EvoScientist:让 AI 科学家学会“长记性“——多智能体进化框架如何实现端到端科研自动化
EvoScientist:让 AI 科学家学会"长记性"——多智能体进化框架如何实现端到端科研自动化
论文标题:EvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
作者:Yougang Lyu, Xi Zhang, Xinhao Yi, Yuyue Zhao, Shuyu Guo, Wenxiang Hu, Jan Piotrowski, Jakub Kaliski, Jacopo Urbani, Zaiqiao Meng, Lun Zhou, Xiaohui Yan
机构:Huawei Technologies Co., Ltd. 等
论文链接:https://arxiv.org/abs/2603.08127
代码链接:https://github.com/EvoScientist/EvoScientist
发表日期:2026 年 3 月
🎯 一句话总结
EvoScientist 是一个会"长记性"的 AI 科学家系统:它由三个专业智能体组成,通过持久记忆和自我进化机制,把每次科研实验的成功经验和失败教训都沉淀下来,让后续的想法生成和实验执行越来越靠谱。6 篇 AI 全自动生成的论文全部被 ICAIS 2025 接收,其中一篇拿了最佳论文奖。
📖 为什么需要这篇论文?
现有 AI 科学家系统的"失忆症"
过去两年,AI 自动科研赛道涌现了一批系统:Sakana AI 的 AI Scientist(v1/v2)、Virtual Scientist、InternAgent 等。这些系统的核心流程大同小异——给定一个研究方向,让 LLM 读论文、想 idea、写代码、跑实验、写论文,一条龙搞定。
听起来很美,但实操中有个严重问题:这些系统都是"一次性"的。
打个生活化的比喻:想象你是一个研究生,导师让你连续做 10 个课题。如果你每做完一个课题就失忆一次,忘掉所有踩过的坑和积累的经验,那第 10 个课题的质量跟第 1 个不会有本质区别。你会重复犯同样的错误——数据预处理忘了归一化、某个 baseline 的超参数调不好、某个看似创新但实际不可行的方向反复尝试。
这恰恰是当前 AI 科学家系统的现状:
- 想法层面:不知道哪些方向已经被验证为"死胡同",反复生成类似的失败想法
- 代码层面:每次从零开始写实验代码,不会复用之前调通的数据处理流水线和训练策略
- 整体层面:缺乏跨任务的经验积累,不会"越做越好"
EvoScientist 要解决的就是这个问题:让 AI 科学家具备"长期记忆"和"自我进化"能力。
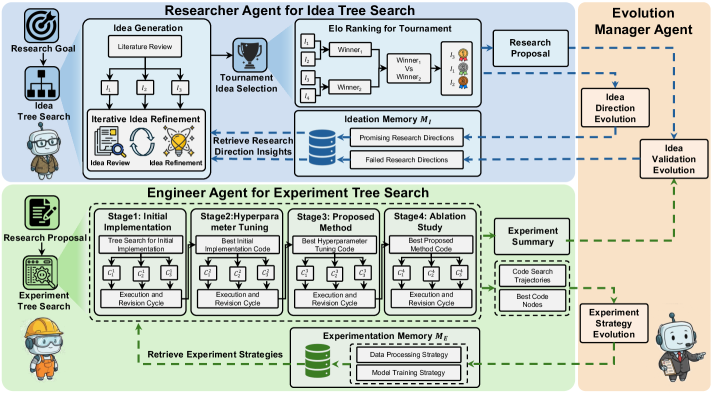
图 1:EvoScientist 整体框架——三个智能体(研究智能体 RA、工程智能体 EA、进化管理智能体 EMA)协作,通过构想记忆和实验记忆实现跨任务的持续进化
🏗️ 方法:三个智能体 + 两块记忆
EvoScientist 的架构设计很清晰,三个角色分工明确:
| 智能体 | 角色定位 | 核心任务 |
|---|---|---|
| 研究智能体(RA) | “科研大脑” | 文献综述、想法生成、想法排名 |
| 工程智能体(EA) | “代码执行者” | 代码实现、实验执行、结果报告 |
| 进化管理智能体(EMA) | “经验总结者” | 从历史交互中提炼可复用知识 |
两块持久记忆则是系统进化的根基:
- 构想记忆 MIM_IMI:记录"哪些方向有前景"和"哪些方向是死胡同"
- 实验记忆 MEM_EME:记录"哪些数据处理策略好用"和"哪些训练技巧有效"
下面拆解每个组件的设计。
研究智能体(RA):想法的"树搜索 + 锦标赛"
想法生成是科研的第一步,也是最难的一步。EvoScientist 用了一套很有意思的"想法树搜索"机制。
想法树搜索:不是一次性让 LLM 蹦出一个想法,而是用树结构做"提议-审查-完善"的迭代搜索。每个节点存储一个想法草稿和它收到的审查反馈,通过不断分支和完善来扩展搜索空间。这比直接让 LLM 一次输出一个想法要靠谱得多——就像写论文,第一版草稿往往很糙,经过反复修改才能出精品。
锦标赛想法选择:候选想法生成后,怎么选最好的?EvoScientist 用了基于 Elo 评分的锦标赛机制。让 LLM 评委对想法进行两两对比,从新颖性、可行性、相关性和清晰度四个维度打分,最终产生排名。保留 Top-3 的想法用于方向总结,排名第一的想法扩展为完整的研究提案。
关键点在于——RA 在生成想法之前,会先从构想记忆中检索相关的方向知识:哪些方向之前被验证为有前景(值得深挖),哪些方向已经被证实是死胡同(不要再踩)。这就像一个有经验的研究生,在选题之前先翻翻组里的"研究日志",避免重蹈覆辙。
工程智能体(EA):四阶段实验树搜索
有了研究提案,接下来要把它变成能跑的代码。EA 把实验过程拆成四个阶段,每个阶段都做树搜索:
- 初始实现(Stage 1):搭建基线代码框架
- 超参数调优(Stage 2):在基线上寻找最优超参数
- 提出方法实现(Stage 3):实现论文提出的核心方法
- 消融实验(Stage 4):验证每个组件的贡献
每个阶段内部是一个"生成代码 → 执行 → 检查结果 → 失败则修正"的循环。EA 在开始工作前,会从实验记忆中检索可复用的执行策略,比如"这类 NLP 任务用什么数据预处理流程效果最好"、"训练时学习率调度用 cosine 比 step 好"等等。
这个设计的好处是什么?假设系统之前做过 5 个 NLP 相关的课题,EA 已经积累了一套行之有效的数据加载、tokenization、训练配置经验。做第 6 个 NLP 课题时,就不需要从零摸索了。
进化管理智能体(EMA):经验的"蒸馏器"
EMA 是整个系统的灵魂——它负责把每次交互的原始轨迹"蒸馏"成精炼的、可复用的知识。具体做三件事:
1. 想法方向进化:从锦标赛排名靠前的想法中提炼"有前景的研究方向"。比如,如果多个高分想法都涉及"对比学习 + 领域自适应"的组合,EMA 会把这个方向模式记下来。
2. 想法验证进化:分析失败的实验——如果工程智能体在预定预算内没跑通代码,或者提出的方法反而不如基线,EMA 会记录这个方向为"失败方向",并分析失败原因。就像医生做手术后的病例讨论:这次为什么失败了?是假设本身有问题,还是实现上的 bug?
3. 实验策略进化:从 EA 的代码搜索轨迹和最终高效实现中,总结可复用的数据处理策略和模型训练策略。
用一个公式来概括整个进化过程:
MIt+1,MEt+1=EMA(Ht,MIt,MEt)M_I^{t+1}, M_E^{t+1} = \text{EMA}(H_t, M_I^t, M_E^t)MIt+1,MEt+1=EMA(Ht,MIt,MEt)
其中 HtH_tHt 是第 ttt 轮任务的完整交互历史,MItM_I^tMIt 和 MEtM_E^tMEt 分别是当前的构想记忆和实验记忆。
🧪 实验:打遍天下无敌手?
