LangGraph 9. Agent 背后:ReAct
引言:为什么需要 AI Agent?
想象一下,你正在计划一次旅行。你需要查询景点信息、预订机票、选择酒店、规划路线,还要查询各种产品的价格。如果每一步都需要你手动操作,这会非常繁琐。但如果有一个智能助手能够理解你的需求,自动完成这些任务,那该多好!
这就是 AI Agent(人工智能代理)要解决的问题。AI Agent 是一个能够感知环境、处理信息并采取行动以实现特定目标的软件程序或系统。 它就像一个超级智能的大语言模型,不仅能够理解问题,还能观察环境、做出决策并执行相应的操作。
💡 理解要点:AI Agent 的核心价值在于它能够自主地完成复杂任务,而不仅仅是回答简单的问题。它结合了理解、推理和行动的能力,使其能够处理需要多步骤操作的实际问题。
1. AI Agent 背后的理论
1.1 人类思维方式的启发
人类在处理复杂问题时有一个显著优势:我们能够吸收大量信息,过滤掉不重要的细节,并根据关键信息做出决策。就像侦探破案一样,我们通常会先将大问题分解为一个个小的假设,然后通过观察逐步支持或反驳这些假设。
从这个现实的观点出发,启发 AI Agent 早期范式的一篇重要论文 👉 REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS 使用"思维链提示"来模仿这个概念,它将多步骤问题分解为中间步骤:
- 发起行动:让大模型执行一项行动,观察所选环境的反馈
- 收集信息:在流程中收集所有信息,并使用它来决定下一步采取什么合适的行动
- 迭代执行:重复此操作来解决更大、更复杂的任务,使用一种称为"推理跟踪"的方法,该方法涉及跟踪整个过程所经历的步骤或阶段以得出结论或解决方案
🔍 实际例子:就像医生诊断疾病一样,医生不会直接给出结论,而是先观察症状(Observation),然后思考可能的原因(Reasoning),接着进行检查或开药(Action),再观察治疗效果,如此循环直到找到正确的治疗方案。
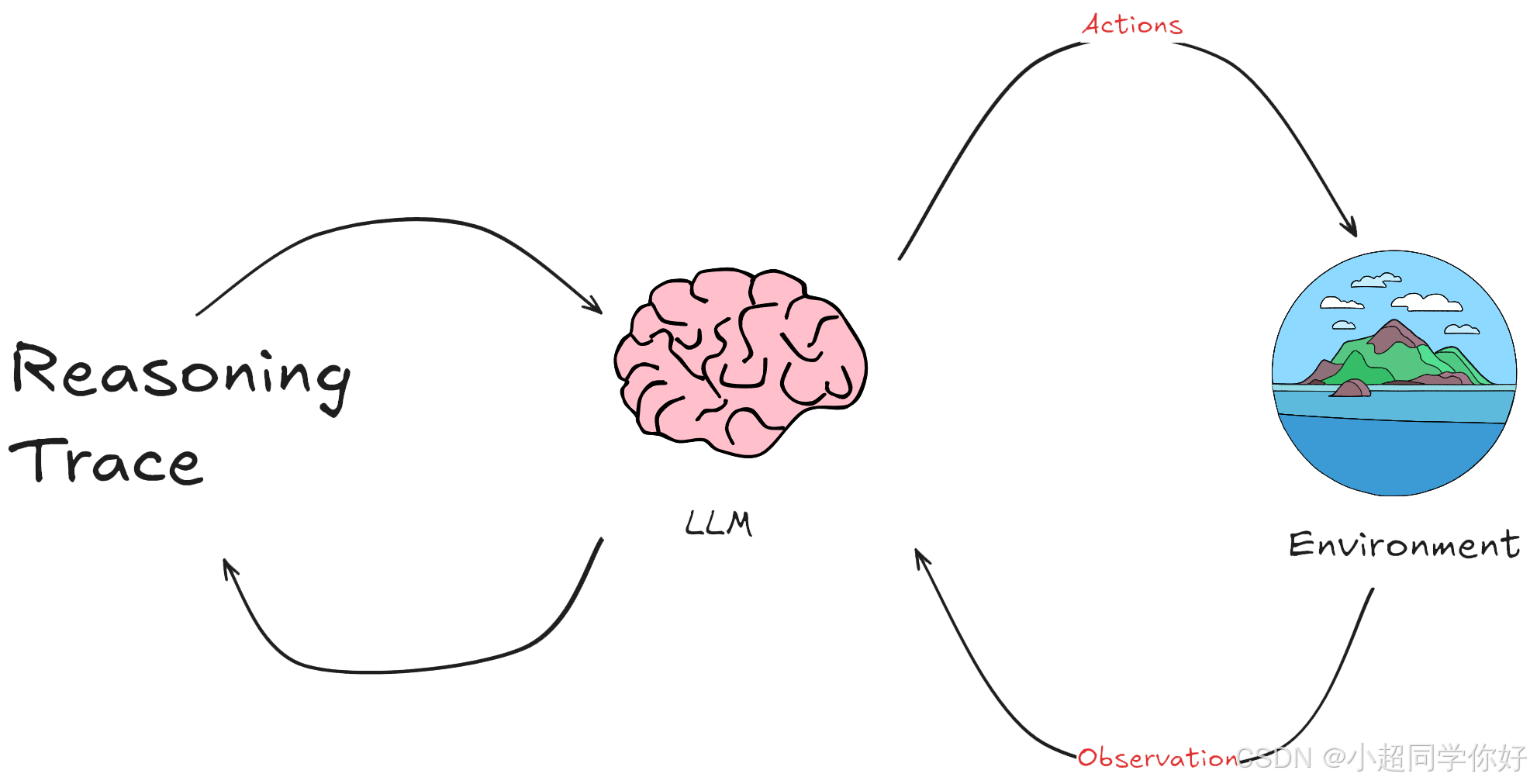
如下图所示,整个过程是一个动态循环。代理不断从环境中学习,通过其行动影响环境,然后根据环境的反馈继续调整其行动和策略。这种模式特别适用于那些需要理解和生成自然语言的应用场景,如聊天机器人、自动翻译系统或其他形式的自动化客户支持。
💡 重点记住:Agent 三步骤:Observation(观察)、Action(行动)、Reasoning(推理)。
1.2 AI Agent 的核心架构
AI Agent 的最经典,同时也是目前任何一套 Agent 框架的基本框架,如下图所示:
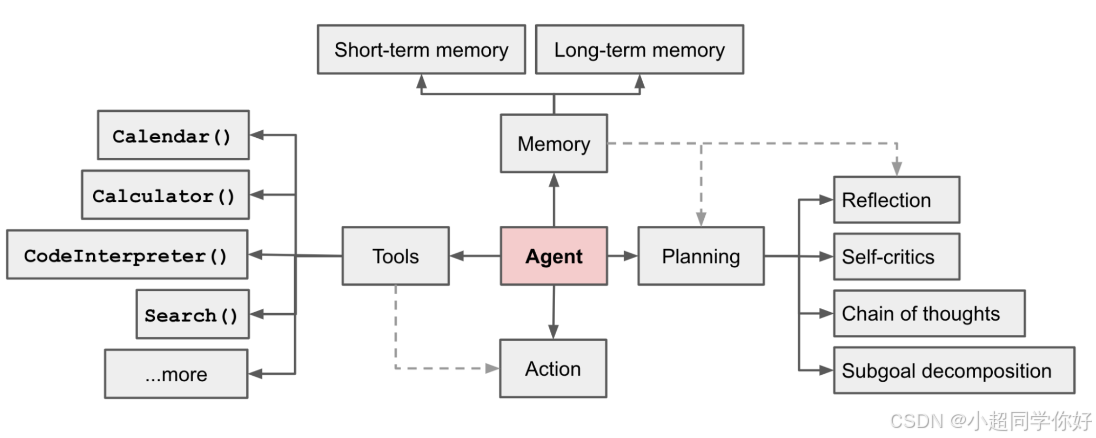
图片来源:https://lilianweng.github.io/posts/2023-06-23-agent/ , 强烈建议大家通篇阅读。
这套智能代理架构是指自主代理的结构化设计,自主代理是能够独立感知环境、做出决策并采取行动以实现特定目标的系统或实体。该架构描述了代理的各个组件如何交互以促进智能行为。
