生产级 RAG 落地全指南:12 个核心组件,拆解从文档到精准回答的系统工程
2026 年,检索增强生成(RAG)已经成为解决大模型幻觉、落地企业私有知识库、打造行业专属 AI 应用的标配方案。但行业的残酷现实是:超过 80% 的 RAG 项目,都卡在了从 Demo 到生产环境的最后一公里 ——Demo 里能完美回答预设问题,一到真实业务场景就频繁幻觉、答非所问、漏关键信息,最终沦为无法落地的 “玩具项目”。
绝大多数项目失败的核心原因,是对 RAG 的认知出现了根本性偏差。太多人把 RAG 简化成了一条极简的线性流程:文档→嵌入生成→向量数据库→检索→LLM 生成,以为只要把文档丢进向量库,接上大模型,就能得到一个精准、可靠的知识库问答系统。
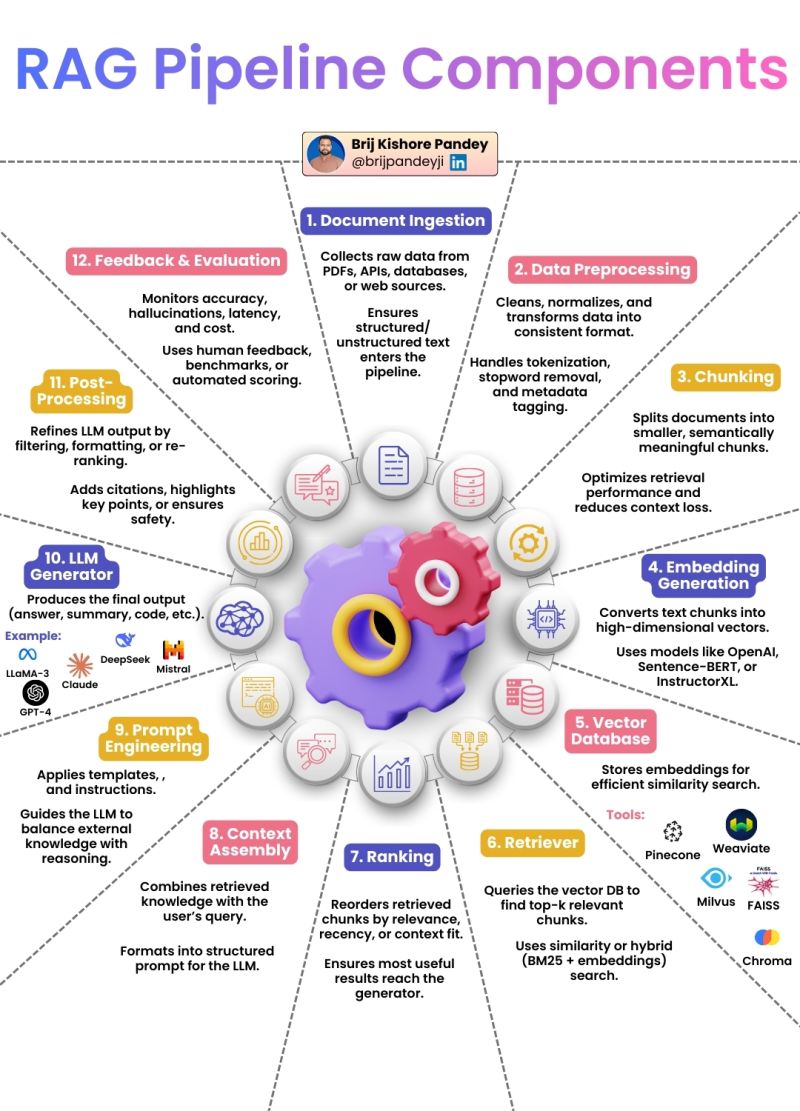
但这是对生产级 RAG 的极度简化。真实的 RAG,是一套由多个精密组件协同工作的工程化系统,从原始数据摄入到最终回答交付,再到持续的优化迭代,一共包含 12 个核心环节。每一个环节,都能成为提升最终效果的关键,也都能成为让整个系统失效的短板。
团队最容易犯的致命错误,就是把几乎所有精力都放在 “选最好的大模型” 上,却完全忽略了整个流水线的工程化打磨。现实是:你可以接入全球最顶级的 GPT-4o、Claude 3.5 Sonnet,但如果检索环节拉胯,找不到相关的上下文,再好的模型也只能编造内容;你可以做到精准的检索召回,但如果上下文组装混乱、噪声过多,模型依然会输出偏离需求的回答;你可以生成逻辑通顺的答案,但如果跳过了引用标注、安全校验、效果评估,最终依然会失去用户的信任。
生产级 RAG 从来都不是一个单纯的 AI 算法问题,而是一个完整的系统设计问题。今天,我们就完整拆解 RAG 流水线的 12 个核心组件,搞懂每个环节的作用、常见的坑,以及能让系统效果翻倍的最佳实践。
1. Document Ingestion(文档摄入):RAG 系统的源头,决定了效果的天花板
文档摄入是整个 RAG 流水线的起点,也是最容易被轻视的环节。它的核心职责,是从 PDF、API 接口、业务数据库、网页、本地文件等各类数据源,完整、准确地采集原始数据,确保结构化、非结构化文本都能无损地进入后续流水线。
很多人以为 “摄入就是把文件读进来”,但实际上,80% 的 RAG 效果问题,在源头就已经埋下了隐患。这个环节最常见的坑包括:
- 多格式解析错误:PDF 的表格、图片内文字、扫描件 OCR 识别失败,Word 的层级结构丢失,网页的广告、页眉页脚等噪声内容被一并采集;
- 多源数据格式混乱:来自不同系统的文档,编码、格式、换行规则不统一,给后续预处理带来巨大麻烦;
- 增量同步机制缺失:无法实时同步数据源的更新,导致 RAG 系统里的内容长期过时,回答完全不符合业务现状;
- 元数据丢失:没有留存文档的来源、更新时间、作者、权限等级、业务分类等关键元数据,后续无法做精准的过滤与加权检索。
这个环节的最佳实践非常明确:
- 采用适配多格式的专业解析工具,比如 Unstructured、LangChain 全品类文档加载器、PyMuPDF,针对扫描件、带复杂格式的文档,搭配 OCR 工具与结构化解析能力,确保文本内容的完整提取;
