论文解读:向量RAG为何回答不了“数据集主题是什么
过去几年,RAG(检索增强生成)几乎成了"让大模型用上私有数据"的标准答案。你有一万份文档,向量化存进数据库,用户提问,系统找出最相关的几段文字,塞进大模型上下文窗口,输出答案。逻辑清晰,效果扎实。
但有一类问题,这套方法从根本上就处理不了。
"这份数据集里的主要主题是什么?""整个语料库中,科学发现是如何被跨学科研究所影响的?"——这类问题不是在找某个具体事实,而是在要求 AI 读懂整个文本宇宙,然后给出一个关于全局结构的判断。
传统向量 RAG 面对这类问题,就像让人只看了一本书里随机翻到的三页,就去写整本书的读后感——工具本身根本不是为此而生的。
就在这种"局部检索够用、全局理解失灵"的关键节点,微软研究院联合多个团队提出了 GraphRAG。
不是一次 RAG 的版本升级,而是一次方法论层面的范式重构。
1. 向量RAG的天花板在哪里
先把问题讲清楚。
传统向量 RAG——GraphRAG 论文里把它叫做 "vector RAG"——在处理点查询时效果极佳。所谓点查询,就是答案存在于某几段具体文本里的问题。"特斯拉2023年第三季度营收是多少?""这份合同的违约条款是什么?"——这类问题,向量 RAG 驾轻就熟。
但当问题换一个层级,麻烦就来了。
"这一千篇科技新闻里,政策与科技创新的核心争议点是什么?""这位播客主持人过去两年采访的嘉宾,在 AI 监管上有哪些不同观点的演变?"
这类问题叫做感知性问题(sensemaking queries)——它们不再找某个具体事实,而是要求模型理解整个数据集的全局结构和主题分布。
向量 RAG 为什么处理不了?本质原因非常直接:它只能把一小块文本塞进上下文窗口,而这些文本是基于"与问题的语义相似度"挑选出来的。对于全局性问题,没有哪几段文本能代表全局。
翻译成人话——用向量 RAG 回答全局问题,就像让一个人只搜索了几个关键词、看了几条摘要,就去判断一个领域的整体走向。
更关键的是,这个问题不是工程优化能解决的。上下文窗口越做越大(128K、1M token),但工业级文档库的体量也在同步扩张。更何况,大模型在超长上下文中存在显著的"中间遗忘"效应(lost in the middle)——信息一旦不在开头或结尾,就容易被悄悄忽略。
这是架构层面的限制,不是参数调优能绕过的。
研究团队由微软三个部门联合组成:微软研究院(Microsoft Research)、微软战略任务与技术部(Strategic Missions and Technologies)、微软首席技术官办公室(Office of the CTO)。共同第一作者 Darren Edge 和 Ha Trinh 均来自微软研究院。这支配置——研究院做方法创新、战略技术部负责工程落地、CTO 办公室提供顶层视野——意味着这不是一篇"概念验证"论文,而是一个已在内部大规模使用、随后对外开源的工程系统的研究总结。
2. 已有的"全局方案"为什么也不够
问题已经清楚了。那有没有已有方案尝试解决这个问题?
