claude +obsidian 建立自己的AI知识库,基于 karpathy
前言
其实最近一直有建立自己的知识库的方法,腾讯有个ima,但是苦于没有linux的模式。一般的知识库呢又是云端的,害,我不想整云端的,我只想本地,昨天刷视频刷到了karpathy的数据库构建方法,我感觉可以试试,应该可以提升自己使用ai的能力。
一、 如何安装claude cli
1. 安装 Node.js
# 添加 NodeSource 仓库
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash -
# 安装 Node.js
sudo apt-get install -y nodejs
安装完成后,在终端运行:
node --version
npm --version

2. 安装 Claude Code
# 全局安装 Claude Code
npm install -g @anthropic-ai/claude-code
执行以下命令,输出版本号即安装成功:
claude --version

二、 配置claude的api
自己搞账号,现在十分的麻烦,而且也不篇一,不如直接咸鱼购买API。我目前使用的是这个店。
之后他直接发给我一个api key,我直接配置环境变量使用就可以了。不同的店这俩可能不一样。
export ANTHROPIC_BASE_URL="https://key.simpleai.com.cn"
export ANTHROPIC_API_KEY="api key"
二、 安装配置obsidian
这个obsidian,我这里只介绍两部分,详细的可以看其他的博客。
1. 如何把obsidian变成ubuntu可以识别的app
🚀 方法一(推荐,最简单)
✅ 用官方 AppImage 正确注册
1️⃣ 找到你的 Obsidian(AppImage)
比如:
~/Downloads/Obsidian-1.4.0.AppImage
