白话详解MCP原理及作用
目录
5.6.MCP 与 Function Calling 的关系
7.2.协议层(Application Layer)- 上层
1.MCP的作用简介
解决AI 模型需要访问各种外部资源(数据库、API、文件系统、第三方服务等),以前每个集成都要单独写适配代码,MCP 把这个过程标准化了。
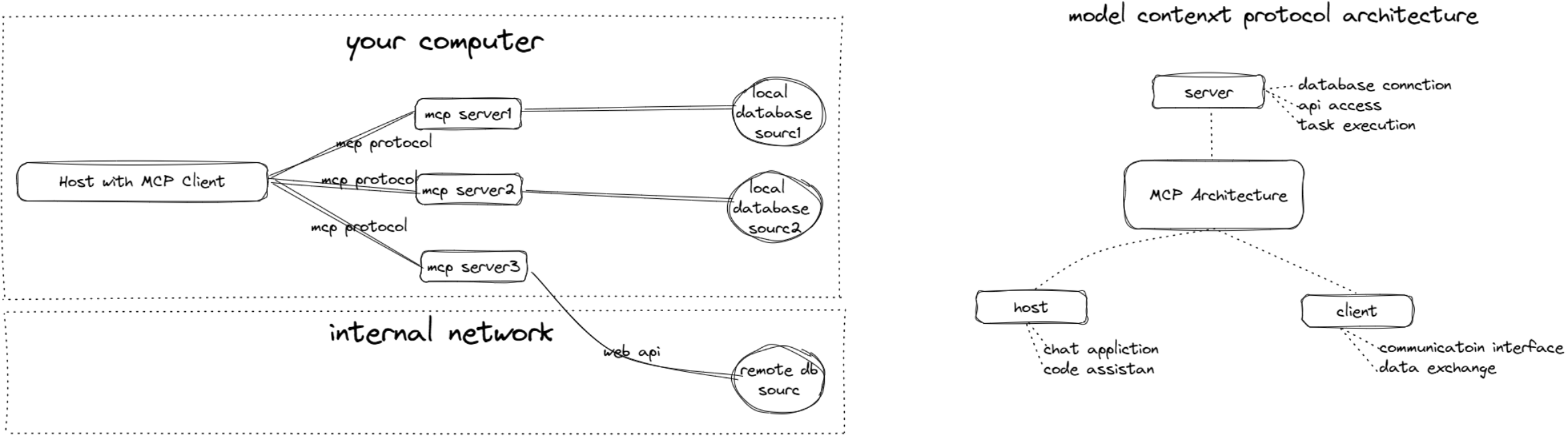
2. MCP标准化通信协议及采用多对一的“总线”模式
- MCP 参考客户端-服务器 (Client-Server) 架构
- ⼀个应⽤(Host with MCP Client),可以同时连接多个 MCP Server
- 每个 Server 专注于⼀项能⼒,⽐如:
- filesystem-server:负责读写本地⽂件。
- git-server:负责执⾏ Git 命令。
- github-server:负责调⽤ GitHub API。
- MCP Host (应⽤):⽤户直接交互的前端,如 IDE 插件。它内置了 MCP Client,如claude desktop、cursor、cline、cherry studio等
- MCP Client (客户端):Host 中负责说“MCP 语⾔”的模块,与 Server 通信。
- MCP Server (服务器):暴露数据和⼯具的本地进程,是你的数据和能⼒的“代⾔⼈”。
- Data/Service(数据/服务):Server 背后连接的真实世界,可以是本地⽂件,也可以是远程API。
3.MCP与Agent 开发的关系
3.1. 构建"原子能力 Agent"的基石
3.1.1.不采用MCP
问题:
❌ 重复造轮子
❌ 质量参差不齐
❌ 维护成本高
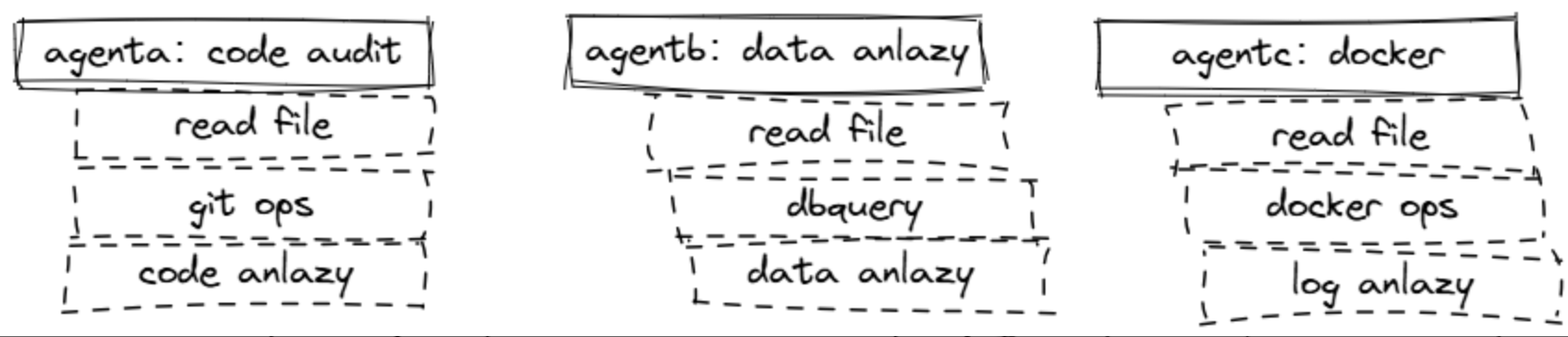 3.1.2.采用MCP
3.1.2.采用MCP
优势:
✅ 快速装备原子能力
✅ 专注业务逻辑
✅ 质量有保障
✅ 社区共建共享
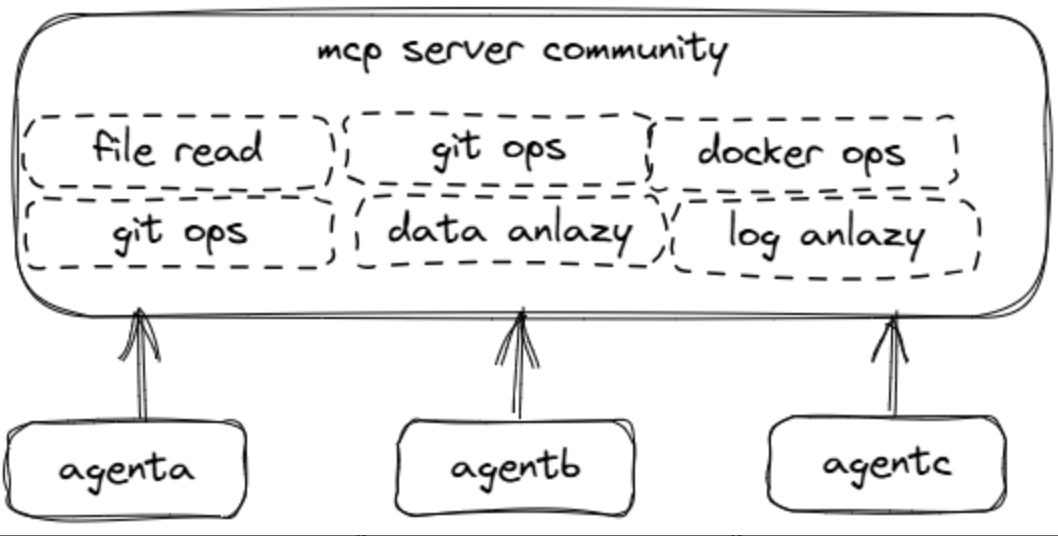
3.2.MCP去构建 Agent 和复杂工作流
- 智能映射: 将 AI 的抽象请求映射到具体工具或数据
- 访问控制: 保障并控制工具的访问权限
- 多步骤编排: 处理复杂的多步骤工具使用流程
- 万物互联: 连接 API、文件、应用程序
