让机器“读懂”人类语言
一、 词向量的训练原理
词向量的核心思想是分布式假设(Distributional Hypothesis):上下文相似的词,其语义也相似。通过训练,我们将每个词映射到一个固定维度的稠密实数向量(Dense Vector)中,使得语义相近的词在向量空间中的距离也相近。
目前最经典的词向量模型是 Google 提出的 Word2Vec,它包含两种主要的训练架构:
1. CBOW (Continuous Bag-of-Words)
CBOW 模型的原理是通过上下文的词来预测中心词。
假设有一句话:“我 喜欢 学习 人工智能”,如果滑动窗口大小为 1,当中心词是“学习”时,上下文词是“喜欢”和“人工智能”。CBOW 会将上下文词的向量取平均或求和,输入到神经网络中,通过 Softmax 层输出预测中心词为“学习”的概率。
2. Skip-Gram
与 CBOW 相反,Skip-Gram 的原理是通过中心词来预测上下文的词。它在大型语料库和生僻词的处理上表现更好。
数学推导(以 Skip-Gram 为例):
给定一个包含 T$个词的训练语料库 w_1, w_2, w_3, w_T,Skip-Gram 的目标是最大化平均对数概率:
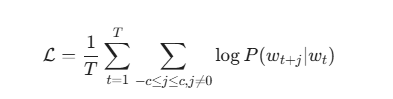
其中,c是上下文窗口的大小,w_t 是中心词,w_{t+j}是上下文词。
概率 P(w_O | w_I) 通常通过 Softmax 函数定义:
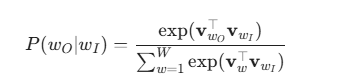
其中,v_w 和 v_w_O 分别是词 w 作为中心词和上下文词时的向量表示,W 是词表的大小。
由于直接计算上述 Softmax 的分母计算量过大(需要遍历整个词表),实际训练中通常采用**负采样(Negative Sampling)技术,将多分类问题转化为二分类问题(判断目标词是否是真实的上下文),从而极大提升训练效率。
二、 语句相似度的计算原理
获得词向量后,我们需要将“词”升级为“句”。最基础且行之有效的方法是对句子中所有词的词向量进行聚合(如求平均值),得到句向量(Sentence Vector)。
获取句向量后,我们通常使用**余弦相似度(Cosine Similarity)**来衡量两个句子在多维空间中的方向差异。
余弦相似度公式:
假设有两个句向量和
,它们之间的余弦相似度计算如下:
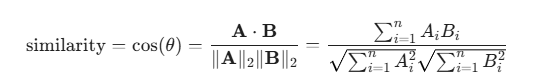
-
余弦值越接近 1,说明两个向量的方向越一致,句子语义越相似。
-
余弦值越接近 0,说明两者正交,相关性低。
1. 三大语句相似度算法大比拼
获取词向量后,如何更好地构建“句向量”?进阶代码实现了三种方法,并进行了对比:
| 方法 | 原理说明 | 优点 | 缺点 |
| 平均词向量 | 直接对句中所有词向量求平均。 | 计算极快,实现简单。 | 赋予了罕见词和常见词相同的权重,不够精确。 |
| TF-IDF 加权 | 计算词频-逆文档频率,作为词向量相加时的权重。 | 突出了句子中的“核心词”(关键词权重更大)。 | 需要额外的 TF-IDF 训练步骤。 |
| WMD (词移距离) | 计算将一个句子的所有词汇“移动”到另一个句子所需的最小距离。 | 不需要显式构建句向量,直接对比,准确率极高。 | 计算复杂度高,处理长文本时速度较慢。 |
三、 Python 代码实现与可视化
以下代码将使用 gensim 库训练一个简单的 Word2Vec 模型,并使用 scikit-learn 和 seaborn 进行降维可视化和相似度热力图展示。
环境依赖: 请确保安装了相关库:
pip install gensim scikit-learn matplotlib seaborn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from sklearn.metrics.pairwise import cosine_similarity
# 设置 matplotlib 支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows 用户使用黑体
# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # Mac 用户请取消此行注释并使用此行
plt.rcParams['axes.unicode_minus'] = False
# 1. 准备训练语料(已分词的二维列表)
sentences = [
["我", "喜欢", "学习", "人工", "智能"],
["他", "热爱", "研究", "机器", "学习"],
["深度", "学习", "是", "人工", "智能", "的", "分支"],
["今天", "天气", "非常", "不错"],
["明媚", "的", "阳光", "让", "人", "心情", "舒畅"],
["我", "喜欢", "吃", "苹果", "和", "香蕉"],
["水果", "富含", "维生素", "对", "身体", "好"]
]
