收藏!手把手实战:RAG-SQL Router如何让AI自动“路由”问题?从入门到源码解析
本文详解实战项目RAG-SQL Router,解决AI如何自动判断是查文档(RAG)还是查数据库(SQL)的问题。文章使用LlamaIndex Workflow构建路由Agent,提供完整代码实现,包含Streamlit交互界面及Cleanlab Codex质量保障。适合程序员学习如何落地大模型智能问答系统,掌握Agent工具调用与结果融合的核心技术。
你有没有遇到过这样的困境:用户问你一个问题,你得先判断是该去文档库里翻翻,还是该查查数据库?更头疼的是,如果判断错了,给出的答案要么不准确,要么干脆答非所问。
今天我想和你聊聊一个实战项目——RAG-SQL Router。这不是什么高深莫测的理论,而是一个能真正解决问题的智能系统。更重要的是,我会把完整的实现思路和代码都分享给你,让你也能动手搭建一个。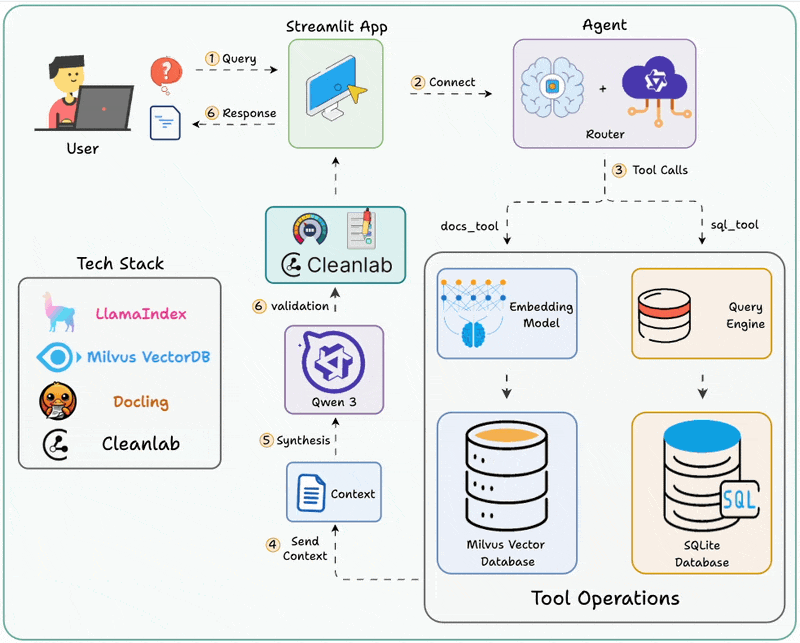
一、为什么需要这样一个系统?
先说说实际场景。假设你在做一个企业内部的智能问答助手:
场景1:非结构化数据查询
- “公司最新的休假政策是什么?”
- “产品功能文档里关于API鉴权的部分怎么说的?”
这类问题的答案藏在PDF、Word文档、Wiki页面里——典型的非结构化数据,最适合用RAG(检索增强生成)来处理。
场景2:结构化数据查询 - “去年第四季度销售额最高的三个地区是哪些?”
- “目前有多少活跃用户?”
这些问题需要的是精确的数字,答案在数据库里——需要Text-to-SQL来解决。
问题来了:当用户随便问一个问题,系统怎么知道该用哪种方式回答?
这就是RAG-SQL Router要解决的核心问题:让AI自己判断该走哪条路。
二、系统架构:Agent如何做决策?