实验设置
EvoScientist 的评估相当全面,覆盖了三个层面:
- 想法生成质量:30 个来自资深 AI 研究人员的研究查询,四维度评估
- 代码执行可靠性:四阶段实验的执行成功率
- 端到端科研能力:提交论文到 ICAIS 2025 进行真实同行评审
基线系统包括 4 个开源系统(Virtual Scientist、AI-Researcher、InternAgent、AI Scientist-v2)和 3 个商业系统(Hypogenic、Novix、K-Dense)。
实现细节方面:想法生成用 Gemini-2.5-Pro,代码生成用 Claude-4.5-Haiku,手稿撰写用 Gemini-2.5-Pro,记忆索引和检索用 mxbai-embed-large 嵌入模型。
想法生成:自动评估全面领先
下表展示了 EvoScientist 与各基线在自动评估中的对比结果(LLM Judge: Gemini-3-flash):
对比开源系统:
| 对比方法 | 新颖性 Win% | 可行性 Win% | 相关性 Win% | 清晰度 Win% | 平均差距 |
|---|---|---|---|---|---|
| vs Virtual Scientist | 96.67 | 93.33 | 90.00 | 96.67 | +93.34 |
| vs AI-Researcher | 96.67 | 90.00 | 86.67 | 93.34 | +87.50 |
| vs InternAgent | 73.33 | 93.33 | 86.67 | 96.67 | +83.33 |
| vs AI Scientist-v2 | 63.33 | 53.33 | 36.67 | 56.67 | +29.17 |
对比商业系统:
| 对比方法 | 新颖性 Win% | 可行性 Win% | 相关性 Win% | 清晰度 Win% | 平均差距 |
|---|---|---|---|---|---|
| vs Hypogenic | 93.33 | 83.34 | 70.00 | 96.67 | +80.83 |
| vs Novix | 90.00 | 53.33 | 46.67 | 70.67 | +46.00 |
| vs K-Dense | 86.67 | 56.67 | 43.33 | 76.67 | +54.50 |
几个有意思的观察:
-
碾压弱基线,但强手之间差距在缩小。对 Virtual Scientist 的胜率接近 100%,但对 AI Scientist-v2 的胜率降到了 63%(新颖性)甚至 37%(相关性)。这说明 Sakana AI 的 v2 版本确实是个硬茬。
-
新颖性是 EvoScientist 最强的维度。几乎在所有对比中,新颖性的胜率都是最高的。这或许得益于构想记忆中积累的"有前景方向"——系统能够在前人经验的基础上提出更有创意的组合。
-
相关性是最容易"打平"的维度。特别是对 K-Dense 和 Novix 的对比中,相关性的平局率高达 36-50%。这合理——相关性更多取决于是否理解了用户目标,进化机制对此的帮助有限。
人工评估:一致性验证
论文还找了专家做人工评估,与自动评估的结论基本一致:
| 对比方法 | 新颖性 Win% | 可行性 Win% | 相关性 Win% | 清晰度 Win% | 平均差距 |
|---|---|---|---|---|---|
| vs InternAgent(人工) | 66.67 | 96.67 | 90.00 | 93.33 | +84.17 |
| vs AI Scientist-v2(人工) | 73.33 | 50.00 | 43.33 | 53.33 | +34.16 |