2️⃣ 移动到标准位置
mkdir -p ~/.local/bin
mv Obsidian-*.AppImage ~/.local/bin/obsidian
chmod +x ~/.local/bin/obsidian
3️⃣ 创建桌面注册(关键)
创建文件:
nano ~/.local/share/applications/obsidian.desktop
写入:
[Desktop Entry]
Name=Obsidian
Exec=/home/你的用户名/.local/bin/obsidian %u
Type=Application
Terminal=false
MimeType=x-scheme-handler/obsidian;
⚠️ 把路径改成你自己的
4️⃣ 注册协议
xdg-mime default obsidian.desktop x-scheme-handler/obsidian
5️⃣ 更新数据库
update-desktop-database ~/.local/share/applications
🧪 测试(非常关键)
在终端执行:
xdg-open "obsidian://open?vault=auto_drive"
👉 如果成功:
✔ Obsidian 打开
✔ 自动进入 auto_drive
👉 说明 Web Clipper也能用了 ✅
2. 如何使用obsdian的web插件从网上抓数据
https://obsidian.md/clipper
之后设置一下语言和保管的库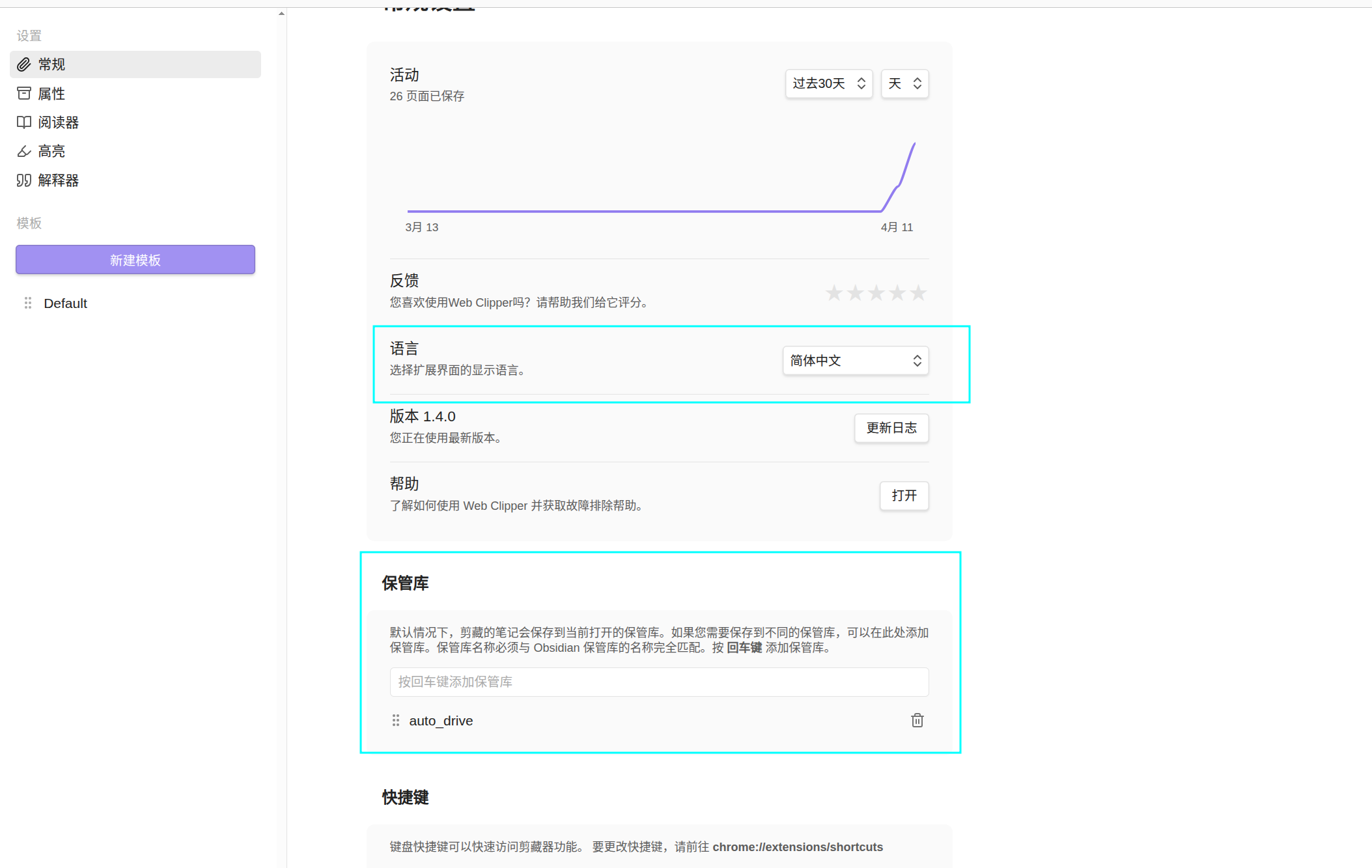
之后保存一下网页默认保存的位置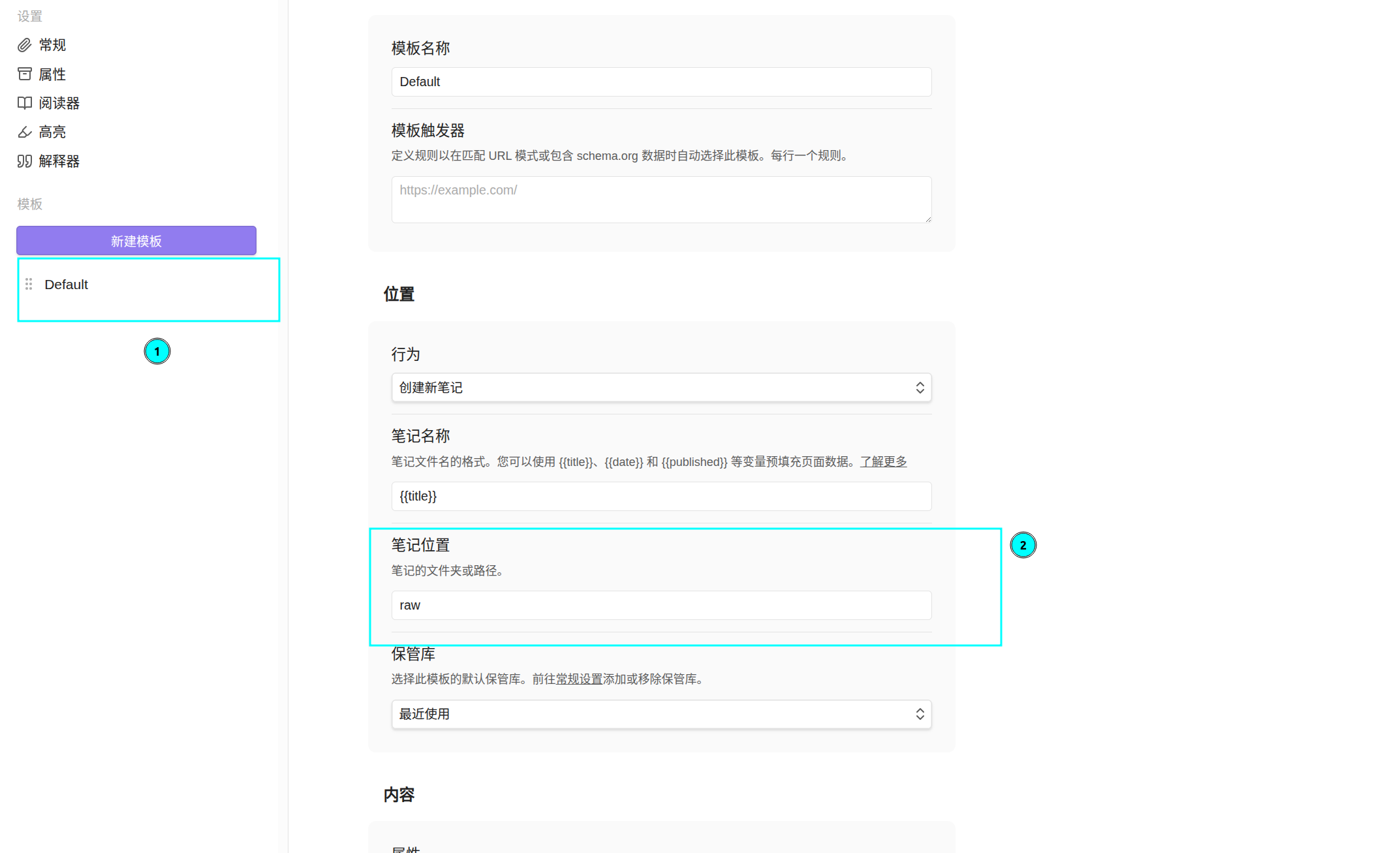
之后右键就有这个候选框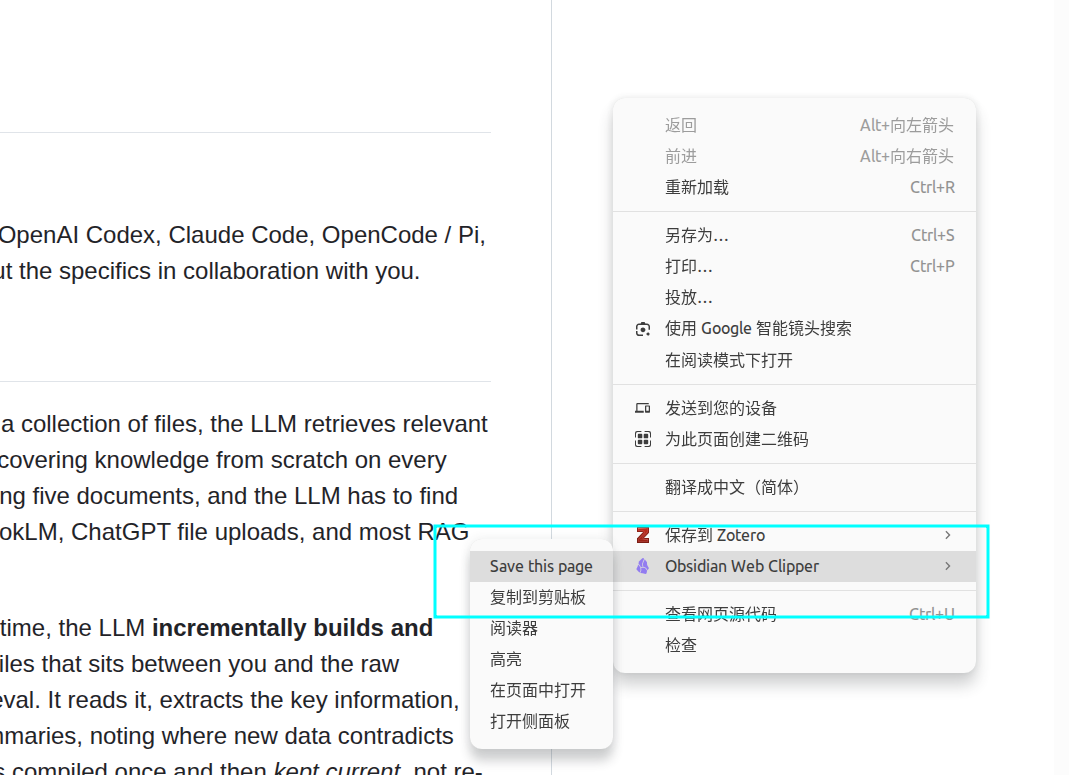
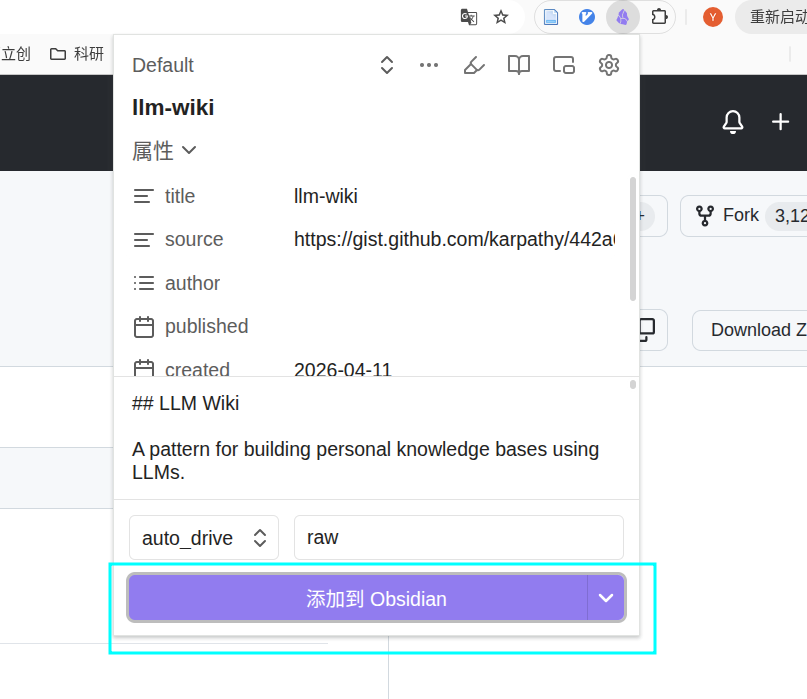
三、 如何构建karpathy的方案
