整合因果推断与可解释AutoML识别中国东部近地面臭氧浓度驱动因子
论文详解 | 整合因果推断与可解释AutoML识别中国东部近地面臭氧浓度驱动因子
原文:Integrating causal inference and interpretable automated machine learning to identify drivers of near-surface ozone concentration in eastern China》
前言
近地面臭氧(O₃)是我国东部经济发达地区最核心的二次大气污染物之一,其形成受气象条件、前体物排放、区域传输等多因素的非线性耦合影响,传统统计模型和化学传输模型(CTMs)分别存在非线性拟合能力不足、计算成本高、不确定性大的痛点。
这篇论文的核心贡献在于:构建了一套「自动化建模-特征解释-因果推断」的完整分析框架,将AutoML(自动化机器学习)、SHAP可解释性分析与因果推断(Causal Forest+Double Machine Learning)深度融合,既实现了近地面臭氧浓度的高精度预测,又从相关性分析进阶到因果关系识别,精准量化了中国东部臭氧污染的核心驱动因子及其空间异质性,为区域空气质量管控提供了方法学支撑和科学依据。
一、论文核心信息与研究背景
1.1 基础发表信息
| 项目 | 详情 |
|---|---|
| 论文标题 | Integrating causal inference and interpretable automated machine learning to identify drivers of near-surface ozone concentration in eastern China |
| 发表期刊 | Environmental Modelling and Software 2026, 196, 106782 |
| 核心关键词 | 近地面臭氧浓度、驱动因子、因果推断、可解释自动化机器学习、中国东部、TROPOMI |
1.2 研究背景与科学问题
- 臭氧污染的现实危害:近地面臭氧是强氧化性二次污染物,长期暴露会提升人体心血管、呼吸系统疾病发病率,同时损伤植被光合能力、降低作物产量,还会通过氧化VOCs促进二次颗粒物生成,加剧复合污染。
- 中国东部的污染现状:中国东部(鲁、苏、皖、浙、赣、闽、沪)是我国经济最发达、工业化城市化程度最高的区域,NOₓ和VOCs前体物排放强度大,臭氧污染呈现浓度高、频发、时空异质性强的特征,多个城市年均浓度超过国家二级标准(160μg/m³)。
- 现有方法的核心局限:
- 传统统计模型(线性回归等):仅能捕捉线性关系,无法刻画臭氧形成的复杂非线性交互作用;
- 化学传输模型(CTMs):受空间分辨率粗、计算成本高、排放清单不确定性大的限制,模拟结果偏差显著;
- 传统机器学习模型:虽能提升预测精度,但存在「黑箱问题」,且仅能分析变量间的相关性,无法区分因果关系,易受混淆变量影响,无法识别真正的驱动机制;
- 自动化机器学习(AutoML)虽能降低建模人工偏差,但缺乏因果层面的验证。
1.3 研究核心目标与创新点
核心目标
基于2022-2023年中国东部多源数据,构建「AutoML-SHAP-因果推断」的集成框架,系统识别近地面臭氧浓度的关键驱动因子,量化各因子的因果效应强度与空间异质性,揭示臭氧污染的驱动机制。
核心创新点
- 方法学创新:首次将AutoML、SHAP可解释性与双因果推断模型(CF+DML)深度融合,形成了从「高精度预测-特征贡献解析-因果效应验证」的全流程分析范式,解决了传统机器学习「只相关、不因果」的核心痛点;
- 模型优化:通过AutoML自动化筛选出最优的Extra Trees模型,实现了臭氧浓度的高精度模拟(R²=0.93),同时通过VIF检验解决了变量多重共线性问题,保证了模型稳定性;
- 机制解析:通过双因果模型交叉验证,明确了气象因子是中国东部臭氧变化的主导因子,量化了温度、区域背景传输等关键因子的因果效应空间分布,为分区管控提供了精准支撑;
- 成果开源:论文完整开源了建模代码、预处理脚本和核心数据集,保证了研究结果的完全可复现性。
二、研究区域与数据来源
2.1 研究区域
论文的研究区域为中国东部7个省级行政区,包括山东省、江苏省、安徽省、浙江省、江西省、福建省和上海市,地理范围约23.56°–38.41°N,113.57°–122.96°E。
对应图表解读:图1 研究区域示意图
- 图1展示了研究区域的地理边界、数字高程模型(DEM)和国家空气质量监测站的空间分布,共包含457个地面监测站点;
- 区域地形特征:北部以平原为主,南部(浙南、福建、江西)以丘陵山地为主,地形差异直接影响臭氧的传输、积累与扩散,是臭氧浓度空间异质性的重要地理背景;
- 该区域是我国工业排放和人为活动强度最高的区域之一,同时地形、气候南北差异大,为臭氧驱动因子的时空异质性分析提供了典型研究场景。
2.2 多源数据与预处理
论文整合了地面观测、卫星遥感、气象再分析、排放清单、地理与社会经济六大类数据,共20个核心变量,具体信息如下表所示。
对应图表解读:表1 数据集与变量规格总览
| 数据类别 | 核心变量 | 缩写 | 数据来源 |
|---|---|---|---|
| 地面观测 | 近地面臭氧监测数据 | O₃ | 中国环境监测总站(CEMC),457个站点小时级数据 |