- 建立全链路的元数据留存机制,给每一份文档、每一页内容都打上完整的元数据标签,这些标签会成为后续检索环节的精准过滤工具;
- 设计增量同步与软删除机制,实时监听数据源的更新、删除操作,保证 RAG 系统里的内容和源数据始终一致,从根源上避免过时、错误的内容进入系统。
2. Data Preprocessing(数据预处理):清洗噪声,为后续环节筑牢基础
如果说文档摄入是保证 “数据完整”,那么数据预处理就是保证 “数据干净”。它的核心职责,是对采集到的原始文本做清洗、标准化、格式统一,同时完成分词、停用词移除、元数据标记等基础处理,把杂乱的原始数据转换成规范、一致的文本格式。
这个环节的核心价值,是过滤掉所有会干扰后续分块、嵌入、检索的噪声内容。常见的坑包括:
- 噪声内容未清理:乱码、特殊符号、无意义的换行与空格、网页的广告与导航内容、文档的页眉页脚等冗余信息被保留,污染后续的分块与嵌入;
- 文本格式不统一:大小写、日期格式、单位、专业术语缩写不统一,导致后续的语义匹配出现偏差;
- 停用词与无意义内容未过滤:大量语气词、连接词、无意义的短句被保留,占用嵌入空间,干扰语义匹配的准确性。
这个环节的最佳实践,是建立一套标准化的预处理流水线:
- 先做全量的噪声过滤,清理乱码、特殊符号、冗余的格式内容,还原干净的文本主体;
- 做文本标准化处理,统一大小写、日期、单位、专业术语的格式,保证同一概念的表述完全一致;
- 完成分词、停用词移除,同时给文本打上对应的元数据标签,和文档级元数据形成联动;
- 针对不同业务场景的文档,定制专属的预处理规则,比如法律文档要保留法条编号,技术文档要保留版本号与层级结构,不能用一套规则处理所有类型的文档。
3. Chunking(分块):最被低估的核心环节,RAG 效果的第一道生死线
分块,是整个 RAG 流水线中,对效果影响最大、却最容易被敷衍处理的环节。它的核心职责,是把预处理后的长文档,拆分成更小的、语义完整的文本块,在优化检索性能的同时,最大限度减少上下文语义的丢失。
绝大多数 RAG 项目的效果翻车,根源都在分块环节。最常见的错误,就是用固定长度的一刀切分块:不管文档的语义结构,直接按固定字符数拆分,经常把一个完整的句子、一个连贯的知识点、一个完整的表格,拆到两个不同的块里。最终的结果是,检索到的文本块语义不完整,哪怕块和问题的相似度再高,大模型也无法从中得到完整的信息,只能编造内容。
除此之外,分块的常见坑还有:
- 块尺寸设置不合理:块太大,单个块里包含太多无关内容,检索时引入大量噪声,浪费上下文窗口;块太小,语义被拆得支离破碎,丢失了关键的上下文关联;
- 没有处理语义边界:完全忽略文档的标题层级、段落结构、语义转折,拆分后的块完全不符合人类的阅读与理解逻辑;
- 没有上下文重叠机制:相邻块之间没有保留重叠内容,导致跨块的完整语义被彻底切断。
这个环节的最佳实践,已经被无数生产级项目验证有效:
- 放弃固定长度分块,采用语义分块:基于句子、段落、标题层级、语义相似度做拆分,确保每一个块都包含一个完整的语义单元,比如 LangChain 的 SemanticChunker、LlamaIndex 的 HierarchicalNodeParser,都是成熟的语义分块工具;
