Spring Boot + DeepSeek 实战教程(非常详细),企业级 AI 知识库构建从入门到精通,收藏这一篇就够了!
摘要:在信息爆炸的时代,企业如何打破部门壁垒,让沉睡的文档“活”起来?本文分享了一个基于 Spring Boot 2.7 + React 18 + DeepSeek 大模型 的企业级知识库管理系统实战方案。通过集成 RAG(检索增强生成) 技术与 向量化语义搜索,我们实现了从“关键词匹配”到“意图理解”的跨越,将员工查找信息的时间从平均 15 分钟缩短至 2 分钟。文章将深入解析系统架构、权限设计、AI 集成核心代码及落地效益,为你提供一套可复制的智能化知识管理解决方案。
一、 痛点:为什么你的企业需要一个 AI 知识库?
你是否也遇到过这样的场景:
- 📂 知识孤岛:技术文档在 GitLab,制度文件在 OA,项目经验在老员工脑子里。
- 🔍 查找如大海捞针:为了找一个 API 规范,要在五个系统中切换,耗时半小时。
- 🔒 权限混乱:敏感财务数据被误传,或者新员工根本看不到该看的文档。
- 🤖 重复劳动:同样的问题,HR 每天要回答十遍,技术人员反复解释架构规范。
传统的网盘或 Wiki 系统已无法满足需求。2026 年的今天,企业需要的不只是存储,而是“懂你”的智能助手。
结合近期行业趋势,DeepSeek 等大语言模型的崛起,让构建低成本、高精度的企业私有知识库成为可能。不同于通用大模型的“幻觉”问题,基于 RAG(Retrieval-Augmented Generation) 架构的知识库,能让 AI 基于企业真实数据回答问题,准确率大幅提升。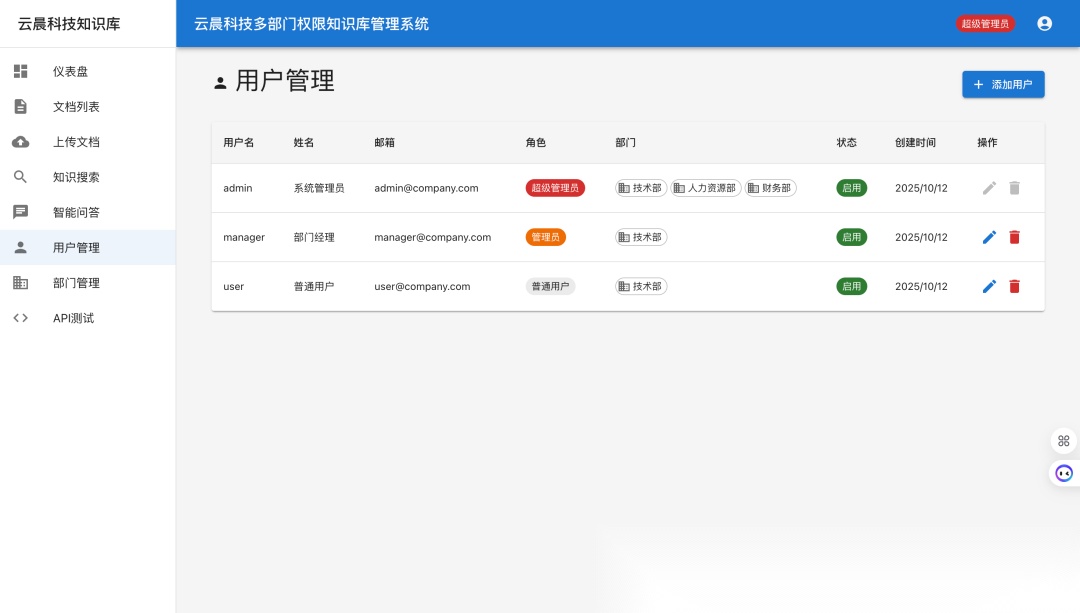
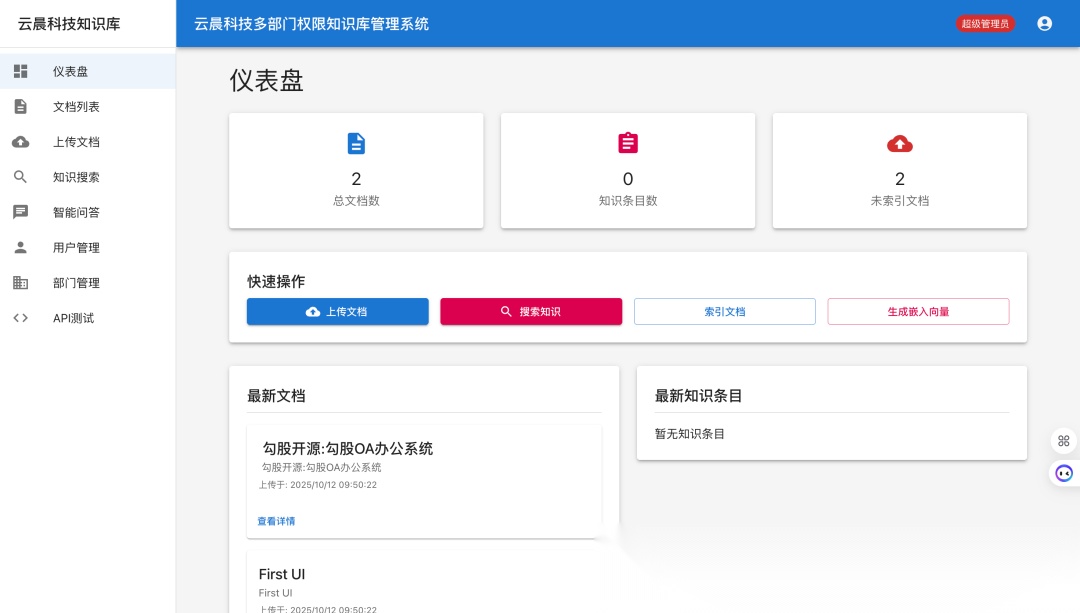
二、 架构揭秘:三层驱动,安全与智能并重
本系统采用经典的前后端分离架构,但在核心层引入了 AI 服务层,形成了独特的四层驱动模型:
graph TD A[用户层: Web/移动端] -->|HTTPS| B(Nginx 反向代理) B --> C[前端应用: React 18 + TS] C -->|RESTful API| D[后端服务: Spring Boot 2.7] D --> E[(MySQL 8.0: 业务数据)] D --> F[文件系统: 文档存储] D --> G{AI 服务层} G -->|语义向量 | H[OpenAI Embeddings] G -->|智能生成 | I[DeepSeek API] D -->|权限过滤 | J[部门权限引擎]
核心技术栈选型理由
| 模块 | 技术选型 | 核心理由 |
|---|---|---|
| 后端框架 | Spring Boot 2.7 | 生态成熟,企业级安全组件完善,易于集成 JWT 与 Security。 |
| 前端框架 | React 18 + TS | 类型安全,组件化开发效率高,Material-UI 快速构建现代化界面。 |
| 大语言模型 | DeepSeek | 中文理解能力极强,API 成本低,适合企业级长文本处理与逻辑推理。 |
| 向量化引擎 | OpenAI Embeddings | 业界标杆,语义捕捉精准,配合余弦相似度算法实现智能检索。 |