有,但都有明显缺陷。
路线一:直接把全文塞进上下文窗口。 大模型的窗口越来越大,直接全文处理不行吗?问题是,对于工业级文档库,百万 token 是常态,千万 token 也不少见。窗口大小永远追不上数据规模。而且越长的上下文,"中间遗忘"效应越严重——代价不只是成本,而是质量本身在退化。
路线二:文本摘要(text summarization)。 直接对所有原始文本做分块 Map-Reduce 式摘要,然后基于摘要回答问题。这个思路比向量 RAG 进了一步,但代价是巨大的 token 消耗——论文实验中,文本摘要(TS)是所有方案里资源消耗最高的(100% 基准)。而且摘要是事先固定的,对于不同问题,摘要的粒度和侧重点未必合适。
换一句话说:向量 RAG 太局部,无法感知全局;纯文本摘要太粗暴,成本高且缺乏结构。两条路都没有真正触及"高效理解全局知识结构"这个核心问题。
GraphRAG 的定位正是在两者之间找到一个新的平衡点——在索引阶段就把数据组织成可以高效支持全局查询的结构,而不是在查询时临时用蛮力处理。
3. GraphRAG的整体思路:先"建图",再"回答"
GraphRAG 的核心直觉非常简单——与其在回答问题时临时从原文找相关段落,不如在索引阶段就把整个语料的知识结构提炼出来。
用一个类比。
向量 RAG 的方式:书上架了,每次有读者来问问题,馆员扫一遍书名和简介,把最像的几本抱过来。
GraphRAG 的方式:书上架之前,先做了一件事——把所有书里提到的人物、地点、事件、关系全部整理成一张知识网络,再把这张网络里关系密切的内容打包成一份份"主题报告"。读者来问"整个图书馆里关于科技政策的争议是什么",馆员直接翻出相关主题报告,而不是重新翻找原书。
GraphRAG 的整个工作流分两个阶段:索引时(Indexing Time)和查询时(Query Time)。
索引时,四步走:
-
把文档切成文本块(Text Chunks)
-
从每个文本块里提取实体和关系(Entities & Relationships)
-
把实体和关系合并成一张知识图谱(Knowledge Graph)
-
对知识图谱做社区检测(Community Detection),生成层级社区摘要(Community Summaries)
查询时,两步走:
-
把问题发给所有社区摘要,每份摘要各自生成一个局部答案
-
把所有局部答案汇总,生成最终的全局回答
把上面这两个阶段放在一张图里来看,整个逻辑就一目了然了
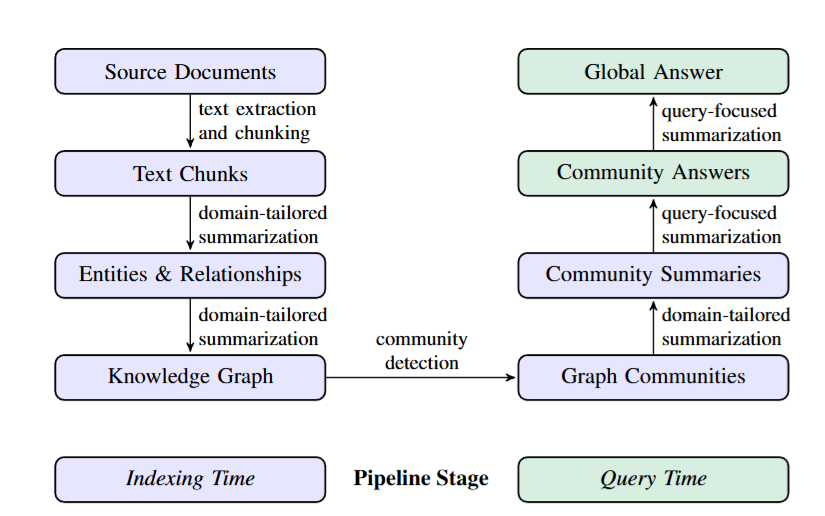
图1
图1是GraphRAG 的完整处理管线。左侧为索引阶段,从源文档出发,经文本切块、实体关系提取、知识图谱构建到社区摘要生成;右侧为查询阶段,社区摘要经 Map-Reduce 处理生成全局答案。每个阶段的输入输出用箭头清晰标注
