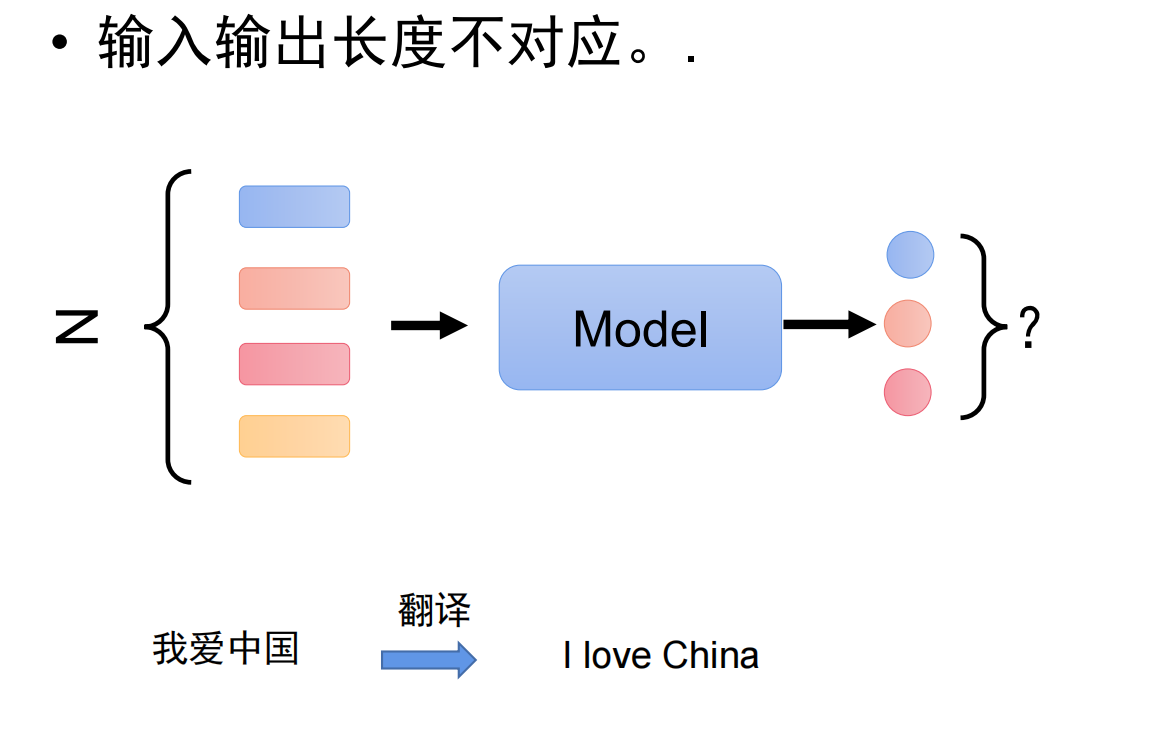
9生成任务&大模型
| 输入 | 输出 | |
| 回归任务 | 向量 | 值 |
| 分类任务 | 图片 | 类别 |
| 序列 | 类别 | |
| 生成任务 | 序列 | 序列 |
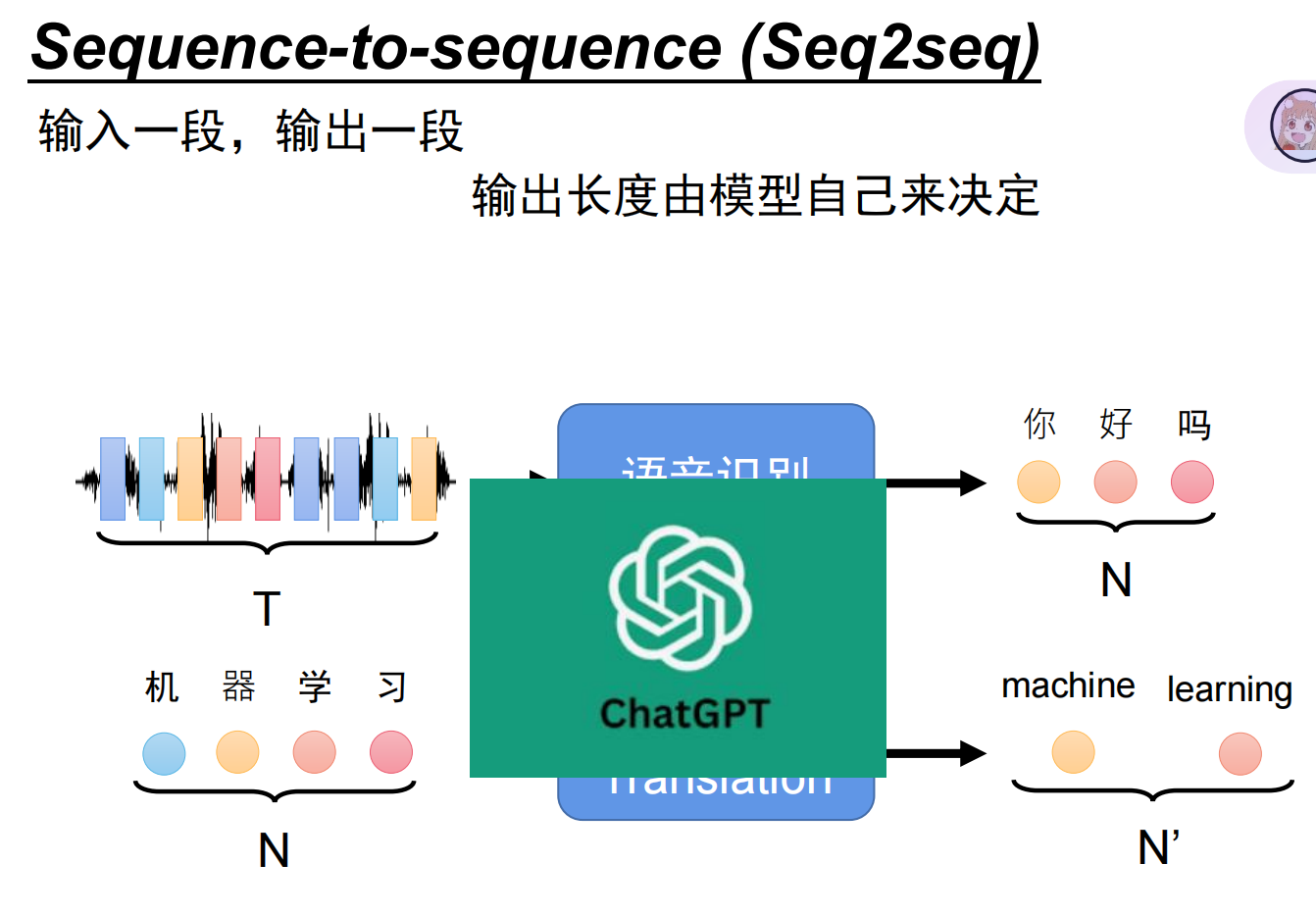
不同 NLP 任务的输入输出形式:
| 任务类型 | 输入形式 | 输出形式 | 示例(输入 -> 输出) |
|---|---|---|---|
| 文本分类 | 一个文本序列 | 一个类别标签 | "这部电影太棒了!" -> "正面" |
| 文本生成 | 一个文本序列(上文) | 一个文本序列(下文) | "中国的首都是" -> "北京" |
| 序列标注 | 一个文本序列 | 等长的标签序列 | "小明在北京上学" -> ["B-PER","I-PER","O","B-LOC","O","O"] |
| 句子对任务 | 两个文本序列 | 一个类别标签或分数 | ["苹果好吃","我不喜欢苹果"] -> "矛盾" |
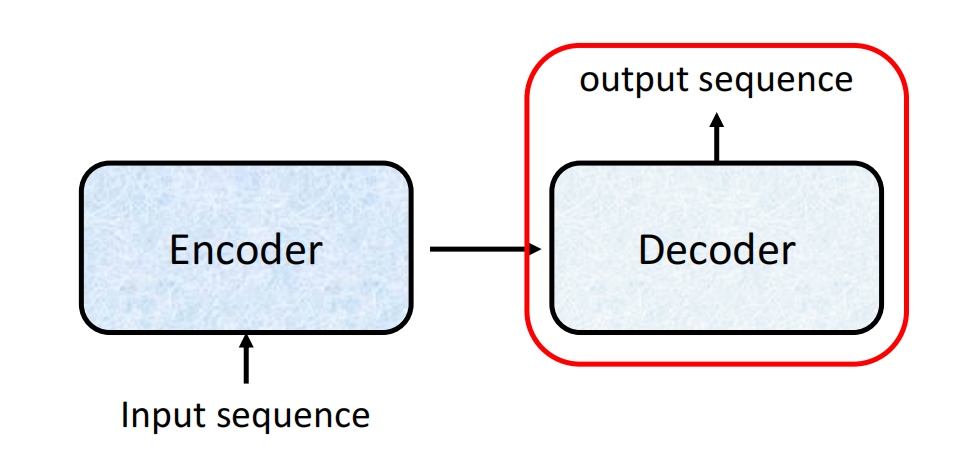
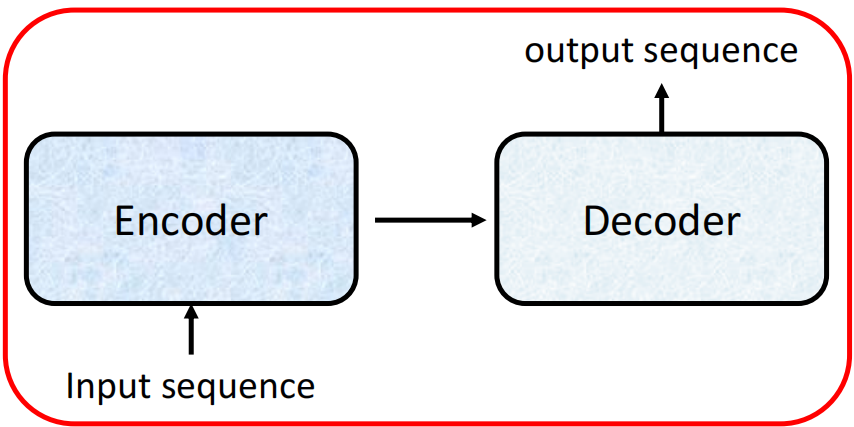
Seq2Seq(Sequence-to-Sequence) 是一种将一个序列转换为另一个序列的通用模型架构。它最初为解决机器翻译问题而提出,后来被广泛应用于文本摘要、对话生成、语音识别、代码生成等众多任务。
