计算机毕业设计Django+大模型中华古诗词知识图谱可视化 古诗词智能问答系统 古诗词数据分析 古诗词情感分析模型 自然语言处理NLP 机器学习 深度学习
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + 大模型中华古诗词知识图谱可视化
摘要:本文旨在探讨如何结合Django框架与大模型技术构建中华古诗词知识图谱,并实现其可视化展示。首先介绍了中华古诗词知识图谱构建的背景与意义,阐述了利用大模型进行知识抽取与整合的优势。接着详细描述了基于Django框架的系统架构设计,包括数据层、业务逻辑层和展示层的实现。然后重点介绍了知识图谱的构建过程,涵盖数据采集、预处理、实体关系抽取以及图谱存储等环节。最后,阐述了如何运用可视化技术将知识图谱以直观、交互的方式呈现给用户,并通过系统测试验证了系统的有效性与实用性。该系统为古诗词研究、教育及文化传播提供了新的工具与平台。
关键词:Django;大模型;中华古诗词;知识图谱;可视化
一、引言
中华古诗词作为中华民族文化的瑰宝,承载着丰富的历史、文学、哲学等信息。传统的古诗词研究方式主要依赖于人工查阅文献和专家分析,效率较低且难以全面挖掘古诗词之间的内在联系。随着信息技术的不断发展,知识图谱作为一种结构化的语义知识库,能够清晰地表示实体及其之间的关系,为古诗词研究提供了新的思路和方法。