这张图揭示了 GraphRAG 的根本逻辑:把知识的全局理解前置到索引阶段,而不是推迟到查询时。
接下来逐层拆解每一步。
4. 从文本到知识图谱:LLM做"抽象摘要"
先说实体和关系提取。
知识图谱——可以理解成"人物关系图"的超级增强版。图里的节点是实体(人、地点、组织、概念),图里的边是关系(谁属于谁、谁影响谁、谁创立了什么)。
GraphRAG 构建知识图谱的方式,是用 LLM 对每个文本块做"抽象摘要"——不是复述原文,而是提炼出结构化的实体和关系。
对每一个文本块,LLM 被提示提取三类信息:
-
实体:名称、类型、描述("NeoChip:专注于可穿戴设备和物联网低功耗处理器的公司")
-
关系:源实体、目标实体、关系描述、关系强度(0-10分)
-
声明(claims):关于实体的可验证事实陈述
这里有个微妙的设计——GraphRAG 对同一段文字会运行多轮自反思(self-reflection):提取完实体后,让 LLM 重新审视自己的输出,问:"有没有遗漏的实体?"如果 LLM 判断有遗漏,就继续补充,直到没有遗漏为止,或达到设定的最大迭代次数。
为什么要自反思?因为 LLM 在处理长文本块时,天然"头重脚轻"——对文本前半段的信息提取得更完整,后半段容易被忽略。自反思相当于让 LLM 反复审阅自己的作业。
数据支撑这一判断的,是下面这张图
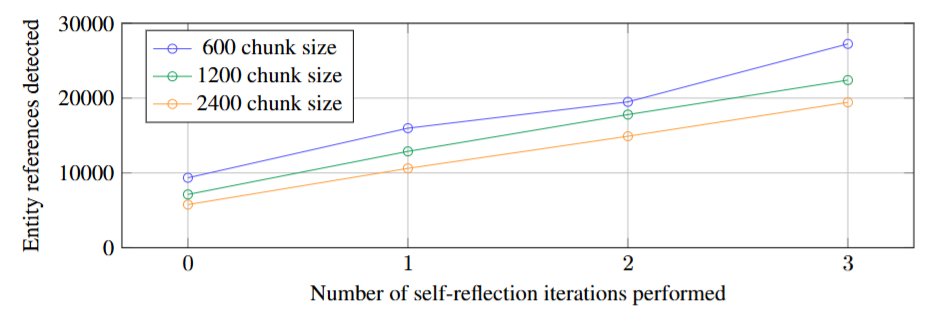
图2
图2显示的是,在 HotPotQA 数据集上,不同文本块大小(600/1200/2400 token)与不同自反思迭代次数(0-3次)下,检测到的实体引用数量对比。600 token 文本块从 0 次迭代时的约 8000 个,上升到 2 次迭代后接近 20000 个,增幅将近 2.5 倍。
更重要的是,自反思机制让 GraphRAG 可以使用更大的文本块(1200 或 2400 token)而不显著损失提取质量——这直接降低了索引阶段的 LLM 调用次数,从而降低成本。
实体合并同样有讲究。跨文档的相同实体用精确字符串匹配来识别,同一实体的多份描述会被聚合,同一关系的多次出现会被累积为边权重(出现次数越多,权重越高)。
论文实验结束后,播客数据集的知识图谱包含 8564 个节点和 20691 条边;新闻数据集更大,包含 15754 个节点和 19520 条边。
这是一张真实的、有权重的知识网络——不是搜索索引,而是对语料的结构性理解。
5. 社区检测:把知识图谱切成"主题片"
知识图谱构建好了,下一步是把它组织成一种"对全局查询友好"的结构。
这里用到了图论里的一个经典工具:社区检测(community detection)。