| vs Novix(人工) | 93.33 | 56.67 | 36.67 | 73.33 | +49.17 |
| vs K-Dense(人工) | 96.67 | 53.34 | 40.00 | 53.34 | +50.84 |
一个亮点是,LLM 评估和人工评估的总体一致性达到了 90.0%,这给自动评估的可信度提供了不错的背书。
代码执行成功率:进化前后对比
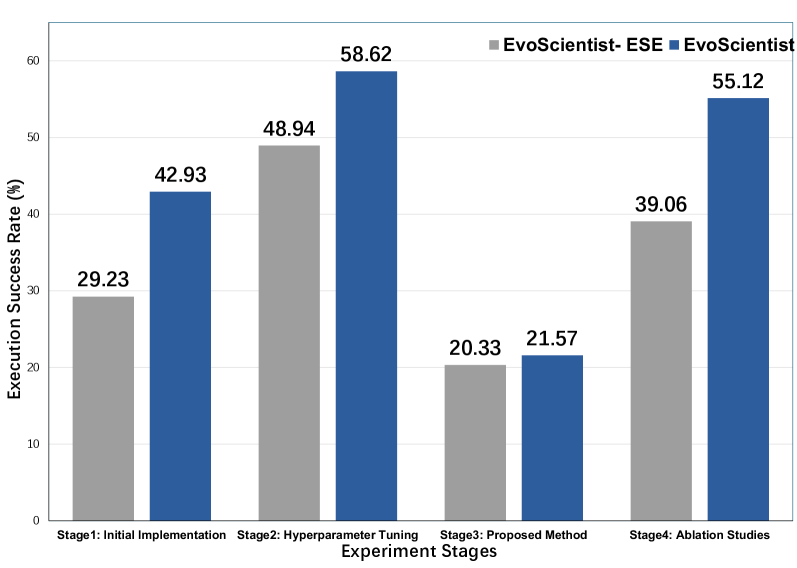
图 2:实验策略进化(ESE)前后各阶段代码执行成功率对比。灰色为进化前,蓝色为进化后。
这张图信息量很大:
| 实验阶段 | 进化前 (%) | 进化后 (%) | 提升 |
|---|---|---|---|
| Stage 1: 初始实现 | 29.23 | 42.93 | +13.70 |
| Stage 2: 超参数调优 | 48.94 | 58.62 | +9.68 |
| Stage 3: 方法实现 | 20.33 | 21.57 | +1.24 |
| Stage 4: 消融实验 | 39.06 | 55.12 | +16.06 |
| 平均 | 34.39 | 44.56 | +10.17 |
Stage 3(方法实现)的提升幅度最小——只有 1.24 个百分点。这反映了一个现实:每个课题提出的核心方法都是独特的,可复用的"通用策略"有限。相比之下,初始实现和消融实验更具模式化,积累的经验更容易迁移。
不过说实话,整体 44.56%的成功率并不算高。这意味着平均每 10 次代码执行,只有不到 5 次能跑通。如果考虑到这还是经过进化后的数据,可以想象 AI 自动科研在工程实现上还有很长的路要走。
消融实验:每块记忆都有用
| 消融配置 | 新颖性 (W/T/L) | 可行性 (W/T/L) | 相关性 (W/T/L) | 清晰度 (W/T/L) | 平均差距 |
|---|---|---|---|---|---|
| 去掉方向进化(-IDE) | 16.67/16.67/66.67 | 20.00/30.00/50.00 | 23.33/50.00/26.67 | 23.33/46.67/30.00 | -22.50 |
| 去掉验证进化(-IVE) | 30.00/26.67/43.33 | 10.00/26.67/63.33 | 30.00/46.67/23.33 | 16.67/46.67/36.67 | -20.00 |
| 全部去掉(-all) | 10.00/10.00/80.00 | 03.33/13.33/83.33 | 16.67/46.67/36.67 | 20.00/46.67/33.33 | -45.83 |
几个值得关注的发现:
- 去掉方向进化(-IDE)对新颖性打击最大:66.67%的情况下完整版胜出。这说明"有前景方向"的积累对生成更有创意的想法至关重要。
- 去掉验证进化(-IVE)对可行性打击最大:63.33%的情况下完整版胜出。这很直觉——知道哪些路走不通,自然能避开不可行的方向。
- 两者都去掉效果断崖式下降:平均差距从-20~-22.5 扩大到-45.83,说明两种进化机制有互补效应。
端到端科研:6/6 全部接收,1 篇最佳论文
这可能是整篇论文最亮眼的结果了:EvoScientist 生成的 6 篇论文全部提交到 ICAIS 2025(AI Scientist Track),全部被接收(会议整体接收率仅 31.71%)。
| 论文标题 | 评审结果 |
|---|---|
| Adaptive Evidential Meta-Learning… | 🏆 最佳论文奖 |
