Transformer原理全解析:小白也能看懂的实战模拟
🔥 Transformer原理全解析:小白也能看懂的实战模拟
一、写在前面:为什么一定要搞懂Transformer?
你一定听过这些热词:ChatGPT、Sora、AI绘画、智能翻译、大语言模型(LLM)。
这些看似五花八门的AI应用,背后其实都站着同一个核心骨架——Transformer。
可以说:不懂Transformer,就等于不懂现代AI。
但很多人对Transformer的印象都是:复杂的向量、晦涩的公式、难懂的术语,看完还是一头雾水。
本文完全抛弃公式堆砌,用**“小白也能听懂”的语言+真实案例**,带你从零到一,彻底搞懂Transformer的工作原理,并用“我爱吃苹果”这个案例,从头模拟一遍完整流程。

二、一句话核心概念:Transformer是什么?
先给大家建立最直观的认知:
Transformer = 一个会“自动找重点”的超级智能翻译官。
它的核心架构只有两大部分,就像人的“大脑”和“双手”:
- Encoder(编码器):负责**“看懂”**输入内容(比如中文句子、图片像素、语音片段)。
- Decoder(解码器):负责**“生成”**输出内容(比如英文翻译、文字、图片、视频)。
而它最厉害的“武器”,就是Attention(注意力机制)——能自动识别输入中“谁和谁关系最紧密”,精准抓住重点。
三、整体架构:Transformer的“大脑结构”
我们可以把Transformer想象成一个**“智能翻译工厂”**,整体流程如下:
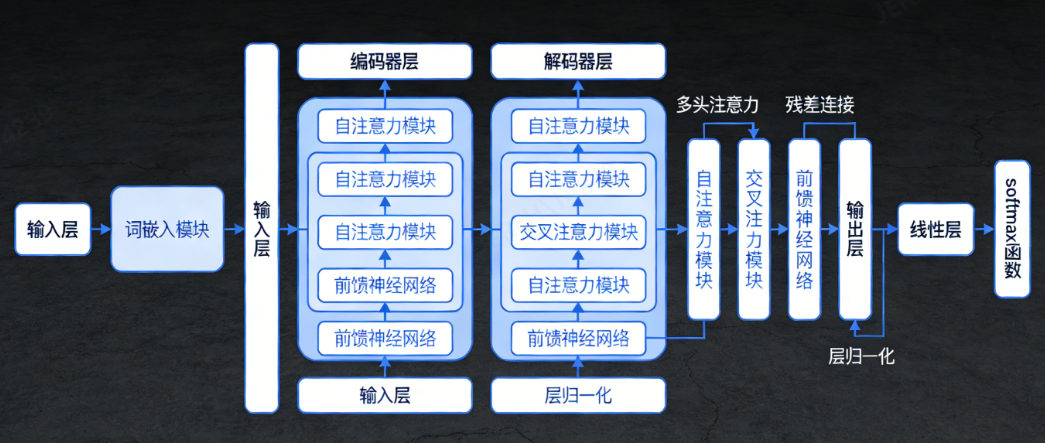
1. Encoder(编码器):核心职责
Encoder是Transformer的“理解大脑”,它的任务只有一个:
把输入内容翻译成模型能读懂的“语义密码”,并建立内容内部的关系图谱。
比如输入是中文句子“我爱吃苹果”,Encoder会把每个词的含义、顺序、词与词之间的关联全部梳理清楚,最终生成一份**“语义记忆库”**,这份记忆库会全程传给Decoder,保证生成不跑偏。
2. Decoder(解码器):核心职责
Decoder是Transformer的“生成双手”,它的任务是:
根据Encoder的语义记忆库,一个元素一个元素地生成输出内容。
比如翻译任务中,Decoder会依次生成“I、love、eating、apples”;在AI绘画任务中,Decoder会根据文字描述,依次生成图片的像素点;在语音合成中,Decoder会生成语音的声波片段。
3. 核心桥梁:注意力机制(Attention)
注意力机制是Transformer的“灵魂”,没有它,Transformer就是一堆无用的数学模型。
它的核心作用是:让模型自动“关注”重要内容,忽略无关内容。
举个简单例子:
读句子“小明把书借给了小红,因为他要复习”,你的大脑会自动:
- 重点关注“他”→ 推断出“他”指的是小明;
- 忽略“因为”“了”这类无意义的连接词。
Transformer的注意力机制,就是让模型也拥有这种“自动抓重点”的能力。
四、核心原理:注意力机制
注意力机制看似复杂,本质就是**“给每个内容打关注度分数”**,我们用3步拆解,保证人人都能懂。
1. 核心三要素:Query、Key、Value
注意力机制围绕三个核心概念展开,我们用**“找人”**的例子类比:
- Query(查询):相当于“我想找什么人”。比如你在人群中找“你的同桌”,这个“找同桌的意图”就是Query。
- Key(键):相当于“每个人的身份标签”。比如人群里每个人都有自己的名字、特征,这些身份标签就是Key。