# 2. 训练 Word2Vec 词向量模型
# vector_size: 词向量维度, window: 上下文窗口, min_count: 忽略词频小于该值的词
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=1, epochs=100)
# ==========================================
# 绘图 1:词向量二维空间 PCA 散点图展示
# ==========================================
words = list(model.wv.index_to_key)
word_vectors = np.array([model.wv[w] for w in words])
# 使用 PCA 将 50 维向量降维至 2 维以便可视化
pca = PCA(n_components=2)
word_vectors_2d = pca.fit_transform(word_vectors)
plt.figure(figsize=(10, 6))
plt.scatter(word_vectors_2d[:, 0], word_vectors_2d[:, 1], edgecolors='k', c='skyblue')
for i, word in enumerate(words):
plt.annotate(word, xy=(word_vectors_2d[i, 0], word_vectors_2d[i, 1]),
xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', fontsize=12)
plt.title("词向量 PCA 降维可视化", fontsize=16)
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()
# ==========================================
# 3. 语句相似度计算
# ==========================================
def get_sentence_vector(sentence, model):
"""通过对句子中的词向量求平均,获取句向量"""
vectors = [model.wv[word] for word in sentence if word in model.wv]
if len(vectors) == 0:
return np.zeros(model.vector_size)
return np.mean(vectors, axis=0)
# 定义要比较相似度的三个测试句子
test_sentences = [
["我", "非常", "喜欢", "人工", "智能"], # 句子 A (与 AI 相关)
["机器", "学习", "非常", "有趣"], # 句子 B (与 AI 相关)
["今天", "的", "阳光", "很", "温暖"] # 句子 C (与天气相关)
]
sentence_labels = ["句子A: 我非常喜欢人工智能", "句子B: 机器学习非常有趣", "句子C: 今天的阳光很温暖"]
# 计算句向量
sent_vectors = np.array([get_sentence_vector(sent, model) for sent in test_sentences])
# 计算余弦相似度矩阵
sim_matrix = cosine_similarity(sent_vectors)
# ==========================================
# 绘图 2:语句相似度热力图展示
# ==========================================
plt.figure(figsize=(8, 6))
sns.heatmap(sim_matrix, annot=True, cmap="YlGnBu", fmt=".3f",
xticklabels=["句子A", "句子B", "句子C"],
yticklabels=sentence_labels)
plt.title("语句余弦相似度热力图", fontsize=16)
plt.yticks(rotation=0)
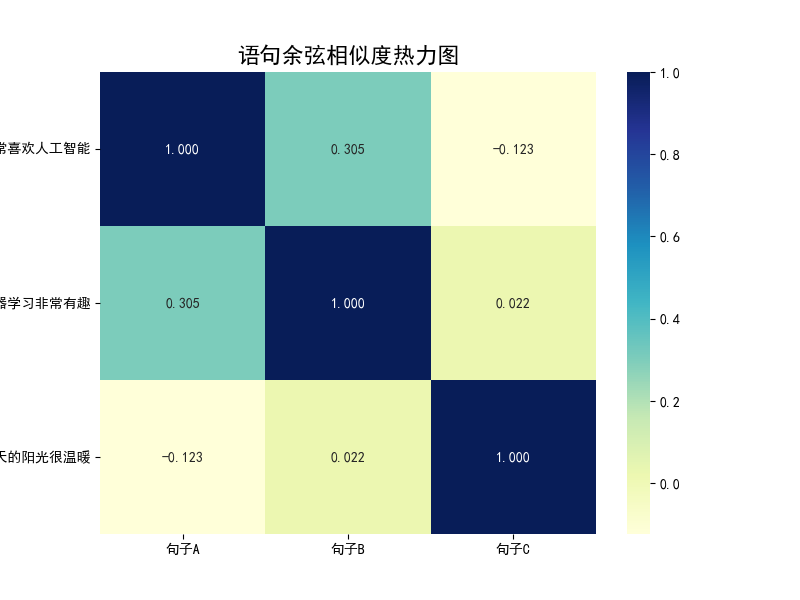
plt.show()代码运行效果说明:
-
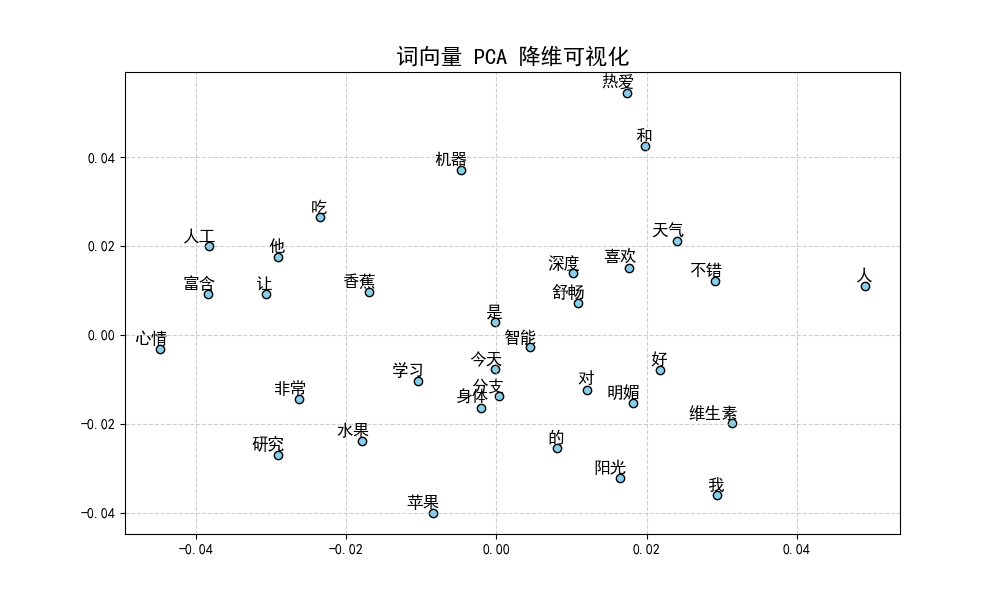
词向量散点图: 运行代码后,您会看到一张散点图。由于模型捕捉了上下文语义,您会发现“人工”、“智能”、“机器”、“学习”这些词在二维平面上聚集得比较近,而“天气”、“阳光”等词则会分布在图的另一个区域。
-
相似度热力图: 热力图会直观显示不同句子的相似度得分。由于句子 A 和 B 都涉及 AI 领域,包含相似上下文的词汇,它们之间的余弦相似度得分会较高(颜色较深);而句子 C 讨论的是天气,与 A 和 B 的得分会明显偏低。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)