Seq2Seq 的核心思想是:使用一个编码器(Encoder) 将输入序列编码为一个固定长度的上下文向量(Context Vector),然后使用一个解码器(Decoder) 从这个上下文向量中逐步生成输出序列。
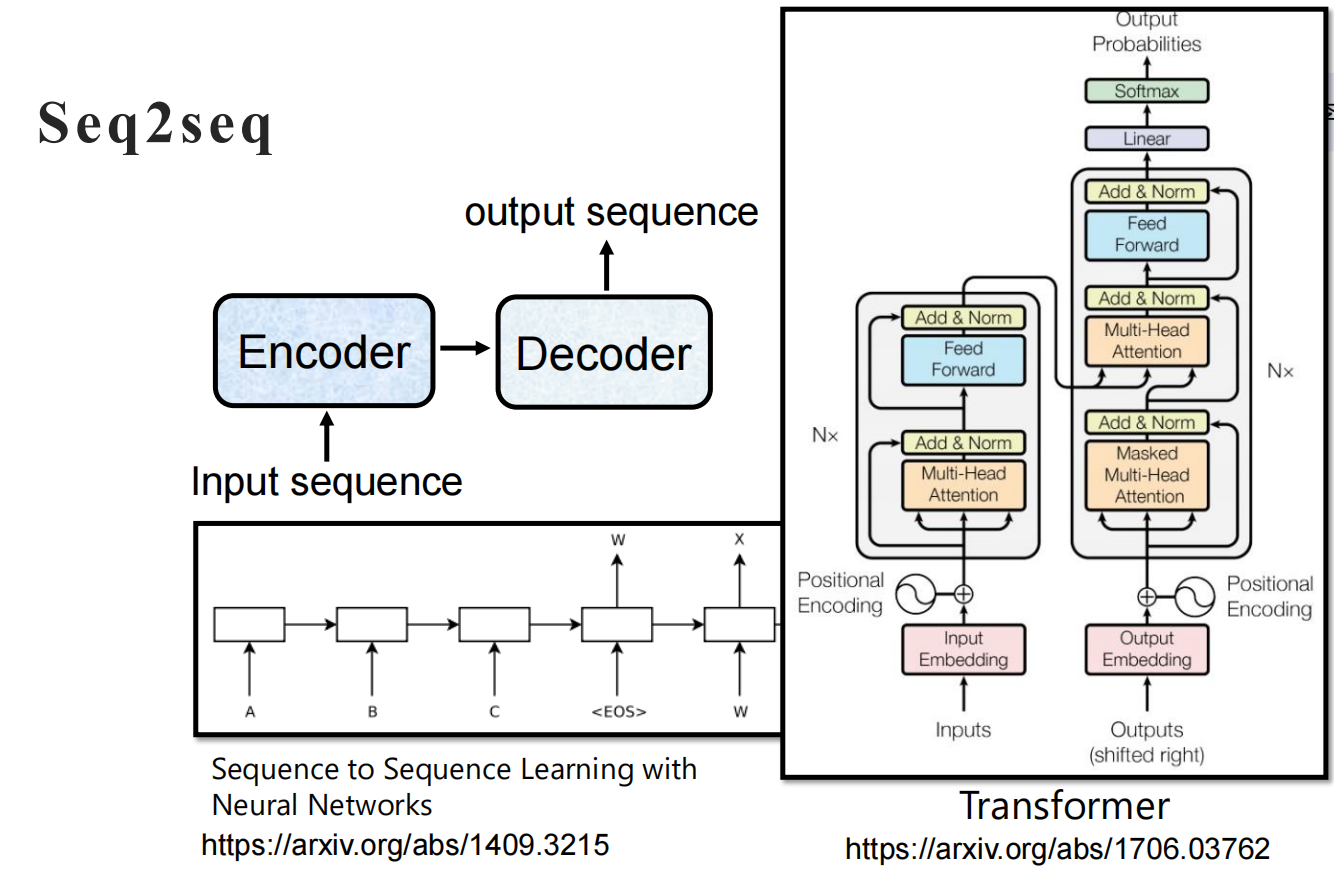
输入序列: [x1, x2, x3, ..., xn]
↓
┌────────────┐
│ 编码器 │ (RNN/LSTM/Transformer)
└────────────┘
↓
上下文向量 (Context Vector)
↓
┌────────────┐
│ 解码器 │ (RNN/LSTM/Transformer)
└────────────┘
↓
输出序列: [y1, y2, y3, ..., ym]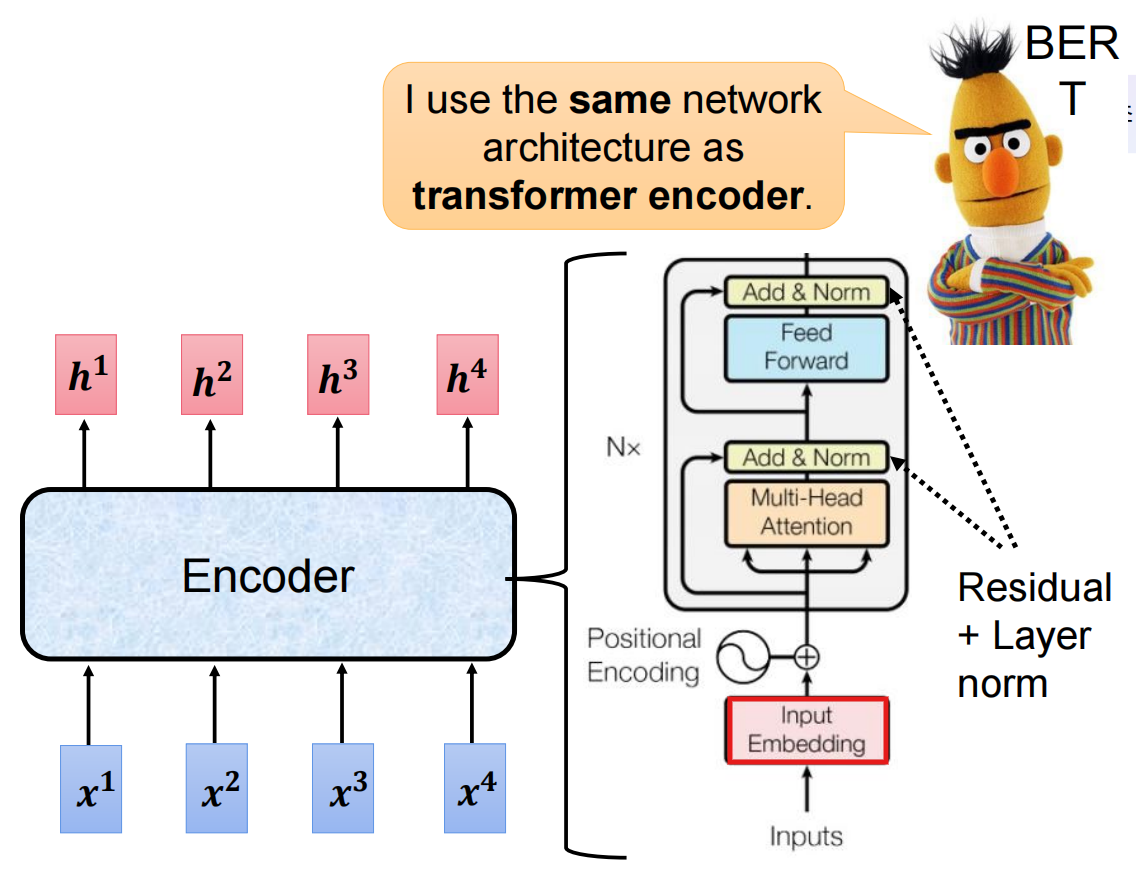
Decoder
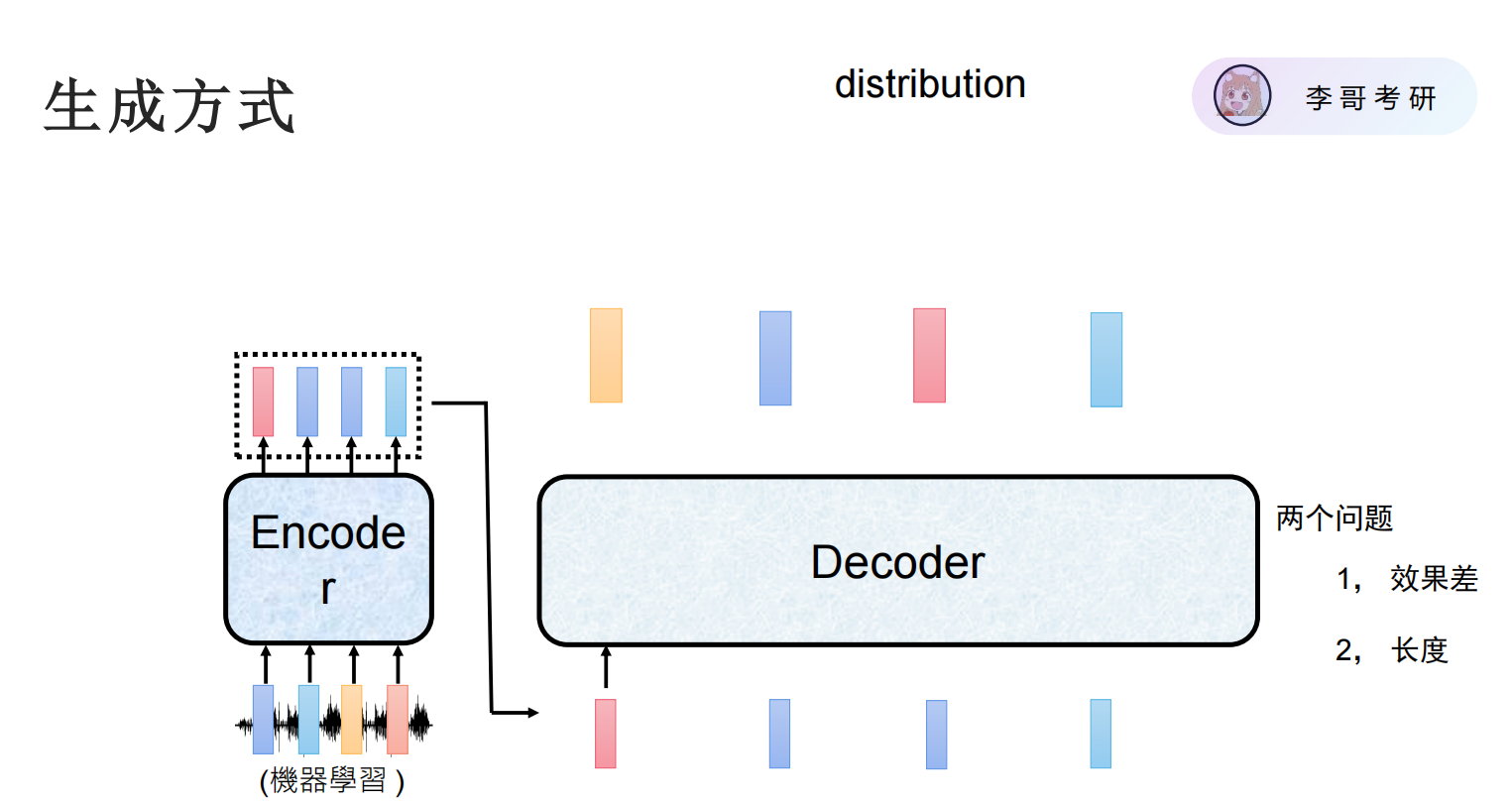
整个过程可以分为两大步:
-
编码器:理解输入,形成“语义精髓”
-
输入:原始文本序列,例如法语句子
"Je t'aime"。 -
过程:编码器(通常是一个 RNN、LSTM 或 Transformer 编码器)逐个词地读取这个句子。它不仅仅是看到单个的词,更重要的是捕捉词与词之间的顺序和依赖关系,从而理解整个句子的含义。
-
输出:编码器将整个句子的“语义精髓”浓缩成一个或多个上下文向量。这个向量是编码器对输入信息的最终总结,包含了生成目标句子所需的所有关键信息。
-
-