- 采用分层分块(父 - 子块)架构:把文档拆分成大的父块和小的子块,检索时用子块做精准的语义匹配,召回后把对应的完整父块送入大模型,既保证了检索的精准度,又避免了上下文丢失;
- 适配文档类型调整块尺寸:FAQ、短问答类文档,块尺寸可以设置在 128-256 个 token;技术文档、法律条文等长文本,块尺寸可以设置在 512-1024 个 token;
- 加入相邻块重叠机制:相邻的块之间保留 10%-20% 的文本重叠,避免跨块的完整语义被切断,最大限度保留上下文的连贯性。
4. Embedding Generation(嵌入生成):语义匹配的核心,把文本转换成机器可理解的语言
嵌入生成,是连接文本与向量检索的核心桥梁。它的核心职责,是通过嵌入模型,把拆分好的文本块,转换成高维的向量嵌入,让机器可以计算文本之间的语义相似度。
这个环节的核心逻辑是:语义越相近的文本,转换后的向量在高维空间中的距离就越近。嵌入模型的选择与使用方式,直接决定了后续检索的匹配精度。常见的坑包括:
- 场景与模型不匹配:用通用的嵌入模型处理专业领域的文档,比如用通用模型处理医疗、法律、工业技术文档,导致专业术语、行业知识的语义匹配效果极差;
- 嵌入模型不一致:生成嵌入用的模型,和检索时用的模型不是同一个,导致向量空间不统一,相似度计算完全失真;
- 忽略嵌入的标准化处理:没有对生成的向量做归一化,导致相似度计算的结果出现偏差;
- 重复计算与资源浪费:没有缓存已经生成的嵌入,文档更新时重复全量生成,浪费算力与时间成本。
这个环节的最佳实践,核心是 “匹配场景、保证一致、优化效率”:
- 优先选择适配业务场景的嵌入模型:通用场景可以选择 OpenAI text-embedding-3-large、BGE-M3、M3E 这类通用强模型;专业领域优先选择经过行业数据微调的领域嵌入模型,大幅提升专业内容的匹配精度;
- 严格保证嵌入模型的一致性:生成、检索、重排序全流程,必须使用同一个嵌入模型,确保向量空间的统一;
- 对生成的向量做归一化处理,保证内积相似度计算的准确性;
- 建立嵌入缓存与增量生成机制,只对新增、更新的文本块生成嵌入,避免重复计算,降低成本与延迟。
5. Vector Database(向量数据库):RAG 的外置记忆体,高效检索的核心载体
向量数据库,是 RAG 系统的 “外置记忆体”,也是整个流水线的核心存储组件。它的核心职责,是存储生成好的向量嵌入,同时提供高效的相似度检索能力,让系统可以在毫秒级,从百万、千万级的向量中,找到和用户查询最相关的文本块。
当前主流的向量数据库包括企业级的 Pinecone、Weaviate、Milvus,轻量开源的 Chroma、FAISS,不同的产品适配不同的业务规模。这个环节的常见坑包括:
- 索引配置不合理:没有针对数据规模与查询场景优化索引,要么检索速度极慢,要么匹配精度大幅下降;
- 忽略元数据过滤能力:没有把元数据和向量绑定存储,无法在检索时做前置过滤,导致大量无关、过时、无权限的内容被召回;
- 生产级能力缺失:没有做数据分片、副本、备份,并发量上来就崩溃,数据丢失无法恢复;