1. 找到他的博客的网页
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
2. 把这个网页保存到obsidian的项目里面
之后在这个项目里面打开claude,之后关键的来了,把这个md发送给claude,说下面的内容
@Clippings/llm-wiki.md 按照karpathy的方法,帮我在这个目录下构建他的目录结构,使用中文。
这就会构建一个系统出来了
3.我可以把他给我写的CLAUDE.md分享出来
LLM Wiki 配置文档
这是一个基于 LLM 的个人知识库系统,用于增量式地构建和维护结构化的知识维基。
核心理念
不同于传统的 RAG 系统在每次查询时从原始文档中检索信息,这个系统会持续构建和维护一个结构化的维基。当添加新的源文档时,LLM 会阅读、提取关键信息,并将其整合到现有维基中——更新实体页面、修订主题摘要、标注矛盾之处、强化或挑战现有的综合分析。
目录结构
/home/yzh/auto_drive/
├── raw/ # 原始源文档(只读,不可修改)
│ ├── assets/ # 图片、附件等资源文件
│ └── [源文档].md # 文章、论文、笔记等
├── wiki/ # LLM 生成和维护的维基页面
│ ├── index.md # 内容索引(按类别组织)
│ ├── log.md # 操作日志(按时间记录)
│ ├── overview.md # 总览页面
│ ├── entities/ # 实体页面(人物、组织、项目等)
│ ├── concepts/ # 概念页面(理论、方法、技术等)
│ ├── sources/ # 源文档摘要页面
│ └── analyses/ # 分析和综合页面
└── CLAUDE.md # 本配置文档
操作流程
1. 摄入(Ingest)
当用户添加新的源文档到 raw/ 目录时:
- 阅读源文档,识别关键信息
- 与用户讨论要点和重点
- 在