为什么需要这样的架构? 就像建造一栋房子需要地基、框架、水电系统等不同组件一样,AI Agent 也需要不同的功能模块来协同工作。该架构包含四个关键组件:
-
规划(Planning):该组件将代理置于动态环境中,使其能够根据其目标和收集的信息制定策略并规划未来的行动。就像旅行前制定行程表一样,规划模块帮助 Agent 确定"做什么"和"怎么做"。
-
记忆(Memory):该组件使智能体能够回忆过去的行为、经历和结果,这对于学习和适应至关重要。想象一下,如果一个人没有记忆,每次遇到同样的问题都要重新思考,那效率会非常低。记忆模块让 Agent 能够"记住"之前的经验。
-
行动(Action):该组件将智能体的决策转化为具体的行动,执行计划的任务以达到预期的结果。这是 Agent 与外部世界交互的桥梁,就像人的手和脚一样。
-
工具(Tools):拥有一名仅拥有 LLM 的代理人就像使用一台没有任何额外设备的计算机一样。工具让代理能够使用互联网、获取特殊知识或与擅长特定事物的几种不同的人工智能模型一起工作,从而使代理变得更加有用。就像工匠需要各种工具来完成不同的工作一样,Agent 也需要各种工具来扩展其能力。
💡 重点记住:Agent 四大模块:Planning(规划)、Memory(记忆)、Action(行动)、Tools(工具)。
1.3 AgentExecutor:执行循环的核心
AgentExecutor 是 AI Agent 能够连续执行正确的工具、不断观察结果、然后决定下一步需要哪种工具的关键组件。这种函数的迭代执行是由 AgentExecutor 执行的。AgentExecutor 指的是代理运行时,整个过程一遍又一遍地重复,直到达到预定义的终止标准。
🔍 实际例子:就像自动导航系统一样,它会不断检查当前位置(Observation),计算最佳路线(Reasoning),然后执行转向或加速等操作(Action),如此循环直到到达目的地。
2. Function Calling
2.1 OpenAI API 基础调用
在深入了解 Function Calling 之前,让我们先回顾一下基础的 OpenAI API 调用方式。理解基础调用有助于我们更好地理解 Function Calling 的工作原理。
为什么需要先了解基础调用? 就像学习开车之前要先了解汽车的基本操作一样,理解基础的 API 调用方式,能够帮助我们更好地理解后续更复杂的功能。
2.1.1 最基础的调用(无记忆功能)
最基础的 OpenAI API 调用(不包含记忆功能):
from openai import OpenAI
client = OpenAI()
while True:
prompt = input('\n用户提问:')
if prompt == "退出":
break # Exit the loop if input is "退出"
