基于 Transformer 的底层视觉骨干网络
引言
Transformer架构自2017年提出以来,在自然语言处理领域取得突破性进展,随后被成功引入计算机视觉任务并展现强大能力。本文就SwinIR、Restormer、HAT等相关论文(持续更新~)为主线,整理一些基于Transformer的底层视觉骨干网络。
这类模型采用"通用特征提取 + 任务特定重建"的模块化架构:Transformer模块负责在特征空间学习长程依赖与内容感知表示,而输入输出分辨率的变化、退化类型的差异则通过可替换的重建头、损失函数等灵活适配。这一设计使得同一骨干网络能够跨越图像超分辨率、去噪、去模糊、去雨等多个底层视觉任务,展现出强大的通用性与可扩展性。
SwinIR
动机
1. 针对CNN:
图像与卷积核之间的交互关系与图像内容无关,使用相同的卷积核对不同的图像区域进行复原处理,并非最优选择。并且,卷积遵循局部处理的原则,难以对图像的长距离依赖关系进行有效建模。
2. 针对VIT分块处理图像(用于缓解Transformer计算复杂度)的方式:
图像块边缘的像素无法利用块外的相邻像素完成图像复原;并且,复原后的图像会在各图像块的边缘处产生边界伪影。
3. Swin Transformer 因融合了CNN 与 Transformer 二者的优势,展现出了极佳的应用前景。于是提出一种基于 Swin Transformer 的图像复原模型,将其命名为 SwinIR。
做法
Overview
分三个模块:浅层特征提取模块、深层特征提取模块和高质量图像重建模块。
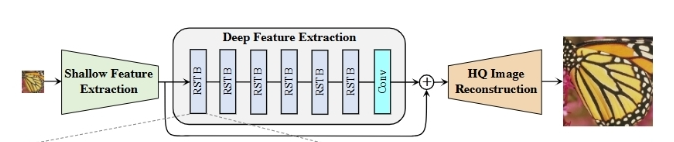
浅层特征提取:仅用一个卷积层。(由输入H×W×3的图像得到H×W×C的浅层特征)
深层特征提取:K个residual Swin Transformer blocks (RSTB),最后加一个卷积层。(由H×W×C的浅层特征得到H×W×C的深层特征)
高质量图像重建:融合深、浅特征后,(两者相加得到H×W×C的深浅特征)利用像素重排重建图像得到输出H×W×3的图像)
核心深层特征提取单元 residual Swin Transformer blocks (RST B)
1. 堆叠 L 层 Swin Transformer 层(STL) + 1 层 3×3 卷积 + 残差连接
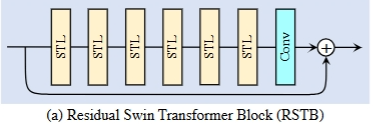
2. Swin Transformer 层(STL)
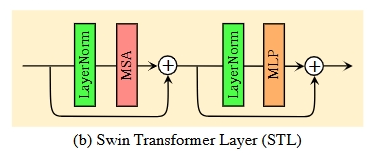
2.1 层归一化
2.2 MSA
(1)窗口划分:将 H×W×C 的特征图划分为若干个固定大小的非重叠窗口(如 8×8),仅在窗口内计算自注意力。
目的:全局自注意力的计算复杂度是 O(HW)2,窗口化后降为 O((HW/M2)⋅M4)=O(HWM2)(M 为窗口大小),大幅降低计算量;图像复原的核心是「局部细节修复」(如超分的纹理、去噪的像素级修正),窗口化能聚焦局部特征,避免全局计算的冗余。