同时,大模型技术的兴起为知识抽取与整合提供了强大的工具。大模型具有强大的语言理解和生成能力,能够从海量的文本数据中自动提取有价值的信息,构建高质量的知识图谱。而Django作为一个成熟、高效的Web框架,具有快速开发、安全可靠等优点,适合用于构建知识图谱的可视化展示系统。
因此,结合Django框架与大模型技术构建中华古诗词知识图谱可视化系统具有重要的现实意义。该系统可以帮助用户更全面、深入地了解古诗词的相关知识,促进古诗词的传播与研究。
二、相关技术概述
2.1 Django框架
Django是一个基于Python的高级Web框架,它遵循MVC(Model-View-Controller)设计模式,鼓励模块化和可重用的代码开发。Django提供了丰富的功能组件,如ORM(对象关系映射)、模板引擎、表单处理等,能够大大提高Web应用的开发效率。在知识图谱可视化系统中,Django可以用于构建系统的后端架构,处理用户请求、管理数据以及与前端进行交互。
2.2 大模型技术
大模型是指具有大量参数和强大语言处理能力的深度学习模型,如GPT系列、BERT等。这些模型通过在大规模文本数据上进行预训练,学习到了丰富的语言知识和语义信息。在知识图谱构建中,大模型可以用于实体识别、关系抽取等任务,能够自动从文本中提取出古诗词相关的实体(如诗人、朝代、诗词标题等)以及它们之间的关系(如创作关系、引用关系等),提高知识抽取的准确性和效率。
2.3 知识图谱可视化技术
知识图谱可视化是将知识图谱中的实体和关系以图形化的方式呈现给用户,使用户能够直观地理解知识之间的结构和联系。常见的可视化技术包括节点链接图、力导向图、树状图等。在实现知识图谱可视化时,可以使用一些开源的可视化库,如D3.js、ECharts等,这些库提供了丰富的图表类型和交互功能,能够满足不同场景下的可视化需求。
三、系统架构设计
3.1 总体架构
本系统采用三层架构设计,包括数据层、业务逻辑层和展示层。数据层负责存储古诗词数据和知识图谱数据;业务逻辑层使用Django框架实现数据的处理和业务逻辑的实现;展示层则通过Web页面将知识图谱可视化结果呈现给用户。
3.2 数据层
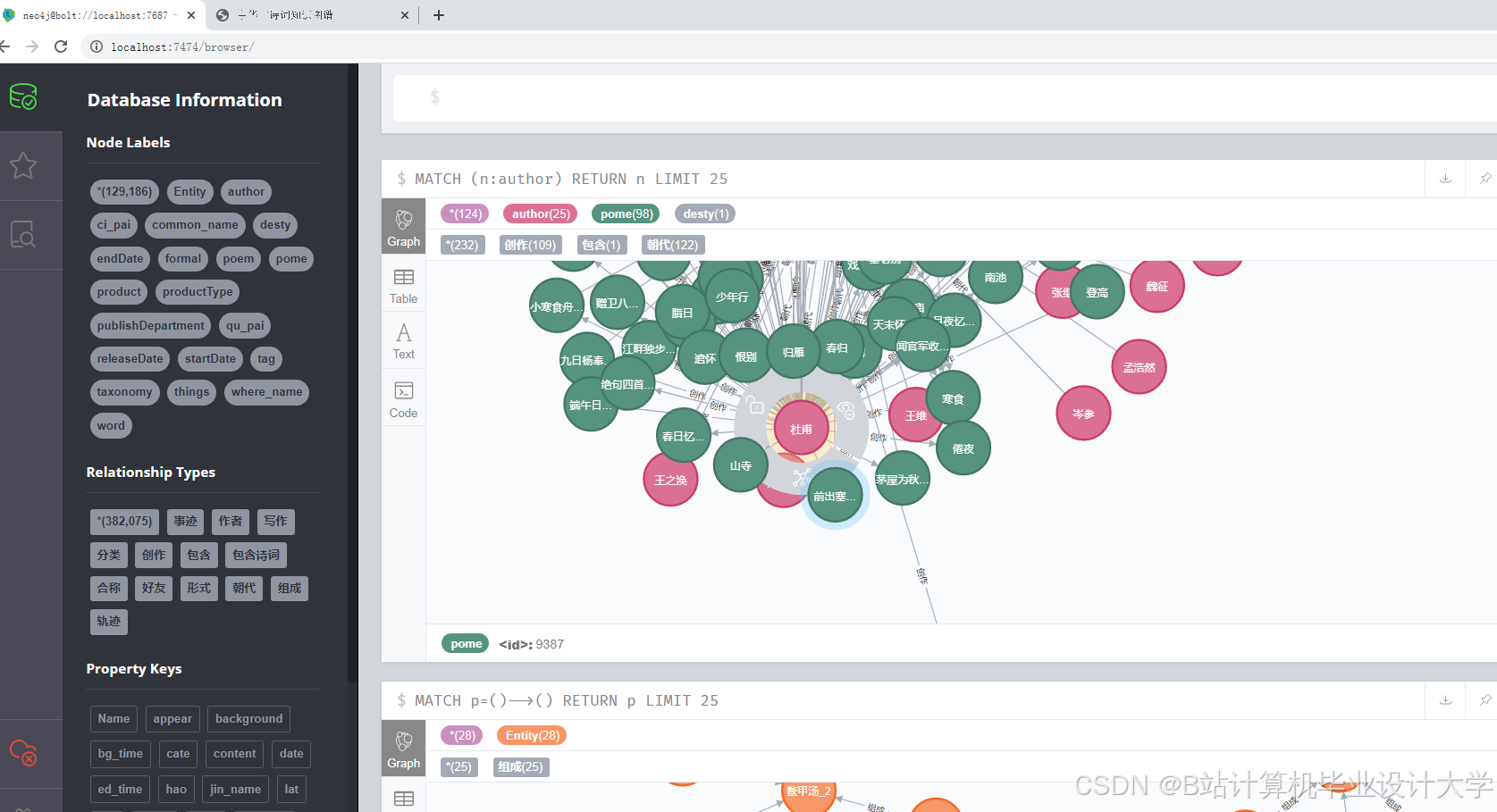
数据层主要包括两个数据库:关系型数据库(如MySQL)用于存储古诗词的原始数据,包括诗词内容、诗人信息、朝代信息等;图数据库(如Neo4j)用于存储知识图谱数据,以图的形式表示实体及其之间的关系。
3.3 业务逻辑层