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一位乐于助人的智能助理"},
{"role": "user", "content": prompt},
]
max_tokens=1024,
temperature=0.8)
message = completion.choices[0].message.content
print(f"模型回复:{message}")
💡 理解要点:这种基础调用方式就像一次性的对话,每次提问都是独立的,模型不会记住之前的对话内容。这就像每次见面都是第一次见面的陌生人一样。
2.1.2 添加记忆功能
为了让模型能够记住之前的对话,我们需要加入记忆功能。就像人类需要记忆来理解上下文一样,模型也需要通过保存历史对话来实现"记忆":
from openai import OpenAI
client = OpenAI()
# Create a conversation list to continuously append historical dialogue records
messages = []
while True:
prompt = input('\n用户提问: ')
if prompt == "退出":
break # Exit the loop if input is "退出"
messages.append(
{
'role':'user',
'content':prompt
})
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages = messages)
response = completion.choices[0].message.content
print(f"模型回复:{response}")
messages.append(
{
'role':'assistant',
'content':response
})
🔍 实际例子:我们打印一下 messages 的内容,注意看,用户的回答被放在了 assistant role 里面;用户的问题被放在了 user role 里面。所以说,大模型实际上是通过不断追加会话消息列表来模拟记忆功能。
[{'role': 'user', 'content': '你好,请你介绍一下你自己'},
{'role': 'assistant',
'content': '你好!我是一款由OpenAI开发的人工智能语言模型,旨在回答问题、提供信息、协助撰写文本和进行多种语言的互动。我可以帮助你寻找知识、解决问题、提供创意建议等。如果你有任何具体问题或者需要帮助的地方,随时问我!'},
{'role': 'user', 'content': '我是木羽,很高兴认识你'},
{'role': 'assistant', 'content': '你好,木羽!很高兴认识你!如果你有什么想聊的或需要帮助的地方,尽管告诉我!'},
{'role': 'user', 'content': '请问我叫什么'},
{'role': 'assistant',
