CVPR 2026 | GS-CLIP:3D几何先验+双流视觉融合,零样本工业缺陷检测新SOTA,四大3D工业数据集全面领先!

论文标题:GS-CLIP: Zero-shot 3D Anomaly Detection by Geometry-Aware Prompt and Synergistic View Representation Learning
作者:Zehao Deng, An Liu, Yan Wang
机构:苏州大学计算机科学与技术学院、清华大学智能产业研究院(AIR)
论文编号:arXiv: 2602.19206v2
代码开源:https://github.com/zhushengxinyue/GS-CLIP
导读:
现有零样本3D异常检测方法将点云投影为2D图像后借助CLIP进行检测,但投影丢失了关键的几何细节,且仅依赖单一视觉模态,检测能力受限。GS-CLIP 提出"几何感知提示学习 + 协同双流视觉表征"两阶段框架:第一阶段从3D点云中提炼全局形状上下文和局部缺陷信息注入文本提示;第二阶段让渲染图和深度图双流并行处理并深度融合。在 MVTec3D-AD、Real3D-AD、Eyecandies、Anomaly-ShapeNet 四大数据集上全面超越 PointAD(NeurIPS'24),O-AUROC 平均提升 1.8%,P-PRO 平均提升 2.5%。
一、问题出在哪?两大瓶颈制约零样本3D异常检测
3D异常检测是工业制造中的核心质检环节。传统无监督方法需要大量目标类别的正常样本进行训练,但在实际工业场景中,商业机密和数据隐私往往使得采集足够训练数据变得极为困难。因此,零样本3D异常检测(ZS3DAD)应运而生——在辅助数据上训练,直接迁移到从未见过的目标类别上检测异常。
当前主流方法的思路是:将3D点云投影为2D图像,借助 CLIP 强大的视觉-语言对齐能力来识别异常。但这条技术路线存在两个根本性瓶颈:
-
瓶颈一:3D几何结构感知缺失
3D到2D的投影本质上是有损压缩——立体结构被压扁成平面像素,关键的几何细节不可避免地被丢弃。模型学到的不是异常的物理几何形态,而只是它们在2D图像上的"影子"。
当某个角度下几何异常的视觉特征不明显时,这种间接检测范式就会失效。
举个例子:一个饼干表面的凹坑,从正上方看只是一个浅浅的阴影,模型很容易漏检。但如果能直接"感知"到3D点云中这个区域的深度突变,检测就会准确得多。
-
瓶颈二:视觉信息利用不充分
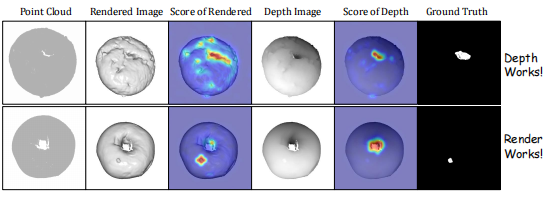
当前方法通常只依赖单一类型的2D表示(渲染图或深度图),但这两种图各有明显的优缺点:
| 表示类型 | 优势 | 劣势 |
| 渲染图 | 纹理和外观细节丰富,擅长捕捉表面划痕、污渍 | 对光照和渲染质量敏感可能引入伪阴影干扰 |
| 深度图 | 直接反馈几何结构,不受光照影响 | 无法捕捉深度变化极小的缺陷(如轻微突起) |
论文用了一个非常直观的对比来说明:
-
饼干表面的凹坑:深度图能清晰显示凹陷,渲染图反而被纹理干扰 → 深度图赢
-
面包圈表面的轻微凸起:深度变化极小,深度图几乎看不出来,但渲染图通过光影变化能捕捉到 → 渲染图赢
只用一种,注定有盲区。两种互补,才能全面覆盖。
二、核心创新:让模型既"看得懂几何"又"看得全视角"
GS-CLIP 的核心思路是通过两阶段学习,分别从文本端和视觉端增强模型能力:
第一阶段:把3D几何信息"翻译"成文本提示,让CLIP的语言端理解几何异常长什么样。 第二阶段:让渲染图和深度图双流并行处理并深度融合,让CLIP的视觉端看得更全面。
-
整体架构
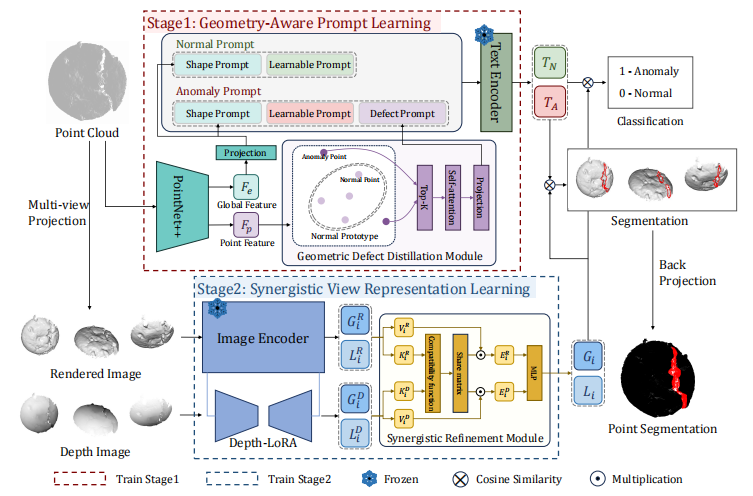
核心流程:
3D 点云
↓
PointNet++ 提取特征
├── 全局特征 → 投影 → Shape Prompt(形状提示)
└── 局部特征 → GDDM(异常评分 → Top-K → Self-Attention)→ Defect Prompt(缺陷提示)
↓
Normal Prompt = Shape + Learnable