| 文档解析 | Apache Tika | 支持 50+ 种格式(PDF/Word/PPT),自动提取文本与元数据。 |
三、 核心功能实战:如何让 AI 真正“懂”业务?
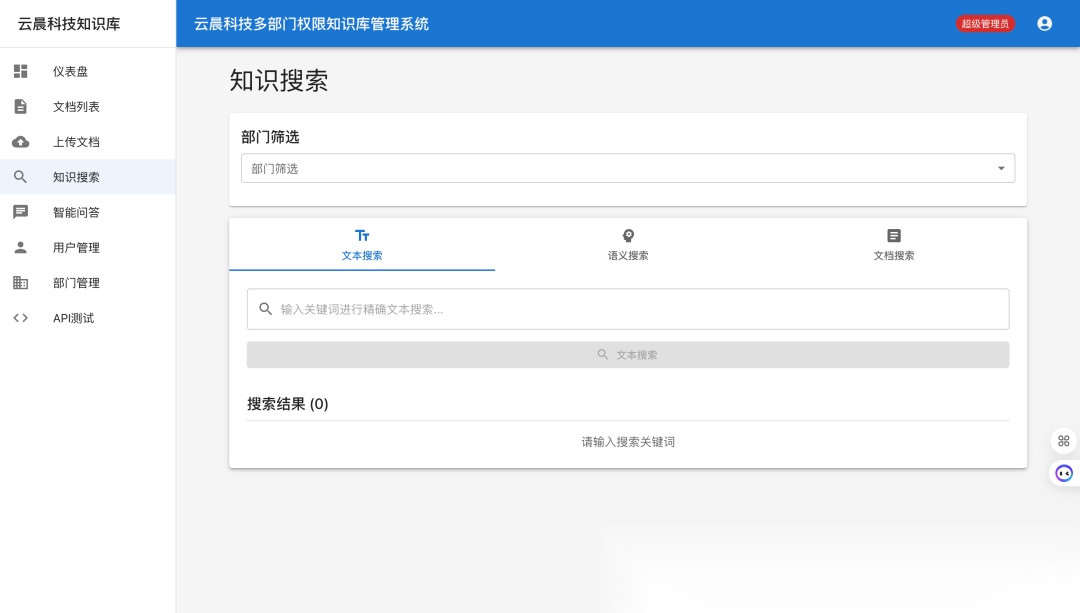
1. 语义搜索:超越关键词的“心意相通”
传统搜索只能匹配“Java 教程”,却搜不到“如何编写后端代码”。我们的系统通过 向量化技术 解决了这个问题。
实现原理:
- 文档分块:上传文档后,利用 Apache Tika 解析文本,并按语义段落切分。
- 向量嵌入:调用 Embeddings API 将文本块转换为高维向量(Vector)。
- 相似度计算:用户提问时,系统将问题也转为向量,通过 余弦相似度算法 检索最相关的片段。
// 核心代码:计算余弦相似度public double calculateCosineSimilarity(String embedding1, String embedding2) { double[] vec1 = parseEmbedding(embedding1); double[] vec2 = parseEmbedding(embedding2); double dotProduct = 0.0, norm1 = 0.0, norm2 = 0.0; for (int i = 0; i < vec1.length; i++) { dotProduct += vec1[i] * vec2[i]; norm1 += vec1[i] * vec1[i]; norm2 += vec2[i] * vec2[i]; } return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));}
效果:用户搜索“怎么请假”,系统能精准匹配到《员工考勤管理制度》中关于“年假申请流程”的段落,即使文档里没有“怎么请假”这四个字。
2. AI 智能问答:RAG 架构消除“幻觉”
单纯的搜索只能给文档列表,而 DeepSeek 的加入让系统能直接给出答案。
工作流:
- 检索:根据用户问题,从向量库中召回 Top 5 相关文档片段。
- 构建上下文:将这些片段作为“已知信息”注入 Prompt。
- 生成:DeepSeek 基于上下文生成自然流畅的回答,并标注来源。
// 构建系统提示词 (System Prompt)private String buildSystemPrompt(List<KnowledgeEntry> entries) { StringBuilder prompt = new StringBuilder("你是一个企业知识库助手。请严格基于以下知识库内容回答问题:\n"); for (int i = 0; i < entries.size(); i++) { prompt.append("[参考片段").append(i+1).append("]: ").append(entries.get(i).getContent()).append("\n"); } prompt.append("如果知识库中没有相关信息,请直接说明,不要编造。"); return prompt.toString();}
3. 多部门权限隔离:安全是企业的生命线