- 可靠执行: 使 AI 在执行真实世界任务时更加可靠
4.MCP核心价值
4.1. 数据安全与隐私
4.1.1 控制权从"服务器中心"到"用户中心"
传统 C/S:服务器是控制中心,客户端是"哑终端"
MCP:Host(本地应用)是控制中心,服务器是"工具提供者"
核心价值:
- 用户掌握数据流向和处理逻辑
- 可自由组合本地和云端能力
- 服务器故障不影响本地功能
4.1.2. 数据主权从"必须上传"到"本地优先"
传统 C/S:数据必须上传到服务器才能处理
风险:
• 代码必须上传到云端
• 无法保证不被记录
• 不符合企业安全要求
MCP:数据优先在本地处理,仅在必要时访问云端
核心价值:
- 敏感数据不离开本地环境
- 符合企业安全和合规要求
- 用户完全控制隐私边界
4.2.架构弹性且从"单一模式"到"混合编排"
传统 C/S:要么纯本地,要么纯云端,二选一
MCP:通过统一协议,无缝融合本地和云端资源
核心价值:
- 本地工具提供低延迟和隐私保护
- 云端服务提供强大能力和实时数据
- Host 智能调度,用户无感知切换
- 离线降级,在线增强
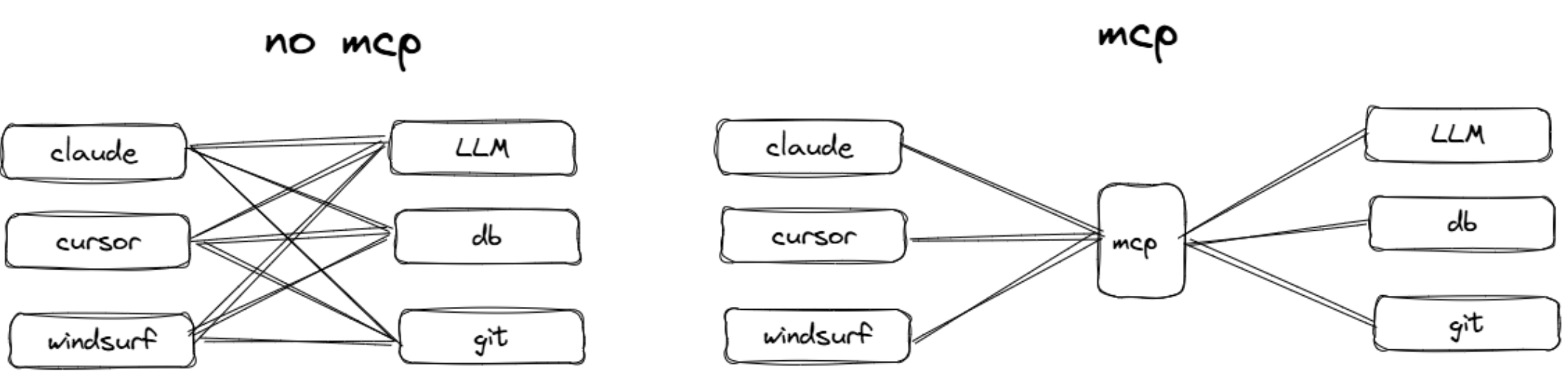
4.3.MCP解决大模型接口间互不兼容
4.3.1无MCP则需要针对不同的大模型定义不同的接口
// 同一个功能,四个大模型,四种写法
// ❌ OpenAI GPT-4 的写法
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,如:北京、上海"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
// ❌ Anthropic Claude 的写法
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"input_schema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,如:北京、上海"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
// ❌ Google Gemini 的写法
{
