OpenClaw 架构解析
OpenClaw 架构解析
-
- 前言
- 一、系统总览:一条消息如何穿过 OpenClaw
- 二、Channel:外部消息世界进入 OpenClaw 的边界层
- 三、Gateway:OpenClaw 的控制中枢与状态宿主
- 四、Session:Agent 下的上下文槽位,而不只是聊天记录
- 五、Routing:由 Gateway 执行的确定性分发机制
- 六、Agent Runtime:把一条输入变成一轮真实 run 的执行内核
- 七、Tool Loop:Agent Runtime 最核心的行动闭环
- 八、pi 栈总览:OpenClaw 嵌入的 agent 引擎体系
- 九、pi-coding-agent:面向宿主的高层 Agent SDK
- 十、pi-agent-core:真正负责 agent loop 的引擎层
- 十一、pi-ai:统一模型、消息与 Provider 的底层抽象层
- 十二、完整执行链:把所有层真正串起来
- 十三、为什么 OpenClaw 这样设计
- 十四、最终总结
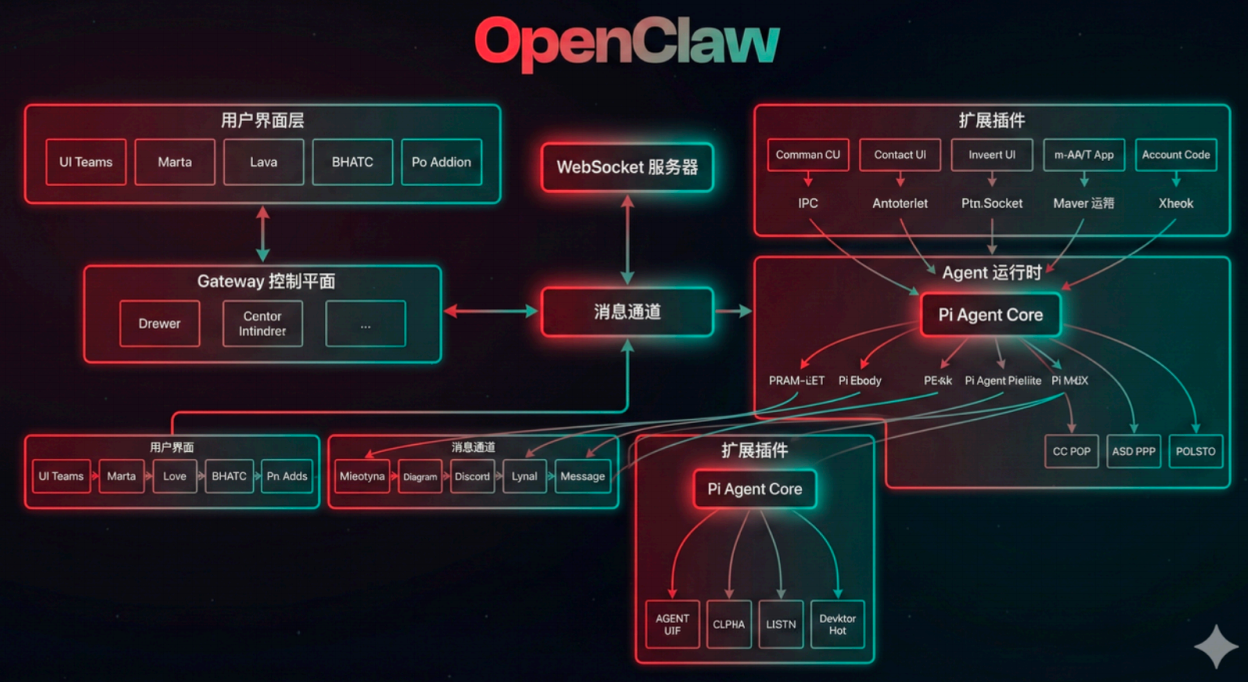
前言
OpenClaw 从表面看像一个“能接 Telegram / Discord / WhatsApp、能调用模型、能用工具回复用户”的 Agent 系统;但如果只把它理解成“聊天入口 + 大模型 + 工具”的三段式结构,就会错过它真正的设计重心。
它真正的核心,不是单纯把消息送给模型,而是把外部平台事件纳入一个可控、可持续、可路由、可持久化、可治理的统一运行体系。这个体系的主干不是某个模型 SDK,而是:
- Channel 负责接入和语义适配
- Gateway 负责控制平面、状态、路由与会话归属
- Session 负责上下文连续性
- Routing 负责确定性分发
- Agent Runtime 负责把一次输入变成一轮真实的 agentic run
- pi 栈负责提供底层 agent 引擎与模型抽象能力
因此,理解 OpenClaw,不能只看“模型怎么回答”,而要看一条消息如何从外部世界进入系统、如何被归属到正确的 agent/session、如何在 runtime 中完成工具闭环、又如何被持久化并送回原平台。
这篇文档的目标,就是把这条链路完整展开,并用系统架构的视角说明 OpenClaw 的真实分层。
一、系统总览:一条消息如何穿过 OpenClaw
先给出整套系统的总时序。它不是“用户消息 → 模型 → 回复”这么短,而是一条跨越多个边界层和运行层的执行链。
[用户]
│
│ 1. 在 Telegram / Discord / WhatsApp 发消息
▼
[Channel]
│
│ 2. 把平台原生事件标准化
│ -> 统一成 OpenClaw 可处理的入站消息
▼
[Gateway]
│
│ 3. 认证 / 控制平面接入 / 路由判断
│ 4. 选中 agent
│ 5. 选中该 agent 下的 session
▼
[OpenClaw Runtime]
│
│ 6. 为这次请求创建 run
│ 7. 串行化当前 session
│ 8. 装配 workspace / bootstrap / skills / settings
│ 9. 准备模型与 auth profile
▼
[pi-coding-agent]
│
│ 10. createAgentSession()
│ 11. 挂上 SessionManager / ResourceLoader / ModelRegistry / tools
▼
[pi-agent-core]
│
│ 12. 开始 agent loop
│ 13. 模型推理
│ 14. 需要时发起 tool execution
│ 15. 工具结果回填,继续 loop
▼
[pi-ai]
│
│ 16. 把“模型调用请求”统一成底层 Model / message / stream
│ 17. 选择并调用具体 provider API
▼
[Provider]
│
│ 18. 真正执行大模型推理并返回流式结果
▲
│
[pi-ai]
│
│ 19. 把 provider 原生响应整理成统一消息/流
▲
[pi-agent-core]
│
│ 20. 判断:最终答复 or 继续调工具
▲
[pi-coding-agent]
│
│ 21. 维持 agent session / managers / resources
▲