wiki/sources/创建摘要页面 - 更新或创建相关的实体页面(
wiki/entities/) - 更新或创建相关的概念页面(
wiki/concepts/) - 更新
wiki/index.md - 在
wiki/log.md追加操作记录
摄入格式规范:
- 源文档摘要页面命名:
wiki/sources/[文档名].md - 实体页面命名:
wiki/entities/[实体名].md - 概念页面命名:
wiki/concepts/[概念名].md
页面模板:
源文档摘要页面:
---
title: [文档标题]
source: [原始文件路径]
date: [摄入日期]
tags: [标签列表]
---
## 概述
[简短概述]
## 关键要点
- 要点1
- 要点2
## 相关实体
- [[实体1]]
- [[实体2]]
## 相关概念
- [[概念1]]
- [[概念2]]
## 详细内容
[详细摘要]
实体页面:
---
title: [实体名称]
type: [人物/组织/项目/产品等]
updated: [最后更新日期]
---
## 基本信息
[实体的基本描述]
## 相关源文档
- [[源文档1]]
- [[源文档2]]
## 相关概念
- [[概念1]]
## 详细信息
[详细内容]
概念页面:
---
title: [概念名称]
category: [类别]
updated: [最后更新日期]
---
## 定义
[概念定义]
## 相关源文档
- [[源文档1]]
## 相关实体
- [[实体1]]
## 详细说明
[详细内容]
2. 查询(Query)
当用户提问时:
- 先阅读
wiki/index.md找到相关页面 - 阅读相关页面内容
- 综合信息并给出带引用的答案
- 如果答案有价值,询问用户是否要将其保存为新的分析页面到
wiki/analyses/
3. 维护(Lint)
定期检查维基健康度:
- 查找页面间的矛盾
- 识别过时的信息