"function_declarations": [{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "OBJECT",
"properties": {
"location": {
"type": "STRING",
"description": "城市名称,如:北京、上海"
},
"unit": {
"type": "STRING",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}]
}
// ❌ Meta Llama 的写法
{
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"location": {
"type": "string",
"description": "城市名称,如:北京、上海",
"required": true
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"required": false
}
}
}
}]
}
4.3.2.有MCP则AI 开发不再关心模型间的差异
有MCP协议自动转为对应的大模型(OpenAPI,Claude,Gemini,DeepSeek)的格式
from mcp.server import Server
from mcp.types import Tool
# 1. 定义 MCP Server(只写一次)
server = Server("weather-service")
@server.tool()
async def get_weather(location: str, unit: str = "celsius") -> dict:
# 实际的天气查询逻辑
return {
"location": location,
"temperature": 25,
"unit": unit,
"condition": "晴天"
}
# 2. 启动 MCP Server
if __name__ == "__main__":
server.run()5.MCP的三种能力
5.1.三种能力之间的关系
历史困境:传统 LLM 只能生成文本,与真实环境隔离,无法感知和改变世界
MCP 突破:通过三种机制,构建"感知 → 理解 → 行动"的完整循环
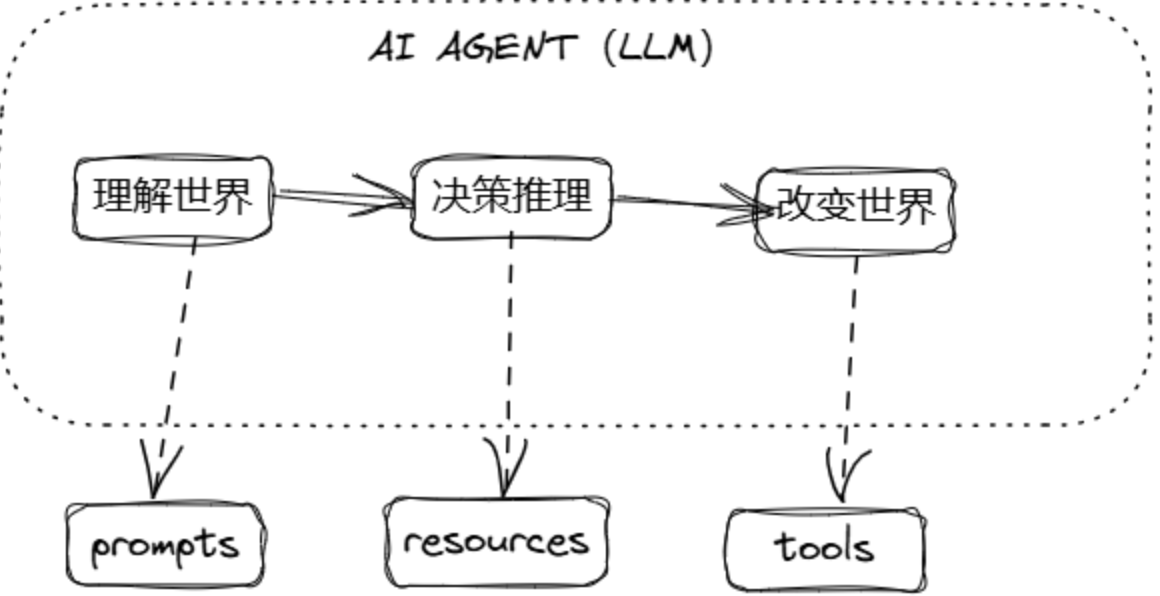