[OpenClaw Runtime]
│
│ 22. 转成 assistant/tool/lifecycle 流
│ 23. 写入 transcript / session persistence
▲
[Gateway]
│
│ 24. 按原 routing 和原 channel 回传
▲
[Channel]
│
│ 25. 转回目标平台格式
▲
[用户]
│
│ 26. 看到最终回复
这张图表达的,不只是“请求经过了哪些模块”,而是 OpenClaw 对一个用户输入所做的全部系统工作:
- 先把外部平台的原生事件接进来。
- 再由 Gateway 统一决定它属于谁、进哪条上下文线。
- 然后由 Runtime 将其变成一个真实的 agentic run。
- 底层借助 pi 栈完成会话构造、agent loop 和模型调用。
- 结果再被桥接回 OpenClaw 的控制面,写入 transcript,并沿原路径返回。
所以从用户视角看,只是“发一句、回一句”;但从系统视角看,中间实际走过的是:
平台适配 → 控制平面 → 路由 → 会话归属 → 运行时编排 → agent loop → 模型抽象 → provider → 事件桥接 → 持久化 → 原路返回。
二、Channel:外部消息世界进入 OpenClaw 的边界层
2.1 定义
Channel 是 OpenClaw 面向外部聊天平台的接入与适配层。它的核心职责不是简单的消息收发,而是将 Telegram、Discord、Signal、WhatsApp 等平台各自不同的事件模型、身份模型和能力模型,转换为 Gateway 可统一处理的内部会话事件;同时再将 Gateway/Runtime 产出的统一动作,按目标平台的能力约束重新编码并投递回去。
因此,Channel 不是一个薄薄的协议转换器,而是一层事件语义边界层。
2.2 为什么 Channel 不是普通 adapter
如果把 Channel 只理解成“SDK 封装层”或“协议转换层”,会严重低估它的复杂度。因为聊天平台之间的差异,并不只是 API 路径不同,而是:
- 身份模型不同
- 群聊与私聊语义不同
- thread / reply / quote 的规则不同
- 媒体与附件处理链路不同
- reaction / edit / delete / poll 等能力支持不一致
- 权限、限流和反机器人策略不同
所以 Channel 真正做的是:
把平台原生事件,变成 OpenClaw 能理解、能路由、能落 session 的内部统一事件;再把 OpenClaw 的统一输出,降级或映射成目标平台真正能发送的动作。
2.3 Channel 的双向职责
Channel 其实是一层双向边界:
入站职责
- 连接具体平台
- 接收平台原始事件
- 识别事件类型与可处理性
- 做平台语义归一化
- 把归一化事件交给 Gateway
出站职责
- 接收 Gateway/Runtime 的统一输出
- 判断目标平台是否支持该动作
- 对文本做切块、对媒体做上传、对 reply/thread 做映射
- 重新编码为平台原生消息并发送
所以 Channel 不是单向“收消息”的入口,而是:
入站:平台事件 → 内部事件
出站:内部动作 → 平台动作
2.4 四层映射:为什么说它是语义边界层
一个成熟的 Channel 至少要完成四层映射:
- 传输层映射:webhook、polling、socket、SDK callback
- 数据结构映射:平台对象拆解成统一字段
- 语义映射:DM / group / thread / quote / mention / attachment 的意义归一
- 能力映射:内部动作能否被平台表达,以及如何降级表达
因此,Channel 的本质不是 TelegramMessage -> InternalMessage 这么简单,而是:
尽可能保真地把平台事件抽象进来,再尽可能合理地把内部结果降级输出回去。
2.5 Channel 不负责什么
为了边界清晰,必须强调 Channel 不负责:
- 不决定由哪个 agent 处理
- 不决定 session 生命周期
- 不进行 LLM 推理
- 不负责 Tool Loop
- 不负责长期记忆逻辑
它负责接入和适配,但不负责系统中枢决策。
三、Gateway:OpenClaw 的控制中枢与状态宿主
3.1 定义
Gateway 不是“消息中转站”,而是 OpenClaw 的系统中枢。它统一持有运行态,统一接住所有入口,统一决定消息归属、会话归属、权限边界和执行路径。