解码器:逐词生成,将“精髓”展开为文字
-
输入:它接收两个东西——一是来自编码器的上下文向量(即句子的“语义精髓”),二是它自己在上一个时间步生成的词。
-
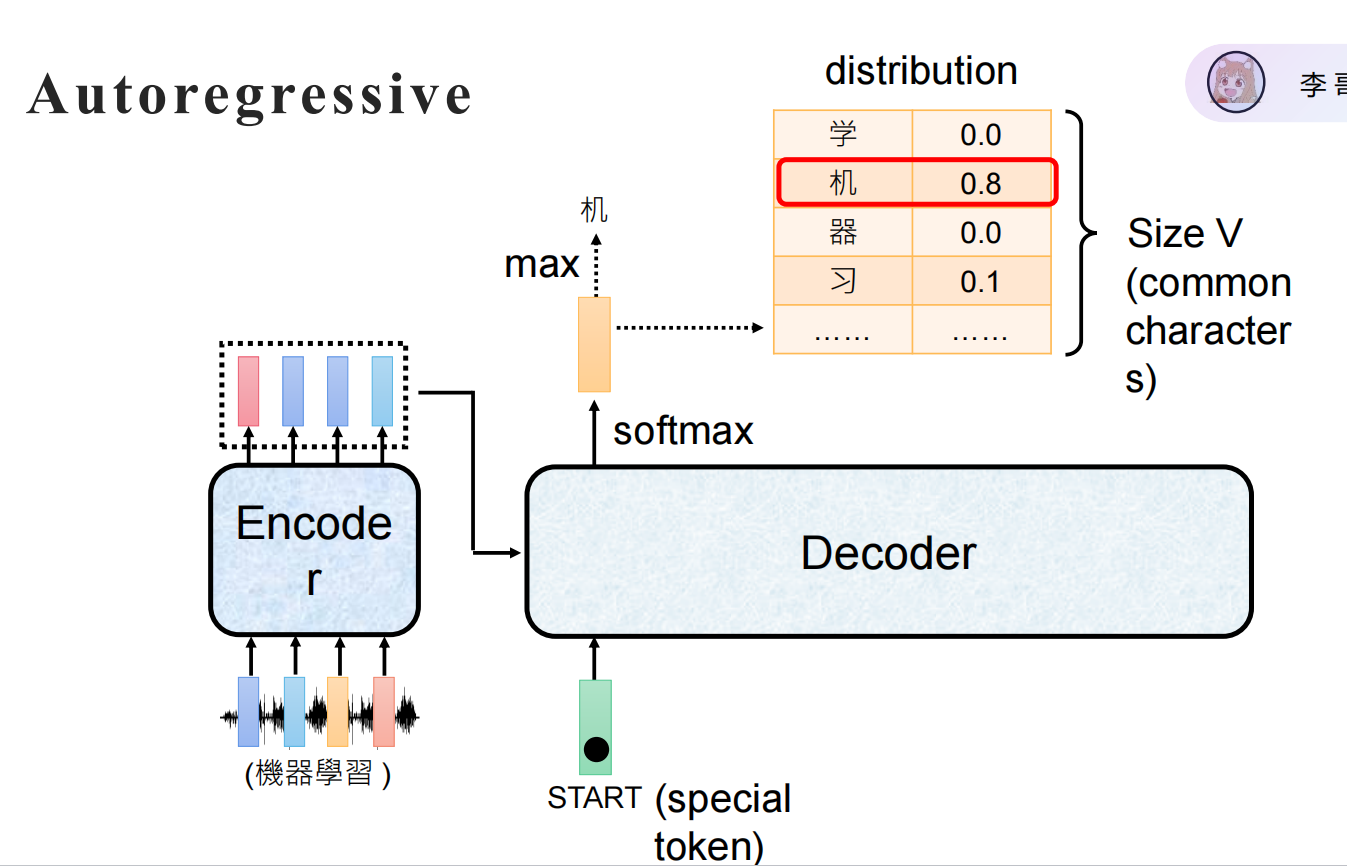
过程:解码器是一个自回归模型,这意味着它是一个词一个词地生成句子的。
-
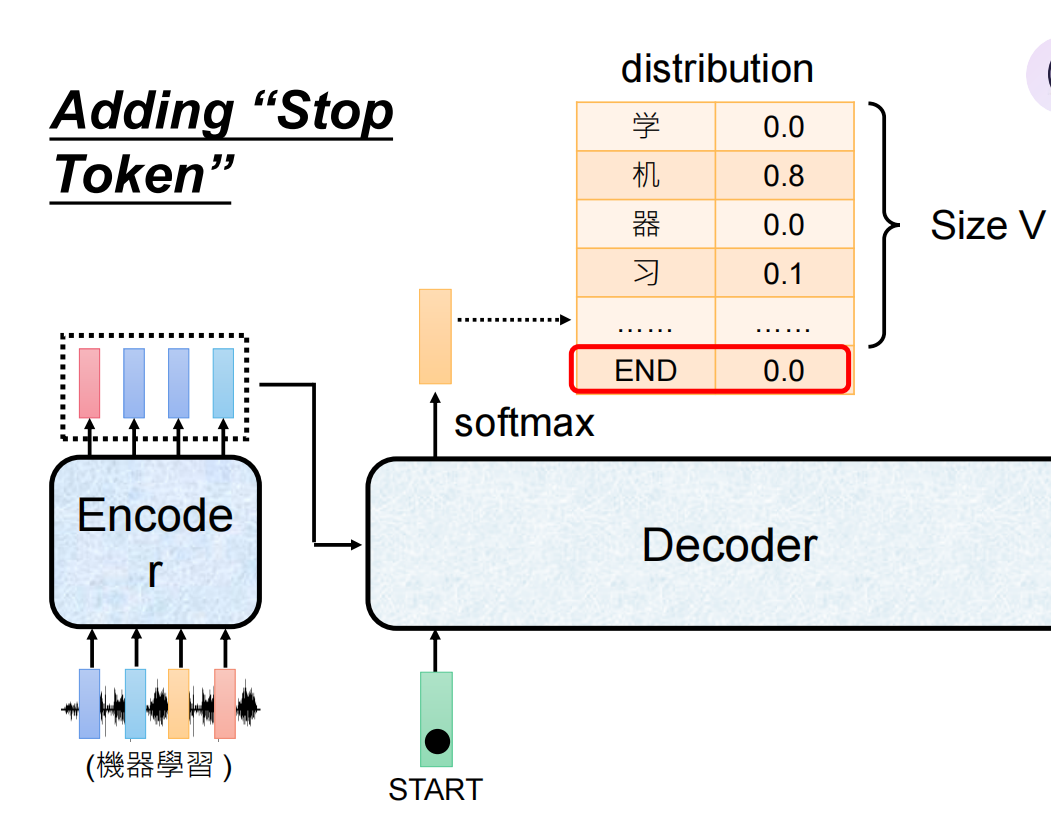
第一步:解码器接收一个特殊的开始符
<sos>(start of sequence) 和上下文向量,预测出第一个最可能的目标词,比如英文的"I"。 -
第二步:解码器将第一步生成的
"I"作为输入,再次结合上下文向量,预测出第二个词"love"。 -
第三步:将
"love"作为输入,预测出第三个词"you"。 -
最后一步:当解码器预测出特殊的结束符
<eos>(end of sequence) 时,生成过程停止。
-
-
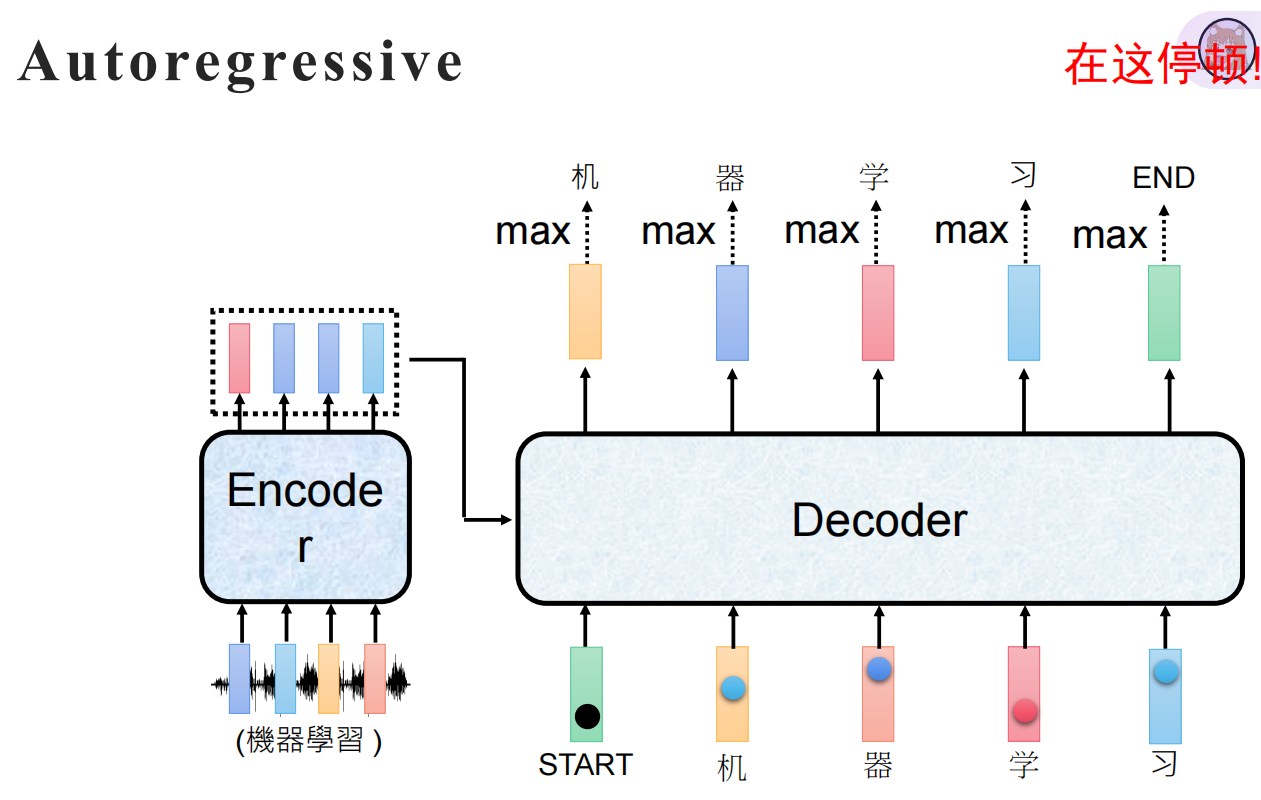
自回归(Autoregressive) 是一种在时间序列预测和自然语言生成中广泛使用的建模方法。它的核心思想是:用过去的值来预测未来的值。在自然语言处理中,这意味着模型根据已经生成的词来预测下一个词。
“自回归”这个名字源于统计学和时间序列分析:
-
自(Auto):表示自己
-
回归(Regression):表示用过去预测未来
在推理(生成)时,必须逐个词生成,因为未来的词还不知道:
step1: 输入 ["<sos>"] → 输出 ["我"]