5.2. Prompts
定义:预设的提示词模板,引导模型如何思考和提问
本质:封装了领域专家的最佳实践和参数优化,降低门槛使用,提升交互确定性
// MySQL MCP Server 提供的 Prompt 模板
{
"name": "analyze_slow_query",
"description": "分析慢查询并提供优化建议",
"prompt": `你是 MySQL 性能优化专家。请按以下步骤分析:
1. 执行 EXPLAIN 分析查询计划
2. 检查索引使用情况(type, key, rows)
3. 分析 Extra 字段(Using filesort, Using temporary)
4. 评估表统计信息是否过期
5. 提供具体优化建议(索引、查询重写、配置调整)
查询语句:{{query}}
数据库版本:{{version}}
表结构:{{schema}}`,
"arguments": [
{"name": "query", "required": true},
{"name": "version", "default": "5.7.32"},
{"name": "schema", "required": false}
]
}
// 价值:
// ✅ 用户无需记住分析步骤
// ✅ 确保分析的完整性和专业性
// ✅ 结果格式统一,便于自动化处理
5.3. Resources
定义:静态知识单元,为模型提供事实依据
本质:用户主动选择的、可信的上下文信息,显式知识注,沉淀与复用,上下文可控
场景:基于项目规范的代码生成
❌ 没有 Resources:
用户:"按照我们的编码规范生成登录模块"
→ 模型使用通用规范
→ 结果不符合团队标准
✅ 使用 Resources:
MCP Server 提供 Resource:
{
"uri": "resource://coding-standards/backend",
"name": "后端编码规范",
"mimeType": "text/markdown",
"content": `
# 后端编码规范
## 错误处理
- 使用自定义异常类 BusinessException
- 统一返回格式:{code, message, data}
## 数据库访问
- 禁止使用 SELECT *
- 必须使用参数化查询防止 SQL 注入
...