整个系统的核心是一个路由Agent,它的工作流程是这样的:
智能体根据用户问题分析意图后,自主选择文档检索或数据库查询工具来获取信息并返回结果。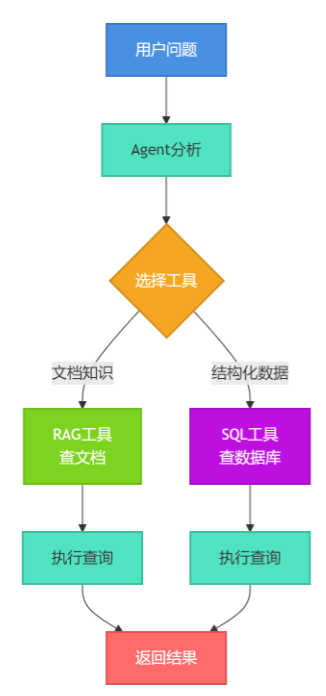
关键组件解析
- Router Agent(路由智能体)
这是整个系统的大脑。它基于LlamaIndex的Workflow框架构建,能够:
- 理解用户问题的语义
- 判断问题类型(文档检索还是数据查询)
- 选择合适的工具
- 甚至可以同时调用多个工具
- RAG工具(向量检索引擎)
负责处理非结构化数据:
- 使用LlamaCloud作为向量数据库
- 支持PDF、Word等文档格式
- 通过语义相似度检索相关内容
- SQL工具(自然语言转SQL引擎)
负责处理结构化数据:
- 将自然语言转换为SQL查询
- 执行数据库查询
- 返回结构化结果
- Cleanlab Codex(质量保障层)
这是个亮点!很多人做Agent,但没人关心输出是否靠谱。Cleanlab Codex提供:
- 自动检测不准确或无用的回答
- 为每个回答提供可信度评分
- 实时验证查询和响应
- 允许专家直接改进回答,无需改代码
三、动手实现:完整代码解析
让我带你一步步搭建这个系统。我会用最实际的代码,而不是空谈理论。
第一步:环境准备
# 创建项目目录mkdir rag-sql-routercd rag-sql-router# 创建虚拟环境python -m venv venvsource venv/bin/activate # Windows用: venv/Scripts/activate# 安装依赖pip install llama-index llama-index-llms-openai / llama-index-embeddings-openai / llama-index-indices-managed-llama-cloud / sqlalchemy streamlit nest-asyncio
第二步:配置API密钥
创建 .env 文件:
OPENAI_API_KEY=your_openai_keyLLAMA_CLOUD_API_KEY=your_llamacloud_keyLLAMA_CLOUD_ORG_ID=your_org_idLLAMA_CLOUD_PROJECT_NAME=your_projectLLAMA_CLOUD_INDEX_NAME=your_index
第三步:搭建SQL查询引擎
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, insertfrom llama_index.core.query_engine import NLSQLTableQueryEnginefrom llama_index.core import SQLDatabase# 创建示例数据库engine = create_engine("sqlite:///:memory:")metadata = MetaData()# 定义城市统计表city_stats = Table( 'city_stats', metadata, Column('city', String, primary_key=True), Column('population', Integer), Column('country', String),)metadata.create_all(engine)# 插入示例数据rows = [ {"city": "Toronto", "population": 2930000, "country": "Canada"}, {"city": "Tokyo", "population": 13960000, "country": "Japan"}, {"city": "Berlin", "population": 3645000, "country": "Germany"},]with engine.connect() as conn: for row in rows: conn.execute(insert(city_stats).values(**row)) conn.commit()# 创建SQL数据库对象sql_database = SQLDatabase(engine, include_tables=["city_stats"])# 创建自然语言SQL查询引擎sql_query_engine = NLSQLTableQueryEngine( sql_database=sql_database, tables=["city_stats"],)
这段代码做了什么?
- 创建了一个内存SQLite数据库(适合演示,生产环境换成MySQL/PostgreSQL)
- 定义了城市统计表,包含城市名、人口、国家字段
- 插入了一些示例数据
- 用
NLSQLTableQueryEngine包装数据库,它能把"人口最多的城市"这样的问题转成SQL
第四步:搭建RAG检索引擎
from llama_index.indices.managed.llama_cloud import LlamaCloudIndeximport os# 连接到LlamaCloud索引rag_index = LlamaCloudIndex( name=os.getenv("LLAMA_CLOUD_INDEX_NAME"), project_name=os.getenv("LLAMA_CLOUD_PROJECT_NAME"), organization_id=os.getenv("LLAMA_CLOUD_ORG_ID"), api_key=os.getenv("LLAMA_CLOUD_API_KEY"),)# 创建查询引擎rag_query_engine = rag_index.as_query_engine()
LlamaCloud是什么?