step2: 输入 ["<sos>", "我"] → 输出 ["爱"]
step3: 输入 ["<sos>", "我", "爱"] → 输出 ["NLP"]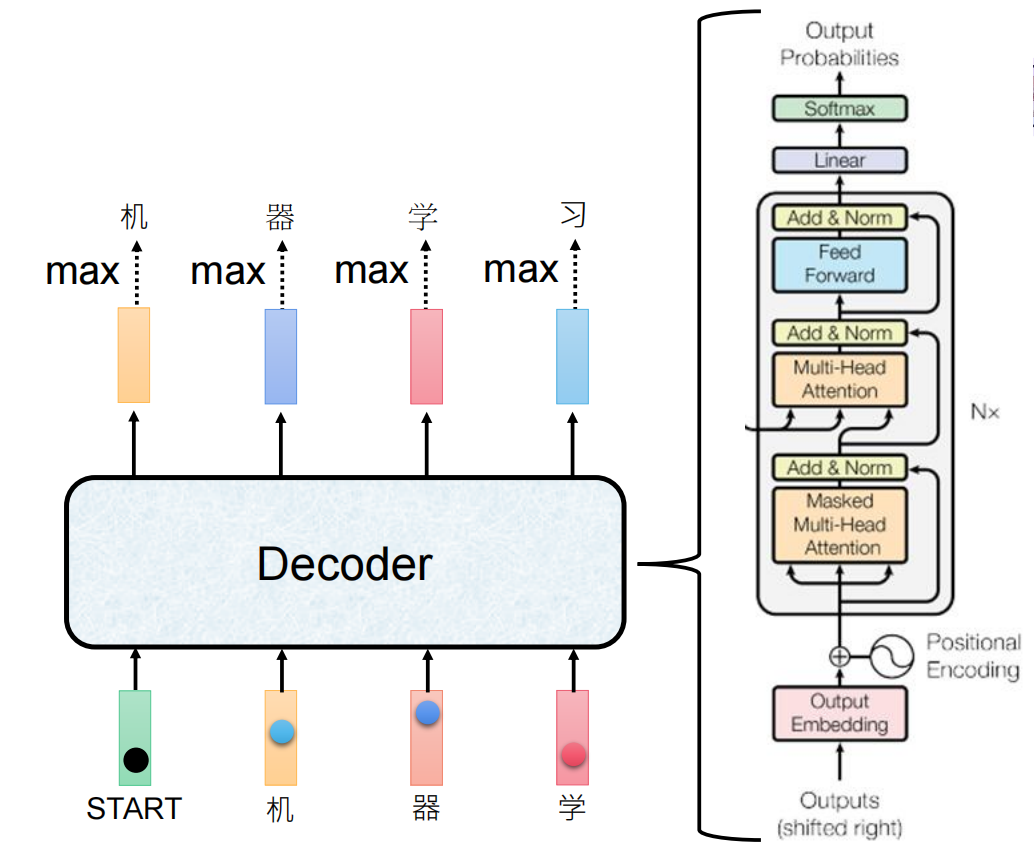
| 维度 | 编码器(Encoder) | 解码器(Decoder) |
|---|---|---|
| 主要任务 | 理解输入序列,提取特征 | 根据理解生成输出序列 |
| 输入 | 原始序列(如源语言句子) | 目标序列(已生成部分)及编码器输出 |
| 输出 | 输入序列的上下文表示 | 下一个词元的概率分布 |
| 注意力机制 | 可看到整个输入序列(双向) | 只能看到已生成部分(单向/因果掩码) |
| 典型应用 | 文本分类、语义理解 | 文本生成、机器翻译 |
| 代表模型 | BERT、RoBERTa | GPT、LLaMA |
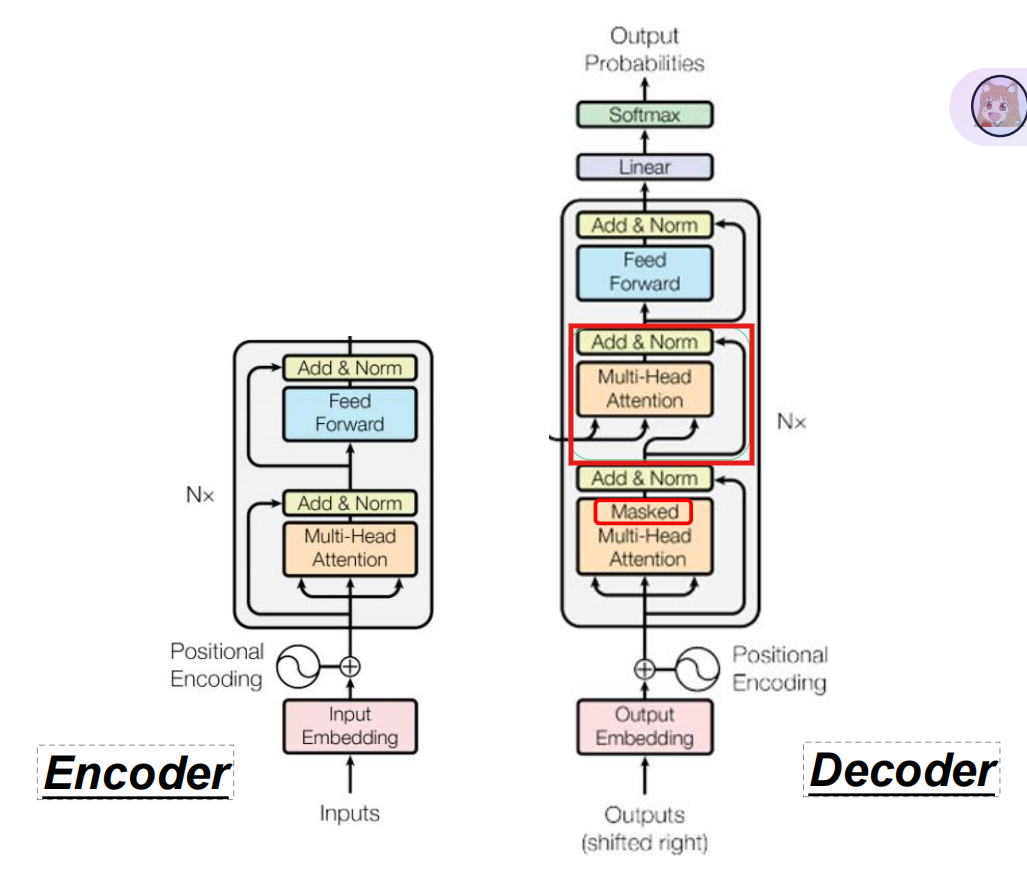
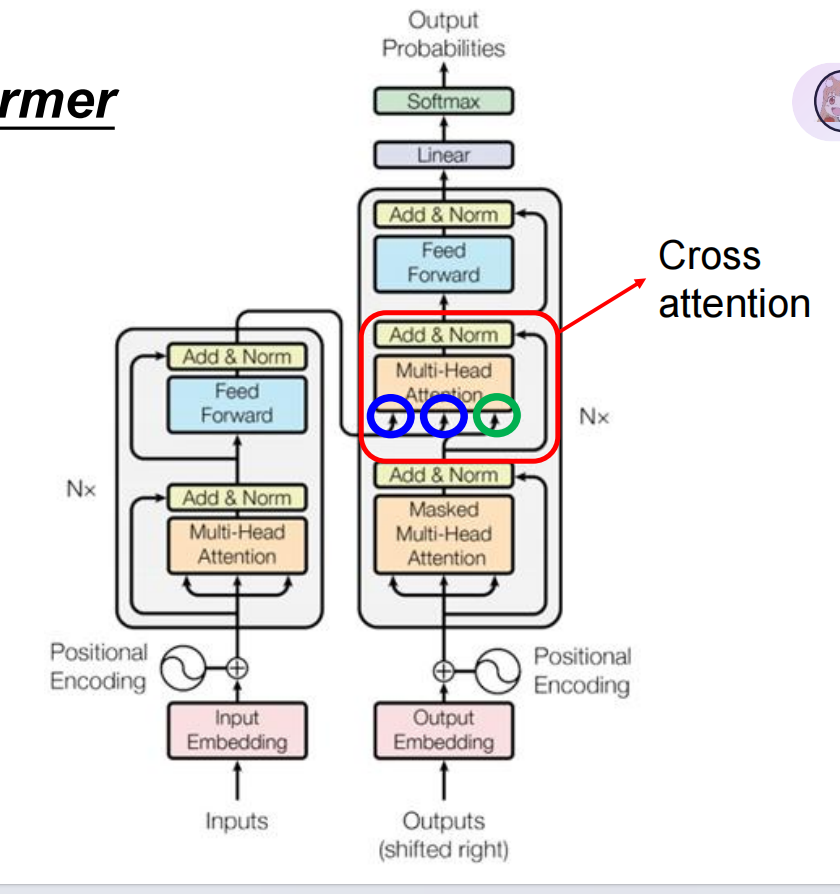
编码器层结构:
输入 → 多头自注意力 → 残差&层归一 → 前馈网络 → 残差&层归一 → 输出
解码器层结构:
输入 → 掩码多头自注意力 → 残差&层归一
→ 编码器-解码器注意力 → 残差&层归一
→ 前馈网络 → 残差&层归一 → 输出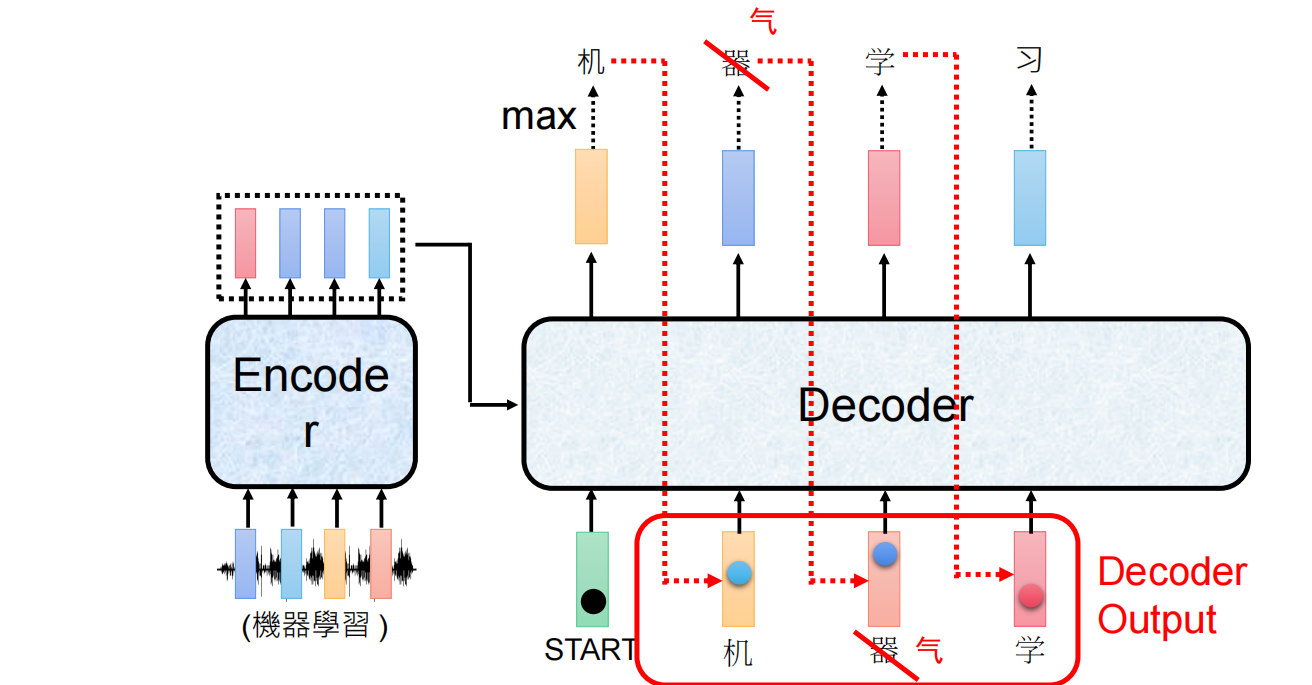
问题:一步错步步错,只能串行不能并行(慢)
优点
-
生成质量高:每一步都基于真实的历史,能捕捉复杂的依赖关系。