`
}
用户:"按照我们的编码规范生成登录模块"
→ 模型自动加载 Resource
→ 生成的代码完全符合团队规范
5.4. Tools
定义:工具执行后的返回结果,作为模型的动态上下文
本质:来自真实世界的实时反馈,帮助模型校准认知
5.4.1.功能1:理解世界的"信息源"(Sensor)
核心:工具执行结果是模型下一步决策的关键信息
用户:"MySQL 服务器响应很慢"
[循环 1] 观察
→ Tool: check_server_status()
→ 结果(动态上下文):"CPU 使用率 95%,慢查询 127 条"
→ 模型理解:可能是查询性能问题
[循环 2] 深入观察
→ Tool: get_slow_queries(limit=5)
→ 结果(动态上下文):
"SELECT * FROM orders WHERE status = 'pending' (执行 2.3s, 扫描 50万行)"
→ 模型理解:全表扫描导致性能问题
[循环 3] 验证假设
→ Tool: check_indexes(table='orders')
→ 结果(动态上下文):"表 orders 没有 status 字段的索引"
→ 模型确认:缺少索引是根本原因
[循环 4] 执行修复
→ Tool: create_index(table='orders', column='status')
→ 结果(动态上下文):"索引创建成功,耗时 1.2s"
[循环 5] 验证效果
→ Tool: test_query_performance()
→ 结果(动态上下文):"查询时间从 2.3s 降至 0.05s"
→ 模型结论:问题已解决
关键:每个 Tool 的执行结果,都成为下一步决策的依据
5.4.2.功能2:执行具有副作用的操作
定义:发送邮件、创建文件、下单购物等具体操作
本质:对外部环境产生实际、持久的改变
核心:执行带有副作用的操作,产生真实影响
用户:"自动优化生产数据库"
Kiro 执行流程:
# 1. 理解世界(只读)
Tool: analyze_slow_queries()
→ 结果:"发现 5 个慢查询"
Tool: check_index_usage()
→ 结果:"表 orders 缺少 user_id 索引"
# 2. 改变世界(写入)
Tool: create_index(
table="orders",
column="user_id",
name="idx_user_id"
)
→ 副作用:数据库中创建了新索引
→ 副作用:磁盘空间减少 50MB
→ 副作用:查询性能提升
Tool: update_table_statistics(table="orders")
→ 副作用:优化器统计信息更新
Tool: log_optimization(
action="create_index",
table="orders",
impact="query_time: 2.3s → 0.05s"
)
→ 副作用:审计日志中记录了操作