直觉上,社区检测做的事,就像在一张错综复杂的人际关系网络里找出"小圈子"——哪些人互相认识得多?这些人就是一个社区。在知识图谱里,一个社区就是一组关系密切的实体——它们可能都属于某个行业、某个事件、某个地理区域,或者某个主题领域。
GraphRAG 使用的是 Leiden 算法(Traag et al., 2019)——这是一种比 Louvain 算法(另一个经典社区检测算法)更稳定、能保证社区内连通性的层级检测算法。
Leiden 算法会递归地检测社区:先找出大社区(Level 0,根层级),再在每个大社区内部找出子社区(Level 1),再往下(Level 2、Level 3……),直到子社区小到无法再分割为止。
这种层级结构是什么样的?图3给出了一个真实的可视化案例
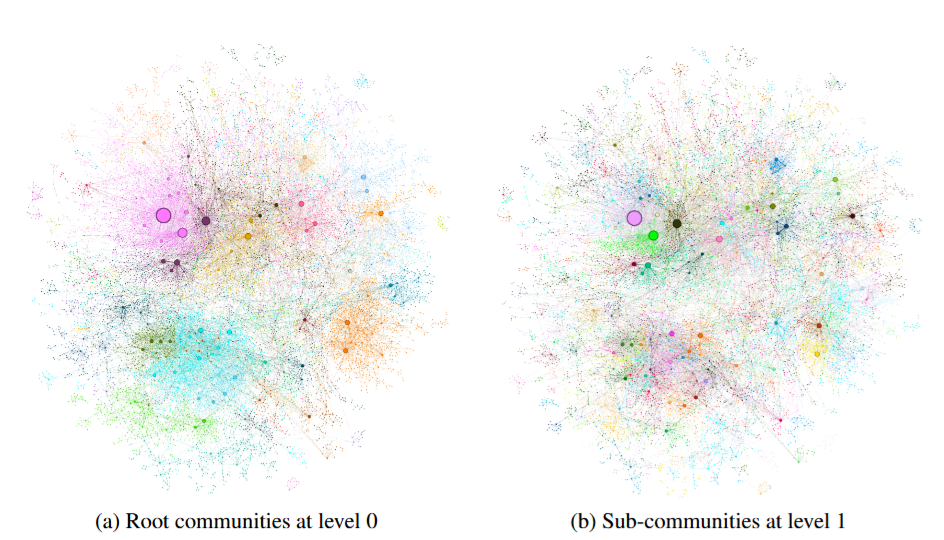
图3
图4是对 MultiHop-RAG 数据集构建的知识图谱应用 Leiden 算法后的社区分层结果。左图(a)为 Level 0 根层级,整张图被切成少数几个大色块,代表宏观主题;右图(b)为 Level 1 子层级,每个大社区内部进一步分裂出更细粒度的子社区,就像把全国地图放大到省级、再到市级。节点大小与连接数成正比,颜色代表所属社区。
这棵社区树有什么用?用于生成分层社区摘要。
对每个社区,GraphRAG 用 LLM 生成一份分析报告式的摘要,包含:这个社区里的核心实体是什么、它们之间的关系如何、有哪些重要的事实声明。报告格式固定,含有标题、执行摘要、影响评分及详细发现。
生成摘要时有一个精心设计的优先级策略:
-
对叶子社区,按实体的边度(连接数量)从高到低排序,优先把最重要的实体和关系塞进上下文窗口,直到装满为止——先讲"大节点",再讲"小节点"。
-
对上层社区,如果所有元素摘要加起来超出了窗口限制,则优先用子社区的摘要替换详细的元素描述——用"精炼版"代替"原材料",从而覆盖更多范围。
结果是什么?一套从宏观到微观、层级分明的知识摘要库。层级之间的资源消耗差距,用图4的数字来说话最有力

图4
图4是两个数据集在不同条件下(C0-C3、TS)的上下文单元数量、对应 token 数以及占文本摘要(TS,100% 基准)的百分比。C0 根层级只需 2.3-2.6% 的 token 即可覆盖全局;C3 低层级则需要 66-74%,但仍显著低于原始文本摘要的全量消耗
这意味着什么?意味着 GraphRAG 可以用极低成本(C0 层,仅占文本摘要方案的 2-3% token)处理那些只需要宏观理解的全局问题,同时在需要时随时"钻入"更细粒度的社区摘要获取细节。效率与深度,不再是非此即彼的选择。
6. 查询时的Map-Reduce:让知识库集体投票
索引做好了,现在看 GraphRAG 如何回答用户的问题。
假设用户问:"这个播客数据集里,科技领袖们对人工智能监管有哪些不同的观点?"