'content': '你刚刚告诉我你叫木羽。如果我理解错了,请告诉我。 你有什么想讨论的或者需要帮助的地方吗?'}]
💡 理解要点:通过维护一个消息历史列表,模型能够"记住"之前的对话内容。这就像给模型配备了一个记事本,它可以在上面记录和回顾之前的对话。
2.2 Function Calling 生命周期
接下来,让我们添加 function calling 功能。为什么需要 function calling? 想象一下,当用户问一个智能客服:"你们家有没有XX商品?"这个时候,大模型需要去数据库中查询,然后根据返回的结果,生成最终的回复。Function Calling 就是让大模型能够调用外部函数来获取实时信息或执行特定操作的能力。
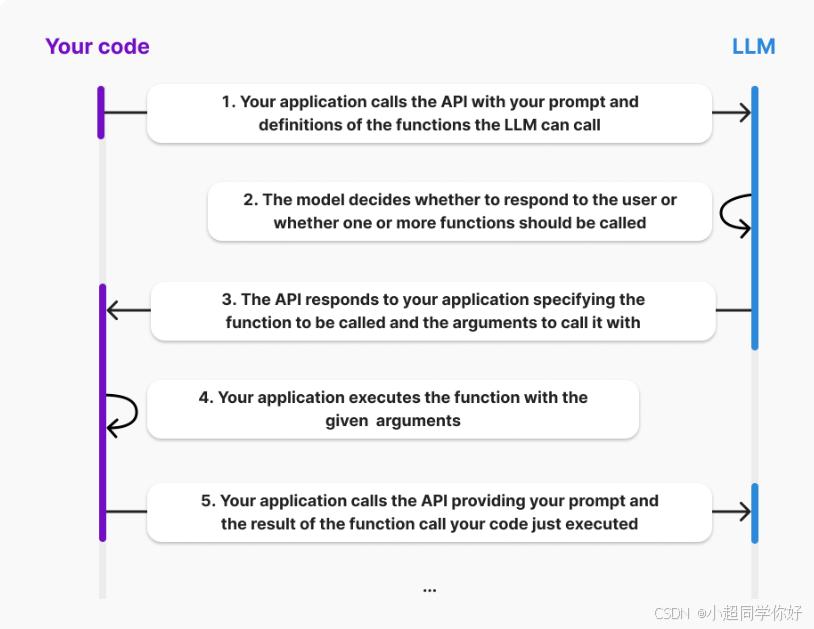
如上图所示,描述了使用大语言模型(LLM)通过 API 进行功能调用的完整生命周期。这个过程就像医生看病一样:先问诊(API调用),然后思考需要做什么检查(模型决策),接着开检查单(API响应),执行检查(执行函数),最后根据检查结果诊断(调用结果处理)。具体过程如下:
-
API调用:应用程序向 API 发送调用请求,附带具体的提示信息和可供 LLM 调用的函数定义。就像病人向医生描述症状一样。
-
模型决策:LLM 评估接收到的输入,并决定是否直接回应用户,或是需要调用一个或多个外部函数以提供更合适的回答。就像医生判断是否需要做检查一样。
-
API响应:API 向应用程序返回响应,指明需要执行的函数以及执行这些函数所需的参数。就像医生开出检查单一样。
-
执行函数:应用程序根据 API 的指示执行指定的函数,使用提供的参数。就像执行检查一样。
-
调用结果处理:完成函数执行后,应用程序再次调用 API,传递先前的提示信息和函数执行的结果,以便 LLM 可以利用这些新数据生成最终的用户响应。就像医生根据检查结果给出诊断一样。
🔍 实际例子:这里我们举一个例子,比如,我们有一个 SportsEquipment.db 文件,这个表有多个字段,包括产品ID、名称、描述、规格、用途、品牌、价格和库存数量。
CREATE TABLE products (
product_id TEXT,
product_name TEXT,
description TEXT,
specifications TEXT,
usage TEXT,
brand TEXT,
price REAL,
stock_quantity INTEGER
)
对于用户的问题,比如:你们家都有什么球在卖,理想情况下,系统需要根据 球 这个关键字向后台数据库执行查询操作。这里我们先新建一个函数:
import sqlite3
def query_by_product_name(product_name):
# Connect to SQLite database
conn = sqlite3.connect('SportsEquipment.db')
cursor = conn.cursor()