Tool: send_report(
to="dba@example.com",
report="optimization_report.pdf"
)
→ 副作用:发送了优化报告邮件
关键:这些操作对生产环境产生了实际影响
5.5 MCP在MySQL慢查询自动优化中流程图
用户:"优化生产数据库的慢查询"
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段 1:引导(Prompts)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
加载 Prompt 模板:
{
"name": "database_optimization_workflow",
"steps": [
"1. 分析慢查询日志",
"2. 检查索引使用情况",
"3. 评估表统计信息",
"4. 生成优化建议",
"5. 执行优化操作",
"6. 验证优化效果"
]
}
价值:将模糊问题转化为结构化流程
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段 2:知识注入(Resources)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
加载相关 Resources:
Resource 1: "mysql_optimization_guide.md" → 提供优化最佳实践
Resource 2: "production_db_schema.sql"→ 提供表结构信息
Resource 3: "last_optimization_report.md"→ 提供历史优化记录(避免重复操作)
价值:模型基于准确的、项目特定的知识
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段 3:理解世界(Tools as Sensors)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Tool: get_slow_queries(hours=24)→ 结果:"发现 15 个慢查询,总耗时 45 分钟" 模型理解:性能问题严重
Tool: analyze_query(query="SELECT * FROM orders WHERE status='pending'")→ 结果:"全表扫描,扫描 50 万行,耗时 2.3s" 模型理解:缺少索引
Tool: check_index(table="orders", column="status")→ 结果:"不存在索引" 模型确认:需要创建索引
Tool: estimate_index_size(table="orders", column="status") 结果:"预计索引大小 15MB,创建耗时 1-2 秒" 模型理解:操作成本可接受
价值:基于真实数据做决策,而非猜测