| 时间变量 | 年积日、经纬度 | Date、Lon、Lat | 监测站点地理信息与时间序列 |
| 气象变量 | 2m地表气温、边界层高度、相对湿度、总降水量、总云量、总蒸散量、地表气压、净辐射、10m东西/南北向风速 | 2mT、BH、RH、TP、TC、TE、SP、NT、UW、VW | ECMWF的ERA5再分析数据集 |
| 卫星观测 | 对流层臭氧柱浓度 | Tor_O₃ | 欧空局Sentinel-5P TROPOMI Level-2产品 |
| 排放清单 | 氮氧化物、挥发性有机物、一氧化碳、细颗粒物 | NOₓ、VOC、CO、PM₂.₅ | 清华大学MEIC中国多尺度排放清单 |
| 其他变量 | 高程、归一化植被指数、人口密度、夜间灯光 | DEM、NDVI、MPD、NTL | 国家地球系统科学数据中心、WorldPop、国家遥感中心 |
数据预处理核心步骤
- 时空匹配:所有原始数据重采样至日时间分辨率、0.05°空间分辨率,通过经纬度匹配将地面臭氧站点数据与多源特征变量融合,采用臭氧日最大8小时平均浓度(MDA8)作为核心预测指标,初始得到166805条数据;
- 自动化数据清洗:基于AutoML框架实现自动化缺失值与异常值检测,缺失值采用前后两天数据均值填充,异常值统一标记为缺失值后同法处理,最终得到155090条高质量数据;
- 多重共线性检验:通过皮尔逊相关分析和方差膨胀因子(VIF)检验,发现CO、NOₓ等前体物变量VIF值超过10,存在严重多重共线性,因此将其从基线模型中剔除;补充实验证明,剔除后模型性能无显著变化,同时保证了模型稳定性,最终保留变量的VIF值均低于10。
对应图表解读:图6 20个核心变量的统计分布与箱线图
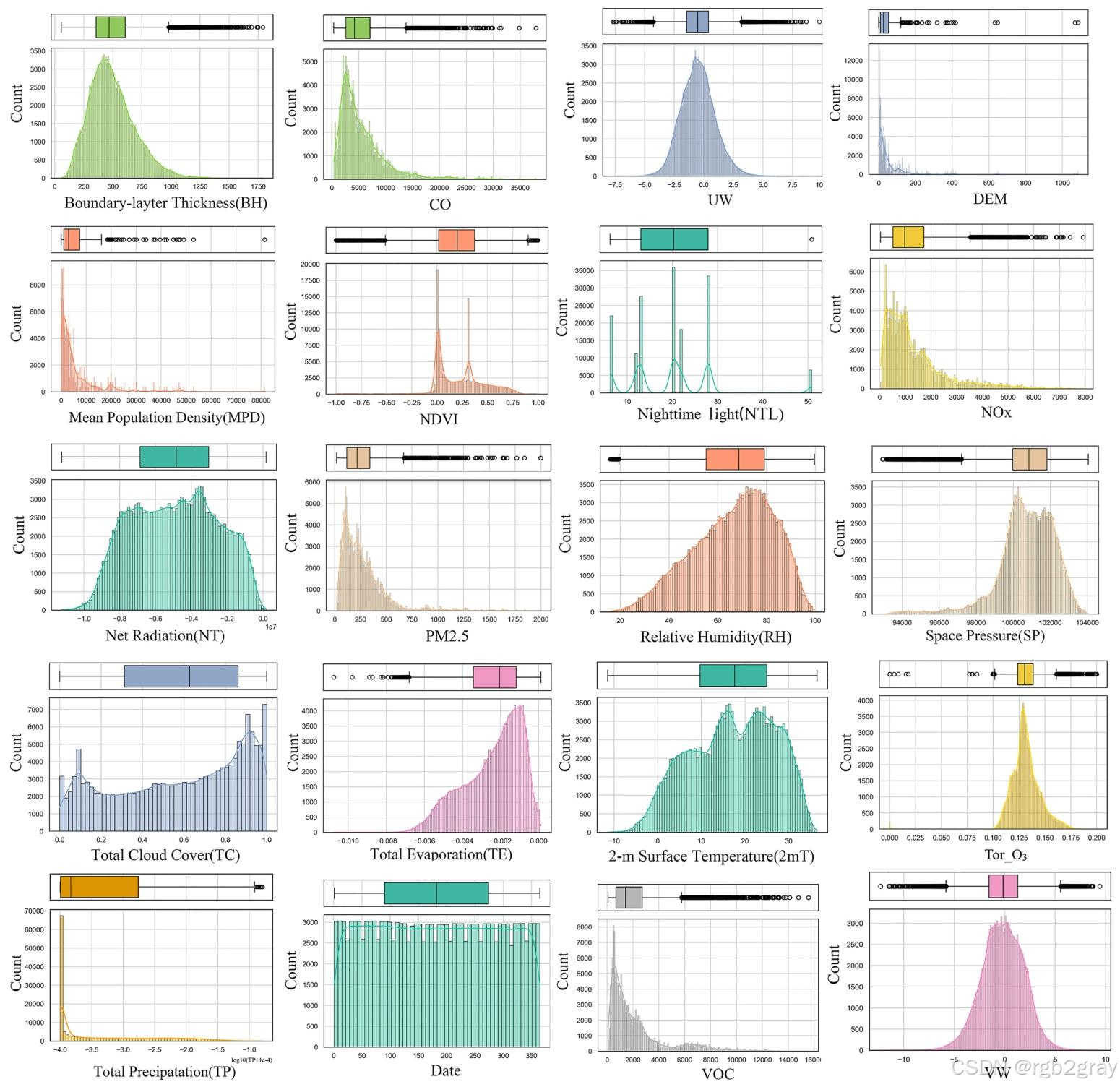
- 图6展示了所有输入变量的概率分布和异常值情况,是数据预处理的关键依据:
- 2m气温、相对湿度、风速等核心气象变量呈近似对称分布,满足机器学习建模的统计假设;
- 总降水量、总蒸散量、净辐射呈明显右偏分布,因此建模前对其进行对数变换,降低极端值对模型的影响;
- NOₓ、VOCs、CO、PM₂.₅等排放变量呈现强偏态和大量异常值,反映了城市和工业排放源的空间分布极不均匀,也为后续多重共线性处理提供了数据支撑。
对应图表解读:图7 变量皮尔逊相关分析图
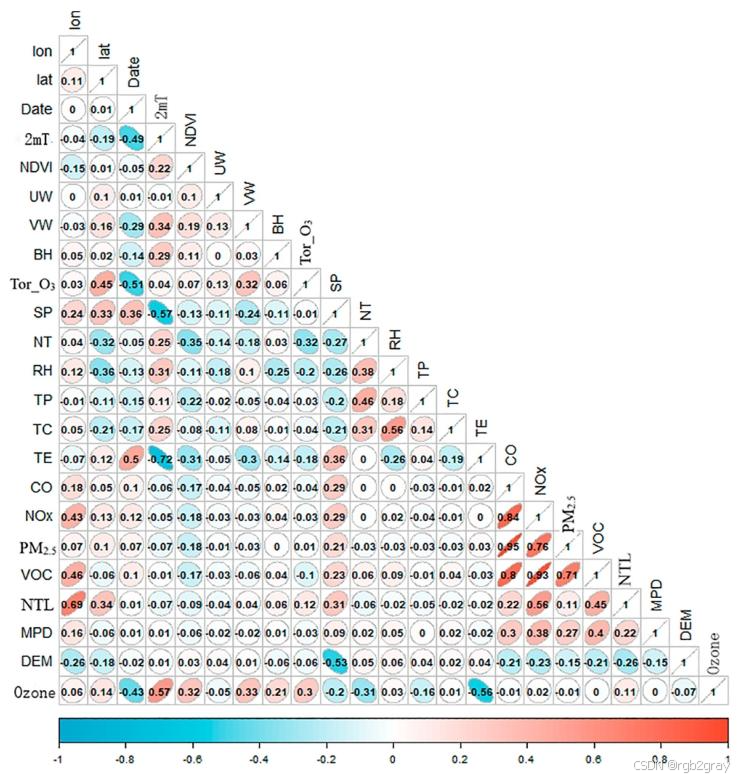
- 图7量化了22个变量(含时空、环境因子)间的线性相关关系,是特征筛选的核心依据:
- 与近地面臭氧呈显著正相关的变量:2m气温(2mT)、NDVI、对流层臭氧柱浓度(Tor_O₃),符合高温促进光化学反应、植被排放生物源VOCs、对流层臭氧垂直传输的物理机制;
- 与近地面臭氧呈显著负相关的变量:年积日(Date)、净辐射(NT)、蒸散量(TE)、风速(UW/VW),反映了臭氧的季节变化特征,以及强风促进污染物扩散、高湿度抑制光化学反应的规律;
- 该分析仅能刻画线性相关关系,无法体现非线性交互作用和因果关系,因此需要后续SHAP和因果推断模型进一步分析。
三、核心方法论详解(重点)
论文的核心技术框架分为三大模块,环环相扣,本节将对每个模块的算法原理、论文实现细节进行深度拆解,并对应解读核心算法示意图。
3.1 整体研究框架
对应图表解读:图2 基于AutoML-SHAP和因果推断的臭氧驱动因子识别框架
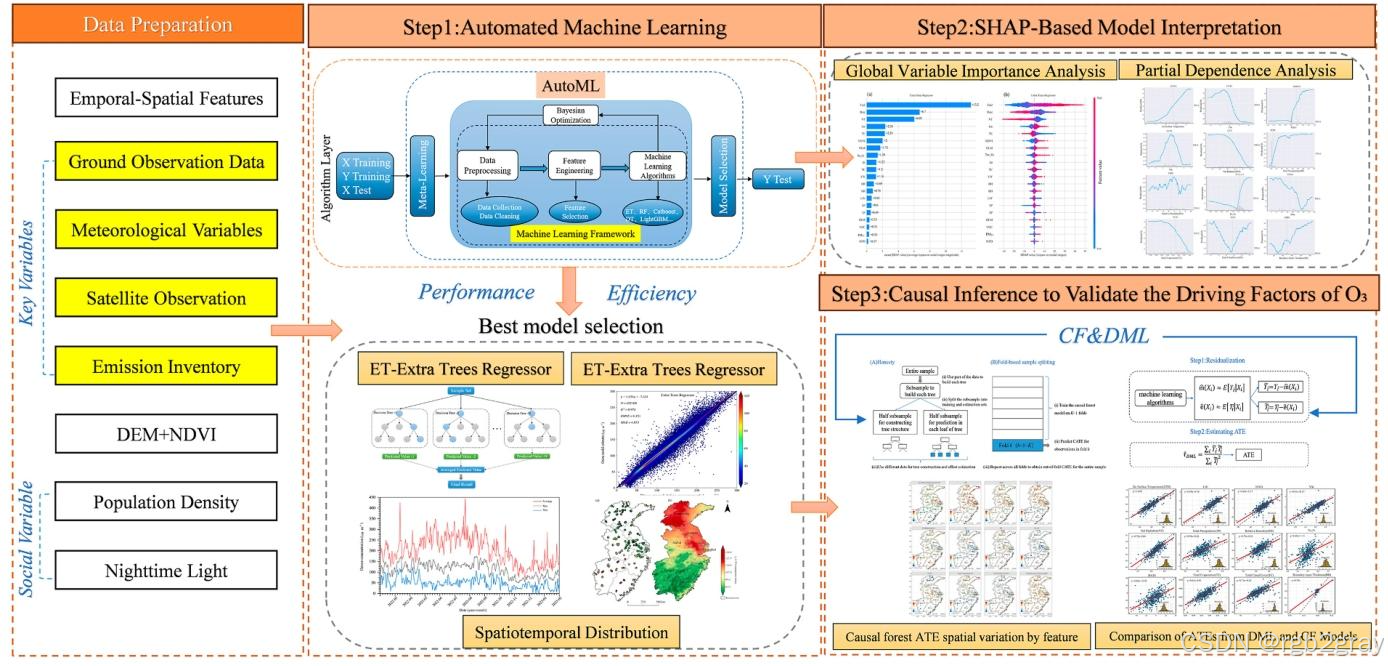
论文的分析流程分为三大核心步骤,形成了完整的闭环分析:
- Step1:自动化机器学习(AutoML):完成数据预处理、多算法对比、最优模型筛选(Extra Trees),实现近地面臭氧浓度的高精度预测,为后续解释性分析和因果推断提供基础模型;
- Step2:基于SHAP的模型解释:通过SHAP值进行全局特征重要性分析和偏依赖分析,量化每个变量对臭氧预测的贡献大小、影响方向和非线性作用模式,筛选出核心影响变量,为因果推断提供处理变量;
- Step3:因果推断验证驱动因子:基于SHAP筛选的核心变量,分别构建Causal Forest(CF)和Double Machine Learning(DML)模型,估计各变量的平均处理效应(ATE)和条件平均处理效应(CATE),验证变量对臭氧浓度的因果效应,同时量化其空间异质性。
3.2 自动化机器学习(AutoML)与Extra Trees模型
3.2.1 AutoML核心原理与论文实现
传统机器学习建模需要人工完成数据预处理、特征工程、算法选择、超参数调优,高度依赖人工经验,易引入主观偏差,且模型泛化性和可复现性不足。
AutoML(自动化机器学习)则实现了建模全流程的自动化,论文基于Python开源库PyCaret搭建AutoML框架,核心能力包括:
- 自动化完成数据清洗、缺失值填充、特征筛选;
- 内置19种机器学习算法,涵盖广义线性模型、树模型、梯度提升模型三大类;
- 通过交叉验证自动完成超参数优化和模型性能对比,筛选出最优算法。
论文中纳入对比的5种高性能算法包括:Extra Trees Regressor(ET)、Random Forest Regressor(RF)、CatBoost Regressor、Decision Tree Regressor(DT)、LightGBM。