(2)移位窗口 :相邻 STL 层交替使用「常规窗口」和「移位窗口」(窗口整体偏移 M/2 像素)目的:解决固定窗口间无信息交互的问题,固定窗口会导致「窗口边界伪影」(复原后图像出现网格状分割),移位窗口让相邻层的窗口重叠,实现跨窗口信息流通;
2.3 MLP
采用一个多层感知机(MLP) 进行进一步的特征变换,该感知机包含两个全连接层,层之间使用 GELU 非线性激活函数。
目的:引入非线性表达能力,自注意力是线性操作,无法拟合复杂映射。MLP + GELU 提供非线性,让模型学会复杂的纹理、边缘、细节恢复;
自注意力只在空间维度做交互(像素之间),MLP 在通道维度做融合(特征之间)
评价
核心模块来自于SwinTransformer,创新度好像少了一点。是一个简单高效的 “应用创新” 论文,把 Swin Transformer 成功落地到底层视觉,为后续大量 Transformer-based 底层图像工作打下基础。
Restormer
动机
将图像分块来减少Transformer计算复杂度的操作:是限制自注意力的空间作用范围,这与建模真实长程像素依赖关系的目标相矛盾。(SwinIR通过移位窗口,可以逐渐传递信息)
核心仍然是Transformer长程依赖能力和计算复杂度的trade-off
.....于是提出了Restormer,核心模块是多深度卷积头转置注意力(MDTA)和门控深度卷积前馈网络(GDFN)
做法
Overview
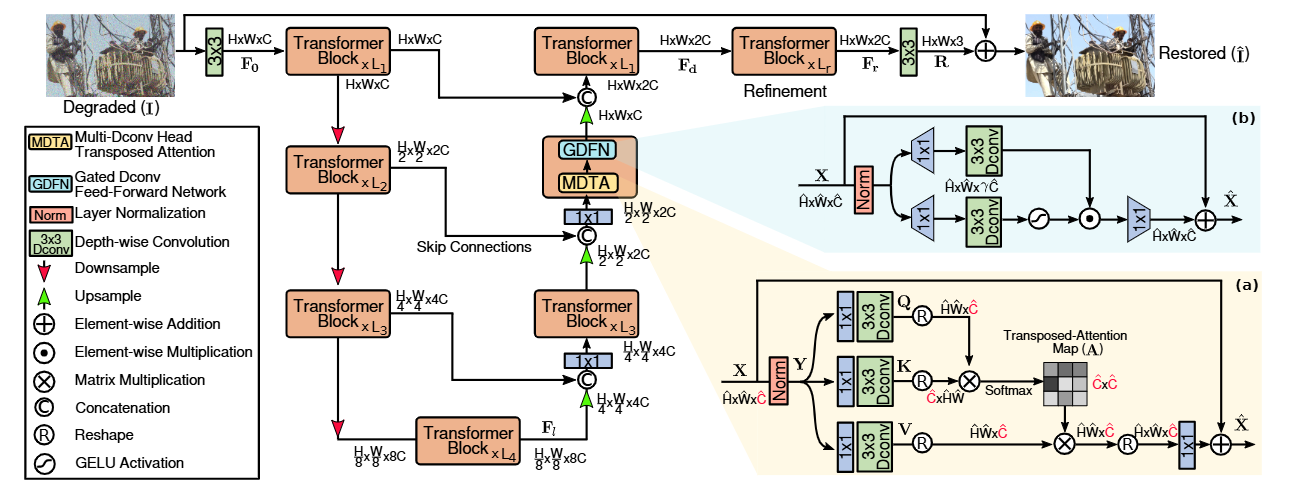
整体分为三部分:浅层特征提取、多尺度编码器 - 解码器深层特征提取、高分辨率细化与图像重建。
浅层特征提取:用一个卷积层将退化图像映射为浅层特征,保留基础纹理与边缘信息。
深层特征提取:4 级对称编码器 - 解码器结构,每级由多个 Restormer 基础 Transformer 块构成;下采样用 pixel-unshuffle,上采样用 pixel-shuffle;编码器与解码器间通过跳跃连接融合多尺度特征。
高分辨率重建:深层特征经细化模块增强后,用卷积输出残差图像,与输入图像相加得到最终清晰图像。
核心 Transformer 块(Restormer Block)
由两个关键创新模块组成:MDTA + GDFN,配合层归一化与残差连接。
1. MDTA: Multi-Dconv Head Transposed Attention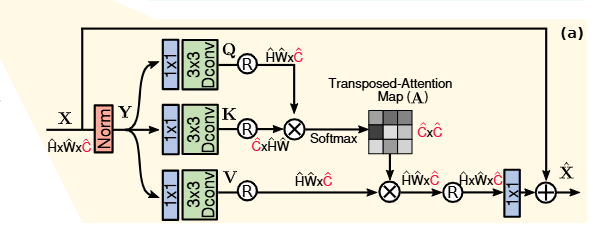
首先是一个1*1卷积,融合跨通道信息;然后用3*3深度卷积在通道级上融合空间信息;由此得到Q,K,V。
传统的Transformer是Q乘K的转置,然后除![]() 后softmax:输出HW*HW的空间上的注意力分数矩阵;现在是用K乘Q然后除可学习的alpha后softmax:输出C*C的通道注意力图了。
后softmax:输出HW*HW的空间上的注意力分数矩阵;现在是用K乘Q然后除可学习的alpha后softmax:输出C*C的通道注意力图了。