业务逻辑层是系统的核心部分,主要完成以下功能:
- 数据采集与预处理:从多个数据源采集古诗词数据,并进行清洗、去重、标准化等预处理操作,确保数据的质量和一致性。
- 知识抽取:利用大模型技术从预处理后的文本数据中抽取实体和关系,构建初始的知识图谱。
- 知识融合与存储:对抽取到的知识进行融合和消歧处理,将处理后的知识存储到图数据库中。
- 接口服务:提供RESTful API接口,为展示层提供数据支持,实现前后端的数据交互。
3.4 展示层
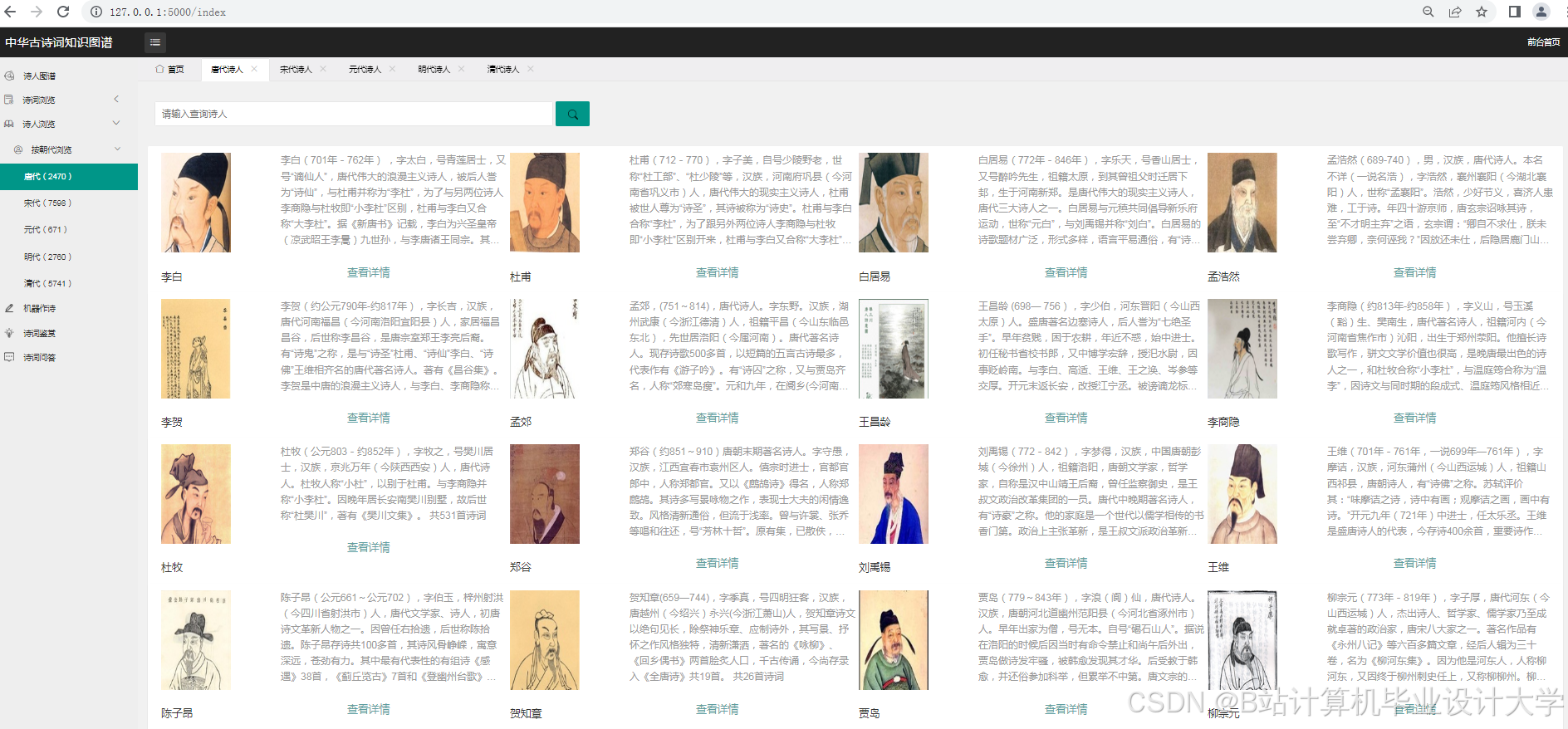
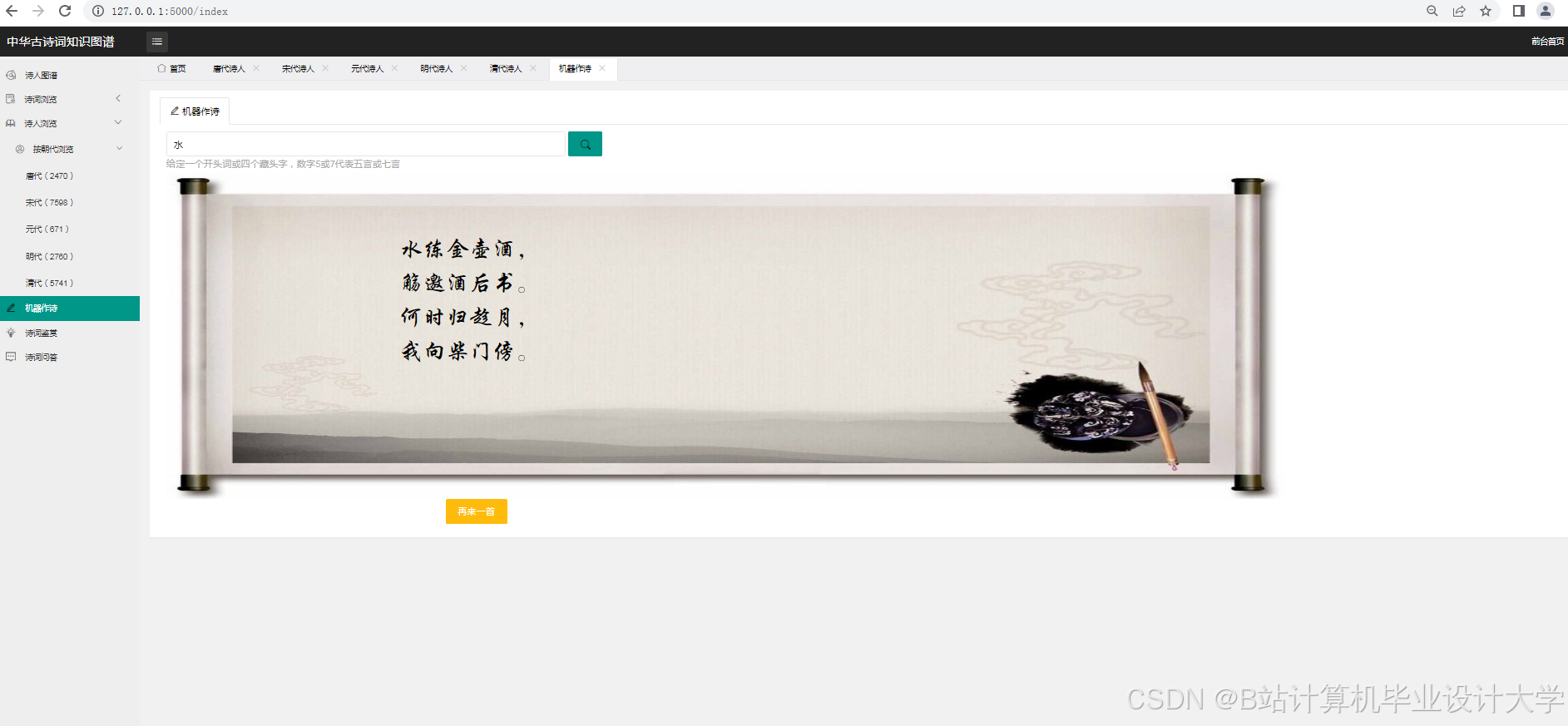
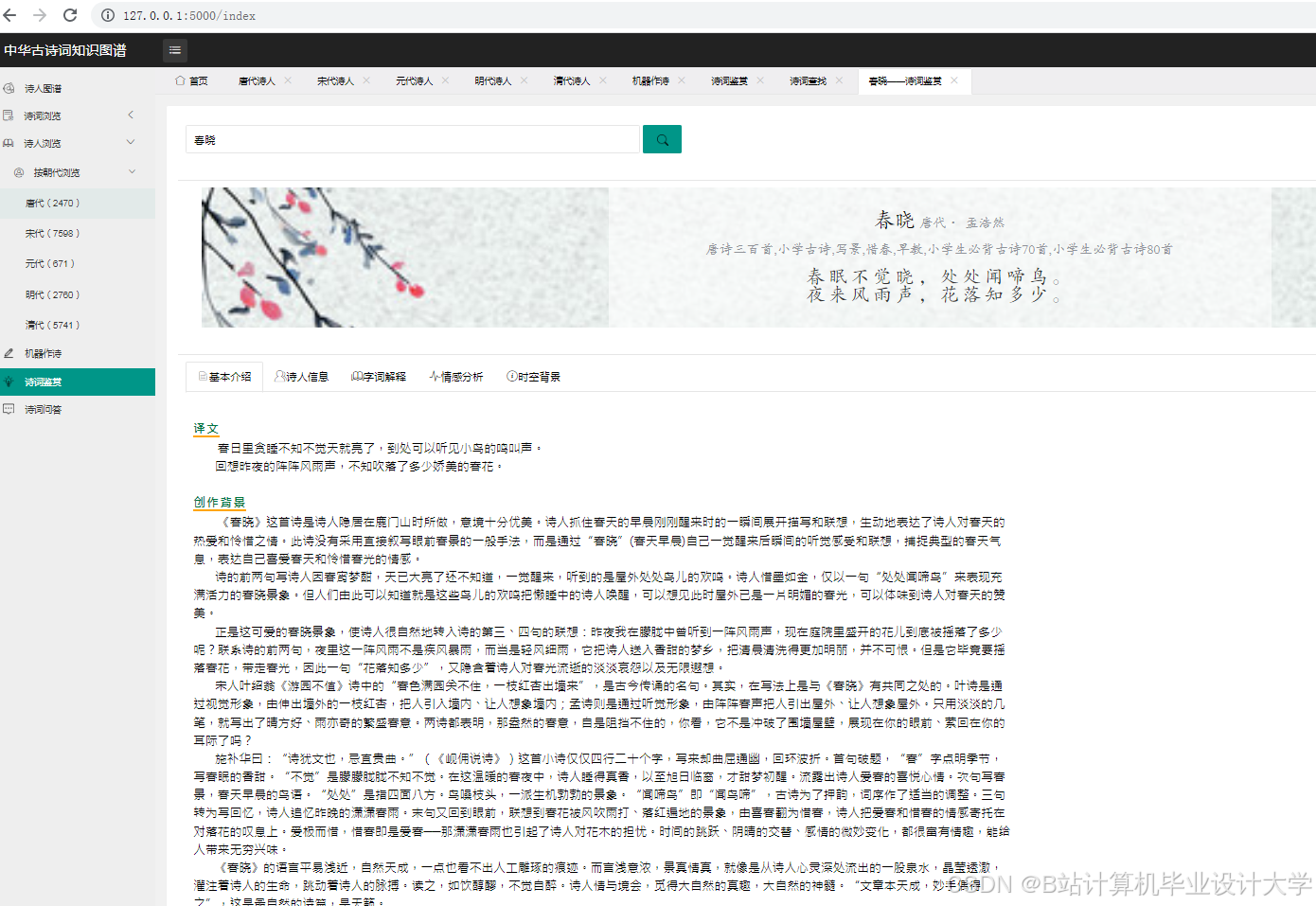
展示层通过Web页面将知识图谱可视化结果呈现给用户。用户可以通过页面上的交互控件对知识图谱进行缩放、拖动、筛选等操作,以便更详细地查看知识之间的关系。同时,展示层还提供了一些辅助功能,如诗词搜索、诗人信息展示等,方便用户获取更多相关信息。
四、知识图谱构建
4.1 数据采集
本系统的数据来源主要包括公开的古诗词数据库、网络爬虫采集的诗词数据以及相关文献资料等。通过编写爬虫程序,从多个诗词网站爬取古诗词数据,并将数据存储到关系型数据库中。
