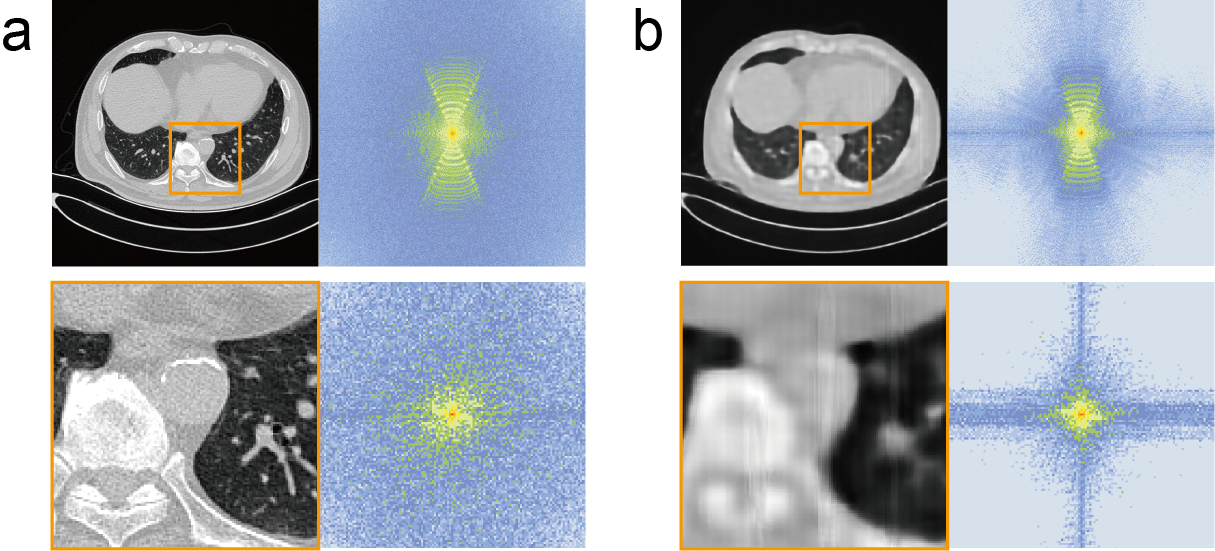
- 图 4 (Fig. 4) 的反面示例: 论文图 4 直观展示了传统 FFL 的灾难性后果。直接在频率域施加对齐约束,极易导致模型在频率域发生过拟合,重构出的图像出现了严重的水波纹状扭曲和网格状失真(即振铃伪影,Aliasing artifacts)。
- HFL 的空间域解法: HFL 采用了一套精妙的转化策略。它利用 5 个不同截止频率的指数高通滤波器,在频率域把预测图和真实图的低频统统挖掉;随后通过逆傅里叶变换 (IFFT),将过滤后的信号变回空间域(此时图像只剩下边缘和噪点的“素描轮廓”);最后,在这两张空间域的“素描图”上逐像素计算 L1 绝对误差。这完美避开了频域直接限制带来的伪影副作用。
- 参数设定的学术包装与工程现实: 论文中声称这 5 个高通滤波器的截断距离为图像短边的 {0.1,0.2,0.3,0.4,0.5}\{0.1, 0.2, 0.3, 0.4, 0.5\}{0.1,0.2,0.3,0.4,0.5} 倍,构建了一个尺度不变的优美数学比例。但深挖开源代码
losses.py会发现,实际代码传递给滤波器的截止距离d0是一组绝对像素值(10, 20, 30, 40, 50)。这揭示了深度学习研究中常见的现象:这组数值本质上来源于实验中对超参数(Hyperparameter)的随手调试,而论文中的相对比例描述,是为了增强方法的普适性和学术严谨性所作的事后重构。
四、 重构能力的终极视觉验证