3.2.2 Extra Trees(极端随机树)算法详解
论文通过AutoML对比,最终筛选出Extra Trees作为臭氧浓度预测的最优模型,其性能显著优于其他算法,本节拆解其核心原理。
对应图表解读:图3 Extra Trees算法原理图
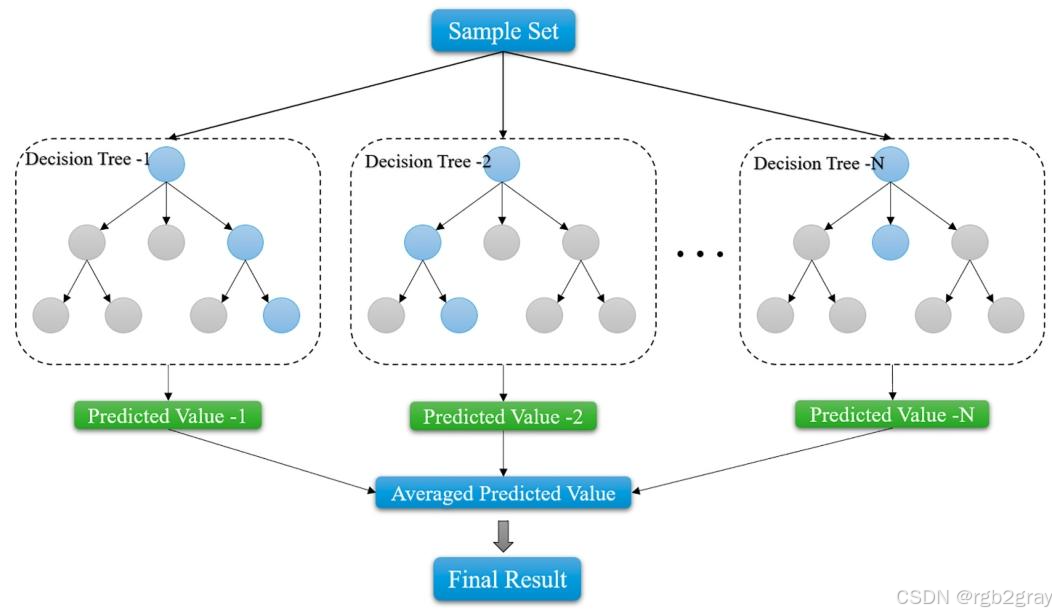
Extra Trees是Geurts等人2006年提出的集成学习算法,属于树模型的集成框架,和随机森林(RF)核心思路一致,都是通过聚合多棵决策树的预测结果得到最终输出,但在节点分裂策略上引入了更强的随机性,核心差异如下:
| 特性 | 随机森林(RF) | 极端随机树(Extra Trees) |
|---|---|---|
| 样本采样 | 对每棵树进行有放回的bootstrap采样 | 使用全部原始样本训练每棵树,无采样 |
| 节点分裂 | 对每个节点,先随机选特征子集,再通过信息增益/基尼系数计算最优分裂点 | 对每个节点,随机选特征子集后,随机生成多个分裂阈值,再从中选最优分裂点 |
| 随机性来源 | 样本随机+特征随机 | 特征随机+分裂阈值随机(双重随机) |
| 过拟合风险 | 中等 | 更低,双重随机策略显著降低过拟合 |
| 非线性拟合能力 | 强 | 更强,对高维、噪声数据鲁棒性更好 |
论文中Extra Trees的核心实现细节:
- 模型输入:经预处理后的17个特征变量(剔除了共线性的CO、NOₓ);
- 模型输出:近地面臭氧日最大8小时平均浓度(MDA8);
- 训练环境:Python 3.9,Jupyter Notebook,通过PyCaret的AutoML流水线完成全流程训练与验证;
- 核心优势:对臭氧形成的复杂非线性关系捕捉能力强,过拟合风险低,为后续SHAP解释提供了高精度的基础模型。
3.3 SHAP可解释性分析
机器学习模型的「黑箱问题」是环境建模的核心痛点——即使模型预测精度高,也无法解释「哪些变量在影响臭氧浓度、影响方向是正还是负、非线性作用模式是什么」。SHAP(SHapley Additive exPlanations,沙普利加和解释)完美解决了这一问题,论文中用其完成特征重要性量化和非线性依赖分析。
3.3.1 SHAP核心原理
SHAP基于合作博弈论中的沙普利值,核心逻辑是:每个特征的SHAP值,等于该特征在所有可能的特征组合中对模型预测结果的边际贡献的平均值。
其核心计算公式如下:
øi=∑S⊆N\{i}∣S∣!⋅(∣N∣−∣S∣−1)!∣N∣![f(S∪{i})−f(S)]ø_{i}=\sum_{S \subseteq N \backslash\{i\}} \frac{|S| ! \cdot(|N|-|S|-1) !}{|N| !}[f(S \cup\{i\})-f(S)]øi=S⊆N\{i}∑∣N∣!∣S∣!⋅(∣N∣−∣S∣−1)![f(S∪{i})−f(S)]
- NNN:所有特征变量的完整集合;
- SSS:不包含特征iii的任意特征子集;
- f(S)f(S)f(S):仅使用子集SSS中的特征时,模型的预测结果;
- f(S∪{i})f(S \cup\{i\})f(S∪{i}):将特征iii加入子集SSS后,模型的预测结果;
- 公式本质:遍历所有特征组合,计算特征iii的边际贡献,再通过加权平均得到最终的SHAP值。
3.3.2 论文中SHAP的核心应用
- 全局特征重要性分析:通过每个特征的平均绝对SHAP值,量化特征对臭氧浓度预测的整体影响程度,实现特征重要性排序;
- 特征影响方向与分布分析:通过SHAP摘要图,展示每个特征的取值高低对臭氧预测的正向/负向影响;
- 偏依赖分析(PDP):通过偏依赖图,刻画单个特征取值变化时,臭氧浓度的边际变化趋势,揭示变量的非线性作用模式,核心公式:
PDP(xi)=1n∑j=1nf(xi,xj,−i)PDP\left(x_{i}\right)=\frac{1}{n} \sum_{j=1}^{n} f\left(x_{i}, x_{j,-i}\right)PDP(xi)=n1j=1∑nf(xi,xj,−i)
- PDP(xi)PDP(x_i)PDP(xi):特征xix_ixi的偏依赖值,代表变量取特定值时,对预测结果的平均影响;
- xj,−ix_{j,-i}xj,−i:第jjj个样本中,除特征xix_ixi外的所有特征向量;
- nnn:样本总数。
论文中基于SHAP库的TreeExplainer模块实现对Extra Trees模型的解释,完美适配树模型的结构,计算效率更高。
3.4 因果推断方法:Causal Forest (CF) 与 Double Machine Learning (DML)
这是论文最核心的创新点——从相关性分析进阶到因果关系识别。SHAP分析只能量化变量与臭氧浓度的相关性,无法回答「这个变量是不是真的导致了臭氧浓度变化」,而因果推断则能在控制混淆变量的前提下,准确估计变量对臭氧浓度的因果效应。
论文中定义的因果问题框架:
- 结果变量(Outcome):近地面臭氧浓度;
- 处理变量(Treatment):SHAP筛选出的核心影响变量(如2m气温、净辐射、Tor_O₃等);
- 控制变量(Confounders):除处理变量外的其他所有特征变量,用于控制混淆因素的影响;