如果要给它一个最准确的定义,可以写成:
Gateway 是 OpenClaw 的常驻控制中枢。它统一持有 sessions、pairing、node registry 等运行态,统一承载 channel connections 与 WebSocket control plane,统一执行 routing、auth、policy 和 agent 入口编排,因此它不是普通网关,而是整个系统的状态宿主与调度核心。
3.2 为什么 Gateway 不是无状态转发器
转发器只负责“把 A 发给 B”。
但 Gateway 至少还负责:
- 持有 sessions
- 持有 routing rules / bindings
- 持有 channel connections
- 持有 pairing 与 node registry
- 暴露 WebSocket control plane
- 暴露 HTTP API / hooks / control UI
- 作为 trusted operator actions 的统一入口
所以 Gateway 真正解决的问题不是“怎么转发消息”,而是:
系统当前处于什么状态,以及这条新输入应该如何进入当前系统状态。
3.3 Gateway 的四层职责
第一层:入口统一
Gateway 统一接住:
- Channel
- CLI
- Web UI
- Control clients
- Nodes
- HTTP 调用
它是单一控制平面的入口宿主。
第二层:状态统一
Gateway 持有系统运行态,例如:
- sessions
- pairing
- node registry
- 当前连接
- 当前配置与策略
这意味着 Gateway 是状态真相源,而不是无状态 API。
第三层:路由统一
Gateway 决定:
- 某条输入归哪个 agent
- 属于哪个 session
- 后续回复从哪里回去
- 哪些绑定与覆盖规则生效
这使它成为 routing brain,而不是 transport pipe。
第四层:权限与策略统一
Gateway 还承担:
- 认证
- 作用域校验
- tool policy
- routing policy
- control-plane 边界
所以它既是控制中枢,也是安全边界。
3.4 为什么 Gateway 必须长期运行
Gateway 不是一次请求起一次的进程,而是 OpenClaw 的常驻底座。
它一旦停止,受影响的不只是聊天回复,还包括:
- control plane 消失
- channel 连接断开
- session 路由入口丢失
- cron / hook 等持续性能力受影响
所以它更像一个长寿命状态机宿主,而不是临时 handler。
3.5 Gateway 与 Channel 的边界
一句话总结:
- Channel 负责把平台现实带进来、把结果送回去
- Gateway 负责决定系统如何理解并处理这条输入
你可以把它们的关系记成:
Channel:这是 Telegram 发来的群消息,带图片,reply 到某条消息
Gateway:这条输入属于哪个 agent、哪个 session、允许触发什么
Runtime:这一轮任务具体怎么完成
四、Session:Agent 下的上下文槽位,而不只是聊天记录
4.1 定义
Session 可以定义为:
某个 agent 下,一段持续累积上下文、设置和运行历史的对话执行槽位。
这个定义里,“槽位”比“聊天框”更准确。因为 Session 不只存消息,还承载:
- 当前上下文连续性
- 会话级设置
- 当前活跃运行
- 历史与持久化状态
- 中止 / 重置 / 延续等生命周期动作
4.2 Session 为什么必须归 Gateway 持有
Session 不可能散落在各个 Channel 里,也不能靠 Runtime 临时现算。因为 Gateway 必须知道:
- 当前有哪些 session
- 每个 session 属于哪个 agent
- 某条新输入应该落到哪个 session
- 某个客户端正在使用哪个 session
- 哪些 session 可以被列出、切换、预览、重置
因此,Session 是 Gateway 持有的核心运行态之一。
4.3 Session 与 Agent 的关系
Session 不是全局裸对象,而是挂在 agent 下面的上下文槽位。
你可以把它理解成:
Agent
├─ Session A