然后计算通道间的关联度:V乘通道注意力图,最后1*1卷积进一步通道融合并残差输出。
2. Gated-Dconv Feed-Forward Network
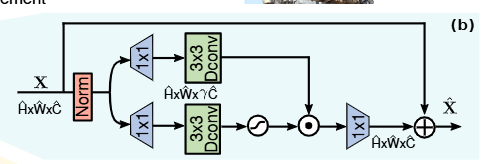
核心就是: “给特征加个开关”:通过两个并行分支的逐元素乘积(⊙),让模型自主决定 “哪些特征该保留、哪些该抑制”扩展维度后逐元素相乘。这种能力来自于一个有GeLU,而一个没有。
评价
Restormer 是2020CVPR oral,含金量很高。Restormer 不依赖窗口 / 分块,直接在通道维度做轻量化自注意力,创新度高,解决高分辨率下 Transformer 复杂度爆炸问题。它是面向底层视觉的原生高效 Transformer 设计,在去雨、去模糊、去噪等任务上全面 SOTA,效率与效果双优,为无窗口、高分辨率 Transformer 复原模型提供全新范式。
HAT
动机
针对SwinIR提出疑问:是否真正利用了Transformer的长局建模能力?
通过局部归因图(LAM)发现SwinIR利用的信息不比CNN多:(红色代表利用到的信息,这种方法源自于论文Interpreting Super-Resolution Networks with Local Attribution Maps这篇论文提出的方法)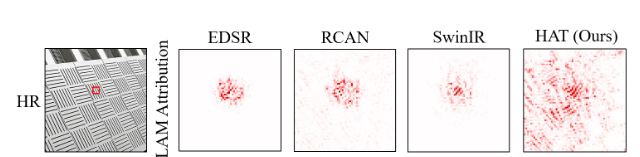
因此他们认为,SwinIR 的性能优势源于其相比 CNN 更强的局部信息建模能力。
于是提出混合注意力Transformer:融合了通道注意力与自注意力两种机制,以此充分发挥通道注意力对全局信息的捕捉能力,以及自注意力强大的特征表征能力;此外,还引入了重叠交叉注意力模块,实现相邻窗口特征更直接的信息交互。
做法
Overview

三个部分组成:浅层特征提取、深层特征提取和图像重建三部分构成。
浅层特征提取:![]() 其中:
其中:![]() ,
,![]() 。浅层特征提取模块可将输入从低维空间映射至高维空间,同时实现对每个像素特征令牌的高维嵌入。此外,网络前向的卷积层有助于模型学习更优质的视觉特征表征,并能提升模型优化过程的稳定性。
。浅层特征提取模块可将输入从低维空间映射至高维空间,同时实现对每个像素特征令牌的高维嵌入。此外,网络前向的卷积层有助于模型学习更优质的视觉特征表征,并能提升模型优化过程的稳定性。
深层特征提取:![]() ,由N1个残差混合注意力组(RHAG)和一个 3×3 卷积层组成。
,由N1个残差混合注意力组(RHAG)和一个 3×3 卷积层组成。
图像重建:![]() ,使用全局残差连接以融合浅层特征与深层特征,再通过重建模块还原出高质量图像。
,使用全局残差连接以融合浅层特征与深层特征,再通过重建模块还原出高质量图像。
核心RHAG块:
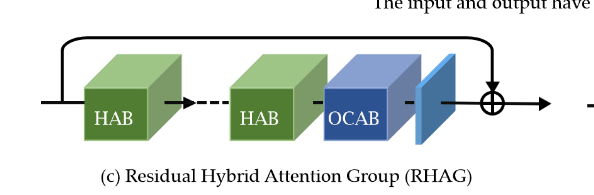
由HAB和OCAB组成:
1. Hybrid Attention Block (HAB):混合注意力块
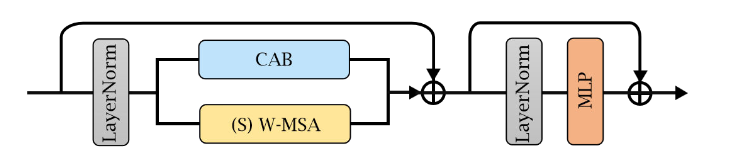