- 核心估计目标:平均处理效应(ATE),即处理变量发生一个单位变化时,臭氧浓度的平均变化量;条件平均处理效应(CATE),即不同子样本/站点下的处理效应,用于刻画空间异质性。
论文同时采用**Causal Forest(因果森林,CF)和Double Machine Learning(双重机器学习,DML)**两种方法,二者形成互补:CF擅长捕捉因果效应的空间异质性,DML擅长估计全局无偏的ATE,二者结果一致则证明因果效应的稳健性。
3.4.1 Causal Forest(CF,因果森林)
核心原理
因果森林是Athey等人2019年提出的非参数因果推断方法,是随机森林的扩展,专门用于估计异质性处理效应,核心创新是**「诚实树(Honest Trees)」**策略。
对应图表解读:图4 因果森林(CF)算法原理图
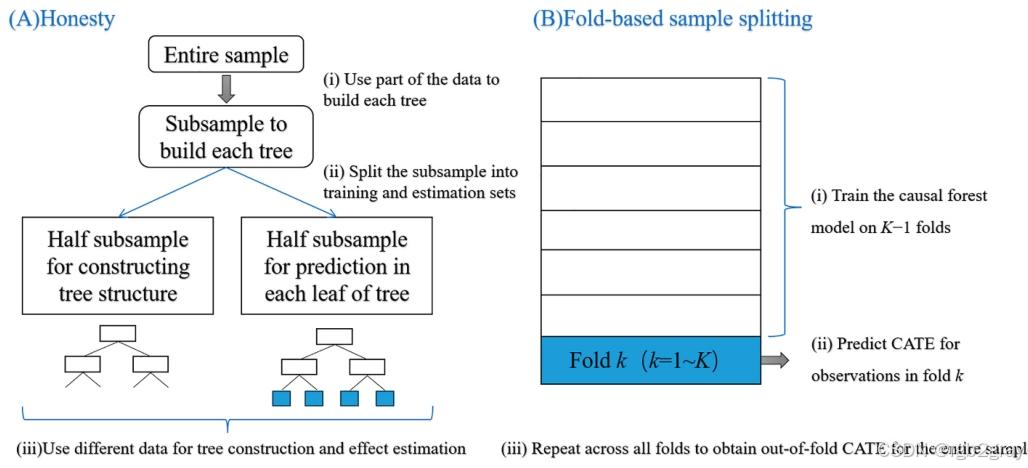
因果森林的核心实现逻辑:
- 诚实树分裂:将数据集随机分为两个子集,一个子集用于构建树的结构(节点分裂),另一个子集用于估计叶子节点的处理效应,彻底避免了传统树模型用同一批数据既建结构又估参数导致的过拟合和偏差;
- 折交叉验证:将数据集分为K折,用K-1折训练因果森林模型,对剩下1折的样本预测CATE,重复所有折后得到全样本的离群CATE估计,保证结果的无偏性;
- CATE估计:基于双稳健估计框架,通过结果变量和处理变量的残差乘积估计每个站点的CATE,再聚合得到整体ATE,核心公式:
τ^s=1n∑i=1n(Yi,s−m^(−i)(Xi,s))(Wi,s−e^(−i)(Xi,s))1n∑i=1n(Wi,s−e^(−i)(Xi,s))2\hat{\tau}_{s}=\frac{\frac{1}{n} \sum_{i=1}^{n}\left(Y_{i, s}-\hat{m}^{(-i)}\left(X_{i, s}\right)\right)\left(W_{i, s}-\hat{e}^{(-i)}\left(X_{i, s}\right)\right)}{\frac{1}{n} \sum_{i=1}^{n}\left(W_{i, s}-\hat{e}^{(-i)}\left(X_{i, s}\right)\right)^{2}}τ^s=n1∑i=1n(Wi,s−e^(−i)(Xi,s))2n1∑i=1n(Yi,s−m^(−i)(Xi,s))(Wi,s−e^(−i)(Xi,s))
- τ^s\hat{\tau}_{s}τ^s:站点sss的条件平均处理效应(CATE);
- Yi,sY_{i,s}Yi,s:站点sss第iii个样本的结果变量(臭氧浓度);
- Wi,sW_{i,s}Wi,s:站点sss第iii个样本的处理变量;
- m^(−i)(Xi,s)\hat{m}^{(-i)}(X_{i,s})m^(−i)(Xi,s):剔除第iii个样本后,模型对结果变量的预测值;
- e^(−i)(Xi,s)\hat{e}^{(-i)}(X_{i,s})e^(−i)(Xi,s):剔除第iii个样本后,模型对处理变量的倾向得分预测值;
- 双稳健特性:只要结果模型m^\hat{m}m^或倾向得分模型e^\hat{e}e^其中一个设定正确,就能得到一致的因果效应估计。
论文中CF的实现细节
- 运行环境:RStudio,基于
grf包实现; - 模型设计:为457个监测站点分别构建独立的CF模型,估计每个站点的CATE,从而刻画因果效应的空间异质性;
- 变量设置:将SHAP筛选的关键变量(2mT、UW/VW、NDVI、Tor_O₃、TP、RH等)依次作为处理变量,其余变量作为控制变量;
- 输出结果:每个变量的CATE空间分布、整体ATE值,以及95%置信区间。
3.4.2 Double Machine Learning(DML,双重机器学习)
核心原理
DML由Chernozhukov等人2017年提出,核心解决高维混淆变量下的因果效应估计偏差问题,基于奈曼正交得分函数,通过「两阶段残差化」实现无偏、稳健的ATE估计。
对应图表解读:图5 双重机器学习(DML)算法原理图
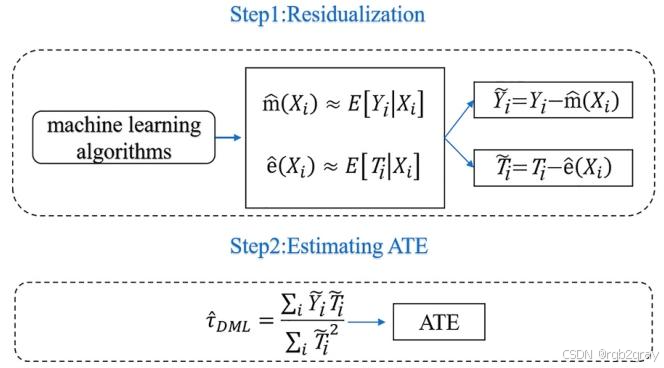
DML的核心实现分为两步:
- Step1:残差化处理
- 用机器学习模型拟合结果变量YYY(臭氧浓度)与控制变量XXX的关系,得到结果残差Y~=Y−Y^(X)\tilde{Y}=Y-\hat{Y}(X)Y~=Y−Y^(X),剔除控制变量对结果变量的影响;
- 用机器学习模型拟合处理变量WWW与控制变量XXX的关系,得到处理残差W~=W−W^(X)\tilde{W}=W-\hat{W}(X)W~=W−W^(X),剔除控制变量对处理变量的影响;
- 残差化的核心意义:剥离混淆变量的影响,剩下的残差仅反映处理变量对结果变量的净影响。
- Step2:ATE估计
- 对结果残差Y~\tilde{Y}Y~和处理残差W~\tilde{W}W~进行线性回归,回归系数即为全局平均处理效应(ATE),公式:
τ^DML=∑W~iY~i∑W~i2\hat{\tau}_{DML}=\frac{\sum \tilde{W}_i \tilde{Y}_i}{\sum \tilde{W}_i^2}τ^DML=∑W~i2∑W~iY~i