向量 RAG 的方式:把这个问题向量化,找出最相关的几段播客文字,塞给 GPT,让它总结。
GraphRAG 的方式是三步走。
第一步:打散社区摘要。 把所有社区摘要随机打散、重新分块(每块固定 token 数量)。这个设计看起来反直觉——为什么要随机打散?原因是防止相关信息集中在某一个上下文窗口里,从而因"中间遗忘"效应被遗漏。随机分布让每个上下文窗口都有均等机会覆盖相关信息。
第二步:Map 阶段——并行生成局部答案。 把用户问题发给每个分块,要求:基于本块内容生成一个局部答案,同时给出 0-100 的"有用程度"评分。得分为 0 的局部答案直接丢弃。这一步全部并行进行,不同分块的处理互不依赖。
第三步:Reduce 阶段——汇总生成全局答案。 把所有局部答案按有用程度评分从高到低排序,依次填入最终上下文窗口,直到装满,再生成最终的全局答案。
这个流程的本质,就是一次知识的"分布式投票"——让数据库里每个知识片段都为这个问题发声,然后按贡献度汇总。
不是找最相似的答案,而是让所有相关内容共同协作生成一个回答。
7. 怎么评测没有标准答案的问题
GraphRAG 要解决的问题本身就让评测变得极其困难。
向量 RAG 的评测相对简单——问题有标准答案(事实查询),正确与否一目了然。但"这个语料库的主要主题是什么"根本没有金标准答案。
GraphRAG 团队的做法是:用 LLM 来出题,再用 LLM 来评判。
出题流程(算法1):
-
给 LLM 一个关于语料库的描述,让它想象 K 类可能用到这个 RAG 系统的用户画像
-
对每个用户画像,让 LLM 设计 N 个该用户可能要完成的任务
-
对每对(用户 × 任务),让 LLM 生成 M 个需要全局理解才能回答的问题
论文实验设置 K=N=M=5,每个数据集生成 125 个测试问题。这类问题长什么样?图5给出了两个典型案例。

图5
图5针对播客数据集和新闻数据集,LLM 生成的用户画像、任务和全局感知问题示例。,以播客数据集为例,为"关注科技政策的科技记者"这个用户角色生成的问题:
-
哪些期次主要讨论科技政策与政府监管?
-
嘉宾们如何看待隐私法对科技发展的影响?
-
有没有嘉宾讨论过创新与伦理考量之间的平衡?
这些问题的特点显而易见:需要通读整个数据集才能回答,不是找某段具体文字。
评判标准,由第二个 LLM 担任裁判,四个维度:
-
全面性(Comprehensiveness):答案覆盖了问题的多少个维度和细节?
-
多样性(Diversity):答案是否提供了不同视角和洞见?
-
赋权性(Empowerment):答案能否帮助用户做出知情判断?
-
直接性(Directness):答案是否简洁直接地回应了问题?
前三个是真正追求的目标,第四个"直接性"作为对照指标——因为直接性与全面性、多样性天然存在张力。没有任何方法能在所有四个维度上同时拔尖。如果一个方法连直接性也赢了,那说明评测本身出了问题。
