深入浅出RNN及其变体:从传统RNN到LSTM、GRU
一、什么是RNN
循环神经网络(Recurrent Neural Network, RNN) 是一类以序列数据为输入的神经网络。它通过网络内部的结构设计,能够有效捕捉序列数据之间的前后关联特征,输出通常也是序列形式。
序列数据:数据前后有关联关系(文本,股票,语音)
二、RNN的作用与类别
1. RNN的作用
RNN能够充分利用序列数据之间的连续性关系,因此非常适合处理自然界中具有连续性的输入数据,如:
-
人类语言(文本、语音)
-
时间序列数据(股票价格、天气变化)
主要应用领域:自然语言处理(NLP)
-
文本分类
-
情感分析
-
意图识别
-
机器翻译
-
阅读理解
-
文本摘要
2. RNN的类别
(1)按输入输出结构分类
| 类别 | 特点 | 应用场景 |
|---|---|---|
| N vs N | 输入与输出等长 | 生成等长度的上下联诗句、序列标注 |
| N vs 1 | 输入序列,输出单个值 | 文本分类、情感分析 |
| 1 vs N | 输入单个值,输出序列 | 图片生成文字(图像描述)AIGC |
| N vs M | 输入输出长度均可变 | 机器翻译、阅读理解、文本摘要 中英文互译 |
(2)按内部构造分类
-
传统RNN
-
LSTM(长短期记忆网络)
-
GRU(门控循环单元)
三、传统RNN
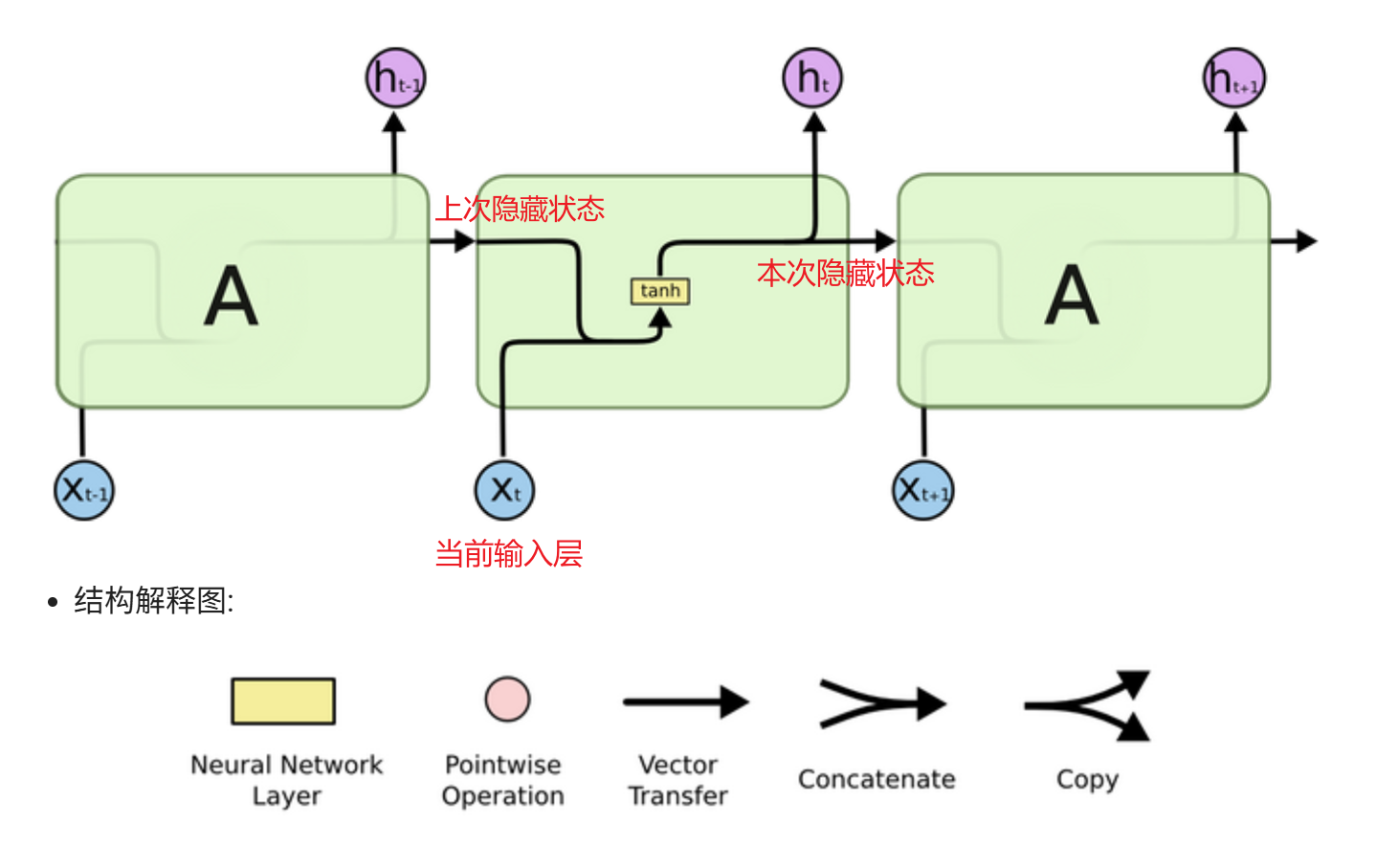
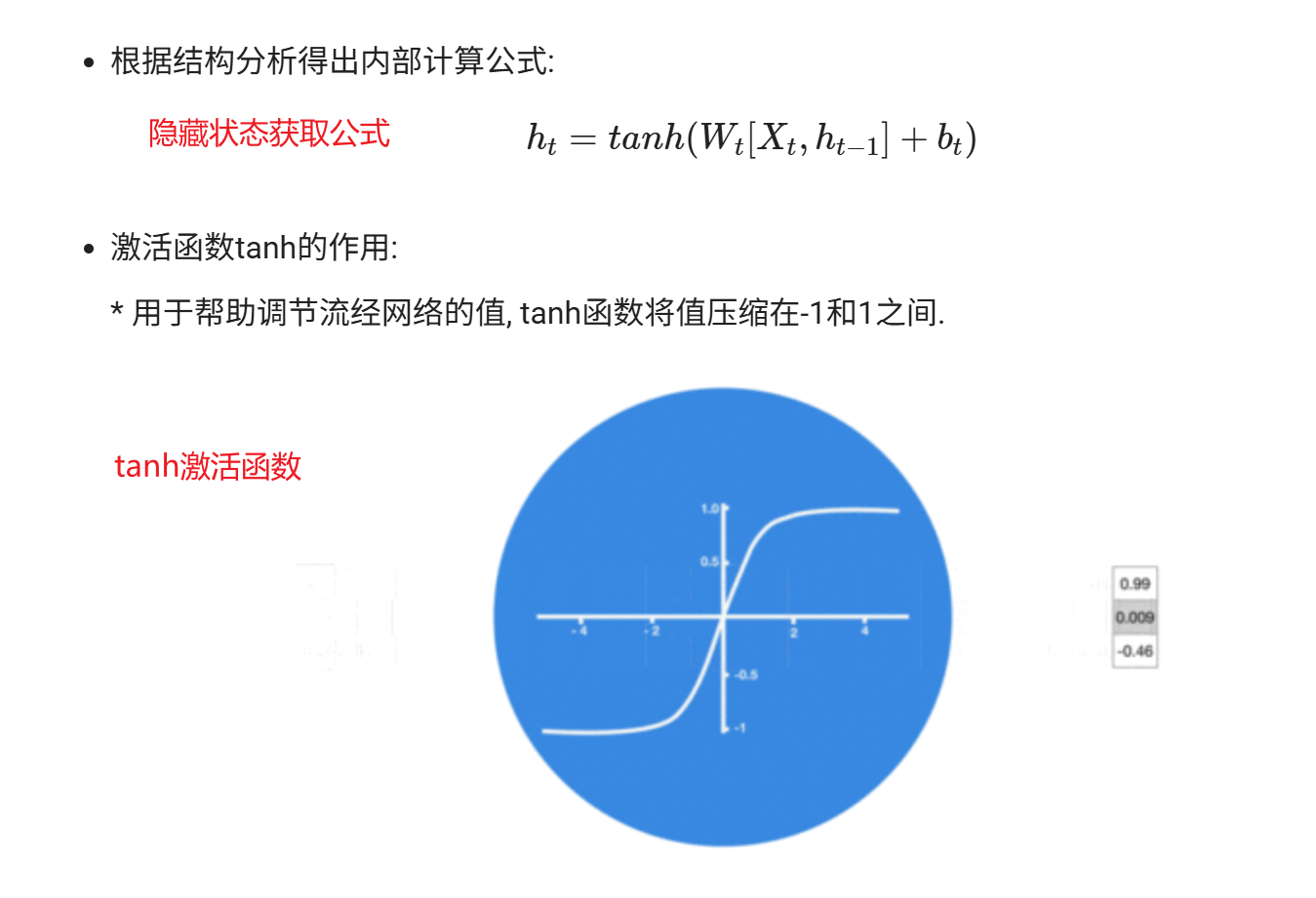
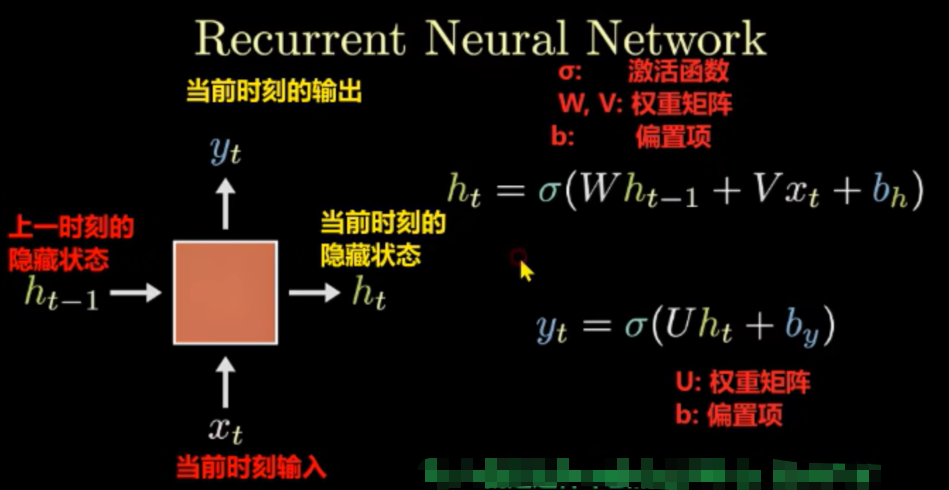
RNN的计算过程是:将上一时刻的隐藏状态与当前输入合并后加权求和,再经过tanh激活得到当前隐藏状态,最后根据任务类型对该隐藏状态进行加权求和后,通过Softmax(多分类取最大值)、Sigmoid(二分类取概率)或直接输出(回归)来得到当前时刻的预测值。
1. 模型结构
-
输入:上一时刻的隐藏状态 ht−1 + 当前时刻的输入 xt
-
输出:当前时刻的输出 output + 当前时刻的隐藏状态 ht
2. 模型构建要点
-
隐藏状态在时间步之间传递信息
-
参数共享:所有时间步使用相同的权重矩阵
3. 优点
-
内部结构简单
-
参数量少,计算资源要求低
4. 缺点
-
长序列处理能力差:当序列过长时,反向传播过程中容易出现梯度消失或梯度爆炸,导致模型难以捕捉长距离依赖关系。
-
缺点的根本原因: 反向传播链式法则中对tanh激活函数求导的范围在 (0-1],如果传播链路过长,链式法则下的累乘,会导致梯度不断衰减,从而导致梯度消失,无法完成权重w的更新,导致模型能力差,无法传播更新到早期记忆的范畴
-
import torch import torch.nn as nn def dm_rnn_for_base(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 1) #A ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(1, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) #C # [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6] output, hn = rnn(input, h0) print('output--->',output.shape, output) print('hn--->',hn.shape, hn) print('rnn模型--->', rnn) # 程序运行效果如下: output---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434], [ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549], [-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]], grad_fn=<StackBackward0>) hn---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434], [ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549], [-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]], grad_fn=<StackBackward0>) rnn模型---> RNN(5, 