CUDA 编程系列(四)《CUDA 程序迁移至天数智芯 GPU》
目录
本文主讲从 CUDA 到国产 GPU,如何高效迁移现有代码,详解天数智芯 GPU 的迁移策略与性能优化方法。前置课程为《内存模型与规约优化》。
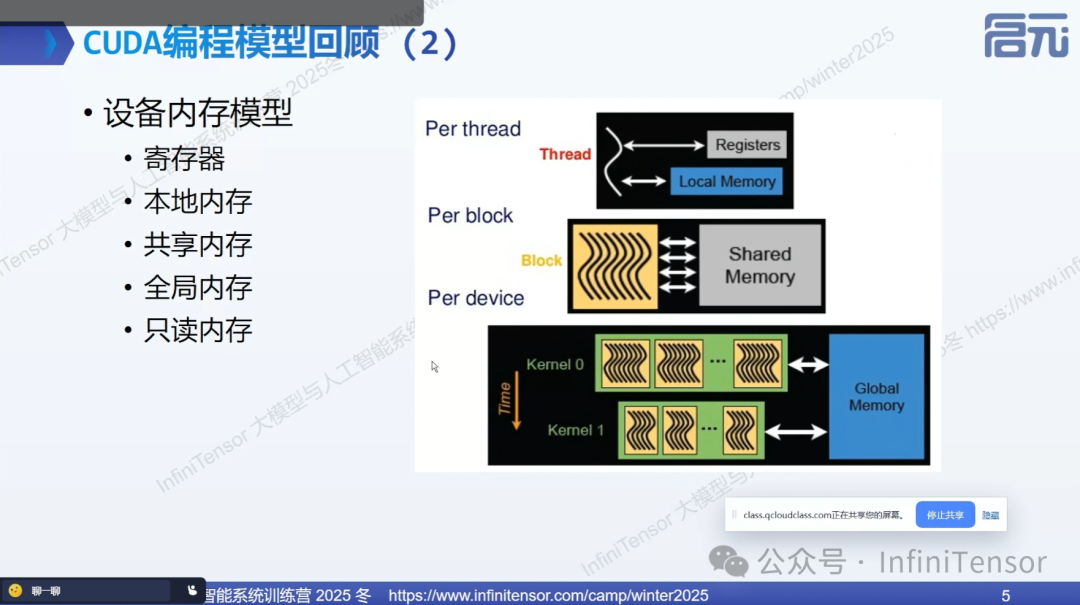
天数智芯GPU架构特性
随着国产 GPU 技术的快速发展,越来越多的 AI 和高性能计算应用开始考虑从 NVIDIA GPU 向国产 GPU 平台迁移。天数智芯作为国内领先的 GPU 厂商,其产品在架构设计上与CUDA生态保持高度兼容,为现有 CUDA 程序的迁移提供了便利条件。
然而,完全兼容不等于直接替换。由于硬件架构的差异,简单的重新编译往往无法获得理想的性能表现。
核心架构差异
天数智芯 GPU 虽然在编程模型上与 CUDA 兼容,但在硬件细节上存在重要差异:
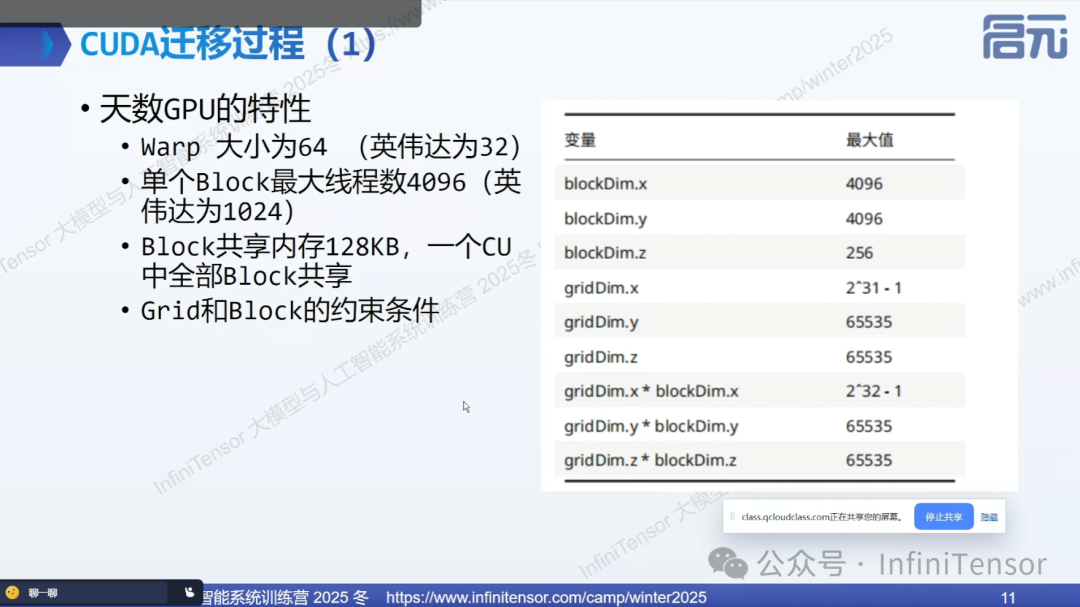
1. Warp 大小不同
-
• NVIDIA GPU:Warp 大小为32个线程
-
• 天数智芯 GPU:Warp 大小为64个线程
影响:原有的 block 大小设置可能导致"尾巴效应",即最后一个 warp 中部分线程处于空闲状态,造成资源浪费。
2. Block 线程限制
-
• NVIDIA GPU:单个 block 最多1024个线程
-
• 天数智芯GPU:单个 block 最多4096个线程
优势:更大的 block 线程数提供了更高的调度灵活性,有利于提高资源利用率。
3. 共享内存配置
-
• 典型配置:每个计算单元(CU)配备 128KB 共享内存
-
• 调度影响:block 使用的共享内存大小直接影响可并行调度的 block 数量
编程模型兼容性
天数智芯 GPU 实现了 CUDA 常用 API 的完整兼容:
-
• 主机端 API(如 cudaMalloc、cudaMemcpy 等)
-
• 设备端内置函数(数学函数、原子操作等)
-
• 编程语法(
__global__、__device__等关键字)
关键结论:标准的CUDA程序通常无需修改源代码即可在天数智芯GPU上运行。
CUDA 程序迁移过程
需要修改的代码类型
1. PTX 汇编代码
-
• 问题:PTX 是 NVIDIA 特有的中间汇编语言
-
• 解决方案:重写为标准 CUDA C++ 代码
-
• 建议:尽量避免使用汇编代码,优先使用高级语言实现
2. 非标准 CUDA 扩展
-
• 问题:某些 NVIDIA 特有的 API 或编译器扩展
-
• 检查方法:编译时查看未定义符号错误
-
• 解决方案:使用天数智芯提供的等效 API 替代
3. 硬件相关假设
-
• 问题:代码中硬编码了 NVIDIA GPU 的硬件参数
-
• 示例:假设 warp 大小为 32,或 block 最大线程数为 1024
-