| Hierarchical Change Signature Analysis… | 🎖️ AI 审议员赞誉奖 |
| Robust Zero-Shot NER for Crises… | ✅ 接收 |
| Adaptive Log Anomaly Detection… | ✅ 接收 |
| ConFIT: Knowledge-Guided Contrastive Framework… | ✅ 接收 |
| Hierarchical Adaptive Normalization… | ✅ 接收 |

图 3:获得 ICAIS 2025 最佳论文奖的"自适应证据元学习"论文全貌
同行评审反馈显示,这些论文的方法论新颖性和实验验证得到了审稿人的认可,但在理论形式化和一致性审计方面仍有改进空间——这和人写的论文面临的评审意见其实差不多。
🔧 技术细节:构想记忆和实验记忆长什么样?
论文的附录提供了 EMA 使用的具体 Prompt,让我们能窥探记忆是如何构建的。
构想记忆的写入
方向进化 Prompt 的核心逻辑(见原文 Figure 8):
- 输入:用户目标 + 锦标赛排名前列的想法
- 任务:从高分想法中提炼"有前景的研究方向"
- 输出格式:每个方向包含标题、核心机制、为什么有前景、关键假设、最小验证计划
验证进化 Prompt 的核心逻辑(见原文 Figure 9):
- 输入:研究提案 + 执行报告
- 任务:判断实验是否失败(两种判定条件:预算内找不到可执行代码;方法性能不如基线)
- 输出:失败原因分析 + 3-6 条可复用的避坑建议
实验记忆的写入
策略进化 Prompt 的核心逻辑(见原文 Figure 10):
- 输入:研究任务描述 + 代码搜索轨迹 + 最终高效代码
- 任务:提炼数据处理策略(数据加载、预处理、增强、划分)和模型训练策略(骨干网络、超参数、优化器、调度器)
- 约束:不能省略具体参数、库函数名等细节,确保"另一个工程师能根据总结重现"
这个设计思路和人类科研中的"实验记录本"如出一辙。区别在于,人类的实验记录本通常格式混乱、关键细节缺失,而 EMA 通过结构化 Prompt 强制输出规范化的知识条目。
📊 与其他 AI 科研系统的对比
| 特性 | AI Scientist v2 | Virtual Scientist | InternAgent | EvoScientist |
|---|---|---|---|---|
| 多智能体架构 | ✅ | ✅ | ✅ | ✅ |
| 持久记忆 | ❌ | ❌ | ❌ | ✅ |
| 跨任务进化 | ❌ | ❌ | ❌ | ✅ |
| 想法树搜索 | ✅ | ❌ | ❌ | ✅ |
| 实验树搜索 | ❌ | ❌ | ❌ | ✅ |
| 端到端论文生成 | ✅ | ✅ | ✅ | ✅ |
| 论文被顶会接收 | ✅(Workshop) | ❌ | ❌ | ✅(含最佳论文) |
核心差异化:EvoScientist 的独特之处在于"进化"二字——其他系统是"一次性"的,每个课题独立处理;而 EvoScientist 能把经验带到下一个课题中,实现跨任务的能力提升。
💡 我的思考和启发
1. 持久记忆是 AI Agent 的下一个必备能力
这篇论文戳中了当前 AI Agent 系统的一个痛点:缺乏长期记忆导致的"失忆症"。不仅 AI 科研系统有这个问题,代码 Agent、客服 Agent、数据分析 Agent 都有。Claude Code 最近加入了 CLAUDE.md 的项目记忆文件,Cursor 也有 .cursorrules,本质上都是在解决同一个问题。EvoScientist 把这个思路从"配置文件"升级到了"自动蒸馏+结构化索引"的高度。
2. 44%的代码执行成功率够用吗?