6)# 输入数据长度发生变化 def dm_rnn_for_sequencelen(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 1) #A ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(20, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) #C # [20,3,5],[1,3,6] --->[20,3,6],[1,3,6] output, hn = rnn(input, h0) # print('output--->', output.shape) print('hn--->', hn.shape) print('rnn模型--->', rnn) # 程序运行效果如下: output---> torch.Size([20, 3, 6]) hn---> torch.Size([1, 3, 6]) rnn模型---> RNN(5, 6)def dm_run_for_hiddennum(): ''' 第一个参数:input_size(输入张量x的维度) 第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数) 第三个参数:num_layer(隐藏层的数量) ''' rnn = nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方? ''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(1, 3, 5) # B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(2, 3, 6) # C output, hn = rnn(input, h0) # print('output-->', output.shape, output) print('hn-->', hn.shape, hn) print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11) # 结论:若只有一个隐藏次 output输出结果等于hn # 结论:如果有2个隐藏层,output的输出结果有2个,hn等于最后一个隐藏层 # 程序运行效果如下: output--> torch.Size([1, 3, 6]) tensor([[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244], [ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437], [ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]], grad_fn=<StackBackward0>) hn--> torch.Size([2, 3, 6]) tensor([[[ 0.4862, 0.6872, -0.0437, -0.7826, -0.7136, -0.5715], [ 0.8942, 0.4524, -0.1695, -0.5536, -0.4367, -0.3353], [ 0.5592, 0.0444, -0.8384, -0.5193, 0.7049, -0.0453]], [[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244], [ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437], [ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]], grad_fn=<StackBackward0>) rnn模型---> RNN(5, 6, num_layers=2)总结一下参数变化,这个地方小编用一个案例作为记忆手段:
-
每批次 5 句话(样本), batch_size = 5
-
每句话(样本) 32 个词语(特征), sequence_length = 32
-