├─ Session B
└─ Session global
所以正确的关系是:
- Agent 是工作主体
- Session 是该主体下面的上下文地址
一个 agent 可以有很多 session,而不是一 agent 一会话。
4.4 SessionKey 是什么
SessionKey 不是授权令牌,而是:
告诉 Gateway:“这条输入应该进入哪个上下文槽位。”
它回答的是“去哪儿”,不是“你是谁”。
因此必须把:
- 身份 / auth
- sessionKey / context selection
明确区分开。
4.5 Session 的三个核心作用
1. 上下文连续性
让后一句能继承前一句的语义环境。
2. 会话级设置承载
不同 session 可以拥有不同的 verbosity、reasoning、delivery 等控制项。
3. 运行历史与生命周期管理
session 可以被持续使用,也可以被 abort、reset 或切换。
4.6 Session 不是安全隔离边界
这是必须强调的一点。
Session 能把上下文分开,但不能替代 trust boundary。它能做到:
- 避免不同任务串上下文
- 让一个 agent 同时服务多个会话槽位
但它不能做到:
- 把共享 Gateway 变成严格多租户安全系统
- 替代真正的 per-tenant 隔离
所以:
Session 能分上下文,不能替代信任边界;需要敌对用户隔离时,要拆 Gateway。
五、Routing:由 Gateway 执行的确定性分发机制
5.1 定义
Routing 不是“模型选一个 channel 或 agent”,而是 Gateway 根据输入来源、绑定规则、上下文规则和目标输出面,确定:
- 由哪个 agent 处理
- 落到哪个 session
- 最终从哪里回去
因此可以把它定义为:
Gateway routing 是一套确定性的核心分发机制:它先根据 binding 和来源元数据把入站流量归到某个 agent,再根据 direct/group/thread 等上下文规则解析为该 agent 下的具体 session,最后将执行结果投递回与入站来源一致的 channel 或绑定目标;其中静态绑定决定归属,动态绑定决定局部覆盖,整个过程不由模型决定,而由 Gateway 核心层和宿主配置控制。
5.2 Routing 要回答的三层问题
第一层:归哪个 agent
某条输入应该由 main、work、research,还是其他 agent 处理。
第二层:进入哪个 session
即使 agent 已确定,仍需决定进入:
- main session
- group session
- thread-bound session
- 显式指定 session key
第三层:结果从哪里回去
结果可能需要回到:
- 原 channel
- 原 account
- 原 peer
- 原 thread
- API / control client
5.3 静态 routing:binding
Binding 是最基础的 routing 规则。它本质上是:
哪类来源的入站流量,归哪个 agent。
它通常按这些维度匹配:
- channel
- accountId
- peer
- guild / team / group 等平台级范围
因此 routing 的第一层是静态归属判断。
5.4 动态 routing:thread / subagent / session binding
Routing 不只是一张静态表。很多情况下还有动态绑定覆盖层,例如:
- thread 已绑定到某个 session target
- subagent 创建了局部 follow-up 路径
- ACP / control session 映射到某个 Gateway session
因此完整的 routing 其实是:
静态绑定决定默认归属,动态绑定负责局部覆盖。
5.5 为什么 routing 必须确定性
Routing 如果交给模型决定,会带来不可控、不审计、不稳定的问题。OpenClaw 选择把它放在 Gateway 核心层,核心原因是:
- 安全
- 可控
- 可审计
- 可回放
- 能保证 reply path 与 inbound path 一致
这也是为什么 OpenClaw 的 routing 本质上属于系统编排,而不是推理结果。
六、Agent Runtime:把一条输入变成一轮真实 run 的执行内核