并行作用标准的通道注意力块(CAB)与多头自注意力(MSA),并用alpha加权。
(CAB:Image Super-Resolution Using Very Deep Residual Channel Attention Networks)
(MSA:SwinIR)
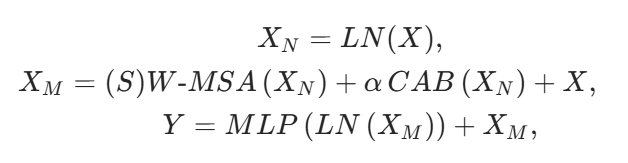
2. Overlapping Cross-Attention Block (OCAB):重叠交叉注意力块
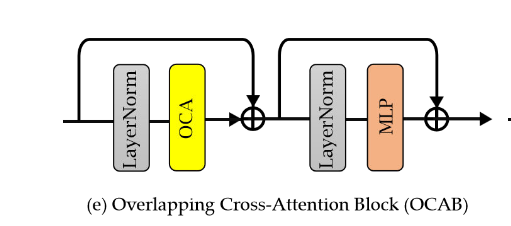
核心在于OCA:查询用小窗口,键 / 值用更大的重叠窗口,让每个查询能看到更多上下文。每个查询都能 “看到” 更大范围的信息,直接实现跨窗口交互:
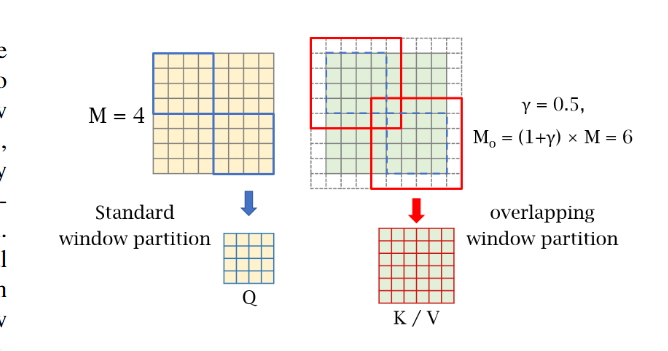
维度变换不会出现问题,只是注意力图不是正方形的了:
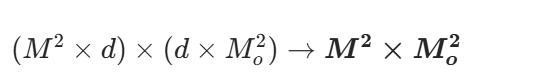
![]()
预训练策略
预训练已被证明在许多高层视觉任务中是有效的。
IPT 强调利用多种低阶任务(如去噪、去雨、超分辨率等)进行预训练,
EDT 则采用特定任务的不同退化等级来开展预训练。
这些工作主要探究多任务预训练对目标任务的效果。与之不同,我们基于同一任务在更大规模的数据集(即 ImageNet [84])上直接进行预训练,结果表明预训练的效果更多地取决于数据的规模与多样性。例如,当我们需要训练一个 4 倍超分辨率模型时,首先在 ImageNet 上训练一个 4 倍超分辨率模型,随后在特定数据集(如 DF2K)上进行微调。我们提出的这一策略,即同任务预训练,更为简洁,同时能带来更显著的性能提升。
其中,IPT:[18] H. Chen, Y. Wang, T. Guo, C. Xu, Y. Deng, Z. Liu, S. Ma, C. Xu, C. Xu, and W. Gao, “Pre-trained image processing transformer,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 12 299–12 310.
EDT:[21] W. Li, X. Lu, S. Qian, and J. Lu, “On efficient transformer-based image pre-training for low-level vision,” in Proc. Int. Joint Conf. Artif. Intell., 2023, pp. 1089–1097.
评价
HAT是2023CVPR后又扩展到TPAMI,可以说是基于 Transformer 底层视觉骨干网络的集大成者。虽然本质性改进相对少,但有机组合、改进了各个模块,取得sota效果,并且动机明确,消融实验相当完善,讨论全面。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)