简单说,它是一个托管的向量数据库服务:
- 你上传文档(PDF、DOCX等)
- 它自动切分、向量化、建索引
- 你只需要调用API查询
当然,你也可以用Qdrant、Pinecone、Weaviate等替代。
第五步:将查询引擎包装成工具
from llama_index.core.tools import QueryEngineTool# SQL工具sql_tool = QueryEngineTool.from_defaults( query_engine=sql_query_engine, name="sql_query_engine", description=( "用于查询城市统计数据,包括人口、国家等信息。" "适合回答关于数字、排名、统计类的问题。" ),)# RAG工具rag_tool = QueryEngineTool.from_defaults( query_engine=rag_query_engine, name="document_search_engine", description=( "用于搜索文档内容,适合回答关于政策、流程、" "说明等需要从文档中查找信息的问题。" ),)
为什么要包装成工具?
这里的description非常关键!Agent会读这些描述来判断该用哪个工具。所以描述要:
- 清晰明确:说清楚工具能做什么
- 区分明显:让Agent能轻松分辨使用场景
- 举例说明:提示适用的问题类型
第六步:构建Router Workflow
这是整个系统最核心的部分:
from llama_index.core.workflow import ( Event, StartEvent, StopEvent, Workflow, step,)from llama_index.llms.openai import OpenAIfrom typing import List, Any# 定义事件类型class PrepEvent(Event): """准备阶段完成事件""" passclass ToolCallEvent(Event): """工具调用事件""" tool_calls: List[Any]# 定义Router Workflowclass RouterWorkflow(Workflow): def __init__(self, tools: List[QueryEngineTool], **kwargs): super().__init__(**kwargs) self.tools = {tool.metadata.name: tool for tool in tools} self.llm = OpenAI(model="gpt-4") @step async def prepare_chat(self, ev: StartEvent) -> PrepEvent: """准备对话消息""" # 获取用户查询 user_msg = ev.query # 构建系统提示 system_prompt = self._build_system_prompt() # 存储到上下文 self.query = user_msg self.messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_msg} ] return PrepEvent() @step async def handle_llm_call(self, ev: PrepEvent) -> ToolCallEvent | StopEvent: """调用LLM决策""" # 准备工具定义给LLM tools_def = [ { "type": "function", "function": { "name": name, "description": tool.metadata.description, "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "用户查询" } }, "required": ["query"] } } } for name, tool in self.tools.items() ] # 调用LLM response = await self.llm.achat( messages=self.messages, tools=tools_def ) # 检查是否有工具调用 if response.message.tool_calls: return ToolCallEvent(tool_calls=response.message.tool_calls) else: # 没有工具调用,直接返回答案 return StopEvent(result=response.message.content) @step async def handle_tool_calls(self, ev: ToolCallEvent) -> StopEvent: """执行工具调用""" results = [] for tool_call in ev.tool_calls: tool_name = tool_call.function.name tool_args = eval(tool_call.function.arguments) # 执行工具 tool = self.tools[tool_name] result = await tool.aquery(tool_args["query"]) results.append({ "tool": tool_name, "result": str(result) }) # 组合结果 final_answer = self._combine_results(results) return StopEvent(result=final_answer) def _build_system_prompt(self) -> str: """构建系统提示""" return """你是一个智能助手,能够访问以下工具:1. SQL查询引擎:用于查询结构化数据2. 文档搜索引擎:用于搜索文档内容根据用户问题,选择合适的工具。如果需要,可以同时使用多个工具。""" def _combine_results(self, results: List[dict]) -> str: """组合多个工具的结果""" if len(results) == 1: return results[0]["result"] combined = "根据查询结果:/n/n" for i, res in enumerate(results, 1): combined += f"{i}. 从{res['tool']}得到: {res['result']}/n" return combined
这个Workflow是怎么工作的?