Anomaly Prompt = Shape + Learnable + Defect
↓
冻结文本编码器 → T_N, T_A
↓
多视角投影 ──┬── 渲染图 → 冻结ViT ──────────┐
└── 深度图 → LoRA微调ViT ───────┤
↓
SRM(双向乘性注意力融合)
↓
协同全局/局部特征 G, L
↓
cos(G, T_A) / cos(G, T_N) → 物体级分类
cos(L, T_A) / cos(L, T_N) → 像素级分割
↓
反投影 → 3D 点级异常分割Stage 1:几何感知提示学习
这一阶段的目标是:让文本提示"嵌入"3D几何信息,而非使用通用的、与几何无关的文本描述。
Shape Prompt(形状提示)—— 注入全局几何上下文
通过 PointNet++ 提取3D点云的全局特征,经投影层映射为形状提示向量。这个向量携带了目标物体的整体几何形状信息("这是一个圆柱体"、"这是一个扁平的圆盘"),帮助模型理解当前检测对象的宏观几何语境。
Defect Prompt(缺陷提示)—— 提炼局部异常线索
这是本文最精巧的设计,由 几何缺陷蒸馏模块(GDDM) 实现:
局部点特征 → 与正常原型记忆库对比 → 计算几何异常分数
↓
取 Top-K 异常分数最高的点特征
↓
Self-Attention 聚合(捕捉异常点之间的结构关系)
↓
投影 → Defect Prompt关键设计:
正常原型记忆库:在辅助数据集上预先学习正常点的特征原型,构成一个紧凑的"正常特征流形"
几何异常评分:每个点的异常分数 = 1 - 与最相似正常原型的余弦相似度。离正常越远,越可疑
Top-K 选择:只保留最可疑的 K 个点的特征,过滤掉正常点的噪声
Self-Attention 聚合:让异常点之间互相交互,理解它们是否共同构成一道划痕或一个凹坑
不对称拼接 —— 巧妙的信息注入策略
最终的提示拼接方式是不对称的:
-
Normal Prompt = Shape Prompt + 可学习提示(没有缺陷信息)
-
Anomaly Prompt = Shape Prompt + 可学习提示 + Defect Prompt(额外注入缺陷信息)
这意味着:只有异常提示携带了缺陷的几何特征描述。当视觉特征与异常提示的相似度更高时,模型就能判断"当前区域的视觉表现与3D几何缺陷的描述更匹配",从而实现更精准的检测。
Stage 2:协同视觉表征学习
Depth-LoRA —— 轻量适配深度图
CLIP 原生是在真实图像上预训练的,天然适配渲染图。但深度图的特征分布与真实图像差异很大,直接用冻结的 ViT 处理效果不佳。
GS-CLIP 的解决方案是:用 LoRA 只微调 ViT 中 MLP 层的参数,完全保留 Multi-Head Self-Attention 块的空间关系建模能力。
原始MLP: MLP(x) = W₂ · GELU(W₁x)
↓ LoRA改造
LoRA-MLP: x' = GELU(W₁x + γB₁A₁x)
MLP'(x) = W₂x' + γB₂A₂x'好处:用极少的额外参数(低秩矩阵 A、B),让 ViT 适配深度图的特征分布,同时不破坏预训练模型的视觉理解能力。
协同精炼模块(SRM)—— 深度融合双流特征
SRM 通过双向乘性注意力实现渲染流和深度流的深度交互:
渲染特征 → 线性投影 → K_R, V_R ─┐
├→ 共享注意力矩阵 S = f₁(K_R) × f₂(K_D)ᵀ
深度特征 → 线性投影 → K_D, V_D ─┘
↓
E_R = Softmax(S) · V_R (深度信息增强渲染特征)
E_D = Softmax(Sᵀ) · V_D (渲染信息增强深度特征)
↓
Concat(E_R, E_D) → MLP → 协同特征 G核心思想:不是简单拼接或相加,而是让两个模态互相查询对方的信息——渲染流"问"深度流"你在这个位置看到了什么几何结构?",深度流"问"渲染流"你在这个位置看到了什么纹理细节?"。最终融合出一个兼具两者优势的统一特征。
跨视角一致性损失