- 对结果残差Y~\tilde{Y}Y~和处理残差W~\tilde{W}W~进行线性回归,回归系数即为全局平均处理效应(ATE),公式:
论文中DML的核心作用
- 估计核心变量的全局ATE,与CF模型得到的空间平均ATE进行对比验证;
- 若两种方法得到的ATE方向、大小高度一致,则证明该变量对臭氧浓度的因果效应是稳健、可靠的;
- 补充计算ATE的95%置信区间,量化因果估计的不确定性。
对应图表解读:图13 变量因果关系有向无环图(DAG)
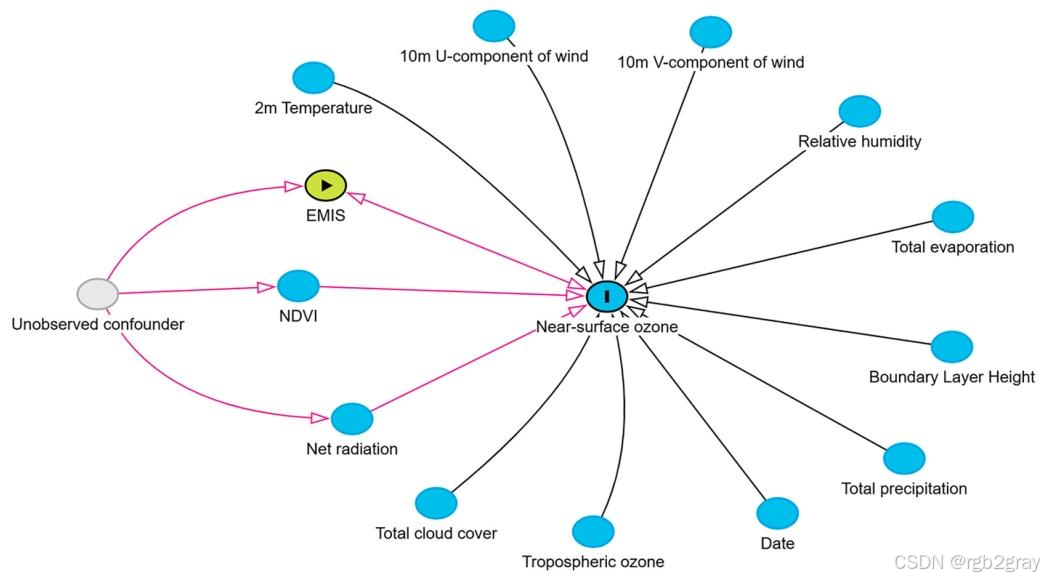
- 论文通过DAG明确了变量间的假设因果关系,清晰展示了气象、地表、排放相关变量对近地面臭氧的影响路径,以及潜在的混淆变量和未观测混淆因素;
- DAG是因果推断的核心前提,明确了变量间的因果顺序,避免了「碰撞偏倚」和「混淆偏倚」,保证了因果识别策略的合理性。
3.5 模型评估指标
论文采用三个经典的回归评估指标,全面评价臭氧浓度预测模型的性能,分别是决定系数R2R^2R2、均方根误差(RMSE)、平均绝对误差(MAE),计算公式如下:
-
决定系数R2R^2R2:量化模型能解释的臭氧浓度变异的比例,越接近1代表模型拟合效果越好
R2=(∑t=1n(yot−y‾o)⋅(ymt−y‾m))2∑t=1n(yot−y‾o)2⋅(ymt−y‾m)2R^{2}=\frac{\left(\sum_{t=1}^{n}\left(y_{o t}-\overline{y}_{o}\right) \cdot\left(y_{m t}-\overline{y}_{m}\right)\right)^{2}}{\sum_{t=1}^{n}\left(y_{o t}-\overline{y}_{o}\right)^{2} \cdot\left(y_{m t}-\overline{y}_{m}\right)^{2}}R2=∑t=1n(yot−yo)2⋅(ymt−ym)2(∑t=1n(yot−yo)⋅(ymt−ym))2 -
均方根误差(RMSE):衡量预测值与观测值的偏差,放大了大误差的影响,反映模型对极端浓度的预测能力,值越小精度越高
RMSE=1n∑t=1n(yot−ymt)2RMSE=\sqrt{\frac{1}{n} \sum_{t=1}^{n}\left(y_{o t}-y_{m t}\right)^{2}}RMSE=n1t=1∑n(yot−ymt)2 -
平均绝对误差(MAE):衡量预测值与观测值的平均绝对偏差,对异常值不敏感,反映模型的整体预测稳定性,值越小精度越高
MAE=1n∑t=1n∣yot−ymt∣MAE=\frac{1}{n} \sum_{t=1}^{n}\left|y_{o t}-y_{m t}\right|MAE=n1t=1∑n∣yot−ymt∣
公式中,yoty_{ot}yot为臭氧浓度观测值,ymty_{mt}ymt为模型预测值,y‾o\overline{y}_oyo和y‾m\overline{y}_mym分别为观测值和预测值的均值,nnn为监测站点数量。
四、实验结果与分析
4.1 模型构建与验证结果
4.1.1 多算法性能对比
对应图表解读:表2 模型精度对比表
| 模型缩写 | 模型全称 | MAE(μg/m³) | RMSE(μg/m³) | R² |
|---|---|---|---|---|
| ET | Extra Trees Regressor | 8.3342 | 12.7055 | 0.9311 |
| RF | Random Forest Regressor | 9.0757 | 13.5938 | 0.9212 |
| CatBoost | CatBoost Regressor | 13.0801 | 17.9447 | 0.8627 |
| DT | Decision Tree Regressor | 12.4269 | 20.0829 | 0.8279 |
| LightGBM | Light Gradient Boosting Machine | 15.4176 | 20.7471 | 0.8164 |
结果解读:
- Extra Trees(ET)模型在所有指标上均表现最优,MAE仅8.33μg/m³,RMSE为12.71μg/m³,R2R^2R2高达0.9311,显著优于其他模型,证明其对臭氧浓度的非线性变化捕捉能力最强;
- 集成树模型(ET、RF)的性能远优于单棵决策树(DT)和梯度提升模型(CatBoost、LightGBM),体现了集成学习在环境污染物浓度预测中的优势;
- 该结果验证了AutoML框架的有效性,通过自动化对比筛选出了最优算法,避免了人工选模型的主观偏差。
4.1.2 模型整体精度验证
对应图表解读:图8 臭氧日浓度估计精度验证密度散点图
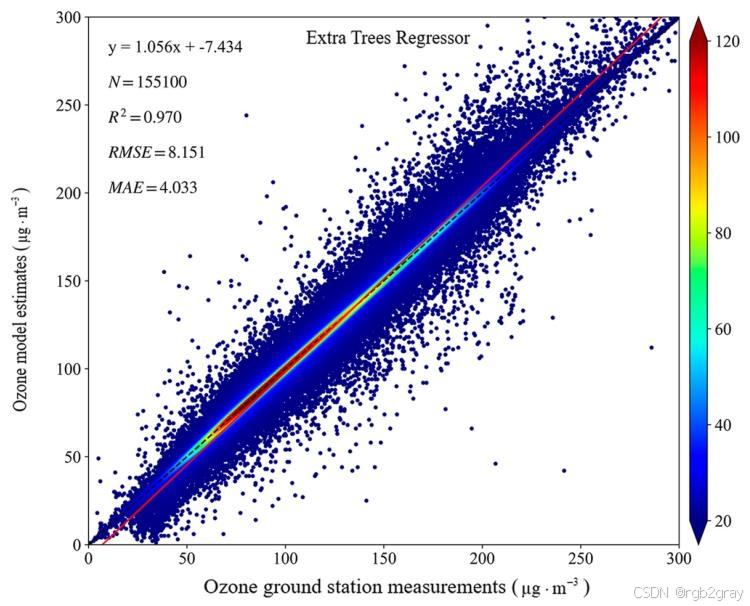
- 图8展示了ET模型预测值与地面站点观测值的拟合效果,拟合方程为y=1.056x−7.434y=1.056x-7.434y=1.056x−7.434,样本量N=155100N=155100N=155100,验证集R2=0.970R^2=0.970R2=0.970,RMSE=8.151μg/m³,MAE=4.033μg/m³;
