【大模型学习】 文本子词分词算法是大语言模型的一项关键技术,负责将文本转换为模型可处理的 token 序列。那为什么不能直接以“字符“或“单词“作为模型的输入单元?
文本在进入大语言模型之前,必须先通过 分词(Tokenization) 转换成 token 序列。很多人会问:既然文本本身就是字符或单词,为什么不直接用 字符(character) 或 单词(word) 作为模型输入?这正是子词分词算法(如 BPE)要解决的问题。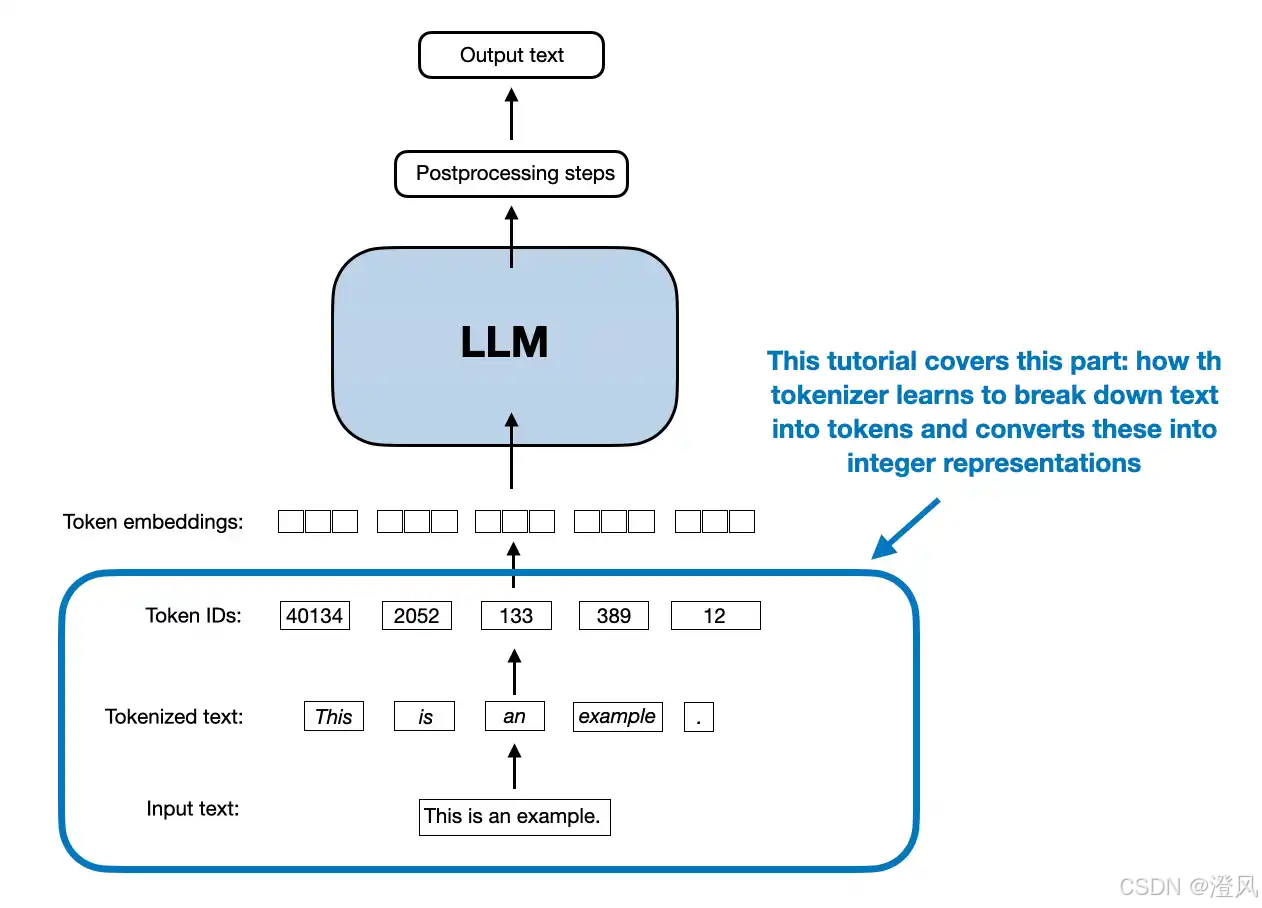
一、为什么不能直接用“字符”作为输入单位
如果使用 字符级(Character-level) 分词,每个字母或汉字都是一个 token。
例如:
Transformer
字符级表示:
T r a n s f o r m e r
存在的问题
1. 序列长度会非常长
字符粒度太细,一句话会被拆成很多 token,例如:
Deep learning models are powerful
字符级 token 可能是:
D e e p _ l e a r n i n g _ m o d e l s ...
序列长度会 增长数倍。
而 Transformer 的计算复杂度与序列长度平方相关:
O(n^2)
序列越长,计算成本越高。
2. 语义表达能力弱
字符本身几乎没有语义。
例如:
c a t
模型需要通过很多层网络才能理解它是一个单词 cat。
这会让训练变得更困难。
二、为什么不能直接用“单词”作为输入单位
另一种直觉是使用 词级(Word-level) 分词。
例如:
Deep learning models are powerful
token:
Deep | learning | models | are | powerful
看起来更合理,但也有严重问题。
1 词表规模会非常巨大
自然语言的词汇量非常大。
例如英语:
run
runs
running
runner
如果全部作为独立词汇,词表可能达到:
数百万甚至上千万
这会导致:
- embedding矩阵巨大
- 训练成本增加
2 OOV(未登录词)问题
如果词表中没有某个词:
ChatGPT
blockchain
microservice
模型就无法处理。
传统方法只能用:
<UNK>
代替。
这样语义信息会丢失。
三、BPE(Byte Pair Encoding)解决了什么问题
BPE 是一种 子词(Subword)分词算法。
它的核心思想是:
通过统计文本中最常见的字符组合,不断合并字符,逐渐形成子词单位。
这样可以在 字符和单词之间找到一个平衡粒度。
四、BPE 的基本过程
假设语料只有这些单词:
low
lower
newest
widest
初始状态:全部拆成字符
l o w
l o w e r
n e w e s t
w i d e s t
第一步:统计最常见的字符对
例如:
e s
出现最多。
合并:
es
第二步:继续统计
可能出现:
lo
再合并。
不断重复这个过程。
最终可能得到:
low
er
new
est
wide
这些就是 子词 token。
五、BPE 的优点
1 词表规模可控
通常:
30k – 100k token
既不会太大,也不会太小。
2 可以处理未登录词
即使遇到新词:
microservice
也可以拆成:
micro + service
或者:
micro + serv + ice
模型仍然可以理解。
3 序列长度适中
相比字符:
token数量减少
相比单词:
语义更灵活
4 能捕捉词内部结构
例如:
unhappy
可以拆成:
un + happy
模型可以学习:
un = 否定前缀
六、总结
为什么不用字符或单词作为输入单位:
| 方法 | 问题 |
|---|---|
| 字符级 | 序列太长、语义弱 |
| 单词级 | 词表巨大、OOV问题 |
BPE 的作用是:
在字符和单词之间找到一个合适的子词粒度。
优势:
- 控制词表规模
- 避免未登录词问题
- 减少序列长度
- 保留一定语义信息
因此 BPE 以及类似的子词分词算法(如 WordPiece、SentencePiece)成为大语言模型的标准分词方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)