-
概率解释清晰:可以精确计算序列的概率。
-
灵活性:可以处理变长序列。
缺点
-
生成速度慢:必须串行生成,无法并行。
-
误差累积:如果某一步预测错误,错误会传播到后续步骤。
-
训练推理不一致:训练时用教师强制(看到真实历史),推理时看到的是自己生成的历史,可能存在差异。
| 特性 | 自回归模型 | 非自回归模型 |
|---|---|---|
| 生成方式 | 逐个词生成,每一步依赖上一步输出 | 一次性生成整个序列 |
| 速度 | 慢(串行计算) | 快(并行计算) |
| 质量 | 通常更高,能捕捉长距离依赖 | 可能稍差,难以处理依赖关系 |
| 典型模型 | GPT、LSTM 语言模型 |
部分非自回归翻译模型(如 NAT) |
Masked Self-attention
掩码自注意力(Masked Self-Attention) 是 Transformer 解码器中的核心机制,它通过在自注意力计算中引入掩码,确保模型在生成每个位置的输出时只能看到当前位置之前的信息,而无法看到未来的信息。这是实现自回归生成的关键技术。
| 特性 | 标准自注意力 | 掩码自注意力 |
|---|---|---|
| 可见范围 | 整个序列 | 当前位置及之前的位置 |
| 掩码矩阵 | 无 | 上三角为 -∞ 的矩阵 |
| 适用场景 | 编码器、非自回归任务 | 解码器、自回归生成任务 |
| 典型模型 | BERT 的注意力层 | GPT 的注意力层 |
| 计算复杂度 | O(n²) | O(n²)(相同,但多一步掩码) |