- 散点高度集中在1:1拟合线附近,无明显的系统偏差,证明ET模型能精准复现中国东部近地面臭氧的逐日浓度变化,预测精度极高。
4.1.3 模型季节性稳定性验证
对应图表解读:图9 模型估计的季节性验证散点图
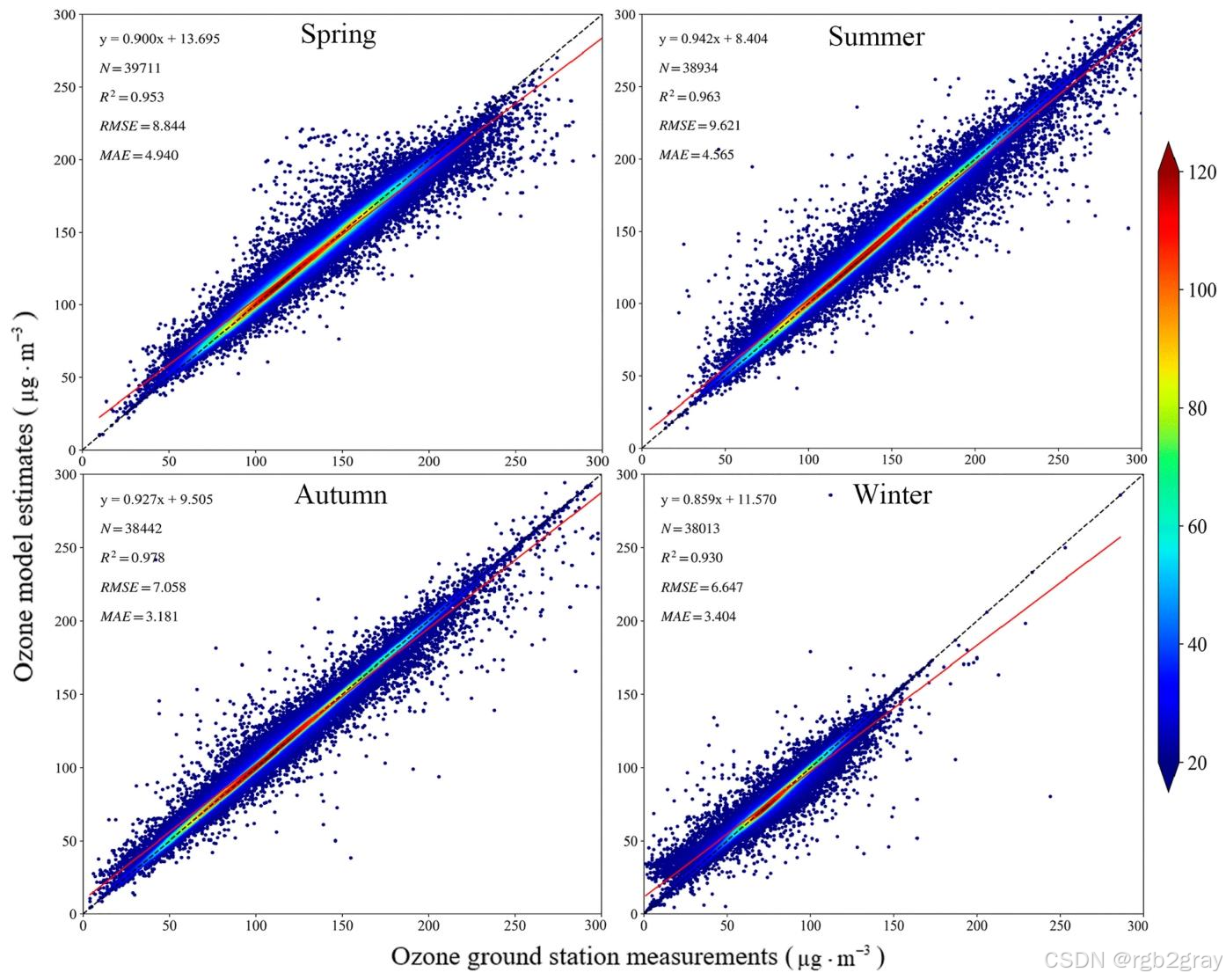
- 图9分别展示了春、夏、秋、冬四个季节的模型拟合效果,四个季节的验证集R2R^2R2分别为0.953、0.963、0.978、0.930,均保持在0.93以上;
- 四个季节的RMSE和MAE均维持在较低水平,即使是臭氧浓度最低、变异性最弱的冬季,模型仍保持极高的拟合精度;
- 该结果证明ET模型在不同季节、不同气象条件下均具有极强的稳定性和泛化能力,无季节性偏差。
4.1.4 臭氧浓度时空分布特征
对应图表解读:图10 中国东部近地面臭氧浓度时空分布图
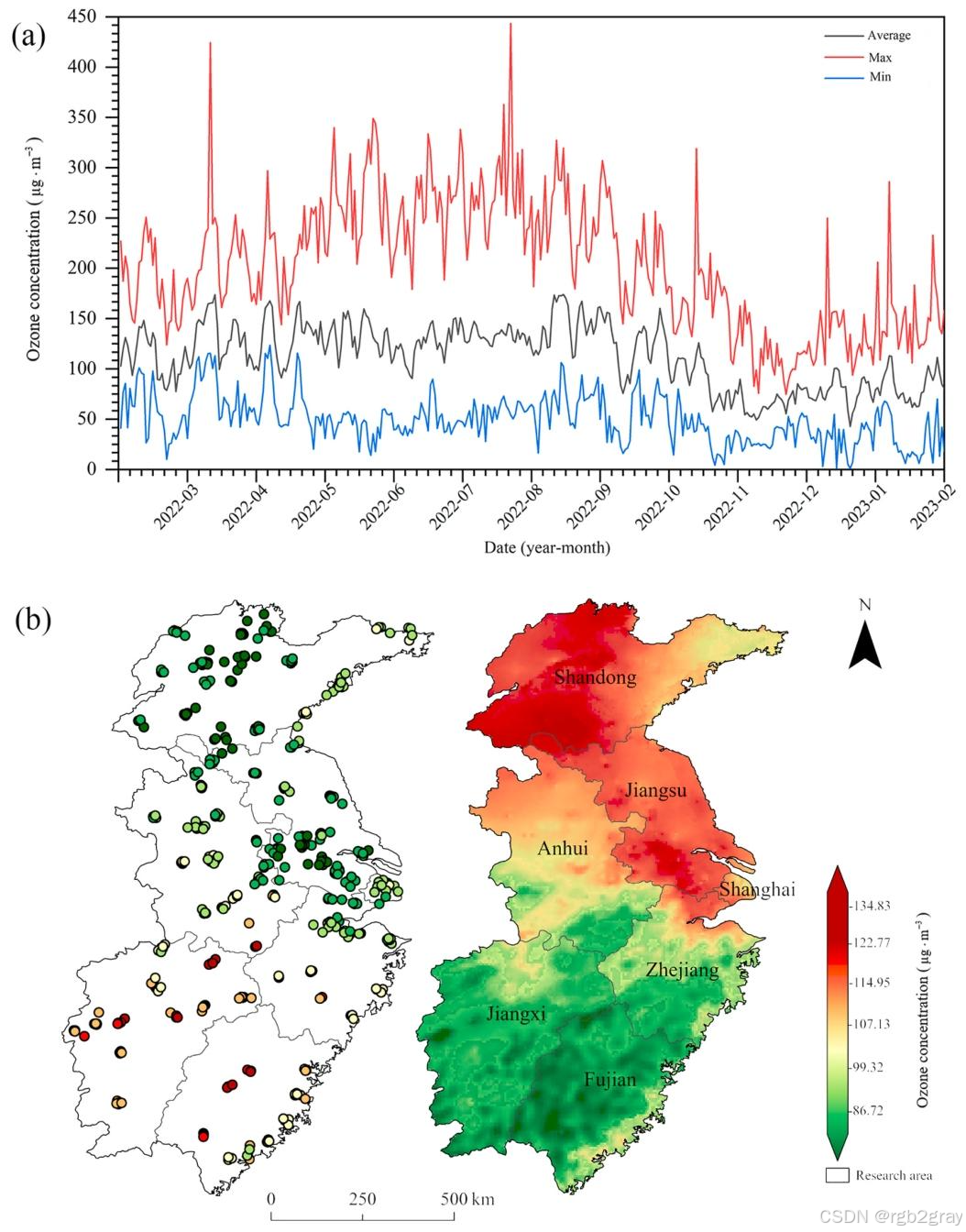
-
图10(a) 时间变化特征:展示了2022年3月-2023年2月臭氧日浓度的最大值、平均值、最小值变化,核心特征:
- 臭氧浓度呈现极强的季节性规律,夏季(6-8月)浓度最高,多次超过300μg/m³,秋冬季浓度显著下降;
- 研究期内,臭氧日浓度超过国家一级标准(100μg/m³)的天数达131天,占比35.9%,证明中国东部臭氧污染的持续性和严重性;
- 年均浓度范围为42.67~173.93μg/m³,峰值和谷值差异极大,体现了臭氧浓度的强时间异质性。
-
图10(b) 空间分布特征:展示了研究区臭氧年均浓度的空间分布,核心特征:
- 整体呈现「北高南低」的空间梯度,高值区集中在山东、江苏、安徽北部,低值区出现在江西、福建、浙江南部;
- 站点观测年均浓度为117.75μg/m³,模型预测均值为112.22μg/m³,偏差极小,证明模型对臭氧空间分布的模拟能力极强;
- 空间异质性与区域工业排放强度、地形、气候条件高度相关:北部平原地区工业排放强、污染物扩散条件差,臭氧浓度高;南部山地丘陵地区植被覆盖率高、降水多、扩散条件好,臭氧浓度低。
4.2 基于SHAP的特征重要性与依赖分析
4.2.1 全局特征重要性分析
对应图表解读:图11(a) SHAP全局特征重要性图
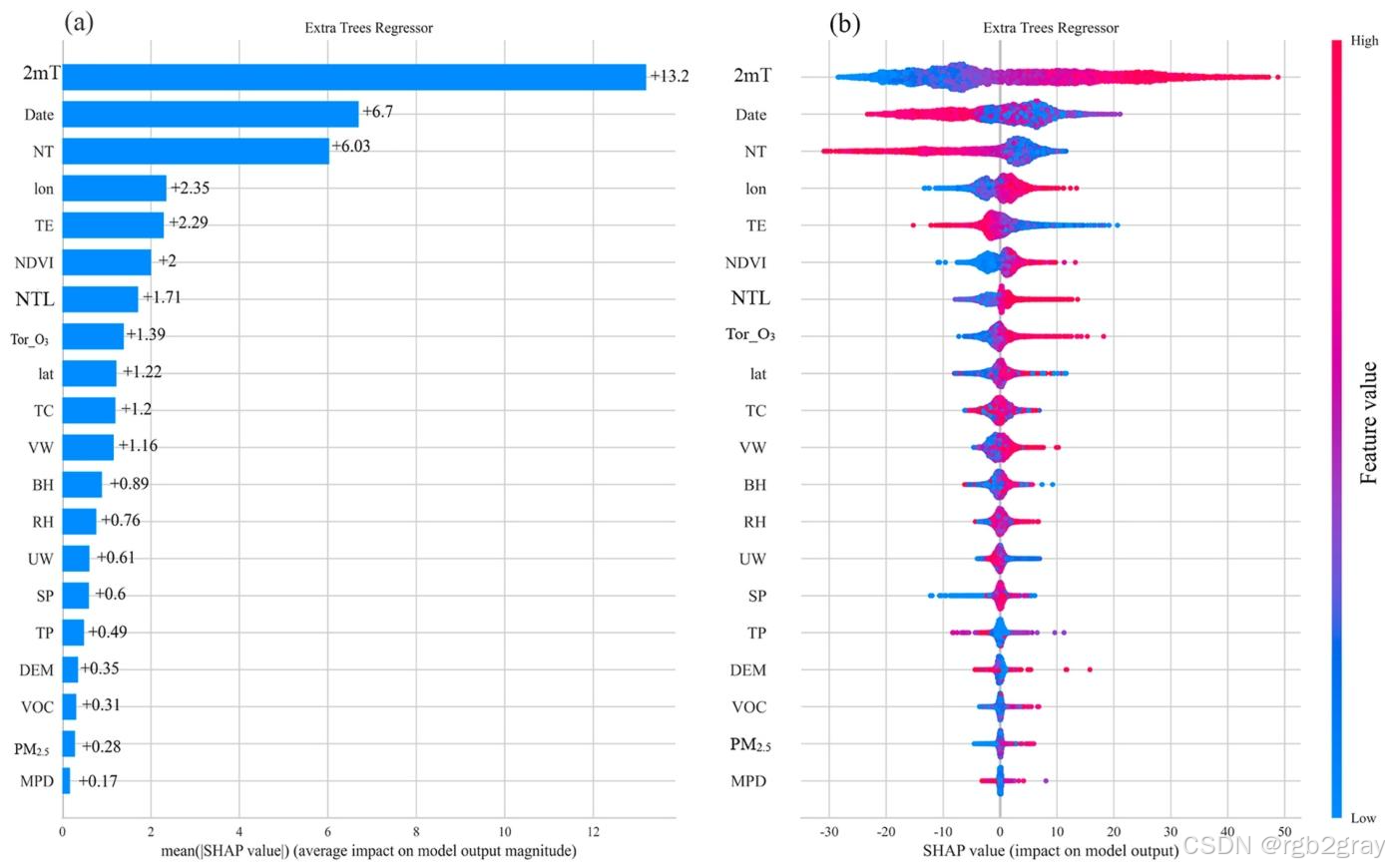
- 图11(a)通过平均SHAP值量化了所有特征对臭氧浓度预测的重要性排序,核心结论:
- 气象因子是臭氧浓度变化的绝对主导因素:排名前3的特征分别是2m地表气温(2mT)、年积日(Date)、净辐射(NT),均为气象/时间相关因子,其平均SHAP值远高于其他变量;
- 其他重要特征依次为经度、总蒸散量(TE)、NDVI、夜间灯光(NTL)、对流层臭氧柱浓度(Tor_O₃)、纬度等;
- 排放相关变量(VOCs、PM₂.₅)的特征重要性排名靠后,说明在研究期内,气象条件对臭氧逐日变化的影响远大于前体物排放的变化。
4.2.2 特征影响方向与分布分析
对应图表解读:图11(b) SHAP摘要图
- 图11(b)中,横轴为SHAP值(正值代表提升臭氧浓度,负值代表降低臭氧浓度),点的颜色代表特征取值的高低(红色为高值,蓝色为低值),核心结论:
- 2m气温(2mT):特征值越高(温度越高),SHAP值显著为正,证明高温显著促进臭氧浓度升高,完全符合光化学反应的物理机制;
- 对流层臭氧柱浓度(Tor_O₃)、夜间灯光(NTL)、经度:高值对应正SHAP值,说明区域背景臭氧传输、城市人为活动强度提升、越靠近东部沿海,臭氧浓度越高;
- 年积日(Date)、净辐射(NT)、总蒸散量(TE):高值对应负SHAP值,说明随着季节向秋冬季推进、净辐射和蒸散量升高,臭氧浓度显著降低。
4.2.3 特征非线性偏依赖分析
对应图表解读:图12 核心变量的偏依赖图(PDP)
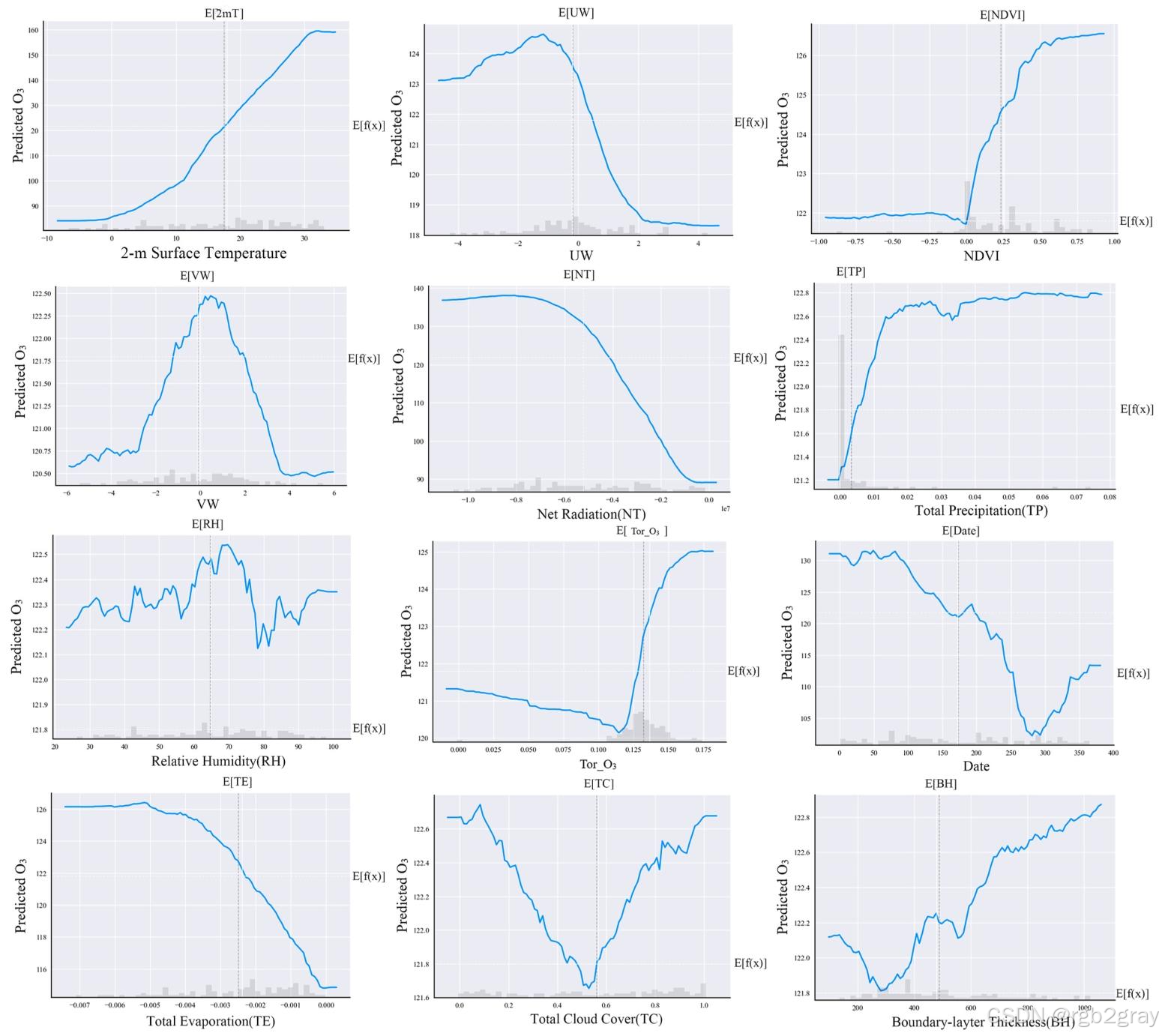
- 图12展示了关键变量取值变化时,臭氧浓度的边际变化趋势,揭示了变量的非线性作用模式,核心结论:
- 2m气温(2mT):与臭氧浓度呈强单调正相关,温度越高,臭氧浓度线性升高,再次验证了高温是臭氧生成的核心驱动因子;
- NDVI:存在明显的阈值效应,NDVI低于0.2时,臭氧浓度缓慢上升;超过0.2后,臭氧浓度快速升高,说明高植被覆盖区生物源VOCs排放显著增强,促进臭氧生成;
- 风速(UW/VW):与臭氧浓度呈「驼峰型」关系,中等风速促进污染物积累,臭氧浓度升高;强风速则显著稀释臭氧,浓度下降;
- 对流层臭氧柱浓度(Tor_O₃):存在明显的阈值效应,超过临界值后,对近地面臭氧的影响显著增强,证明区域背景传输对近地面臭氧的贡献存在非线性特征;
- 相对湿度(RH):与臭氧浓度呈单调负相关,湿度越高,臭氧浓度越低,因为高湿度抑制光化学反应,同时促进前体物的湿沉降;
- 年积日(Date):呈现明显的循环周期,夏季臭氧浓度最高,秋冬季最低,完美匹配臭氧的季节变化规律。
4.3 基于因果推断的臭氧驱动因子识别
4.3.1 因果效应的空间异质性分析
对应图表解读:图14 基于因果森林模型的不同变量ATE空间分布图
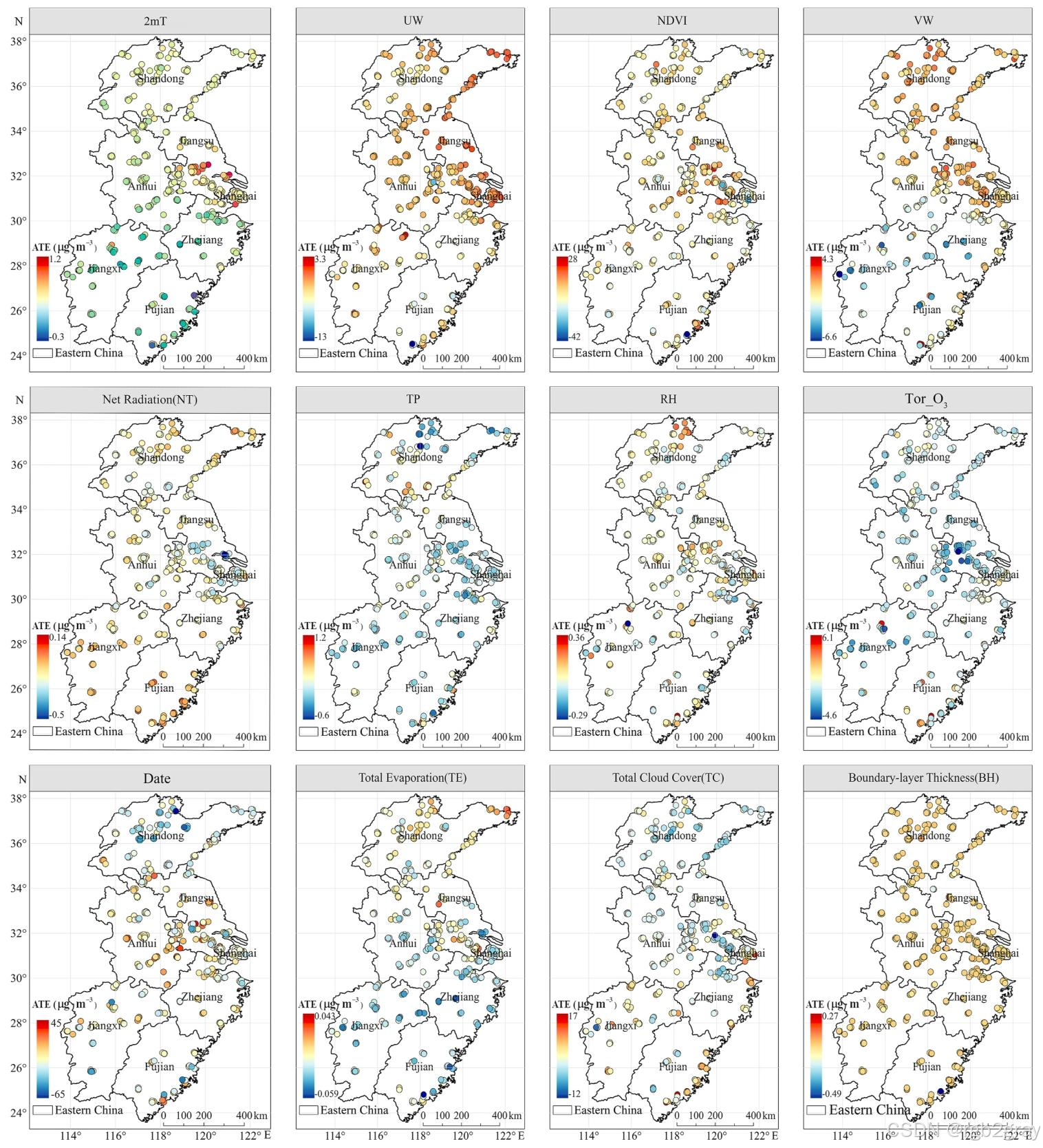
- 图14展示了核心变量平均处理效应(ATE)的空间分布,暖色代表正因果效应(提升臭氧浓度),冷色代表负因果效应(降低臭氧浓度),颜色越深代表因果效应越强,这是论文最核心的结果之一,核心结论:
- 2m地表气温(2mT):在整个研究区均呈现显著的正因果效应,高值区集中在山东、江苏等高排放省份,证明温度升高对臭氧生成的强正向因果影响,且在工业排放强度高的区域效应更强;
- NDVI:在山东半岛、苏皖交界区域呈现显著的正因果效应,证明这些区域的生物源VOCs排放对臭氧生成有显著的因果贡献;
- 对流层臭氧柱浓度(Tor_O₃):在江苏中部、浙江北部呈现显著的正因果效应,证明这些区域存在显著的对流层臭氧向下传输,区域背景传输是近地面臭氧的重要驱动因子;
- 净辐射(NT)、总蒸散量(TE)、总降水量(TP):在南部区域(江西、福建、浙江中南部)呈现显著的负因果效应,证明高湿度、降水多的环境显著抑制臭氧生成;
- 风速(UW/VW):在研究区大部分区域呈正因果效应,反映了区域传输对臭氧的影响,尤其是中国东部北部区域,受京津冀地区臭氧和前体物平流输送的影响显著;
- 边界层高度(BH):在安徽中南部、江苏、浙江北部呈正因果效应,边界层升高增强了垂直混合,促进对流层臭氧向近地面传输;
- 总云量(TC):在大部分站点呈负因果效应,云量增加削弱太阳辐射,抑制光化学反应,显著降低臭氧浓度;
- 年积日(Date):整体呈负因果效应,在山东中部、安徽北部效应更强,反映了这些区域臭氧浓度的季节波动更显著。
4.3.2 双因果模型的稳健性验证
对应图表解读:图15 CF与DML模型的ATE对比图
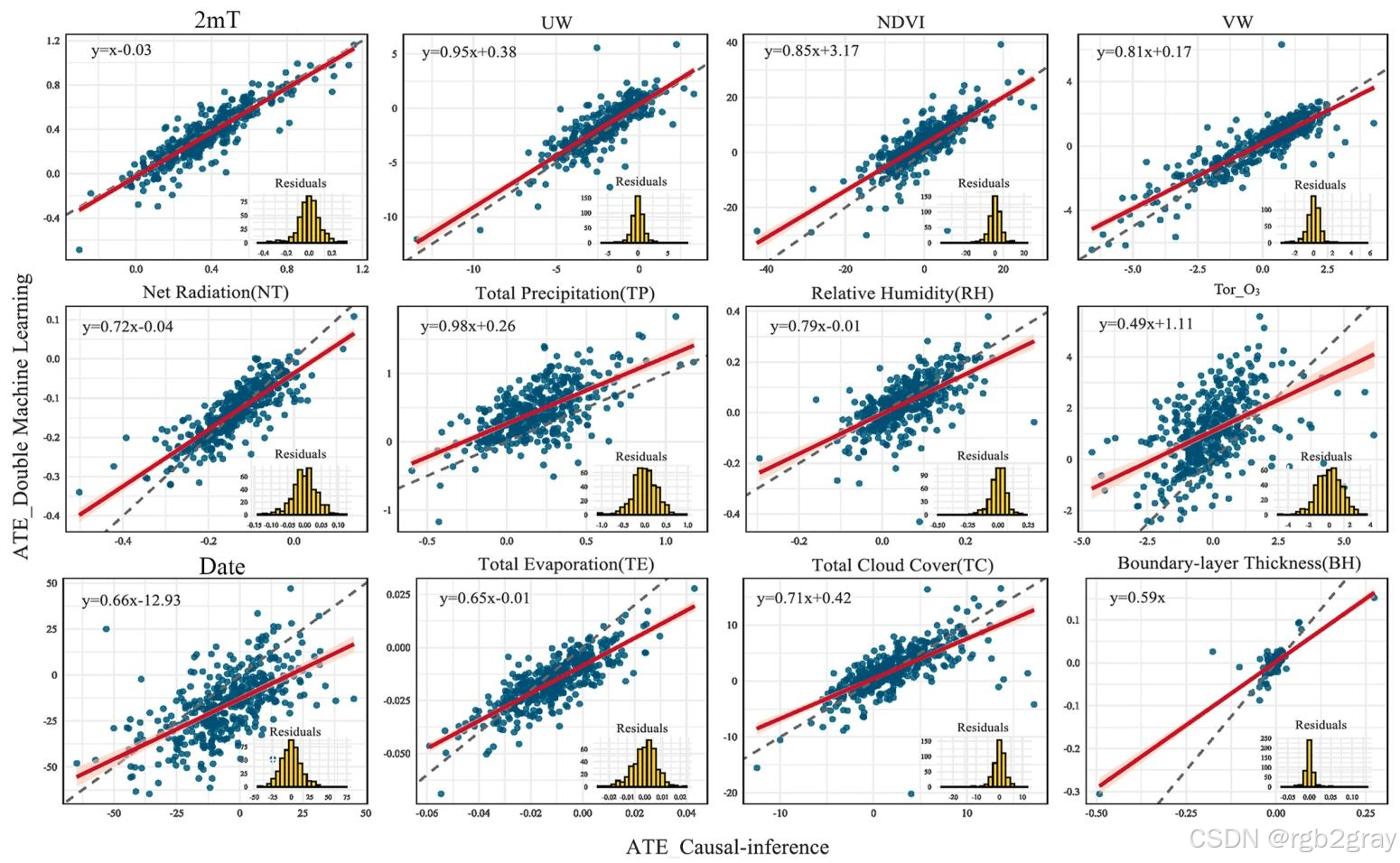
- 图15的横轴为CF模型得到的站点平均ATE,纵轴为DML模型得到的全局ATE,每个散点对应一个站点的变量ATE对,核心结论:
- 2m气温(2mT)、NDVI、净辐射(NT)、风速(UW/VW)、总降水量(TP)等核心变量的ATE在两种方法中呈现极强的一致性,回归斜率接近1,残差呈正态分布,证明这些变量的因果效应估计是高度稳健的;
- Tor_O₃和Date的ATE也呈现强一致性,但部分站点存在偏差,说明其因果效应受时间变化和区域传输的影响,存在一定的空间异质性;
- 蒸散量(TE)、相对湿度(RH)、总云量(TC)、边界层高度(BH)的拟合斜率略低于1,残差分散性更大,说明其因果效应的空间异质性更强,对控制变量的选择更敏感;
- 所有变量的ATE均呈现显著的正相关关系,证明CF和DML两种方法的结果交叉验证了核心驱动因子的因果效应,结论可靠。
4.3.3 因果效应的不确定性分析
对应图表解读:图16 CF和DML框架下的ATE估计值与95%置信区间
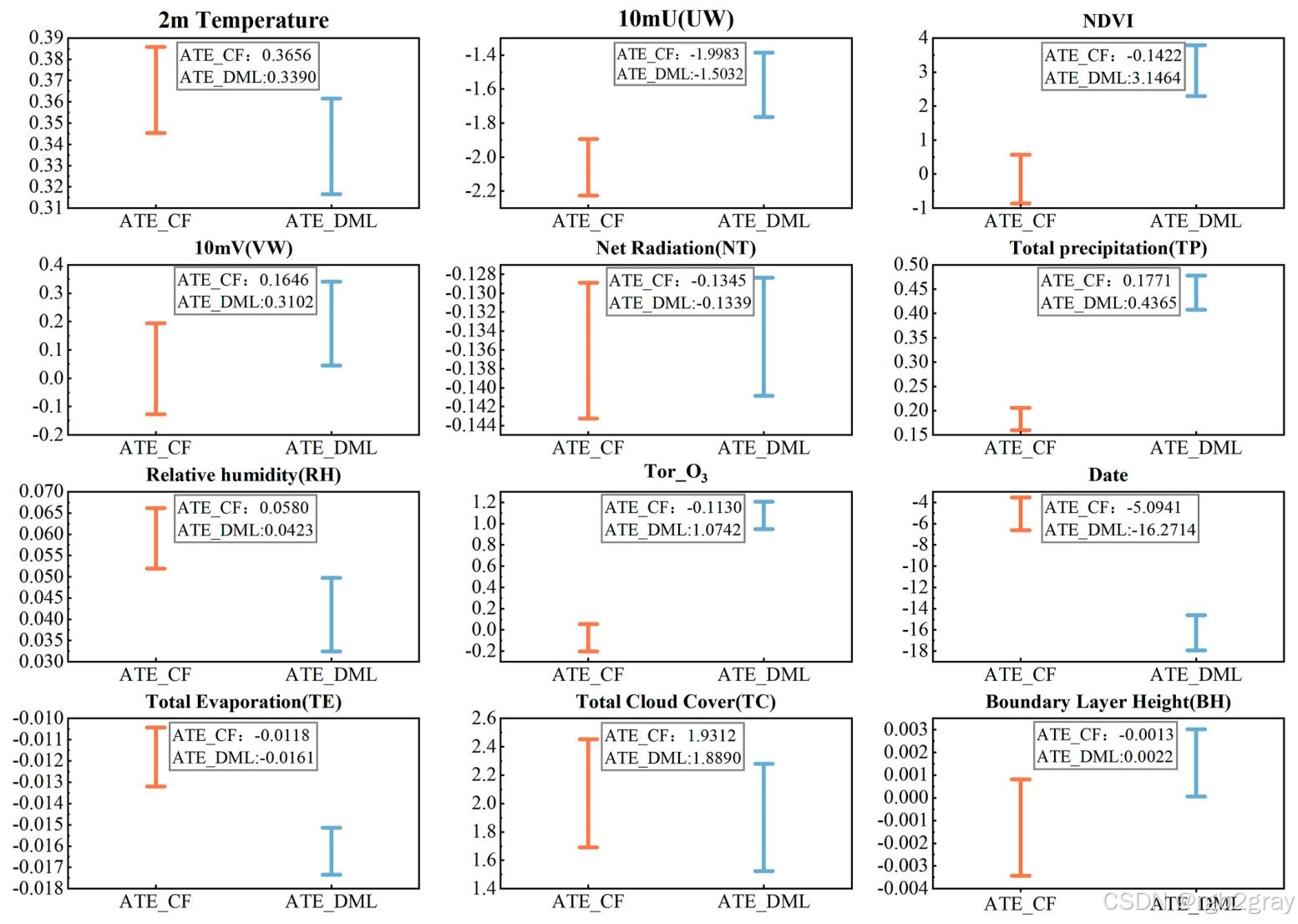
- 图16展示了所有核心变量的ATE点估计和95%置信区间,核心结论:
- 2m气温、NDVI、风速、Tor_O₃等变量的置信区间窄,且不包含0,证明其因果效应统计显著,估计结果稳定;
- 水汽、云量相关变量的置信区间相对更宽,反映其空间变异性更高,对局地气象条件更敏感;
- CF和DML两种方法得到的ATE点估计高度接近,置信区间大部分重叠,再次验证了因果效应估计的稳健性。
五、论文讨论部分深度解读
5.1 数据时间代表性
论文研究期为2022年3月-2023年2月,仅1年时间,作者对此进行了充分论证:
- 研究采用日分辨率数据,完整覆盖了臭氧的季节、日内变化周期,能充分捕捉短期气象驱动因子的影响;
- 对比2017-2023年全国臭氧平均浓度和超标频率,2022-2023年处于多年平均范围内,无异常事件和政策突变,数据具有代表性;
- 研究期内臭氧日浓度的概率分布与长期气候态一致,能反映典型的臭氧变化特征;
- 该时间框架的选择是为了聚焦模型可解释性和日尺度因果机制,框架可直接扩展到多年数据集,用于分析年际变化和政策效应。
5.2 模型适用性、局限性与可靠性
模型可靠性验证
- 十折交叉验证、季节性测试、空间对比验证均证明模型预测精度稳定,无过拟合;
- CF和DML双因果模型的结果高度一致,验证了因果解释的稳健性。
模型局限性
- 在罕见、极端气象条件下(如静稳天气、异常湿度事件),模型预测精度会下降,因为这些场景在训练数据中占比低;
- 模型针对中国东部区域校准,向其他气候区、排放场景的迁移性需要进一步验证;
- 研究主要采用同期变量,未纳入滞后预测因子,无法充分捕捉臭氧的日持续性和天气尺度变异性。
5.3 与传统方法的性能对比
论文将提出的AutoML-SHAP框架与传统方法进行了全面对比,核心优势如下:
| 方法类型 | 核心局限 | 本文框架的优势 |
|---|---|---|
| 化学传输模型(WRF-CMAQ等) | 空间分辨率粗、计算成本高、排放清单不确定性大、系统偏差显著 | 计算效率高、无需复杂的排放清单输入、预测精度更高,同时能通过可解释性和因果推断揭示驱动机制 |
| 传统统计模型(线性回归等) | 仅能捕捉线性关系,无法刻画非线性交互作用 | 完美捕捉多因子的非线性耦合关系,同时通过SHAP和因果推断保证了结果的可解释性 |
| 传统机器学习模型(RF、XGBoost) | 黑箱问题,仅能分析相关性,无法识别因果关系,人工调参依赖强 | 通过AutoML实现自动化建模,减少人工偏差;通过SHAP解决黑箱问题;通过因果推断实现从相关到因果的跨越 |