输入张量维度 128 input_size = 128 一般是词向量的长度
-
隐藏层张量维度 256 hidden_size = 256 一般自己来定,通常是2的n次幂
-
隐藏层数量 1 num_layer 一般代表着经过几层循环网络层处理,信息是递进的
-
输入 (in) RNN层 输出 (out) ┌─────────┐ ┌─────────┐ ┌─────────┐ │ 32×5×128│ ───→ │ 128维 │ ─────→ │ 32×5×256│ └─────────┘ │ 256维 │ └─────────┘ │ layer=1 │ └─────────┘ ↑ 隐藏状态 (hn) ┌─────────┐ │ 1×5×256 │ └─────────┘ -
参数说明表格
变量 维度 含义 nn 128 256 1 输入大小=128,隐藏层大小=256,层数=1 in 32×5×128 特征数=32,样本=5,每个时间步输入128维 ho 1×5×256 5个样本 当前时间步的隐藏状态(1层,5个样本,256维) out 32×5×256 5个样本其中每个时间步的输出(用于下一个时间步或预测) hn 1×5×256 5个样本最后一个时间步的隐藏状态(用于后续序列初始化)
四、LSTM(长短期记忆网络)
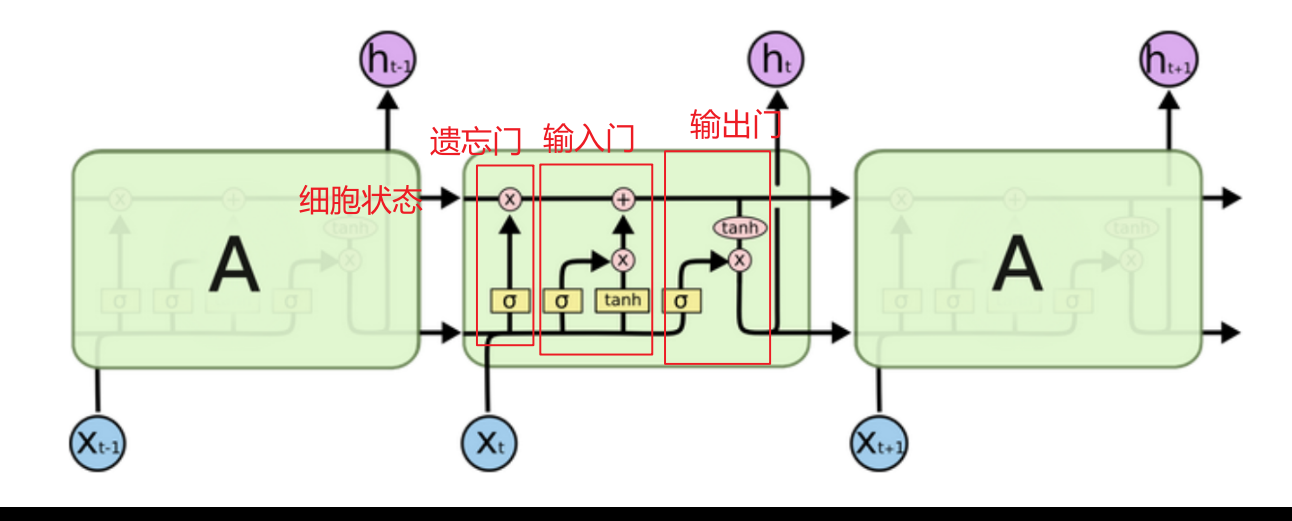
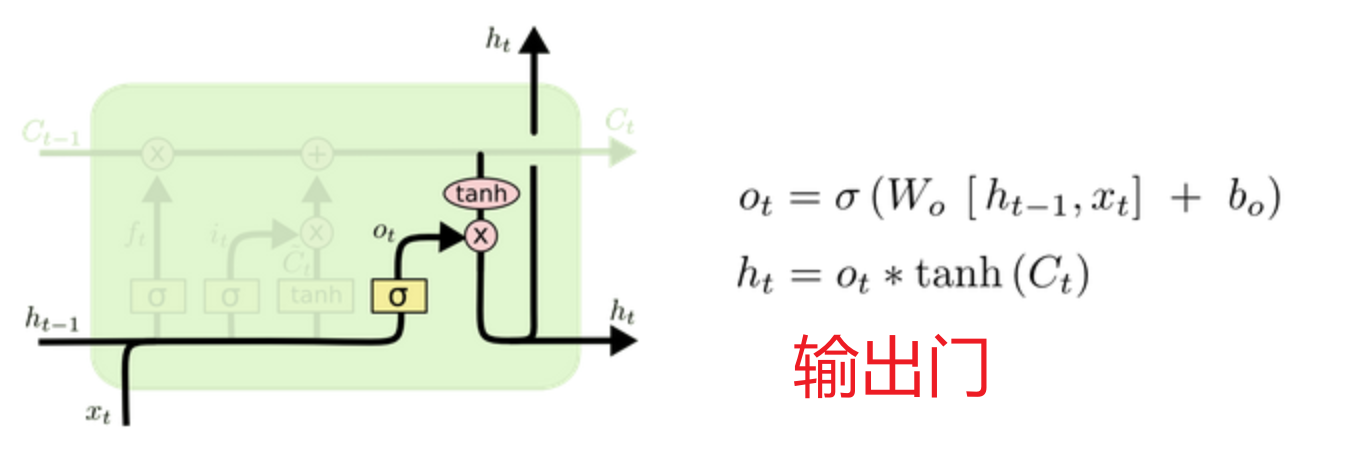
小编的整体理解:
LSTM又称长短时记忆,分为长时C(细胞状态)、短时ht(上一次的隐藏状态)
主要分为遗忘门、输入门、细胞状态、输出门四部分
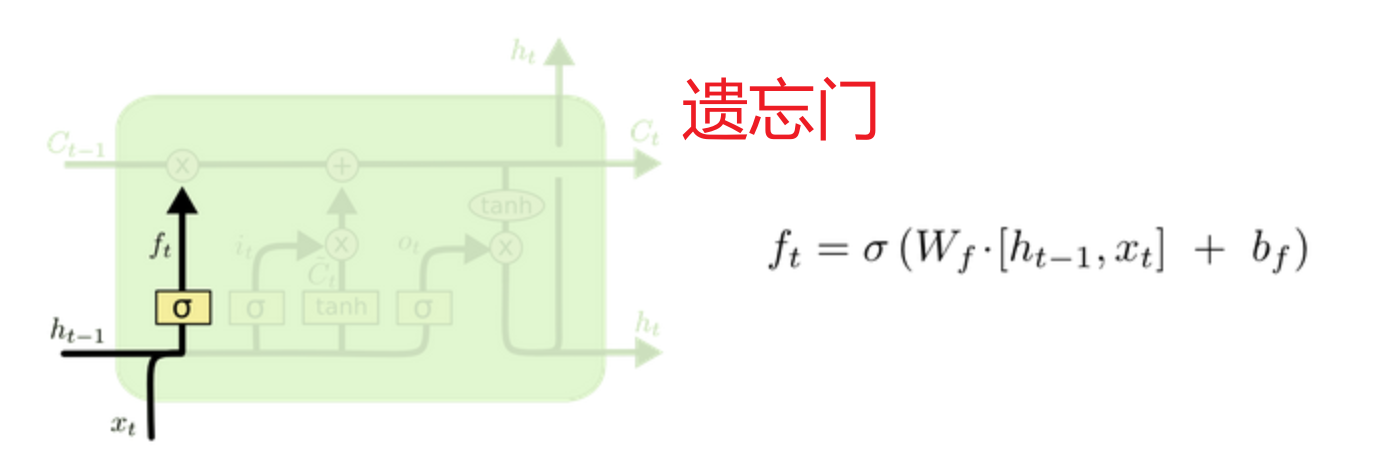
遗忘门:利用 上次隐藏状态和当前输入 加权求和的sigmoid激活函数当作门值(0,1] 过滤细胞状态(历史数据库),意义在于根据 本次输入和上次隐藏 的具体内容决定遗忘掉哪些数据
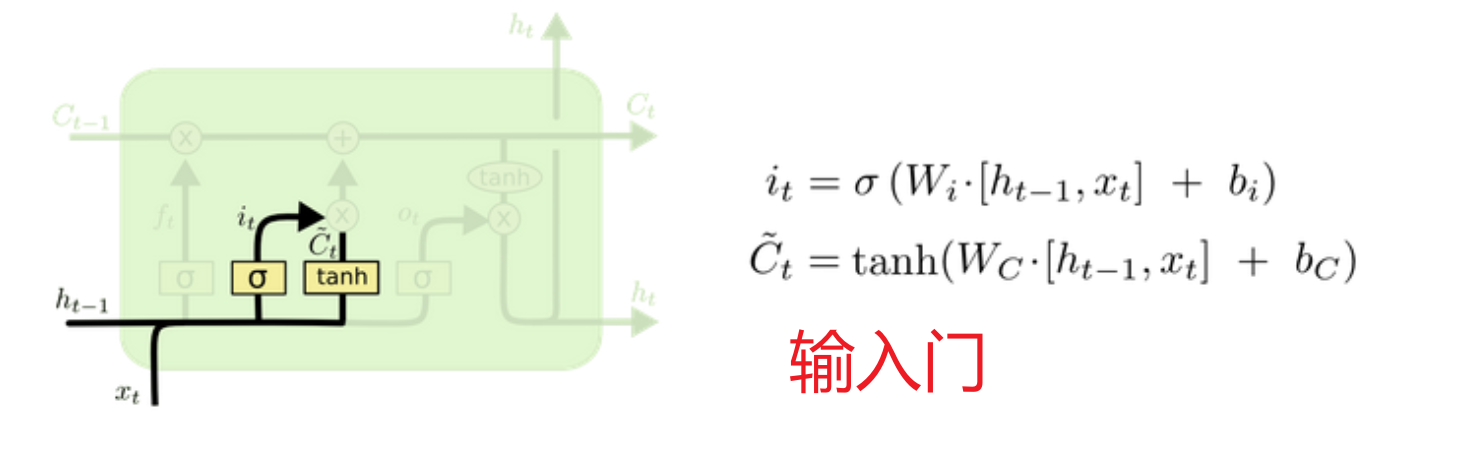
输入门:利用 上次隐藏状态和当前输入 加权求和的tanh激活函数(-1,1]决定留下什么数据当作输入,再利用sigmoid激活函数当作门值(0,1]过滤当前输入保留多少,意义在于根据 本次输入和上次隐藏 的具体内容决定留下哪些数据进入历史数据库
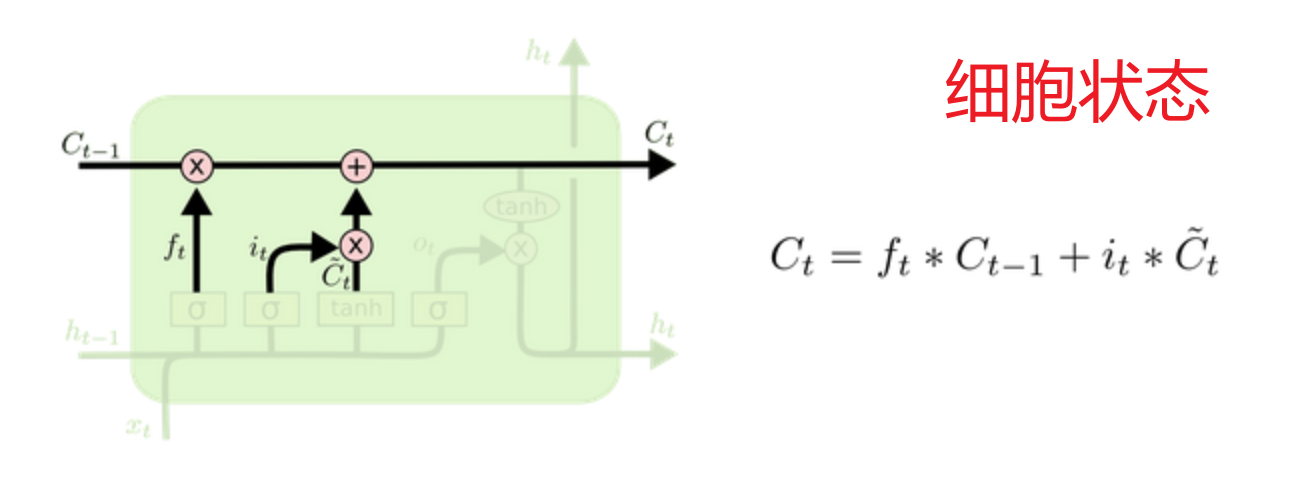
细胞状态:利用遗忘门过滤后的数据 + 输入门过滤后的数据 组合成实时的历史数据库
输出门:利用 细胞状态 数据加权求和的tanh激活函数(-1,1]决定留下什么数据当作本次隐藏,再利用上次隐藏 状态和当前输入加权求和的sigmoid激活函数当作门值(0,1]过滤当前输出保留多少,意义在于根据本次输入和上次隐藏的具体内容决定留下哪些数据当作本次隐藏
简短点说就是
长短时记忆主要分为四部分 遗忘门 输入门 输出门 细胞状态
遗忘门:根据最新输入的激活函数当作门值,决定遗忘掉哪些不重要的信息
输入门:根据最新输入的激活函数决定哪些数据纳入细胞状态
细胞状态:遗忘门过滤后的历史细胞信息 + 输入门过滤后的新信息
输出门:根据最新输入的激活函数和细胞状态的激活函数决定哪些数据当作本次隐藏状态
1. 模型结构
LSTM通过精心设计的门控机制来控制信息的流动,主要包括:
-
遗忘门:决定丢弃哪些信息
-
输入门:决定更新哪些新信息
-
细胞状态:长期记忆的载体
-
输出门:决定输出哪些信息
2. 模型构建要点
-
细胞状态(CtCt)贯穿整个序列,信息可以长期保存
-
三个门控单元协同工作,实现信息的精细化控制
3. 优点
-
相比传统RNN,能够有效捕捉长序列之间的语义关联
-
显著缓解梯度消失/爆炸问题
4. 缺点
-
内部结构复杂,参数量增加
-
训练效率较低,同等算力下比传统RNN慢
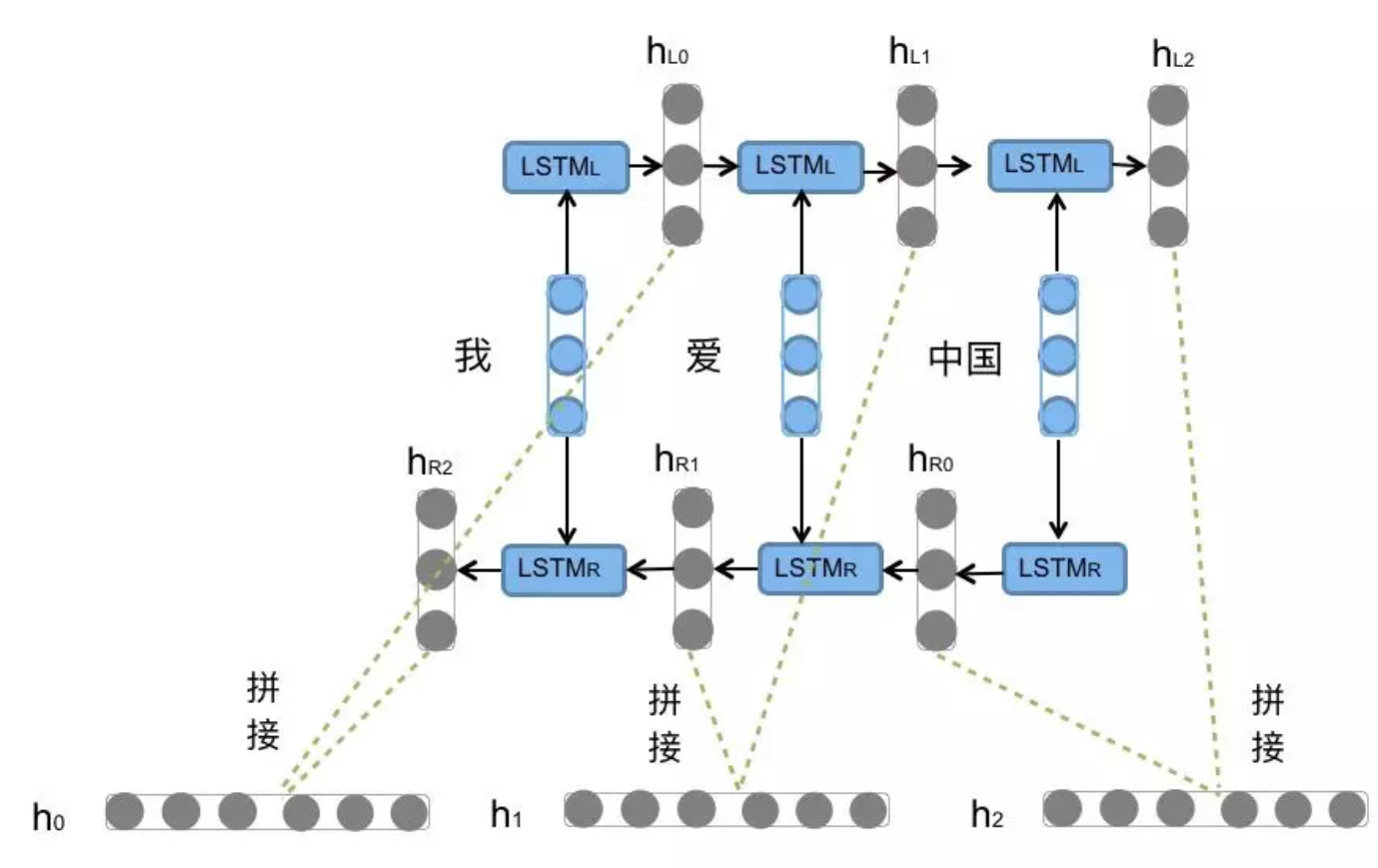
5. BI-LSTM(双向LSTM)
-
原理:将LSTM应用两次,方向相反(正向+反向)
-
输出:将两个方向的LSTM结果拼接
-
作用:能够同时捕捉序列的上文和下文信息
-
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
>>> import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> cn
tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],
[ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],
[ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],
[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],
[ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],
[-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],
grad_fn=<StackBackward>)
五、GRU(门控循环单元)
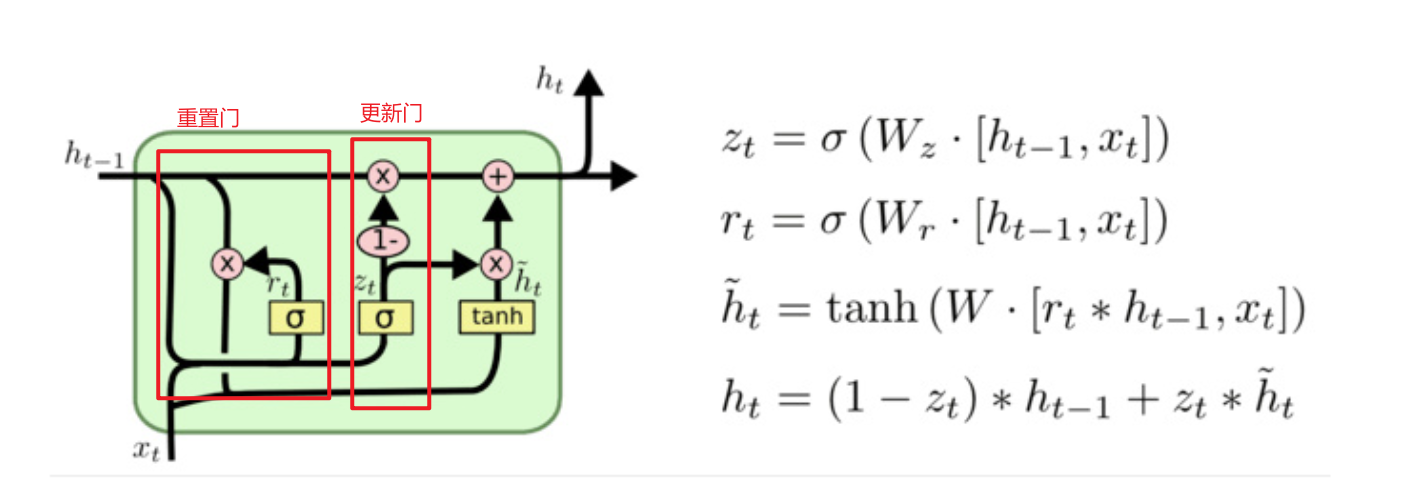
11将LSTM的隐藏状态和细胞状态合并在一起,减少了参数的运算,提高了运算效率
将LSTM的遗忘门和输入们合并为更新门,同时引入重置门
主要分为 重置门和 更新门
重置门:决定 历史信息 和新信息的结合
更新门:决定 历史信息的过滤 和 新信息的加入
1. 模型结构
GRU是LSTM的简化版本,将遗忘门和输入门合并为更新门,同时引入重置门:
-
重置门:决定如何将新的输入信息与之前的记忆结合
-
更新门:决定保留多少历史信息和加入多少新信息
2. 模型构建要点
-
结构比LSTM更简单,只有两个门
-
没有独立的细胞状态,隐藏状态直接传递信息
3. 优点
-
与LSTM效果相当,同样能有效抑制梯度消失/爆炸
-
计算复杂度比LSTM低,训练效率更高
4. 缺点
-
仍然不能完全解决梯度消失问题
-
不可并行计算(RNN系列的通病)
-
随着数据量和模型规模增大,成为发展的关键瓶颈
5. BI-GRU(双向GRU)
-
原理:与Bi-LSTM类似,将GRU应用两次(正向+反向)
-
输出:拼接两个方向的GRU结果
-
>>> import torch >>> import torch.nn as nn >>> rnn = nn.GRU(5, 6, 2) >>> input = torch.randn(1, 3, 5) >>> h0 = torch.randn(2, 3, 6) >>> output, hn = rnn(input, h0) >>> output tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460], [-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173], [-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]], grad_fn=<StackBackward>) >>> hn tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338], [-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591], [ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]], [[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460], [-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173], [-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]], grad_fn=<StackBackward>)
六、总结对比
| 模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 传统RNN | 结构简单,参数量少,训练快 | 长序列梯度消失/爆炸 | 短序列任务 |
| LSTM | 长序列建模能力强,缓解梯度问题 | 结构复杂,训练慢 | 需要长期依赖的任务(机器翻译、文本生成) |
| GRU | 效果与LSTM相当,效率更高 | 仍存在梯度问题,不可并行 | 平衡效果和效率的中长序列任务 |
| 双向变体 | 同时捕捉上下文信息 | 计算量翻倍 | 需要完整上下文的任务(阅读理解、情感分析) |
七、综合案例RNN人名分类器
1 任务目的:
目的: 给定一个人名,来判定这个人名属于哪个国家
典型的文本分类任务: 18分类---多分类任务