- 增量更新与过期数据处理不当:无法高效更新向量,过期的内容没有被清理,持续污染检索结果。
这个环节的最佳实践,核心是 “适配场景、优化性能、保障稳定”:
- 根据业务规模选择合适的向量数据库:个人 Demo、轻量场景用 Chroma、FAISS 即可;企业级生产环境,优先选择支持分布式部署、高可用、元数据过滤能力强的 Pinecone、Milvus、Weaviate;
- 优化索引配置:针对百万级以上的向量数据,采用 HNSW 这类高性能的近似最近邻索引,平衡检索速度与匹配精度,同时根据数据规模调整索引参数;
- 开启元数据过滤能力:把文档的元数据和向量绑定存储,检索时可以按业务分类、更新时间、权限等级、文档类型做前置过滤,从根源上减少无关内容的召回;
- 建立完善的运维机制:做好数据的分片、副本、备份,保证生产环境的高可用;设计增量更新与软删除机制,高效处理数据的新增、修改、删除,保证向量库的内容始终和源数据一致。
6. Retriever(检索器):RAG 的 “眼睛”,决定了能不能找到最相关的知识
检索器,是 RAG 系统的 “眼睛”,也是整个流水线的核心环节。它的核心职责,是把用户的查询转换成向量,向向量数据库发起查询,找到和用户问题最相关的 Top-K 个文本块,为后续的回答生成提供核心上下文。
很多人以为检索就是 “查向量库”,但实际上,检索环节的设计,直接决定了 RAG 系统的召回率 —— 也就是能不能把所有和问题相关的内容都找出来。如果召回环节漏了关键信息,哪怕后面的环节做得再好,大模型也不可能给出正确的回答。这个环节的常见坑包括:
- 只用纯向量相似度检索:完全依赖向量的语义匹配,忽略了关键词匹配,导致专有名词、缩写、数字、特定术语的匹配效果极差,很多精准相关的内容被漏掉;
- Top-K 设置不合理:Top-K 太小,漏了大量相关内容,召回率不足;Top-K 太大,引入了太多无关的噪声内容,浪费大模型的上下文窗口,还会导致回答偏离主题;
- 没有做前置权限过滤:把用户没有权限查看的内部文档也检索出来,导致敏感信息泄露;
- 检索方式过于单一:只用用户的原始问题做单次检索,无法覆盖复杂问题的多个维度,导致关键信息遗漏。
这个环节的最佳实践,是用多元化的检索策略,最大化召回率,同时最小化噪声:
- 采用混合检索(Hybrid Search):结合向量的语义匹配和 BM25 的关键词匹配,兼顾语义理解和精确匹配,大幅提升专业术语、特定概念的召回率,当前主流的向量数据库都已经原生支持混合检索;
- 采用多查询检索(Multi-Query):用大模型把用户的原始问题,拆分成多个不同维度、不同表述的子问题,分别发起检索,覆盖问题的所有相关维度,避免单一查询的语义偏差导致的信息遗漏;
- 动态调整 Top-K:根据问题的复杂度、长度,动态调整召回的块数量,简单问题用小的 Top-K,复杂的多步推理问题用大的 Top-K;
- 加入前置过滤与权限管控:检索前先根据用户的权限、问题的业务场景,用元数据做前置过滤,只在用户有权限、业务相关的内容里做检索,既提升了检索效率,又避免了敏感信息泄露;
- 采用父文档检索:先检索精准匹配的子块,再召回子块对应的完整父文档,解决分块带来的上下文丢失问题,给大模型提供更完整的语义背景。