4.2 数据预处理
数据预处理是知识图谱构建的重要环节,主要包括以下步骤:
- 数据清洗:去除数据中的噪声、重复数据和错误数据,确保数据的准确性和完整性。
- 文本分词:使用中文分词工具(如jieba分词)对诗词内容进行分词处理,将文本转换为词语序列。
- 词性标注与命名实体识别:对分词后的词语进行词性标注,并识别出其中的命名实体,如诗人、朝代、诗词标题等。
4.3 实体关系抽取
利用大模型技术进行实体关系抽取是知识图谱构建的关键步骤。本系统采用基于预训练大模型(如BERT)的实体关系抽取方法,具体步骤如下:
- 模型微调:在预训练大模型的基础上,使用标注好的古诗词数据集进行微调,使模型能够更好地适应古诗词领域的实体关系抽取任务。
- 实体关系抽取:将预处理后的文本数据输入到微调后的模型中,模型输出实体之间的关系对,如“李白 - 创作 - 《静夜思》”。
4.4 知识融合与存储
由于数据来源的多样性,抽取到的知识可能存在重复、冲突等问题。因此,需要进行知识融合与消歧处理,将相同或相似的实体进行合并,解决实体之间的冲突。处理后的知识以图的形式存储到图数据库中,每个实体作为图中的一个节点,实体之间的关系作为图中的边。
五、知识图谱可视化实现
5.1 可视化库选择