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段 4:改变世界(Tools as Actors)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Tool: create_index(
table="orders",
column="status",
name="idx_status"
)
→ 副作用:数据库中创建了索引
→ 结果:"索引创建成功"
Tool: update_statistics(table="orders")→ 副作用:优化器统计信息更新
Tool: test_query_performance(query="...")→ 结果:"查询时间从 2.3s 降至 0.05s" 模型验证:优化成功
Tool: generate_report(
optimizations=[...],
output="optimization_report_2026-03-11.md"
)
→ 副作用:创建了优化报告文件
Tool: send_notification(
to="dba-team@example.com",
subject="数据库优化完成",
body="已优化 15 个慢查询,平均性能提升 45 倍"
)
→ 副作用:发送了邮件通知
价值:自动执行完整的优化流程,产生真实影响
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
阶段 5:知识沉淀(Resources)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Tool: register_resource(
uri="resource://optimization-reports/2026-03-11",
content="{{optimization_report_2026-03-11.md}}"
)
→ 将本次优化报告注册为 Resource
→ 下次优化时自动加载,避免重复操作
价值:知识积累,持续改进
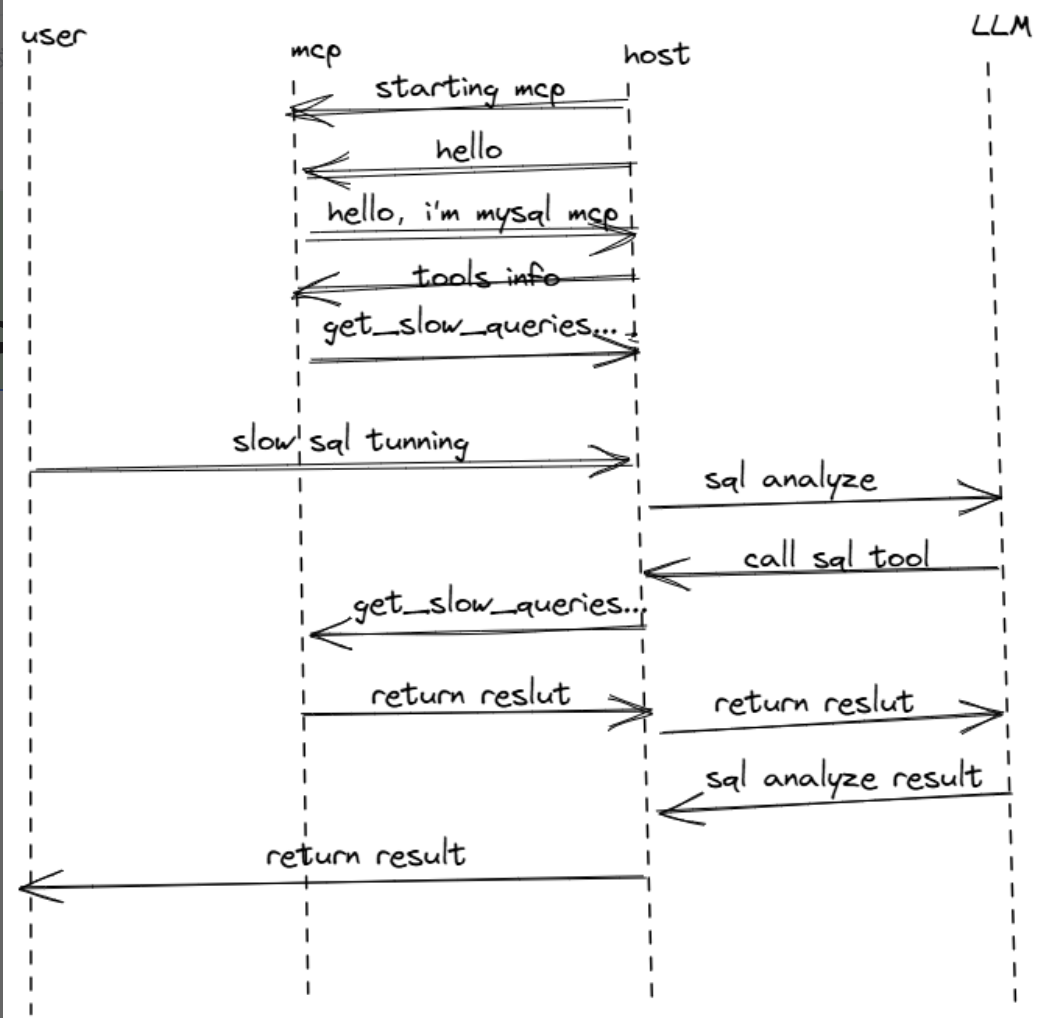
5.6.MCP 与 Function Calling 的关系
Function Calling(函数调用) = AI 的"决策大脑"
MCP(模型上下文协议) = 标准化的"工具基础设施"
两者是互补关系,缺一不可:
- Function Calling 赋予 AI "知道该做什么"的智能
- MCP 提供 AI "能够做什么"的能力边界
[Function Calling 决策]
1. 识别需要调用 run_explain 工具 → MCP 服务器执行 EXPLAIN,返回执行计划
2. 分析结果,决定调用 check_indexes 工具 → MCP 服务器查询索引信息,发现缺少 user_id 索引