7. Ranking(重排序):用极小成本实现效果翻倍,最容易被忽略的优化环节
重排序,是检索环节的最后一道筛选,也是用极低的成本,就能让 RAG 效果翻倍的关键环节,却被绝大多数项目完全忽略。它的核心职责,是对检索器召回的 Top-K 个文本块,做更精细的相关性排序,同时过滤掉低相关的内容,确保只有最有用、最相关的内容,能被送到大模型的上下文窗口里。
很多人会问:向量库已经做了相似度排序,为什么还要额外做重排序?核心原因是,向量库的相似度检索是为了快速处理百万级数据做的近似匹配,精度有限,只能做粗筛;而专门的重排序模型,可以对用户问题和每一个文本块做精细的交叉注意力计算,得到更精准的相关性评分,把粗筛结果里的 “漏网之鱼” 找出来,把低相关的内容过滤掉。
这个环节的常见坑,就是完全不做重排序,只靠向量库的相似度排序,导致很多高相关但相似度分数略低的内容,被排在 Top-K 之外,根本无法进入大模型的上下文;或者用和业务场景不匹配的重排序模型,排序效果甚至不如原始的相似度排序。
这个环节的最佳实践非常简单,却效果显著:
- 采用专门的交叉编码器重排序模型,比如 BGE-Reranker、ColBERT,对检索器召回的 Top-K 个块(比如 Top20-30)做精细的相关性重排序;
- 重排序后,只保留最相关的 Top-N 个块(比如 Top5-10),既保证了召回率,又最大限度减少了上下文的噪声;
- 加入自定义的加权规则,比如最新发布的内容权重更高、官方文档权重高于社区内容、高优先级的业务文档权重更高,让排序结果更贴合业务需求;
- 针对业务场景微调重排序模型,用业务里的真实问答对做微调,让重排序的精度进一步提升。
8. Context Assembly(上下文组装):决定大模型能不能用好检索到的知识
上下文组装,是连接检索环节和大模型生成环节的桥梁。它的核心职责,是把重排序后的高相关文本块,和用户的查询结合起来,格式化成结构清晰、逻辑连贯的提示词上下文,让大模型可以清晰、准确地理解检索到的知识,同时避免无关内容的干扰。
这个环节的常见坑,是把检索到的文本块随便堆在一起,完全不做结构化处理,导致大模型找不到重点,甚至误解上下文的内容。具体包括:
- 上下文无结构化:所有文本块堆在一起,没有分隔、没有标注,大模型无法区分不同的知识点,也无法对应内容的来源;
- 冗余内容过多:没有去重处理,多个块里的重复内容被反复放入上下文,浪费窗口空间,还会干扰大模型的判断;
- 来源信息缺失:没有标注每个文本块的来源、更新时间,大模型无法做引用标注,用户也无法验证内容的真实性;
- 上下文长度失控:放入的内容超过了大模型的上下文窗口限制,导致内容被截断,关键信息丢失。
这个环节的最佳实践,核心是 “结构化、去冗余、控长度、标来源”:
- 结构化组装上下文:给每个文本块标清楚序号、文档标题、来源链接、更新时间,用清晰的分隔符分开,让大模型可以清晰地识别每个独立的知识点;
- 按相关性排序:把重排序后最相关的内容放在上下文的最前面,大模型对前置内容的关注度更高,能最大限度保证核心信息不被忽略;
- 去重与精简:过滤掉重复、冗余的内容,对过长的文本块做精简,只保留和用户问题相关的核心内容;