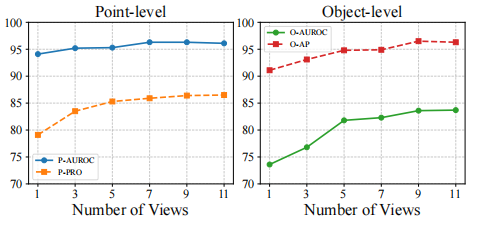
为了增强模型的泛化能力,GS-CLIP 还引入了跨视角一致性损失:
L_con = 1 - (1/v) Σ cos(Gᵢ, G̅)鼓励模型对同一物体的不同视角学到一致的全局表征,提升对未知视角的鲁棒性。
三、实验结果:四大数据集全面验证
1.实验设置:
| 配置 | 详情 |
| 数据集 | MVTec3D-AD (10类真实工业)、Real3D-AD (12类真实)、Eyecandies (10类合成)、Anomaly-ShapeNet (40类合成) |
| 评估指标 | O-AUROC (物体级检测)、O-AP (物体级精度)、P-AUROC (点级检测)、P-PRO (点级定位) |
| 零样本设置 | one-vs-rest (同数据集3个类别上训练,其余测试) + cross-dataset (MVTec3D训练,其余测试) |
| 对比方法 | CLIP、AA-CLIP (CVPR'25)、3DzAL (WACV'25)、MVP-CLIP、PointAD (NeurIPS'24) |
2.One-vs-Rest 设置:全面领先
| 方法 | 会议 | MVTec3D O-R/O-A | MVTec3D P-R/P-P | Eyecandies O-R/O-A | Real3D O-R/O-A | A-ShapeNet O-R/O-A |
|---|---|---|---|---|---|---|
| CLIP | ICML'21 | 61.2/85.8 | 80.3/54.4 | 66.7/69.2 | 68.8/72.3 | 78.2/79.5 |
| AA-CLIP | CVPR'25 | 74.2/88.5 | 87.1/61.6 | 66.5/68.0 | 74.8/76.3 | 83.1/84.5 |
| MVP-PCLIP | arXiv'24 | 81.3/92.7 | 94.6/83.6 | 69.3/72.7 | 74.9/75.3 | 78.7/83.8 |
| PointAD | NeurIPS'24 | 82.0/94.2 | 95.5/84.4 | 69.1/73.8 | 74.8/76.9 | 82.6/85.6 |
| GS-CLIP | - | 83.6/96.5 | 96.3/86.4 | 71.5/75.9 | 76.4/77.7 | 84.1/86.8 |
GS-CLIP 在四大数据集上全面取得最优,相比 PointAD(NeurIPS'24):O-AUROC 平均 +1.8%,O-AP 平均 +1.6%,P-PRO 平均 +2.5%。
几个关键观察:
-
原始 CLIP 和 2D 适配方法 AA-CLIP 表现平平 → 证明直接套用2D模型到3D领域效果有限
-
PointAD 仅用渲染图 → 受光照和渲染伪影影响,纯几何异常容易漏检
-
MVP-PCLIP 仅用深度图 → 虽然擅长捕捉整体形状异常,但微小表面缺陷(划痕、轻微凸起)检测受限
-
GS-CLIP 双流融合 + 几何先验 → 两种视觉模态互补 + 3D几何信息直接注入,全面领先
3.Cross-Dataset 设置:泛化能力优异
| 方法 | Eyecandies O-R/O-A | Eyecandies P-R/P-P | Real3D O-R/O-A | A-ShapeNet O-R/O-A |
|---|---|---|---|---|
| AA-CLIP | 63.6/65.3 | 82.6/39.8 | 70.2/71.7 | 76.2/77.5 |
| MVP-PCLIP | 66.7/70.7 | 88.3/66.0 | 74.9/75.6 | 78.4/82.5 |
| PointAD | 69.5/74.3 | 91.8/71.4 | 75.9/78.9 | 82.3/85.6 |
| GS-CLIP | 70.3/75.3 | 92.9/73.4 | 76.2/77.1 | 82.6/84.8 |
