【瑞萨AI挑战赛】基于RA8P1 Ethos-U55 NPU, 部署YOLO-Fastest驾驶员困意识别模型
在之前的文章中介绍了如何调用用Google Colab的免费云端GPU资源,对YOLO-Fastest模型进行训练,在这里补充一下训练模型之前需要做好的数据集格式处理,以及得到模型数据之后,如何将其部署到RA8P1 RT-Thread Titan Board开发板的Ethos-U55 NPU上来运行。
数据集格式整理
这里使用的数据集是Robofolw上的Driver Drowsiness Detection Computer Vision Model数据集,链接:https://universe.roboflow.com/tesi-jotog/driver-drowsiness-detection-7fvkf
虽然说下载数据集时可以选择基于多种不同YOLO模型的格式,但是实际下载下来的仍是Pascal VOC格式。和YOLO-Fastest模型所需要的文件路径还是存在差异。即标注信息均记录在_annotations.txt文件内,而没有按照YOLO格式分为一个个和图片名称对应的单独.txt文件。
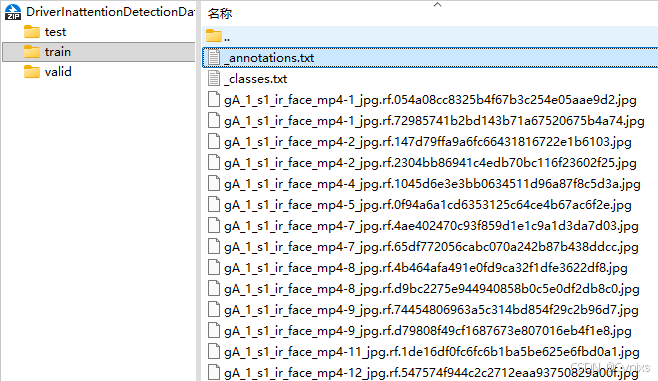
可以使用下面的Python脚本转换数据集的格式:
"""
Pascal VOC格式转YOLO格式脚本
原始格式: 文件名.jpg x_min,y_min,x_max,y_max,class_id
YOLO格式: class_id x_center y_center width height (归一化坐标)
"""
import os
import glob
from PIL import Image
import argparse
def convert_voc_to_yolo(voc_file_path, images_dir, output_dir, class_list_file=None):
"""
将Pascal VOC格式标注文件转换为YOLO格式
参数:
voc_file_path: VOC格式标注文件路径(如:_annotations.txt)
images_dir: 图片文件所在目录
output_dir: YOLO格式标注文件输出目录
class_list_file: 可选的类别名称文件路径(每行一个类别名)
"""
# 读取类别映射(如果有的话)
class_map = {}
if class_list_file and os.path.exists(class_list_file):
with open(class_list_file, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
class_name = line.strip()
if class_name:
class_map[class_name] = idx
print(f"已加载 {len(class_map)} 个类别")
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 统计信息
total_boxes = 0
processed_images = 0
skipped_images = 0
# 读取VOC标注文件
with open(voc_file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
print(f"共读取 {len(lines)} 条标注记录")
# 按图片名分组标注
annotations_by_image = {}
for line in lines:
line = line.strip()
if not line:
continue
parts = line.split()
if len(parts) < 2:
continue
image_name = parts[0]
bbox_info = parts[1]
# 解析边界框信息
bbox_parts = bbox_info.split(',')
if len(bbox_parts) < 5:
continue
x_min = int(bbox_parts[0])
y_min = int(bbox_parts[1])
x_max = int(bbox_parts[2])
y_max = int(bbox_parts[3])
class_id = int(bbox_parts[4])
if image_name not in annotations_by_image:
annotations_by_image[image_name] = []
annotations_by_image[image_name].append({
'x_min': x_min,
'y_min': y_min,
'x_max': x_max,
'y_max': y_max,
'class_id': class_id
})
print(f"共发现 {len(annotations_by_image)} 张图片有标注")
# 为每张图片创建YOLO格式标注文件
for image_name, bboxes in annotations_by_image.items():
# 构建图片完整路径
image_path = os.path.join(images_dir, image_name)
# 检查图片是否存在
if not os.path.exists(image_path):
print(f"警告: 图片不存在,跳过 {image_name}")
skipped_images += 1
continue
try:
# 获取图片尺寸
with Image.open(image_path) as img:
img_width, img_height = img.size
# 创建YOLO格式标注文件
txt_filename = os.path.splitext(image_name)[0] + '.txt'
txt_path = os.path.join(output_dir, txt_filename)
with open(txt_path, 'w', encoding='utf-8') as txt_file:
for bbox in bboxes:
# 计算归一化坐标
x_center = (bbox['x_min'] + bbox['x_max']) / (2.0 * img_width)
y_center = (bbox['y_min'] + bbox['y_max']) / (2.0 * img_height)
width = (bbox['x_max'] - bbox['x_min']) / img_width
height = (bbox['y_max'] - bbox['y_min']) / img_height
# 确保坐标在0-1范围内
x_center = max(0.0, min(1.0, x_center))
y_center = max(0.0, min(1.0, y_center))
width = max(0.0, min(1.0, width))
height = max(0.0, min(1.0, height))