- 严格控制上下文长度:根据大模型的上下文窗口上限,预留足够的空间给生成回答,避免内容被截断;
- 加入清晰的规则说明:在上下文的开头,明确告诉大模型,必须基于下面提供的上下文回答问题,不能编造内容。
9. Prompt Engineering(提示词工程):引导大模型正确使用知识,从根源减少幻觉
提示词工程,是 RAG 系统的 “指挥棒”。它的核心职责,是通过清晰的指令、模板、规则,引导大模型严格基于检索到的外部知识回答问题,平衡外部知识和自身的推理能力,从根源上减少幻觉,同时让回答的格式、风格、深度完全符合业务需求。
很多人以为 RAG 的提示词就是 “基于下面的内容回答问题”,但实际上,提示词的质量,直接决定了大模型能不能正确使用上下文,会不会编造内容,回答能不能满足业务要求。这个环节的常见坑包括:
- 核心规则缺失:没有明确要求大模型 “必须基于提供的上下文回答,上下文没有的内容要明确告知用户,禁止编造”,导致大模型频繁用预训练知识编造内容;
- 指令模糊不清:没有明确回答的格式、长度、语气、专业度,大模型的输出忽长忽短、风格混乱,不符合业务要求;
- 没有异常场景处理:没有定义 “上下文没有相关内容”、“问题违规”、“上下文有冲突” 等异常场景的处理规则,大模型在这些场景下会硬编内容;
- 没有引用标注要求:没有要求大模型标注回答内容对应的上下文来源,导致出现幻觉时无法追溯,用户也无法验证内容的真实性。
这个环节的最佳实践,是搭建一套结构化、场景化的提示词模板,核心包含 6 个部分:
- 角色设定:给大模型设定清晰的角色,比如 “专业的企业内部知识库客服”、“资深的技术文档工程师”,让它的回答贴合角色定位;
- 核心规则:明确不可突破的红线,包括必须基于提供的上下文回答、禁止编造内容、上下文没有相关内容时明确告知用户、禁止输出违规内容;
- 回答格式要求:明确回答的结构、格式、长度,比如用 markdown 格式、分点回答、先给核心结论再做解释,同时要求标注每个知识点对应的上下文来源编号;
- 少样本示例:给大模型提供 2-3 个符合要求的问答示例,让它清晰地知道正确的回答方式;
- 上下文内容:放入组装好的结构化检索上下文;
- 用户的原始问题:放在提示词的最后,让大模型聚焦问题本身。
同时,要针对不同的业务场景优化提示词,比如客服场景要求简洁友好、快速解决问题,技术文档场景要求准确严谨、步骤清晰,法律场景要求合规严谨、标注法条来源,不能用一套模板应对所有场景。
10. LLM Generator(大模型生成器):最终回答的生成环节,但不是系统的核心
大模型生成器,是整个 RAG 流水线的最后一个生成环节,它的核心职责,是基于组装好的上下文和提示词指令,生成最终的输出内容,包括问答回答、文档摘要、代码生成、方案撰写等。当前主流的模型包括闭源的 GPT-4 系列、Claude 3 系列,开源的 Llama 3、DeepSeek、Mistral 等。
这个环节最常见的认知误区,就是把大模型当成 RAG 系统的核心,以为只要用了最好的大模型,就能得到最好的效果。但现实是:哪怕你接入了全球最顶级的大模型,如果前面的检索环节找不到相关内容,上下文里全是噪声,提示词没有明确的规则,大模型依然会输出充满幻觉、答非所问的内容。大模型只是整个流水线的最后一环,它的能力上限,完全被前面所有环节的短板限制。