6.1 定义
Agent Runtime 不是“调模型的薄层”,而是把一条已经被 Gateway 正确路由进来的输入,变成一次完整、可持续、可中断、可落盘的 agentic run 的执行内核。
可以用一句话概括:
Gateway 决定“这条消息去哪儿”,Runtime 决定“到了以后这一轮怎么完成”。
6.2 Runtime 的 authoritative path
一轮真实的 run 并不是简单的“拿上下文调一次模型”,而是完整的执行链:
intake
-> context assembly
-> model inference
-> tool execution
-> streaming replies
-> persistence
这条链就是 Runtime 的 authoritative path。
6.3 Runtime 是状态机,而不是函数调用
Runtime 的真实形态更接近:
接受输入
-> 解析当前 session 状态
-> 装配上下文与工作环境
-> 选择模型与 auth
-> 调模型
-> 如需工具则执行工具
-> 回填结果
-> 继续推理
-> 发出流式事件
-> 写入持久化
-> 结束 run
因此 Runtime 关注的不是“这句话怎么答”,而是:
- run 从什么状态开始
- 中间发生了哪些状态转移
- 最后把 session 留在什么状态
这就是典型的状态机思维。
6.4 Runtime 的五项关键职责
1. 创建 run
每次输入都会触发一个 run,而不是简单的一发一回。
2. 串行化 session lane
同一个 session 不允许同时乱跑多轮 loop,否则会造成:
- 历史顺序错乱
- 工具结果串线
- 会话状态不一致
所以 runs 会按 session 串行化。
3. 装配执行环境
包括:
- workspace
- bootstrap/context files
- skills snapshot
- settings
- system prompt 相关上下文
- SessionManager
4. 解析模型与 auth profile
Runtime 不只是填一个模型名,而是要决定:
- 用哪个 model
- 用哪个 provider
- 用哪个 auth profile
- 失败时如何 failover
5. 负责 streaming、治理与持久化
Runtime 会:
- 发出 assistant/tool/lifecycle 流
- enforce timeout
- 在必要时 abort run
- 处理 compaction / retry
- 将结果写入 transcript 与 session persistence
6.5 Runtime 与 SessionManager
Runtime 最终不是只要“答对”,而是要“留下正确的会话状态”。因此 SessionManager 不是附属品,而是 Runtime 保证上下文连续与持久一致性的关键基础设施。
6.6 Runtime 与 Memory
要明确区分两个层次:
- Session:当前对话线的短期连续性
- Memory:长期提炼、写入磁盘、可再检索的知识
Runtime 是把两者连接起来的桥,而不是等同于任何一方。
七、Tool Loop:Agent Runtime 最核心的行动闭环
7.1 定义
Tool Loop 不是“模型顺手调个工具”,而是 Runtime 把“模型的意图”变成“真实执行闭环”的核心机制。
可以直接定义为:
Tool Loop 是 Agent Runtime 的核心行动回路:模型先基于当前 session、workspace、skills 和 system prompt 判断是否需要外部能力;一旦提出工具调用意图,Runtime 就以受控方式执行工具、发出工具流事件、清理并持久化结果,再把结果回填进当前 run 的上下文,让模型继续推理;这一过程可重复多轮,直到形成最终答复、命中抑制规则、超时中止或错误结束。
7.2 Tool Loop 的标准闭环
模型读取上下文
-> 判断是否需要调用工具
-> Runtime 执行工具
-> 工具结果回填
-> 模型继续推理
-> 直到输出最终答复
7.3 它为什么是 Runtime 的核心
因为模型本身只能提出工具意图,无法真的去:
- 执行工具
- 记录工具生命周期
- 清理结果
- 把结果持久化
- 再把新事实送回下一轮推理
Runtime 才是这个闭环的宿主。
