深度学习篇---参数归一化的全面解析
一、参数归一化的核心概念与必要性
1.1 什么是参数归一化?
参数归一化是将不同尺度、不同分布的数据特征转换到统一标准范围内的数学变换过程。在深度学习和机器学习中,这是最基础且最重要的预处理步骤之一,相当于为不同“语言”的数据建立统一的“翻译标准”。
1.2 为什么需要归一化?
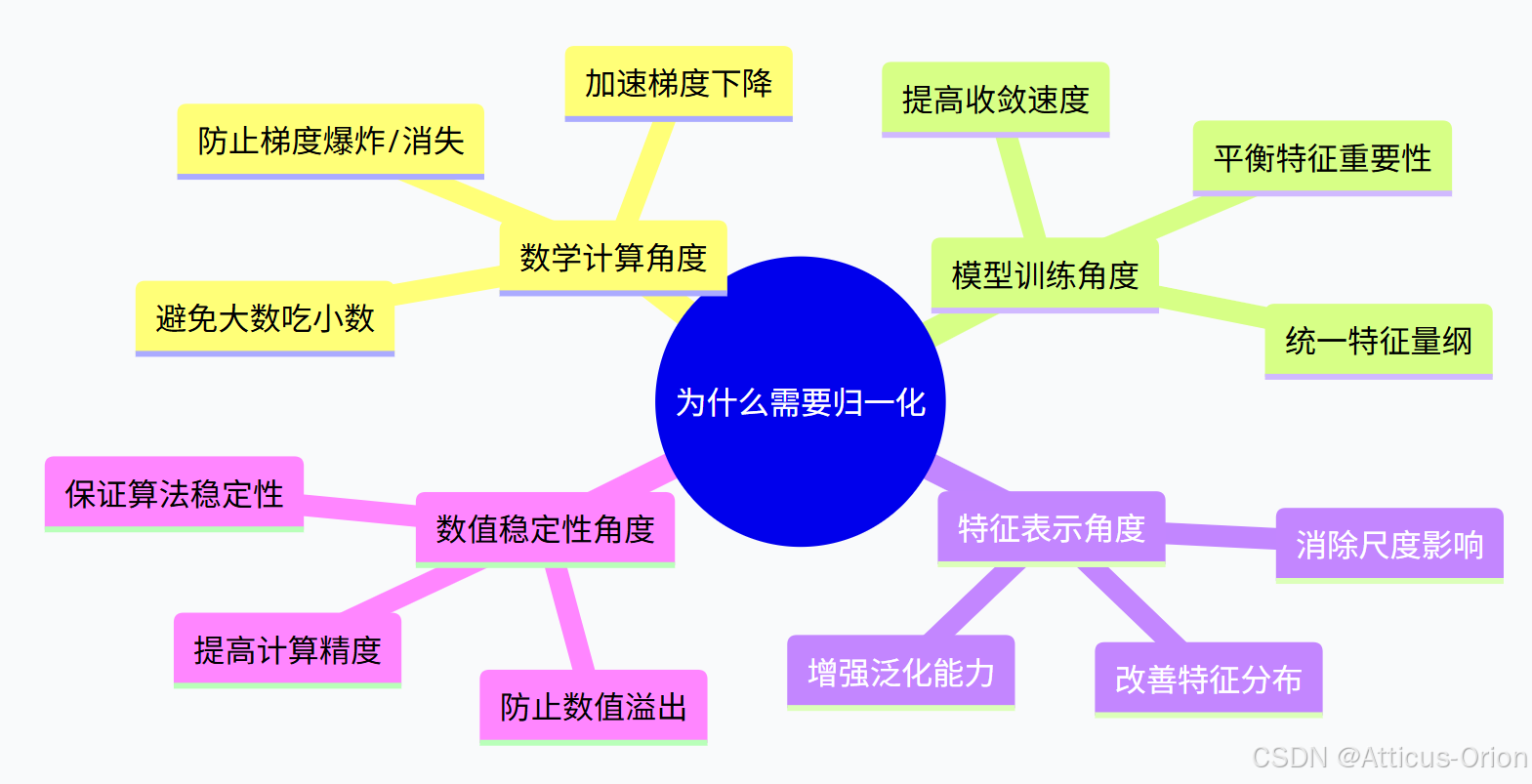
二、归一化的数学原理深度解析
2.1 特征尺度差异的数学影响
当特征尺度差异巨大时,损失函数的等高线会呈现极端的椭圆形。想象一个场景:一个特征取值范围是0-1000,另一个特征取值范围是0-1。在参数空间中,损失函数的形状会被极度拉伸,导致梯度下降优化路径呈现出锯齿状震荡,就像在一个狭长的山谷中来回弹跳,而不是直接走向最低点。
未归一化的问题表现:
-
大尺度特征的梯度巨大,参数更新步长大
-
小尺度特征的梯度微小,参数更新步长小
-
优化路径曲折,收敛极其缓慢
-
需要极小的学习率来防止震荡
归一化后的改善:
-
所有特征的梯度尺度一致
-
各参数更新步长协调
-
优化路径直接指向最优点
-
可以使用更大的学习率加速收敛
2.2 梯度下降的几何解释
在未归一化的特征空间中,损失函数的等高线呈现为偏心率很大的椭圆。梯度方向并不直接指向最优点,而是垂直于等高线的方向,导致优化路径呈现Z字形。归一化后,等高线接近圆形,梯度方向直接指向圆心,优化路径大幅缩短。
三、常见的归一化方法对比
3.1 主要归一化方法分类
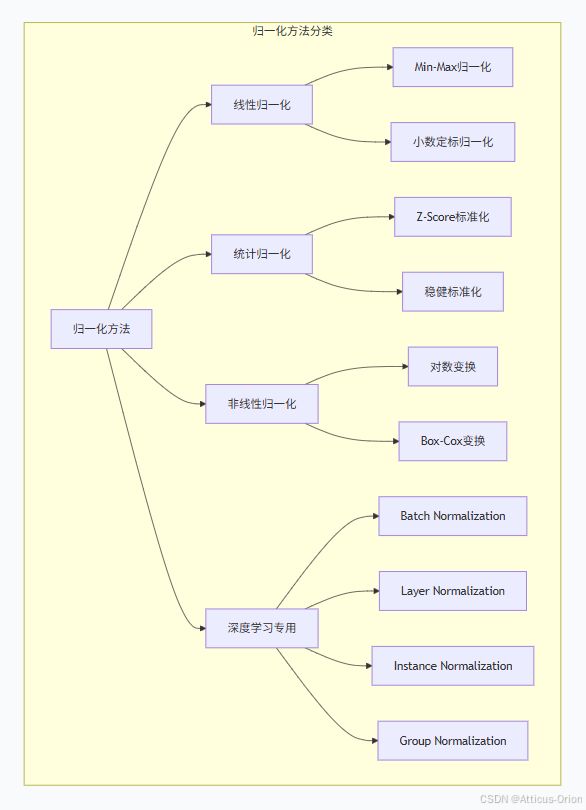
3.2 各归一化方法的特性对比
| 方法名称 | 数学本质 | 输出范围 | 适用场景 | 优缺点 |
|---|---|---|---|---|
| Min-Max归一化 | 线性映射到[0,1]区间 | [0, 1] | 图像处理、神经网络输入层 | 简单直观,但对异常值极度敏感,异常值会压缩正常数据的分布范围 |
| Z-Score标准化 | 转换为标准正态分布 | 理论上无界,实际约[-3,3] | 大多数机器学习算法 | 鲁棒性好,保留原始分布形状,适合数据近似正态分布的场景 |
| 稳健标准化 | 基于中位数和四分位距 | 无界 | 含异常值的数据 | 对异常值几乎不敏感,适合金融数据、传感器数据等含噪声的场景 |