2 数据格式
注意:两列数据,第一列是人名,第二列是国家类别,中间用制表符号"\t"隔开
Ang Chinese
AuYong Chinese
Yuasa Japanese
Yuhara Japanese
Yunokawa Japanese
3. 任务实现流程
1. 获取数据:案例中是直接给定的
2. 数据预处理: 脏数据清洗、数据格式转换、数据源Dataset的构造、数据迭代器Dataloader的构造
3. 模型搭建: RNN、LSTM、GRU一系列模型
4. 模型训练和评估(测试)
5. 模型上线---API接口
4 数据预处理
4.1读取txt文档数据
将文档里面的数据读取到内存中,实际上我们做了一个操作: 将人名存放到一个列表中,国家类别存放到一个列表中
4.2 构建自己的数据源DataSet
使用Pytorch框架,一般遵从一个规矩:使用DataSet方法构造数据源,来让模型进行使用
构造数据源的过程中:必须继承torch.utils.data.Dataset类,必须构造两个魔法方法:__len__(), __getitem__()
__len__(): 一般返回的是样本的总个数,我们可以直接len(dataset对象)直接就可以获得结果
__getitem__(): 可以根据某个索引取出样本值,我们可以直接用dataset对象[index]来直接获得结果
4.3 构建数据源Dataloader
为了将Dataset我们上一步构建的数据源,进行再次封装,变成一个迭代器,可以进行for循环,而且,可以自动为我们dataset里面的数据进行增维(bath_size),也可以随机打乱我们的取值顺序
5 模型搭建
5.1 搭建RNN模型
RNN模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。
5.2 搭建LSTM模型
LSTM模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。
5.3 搭建GRU模型
GRU模型在实例化的时候,默认batch_first=False,因此,需要小心输入数据的形状
因为: dataloader返回的结果x---》shape--〉[batch_size, seq_len, input_size], 我们的代码是batch_first=True,这样做的目的,可以直接承接x的输入。
6 模型训练
1.获取数据
2.构建数据源Dataset
3.构建数据迭代器Dataloader
4.加载自定义的模型
5.实例化损失函数对象
6.实例化优化器对象
7.定义打印日志参数
8.开始训练
8.1 实现外层大循环epoch
(可以在这构建数据迭代器Dataloader)
8.2 内部遍历数据迭代球dataloader
8.3 将数据送入模型得到输出结果
8.4 计算损失
8.5 梯度清零: optimizer.zero_grad()
8.6 反向传播: loss.backward()
8.7 参数更新(梯度更新): optimizer.step()
8.8 打印训练日志
9. 保存模型: torch.save(model.state_dict(), "model_path")
7 模型预测
1.获取数据
2.数据预处理:将数据转化one-hot编码
3.实例化模型
4.加载模型训练好的参数: model.load_state_dict(torch.load("model_path"))
5.with torch.no_grad():
6.将数据送入模型进行预测(注意:张量的形状变换)# -*- coding:utf-8 -*-
# 导入torch工具
import json
import matplotlib.pyplot as plt
import torch
# 导入nn准备构建模型
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 导入torch的数据源 数据迭代器工具包
from torch.utils.data import Dataset, DataLoader
# 用于获得常见字母及字符规范化
import string
# 导入时间工具包
import time
# 进度条
from tqdm import tqdm
# todo: 1.获取常用的字符数量:也就是one-hot编码的去重之后的词汇的总量n
all_letters = string.ascii_letters + " ,;.'"