- prepare/_chat: 接收用户问题,准备系统提示和对话消息
- handle/_llm/_call: 调用LLM,让它决定用哪个工具(或多个工具)
- handle/_tool/_calls: 实际执行工具调用,获取结果
- 如果有多个结果,组合起来返回
关键点在于:
- Event驱动:每个step返回一个Event,触发下一个step
- 异步执行:所有step都是async,支持并发
- 灵活路由:LLM可以选择0个、1个或多个工具
第七步:创建Streamlit界面
import streamlit as stimport asyncio# 页面配置st.set_page_config(page_title="RAG-SQL Router", page_icon="🤖")st.title(" 智能路由问答系统")st.markdown("**问我任何问题,我会自动选择最佳方式回答!**")# 初始化工具和workflowif "workflow" not in st.session_state: # 创建工具 tools = [sql_tool, rag_tool] # 初始化workflow st.session_state.workflow = RouterWorkflow( tools=tools, timeout=60.0 )# 聊天历史if "messages" not in st.session_state: st.session_state.messages = []# 显示历史消息for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"])# 用户输入if prompt := st.chat_input("在这里输入你的问题..."): # 显示用户消息 st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) # 调用workflow获取答案 with st.chat_message("assistant"): with st.spinner("思考中..."): # 运行workflow result = asyncio.run( st.session_state.workflow.run(query=prompt) ) # 显示答案 st.markdown(result) # 保存助手回答 st.session_state.messages.append({"role": "assistant", "content": result})# 侧边栏:显示可用工具with st.sidebar: st.subheader("🔧 可用工具") st.write("1. SQL查询引擎") st.caption("查询城市统计数据") st.write("2. 文档搜索引擎") st.caption("搜索文档内容") if st.button("清空对话"): st.session_state.messages = [] st.rerun()
第八步:运行系统
streamlit run app.py
打开浏览器,访问 http://localhost:8501,试试这些问题:
SQL类问题:
- “哪个城市人口最多?”
- “有多少个欧洲城市?”
RAG类问题: - “文档里提到的政策要点是什么?”
- “关于API使用的说明在哪里?”
混合问题: - “东京的人口是多少?同时告诉我文档里关于东京的介绍。”
四、加入Cleanlab Codex:让输出更可靠
前面的系统已经能工作了,但有个问题:怎么知道AI的回答靠不靠谱?
这就是Cleanlab Codex的价值。它能:
- 自动检测问题回答
- 答非所问
- 信息不完整
- 事实错误
- 提供可信度评分
- 每个回答都有0-1的分数
- 分数低于阈值触发告警
- 支持专家反馈
- SME(领域专家)可以直接标注
- 系统自动学习改进
集成代码示例:
from cleanlab_codex import CleanlabCodex# 初始化Codexcodex = CleanlabCodex(api_key=os.getenv("CLEANLAB_API_KEY"))# 在workflow中使用@stepasync def validate_response(self, ev: StopEvent) -> StopEvent: """验证响应质量""" # 获取原始回答 response = ev.result # 验证质量 validation = codex.validate( query=self.query, response=response, context=self.retrieved_context ) # 添加可信度评分 confidence = validation.trustworthiness_score if confidence < 0.7: response += f"/n/n 可信度: {confidence:.2%} (建议人工确认)" else: response += f"/n/n 可信度: {confidence:.2%}" return StopEvent(result=response)
五、实际应用场景
这套系统不是玩具,我们来看看能解决什么实际问题:
场景1:企业知识库
问题: 公司有大量文档(员工手册、产品文档、流程规范)和业务数据(销售、用户、财务)。员工经常不知道去哪找信息。
解决方案:
- RAG工具索引所有文档
- SQL工具连接业务数据库
- 员工直接问问题,系统自动路由
效果: - 减少80%的重复咨询
- 提升员工自助查询效率
- 数据和文档统一入口
场景2:客户服务系统
问题: 客服需要回答产品使用问题(文档)和订单状态(数据库)。
解决方案:
- RAG工具索引产品文档、FAQ
- SQL工具连接订单系统
- 客服输入问题,系统提供参考答案
效果: - 新客服上手快
- 答案标准化
- 响应时间缩短50%
场景3:数据分析助手
问题: 业务人员不会写SQL,但需要经常查数据。
解决方案:
- SQL工具连接数据仓库
- RAG工具提供分析方法论文档
- 自然语言查询,自动生成SQL
效果: - 降低对数据团队的依赖
- 提升数据驱动决策效率
- 减少重复分析工作
六、关键经验和坑
搭建这个系统时,我踩过不少坑,分享几个关键经验:
1. 工具描述要精准
坑: 最开始我的SQL工具描述是"用于查询数据"——太模糊了!结果Agent经常选错。
解决: 改成"用于查询城市统计数据,包括人口、国家等信息。适合回答关于数字、排名、统计类的问题。"——具体、清晰、有例子。
2. 处理好并发调用
坑: 用户问"东京人口多少?文档里怎么说的?"——需要同时调用两个工具,但结果怎么组合?
