深度学习用于自然语言处理:CBOW训练和测试
一、根据上下文预测当前词
继续上文对CBOW自然语言处理的过程分析。
一个函数,将上下文文本转化为pytorch张量
def make_context_vector(context, word_to_idx):
idxs = [word_to_idx[w] for w in context]
return torch.tensor(idxs, dtype=torch.long) # 强制类型的转换,将列表转换为张量
搭建神经网络模型,nn.embeddings是一个网络层,构建49x10的一个矩阵
全连接层[4x49]*[49x10]=[4x10]==>>[1x10],全连接128个神经元
这里len(inputs)就是4,其实就是求平均,确保最后只有一行输出。这里的relu不是一个网络层。log_softmax提前现在这里做一个交叉熵函数(可以把大的值变得越大,小的越小,拉大之间的差距,方便后面对比),其实就是把交叉熵损失函数拆成两部分进行。
class CBOW(nn.Module): # 神经网络
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__() # 父类的初始化
self.embeddings = nn.Embedding(vocab_size, embedding_dim) # vocab_size:词嵌入的one-hot大小,embedding_dim:压缩后的词嵌入大小
self.proj = nn.Linear(embedding_dim, 128)
self.output = nn.Linear(128, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)/len(inputs) # 对嵌入向量求和
out = F.relu(self.proj(embeds)) # nn.relu激活层
out = self.output(out)
nll_prob = F.log_softmax(out, dim=-1) # softmax交叉熵
return nll_prob
设备使用,输入词表的大小(49),和词向量的维度也就是embedding层的维度(10)。
原来是49*49,压缩为49*10
# 模型在cuda训练
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(device)
model = CBOW(vocab_size, 10).to(device) # 语料库中一共有49个单词
optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器
1.训练
这里使用的二分类损失函数,和上面我们提到的交叉熵函数共同作用就是交叉熵损失函数。
tqdm,添加一个进度条,只要有for循环就可以使用进度条
target,对应的编码转化为张量
前向传播进入神经网络模型forward,context_vector就是我们传入的参数,对应input,在下面内容展示中我们知道context_vector的内容其实就是目标词上下文词张量矩阵
losses = [] # 存储损失的集合
loss_function = nn.NLLLoss() # NLLLoss损失函数(当分类类别非常多的情形),这里和Log_softmax合在一起就是交叉熵损失
model.train() # 设置模型为训练模式
for epoch in tqdm(range(200)): # 开始训练
total_loss = 0