这个环节的常见坑包括:
- 盲目追求大模型:不管业务场景,都用最贵、最大的模型,导致成本极高,却没有带来对应的效果提升;
- 模型参数设置不合理:温度(Temperature)设置过高,导致回答随机性强、幻觉频发;温度设置过低,导致回答过于死板、缺乏灵活性;
- 没有做异常处理:大模型的输出超时、内容违规、格式错误时,没有对应的兜底机制,直接把异常内容返回给用户;
- 没有做成本控制:没有限制生成长度,没有优化调用频率,导致大模型的调用成本失控。
这个环节的最佳实践,核心是 “适配场景、优化参数、控制成本、兜底异常”:
- 根据业务场景选择合适的模型:简单的 FAQ 问答、内部知识库查询,用 7B-70B 的开源小模型就能满足需求,大幅降低成本;复杂的长文档推理、多轮对话、专业内容生成,用 GPT-4o、Claude 3.5 这类大模型,保证效果;
- 优化模型生成参数:RAG 场景下,温度一般设置在 0.1-0.3,最大限度减少幻觉;Top-P 设置在 0.9 左右,平衡回答的稳定性和灵活性;设置合理的最大生成长度,避免无效的长文本输出;
- 建立完善的异常兜底机制:针对模型超时、内容违规、格式错误等异常情况,设置重试机制和兜底回复,保证用户体验的稳定性;
- 做好成本控制:通过缓存常见问题的回答、优化上下文长度、选择合适的模型,控制大模型的调用成本,避免成本失控。
11. Post-Processing(后处理):给用户的最后一道把关,提升回答的可信度与安全性
后处理,是 RAG 系统交付给用户之前的最后一道把关。它的核心职责,是对大模型生成的内容做进一步的优化、校验、格式化,同时加入引用标注、安全校验,确保输出的内容准确、合规、安全、易用。
很多项目完全跳过了这个环节,大模型生成什么就直接给用户看什么,最终导致格式混乱、引用错误、幻觉内容、甚至违规内容直接流出,严重影响用户的信任。这个环节的常见坑包括:
- 完全不做事实一致性校验,大模型编造的幻觉内容直接交付给用户;
- 没有做格式优化,输出的内容格式混乱,可读性极差;
- 没有标注引用来源,用户无法验证内容的真实性,出现问题也无法追溯;
- 没有安全审核,违规、有害、偏见的内容直接流出,给企业带来合规风险。
这个环节的最佳实践,是搭建一套完整的后处理流水线,覆盖 4 个核心环节:
- 格式与内容优化:根据业务需求,对生成的内容做格式化处理,比如统一 markdown 格式、调整段落结构、高亮核心结论、拆分长文本,提升内容的可读性;
- 事实一致性校验:用专门的校验模型,或者大模型自身,检查生成的内容和检索到的上下文是否一致,过滤掉编造的、和上下文无关的幻觉内容,确保回答的每一句话都有上下文支撑;
- 引用与溯源标注:把回答里的每一个知识点,和对应的上下文来源对应起来,标注清楚来源文档、页码、链接,用户可以直接点击查看原文,大幅提升回答的可信度;
- 安全与合规审核:通过内容安全模型,审核生成的内容,过滤掉违规、有害、偏见、敏感的内容,同时设置兜底回复,确保输出的内容完全符合企业的合规要求。
12. Feedback & Evaluation(反馈与评估):整个系统的闭环,持续优化的核心