| 对数变换 | 压缩指数级增长的数据 | (-∞, +∞) | 长尾分布数据 | 能将偏态分布转换为接近正态分布,适合处理收入、房价等指数增长数据 |
| Sigmoid归一化 | S型曲线非线性映射 | (0, 1) | 概率输出 | 两端饱和的特性可以抑制极值,但梯度在两端会消失 |
| Tanh归一化 | 双曲正切映射 | (-1, 1) | 需要零中心的数据 | 零中心对称,比Sigmoid梯度更强,适合循环神经网络 |
四、深度学习中的归一化
4.1 Batch Normalization 的革命性影响
Batch Normalization的提出是深度学习领域的一个重要里程碑。它的核心思想是在每一层的激活函数之前,对mini-batch的数据进行归一化,使每一层的输入都保持稳定的分布。
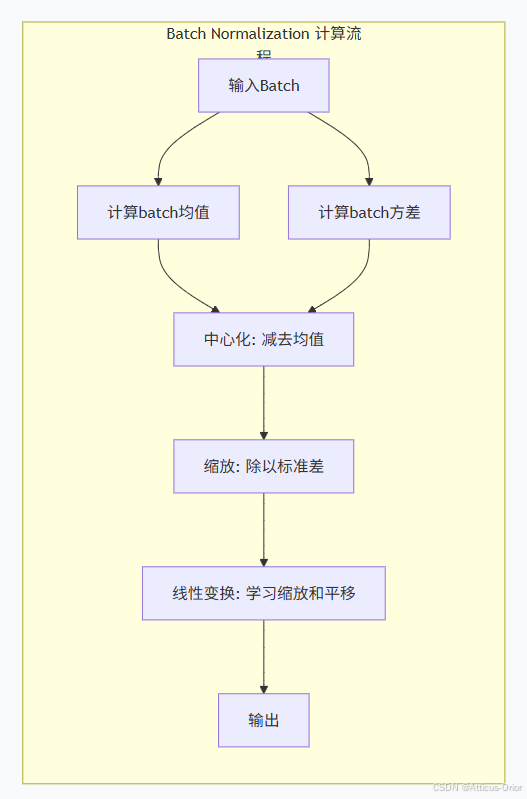
Batch Normalization带来的革命性改变:
-
允许使用更高的学习率,加速训练数倍
-
减轻了对参数初始化的依赖
-
起到了正则化的作用,减少了Dropout的需求
-
解决了内部协变量偏移问题
4.2 各种Normalization的对比
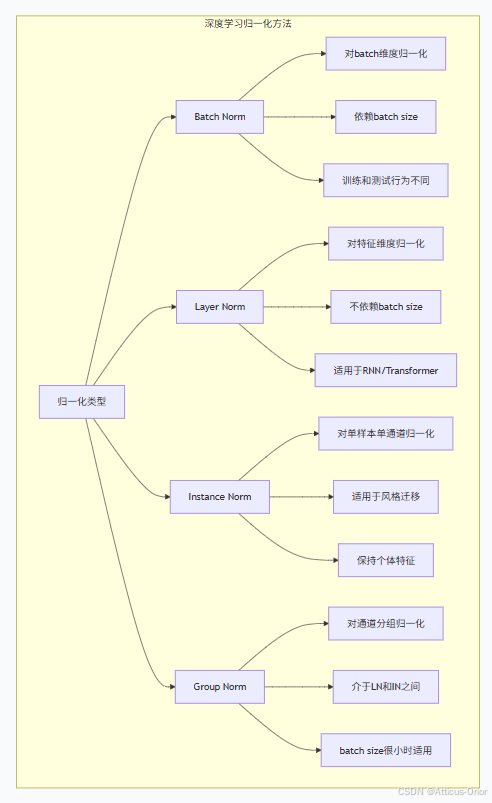
4.3 不同归一化方法的适用场景
| 方法 | 归一化维度 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|---|
| Batch Norm | 跨样本的同一通道 | CNN图像分类、目标检测 | 训练稳定,收敛快 | 依赖batch size,小batch效果差 |
| Layer Norm | 单样本的所有特征 | RNN、Transformer、BERT | 不依赖batch,适合序列 | 计算量较大 |
| Instance Norm | 单样本单通道 | 风格迁移、图像生成 | 保持个体风格特征 | 可能丢失全局信息 |
| Group Norm | 通道分组 | 小batch目标检测、视频分析 | batch很小时表现好 | 需要选择合适的分组数 |
五、归一化在目标检测中的重要性
5.1 目标检测中的多尺度问题
在目标检测任务中,各种特征的尺度差异更加显著:
尺度差异的具体表现:
-
边界框坐标:0-1920像素的大范围数值
-
置信度分数:0-1的小范围概率值
-
宽高比:可能从0.1到10跨越两个数量级
-
距离估计:从几米到上百米的巨大跨度
如果没有归一化,边界框坐标的损失会完全主导训练过程,导致模型只关注框的位置而忽视分类准确性。这就好比让一个人同时关注显微镜下的细节和望远镜里的全景,没有合适的“调焦”机制,必然顾此失彼。
5.2 多任务学习的归一化挑战
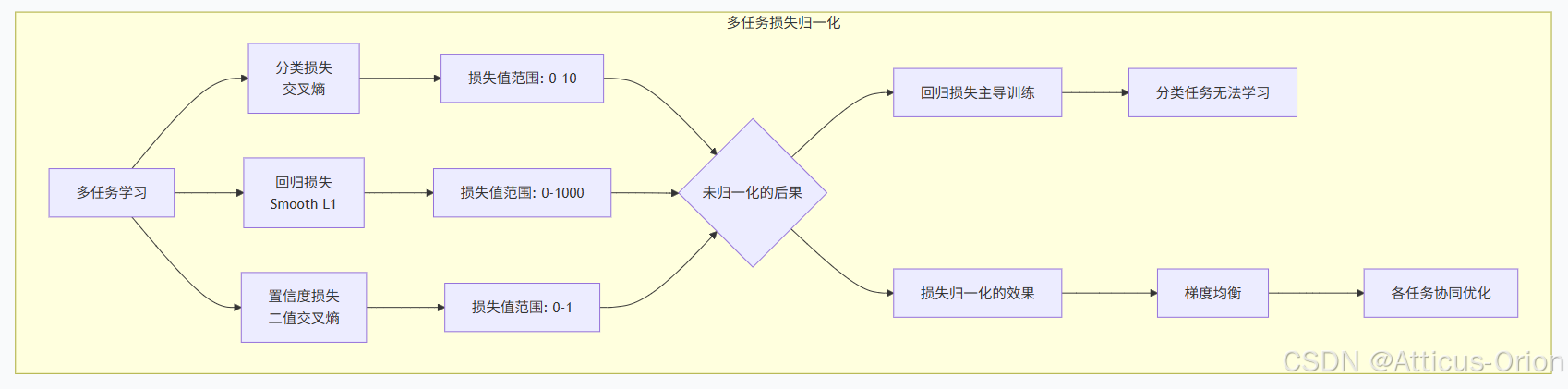
5.3 目标检测中的归一化实践要点
关键参数的归一化策略:
-
边界框坐标:除以图像尺寸,映射到[0,1]区间,使不同分辨率的图像特征统一
-
锚点框尺寸:相对于特征图步长进行归一化,保持尺度不变性
-
多任务损失:采用不确定性加权或梯度均衡,使各任务贡献平衡
-
特征金字塔:在不同层级的特征图上应用独立的归一化参数
六、归一化对模型性能的影响
6.1 收敛速度的显著提升
归一化能够将训练收敛速度提升3-5倍的根本原因在于它改变了损失景观的几何特性。在归一化的特征空间中,损失函数的等势面更加接近球形,梯度方向直接指向最优点,避免了在狭长山谷中的震荡。
收敛速度对比:
-
未归一化:需要50-100轮才能达到可接受的损失值
-
归一化后:10-20轮就能达到相同甚至更好的效果
6.2 数值稳定性的保障
未归一化的计算过程如同用天文数字做加减法,极易出现数值问题:
数值不稳定的表现:
-
梯度爆炸:参数更新步长过大,损失变为NaN
-
梯度消失:参数几乎不更新,模型无法学习
-
精度损失:大数吃小数,有效信息丢失
归一化将数据压缩到合理范围,确保所有计算都在浮点数的精度范围内进行,从根本上避免了数值问题。
6.3 泛化能力的提升
归一化通过减少内部协变量偏移,使每一层的输入分布更加稳定,这相当于为网络提供了隐式的正则化。模型不再需要适应训练数据的特定分布,而是学习到更加本质的特征表示,从而在测试集上表现更好。
七、归一化的最佳实践与常见问题
7.1 归一化选择指南
7.2 常见问题与解决方案
| 问题 | 现象 | 根本原因 | 解决方案 |
|---|---|---|---|
| 训练不稳定 | Loss剧烈震荡或发散 | 特征尺度差异过大 | 使用Z-Score标准化,配合梯度裁剪 |
