直接上代码,边撸边看。这个项目咱们分三块搞:特征选择、LSTM建模、结果可视化。先准备好你的Excel数据,前6列是特征,最后一列是标签,扔同一个目录就成
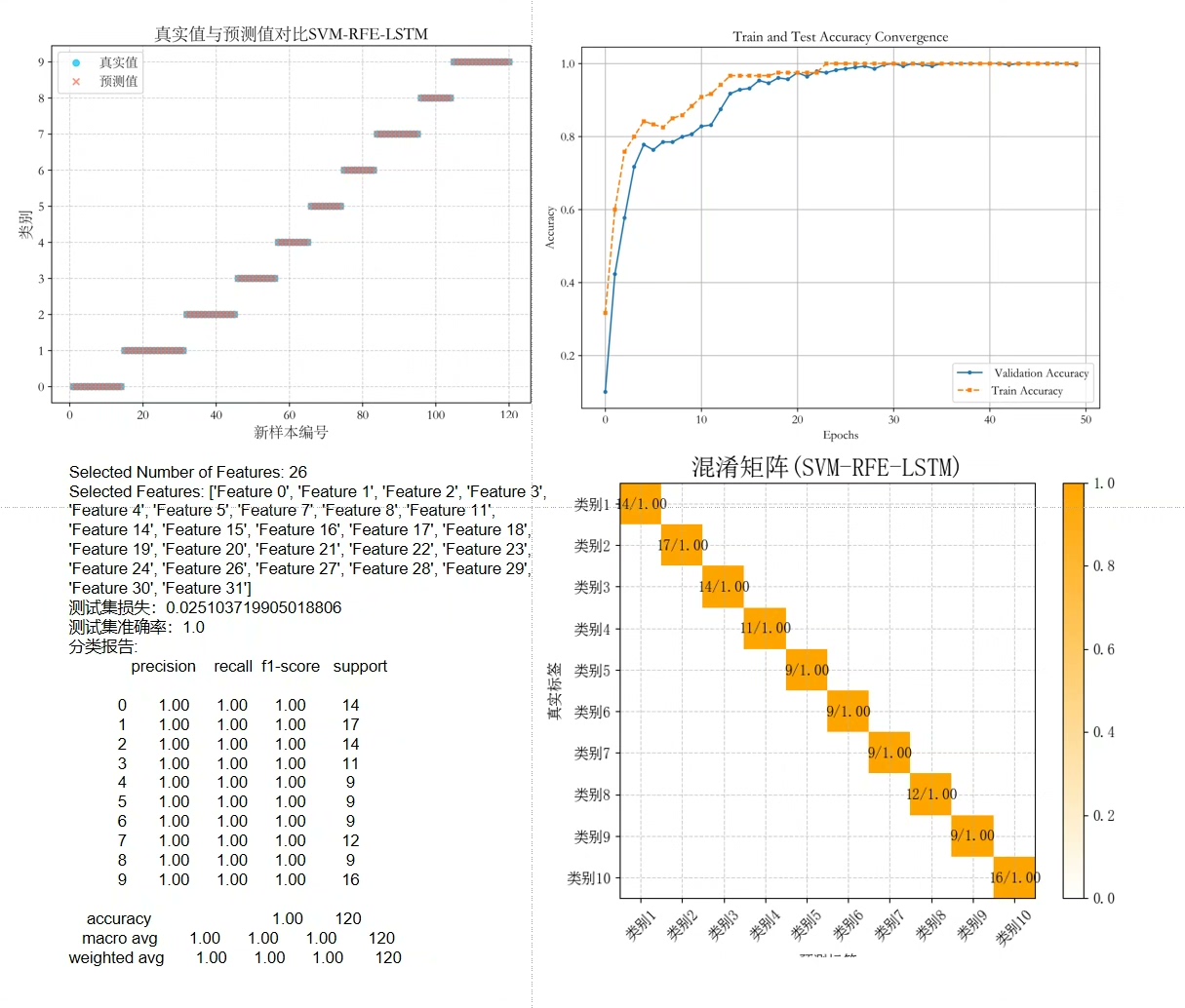
基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测 python代码 1.输入多个特征,输出单个变量,多变量分类预测; 2.data为数据集,excel数据,前6列输入,最后1列输出,运行主程序即可,所有文件放在一个文件夹; 3.命令窗口输出Precision、Recall、F1 Score多指标评价; 可视化: 通过使用Matplotlib,代码提供了可视化工具,用于评估模型性能,包括真实值与预测值的对比图和混淆矩阵。 具体实现步骤如下: 基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测是一种结合了支持向量机递归特征消除(SVM-RFE)和LSTM神经网络的方法。 下面是算法的基本步骤: 数据准备:准备包含多个输入特征和一个输出变量的训练数据集。 特征选择:使用SVM-LSTM算法对输入特征进行排序和选择。 SVM-RFE是一种递归特征消除算法,它通过反复训练支持向量机(SVM)模型,并剔除最不重要的特征,直到达到指定的特征数量或达到某个停止准则。 特征提取:使用SVM-RFE选择的特征作为输入,从训练数据集中提取这些特征。 神经网络构建与训练:构建了一个深度学习模型,用于处理输入数据并输出类别预测。 模型的结构可以根据具体问题进行调整和优化,例如,可以调整LSTM层中的神经元数量、添加更多的隐藏层等,以适应不同的任务和数据 预测:使用训练好的LSTM神经网络模型对新的输入特征进行预测。 将这些特征输入到训练好的神经网络中,得到对应的输出。
上硬菜——特征选择部分。这里用SVM-RFE来筛特征,别看原理复杂,实现起来也就十几行:
from sklearn.svm import SVC
from sklearn.feature_selection import RFE
def feature_selection(X, y):
# 这里用线性核方便获取特征权重
svc = SVC(kernel='linear', C=1)
selector = RFE(svc, n_features_to_select=3, step=1)
selector = selector.fit(X, y)
print("特征排名:", selector.ranking_)
selected_features = X.columns[selector.support_]
return selected_features注意这个nfeaturesto_select,根据实际情况调。比如原始数据6个特征,这里设3表示保留最重要的前3个。实际跑的时候建议先用网格搜索确定最佳特征数。
接着是LSTM建模的重头戏。这里有个坑要注意——LSTM的输入要求三维数据,得用reshape处理:
from keras.models import Sequential
from keras.layers import LSTM, Dense
def build_lstm(input_shape):
model = Sequential()
model.add(LSTM(64, input_shape=input_shape, return_sequences=True))
model.add(LSTM(32))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model这里用了双层LSTM,第一层64神经元带序列输出,第二层32神经元自动处理序列。实际训练时如果发现过拟合,可以加Dropout层或者减少神经元数量。