跨数据集设置涉及物体语义、背景、采集方式(真实/合成)的显著偏移,是更严格的泛化能力测试。GS-CLIP 依然保持领先,且相比 one-vs-rest 设置性能下降极小,说明几何先验和双流融合赋予了模型更强的跨域泛化能力。
4.多模态设置:锦上添花
对于包含 RGB 彩色图像的数据集(MVTec3D-AD、Eyecandies),GS-CLIP 采用即插即用的多模态融合方法进一步提升:
| 方法 | MVTec3D O-R/O-A | MVTec3D P-R/P-P | Eyecandies O-R/O-A | Eyecandies P-R/P-P |
|---|---|---|---|---|
| CLIP* | 60.4/86.4 | 81.7/56.0 | 73.0/73.9 | 78.0/31.8 |
| AA-CLIP* | 67.2/89.4 | 94.5/74.6 | 71.7/69.1 | 86.8/74.2 |
| MVP-PCLIP | 85.7/95.8 | 96.5/90.4 | 78.2/80.1 | 94.9/83.6 |
| PointAD | 86.9/96.1 | 97.2/90.2 | 77.7/80.4 | 95.3/84.3 |
| GS-CLIP | 88.2/97.5 | 97.6/91.3 | 79.3/82.2 | 95.8/86.4 |
RGB 图像提供了渲染图和深度图所缺失的真实色彩和精细纹理信息,对检测表面划痕、污渍、变色等缺陷至关重要。GS-CLIP 在多模态设置下依然取得最优,MVTec3D-AD 上 O-AUROC 达 88.2%,Eyecandies 上达 79.3%。
5.计算开销分析
| 方法 | 推理时间(s) | FPS | 显存占用(MB) |
|---|---|---|---|
| CLIP* | 0.23 | 4.34 | 3312 |
| AA-CLIP* | 0.29 | 3.45 | 3826 |
| MVP-PCLIP | 0.46 | 2.17 | 4583 |
| PointAD | 0.40 | 2.52 | 4275 |
| GS-CLIP | 0.51 | 1.96 | 5872 |
GS-CLIP 的推理时间(0.51s)和显存占用(5872MB)略高于其他方法,这是双流架构 + PointNet++ + GDDM 的代价。但考虑到其在四大数据集上的全面精度优势,这是一个合理的精度-效率权衡。

四、消融实验:每个模块都在贡献
在 MVTec3D-AD 上逐步叠加各组件的消融实验:
| SRM | Shape Prompt | Defect Prompt | L_con | O-R/O-A | P-R/P-P |
|---|---|---|---|---|---|
| (仅渲染图) | 80.9/91.7 | 93.5/83.1 | |||
| (仅深度图) | 81.4/91.4 | 92.2/82.5 | |||
| ✔ | 82.3/93.9 | 94.6/84.8 | |||
| ✔ | ✔ | 82.5/94.8 | 95.2/85.1 | ||
| ✔ | ✔ | 82.9/94.4 | 95.6/85.6 | ||
| ✔ | ✔ | ✔ | 83.1/96.2 | 96.0/86.2 | |
| ✔ | ✔ | ✔ | ✔ | 83.6/96.5 | 96.3/86.4 |
逐层分析:
-
SRM 双流融合:相比单独使用渲染图或深度图,O-AUROC +1.4%/+0.9%,P-PRO +1.7%/+2.3% → 双流融合带来的增益是最基础也最显著的
-
Shape Prompt:O-AP 从 93.9% → 94.8%(+0.9%)→ 宏观几何上下文有助于物体级整体判断
-
Defect Prompt + GDDM:P-PRO 从 84.8% → 85.6%(+0.8%),点级定位提升最大 → 局部缺陷信息对精确定位异常区域至关重要
-
Shape + Defect 组合:O-AP 从 94.8% 飙升至 96.2%(+1.4%),效果显著叠加
-