本系统选择D3.js作为知识图谱可视化的库。D3.js是一个基于数据驱动的JavaScript可视化库,它提供了丰富的图表类型和强大的交互功能,能够满足知识图谱可视化的需求。
5.2 可视化实现步骤
- 数据获取:通过Django提供的RESTful API接口从图数据库中获取知识图谱数据,并将其转换为JSON格式。
- 图形绘制:使用D3.js根据获取到的JSON数据绘制节点链接图,将实体表示为节点,关系表示为边。通过设置节点的颜色、大小和边的粗细等属性,使知识图谱更加直观、美观。
- 交互功能实现:为知识图谱添加交互功能,如节点的点击事件、缩放、拖动等。当用户点击某个节点时,显示该节点的详细信息,如诗人的生平介绍、诗词的内容等。
六、系统测试与评估
6.1 功能测试
对系统的各个功能模块进行测试,包括数据采集、知识抽取、知识融合、可视化展示等。测试结果表明,系统能够准确地采集古诗词数据,有效地抽取实体和关系,实现知识的融合与存储,并将知识图谱以直观的方式展示给用户。
6.2 性能测试
对系统的性能进行测试,包括响应时间、吞吐量等指标。测试结果表明,系统在处理大量数据时能够保持较好的性能,满足用户的使用需求。
6.3 用户反馈
邀请部分古诗词研究者和爱好者对系统进行试用,并收集他们的反馈意见。用户普遍认为该系统能够帮助他们更全面、深入地了解古诗词的相关知识,为古诗词研究和学习提供了便利。