# 写入YOLO格式行
yolo_line = f"{bbox['class_id']} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n"
txt_file.write(yolo_line)
total_boxes += 1
processed_images += 1
except Exception as e:
print(f"错误: 处理图片 {image_name} 时出错: {str(e)}")
skipped_images += 1
# 生成类别文件(如果未提供)
if not class_list_file and annotations_by_image:
# 从标注中提取所有类别ID
all_class_ids = set()
for bboxes in annotations_by_image.values():
for bbox in bboxes:
all_class_ids.add(bbox['class_id'])
# 排序类别ID
sorted_class_ids = sorted(list(all_class_ids))
# 生成classes.txt文件
classes_path = os.path.join(output_dir, 'classes.txt')
with open(classes_path, 'w', encoding='utf-8') as f:
for class_id in sorted_class_ids:
f.write(f"{class_id}\n")
print(f"已生成类别文件: {classes_path}")
print(f"发现类别ID: {sorted_class_ids}")
# 打印统计信息
print("\n" + "="*50)
print("转换完成!")
print(f"成功处理图片数: {processed_images}")
print(f"跳过的图片数: {skipped_images}")
print(f"总边界框数: {total_boxes}")
print(f"YOLO标注文件保存至: {output_dir}")
print("="*50)
def main():
parser = argparse.ArgumentParser(description='将Pascal VOC格式转换为YOLO格式')
parser.add_argument('--voc_file', required=True, help='VOC格式标注文件路径')
parser.add_argument('--images_dir', required=True, help='图片文件目录')
parser.add_argument('--output_dir', required=True, help='YOLO标注输出目录')
parser.add_argument('--class_list', help='类别名称文件(可选)')
args = parser.parse_args()
# 执行转换
convert_voc_to_yolo(
voc_file_path=args.voc_file,
images_dir=args.images_dir,
output_dir=args.output_dir,
class_list_file=args.class_list
)
if __name__ == "__main__":
main()而后调用下面的Python命令实现格式转换:
python voc_to_yolo.py --voc_file _annotations.txt --images_dir /path/to/images --output_dir ./yolo_labels运行后的数据集目录结构如下所示,以训练集数据为例:
train/
├── images/ # 原图片目录│ ├── image1.jpg
│ ├── image2.jpg
├── labels/ # YOLO格式标注
│ ├── image1.txt
│ ├── image2.txt
每个图片对应的同文件名.txt标注文件如下:
1 0.4828125 0.565625 0.203125 0.40859375在mydata目录下根据根据当前的训练、验证和测试目录,配置data.yaml文件如下。将图像分类为2类,0表示Drowsiness,1表示Normal:
train: ./mydata/train/images
val: ./mydata/valid/images
test: ./mydata/test/images
nc: 2
names: ['Drowsiness', 'Normal']Colab模型在线训练
最开始选择参考的是RT-Thread官方文章进行部署,文章链接:1 GHz Arm® Cortex®-M85 MCU上部署AI模型https://mp.weixin.qq.com/s/qPou70tl4VqSWP6MhxZVgw![]() https://mp.weixin.qq.com/s/qPou70tl4VqSWP6MhxZVgw
https://mp.weixin.qq.com/s/qPou70tl4VqSWP6MhxZVgw
在将本地将环境部署好之后,由于个人电脑没有Nvidia显卡支持CUDA API进行训练加速,调用Darknet基于CPU进行训练的时间居然为2500+小时。即使挂机尝试训练了30+小时,也仅训练完成了1000余次循环,训练效率实在太低,无奈只能另寻其他方法。
最终使用Google Colab云服务器的免费GPU资源,来在线训练模型,详细可以参考我之前的这篇文章:
RUHMI介绍
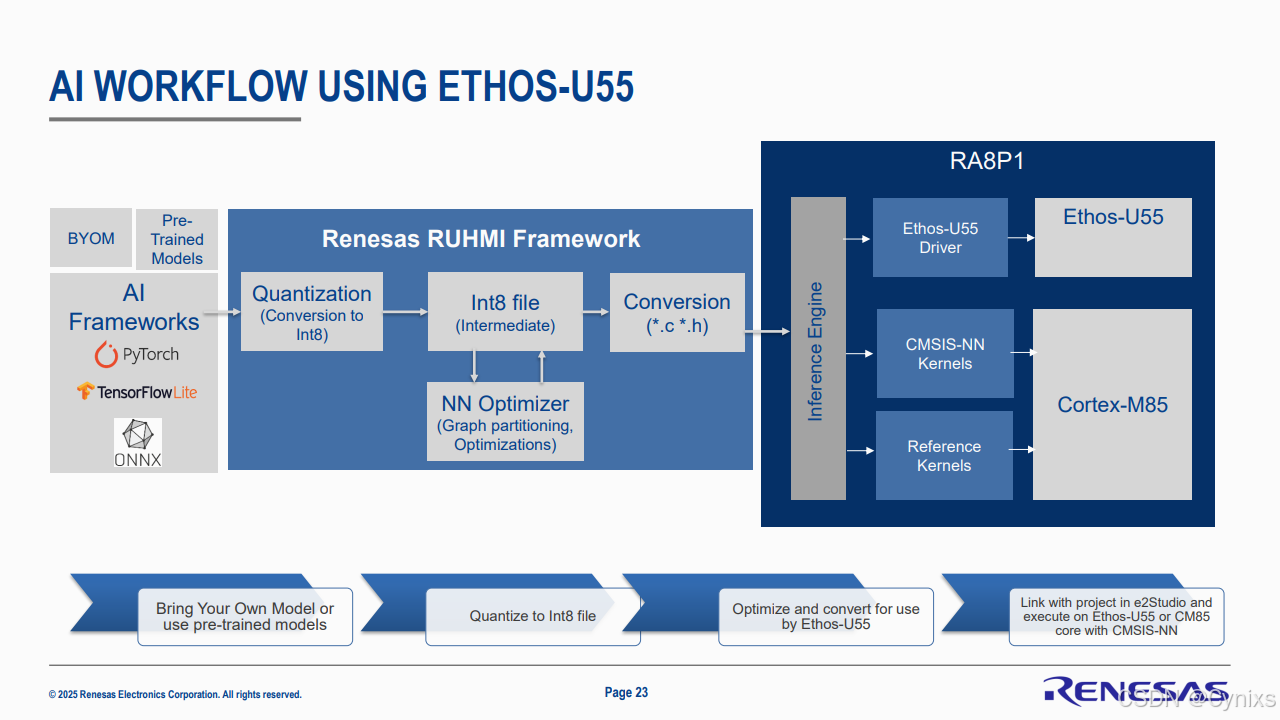
RUHMI是瑞萨电子推出的一套专为嵌入式AI模型部署设计的综合性工具链,其原生支持TensorFlow Lite、PyTorch和ONNX等主流机器学习框架的模型导入。支持生成高度优化的C代码、头文件及二进制权重文件,可直接集成到E2 Studio开发环境中。
参考瑞萨官方资料,AI模型部署到NPU上若通过RUHMI工具实现,大致的实现框架如下:
RUHMI工具的Github页面上列出了许多官方测试过的AI模型,仅为示例,支持模型的不仅限于以下模型:https://github.com/renesas/ruhmi-framework-mcu/blob/main/docs/models_tested.md
| Model | Framework | Data Format Pre-Input | |
|---|---|---|---|
| 1 | Efficientnet | ONNX | FP32 |
| 2 | mnasnet_op14 | ONNX | FP32 |
| 3 | mobilenetv2-12 | ONNX | FP32 |
| 4 | nanodet-plus-m-1.5x_416 | ONNX | FP32 |
| 5 | Regnetx_002_op14 | ONNX | FP32 |
| 6 | SESR-M5 | ONNX | FP32 |
| 7 | squeezenet1.1-7 | ONNX | FP32 |
| 8 | resnet18 | pytorch | FP32 |
| 9 | Squeezenet1_0 | pytorch | FP32 |