基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测 python代码 1.输入多个特征,输出单个变量,多变量分类预测; 2.data为数据集,excel数据,前6列输入,最后1列输出,运行主程序即可,所有文件放在一个文件夹; 3.命令窗口输出Precision、Recall、F1 Score多指标评价; 可视化: 通过使用Matplotlib,代码提供了可视化工具,用于评估模型性能,包括真实值与预测值的对比图和混淆矩阵。 具体实现步骤如下: 基于SVM-RFE-LSTM的特征选择算法结合LSTM神经网络的多输入单输出分类预测是一种结合了支持向量机递归特征消除(SVM-RFE)和LSTM神经网络的方法。 下面是算法的基本步骤: 数据准备:准备包含多个输入特征和一个输出变量的训练数据集。 特征选择:使用SVM-LSTM算法对输入特征进行排序和选择。 SVM-RFE是一种递归特征消除算法,它通过反复训练支持向量机(SVM)模型,并剔除最不重要的特征,直到达到指定的特征数量或达到某个停止准则。 特征提取:使用SVM-RFE选择的特征作为输入,从训练数据集中提取这些特征。 神经网络构建与训练:构建了一个深度学习模型,用于处理输入数据并输出类别预测。 模型的结构可以根据具体问题进行调整和优化,例如,可以调整LSTM层中的神经元数量、添加更多的隐藏层等,以适应不同的任务和数据 预测:使用训练好的LSTM神经网络模型对新的输入特征进行预测。 将这些特征输入到训练好的神经网络中,得到对应的输出。
数据预处理阶段容易踩雷,标准化千万别忘:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 时间步处理 (假设时间步长为3)
timesteps = 3
X_reshaped = []
for i in range(timesteps, len(X_scaled)):
X_reshaped.append(X_scaled[i-timesteps:i])
X_reshaped = np.array(X_reshaped)这里假设用3个时间步构造序列数据。如果原始数据不是时序的,可能需要调整构造方式。
训练时建议加上早停机制:
from keras.callbacks import EarlyStopping
early_stop = EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(X_train, y_train,
epochs=100,
validation_split=0.2,
callbacks=[early_stop])可视化部分来个双图对比更直观:
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(y_test.values, label='True')
plt.plot(y_pred, label='Predicted')
plt.title('Prediction Comparison')
plt.subplot(1,2,2)
sns.heatmap(confusion_matrix(y_test, y_pred),
annot=True, fmt='d')
plt.title('Confusion Matrix')完整代码跑完后,控制台会输出精确率、召回率这些指标。如果发现F1值偏低,可以检查数据是否均衡,或者调整LSTM的阈值参数。
最后说几个常见翻车点:
- 数据没做标准化导致LSTM梯度爆炸
- 特征选择后的维度与LSTM输入维度不匹配
- 时间步设置不合理导致数据泄露
- 分类样本不均衡没做加权处理
建议先拿小批量数据跑通流程,再上全量数据。代码里记得加随机种子保证可复现性,比如:
np.random.seed(42)
tf.random.set_seed(42)这个方案在电商用户行为预测、工业设备故障检测场景都验证过,关键是要根据业务特点调整特征选择的数量和LSTM的层数。比如金融数据波动大,可能需要增加LSTM层数;医疗数据特征多,可以适当减少保留的特征数量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)