# print(f'all_letters-->{all_letters}')
n_letters = len(all_letters)
print(f'当前字符的总量--》{n_letters}')
# todo:2. 获取国家名种类数
categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese',
'French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 国家名个数
categorynum = len(categorys)
print('国家总数--->', categorynum)
# todo:3. 读取数据到内存
def read_data(filepath):
# 3.1 定义两个空列表my_list_x(存储人名), my_list_y(存储国家类型)
my_list_x , my_list_y = [], []
# 3.2 读取文件内容
with open(filepath, encoding='utf-8') as fr:
for line in fr.readlines():
if len(line) <= 5:
continue
x, y = line.strip().split('\t')
my_list_x.append(x)
my_list_y.append(y)
return my_list_x, my_list_y
# todo:4.构建Dataset类
class NameDataset(Dataset):
def __init__(self, my_list_x, my_list_y):
super().__init__()
# 获取x
self.my_list_x = my_list_x
# 获取y
self.my_list_y = my_list_y
# 获取样本的数量
self.sample_len = len(my_list_x)
# 获取样本的数量
def __len__(self):
return self.sample_len
# 根据索引取出元素item:代表索引
def __getitem__(self, item):
# 1.对异常索引进行修正
item = min(max(item, 0), self.sample_len-1)
# 2.根据索引取出样本
x = self.my_list_x[item]
# print(f'x-->{x}')
y = self.my_list_y[item]
# print(f'y--->{y}')
# 3.将人名变成one-hot编码的张量形式
# 3.1 初始化全零的张量 #(3, 57)
tensor_x = torch.zeros(len(x), n_letters)
# print(f'tensor_x-->{tensor_x}')
# 3.2 遍历人名的每一个字母,进行one-hot编码的赋值
for idx, letter in enumerate(x):
# print(f'idx--》{idx}')
# print(f'letter--》{letter}')
tensor_x[idx][all_letters.find(letter)] = 1
# print(f'tensor_x--》{tensor_x}')
# print(f'tensor_x修改之后的:-->{tensor_x}')
tensor_y = torch.tensor(categorys.index(y), dtype=torch.long)
return tensor_x, tensor_y
# todo: 5.实例化dataloader对象
def get_dataloader():
# 读取文档数据
my_list_x, my_list_y = read_data(filepath='./data/name_classfication.txt')
# 获取dataset对象
name_dataset = NameDataset(my_list_x, my_list_y)
# 封装dataset得到dataloader对象: 会对数据进行增加维度
train_dataloader = DataLoader(dataset=name_dataset,
batch_size=1,
shuffle=True)
return train_dataloader
# todo: 6.定义RNN层
class NameRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:代表输入数据的词嵌入维度
self.input_size = input_size
# hidden_size:代表RNN模型输出的维度(隐藏层输出维度)
self.hidden_size = hidden_size
# output_size: 输出层类别的总个数:18个国家
self.output_size = output_size
# num_layers:RNN隐藏层的个数
self.num_layers = num_layers
# 定义RNN层:(默认情况下:batch_first为False)
self.rnn = nn.RNN(self.input_size, self.hidden_size, num_layers)
# 定义输出层
self.out = nn.Linear(self.hidden_size, self.output_size)
# 定义logSoftmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x, h0):
# print(f'x--->{x.shape}')
# print(f'h0--->{h0.shape}')
# x:代表输入的原始数据维度[seq_len, input_size]
# h0:代表初始化的值,[num_layers, batch_size, hidden_size]-->[1, 1, 128]
# x需要先升维:[seq_len, input_size]--》[seq_len, batch_size, input_size]
x1 = torch.unsqueeze(x, dim=1) # x.unsqueeze(dim=1)
# print(f'x1-->{x1.shape}')
# 将x1和h0送入RNN模型
output, hn = self.rnn(x1, h0)
# print(f'output--》{output.shape}')
# print(f'hn--》{hn.shape}')
# 获取最后一个单词的隐藏层张量来代表整个句子(人名)的语意
# 这里可以直接用hn代替
temp = output[-1] # [1, 128]
# 将temp送入输出层:result-->[1, 18]
result = self.out(temp)
return self.softmax(result), hn
def inithidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)
# tood: 7.定义LSTM层
class NameLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:代表输入数据的词嵌入维度
self.input_size = input_size
# hidden_size:代表LSTM模型输出的维度(隐藏层输出维度)
self.hidden_size = hidden_size
# output_size: 输出层类别的总个数:18个国家
self.output_size = output_size
# num_layers:LSTM隐藏层的个数
self.num_layers = num_layers
# 定义LSTM层:(默认情况下:batch_first为False)
self.lstm = nn.LSTM(self.input_size, self.hidden_size, num_layers)
# 定义输出层
self.out = nn.Linear(self.hidden_size, self.output_size)
# 定义logSoftmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x0, h0, c0):
# x0:代表输入的原始数据维度[seq_len, input_size]-->[5, 57]
# h0,c0:代表初始化的值,[num_layers, batch_size, hidden_size]-->[1, 1, 128]
# x0需要先升维:[seq_len, input_size]--》[seq_len, batch_size, input_size]
x1 = torch.unsqueeze(x0, dim=1)
# 把x0,h0,c0送入lstm模型output-->[5, 1, 128]
output, (hn, cn) = self.lstm(x1, (h0, c0))
# 取出最后一个单词的对应的向量output[-1]-->[1, 128]
temp = output[-1]
# 将temp送入输出层:result-->[1, 18]
result = self.out(temp)
return self.softmax(result), hn, cn
def inithidden(self):
h0 = torch.zeros(self.num_layers, 1, self.hidden_size)
c0 = torch.zeros(self.num_layers, 1, self.hidden_size)
return h0, c0
# todo: 8.定义GRU层
class NameGRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
# input_size:代表输入数据的词嵌入维度
self.input_size = input_size
# hidden_size:代表RNN模型输出的维度(隐藏层输出维度)
self.hidden_size = hidden_size
# output_size: 输出层类别的总个数:18个国家
self.output_size = output_size
# num_layers:RNN隐藏层的个数
self.num_layers = num_layers
# 定义GRU层:(默认情况下:batch_first为False)
self.gru = nn.GRU(self.input_size, self.hidden_size, num_layers)
# 定义输出层
self.out = nn.Linear(self.hidden_size, self.output_size)
# 定义logSoftmax层
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, x, h0):
# print(f'x--->{x.shape}')
# print(f'h0--->{h0.shape}')
# x:代表输入的原始数据维度[seq_len, input_size]
# h0:代表初始化的值,[num_layers, batch_size, hidden_size]-->[1, 1, 128]
# x需要先升维:[seq_len, input_size]--》[seq_len, batch_size, input_size]
x1 = torch.unsqueeze(x, dim=1) # x.unsqueeze(dim=1)
# print(f'x1-->{x1.shape}')
# 将x1和h0送入GRU模型
output, hn = self.gru(x1, h0)
# print(f'output--》{output.shape}')
# print(f'hn--》{hn.shape}')
# 获取最后一个单词的隐藏层张量来代表整个句子(人名)的语意
# 这里可以直接用hn代替
temp = output[-1] # [1, 128]
# 将temp送入输出层:result-->[1, 18]
result = self.out(temp)
return self.softmax(result), hn
def inithidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)
mylr = 1e-3
epochs = 1
# todo: 9 定义RNN训练的函数
def train_rnn():
# 1.读取文档数据
my_list_x, my_list_y = read_data(filepath='./data/name_classfication.txt')
# 2.获取dataset对象
name_dataset = NameDataset(my_list_x, my_list_y)
# 3.实例化模型
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameRNN(input_size, hidden_size, output_size)
# 4.实例化损失函数对象
cross_entropy = nn.NLLLoss()