在自回归生成任务中(如文本生成、机器翻译的解码阶段),模型需要逐个词地生成输出序列。当预测第 t 个词时,模型只能依赖已经生成的词(位置 1 到 t-1),而不能看到未来的词(位置 t 及以后)。如果不加掩码,自注意力会让每个位置都能看到整个序列,这就相当于“作弊”——模型可以根据未来的词来预测当前词,这在真实生成场景中是不可能的。
4阶掩码矩阵(下三角矩阵)
位置: 1 2 3 4
1: [ 0, -∞, -∞, -∞ ]
2: [ 0, 0, -∞, -∞ ]
3: [ 0, 0, 0, -∞ ]
4: [ 0, 0, 0, 0 ]解码器输入
↓
[掩码多头自注意力] ← 这里使用因果掩码,防止看到未来
↓
[残差连接 + 层归一化]
↓
[编码器-解码器注意力] ← 这里无掩码,可以关注编码器所有输出
↓
[残差连接 + 层归一化]
↓
[前馈网络]
↓
[残差连接 + 层归一化]
↓
解码器输出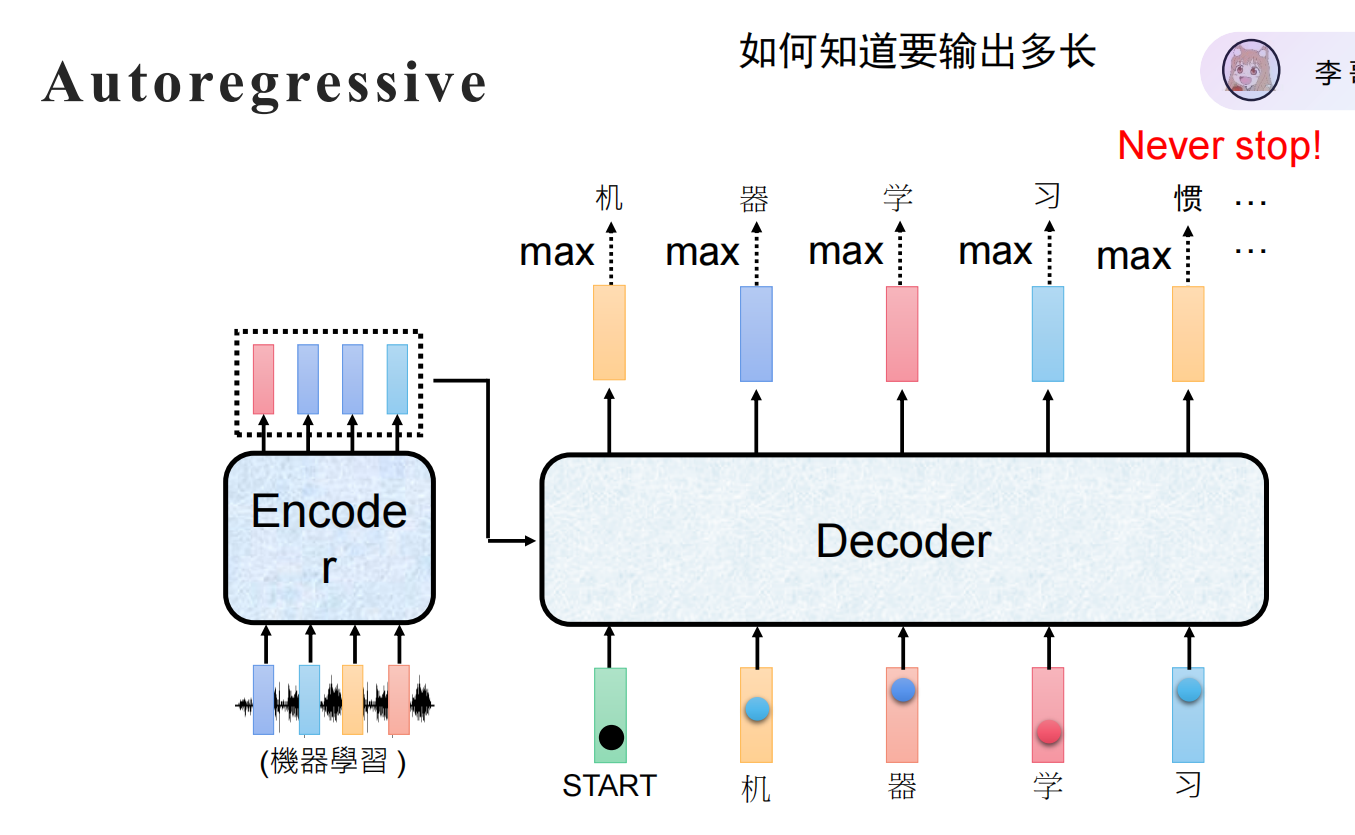
Cross-Attention
交叉注意力(Cross-Attention) 是 Transformer 解码器中的一个关键子层,它允许解码器在生成每个目标词时,动态地关注编码器输出的所有位置,从而获取输入序列的相关信息。它是连接编码器和解码器的桥梁,也是 Seq2Seq 模型能够有效工作的核心。
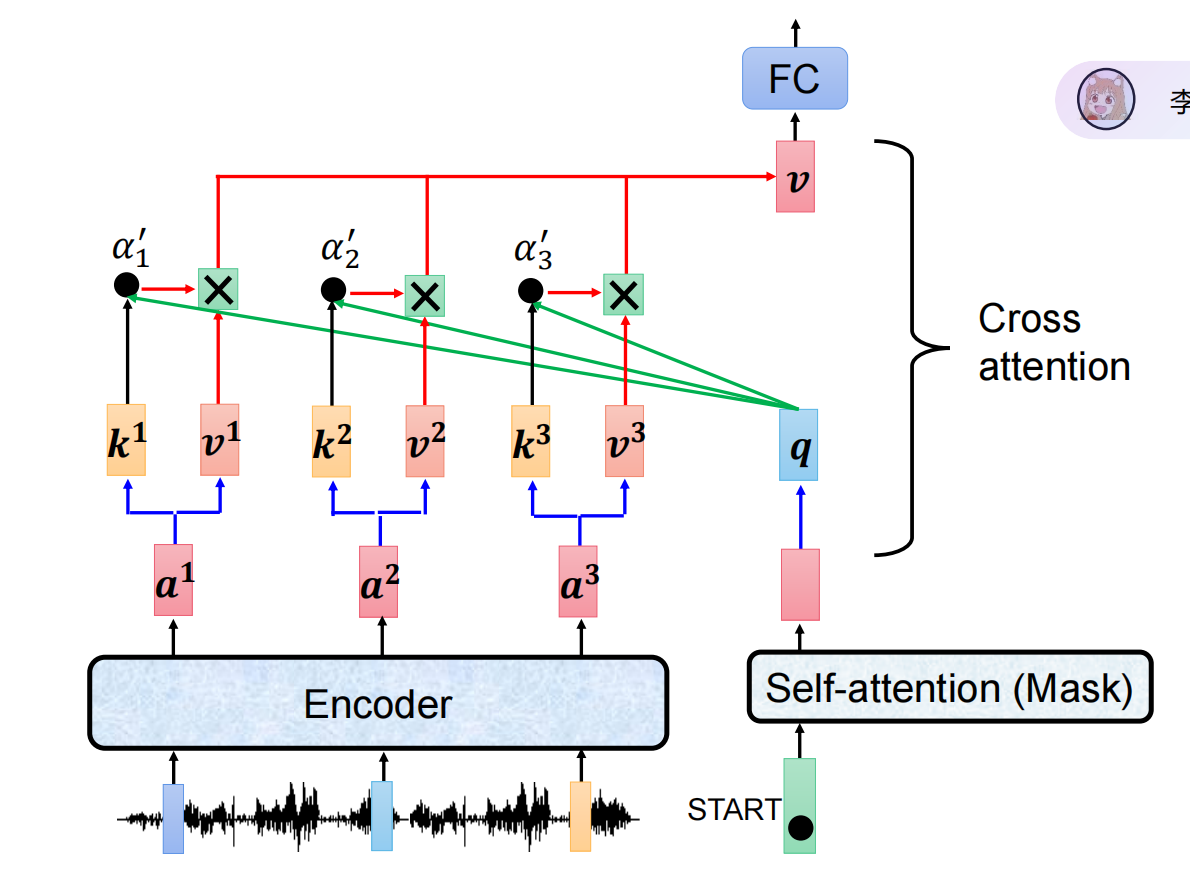
交叉注意力与自注意力在计算上非常相似,唯一的区别在于 Query、Key、Value 的来源不同:
| 组件 | 自注意力 | 交叉注意力 |
|---|---|---|
| Query | 来自当前层输入(同一序列) | 来自解码器上一层的输出 |
| Key | 来自当前层输入 | 来自编码器的输出 |
| Value | 来自当前层输入 | 来自编码器的输出 |
-
解码器 的上一子层输出作为 Query。
-
编码器 的最终输出作为 Key 和 Value。
-
计算 Query 与所有 Key 的注意力分数,得到每个编码器位置的权重。
-
用这些权重对 Value 加权求和,得到当前解码器位置关注的上下文向量。
-
这个上下文向量与解码器的输入一起用于后续计算。
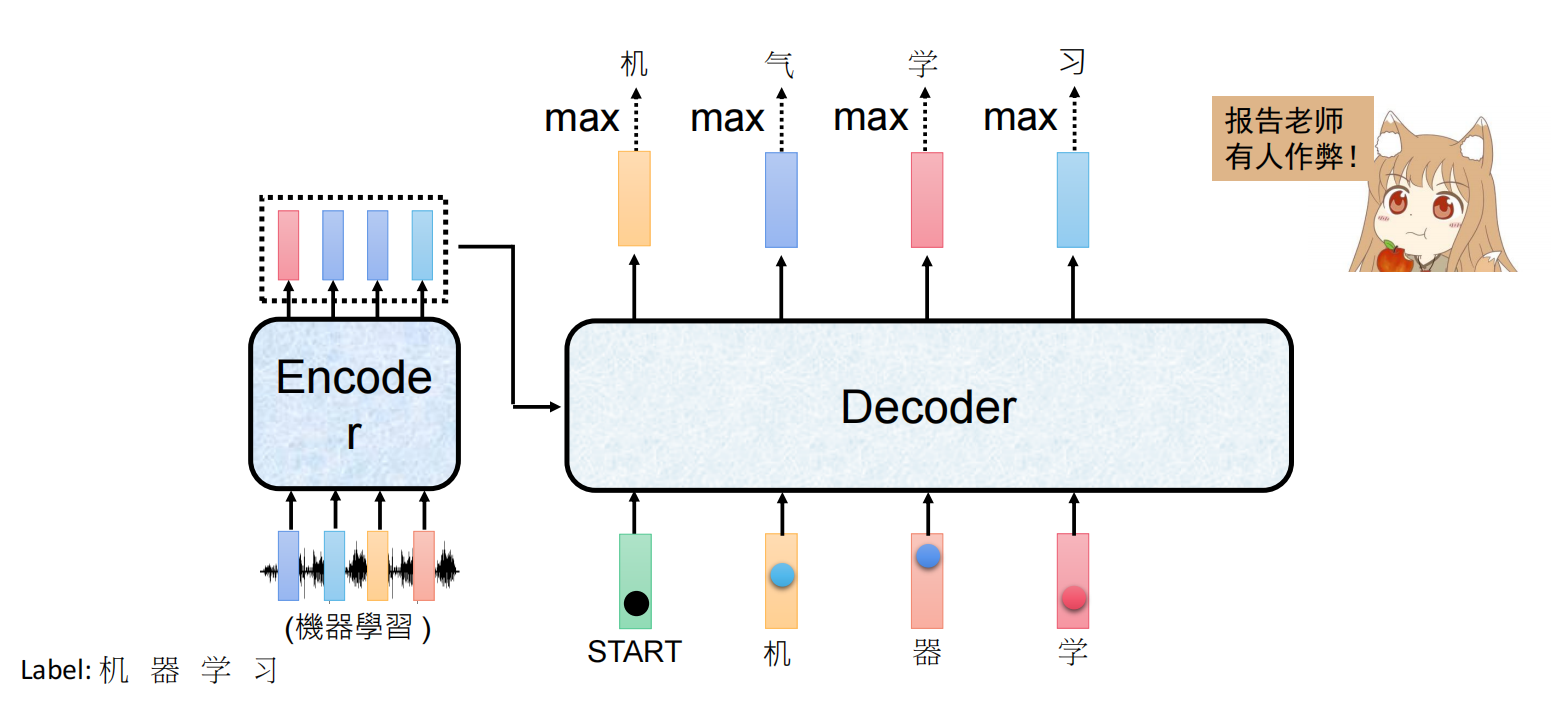
生成任务Training
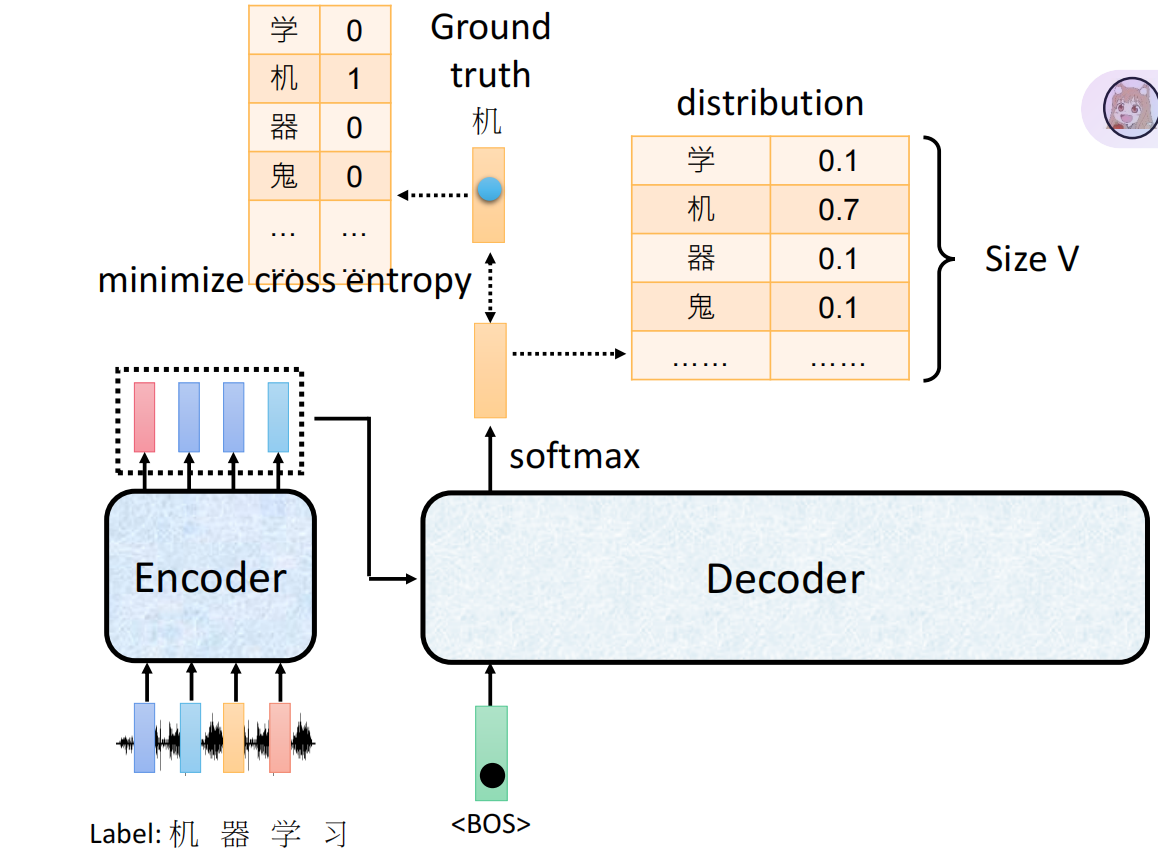
交叉熵损失函数
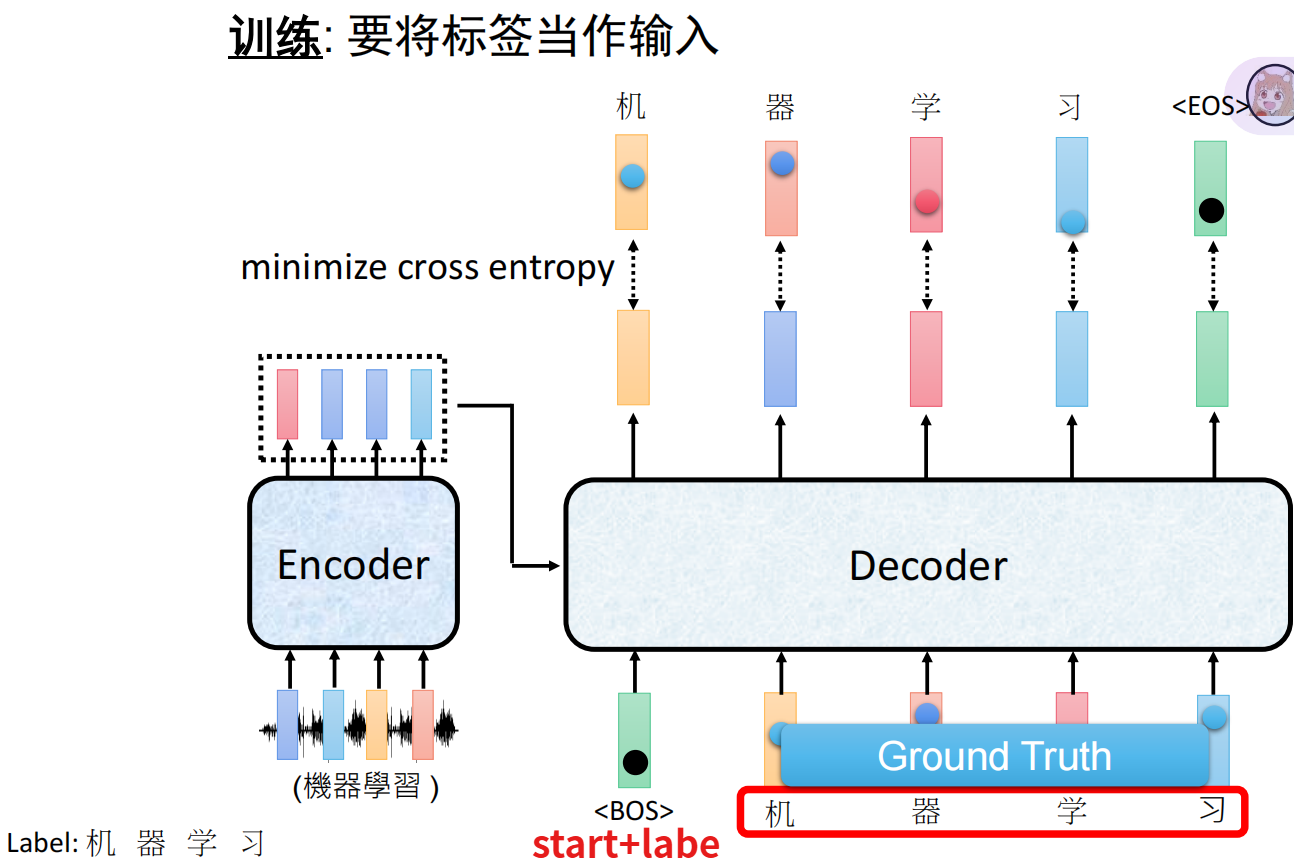
输入:start+label
输出:label+end
输入长度=输出长度
计算输出与真实label+end之间的损失
ground truth真实标签
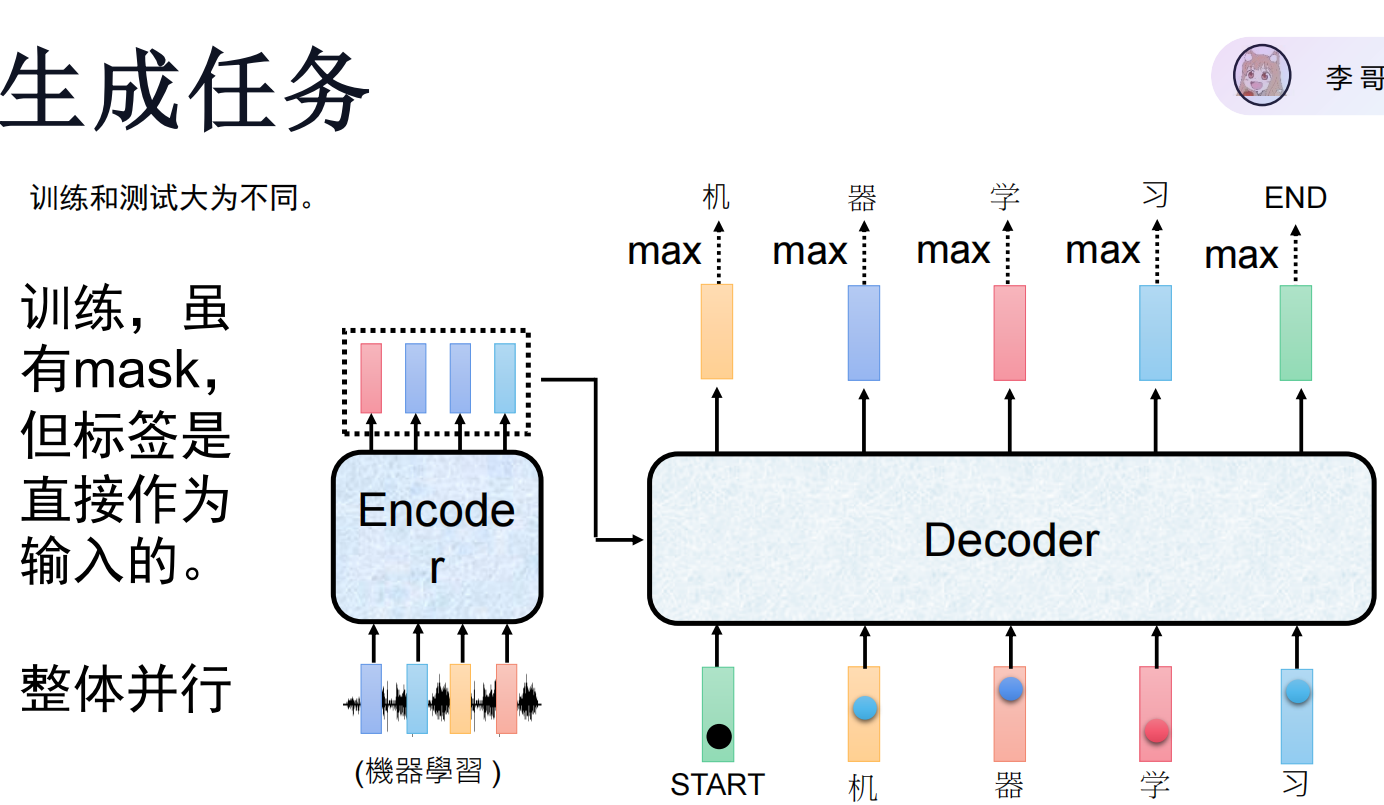
生成任务的推断

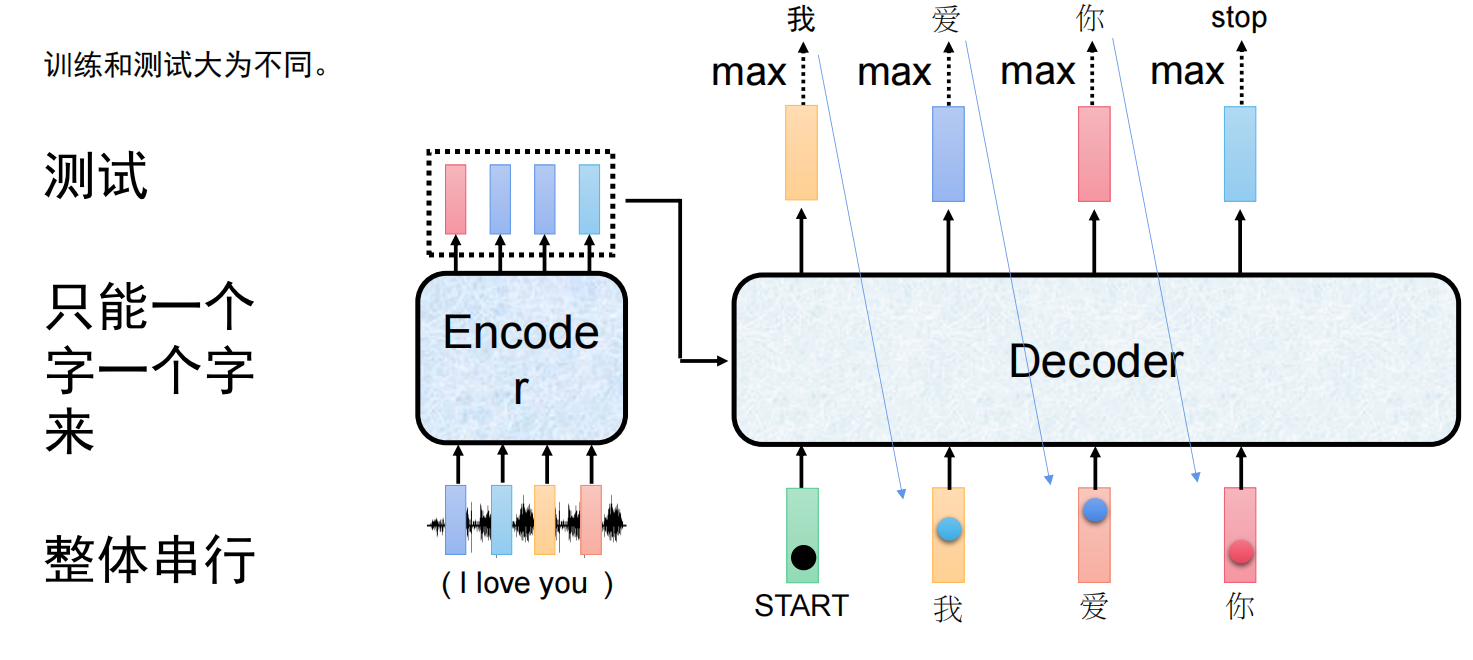
Beam Search
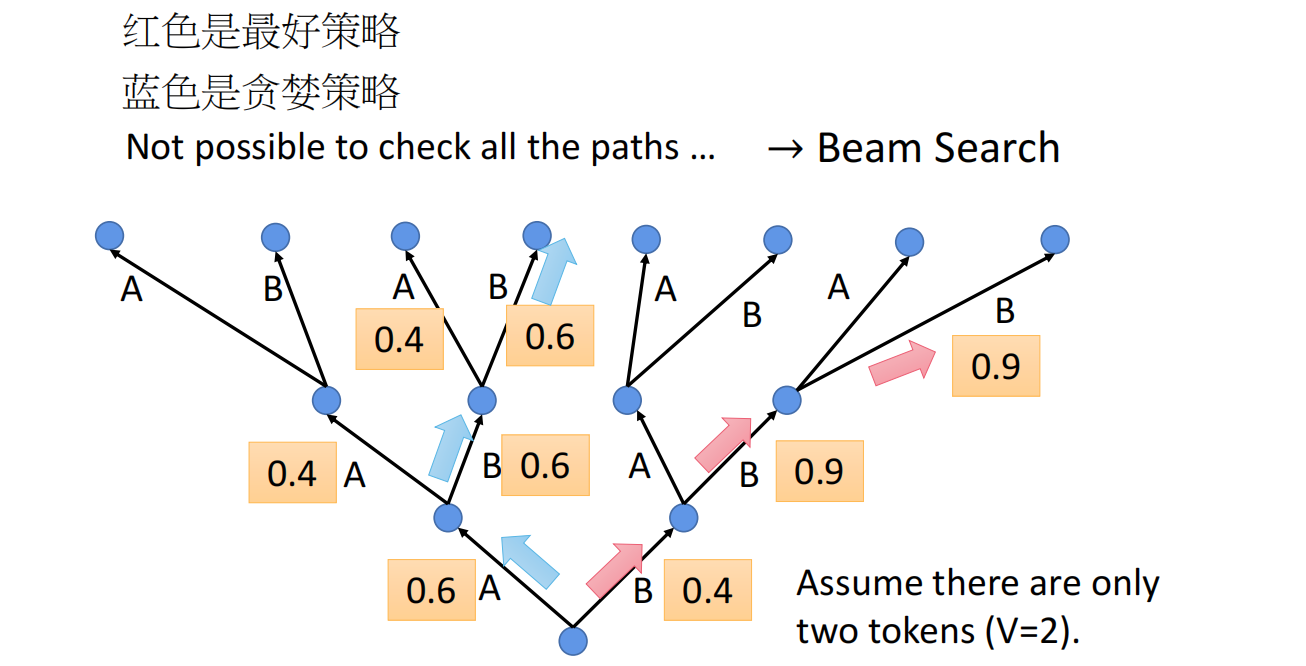