- 发现孤立页面(无入链)
- 找出缺失的概念页面
- 检查缺失的交叉引用
- 建议需要补充的信息
索引和日志
index.md 格式
按类别组织,每个条目包含:链接、一句话摘要、元数据
# 维基索引
## 源文档摘要 (X 篇)
- [[文档1]] - 简短描述 (2026-04-11)
- [[文档2]] - 简短描述 (2026-04-10)
## 实体 (X 个)
- [[实体1]] - 简短描述
- [[实体2]] - 简短描述
## 概念 (X 个)
- [[概念1]] - 简短描述
- [[概念2]] - 简短描述
## 分析 (X 篇)
- [[分析1]] - 简短描述 (2026-04-11)
log.md 格式
按时间倒序记录,每条以统一前缀开始便于解析:
# 操作日志
## [2026-04-11] 摄入 | 文档标题
- 创建源文档摘要:[[sources/文档名]]
- 更新实体页面:[[entities/实体1]], [[entities/实体2]]
- 创建概念页面:[[concepts/概念1]]
## [2026-04-10] 查询 | 用户问题
- 查询相关页面:[[页面1]], [[页面2]]
- 生成答案并保存到:[[analyses/分析标题]]
工作原则
- LLM 完全拥有 wiki/ 目录:创建、更新、维护所有页面
- raw/ 目录只读:LLM 只读取,从不修改
- 使用中文:所有维基页面使用中文撰写
- 保持交叉引用:使用
[[页面名]]格式创建维基链接 - 增量更新:每次摄入新源文档时,更新所有相关页面
- 标注矛盾:当新信息与旧信息冲突时,在相关页面中明确标注
- 保持一致性:确保所有页面间的信息一致
- 用户主导:用户负责策划源文档、指导分析、提出问题;LLM 负责所有维护工作
当前状态
- 维基已初始化
- 等待用户添加源文档并开始摄入流程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)