for context, target in data:
#遍历每个训练样本,这里的data就是我们上文分析过的上下文和预测词组合的元组
context_vector = make_context_vector(context, word_to_idx).to(device)
target = torch.tensor([word_to_idx[target]]).to(device)
# 开始前向传播,进入forward
train_prediction = model(context_vector) # 可以不写forward, torch的内置功能
loss = loss_function(train_prediction, target) # 计算真实值和预测值之间的差距
# 反向传播
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播计算得到每个参数的梯度值
optimizer.step() # 根据梯度更新网络参数
total_loss += loss.item()
losses.append(total_loss)
print(losses)data内容:
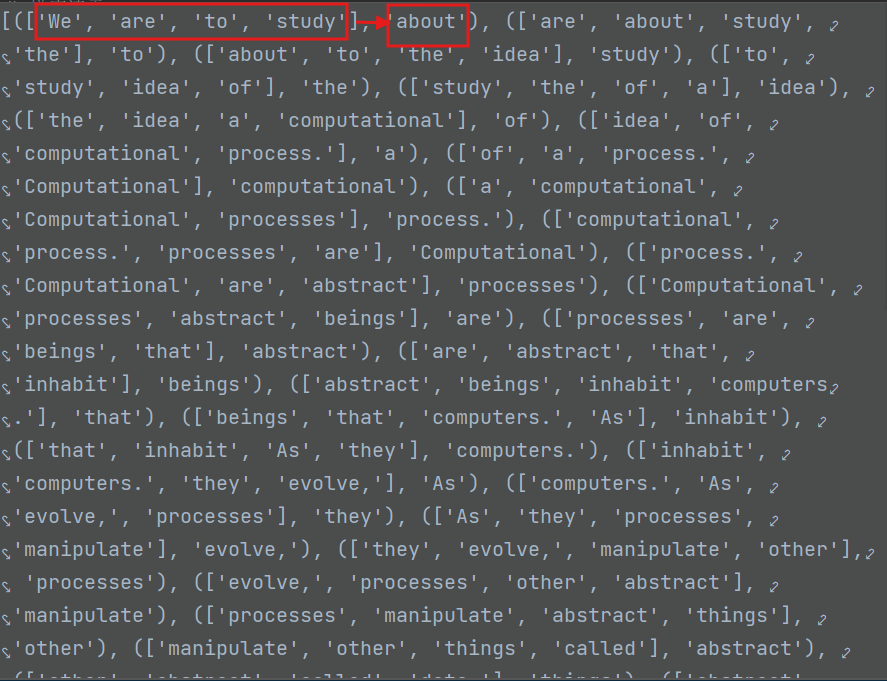
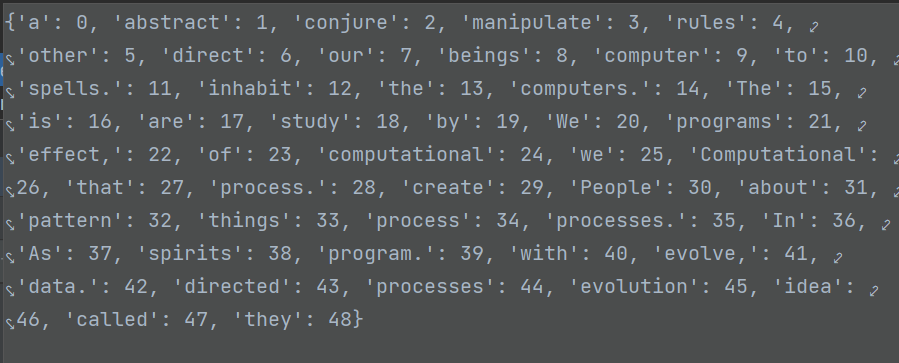
word_to_idx内容:(每一次运行的编码都是不一样的)
根据word_to_idx编号把data中每一组上下文此列表转化为张量,例如:

target也就是我们目标,要预测的那个词也根据word_to_idx编号转为张量,about编码是31
![]()
inputs是四个词的索引,embeddings把他转化为10维的向量
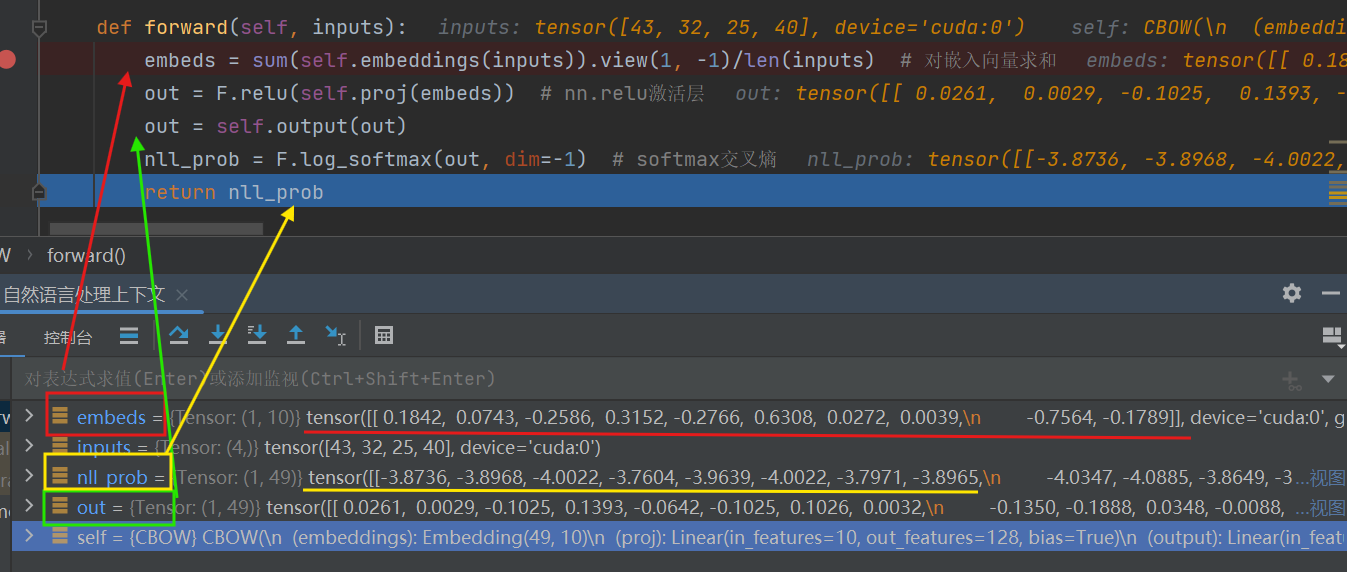
2.测试
# 测试
context = ['People', 'create', 'to', 'direct'] # People create programs to direct
context_vector = make_context_vector(context, word_to_idx).to(device)
# 预测的值
model.eval() # 进入测试模式
predict = model(context_vector)
max_idx = predict.argmax(1) # dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
print(f"测试上下文: {context}")
print(f"预测结果索引: {max_idx.item()}")
print(f"预测的单词: '{idx_to_word[max_idx.item()]}'")3.输出权重
datach():转化为numpy矩阵,拿回cpu中,w权重就是我们需要保存下来的,权重矩阵w=所有词的向量表。为我们下面词嵌入字典的保存做准备。
# 获取词向量,这个Embedding就是我们需要的问题向量。他只是一个模型的一个中间过程
print("CBOW embedding weight=", model.embeddings.weight) # GPU
W = model.embeddings.weight.cpu().detach().numpy()
# .detach(): 这个方法会创建一个新的Tensor,它和原来的Tensor共享数据,
# 但不会参与梯度的反向传播,这对于防止在计算梯度时意外修改某些参数很有用
# print(W)
4.生成词嵌入字典