Beam Search(束搜索) 是一种在序列生成任务(如机器翻译、文本摘要、对话生成)中常用的解码策略。它在每个时间步保留多个候选序列(称为“束”),而不是像贪心搜索那样只保留一个最优解,从而在生成质量和计算效率之间取得平衡。
当前候选:
1. "我" (0.4)
- "我 爱" (0.4 × 0.5 = 0.20)
- "我 很" (0.4 × 0.3 = 0.12)
2. "爱" (0.3)
- "爱 你" (0.3 × 0.6 = 0.18)
- "爱 我" (0.3 × 0.2 = 0.06)
保留 top 2: ["我 爱"(0.20), "爱 你"(0.18)]| 束宽 | 优点 | 缺点 |
|---|---|---|
| 小 (如 1) | 速度快,计算量小 | 易陷入局部最优,生成质量可能较差 |
| 中 (如 4-10) | 平衡质量和速度,多数任务常用 | 计算量随 k 线性增长 |
| 大 (如 50+) | 更可能找到全局最优 | 计算量巨大,收益递减,可能引入噪声 |
贪婪策略
贪心搜索在每个时间步只选择概率最高的词作为输出。虽然简单高效,但它容易陷入局部最优——当前的最佳选择可能导致后续无法生成整体最优的句子。
例子:翻译 "I love NLP"
-
贪心可能选择概率最高的第一个词 "I"(没问题)
-
但第二个词,可能 "really" 概率比 "love" 略低,但若选了 "really",后面可能生成不通顺的句子
-
贪心无法回头修正

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)