7.4 工具执行时 Runtime 在做什么
至少包括:
- 截获工具调用意图
- 校验 / 规整参数
- 执行工具
- 发出 tool start/update/end 事件
- 清理大结果或图像载荷
- 将结果写入 transcript / session
- 依据规则抑制重复 assistant 确认
7.5 为什么 Tool Loop 可以跑很多轮
因为一次工具结果经常不足以直接结束任务。比如:
- 先列目录
- 再读文件
- 再搜索网页
- 再综合回答
所以 Tool Loop 的本质不是“一次工具调用”,而是:
模型—工具—模型—工具—模型……直到达到可结束状态。
7.6 Tool Loop 的终止条件
一轮 Tool Loop 通常在以下情况结束:
- 模型判断信息已足够,输出最终答复
- 工具已直接完成用户可见动作
- 运行超时,被 Runtime 中止
- 出现错误或外部取消
7.7 Tool Loop 为什么必须串行
多步工具调用特别容易污染 session。如果同一 session 并发跑两轮 Tool Loop,会导致:
- A run 用旧上下文继续推理
- B run 已经改写历史
- 工具结果交叉污染
因此 Tool Loop 的稳定性建立在 per-session serialization 之上。
八、pi 栈总览:OpenClaw 嵌入的 agent 引擎体系
OpenClaw 自己的系统层并不直接从模型 SDK 起步,而是把一套名为 pi 的 agent 栈内嵌进来。整体可以分成三层:
OpenClaw 自己的系统层
├─ Channel
├─ Gateway
├─ Session / Routing
└─ OpenClaw Agent Runtime
pi 嵌入层
└─ pi-coding-agent
├─ createAgentSession
├─ SessionManager
├─ ResourceLoader
├─ ModelRegistry
└─ built-in tools
pi 核心执行层
└─ pi-agent-core
├─ agent loop
├─ tool execution
└─ AgentMessage types
pi 模型抽象层
└─ pi-ai
├─ Model
├─ provider APIs
├─ streamSimple
└─ message abstractions
关键点在于:
OpenClaw 不是把 pi 当外部子进程或 RPC 黑盒使用,而是直接 import 并实例化 pi 的 AgentSession,把整套能力嵌进自己的 Gateway/session/routing/runtime 体系里。
九、pi-coding-agent:面向宿主的高层 Agent SDK
9.1 定义
pi-coding-agent 是 pi 栈里最靠上的高层 SDK。它把“创建 agent 会话、管理会话状态、加载资源、注册模型、接入内建工具”这些 Runtime 真正需要的能力,打包成了 OpenClaw 可直接嵌入的入口层。
可以定义为:
pi-coding-agent是 pi 栈中的高层 agent SDK:它向宿主暴露createAgentSession、SessionManager、ModelRegistry、AuthStorage和 built-in tools 等接口,把底层模型抽象与 agent loop 封装成可嵌入、可管理、可持久化的 agent session 运行单元,因此 OpenClaw 直接对接它来创建嵌入式 agent,而不是直接从更底层的pi-agent-core或pi-ai起步。
9.2 为什么 OpenClaw 直接接它
因为 OpenClaw 需要的不是一个“只会跑 loop 的底层引擎”,而是一个:
- 可创建 session
- 可挂载 manager
- 可注入工具
- 可接宿主工作区与 system prompt
- 可由宿主完全控制生命周期
的高层构造入口。
createAgentSession() 正是这个入口。
9.3 它负责什么
可以分成四类:
- 会话构造:
createAgentSession - 会话管理:
SessionManager - 模型与认证组织:
ModelRegistry/AuthStorage - 内建工具集合:built-in tools
9.4 它与 OpenClaw Runtime 的边界
pi-coding-agent 提供的是高层机制,而 OpenClaw 仍然掌握系统宿主权。边界大致是:
pi-coding-agent 负责:
- agent session 构造能力
- 会话管理抽象
- 模型注册抽象
- 认证存储抽象
- 内建工具集合
OpenClaw 负责:
- Gateway
- routing
- session ownership
- discovery
- tool wiring
- channel/context/system prompt 定制
- 控制面事件桥接
所以 OpenClaw 借用了这层 SDK,但没有把自己降格为 pi CLI 的壳子。
十、pi-agent-core:真正负责 agent loop 的引擎层
10.1 定义
pi-agent-core 不是 OpenClaw 直接拿来创建 agent 会话的那层,而是 pi 栈里真正负责:
- agent loop
- tool execution
AgentMessage类型系统
的核心引擎层。
可以定义为:
pi-agent-core的职责不是创建高层会话接口,而是提供 agent loop、tool execution 和AgentMessage这些核心运行语义。
10.2 它和 pi-coding-agent 的边界
pi-coding-agent更像高层 SDK,负责把底层能力组装成可创建的AgentSessionpi-agent-core更像引擎内核,负责 session 创建之后,内部真正怎么跑
一句好记的话是:
pi-coding-agent负责把车组起来并交给宿主,pi-agent-core负责这辆车的发动机和传动系统怎么工作。
10.3 为什么说 Tool Loop 的“引擎味”属于它
因为工具执行语义首先属于 pi-agent-core。模型如何提出工具意图、工具如何进入 agent loop、结果如何变成下一轮推理的一部分,这些都更接近 pi-agent-core 的职责。
10.4 AgentMessage 的意义
AgentMessage 不只是“消息对象”,而是 agent loop 内部的运行语言。它用于表达:
- 模型说了什么
- 工具发生了什么
- 运行推进到了哪一步
- 哪些事件应该被上层桥接为 assistant/tool/lifecycle 流
所以 AgentMessage 是 agent 内部语义与外部事件流之间的桥梁。
十一、pi-ai:统一模型、消息与 Provider 的底层抽象层
11.1 定义
pi-ai 不是 agent,不是 session manager,也不是 Tool Loop 的编排层;它是 pi 栈最底层的 LLM 抽象层,负责:
ModelstreamSimple- message types
- provider APIs
可以定义为:
pi-ai是 pi 栈最底层的 LLM 抽象层,不是 agent 层。它主要负责Model、streamSimple、message types 和 provider APIs。
11.2 它真正解决的问题
1. Model 抽象
让上层不必直接面向 OpenAI、Anthropic、Gemini 各自不同的调用接口,而是统一地说:
我要与一个 Model 交互。
2. 流式输出抽象
不同 provider 的流式响应需要先被统一成上层可消费的流。
3. 消息类型抽象
不同 provider 的角色字段、多模态结构、tool call 格式都不一致,需要先统一到 message types。
4. Provider API 封装
最终还要落到具体厂商 API,但上层不需要直接处理其私有格式。
11.3 它与上层的边界
pi-ai负责“模型怎么被统一调用”pi-agent-core负责“agent 怎么基于模型推进循环”pi-coding-agent负责“宿主怎样拥有一个可运行的 agent session”
一句最好记的话:
pi-ai负责“模型怎么说话”,pi-agent-core负责“agent 怎么行动”,pi-coding-agent负责“宿主怎么拥有这套行动能力”。
十二、完整执行链:把所有层真正串起来
到这里,可以把整个系统执行链完整地重述一遍:
用户在外部平台发消息
-> Channel 接住平台原生事件
-> Channel 将其归一化为内部入站事件
-> Gateway 依据认证、binding、routing 和上下文规则做分发
-> Gateway 选中 agent
-> Gateway 选中该 agent 下的 session