| 10 | ad01_fp32 | tflite | FP32 |
| 11 | mobilenetv2_model | tflite | FP32 |
| 12 | Ad_medium | tflite | INT8 |
| 13 | KWS_micronet_m | tflite | INT8 |
| 14 | person-det | tflite | INT8 |
| 15 | vww4_128_128 | tflite | INT8 |
| 16 | yolo-fastest-192_face_v4 | tflite | INT8 |
RUHMI转换和部署模型
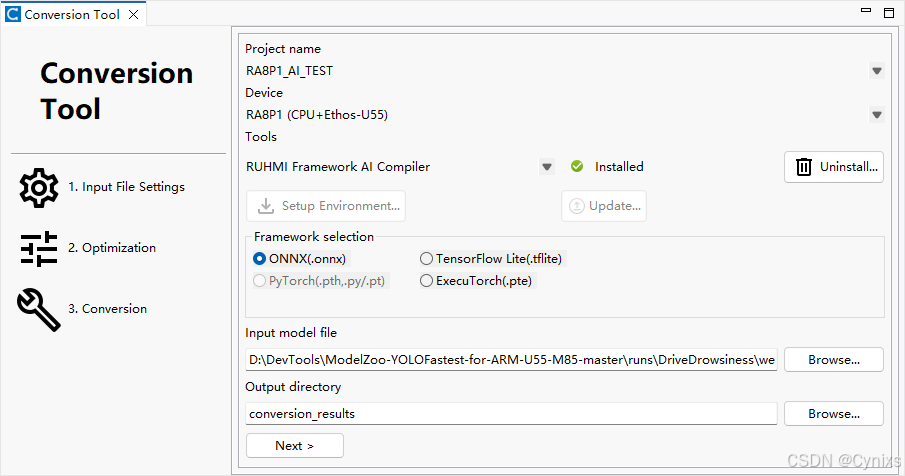
这里所使用的RUHMI框架是基于e2 Studio的,当然也有基于CLI命令行的形式可以选择,只是缺少了图形界面,功能都是一样的。
RUHMI软件界面如下,工程路径可以随意选择,后续只是将.c和.h文件生成到对应目录下而已。
可以在这里选择部署AI模型的模块(CPU+NPU或者CPU Only),这里选择NPU部署,但是实际上当模型的算子NPU无法完全支持的时候,还是会引入CPU介入。然后就一步步跟着工具界面提示往下进行即可。
框架选择这里,由于RUHMI目前暂时不支持PyTorch格式模型,因此我们需要将之前训练出的best.pt文件转换为ONNX格式。可以参考其他博客文章介绍的方法,或者直接用AI写一个Python脚本转换即可,最终得到对应的.onnx文件。
RUHMI工具会自动执行AI模型的量化转换步骤,可以选取图片作为校准数据集:
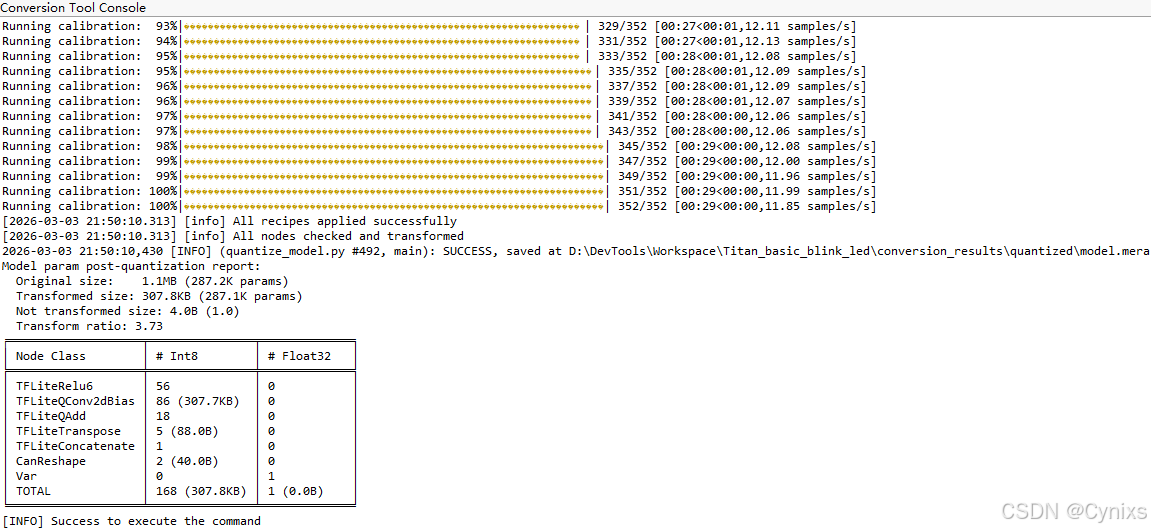
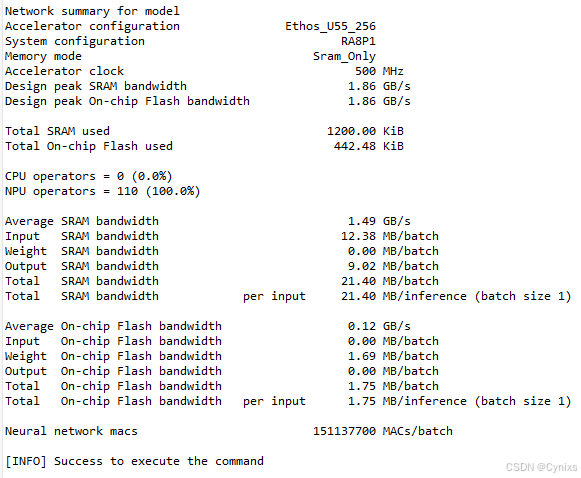
编译完成,成功生成基于Ethos-U55 NPU部署的模型。从输出日志中可以看到,需要CPU介入操作为0%。即全部的模型推理均为NPU 100%完成,RUHMI将该AI模型实现了完全的硬件加速,CPU无需参与计算,这也是优化最理想的状态:
模型集成到RT-Thread工程
将RUHMI工具生成的工程目录\conversion_results\converted\build\MCU\compilation\src下的文件复制到RT-Thread的AI模型示例工程中的src\models路径下,其中hal_entry.c不需要复制。
而models路径中默认的SConscript脚本文件需要保留,它会自动自动收集当前目录下的所有C源文件,并将其定义为名为“Models”的编译单元,以便集成到整个工程中:
最终的文件夹内容如下:
在yolo_rtthread.h文件中修改配置参数,如置信度CONF_THRESH、输入分辨率320×320,anchors(参考模型训练完成后的输出路径runs中的anchors.json文件)等。其间又修改了许多编译报错内容,比如变量存储地址等。
最终修改完成后成功编译,烧录的运行结果如下,:
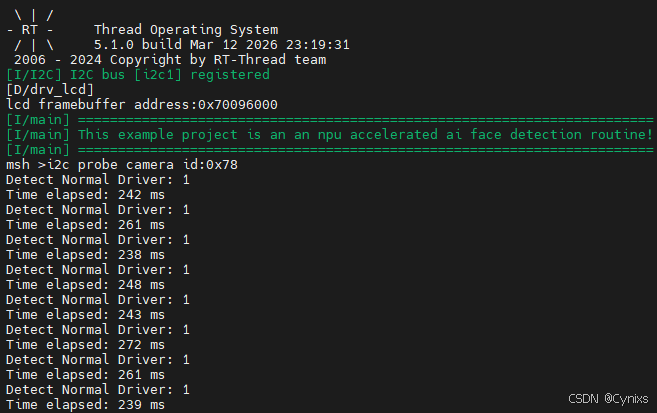
可以看出推理时间相比于RT-Thread默认例程192×192分辨率下约56ms是更慢了。
分析:这可能由于分辨率提高为了320×320,相关变量所需空间变大,而内置RAM无法完全存储,因此部分变量存储在了外置的Hyper RAM中,其读写速度是低于内置RAM的,从而最终导致了推理时间的延长。
识别到疲惫状态驾驶的驾驶员,用红色方框标注:

识别到正常状态驾驶员,用蓝色方框标注:


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)