| 现有AutoML+SHAP研究 | 缺乏因果验证,无法区分真实驱动机制和虚假相关 | 融合双因果推断模型,交叉验证变量的因果效应,结论更具科学可靠性 |
本文框架最终实现了R2=0.93R^2=0.93R2=0.93的拟合精度,同时兼具高可解释性和因果严谨性,弥合了数据驱动预测与科学机理理解之间的鸿沟。
5.4 结果的物理意义与领域启示
论文的核心结果具有明确的大气物理与化学机理支撑,而非单纯的统计规律:
- 温度的正向因果效应,完全匹配臭氧光化学反应机制——高温加速NO₂光解,提升VOCs反应活性,从而促进臭氧生成;
- 降水、蒸散量、湿度的负向因果效应,源于高水汽环境促进臭氧和前体物的湿沉降,同时改变边界层动态,降低光化学效率;
- 对流层臭氧柱浓度的正向因果效应,反映了稳定气象条件下,背景臭氧的向下混合对近地面浓度的贡献;
- 风速的双向效应,既可以通过平流输送带来臭氧和前体物,也可以通过强扩散稀释臭氧,与区域大气传输过程完全匹配。
5.5 基于机器学习的臭氧建模最佳实践
基于本研究的建模过程和实证结果,论文提出了机器学习臭氧建模的最佳实践规范,为后续研究提供了重要参考:
- 数据预处理与验证:必须保证数据的时空一致性,采用时间感知的划分策略(如季节性、滚动交叉验证),避免数据泄露,同时通过空间交叉验证评估模型的区域泛化能力;
- 特征工程:必须基于NOₓ-VOCs光化学反应机理构建特征,纳入气象、辐射、传输、前体物、地表等关键变量,可进一步纳入滞后预测因子捕捉臭氧的时间持续性;
- 模型评估:不能仅关注R2R^2R2、RMSE等统计精度指标,还需评估模型对季节变化、重污染事件、空间分布的还原能力,保证模型在监管评估和预报场景的可靠性;
- 可解释性与因果验证:必须结合SHAP等可解释性方法和因果推断框架,保证模型学习到的关系是物理意义明确的,而非统计伪相关;
- 可复现性:必须纳入不确定性量化、集成验证,同时透明公开数据来源、预处理流程、随机种子设置,保证研究结果可复现。
六、研究结论与政策启示
6.1 核心研究结论
- 论文构建的「AutoML-SHAP-因果推断」集成框架,能精准模拟中国东部近地面臭氧浓度的时空变化,最优的Extra Trees模型拟合R2R^2R2达0.93,季节性验证R2R^2R2均保持在0.93以上,预测精度和稳定性显著优于传统机器学习模型。
- 气象因子是中国东部近地面臭氧浓度变化的主导驱动因子:SHAP分析和双因果推断模型一致证明,2m地表气温是影响臭氧浓度的最核心因子,呈现显著的正向因果效应,在山东、江苏等高排放省份效应最强;净辐射、相对湿度、降水、云量等气象因子也对臭氧浓度有显著的因果影响。
- 区域背景传输是臭氧污染的重要贡献源:对流层臭氧柱浓度(Tor_O₃)在江苏中部、浙江北部呈现强正向因果效应,证明这些区域的近地面臭氧浓度显著受对流层臭氧向下传输的影响。
- 臭氧驱动因子的因果效应呈现显著的空间异质性:北部平原区域受温度、区域传输的影响更强,南部山地丘陵区域受降水、湿度、辐射的抑制效应更显著,生物源VOCs在山东半岛、苏皖交界区域有显著的正向因果贡献。
- CF和DML双因果模型得到的因果效应方向、空间分布高度一致,证明了研究结论的稳健性,同时也验证了该集成框架在大气污染物驱动因子识别中的有效性。
6.2 政策启示
- 臭氧管控需充分考虑气象因子的影响:未来气候变暖背景下,高温等气象条件会进一步加剧臭氧污染,区域减排策略不能仅聚焦前体物减排,还需针对温度、辐射、边界层动态等气候敏感因子,制定适应性管控政策。
- 实施分区精准管控:针对驱动因子的空间异质性,制定差异化的管控策略——山东、江苏等高排放省份,需重点针对高温天气强化前体物应急减排;江苏中部、浙江北部需重点考虑区域背景传输的影响,强化区域联防联控;南部区域需重点关注高湿气象条件下的臭氧生成潜力变化。
- 重污染应急需关注气象驱动阈值:基于温度、辐射、风速等因子的非线性作用阈值,建立臭氧重污染的气象预警体系,提前启动应急减排措施,抵消气象条件带来的臭氧生成增益。
- 将生物源VOCs纳入管控体系:针对山东半岛、苏皖交界等区域,生物源VOCs对臭氧生成有显著因果贡献,需在臭氧管控中统筹考虑人为源和生物源VOCs的协同减排。
七、论文开源代码与数据复现指南
论文完整开源了所有代码和核心数据集,保证了研究的完全可复现性,具体信息如下:
- 代码仓库:GitHub开源地址 https://github.com/sj2023212923/O₃-Driver-CausalAnalysis
- 核心代码:包含数据预处理、SHAP解释、偏依赖分析、因果森林因果推断的全流程脚本,支持Python和R双环境;
- 环境依赖:
- Python 3.10+:PyCaret、SHAP、scikit-learn、pandas、EconML;
- R 4.2+:ggplot2、mgcv、grf;
- 地理数据处理:ArcGIS Pro 3.x;
- 绘图:Origin 2021;
- 核心数据集:开源在Zenodo平台(https://doi.org/10.5281/zenodo.15780809),包含2022-2023年中国东部近地面臭氧和所有预测变量的匹配数据集;
- 开源协议:MIT协议,可自由使用和修改,需引用原论文。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)