反馈与评估,是整个 RAG 流水线的最后一个环节,也是让系统能长期稳定运行、持续优化的核心,更是绝大多数项目完全缺失的环节。它的核心职责,是持续监控系统的准确率、幻觉率、延迟、成本,通过人工反馈、自动化基准测试、用户行为数据,持续优化整个流水线的每一个环节。
很多企业的 RAG 系统上线后就再也不管了,没有监控、没有评估、没有优化,随着业务数据的更新、用户需求的变化,系统的效果会越来越差,最终被用户弃用。这个环节的常见坑包括:
- 没有量化的评估指标,全靠主观感受判断系统好坏,根本不知道哪里出了问题;
- 没有自动化的评估机制,只能靠人工抽查,无法及时发现系统效果的下降;
- 用户反馈只是摆设,没有把反馈落地到系统的优化中,用户反复踩同一个坑;
- 没有持续的迭代优化,上线后就不再调整分块、检索、提示词等环节,系统效果持续下滑。
这个环节的最佳实践,是搭建一套 “监控 - 评估 - 反馈 - 优化” 的完整闭环:
- 建立量化的评估指标体系,覆盖三大维度:
- 检索指标:召回率、精确率、MRR(平均倒数排名),衡量检索环节能不能找到相关的内容;
- 生成指标:幻觉率、事实一致性、回答相关性、流畅度、用户满意度,衡量生成内容的质量;
- 系统指标:平均延迟、吞吐量、单次查询成本、系统可用性,衡量系统的工程化表现。
- 搭建自动化的评估流水线:用 RAGAS、ARES 这类 RAG 专用评估工具,搭建自动化的评估流程,定期用业务基准测试集,自动评估系统的全链路效果,一旦指标出现下降,立刻触发告警;
- 建立完善的用户反馈机制:在产品里加入回答点赞、点踩、纠错、评论功能,收集用户的真实反馈,把用户点踩的、纠错的问题,加入到优化测试集中,定位问题根源,针对性优化;
- 持续的迭代优化与 A/B 测试:针对分块策略、嵌入模型、检索方式、提示词模板等环节的优化,做严格的 A/B 测试,用量化的指标验证优化效果,避免凭感觉调整;
- 定期更新基准测试集:把用户的高频问题、边缘问题、难例、新的业务场景,持续加入到测试集中,保证评估体系能覆盖真实的业务需求,让系统的优化始终贴合用户的真实需求。
结语:生产级 RAG 的竞争,是系统工程的竞争
到这里,我们已经完整拆解了生产级 RAG 流水线的 12 个核心组件。你会发现,真正决定 RAG 系统上限的,从来不是你用了多好的大模型,而是整个流水线的工程化打磨 —— 从源头的文档摄入,到最终的反馈优化,每一个环节的短板,都会成为整个系统的天花板。
太多团队把 90% 的精力放在了大模型的选型上,却忽略了分块、检索、重排序、评估这些更关键的环节,最终陷入了 “Demo 效果惊艳,生产环境一塌糊涂” 的困境。
生产级 RAG 从来都不是一个简单的 “向量库 + 大模型” 的玩具,而是一套精密、完整、闭环的系统工程。它的核心竞争力,从来不是单点的算法突破,而是全链路的精细化打磨、持续的闭环优化。
2026 年,RAG 的竞争早已不是模型的竞争,而是工程化能力的竞争。只有把每一个环节都做扎实,搭建起完整的流水线与优化闭环,才能真正落地一套稳定、可靠、低幻觉、高可用的生产级 RAG 系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)