| 收敛极其缓慢 | Loss下降非常慢 | 梯度各向异性严重 | 应用Batch Norm,适当提高学习率 |
| 过拟合 | 训练集效果好,测试集差 | 归一化参数过拟合训练集 | 增加数据增强,使用Dropout |
| Batch Size敏感 | 小batch时效果骤降 | BN统计量估计不准 | 改用Group/Layer Norm |
| 训练推理不一致 | 训练和推理性能差异大 | BN统计量更新问题 | 使用全局统计量,冻结BN层 |
| 数值溢出 | Loss突然变为NaN | 特征值过大或过小 | 先做异常值处理,再归一化 |
7.3 关键实践经验
数据预处理阶段:
-
始终在训练集上计算归一化参数,然后应用到验证集和测试集
-
保存归一化参数,确保推理时使用相同的变换
-
处理异常值:可以先进行截断或使用稳健标准化
模型设计阶段:
-
CNN网络优先考虑Batch Norm
-
RNN/Transformer使用Layer Norm
-
小batch场景使用Group Norm
-
风格迁移任务使用Instance Norm
训练阶段:
-
归一化后可以使用更高的学习率
-
监控激活值的分布,确保归一化有效
-
可以逐步减少正则化强度
八、归一化在行车记录仪项目中的具体应用
8.1 需要归一化的关键参数
空间参数:
-
边界框坐标:范围0-1920像素,需归一化到[0,1]
-
距离估计:范围0-100米,需对数变换压缩尺度
-
相对位置:需考虑图像坐标系到世界坐标系的映射
运动参数:
-
速度:单位像素/帧,需归一化到[-1,1]
-
加速度:单位m/s²,需使用tanh映射
-
角速度:需考虑方向性,使用正弦/余弦编码
风险参数:
-
个体风险值:范围0-100%,线性映射到[0,1]
-
碰撞时间TTC:范围0-30秒,使用指数衰减映射
-
质量系数:范围1.0-2.0,线性映射到[0,1]
8.2 风险分数的非线性归一化策略
风险感知需要特殊的非线性映射,以突出高风险区域:
线性映射:直接映射0-100%到0-1,简单但无法突出风险变化
Sigmoid映射:在50%附近斜率最大,使中风险区域的变化更敏感,适合预警场景
分段映射:
-
低风险区(0-30%):压缩映射,减少对安全场景的过度反应
-
中风险区(30-60%):线性映射,保持正常预警灵敏度