• 解决方案:使用运行时查询或宏定义来适配不同硬件
编译错误排查
常见的编译错误主要来源于:
-
• 非标准C++代码:不同编译器对非标准代码的容错处理不同
-
• 未初始化内存:某些编译器自动初始化内存为 0,而其他编译器不会
-
• API缺失:天数智芯 SDK 可能尚未实现某些较新的 CUDA API
调试建议:仔细阅读编译错误信息,逐条修正代码规范性问题。
编译环境配置
SDK 安装步骤
-
1. 依赖准备:
-
• 安装 C/C++ 编译器和标准库
-
• 安装 make 工具
-
• 安装 Linux 内核头文件
-
-
2. SDK 安装:
-
• 下载天数智芯 SDK 安装包
-
• 按照官方文档执行安装脚本
-
• 验证驱动安装(执行
ixsmi命令)
-
- 3. 环境变量配置:
# 添加编译器路径 export PATH=$PATH:/path/to/tianshu/bin # 添加动态库路径 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/tianshu/lib64
编译器选择
-
• 主机端代码(纯 CPU 代码):可使用系统默认编译器
-
• 设备端代码(包含核函数):必须使用天数智芯提供的编译器
-
• 混合代码(.cu 文件):必须使用天数智芯编译器
编译配置详解
基础编译命令
# 天数智芯编译器
tianshu-c++
# 必需参数
-fPIC # 生成位置无关代码(用于动态库)
--gpu-architecture=iv11 # 指定GPU架构(根据实际型号调整)
--cuda-path=/path/to/sdk # 指定SDK路径
# 标准参数
-I/path/to/include # 头文件路径
-L/path/to/lib64 # 库文件路径
-lcuda # 链接CUDA运行时库Makefile 迁移
Makefile 迁移主要涉及变量定义的修改:
# 原NVIDIA配置
NVCC = nvcc
NVCC_FLAGS = -arch=sm_75 -O3
# 天数智芯配置
TS_CC = tianshu-c++
TS_FLAGS = --gpu-architecture=iv11 -O3
# 编译规则
%.o: %.cu
$(TS_CC) $(TS_FLAGS) -c $< -o $@关键点:移除 NVIDIA 特有的编译参数,替换为天数智芯对应的参数。
CMake 配置
天数智芯提供了增强版 CMake,简化了配置过程:
1. 安装天数智芯 CMake
# 安装增强版CMake
./tianshu-cmake-installer.sh --prefix=/opt/tianshu-cmake
# 配置环境变量
export PATH=/opt/tianshu-cmake/bin:$PATH2. CMakeLists.txt 配置