这是一个精心设计的"自我验证机制"。
8. 实验结果:数字说话
一句话总结:GraphRAG 在全局感知问题上,对向量 RAG 的胜率超过 70%,且这一优势在统计上高度显著(p<0.001)。
GraphRAG 在两个数据集——播客文字记录(约 100 万 token,1669 个文本块)、新闻文章(约 170 万 token,3197 个文本块)——上,与向量 RAG(SS)和文本摘要(TS)进行了全面的六条件比较(C0、C1、C2、C3、TS、SS)。
全面性:所有 GraphRAG 条件(C0-C3)vs 向量 RAG 的胜率,在播客数据集为 72-83%,在新闻数据集为 72-80%(均为 p<0.001)。换句话说,在 125 个全局感知问题、每题重复 5 次的设置下,超过 7 成的情况 GraphRAG 都更全面。这不是小差距。
多样性:胜率同样显著,播客 75-82%,新闻 62-71%。
直接性:如预期,向量 RAG 最直接——它只检索最相关的几段,答案当然更聚焦简洁。这正好印证了评测方案的合理性:GraphRAG 更全面,向量 RAG 更直接,两者的优劣并不是零和游戏。
想把所有数字一眼看全,图6的热力矩阵是最直观的总结
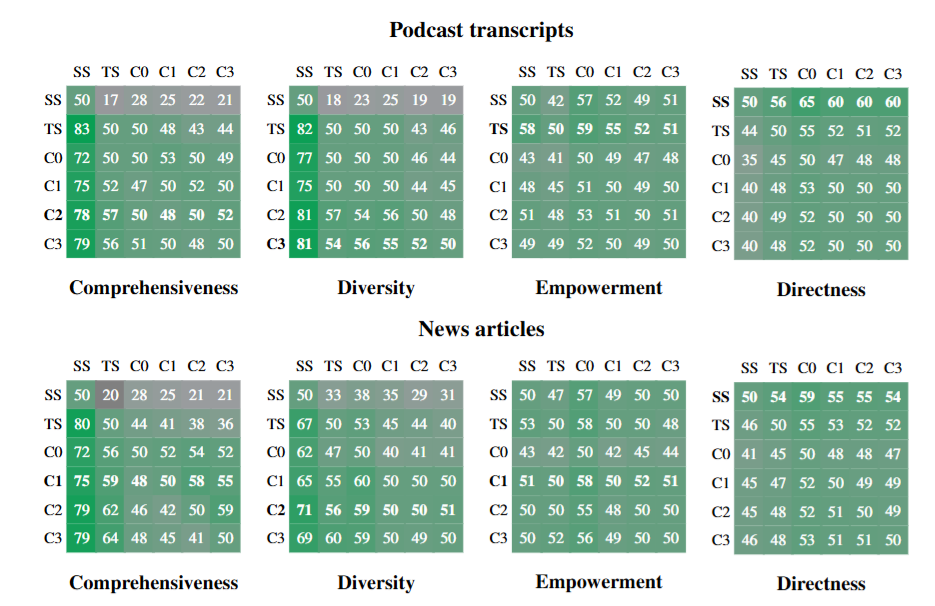
图6
图6是两个数据集、四个评估指标(全面性、多样性、赋权性、直接性)下,六个条件(SS、TS、C0-C3)两两比较的胜率矩阵(行条件胜过列条件的百分比)。颜色越深代表胜率越高。所有 GraphRAG 条件在全面性和多样性上对 SS(向量 RAG)呈系统性压制;而在直接性一列,SS 同样系统性占优——结构自洽,符合预期。
GraphRAG vs 纯文本摘要(TS):GraphRAG(除了根层级 C0)在全面性和多样性上通常也略优于纯文本摘要。播客 C2 层的全面性胜率 57%(p<0.001),新闻 C3 层 64%(p<0.001)。图结构带来的知识组织,确实给摘要质量带来了额外提升——而不只是成本上的节省。
成本对比是 GraphRAG 最惊人的优势之一:根层级社区摘要(C0)处理每个查询只需消耗文本摘要方案 2.3-2.6% 的 token。换句话说,C0 GraphRAG 以不到 3% 的计算代价,就能在全面性和多样性上对向量 RAG 形成压倒性优势。这不是数量级上的优势,而是工程实用性上的分水岭。
论文在 Experiment 2 里还用了第二套方法验证:提取每个答案里的"可验证事实声明"数量来量化全面性,用声明聚类数量量化多样性。GraphRAG 生成答案的平均声明数为 31-34 条,向量 RAG 只有约 25-26 条。
具体数字,图7列得清清楚楚