论文在涵盖 1700 万张图像、9 种模态的庞大数据集上进行了预训练,并在 32 个下游任务中展现出了优异的泛化性能。其卓越的高频捕获能力在 图 5 (Fig. 5) 的定性重构结果中体现得淋漓尽致。
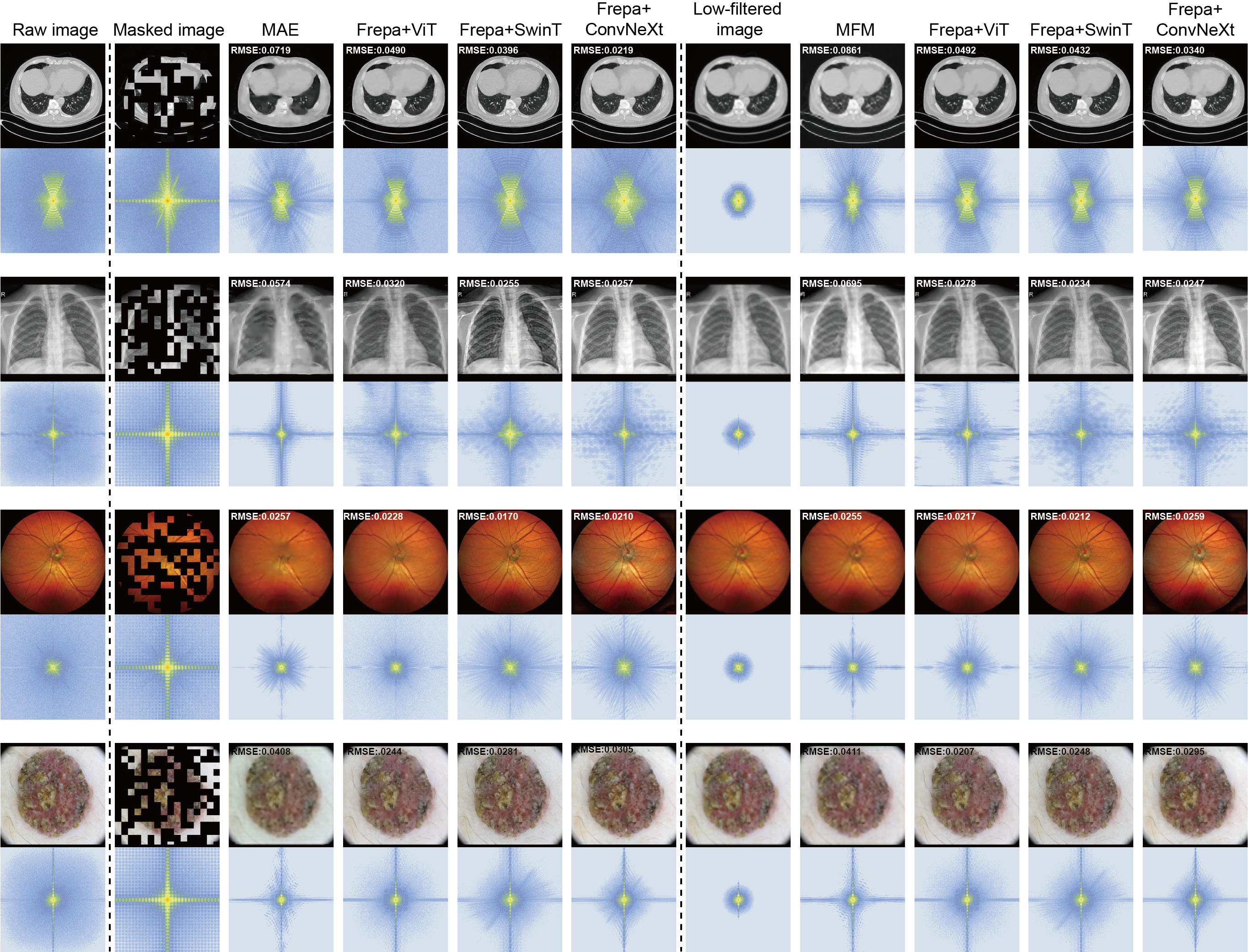
图 5 采用了“空间视觉 + 频率频谱 + RMSE 误差”三位一体的展示方式:
- 对比 MAE: 面对随机掩蔽,MAE 的重构图像极其模糊,其频率谱能量死死收缩在中心(仅有低频);而 Frepa 重构的血管边缘锐利,频率谱中代表高频的十字星芒清晰可见,能量有效向外围扩散。
- 极限鲁棒性测试: 图 5 右半部分展示了应对“低通滤波模糊”时的重构表现。作者强调,这种模糊退化模式在 Frepa 的预训练阶段是“从未见过的 (Zero-shot corruption)”。即便如此,Frepa 依然成功“推断”并补全了丢失的高频纹理。这证明了模型并非死记硬背某种特定的掩码规则,而是真正内化了医学图像底层的高频纹理生成先验。
五、 小结
这篇论文敏锐地捕捉到了医学基础模型领域的核心痛点。它通过数学直觉与底层信号处理逻辑(FFT、频域掩码、空间域高频过滤)的深度结合,构建了一套逻辑自洽且行之有效的预训练框架。
尽管在开源代码的核对中,我发现了一些诸如超参数对齐差异、以及辅助损失项的实现偏差,但这并不掩盖其“通过频域操作强化高频表征”这一核心思路的巨大启发意义。对于旨在提升微小病灶检测和精细结构分割能力的医疗 AI 开发者而言,该框架提供了一条极具价值的破局之道。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)