解决:
- Workflow支持并发step
- 在
_combine_results里做好结果聚合 - 让LLM再做一次总结
3. 数据库连接要健壮
坑: SQLite内存数据库重启就没了,生产环境不能用。
解决:
# 生产环境用持久化数据库engine = create_engine( "postgresql://user:pass@host:5432/db", pool_pre_ping=True, # 检查连接有效性 pool_size=10, # 连接池)
4. Token消耗要控制
坑: 每次查询都把全部上下文传给LLM,token消耗巨大。
解决:
- 只传必要的上下文
- 使用更便宜的模型做路由(gpt-3.5-turbo)
- 缓存常见问题的答案
5. 错误处理要完善
坑: SQL语法错误、网络超时、API限流都会导致系统崩溃。
解决:
try: result = await tool.aquery(query)except SQLAlchemyError as e: result = f"数据库查询失败: {str(e)}"except TimeoutError: result = "查询超时,请稍后重试"except Exception as e: result = f"系统错误: {str(e)}" # 记录日志 logger.error(f"Tool error: {e}", exc_info=True)
七、性能优化建议
如果你要把这套系统用到生产环境,这些优化必不可少:
1. 缓存机制
from functools import lru_cacheimport hashlib@lru_cache(maxsize=1000)def cached_query(query_hash: str): """缓存查询结果""" # 实际查询逻辑 pass# 使用时query_hash = hashlib.md5(query.encode()).hexdigest()result = cached_query(query_hash)
2. 批量查询
对于相似查询,批量处理:
async def batch_query(queries: List[str]): """批量执行查询""" tasks = [workflow.run(query=q) for q in queries] return await asyncio.gather(*tasks)
3. 监控和日志
import loggingfrom datetime import datetimelogging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('rag_sql_router.log'), logging.StreamHandler() ])logger = logging.getLogger(__name__)# 在关键位置记录logger.info(f"Query received: {query}")logger.info(f"Tool selected: {tool_name}")logger.info(f"Response time: {elapsed:.2f}s")
4. 限流保护
from functools import wrapsimport timedef rate_limit(max_calls: int, time_window: int): """限流装饰器""" calls = [] def decorator(func): @wraps(func) async def wrapper(*args, **kwargs): now = time.time() # 清理过期记录 calls[:] = [c for c in calls if c > now - time_window] if len(calls) >= max_calls: raise Exception("请求过于频繁,请稍后再试") calls.append(now) return await func(*args, **kwargs) return wrapper return decorator@rate_limit(max_calls=10, time_window=60)async def handle_query(query: str): """处理查询,每分钟最多10次""" pass
八、总结
看到这里,你大概已经能感受到:RAG-SQL Router 这东西看起来像“多加了一个路由层”,但真正解决的是落地时最容易被忽视的一件事——把“该去哪儿找答案”这一步交给系统,而不是交给用户。
很多企业内部问答做不起来,并不是因为模型不够强,而是因为入口不够统一:同一句话问出来,有时候是制度条款,有时候是数据口径,有时候还夹杂着流程步骤。人能凭经验判断“先查文档还是先查库”,但系统如果没有这个判断能力,就会变成两种尴尬:
-
只做RAG:回答得像“引用资料”,听起来挺像那么回事,但数字经不起核对;
-
只做Text-to-SQL:能查到数,但对“为什么这么算”“规则写在哪”完全没有解释能力。
Router 的价值,就是让这两套能力不再互相拖后腿,而是互相补位:需要确定性的时候走SQL,需要背景解释的时候走RAG,复杂一点的问题就两条路一起跑,最后再把结果合到一张桌子上给你。如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~
① 全套AI大模型应用开发视频教程
(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)
② 大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!
③ 大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
④ AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
⑤ 大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。
⑥ 大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

以上资料如何领取?

为什么大家都在学大模型?
最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!

这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

以上全套大模型资料如何领取?


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献226条内容
已为社区贡献226条内容

所有评论(0)