这是本系统与开源 ChatBot 最大的不同。我们设计了 用户 - 部门 - 文档 的多对多权限模型。
- 数据隔离:技术部的文档,财务部员工绝对不可见(除非授权)。
- 动态过滤:在向量检索前,先通过 SQL 过滤掉无权访问的
department_id。 - 角色控制:
SUPER_ADMIN:全知全能。ADMIN:管理本部门数据。USER:仅查看与问答。
// 权限过滤逻辑public List<KnowledgeEntry> searchByUser(User user, String query) { Set<Long> allowedDeptIds = user.getDepartments().stream() .map(Department::getId) .collect(Collectors.toSet()); // 先在数据库层面过滤权限,再进行向量匹配,确保数据安全 return knowledgeEntryRepository.findByDepartmentIdInAndContentSimilar( allowedDeptIds, generateEmbedding(query) );}
四、落地成效:数据说话
在某拥有 200+ 技术人员的互联网公司部署后,效果显著:
| 指标 | 传统模式 | AI 知识库模式 | 提升幅度 |
|---|---|---|---|
| 信息查找时间 | 平均 15-20 分钟 | 2-3 分钟 | 🚀 85% |
| 新员工上手周期 | 2-3 周 | 3-5 天 | 🚀 70% |
| 重复咨询量 | 每日 50+ 次 | 每日 5 次以下 | 🚀 90% |
| 知识覆盖率 | 约 40% (分散) | 95%+ (统一) | 📈 显著提升 |
 真实反馈:
真实反馈:
“以前遇到一个报错,我要去翻 Wiki、查 Git 记录、问老同事,现在直接问系统,它直接把三年前那个类似项目的解决方案推给我了,还附带了代码片段。” —— 某高级开发工程师
五、避坑指南与最佳实践
在开发过程中,我们也踩了不少坑,总结几点关键经验:
- 文档切片策略:不要简单按字符数切割。我们采用了按段落 + 标题层级的混合切片策略,保留了上下文完整性,显著提升了 RAG 的准确率。
- 混合检索机制:纯向量搜索在处理专有名词(如特定错误码)时表现不佳。我们采用了 “关键词检索 + 向量检索” 的加权混合模式,兼顾精确匹配与语义理解。
- 成本控制:Embeddings 和 LLM 调用都有成本。我们引入了缓存机制,对高频问题直接返回缓存答案;对长文档进行异步向量化处理,避免阻塞主线程。
- 数据安全:所有上传文档在落盘前进行病毒扫描,敏感字段(如手机号)在入库前通过正则自动脱敏。
六、结语:知识管理的未来
2026 年,企业竞争的本质是认知效率的竞争。
这套系统不仅仅是一个工具,它是企业知识的**“第二大脑”**。它将散落在各处的非结构化数据,转化为可对话、可推理的资产。随着 GraphRAG(知识图谱 + RAG) 技术的成熟(如 2026 年最新趋势所示),未来的知识库将不仅能回答问题,还能理清复杂的人物关系、项目脉络和因果逻辑。
别让知识沉睡在硬盘里,现在就行动,用 AI 激活你的企业智慧!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)