- Value(值):相当于“每个人的具体信息”。比如每个人的身高、爱好、座位号,这些详细信息就是Value。
2. 注意力计算逻辑:三步找重点
以句子中的一个词“爱”为例,注意力机制的计算流程如下:
- 生成Query/Key/Value:“爱”生成自己的Query(我要找和我关系紧密的词),其他词(我、吃、苹果)生成自己的Key(我的身份)和Value(我的详细信息)。
- 计算相似度分数:用Query和其他词的Key做匹配,算“像不像”。匹配度越高,分数越高。
- “爱”和“我”匹配:关系紧密 → 分数90分;
- “爱”和“吃”匹配:关系极紧密 → 分数95分;
- “爱”和“苹果”匹配:有点关联 → 分数70分。
- 加权融合信息:把所有词的Value按相似度分数加权相加。最终“爱”不再是孤立的字,而是带着“我、吃、苹果信息的融合词”。
3. 两种核心注意力类型
Transformer中最常用的是两种注意力,也是理解Encoder和Decoder的关键:
- 自注意力(Self-Attention):让内容内部的元素互相匹配,建立内容自身的关系。比如Encoder用自注意力,让“我”“爱”“吃”“苹果”互相建立关联。
- 交叉注意力(Cross-Attention):让Decoder的生成内容和Encoder的语义记忆库匹配,保证生成不偏离输入。比如Decoder翻译时,用交叉注意力对照Encoder的中文记忆,确保英文翻译准确。
五、实战模拟:用“我爱吃苹果”走完完整Transformer流程
我们选一个最基础的任务:将中文句子“我爱吃苹果”翻译成英文。
整个流程分为4大步骤,我们一步步拆解,全程不涉及任何复杂公式。
步骤1:输入预处理——把句子变成模型能读懂的“密码”
模型不认识汉字,也不认识图片,所以第一步要把输入内容“翻译”成模型能理解的向量(可以简单理解为“语义编号”),做两件事:
1. 词嵌入(Embedding):给每个词分配“语义编号”
给句子中的每个词分配一个专属的语义向量,比如:
- 我 → 语义向量A;
- 爱 → 语义向量B;
- 吃 → 语义向量C;
- 苹果 → 语义向量D。
2. 位置编码(Positional Encoding):给每个词贴“顺序标签”
Transformer本身不知道内容的顺序,所以必须手动给每个元素贴上顺序标签:
- 我:第1个词;
- 爱:第2个词;
- 吃:第3个词;
- 苹果:第4个词。
经过这一步,模型知道了:这是4个按顺序排列的语义向量,对应“我、爱、吃、苹果”。
步骤2:Encoder(编码器)——看懂中文,生成语义记忆库
Encoder的核心任务是:用自注意力,让每个词互相匹配,建立整句的语义关系。
我们以“爱”这个词为例,模拟自注意力的完整过程:
- 生成Query/Key/Value:
- “爱”生成Query:我要找和我关系紧密的词;
- “我”“吃”“苹果”生成Key:我的身份;
- “我”“吃”“苹果”生成Value:我的详细信息(比如“我”是主语,“吃”是动作,“苹果”是对象)。
- 计算相似度分数:
- “爱”与“我”匹配:关系紧密 → 90分;
- “爱”与“吃”匹配:关系极紧密 → 95分;
- “爱”与“苹果”匹配:有点关联 → 70分。
- 加权融合信息:
模型把这些分数归一化,得到注意力权重,再用权重对Value加权求和。最终“爱”变成了**“带着我、吃、苹果信息的融合词”**。
同理,“我”“吃”“苹果”也会经过同样的自注意力过程,最终Encoder处理完所有词,生成一份中文语义记忆库,里面清晰记录着:
主语是“我”,动作是“爱吃”,对象是“苹果”。