跨视角一致性损失:在已经很强的基础上再添 +0.5%/+0.3%/+0.2% → 锦上添花
GDDM 参数分析
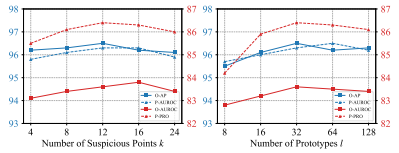
| 参数 | 最优值 | 分析 |
|---|---|---|
| Top-K 异常点数 k | 12 | k=4→12 性能稳步上升(P-PRO:85.5→86.4);k>12 后引入正常点噪声,性能下降 |
| 正常原型数 l | 32 | l 过小无法充分建模正常特征分布;l=32 达到峰值;继续增大无显著收益 |
五、方法亮点总结
| 亮点 | 说明 |
|---|---|
| 3D几何先验注入 | 首次将3D点云的几何信息直接嵌入CLIP文本提示,而非仅在2D图像层面做文章 |
| 几何缺陷蒸馏 | GDDM 通过正常原型记忆库+Top-K+Self-Attention,从点云中精准提炼缺陷描述 |
| 双流协同融合 | 渲染图和深度图通过双向乘性注意力深度交互,互补各自的视觉盲区 |
| 不对称提示设计 | 仅异常提示携带缺陷信息,形成清晰的正常/异常语义区分 |
| LoRA轻量适配 | 仅微调ViT的MLP层,用极少参数让预训练模型适配深度图 |
| 跨域泛化强化 | Cross-dataset设置下性能降幅极小,几何先验赋予了更强的迁移能力 |
| 即插即用扩展 | 可直接叠加RGB多模态融合,MVtec3D-AD上O-AUROC达88.2%,O-AP达97.5% |
六、局限性与未来方向
-
计算开销:双流架构 + PointNet++ + GDDM 带来了 0.51s 推理时间和 5872MB 显存占用(对比 PointAD 的 0.40s 和 4275MB),在对实时性要求极高的产线部署场景下需要进一步优化
-
点云质量依赖:方法依赖高质量的3D点云输入,在低精度扫描设备或噪声较大的场景下效果有待验证
-
更多模态融合:当前双流架构的成功暗示了进一步融合更多模态(如法线图、曲率图)的潜力
-
大规模预训练:结合3D点云的大规模预训练模型(如Point-BERT、PointMAE),有望进一步提升几何特征提取的质量
七、总结:
这篇工作的核心洞察非常精准——当3D信息被投影到2D后,几何细节的丢失是不可逆的,与其在2D图像上修修补补,不如直接从3D点云中提取几何先验注入到检测框架中。从这个角度出发,GS-CLIP 给出了一套逻辑自洽且效果显著的解决方案。
GDDM 的设计尤其值得关注。它不是简单地把所有点特征都塞进提示里,而是通过"正常原型记忆库→异常评分→Top-K筛选→Self-Attention聚合"这一精心设计的流水线,让模型只关注真正可疑的几何区域。消融实验也清晰地验证了这一设计的有效性——Defect Prompt 对点级定位的提升是所有组件中最大的。
双流架构的互补性也被实验充分证明。论文中那个"饼干凹坑 vs 面包圈凸起"的例子非常直观——两种视觉模态确实各有所长,强行二选一只会留下盲区。SRM 的双向乘性注意力设计让两个模态不是简单地"物理拼接",而是"化学反应"级的深度融合。
从实用角度看,GS-CLIP 在跨数据集设置下的稳健表现令人印象深刻。工业场景中最头疼的问题就是"换一种产品就要重新训练",GS-CLIP 的强泛化能力让它离实际落地更近了一步。不过,计算开销是需要关注的问题——0.51s 的推理时间和 5872MB 的显存占用相比 PointAD(0.40s、4275MB)有明显增加,在对实时性和资源敏感的产线部署场景下,如何在保持精度优势的同时优化效率,是后续值得探索的方向。
论文地址:arXiv 2602.19206v2
代码开源:https://github.com/zhushengxinyue/GS-CLIP
数据集:MVTec3D-AD / Real3D-AD / Eyecandies / Anomaly-ShapeNet
机构:苏州大学 + 清华大学智能产业研究院(AIR)

点赞/关注/收藏
持续更新ing!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)