cmake_minimum_required(VERSION 3.18)
project(MyProject LANGUAGES CXX CUDA)
# 查找天数智芯CUDA支持
find_package(CUDA REQUIRED)
# 包含头文件和库路径
include_directories(${TIANSHU_INCLUDE_DIRS})
link_directories(${TIANSHU_LIBRARY_DIRS})
# 设置GPU架构
set(CMAKE_CUDA_ARCHITECTURES "iv11")
# 添加可执行文件
cuda_add_executable(myapp main.cu utils.cu)
# 链接运行时库
target_link_libraries(myapp ${TIANSHU_CUDA_LIBRARIES})天数 SDK 中的常用工具
天数智芯 SDK 提供了一套完整的开发辅助工具,涵盖了从状态监控、性能分析到代码调试的全流程。为了方便 CUDA 开发者快速上手,下表整理了主要工具及其功能,并列出了与 NVIDIA 工具链的对应关系。
1. 系统管理与监控
-
• ixSMI (System Management Interface)
-
• 对标工具:
nvidia-smi -
• 功能简介:提供系统管理信息,用于对天数智芯加速卡进行实时监控,包括查看驱动版本、设备温度、功耗及显存使用率等关键指标。
-
2. 性能分析 (Profiling)
-
• ixPROF (Profiler 工具)
-
• 对标工具:
nvprof/nsys(命令行模式) -
• 功能简介:用于收集和查看追踪数据 (Trace),帮助开发者了解加速卡的详细运行状态,从而进行系统级的性能瓶颈分析。
-
-
• ixSYS (可视化性能分析工具)
-
• 对标工具:
Nsight Systems -
• 功能简介:在 CUDA 应用程序运行时对系统进行采样并抓取 Trace。其核心优势是支持 Web 图形化展示,开发者可以通过浏览器直观地查看统计图表和性能流水线。
-
3. 代码调试
-
• ixGDB (代码调试工具)
-
• 对标工具:
cuda-gdb -
• 功能简介:针对天数智芯加速卡的开源调试工具,支持对运行在 GPU 上的 CUDA 应用程序进行断点调试、变量检查和单步执行。
-

总结
CUDA 程序迁移至天数智芯 GPU 是一个系统工程,需要从兼容性评估、代码适配、编译配置到性能优化的全流程考虑。虽然天数智芯 GPU 在编程模型上保持了良好的 CUDA 兼容性,但要获得最佳性能仍需针对其硬件特性进行专门优化。随着国产 GPU 生态的不断完善,相信未来会有更多优秀的 AI 和高性能计算应用在国产平台上发挥出色性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)