# 5.实例化优化器对象
adam = optim.Adam(rnn_model.parameters(), lr=mylr)
# 6. 定义训练模型的打印日志的参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练的样本的总个数
total_loss = 0.0 # 已经训练的样本的损失之和
total_loss_list = [] # 每隔100个样本计算一下平均损失,画图
total_num_acc = 0 # 已经训练的样本中预测正确的样本的个数
total_acc_list = [] # 每隔100个样本计算一下平均准确率,画图
# 6.开始模型的训练
# 开始外部epoch的迭代
for epoch_idx in range(epochs):
# 实例化dataloader
train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)
# 开始内部数据的迭代
for idx, (x, y) in enumerate(tqdm(train_dataloader)):
# print(f'x--》{x.shape}')
# print(f'y--》{y.shape}')
# # 将数据送入模型
h0 = rnn_model.inithidden()
output, hn = rnn_model(x[0], h0)
# print(f'output-->{output}')
# print(f'y-->{y}')
# 计算损失:output.shape-->[1, 18];y.shape-->[1]
my_loss = cross_entropy(output, y)
# print(f'my_loss--》{my_loss}')
# 梯度清零
adam.zero_grad()
# 反向传播: 计算梯度
my_loss.backward()
# 梯度更新
adam.step()
# 打印日志参数
# 获取已经训练的样本的总数
total_iter_num += 1
# 获取已经训练的样本的总损失
total_loss = total_loss + my_loss.item()
# 获取已经训练的样本中预测正确的总个数
# print(f'output--》{output}')
# torch.argmax(output)取出概率值最大值对应的索引
pred_idx = 1 if torch.argmax(output).item() == y.item() else 0
# print(f'pred_idx-->{pred_idx}')
total_num_acc = total_num_acc + pred_idx
# 每100次训练 求一次平均损失 平均准确率
if total_iter_num % 100 == 0:
# 保留平均损失
avg_loss = total_loss / total_iter_num
total_loss_list.append(avg_loss)
# 保留平均准确率
avg_acc = total_num_acc / total_iter_num
total_acc_list.append(avg_acc)
# 每隔2000步,打印日志
if total_iter_num % 2000 == 0:
temp_loss = total_loss / total_iter_num
temp_acc = total_num_acc / total_iter_num
print('轮次:%d, 损失:%.6f, 时间:%d,准确率:%.3f' %(epoch_idx+1, temp_loss, time.time() - start_time, temp_acc))
# 每轮都保存一个模型
torch.save(rnn_model.state_dict(), './save_model/ai_rnn_%d.bin'%(epoch_idx+1))
# 7.计算训练的总时间
all_time = time.time() - start_time
# 8.将训练的结果进行保存
dict1 = {"total_loss_list": total_loss_list,
"all_time": all_time,
"total_acc_list": total_acc_list}
with open('rnn_result.json', 'w') as fw:
fw.write(json.dumps(dict1))
# return total_loss_list, all_time, total_acc_list
# todo: 10 定义LSTM训练的函数
def train_lstm():
# 1.读取文档数据
my_list_x, my_list_y = read_data(filepath='./data/name_classfication.txt')
# 2.获取dataset对象
name_dataset = NameDataset(my_list_x, my_list_y)
# 3.实例化模型
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameLSTM(input_size, hidden_size, output_size)
# 4.实例化损失函数对象
cross_entropy = nn.NLLLoss()
# 5.实例化优化器对象
adam = optim.Adam(rnn_model.parameters(), lr=mylr)
# 6. 定义训练模型的打印日志的参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练的样本的总个数
total_loss = 0.0 # 已经训练的样本的损失之和
total_loss_list = [] # 每隔100个样本计算一下平均损失,画图
total_num_acc = 0 # 已经训练的样本中预测正确的样本的个数
total_acc_list = [] # 每隔100个样本计算一下平均准确率,画图
# 6.开始模型的训练
# 开始外部epoch的迭代
for epoch_idx in range(epochs):
# 实例化dataloader
train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)
# 开始内部数据的迭代
for idx, (x, y) in enumerate(tqdm(train_dataloader)):
# print(f'x--》{x.shape}')
# print(f'y--》{y.shape}')
# # 将数据送入模型
h0, c0 = rnn_model.inithidden()
output, hn, cn = rnn_model(x[0], h0, c0)
# 计算损失:output.shape-->[1, 18];y.shape-->[1]
my_loss = cross_entropy(output, y)
# print(f'my_loss--》{my_loss}')
# 梯度清零
adam.zero_grad()
# 反向传播: 计算梯度
my_loss.backward()
# 梯度更新
adam.step()
# 打印日志参数
# 获取已经训练的样本的总数
total_iter_num += 1
# 获取已经训练的样本的总损失
total_loss = total_loss + my_loss.item()
# 获取已经训练的样本中预测正确的总个数
# print(f'output--》{output}')
# torch.argmax(output)取出概率值最大值对应的索引
pred_idx = 1 if torch.argmax(output).item() == y.item() else 0
# print(f'pred_idx-->{pred_idx}')
total_num_acc = total_num_acc + pred_idx
# 每100次训练 求一次平均损失 平均准确率
if total_iter_num % 100 == 0:
# 保留平均损失
avg_loss = total_loss / total_iter_num
total_loss_list.append(avg_loss)
# 保留平均准确率
avg_acc = total_num_acc / total_iter_num
total_acc_list.append(avg_acc)
# 每隔2000步,打印日志
if total_iter_num % 2000 == 0:
temp_loss = total_loss / total_iter_num
temp_acc = total_num_acc / total_iter_num
print('轮次:%d, 损失:%.6f, 时间:%d,准确率:%.3f' %(epoch_idx+1, temp_loss, time.time() - start_time, temp_acc))
# 每轮都保存一个模型
torch.save(rnn_model.state_dict(), './save_model/ai_lstm_%d.bin'%(epoch_idx+1))
# 7.计算训练的总时间
all_time = time.time() - start_time
# 8.将训练的结果进行保存
dict1 = {"total_loss_list": total_loss_list,
"all_time": all_time,
"total_acc_list": total_acc_list}
with open('lstm_result.json', 'w') as fw:
fw.write(json.dumps(dict1))
# return total_loss_list, all_time, total_acc_list
# todo: 11 定义GRU训练的函数
def train_gru():
# 1.读取文档数据
my_list_x, my_list_y = read_data(filepath='./data/name_classfication.txt')
# 2.获取dataset对象
name_dataset = NameDataset(my_list_x, my_list_y)
# 3.实例化模型
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameGRU(input_size, hidden_size, output_size)
# 4.实例化损失函数对象
cross_entropy = nn.NLLLoss()
# 5.实例化优化器对象
adam = optim.Adam(rnn_model.parameters(), lr=mylr)
# 6. 定义训练模型的打印日志的参数
start_time = time.time() # 开始的时间
total_iter_num = 0 # 已经训练的样本的总个数
total_loss = 0.0 # 已经训练的样本的损失之和
total_loss_list = [] # 每隔100个样本计算一下平均损失,画图
total_num_acc = 0 # 已经训练的样本中预测正确的样本的个数
total_acc_list = [] # 每隔100个样本计算一下平均准确率,画图
# 6.开始模型的训练
# 开始外部epoch的迭代
for epoch_idx in range(epochs):
# 实例化dataloader
train_dataloader = DataLoader(dataset=name_dataset, batch_size=1, shuffle=True)
# 开始内部数据的迭代
for idx, (x, y) in enumerate(tqdm(train_dataloader)):
# print(f'x--》{x.shape}')
# print(f'y--》{y.shape}')
# # 将数据送入模型
h0 = rnn_model.inithidden()
output, hn = rnn_model(x[0], h0)
# print(f'output-->{output}')
# print(f'y-->{y}')
# 计算损失:output.shape-->[1, 18];y.shape-->[1]
my_loss = cross_entropy(output, y)
# print(f'my_loss--》{my_loss}')
# 梯度清零
adam.zero_grad()
# 反向传播: 计算梯度
my_loss.backward()
# 梯度更新
adam.step()
# 打印日志参数
# 获取已经训练的样本的总数
total_iter_num += 1
# 获取已经训练的样本的总损失
total_loss = total_loss + my_loss.item()
# 获取已经训练的样本中预测正确的总个数
# print(f'output--》{output}')
# torch.argmax(output)取出概率值最大值对应的索引
pred_idx = 1 if torch.argmax(output).item() == y.item() else 0