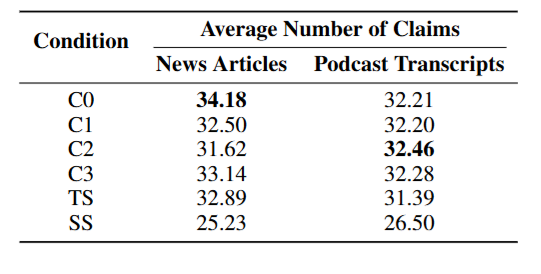
图7
图7两个数据集中,各条件下从答案里提取的平均声明数量。所有全局方法(C0-C3、TS)的声明数均显著高于向量 RAG(SS)——差异的 p 值均小于 0.05。GraphRAG 的 C0 条件在新闻数据集上以 34.18 条声明领跑所有条件,验证了其在宏观全面性上的优势。
结果方向与 LLM 评判高度一致。
抽象的胜率数字落地到一个具体案例,看起来是什么感觉?图8提供了一个有说服力的例子。
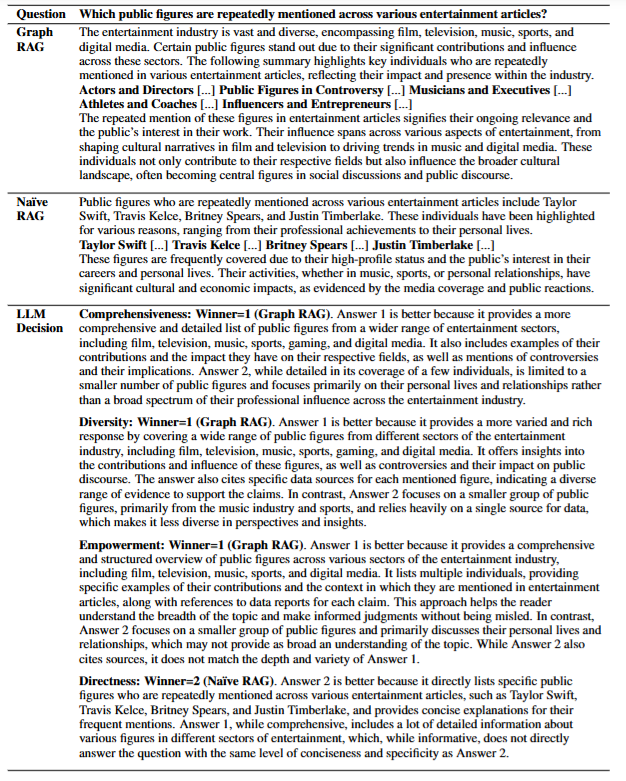
图8
图8中,新闻文章数据集上,问题"哪些公众人物在各类娱乐文章中被反复提及?"的 GraphRAG 答案(覆盖影视、音乐、体育、数字媒体多个维度)与向量 RAG 答案(聚焦 Taylor Swift、Travis Kelce 等少数人物)的对比,以及 LLM 裁判在四个维度上的判定理由。
裁判 LLM 在全面性、多样性、赋权性上都判定 GraphRAG 获胜,只有直接性选择了向量 RAG——"Answer 2 更直接,用具体名字直接回答了问题"。
这正是这两种方法本质差异的缩影。
9. GraphRAG的局限与未来方向
任何一篇研究都不是终点,这篇也不例外。
当前评测只覆盖了两个数据集、百万 token 量级,更大规模或更专业领域(医学、法律、金融)的泛化能力还需要更多验证。知识图谱提取和社区摘要生成过程中的幻觉率——即内容是否忠实于原文——目前没有系统性分析,这是生产环境部署中需要重点关注的风险点。
此外,论文明确指出,赋权性(Empowerment)这个维度的结果比较混杂。裁判 LLM 的分析表明,"能否提供具体的例子、引用和引证"是影响用户做出知情判断的关键——这说明 GraphRAG 的元素提取提示还有调优空间,目前的图索引对具体细节的保留能力仍不够完善。
未来方向,GraphRAG 团队已经明确给出了几条:
-
局部-全局混合 RAG:把基于向量相似度的局部检索与图结构的全局理解结合起来,实现"针对具体问题灵活切换检索策略"的系统
-
即时社区报告生成(roll-up):在查询时根据问题动态生成相关的社区摘要,而不只是使用预生成的静态摘要
-
跨层级下钻(drill-down):让用户从高层摘要出发,沿着社区层级逐步下探到具体细节,像浏览一棵真正的"知识树"
这三个方向叠加,将是下一代企业知识管理系统——那种能真正"读懂"大规模文档库、而不只是从里面"找东西"的系统——的技术雏形。
GraphRAG 不是终点。但它无疑是迈向"AI 真正理解数据全局"这个愿景的关键一步。
论文地址:https://arxiv.org/pdf/2404.16130v2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)