-
高风险区(60-100%):放大映射,使危险情况更加突出
8.3 多任务损失的均衡策略
行车记录仪项目涉及多个任务:目标检测、距离估计、风险预测等。这些任务的损失尺度差异巨大,需要精心的均衡策略:
损失均衡方法:
-
不确定性加权:根据任务噪声自动调整权重
-
梯度归一化:确保各任务梯度尺度相近
-
动态权重调整:根据训练进度调整任务重要性
九、归一化的哲学思考
9.1 归一化与信息论
从信息论的角度看,归一化是一种最优编码策略。它将不同来源的信息转换到相同的动态范围,使得每个特征维度都能充分利用有限的数值精度,最大化信息传输效率。这相当于为每个特征分配了等量的"比特预算",避免了某些特征占据过多精度资源。
9.2 归一化与生物视觉
有趣的是,归一化与生物视觉系统有着惊人的相似性。人眼的视网膜细胞会对光线强度进行对数变换,使我们能够在从星光到阳光的广阔亮度范围内保持视觉敏感度。这正是归一化的生物学原型——在不同尺度下保持信息感知的均衡。
9.3 归一化的普遍性
从更广阔的视角看,归一化是一种普遍存在于自然界和人类社会的现象:
-
经济学中的价格指数化
-
心理学中的感觉适应
-
社会学中的标准化度量衡
这些都体现了归一化的核心思想:建立统一的参考系,使不同尺度的现象可以公平比较和有效处理。
十、总结框图
十一、最终结论
参数归一化不是可有可无的技术选项,而是深度学习项目的必备基础。它通过数学变换消除特征的尺度差异,使模型能够公平地学习所有特征的重要性。
归一化的核心价值可以概括为:
-
数学上:解决了不同量纲特征的线性组合问题
-
算法上:加速收敛,提高稳定性
-
工程上:保障数值计算的安全可靠
-
应用上:增强模型的泛化能力和鲁棒性
对于行车记录仪这样的实时安全系统,正确的归一化不仅关系到模型的性能,更直接影响到系统的可靠性和安全性。在高速行驶的场景中,每一毫秒的延迟都可能带来安全隐患,每一次误判都可能造成严重后果。因此,归一化不是锦上添花,而是保障系统正常运行的基础设施。
正如建筑师不会忽视地基的重要性,深度学习工程师也不应低估归一化的价值。它是构建可靠、高效、精准AI系统的奠基石。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献85条内容
已为社区贡献85条内容

所有评论(0)