基于LDA主题模型的数据素养评价指标体系研究
导读:
在信息化快速发展的背景下,大学生数据素养已成为衡量其数字社会适应能力的重要指标。为精准评估其水平,本研究基于中国知网(CNKI)近十年1291篇相关文献,运用潜在狄利克雷分配(LDA)模型进行分析,揭示了数据分析、数据安全、数据素养教育等研究热点,并构建涵盖5个一级指标和23个二级指标的大学生数据素养测评体系。该体系为数据素养教育的优化与课程改革提供了科学依据,推动高质量教学发展,并为后续研究提供了新的视角与方向。
作者信息:
郑 浩*, 邓海生:西京学院计算机学院,陕西 西安
论文详情
LDA主题模型
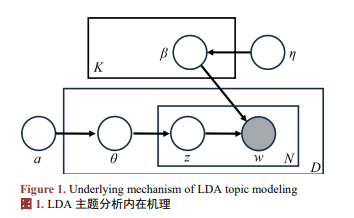
主题概率模型无需预设文本结构或依赖语法规则,适用于大规模稀疏文本,在主题发现与提炼方面具有优势。相关方法包括LDA、STM、PLSI和Unigram等。其中,Blei等人提出的LDA以稳定性与有效性著称,应用最为广泛。本文采用LDA对文献数据进行主题识别与分析,以揭示大学生数据素养研究的主要内容与结构,其基本原理如图1所示。
数据采集
本研究以中国知网(CNKI)为主要数据来源,以“数据素养”为检索主题,检索时间范围为2010年4月至2025年12月,共获得3135篇文献。经模糊筛选与人工复核,剔除与研究无关及非学术性文献后,最终保留1291篇有效样本,其中包括学术期刊1073篇、学位论文154篇、学术会议论文29篇、报纸文章10篇及特色期刊论文25篇。
主题模型分析
LDA主题模型分析包括三个主要环节:文本预处理以确保数据质量,模型构建以提取潜在主题结构,及基于输出结果的主题特征抽取与评价指标构建。详情参见原文链接。
主题特征抽取
主题模型的输出本质为“主题–词项”概率分布,既包含代表性强但语义泛化的高频词,也包含区分度高但可能低频的特征词。若仅按概率排序,易出现代表性有余而区分性不足;若仅按区分度排序,则可能引入稀疏且解释性不稳的词。为兼顾两者,本文在主题词提取中同时考虑词项在主题下的条件概率及其相对全局语料分布的提升程度,采用“相关性”综合排序进行加权计算,以增强主题解释的科学性与稳定性。其计算公式如(2-8):![]()
其中,λ 用于平衡高概率词与高区分度词的权重。本文取λ=0.6 ,以兼顾主题词的代表性与区分性,避免仅由通用高频词主导而削弱解释力。最终,从每个主题中选取相关性得分最高的前10个词作为该主题的特征词集合。
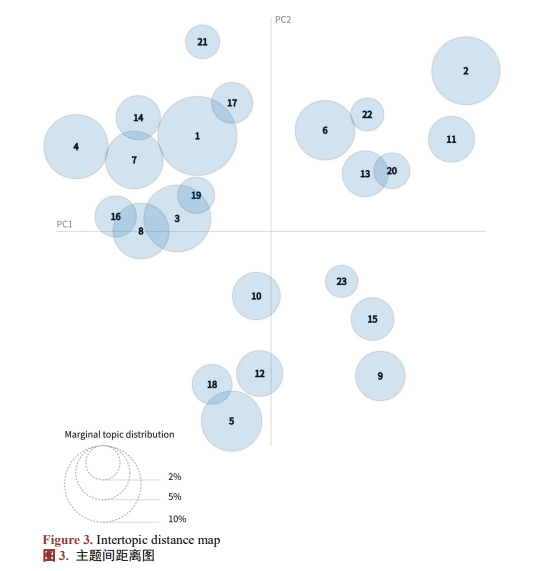
如图3和表1所示,各主题的前10个特征词能够清晰地呈现主题的内涵与边界。


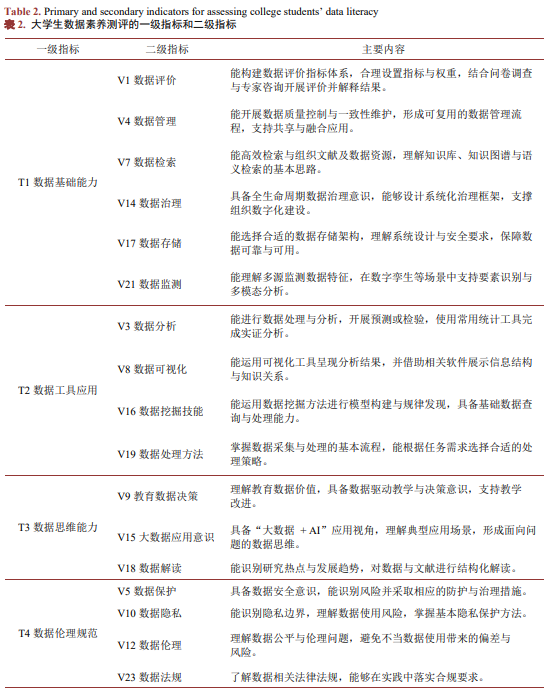
本文以国内外关于数据素养内涵与结构维度的研究成果为理论锚点,在系统梳理既有模型的基础上,对一级指标进行整合与重构,如表2。

本研究立足信息化时代数据素养的战略价值,针对大学生数据素养差异显著及既有测评体系适配性不足的问题,运用LDA主题模型对近十年相关文献进行系统分析,构建了包含数据基础能力、工具应用、思维能力、伦理规范与践行能力五个维度、23项指标的大学生数据素养评价体系。该体系以数据驱动的量化结果为依据,融合国内外理论框架,覆盖数据全生命周期核心能力,为高校数据素养测评与课程建设提供了参考。
未来可在此基础上进一步拓展指标内涵,将生成式 AI、数字孪生等新兴技能纳入评估;开展面向不同学科与年级群体探索差异化培养路径;开发配套教学与测评工具,推动数据素养教育与专业课程深度融合。同时,加强国际比较与本土化适配,借鉴先进经验优化教育模式,推动数字时代复合型人才培养。
基金项目:
本文系2023年度教育部人文社会科学研究规划基金项目“大学生数据素养评价体系理论及实证研究”(23YJAZH022);中国民办教育协会2025年度规划课题“智慧软件在大学生人工智能素养培养中的应用研究”(CANQN250577);西京学院2025年度教育教学改革研究项目“人工智能素养培养的‘积木式’教学工具开发与创新教学模式研究”(JGYB2527)的研究成果。
原文链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)