这份记忆库就是Decoder生成的唯一依据,全程不会丢失。
步骤3:Decoder(解码器)——逐词生成英文翻译
Decoder是一个词一个词地生成英文的,每生成一个词,都会经历**“掩码自注意力 + 交叉注意力”**两个核心步骤,直到生成结束符。
我们依次模拟生成“I、love、eating、apples”的全过程:
生成第1个词:I
- 掩码自注意力(Masked Self-Attention):
Decoder初始只有一个开始符<start>,此时只能看自己,绝对不能偷看未来的词(防止作弊)。这一步是为了让Decoder理解已生成的内容。 - 交叉注意力(核心!):
Decoder拿着当前的生成状态,去查询Encoder的中文语义记忆库:第一个词的内容是“我”。
模型匹配“我”的英文翻译 → I。 - 生成结果:Decoder输出第一个英文单词I。
生成第2个词:love
- 掩码自注意力:
现在Decoder已生成“I”,只能看“I”和自己,梳理已生成内容的关系。 - 交叉注意力:
Decoder拿着“I”去查询语义记忆库:“我”后面的动作是“爱”。
模型匹配“爱”的英文翻译 → love。 - 生成结果:Decoder输出第二个英文单词love。
生成第3个词:eating
- 掩码自注意力:
已生成“I、love”,梳理这两个词的关联。 - 交叉注意力:
Decoder拿着“I love”去查询语义记忆库:“我爱”后面的动作是“吃”。
模型匹配“吃”的英文形式(动名词)→ eating。 - 生成结果:Decoder输出第三个英文单词eating。
生成第4个词:apples
- 掩码自注意力:
已生成“I、love、eating”,梳理三者的关联。 - 交叉注意力:
Decoder拿着整句英文去查询语义记忆库:“吃”的对象是“苹果”。
模型匹配“苹果”的英文翻译 → apples。 - 生成结果:Decoder输出第四个英文单词apples。
结束流程
Decoder遇到结束符<end>,翻译任务完成,最终生成完整英文句子:
I love eating apples.
步骤4:最终验证
整个Transformer流程结束,输入“我爱吃苹果”,输出“I love eating apples”,翻译准确完成。
六、核心总结:3句话背下Transformer原理
为了方便记忆,我们把Transformer的核心原理浓缩成3句大白话:
- Encoder负责“看懂”:用自注意力,让每个元素互相匹配,建立输入内容的语义关系,生成记忆库。
- Decoder负责“生成”:用掩码自注意力防止偷看未来,用交叉注意力时刻对照Encoder的记忆库,逐元素生成输出内容。
- 注意力机制是灵魂:通过Query、Key、Value计算相似度,自动抓住输入中的重点和关联,让模型更智能。
七、补充
补充以下硬核要点:
- 架构本质:基于自注意力机制的Seq2Seq(序列到序列)模型,通过Encoder-Decoder架构实现输入到输出的映射。
- 核心优势:解决了传统RNN/LSTM的长距离依赖问题,自注意力机制可并行计算,训练效率远高于传统循环模型。
- 应用扩展:不仅限于NLP领域,通过ViT(视觉Transformer)、Whisper(语音Transformer)等变体,已广泛应用于计算机视觉、语音识别、多模态融合等场景。
- 高效优化:2025-2026年主流优化方向包括FlashAttention(降低显存占用)、Mamba/SSM(长序列高效计算)、MoE(混合专家模型,稀疏激活提升效率)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)