词嵌入字典是不是就相当于人类的字典一样,这个字典是给机器使用的,方面以后机器进行理解词义的时候使用,尤其是压缩词的时候。对于人来说字典就是词义,对于机器来说他的‘字典’就是词向量。这里词向量其实就是上面我们获得的w权重矩阵。
# 生成词嵌入字典,即[单词1:词向量1, 单词2:词向量2...]的格式
word_2_vec = {}
for word in word_to_idx.keys():
word_2_vec[word]=W[word_to_idx[word],:]
print('over')
np.savez('word2vec实现.npz',file1=W)
data=np.load('word2vec实现.npz')
print(data.files)
a=data[data.files[0]]
print(a)词嵌入字典文件保存后缀通常为npz或者npy
二、numpy进行保存和读取词嵌入字典文件
有两种保存方法和对应的读取方法
import numpy as np1.第一种
保存:
#第一种
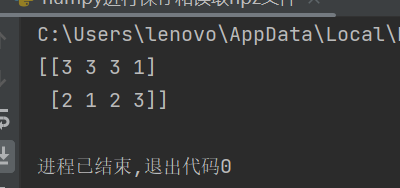
a = np.random.randint(5, size=(2, 4)) #随机生成2行4列的数据,数据值为0~5之间
np.save('test.npy', a)
读取:
b = np.load('test.npy')
print(b)结果
2.第二种
保存:
a = np.random.randint(0, 10, (3,), dtype='int')
b = np.random.randint(0, 10, (3,), dtype='int')
c = np.random.randint(0, 10, (3,), dtype='int')
np.savez('test.npz', file1 = a, file2 = b, file3 = c) #压缩存储数组,并给数组分别命名读取:
data = np.load('test.npz')
print(data.files)结果:
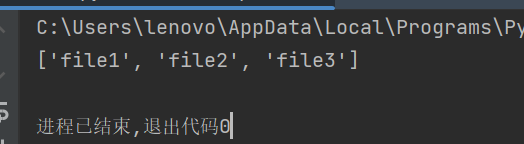
读取具体内容:
data = np.load('test.npz')
aa = data[data.files[0]]
print(aa)结果:
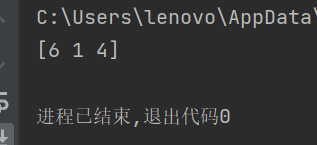
三、拓展
其实我们使用的输入法,当我们输入一个词后后面后陆续出来我们可能会用到的词。输入法原理也是一样的,只不过是输入法不是上下文,而是根据前文预测下一个词,自然语言联想系统。
实际上换汤不换药,基本原理都是一样的
学要修改的最重要的地方就是data这里,因为我们要获取的是前文。
data = [] # 获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(len(raw_text) - CONTEXT_SIZE):#(2,60),从第三个值开始预测
context = raw_text[i:i + CONTEXT_SIZE] # 前CONTEXT_SIZE个词
target = raw_text[i + CONTEXT_SIZE] # 下一个词
data.append((context, target))
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 37
37 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)