-> Runtime 创建 run
-> Runtime 以 per-session lane 串行化运行
-> Runtime 装配 workspace / bootstrap / skills / settings / system prompt
-> Runtime 解析模型与 auth profile
-> OpenClaw 调用 pi-coding-agent.createAgentSession()
-> pi-coding-agent 创建带 SessionManager / ResourceLoader / ModelRegistry / tools 的 AgentSession
-> pi-agent-core 开始 agent loop
-> 模型先基于当前上下文做推理
-> 若需要外部能力,则进入 Tool Loop
-> Runtime 执行工具、发出 tool stream、清理结果并回填
-> pi-agent-core 继续 loop,直到形成最终答复
-> pi-ai 负责统一模型调用、消息抽象和 provider 流式输出
-> provider 真正执行推理并返回原生结果
-> pi-ai 将 provider 结果整理回统一消息/流
-> OpenClaw Runtime 订阅并桥接为 assistant/tool/lifecycle 流
-> Runtime 将 transcript 和 session 结果持久化
-> Gateway 按原 routing 决定输出目标
-> Channel 将内部统一输出重新编码成目标平台消息
-> 用户在原平台看到最终回复
这就是 OpenClaw 的真实主干。
十三、为什么 OpenClaw 这样设计
到最后,最重要的问题不是“它有哪些模块”,而是:为什么它要这样设计。
13.1 为什么 routing 不交给模型
因为 routing 属于:
- 安全边界
- 可控边界
- 可审计边界
- 可回放边界
如果把 agent / channel / session 归属交给模型,就会失去确定性。
13.2 为什么 session 必须由 Gateway 持有
因为 session 是系统运行态的一部分,不是 UI 层的聊天框,也不是平台私有对象。它必须成为统一上下文路由的核心对象。
13.3 为什么 Runtime 必须串行化 session
因为 agent 系统不是纯文本生成,而是会读历史、调工具、写状态。只要同一个 session 并发跑两轮,结果就会不可预期。
13.4 为什么要嵌入 pi,而不是当成外部服务调用
因为 OpenClaw 需要:
- 掌控 session 生命周期
- 掌控事件桥接
- 掌控工具注入
- 掌控 system prompt 定制
- 掌控 failover / compaction / persistence
如果把 pi 当黑盒子进程或 RPC 服务,这些控制能力会明显减弱。
13.5 为什么 Channel 必须是语义边界层
因为外部聊天平台不是统一世界。平台现实本身就是脏的、异构的、有损的、不对称的。系统必须在入口就承认这一点。
十四、最终总结
如果把 OpenClaw 的整个架构压缩成一句话,可以这样说:
OpenClaw 不是“一个会聊天并会调工具的模型外壳”,而是一个以 Gateway 为中枢、以 Session 和 Routing 为状态与分发骨架、以 Agent Runtime 为执行内核、并以内嵌 pi 栈为 agent 引擎与模型抽象底座的统一控制系统;它的核心价值不在于单次模型回答,而在于把外部平台事件纳入一个可控、可持续、可治理、可持久化的 agent execution framework。
如果再压缩成最值得记住的六句话,就是:
- Channel 是语义边界层,不是普通协议转换器。
- Gateway 是控制中枢与状态宿主,不是无状态转发器。
- Session 是 agent 下的上下文槽位,不只是聊天记录。
- Routing 是 Gateway 的确定性核心分发机制,不由模型决定。
- Runtime 是真实 agent run 的执行内核,是状态机,不是薄函数。
- pi 栈提供底层 agent 引擎和模型抽象,OpenClaw 则把它们嵌进自己的系统控制框架。
至此,OpenClaw 的整个主架构就算真正讲透了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)