3. 决定调用 analyze_table_stats 工具 → MCP 服务器获取表统计信息(100万行数据)
4. 决定调用 suggest_index 工具 → MCP 服务器计算最优索引方案
5. 请求用户批准后,调用 create_index 工具 → MCP 服务器安全地创建索引
6. 调用 verify_optimization 工具 → MCP 服务器验证优化效果(查询时间从 2.3s 降至 0.05s)6.MCP 通信技术架构与原理简述
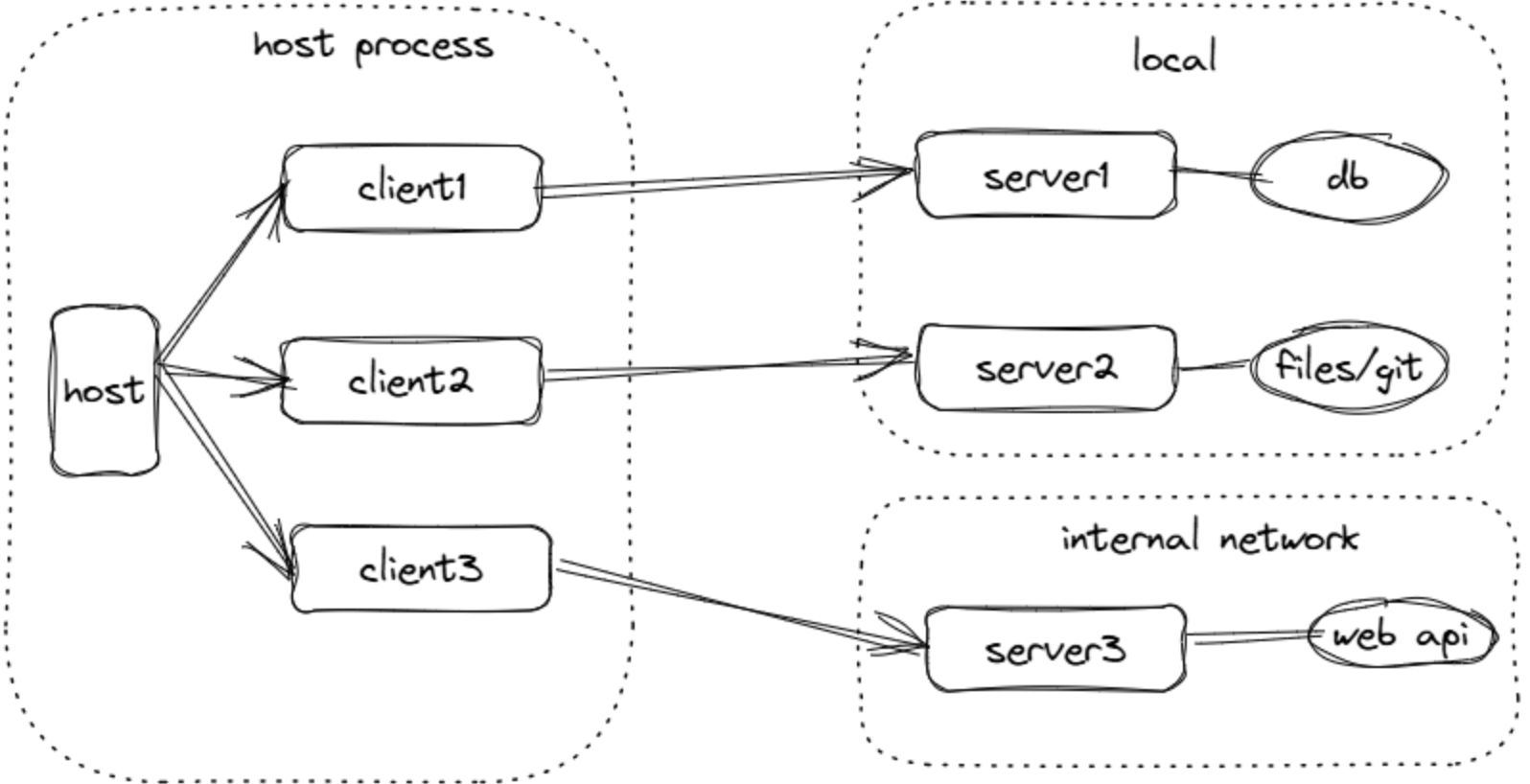
- 宿主进程:容器与协调者,承担以下职责:
- 创建并管理多个客户端实例
- 控制客户端连接权限与生命周期
- 执行安全策略与用户同意要求
- 处理用户授权决策
- 协调AI/LLM集成与采样
- 管理跨客户端的上下文聚合
- 宿主可创建管理多个客户端
- 客户端:由宿主创建,并维护服务器连接:
- 为每个服务器建立有状态会话
- 处理协议协商与能力交换
- 双向路由协议消息
- 管理订阅与通知机制
- 保持服务器间的安全边界
- 与特定服务器1:1 保持对应关系
- 服务器:提供专业化上下文与能力:
- 通过MCP原语暴露资源、工具和提示
- 独立运行,各司其职
- 通过客户端接口请求采样
- 必须遵守安全约束
- 可以是本地进程或远程服务
7.分层架构
7.1.架构
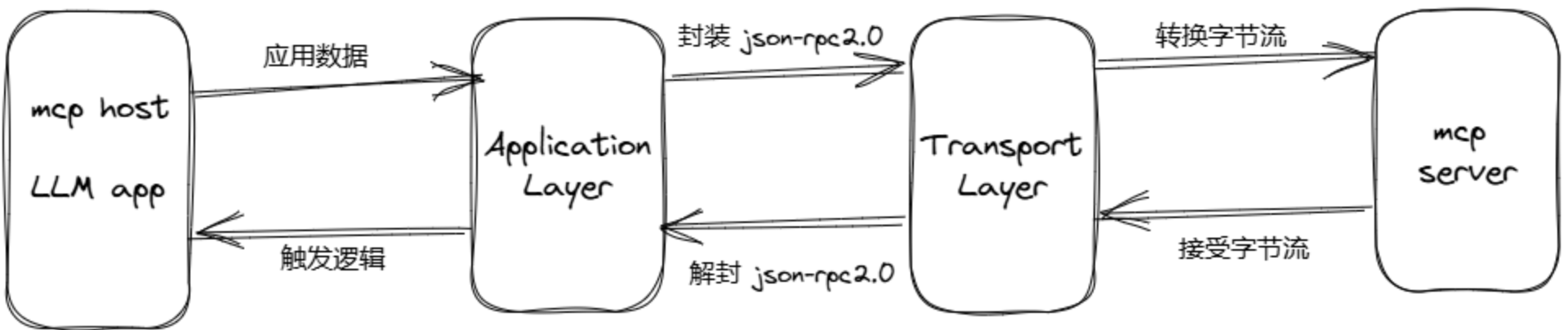
7.2.协议层(Application Layer)- 上层
- 功能:处理消息帧、请求/响应,链接和高级通信模型(面向应用)
- 核心类:protocol、client,server
- 消息格式标准化
- 使用 JSON-RPC 2.0 规范,官方规范介绍:https://wiki.geekdream.com/Specification/json-rpc_2.0.html
- 统一的请求/响应结构
- 错误码和异常处理机制
- 业务语义定义
- Tools(工具调用)
- Resources(资源访问)
- Prompts(提示模板)
- 生命周期管理(initialize、shutdown)
- 会话管理
- 请求 ID 追踪
- 上下文保持
- 状态同步
7.3.传输层(Transport Layer)- 下层
- 功能:处理客户端与服务器之间的实际通信(面向网络),所有传输都使用 JSON-RPC 2.0 交换消息。
- 两种种传输方式
- STDIO 传输,本地通信
- 进程间通信(IPC),标准输入/输出流
- 适合本地、单客户端场景
- SSE 传输(流式HTTP),远程通信
- 网络通信,使用Server-Sent Events 实现服务端推送,使用http post进行客户端到服务器的消息传递
- 适合远程、多客户端场景
- STDIO 传输,本地通信

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)