七、结论与展望
7.1 结论
本文结合Django框架与大模型技术构建了中华古诗词知识图谱可视化系统。通过数据采集、预处理、知识抽取、知识融合与存储等环节,构建了高质量的古诗词知识图谱,并利用D3.js实现了知识图谱的可视化展示。系统测试结果表明,该系统具有功能完整、性能良好等优点,能够为古诗词研究、教育及文化传播提供有力的支持。
7.2 展望
未来的工作可以从以下几个方面展开:
- 数据扩充:不断扩充古诗词数据来源,增加知识图谱的规模和覆盖范围,提高系统的知识丰富度。
- 模型优化:进一步优化大模型,提高知识抽取的准确性和效率,探索更加有效的知识融合方法。
- 功能拓展:增加更多的功能模块,如诗词推荐、诗词创作辅助等,提升系统的实用性和用户体验。
通过不断的研究和改进,相信中华古诗词知识图谱可视化系统将在古诗词领域发挥更大的作用,为传承和弘扬中华民族优秀传统文化做出贡献。
运行截图
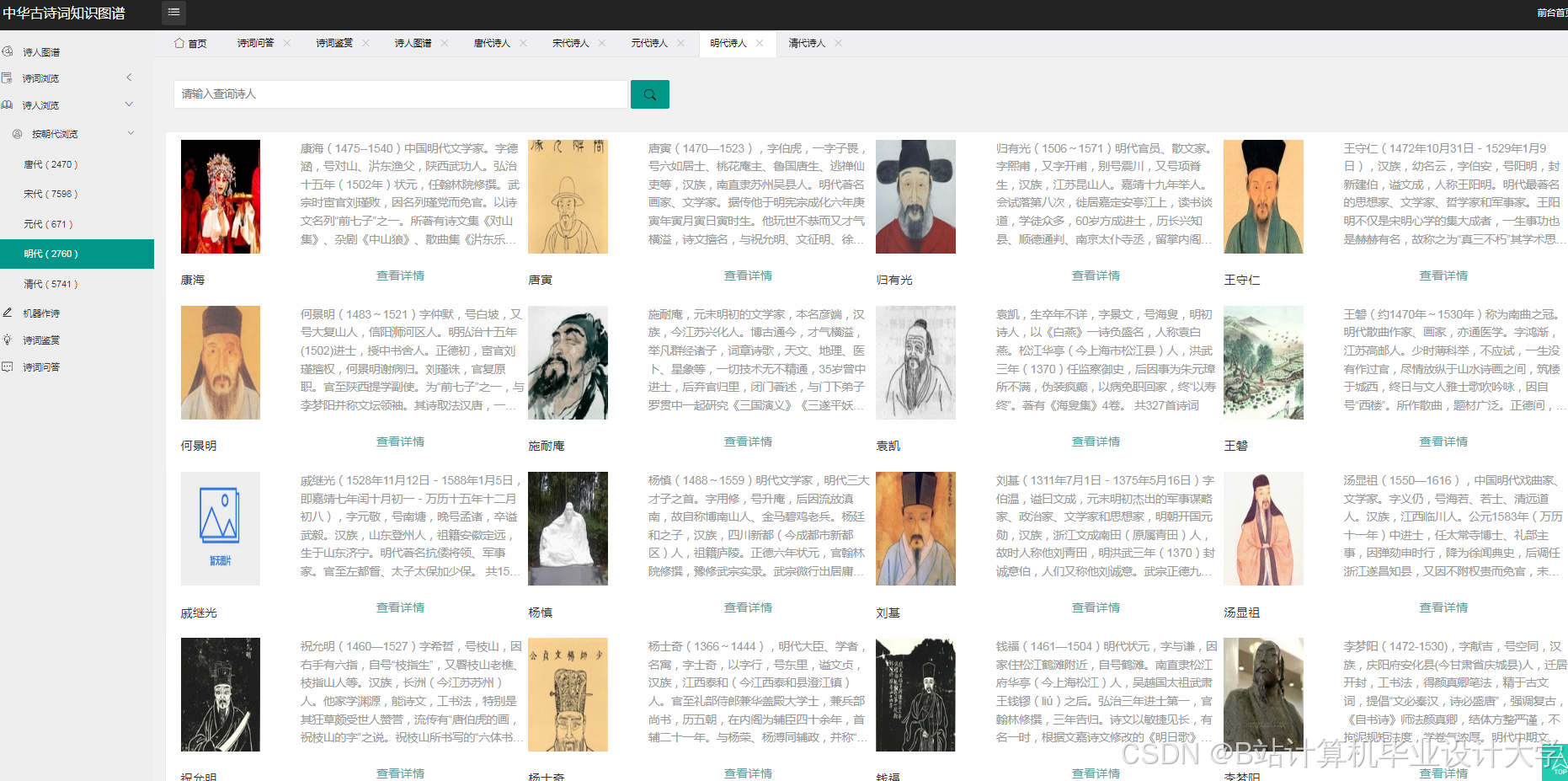
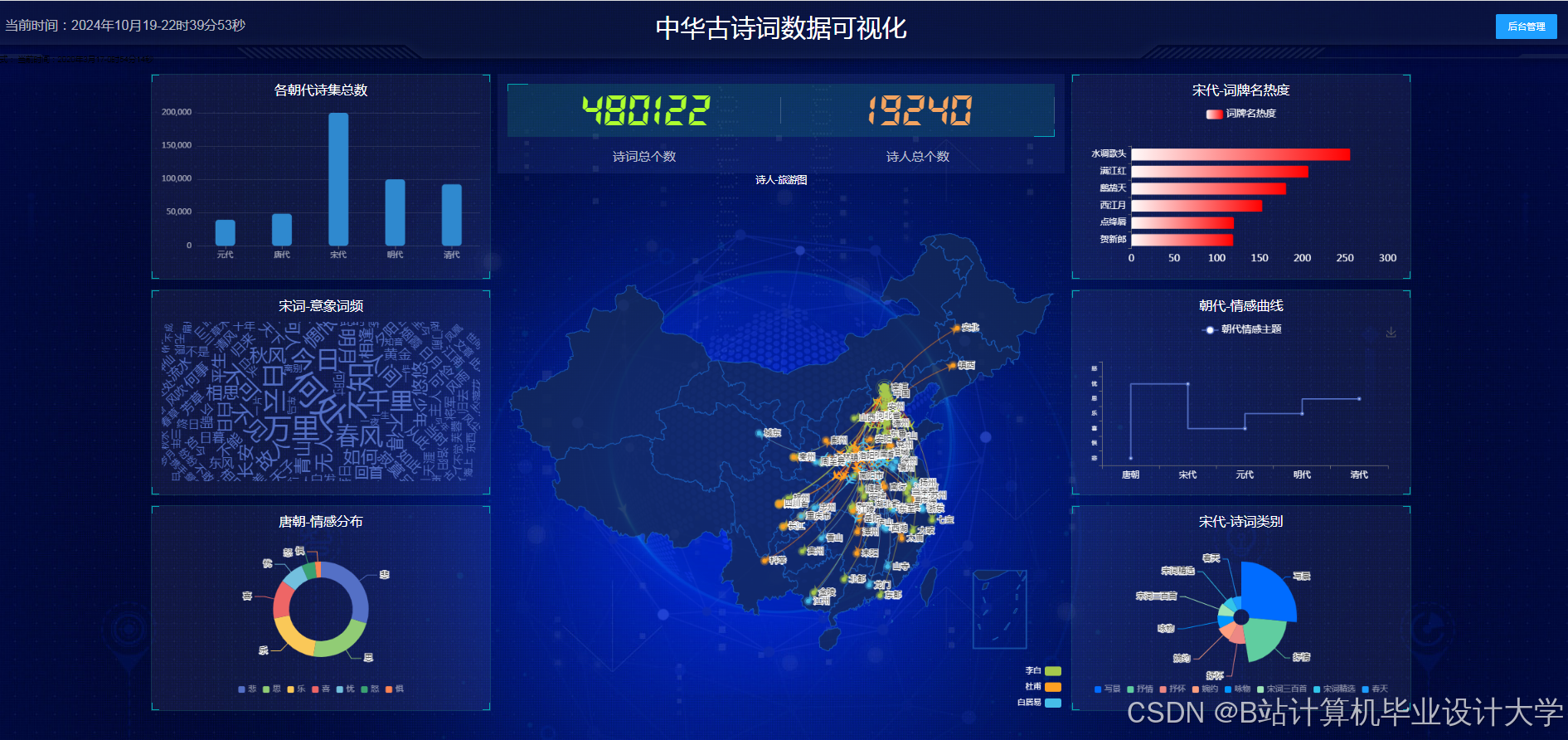
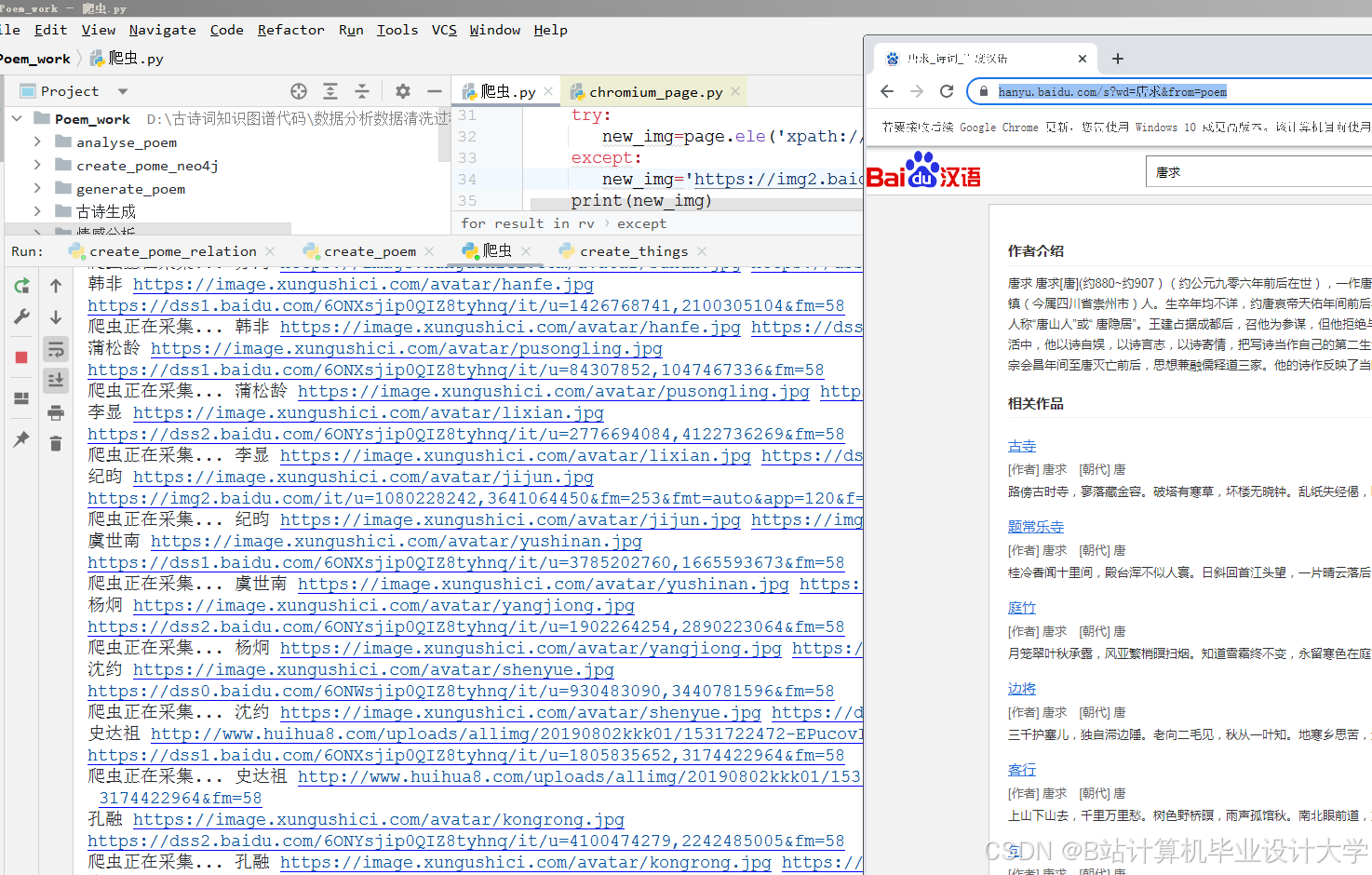