# print(f'pred_idx-->{pred_idx}')
total_num_acc = total_num_acc + pred_idx
# 每100次训练 求一次平均损失 平均准确率
if total_iter_num % 100 == 0:
# 保留平均损失
avg_loss = total_loss / total_iter_num
total_loss_list.append(avg_loss)
# 保留平均准确率
avg_acc = total_num_acc / total_iter_num
total_acc_list.append(avg_acc)
# 每隔2000步,打印日志
if total_iter_num % 2000 == 0:
temp_loss = total_loss / total_iter_num
temp_acc = total_num_acc / total_iter_num
print('轮次:%d, 损失:%.6f, 时间:%d,准确率:%.3f' %(epoch_idx+1, temp_loss, time.time() - start_time, temp_acc))
# 每轮都保存一个模型
torch.save(rnn_model.state_dict(), './save_model/ai_gru_%d.bin'%(epoch_idx+1))
# 7.计算训练的总时间
all_time = time.time() - start_time
# 8.将训练的结果进行保存
dict1 = {"total_loss_list": total_loss_list,
"all_time": all_time,
"total_acc_list": total_acc_list}
with open('gru_result.json', 'w') as fw:
fw.write(json.dumps(dict1))
# return total_loss_list, all_time, total_acc_list
# todo:12 绘图对比不同模型的性能
def compare_rnns():
# 1.读取rnn模型的训练结果
with open('rnn_result.json', 'r')as fr:
rnn_dict = json.loads(fr.read())
# print(f'rnn_dict--->{rnn_dict}')
# print(f'rnn_dict--->{type(rnn_dict)}')
# 2.读取lstm模型的训练结果
with open('lstm_result.json', 'r') as fr:
lstm_dict = json.loads(fr.read())
# 3.读取gru模型的训练结果
with open('gru_result.json', 'r') as fr:
gru_dict = json.loads(fr.read())
# 4. 绘图
# 4.1 绘制损失对比曲线图
plt.figure(0)
plt.plot(rnn_dict["total_loss_list"], label='RNN')
plt.plot(lstm_dict["total_loss_list"], label='LSTM', color='red')
plt.plot(gru_dict["total_loss_list"], label='GRU', color='blue')
plt.legend(loc='upper left')
plt.savefig('./ai_avg_loss.png')
plt.show()
# 4.2 绘制柱状图对比时间
plt.figure(1)
x_data = ["RNN", "LSTM", "GRU"]
y_data = [rnn_dict["all_time"], lstm_dict["all_time"], gru_dict["all_time"]]
plt.bar(range(len(x_data)), y_data, tick_label=x_data)
plt.savefig("./ai_time.png")
plt.show()
# 4.3 绘制准确率对比图
plt.figure(2)
plt.plot(rnn_dict["total_acc_list"], label='RNN')
plt.plot(lstm_dict["total_acc_list"], label='LSTM', color='red')
plt.plot(gru_dict["total_acc_list"], label='GRU', color='blue')
plt.legend(loc='upper left')
plt.savefig('./ai_avg_acc.png')
plt.show()
def test_dataset():
# 读取文档数据
my_list_x, my_list_y = read_data(filepath='./data/name_classfication.txt')
# 获取dataset对象
name_dataset = NameDataset(my_list_x, my_list_y)
print(len(name_dataset))
# print(name_dataset.__len__())
tensor_x, tensor_y = name_dataset[0]
print(f'tensor_x--》{tensor_x}')
print(f'tensor_y--》{tensor_y}')
# todo:13.定义将人名转换为向量的函数
def name2tensor(x):
'''
将x转换成one-hot编码的向量形式
:param x: "bai"
:return:[[0,1,...], [..], [..]]
'''
# 1 初始化全零的张量 #(3, 57)
tensor_x = torch.zeros(len(x), n_letters)
# print(f'tensor_x-->{tensor_x}')
# 2 遍历人名的每一个字母,进行one-hot编码的赋值
for idx, letter in enumerate(x):
# print(f'idx--》{idx}')
# print(f'letter--》{letter}')
tensor_x[idx][all_letters.find(letter)] = 1
# print(f'tensor_x--》{tensor_x}')
return tensor_x
# todo: 14.定义rnn模型的预测函数
def rnn_predict(x):
# 1.将x--》人名转换为向量
tensor_x = name2tensor(x)
# 2. 实例化模型并加载训练好的模型参数
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameRNN(input_size, hidden_size, output_size)
rnn_model.load_state_dict(torch.load('./save_model/ai_rnn_1.bin'))
# 3. 预测
with torch.no_grad():
# 将数据送入模型
h0 = rnn_model.inithidden()
output, hn = rnn_model(tensor_x, h0)
print(f'output--》{output}')
# 取出预测结果中topk3
topv, topi = torch.topk(output, k=3, dim=1)
print(f'topv--》{topv}')
print(f'topi--》{topi}')
print(f'rnn预测的结果')
for i in range(3):
tempv = topv[0][i]
tempi = topi[0][i]
str_class = categorys[tempi]
print(f'当前的人名是:{x}, 预测值是:{tempv:.2f}, 预测真实国家是:{str_class}')
# todo: 15.定义lstm模型的预测函数
def lstm_predict(x):
# 1.将x--》人名转换为向量
tensor_x = name2tensor(x)
# 2. 实例化模型并加载训练好的模型参数
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameLSTM(input_size, hidden_size, output_size)
rnn_model.load_state_dict(torch.load('./save_model/ai_lstm_1.bin'))
# 3. 预测
with torch.no_grad():
# 将数据送入模型
h0, c0 = rnn_model.inithidden()
output, hn, cn = rnn_model(tensor_x, h0, c0)
print(f'output--》{output}')
# 取出预测结果中topk3
topv, topi = torch.topk(output, k=3, dim=1)
print(f'topv--》{topv}')
print(f'topi--》{topi}')
print(f'rnn预测的结果')
for i in range(3):
tempv = topv[0][i]
tempi = topi[0][i]
str_class = categorys[tempi]
print(f'当前的人名是:{x}, 预测值是:{tempv:.2f}, 预测真实国家是:{str_class}')
# todo: 16.定义gru模型的预测函数
def gru_predict(x):
# 1.将x--》人名转换为向量
tensor_x = name2tensor(x)
# 2. 实例化模型并加载训练好的模型参数
input_size = 57
hidden_size = 128
output_size = 18
rnn_model = NameGRU(input_size, hidden_size, output_size)
rnn_model.load_state_dict(torch.load('./save_model/ai_gru_1.bin'))
# 3. 预测
with torch.no_grad():
# 将数据送入模型
h0 = rnn_model.inithidden()
output, hn = rnn_model(tensor_x, h0)
print(f'output--》{output}')
# 取出预测结果中topk3
topv, topi = torch.topk(output, k=3, dim=1)
print(f'topv--》{topv}')
print(f'topi--》{topi}')
print(f'rnn预测的结果')
for i in range(3):
tempv = topv[0][i]
tempi = topi[0][i]
str_class = categorys[tempi]
print(f'当前的人名是:{x}, 预测值是:{tempv:.2f}, 预测真实国家是:{str_class}')
if __name__ == '__main__':
# train_dataloader = get_dataloader()
# model = NameRNN(input_size, hidden_size, output_size)
# # model = NameLSTM(input_size, hidden_size, output_size)
# model = NameGRU(input_size, hidden_size, output_size)
# print(model)
# for x, y in train_dataloader:
# # x.shape--》[batch_size, seq_len, input_size],因为batch_size=1
# h0 = model.inithidden()
# output, hn = model(x[0], h0)
# print(f'output--》{output.shape}')
# print(f'hn--》{hn.shape}')
# break
# train_rnn()
# train_lstm()
# train_gru()
# compare_rnns()
# result = name2tensor(x="bai")
# print(result)
rnn_predict(x="zhang")
print('*'*80)
lstm_predict(x="zhang")
print('*'*80)
gru_predict(x="zhang")
未来展望:RNN系列模型的串行计算特性限制了其在超大规模数据和模型上的发展。随着Transformer等并行化架构的兴起,RNN在NLP领域的统治地位逐渐被取代,但在某些特定场景(如小规模序列数据、实时性要求高的任务)中,GRU/LSTM仍然是极具竞争力的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 29
29 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)