说实话,这个数字让我有点担忧。在工程实践中,一半以上的代码执行失败,意味着巨大的计算资源浪费。考虑到实验用的是 Claude-4.5-Haiku(不是最强的代码模型),换成更强的模型可能有提升空间。但更根本的问题在于——AI 生成的实验代码在面对复杂的依赖关系、环境配置和边界情况时依然脆弱。
3. ICAIS 2025 的接收率值得讨论
6 篇全部接收确实亮眼,但 ICAIS 2025 是一个专门为"AI Scientist"设立的 Track,其审稿标准和 NeurIPS/ICML 这类顶会相比如何?论文提到会议整体接收率 31.71%(82 投 26 中),这个接收率在 AI 领域算中等偏低。不过考虑到这是 AI 自动生成的论文,能通过真人审稿本身就是里程碑式的成就。
4. 进化管理智能体的设计值得借鉴
EMA 的设计理念——用 LLM 来总结 LLM 的经验——是一种很实用的"元认知"范式。我觉得这个思路可以迁移到很多场景:
- 代码 Agent:从历史 debug 轨迹中提炼"避坑指南"
- 数据分析 Agent:从历史分析报告中提炼"数据质量检查清单"
- 客户服务 Agent:从历史对话中提炼"高频问题应对策略"
5. 记忆的"保质期"问题
论文没有讨论的一个问题是:积累的记忆会不会过时?在 AI 领域,两年前的最佳实践可能现在已经不再最优。如果构想记忆中存了"X 方向是死胡同",但两年后新技术出来让这个方向变得可行了,系统反而会被旧记忆"误导"。如何设计记忆的"遗忘机制"或"版本控制",是后续值得探索的方向。
⚠️ 局限性
作者在论文中坦诚指出了几个局限:
-
仅覆盖计算类研究:评估集中在通过模拟和代码执行就能验证假设的计算任务上。推广到需要物理实验的学科(化学、生物等)仍是开放问题。
-
评估规模有限:30 个研究查询、6 篇端到端论文——数量上还不够大。统计显著性在某些对比中可能不够稳健。
-
依赖强 LLM 基础模型:系统依赖 Gemini-2.5-Pro 和 Claude-4.5-Haiku,换成开源模型效果可能大打折扣。
-
记忆检索的准确性:论文用了基于嵌入的语义检索,但没有做记忆检索准确性的消融分析。如果检索到不相关的记忆,反而可能引入噪声。
🔗 相关资源
- 论文:https://arxiv.org/abs/2603.08127
- 代码:https://github.com/EvoScientist/EvoScientist(Apache-2.0 License,支持 pip install)
- 相关工作:AI Scientist v2(Sakana AI)、Virtual Scientist(ACL 2025)、InternAgent-1.5
- DeepResearch Bench II:EvoScientist 在提交时排名第一
📝 总结
EvoScientist 抓住了 AI 自动科研领域的一个关键痛点——系统不会从历史中学习——并给出了一个工程上可落地的解决方案。三智能体+双记忆的架构简洁有效,实验结果在想法生成和端到端论文产出上都很能打。
当然,代码执行成功率还有很大提升空间,评估的广度和深度也还可以继续扩展。但这篇论文提出的"多智能体进化"范式,我认为是 AI 科研系统从"能用"走向"好用"的关键一步。
一句话:AI 科学家最缺的不是智商,而是记忆力。EvoScientist 开始补上这一课了。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我的微信公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)