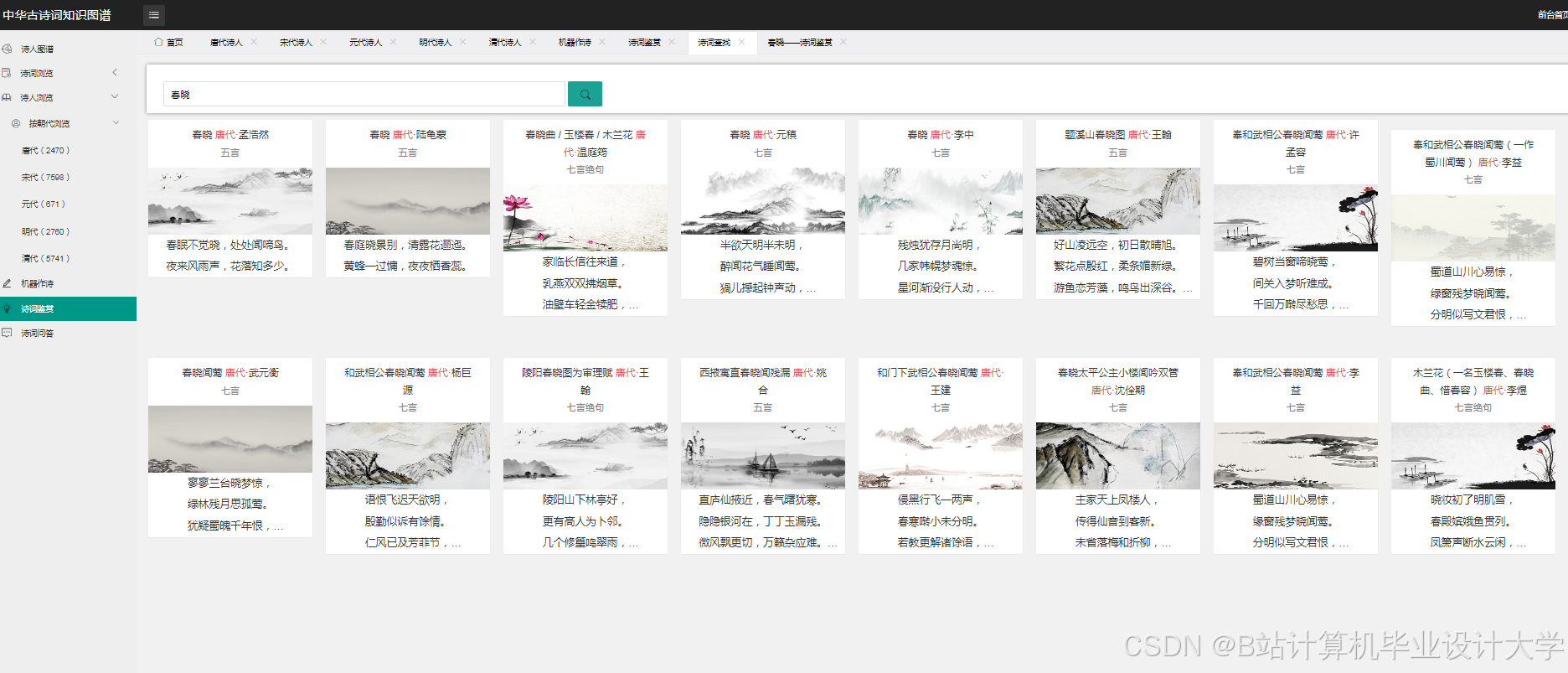
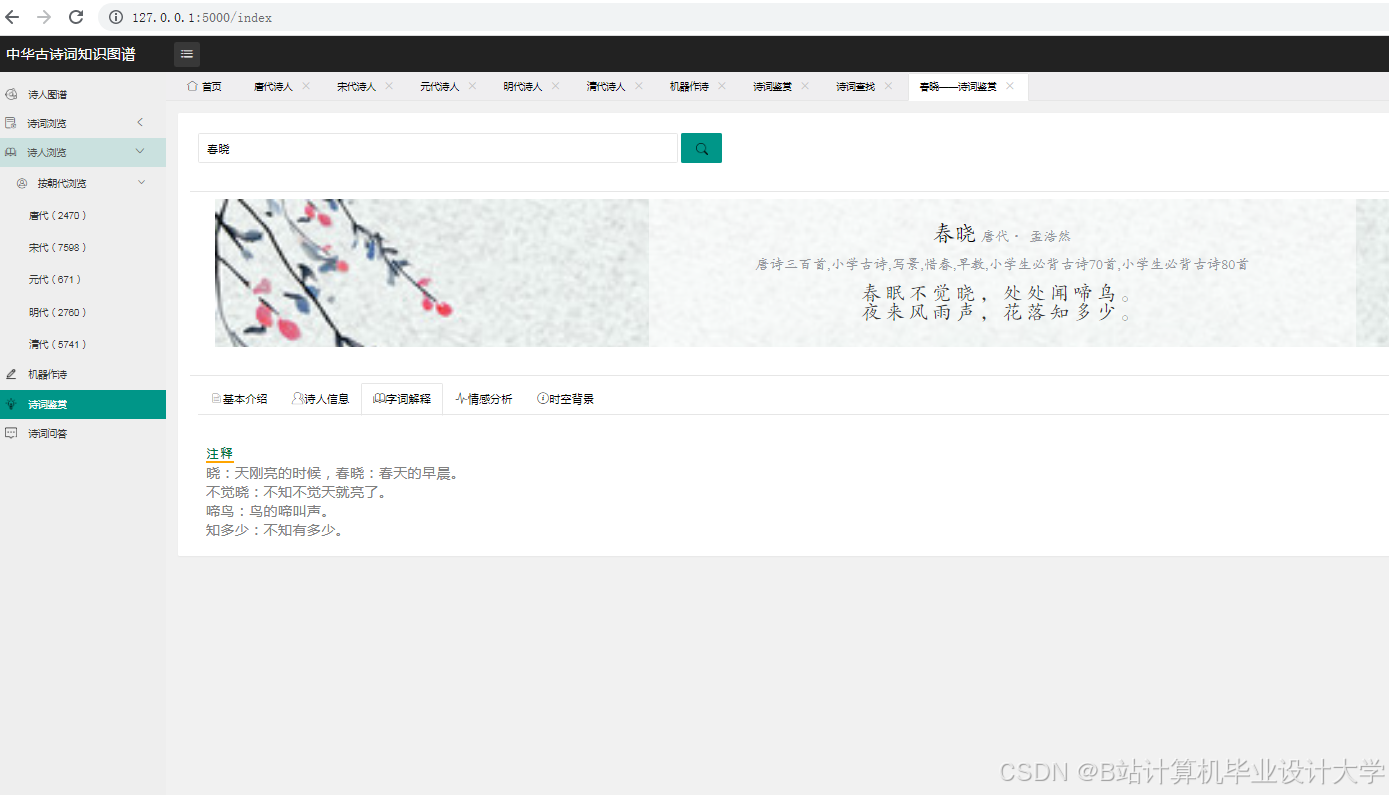
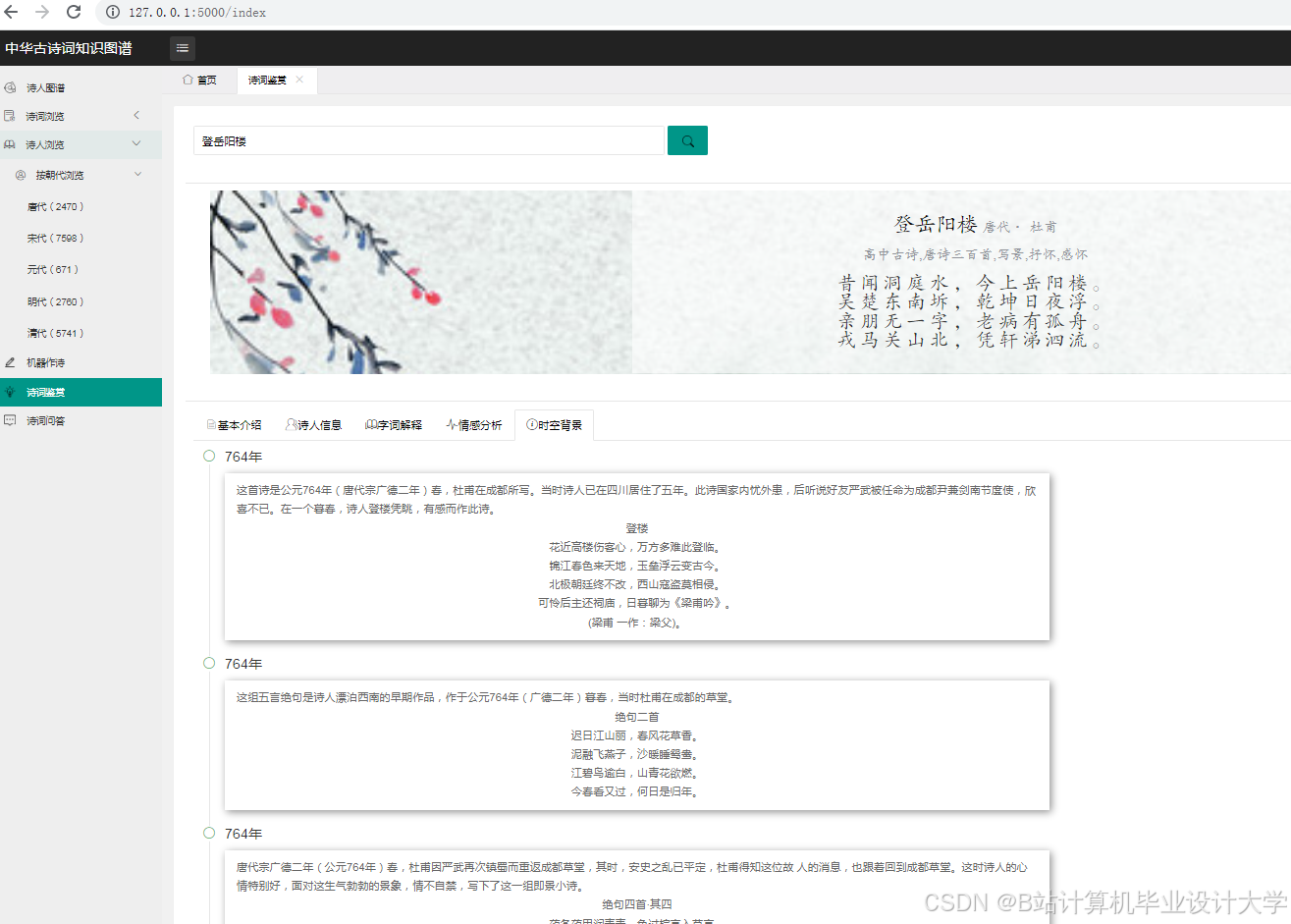
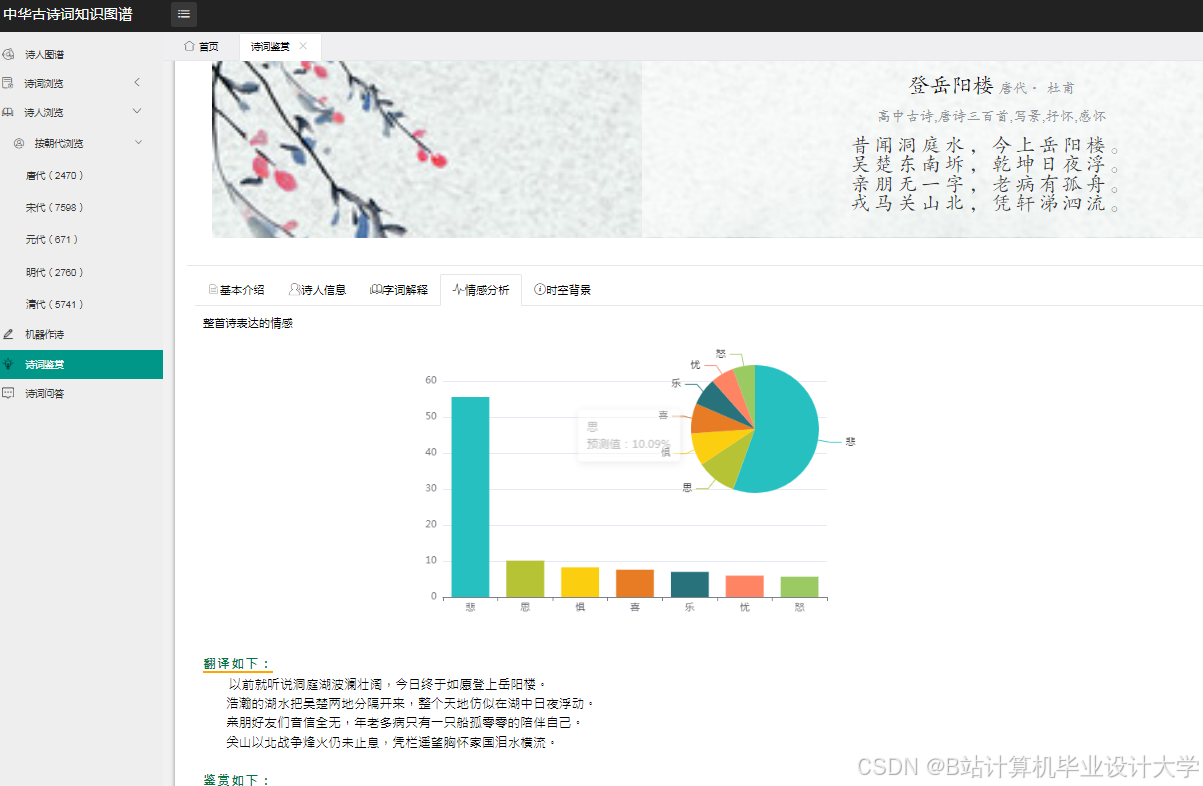
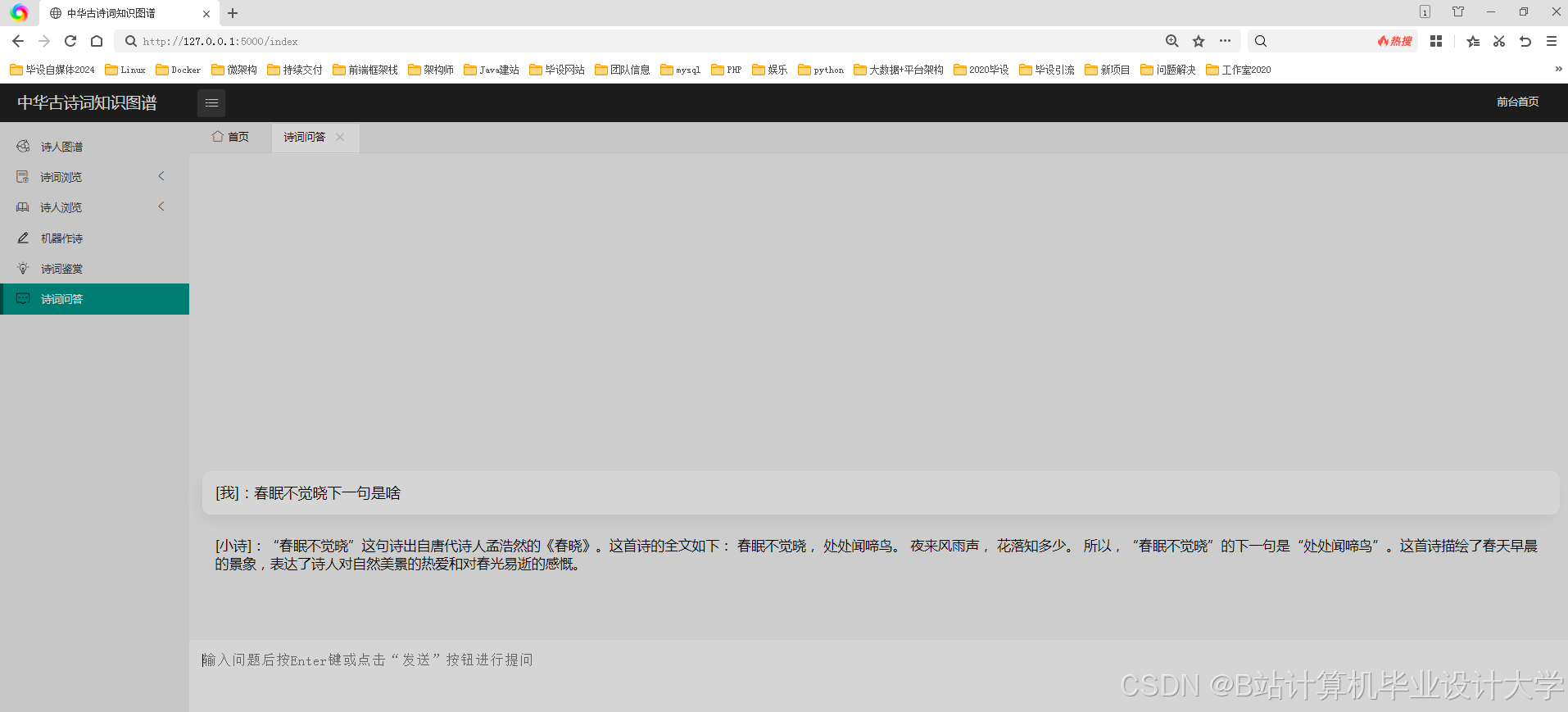
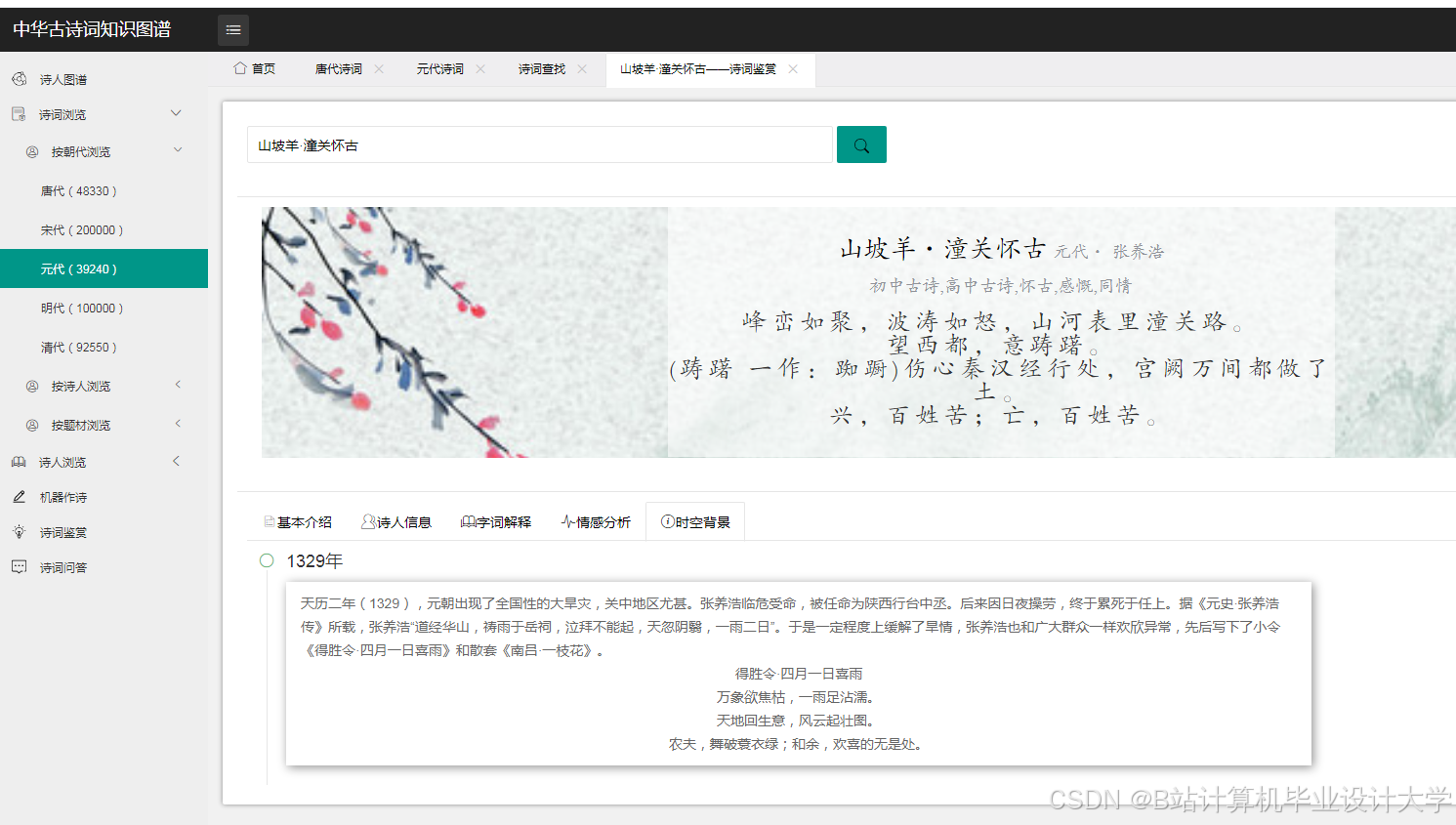
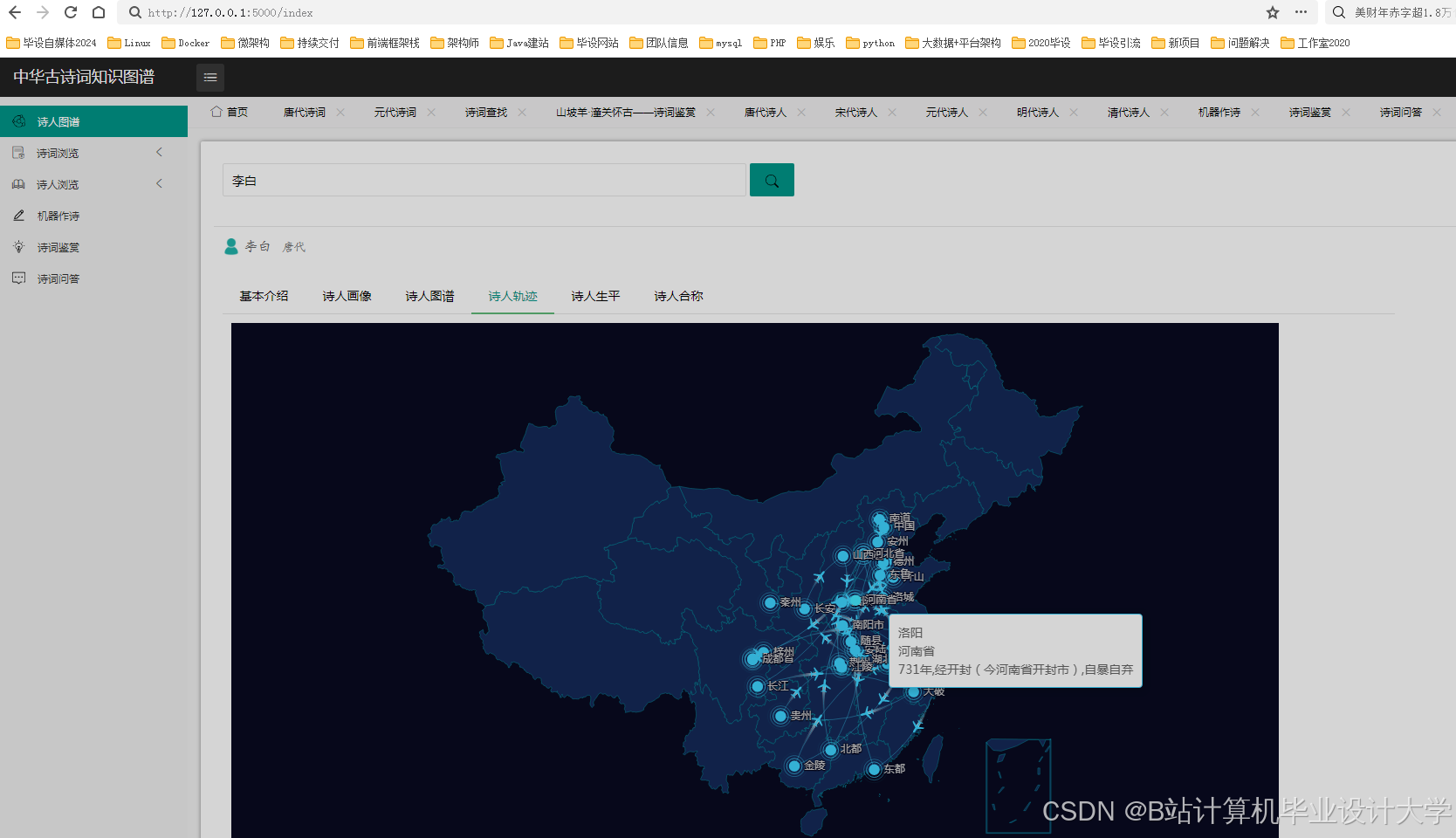
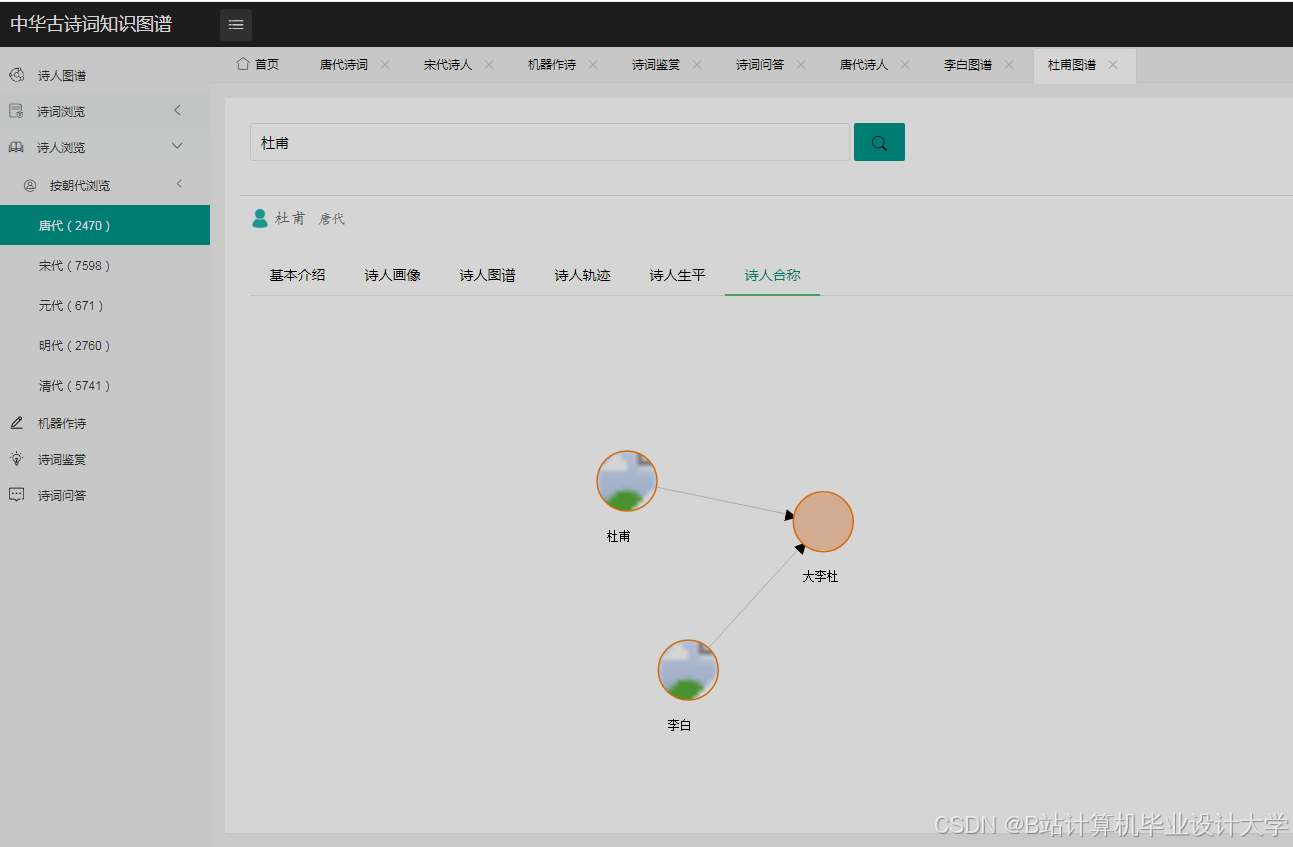
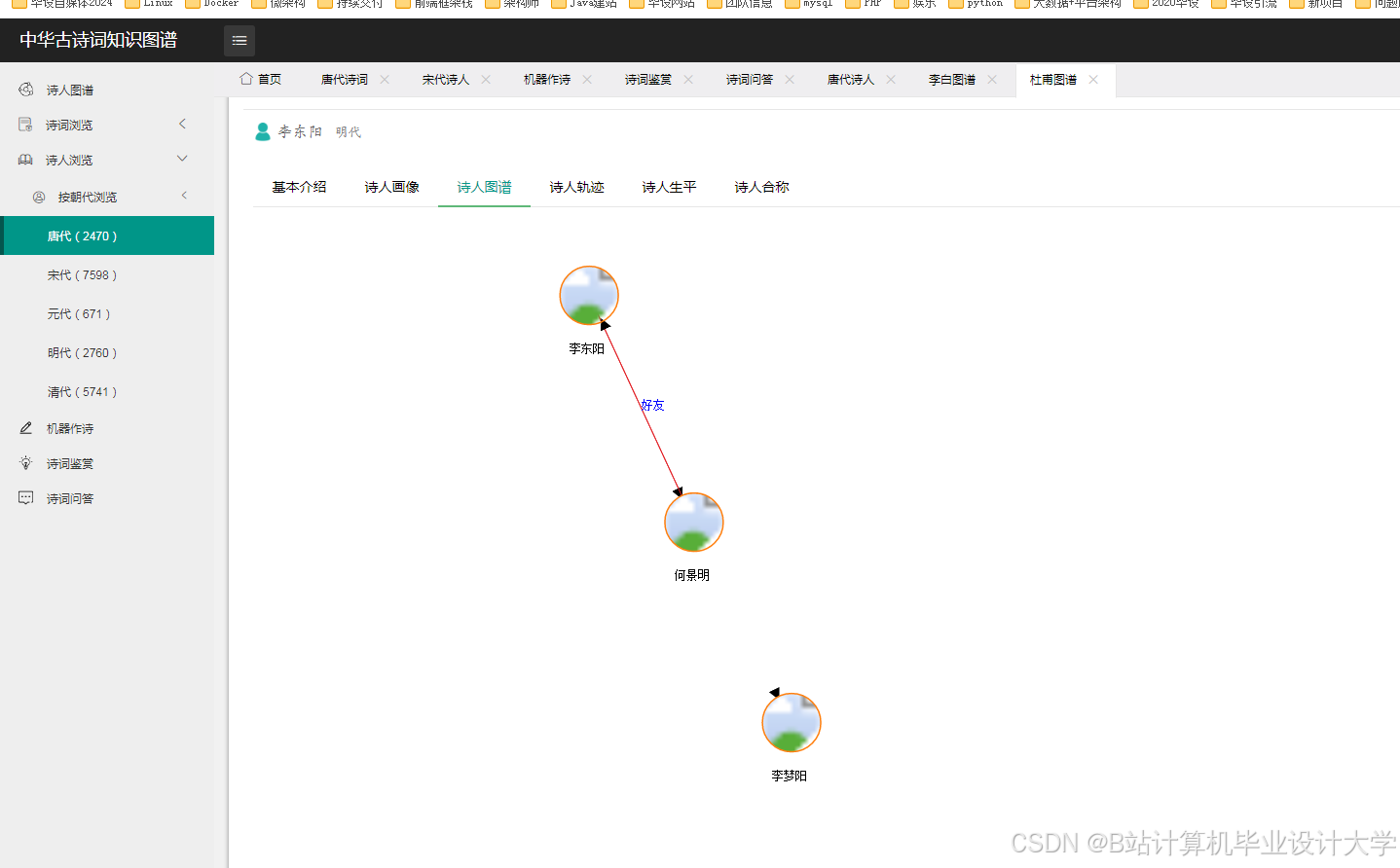
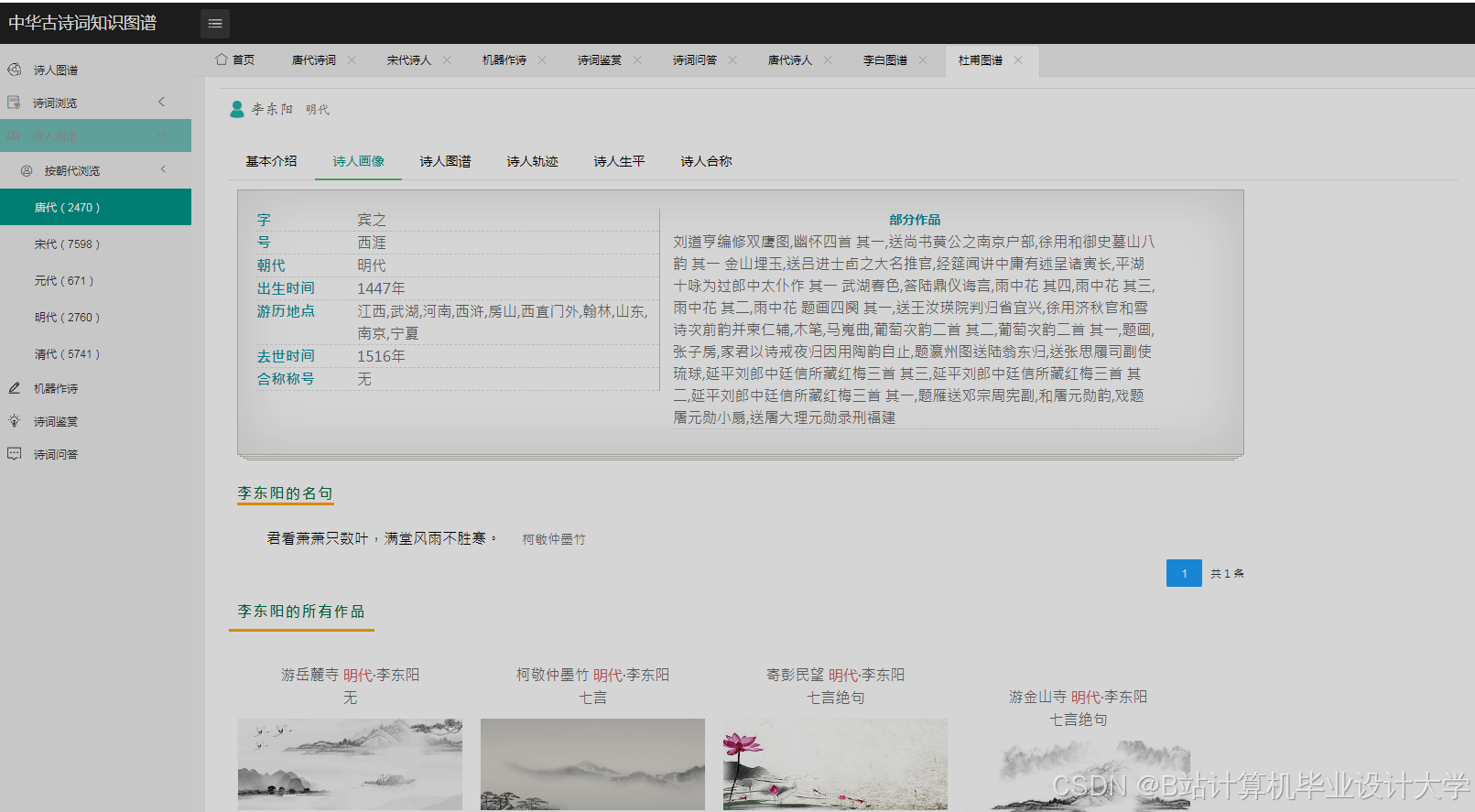
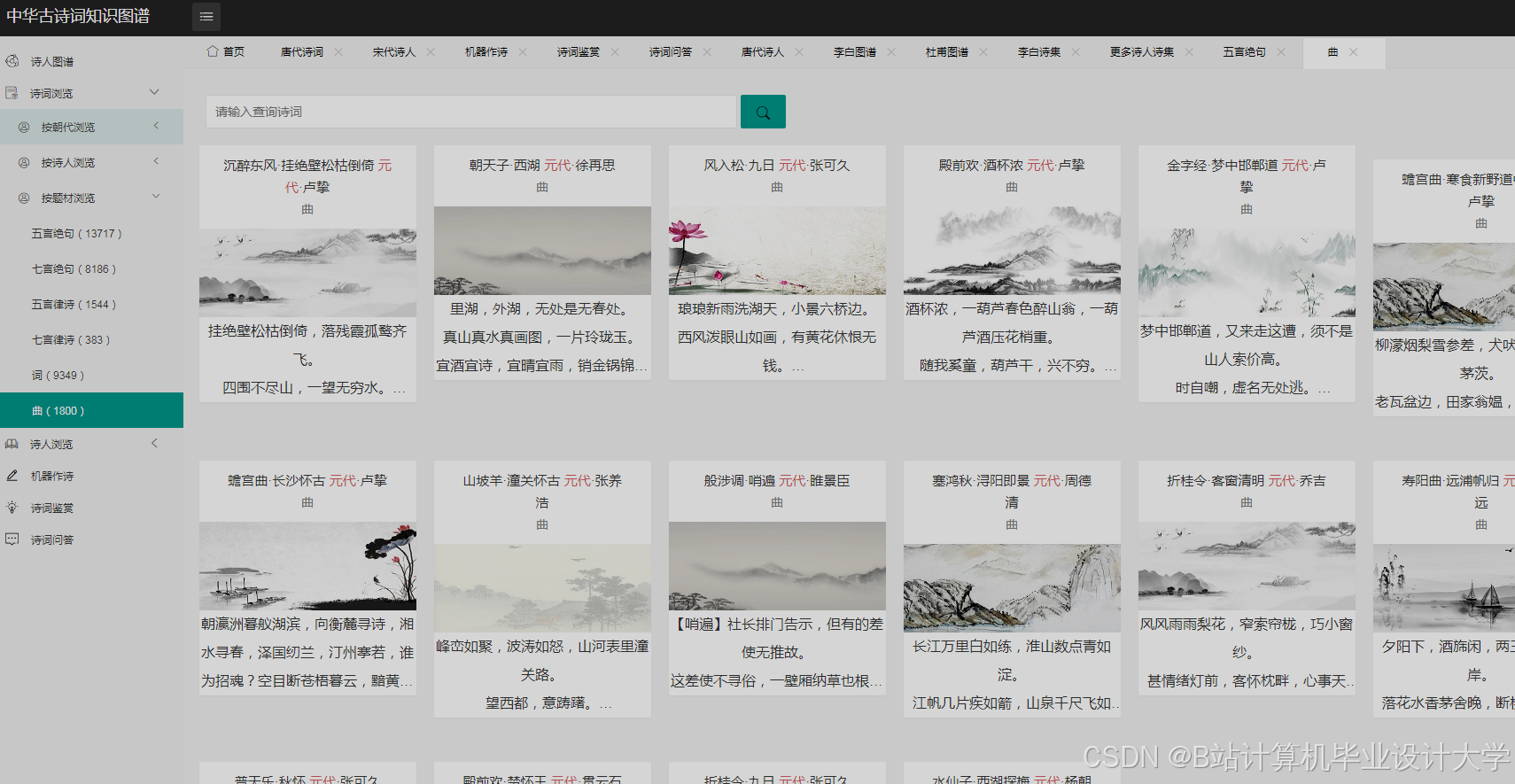
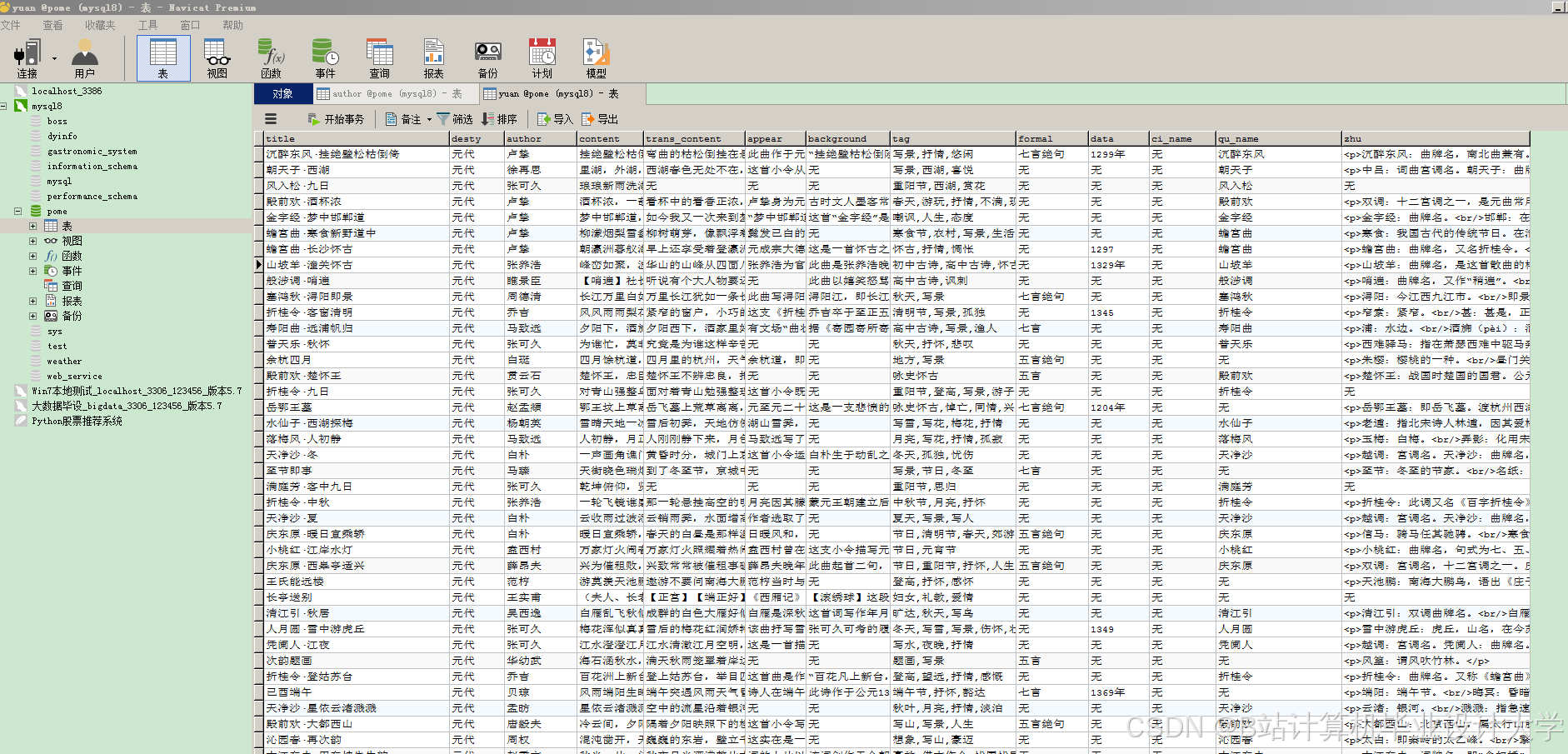
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献213条内容
已为社区贡献213条内容

所有评论(0)