# Use SQL query to find products by name. The '%' symbol allows partial matching.
cursor.execute("SELECT * FROM products WHERE product_name LIKE ?", ('%' + product_name + '%',))
# Fetch all queried data
rows = cursor.fetchall()
# Close connection
conn.close()
return rows
比如,我们给 query_by_product_name 函数的输入是 球,那么函数最终返回:
Matching Products:
('001', '足球', '高品质职业比赛用球,符合国际标准', '圆形,直径22 cm', '职业比赛、学校体育课', '耐克', 120.0, 50)
('002', '羽毛球拍', '轻量级,适合初中级选手,提供优秀的击球感受', '碳纤维材质,重量85 g', '业余比赛、家庭娱乐', '尤尼克斯', 300.0, 30)
('003', '篮球', '室内外可用,耐磨耐用,适合各种天气条件', '皮质,标准7号球', '学校、社区运动场', '斯伯丁', 200.0, 40)
('008', '乒乓球拍套装', '包括两只拍子和三个球,适合家庭娱乐和业余训练', '标准尺寸,拍面防滑处理', '家庭、社区', '双鱼', 160.0, 35)
然后,我们向大模型描述这个函数,以便大模型知道如何调用它,以及在什么情况下需要调用它,并且将函数定义作为可用工具以及消息传递给大模型:
tools = [
{
"type": "function",
"function": {
"name": "query_by_product_name",
"description": "Query the database to retrieve a list of products that match or contain the specified product name. This function can be used to assist customers in finding products by name via an online platform or customer support interface.",
"parameters": {
"type": "object",
"properties": {
"product_name": {
"type": "string",
"description": "The name of the product to search for. The search is case-insensitive and allows partial matches."
}
},
"required": ["product_name"]
}
}
}
]
最后,通过 tools 参数进行工具传递。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
💡 理解要点:大模型会根据用户的问题以及工具中函数的描述,来自行决定是否调用此函数。这就像给模型提供了一本工具手册,模型会根据情况选择合适的工具。
比如,我们问了一个和这个函数没有关系的问题:
from openai import OpenAI
client = OpenAI()
messages = [
{"role": "user", "content": "你好,在吗"}
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools, # Add tools here
)
我们收到的回复:
ChatCompletion(id='chatcmpl-A6aZqaLTiuRfZRPC9Y4HRD8otDBHQ', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='在的,有什么可以帮助您的吗?', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1726133934, model='gpt-4o-mini-2024-07-18', object='chat.completion', service_tier=None, system_fingerprint='fp_483d39d857', usage=CompletionUsage(completion_tokens=10, prompt_tokens=104, total_tokens=114))
response.choices[0].message.content 包含了大模型对于这个问题的回复:在的,有什么可以帮助您的吗?但这里,大模型并没有调用任何函数。这说明模型能够智能地判断什么时候需要调用函数,什么时候可以直接回答。
🔍 实际例子:我们再问一个问题,这次是关于产品的:
messages = [
{"role": "user", "content": "你好,你家都卖什么球?"}
]
我们收到的回复:
ChatCompletion(id='chatcmpl-A6aaHkwifCmRmxPOKVkVQc5yppiY9', choices=[Choice(finish_reason='tool_calls', index=0, logprobs=None, message=ChatCompletionMessage(content=None, refusal=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_6Axa00hfMAVSzSGEBMIjXFZw', function=Function(arguments='{"product_name":"球"}', name='query_by_product_name'), type='function')]))], created=1726133961, model='gpt-4o-mini-2024-07-18', object='chat.completion', service_tier=None, system_fingerprint='fp_483d39d857', usage=CompletionUsage(completion_tokens=17, prompt_tokens=109, total_tokens=126))
这个时候,我们发现 response.choices[0].message.content 是 None,但 tool_calls 是有值的。打印 response.choices[0].message.tool_calls[0] 可以获得:
ChatCompletionMessageToolCall(id='call_6Axa00hfMAVSzSGEBMIjXFZw', function=Function(arguments='{"product_name":"球"}', name='query_by_product_name'), type='function')
我们可以看到,系统调用 query_by_product_name 函数,输入是 product_name 参数值是 球。我们可以调用 final_res = query_by_product_name(product_name) 以获得最后的结果。
💡 理解要点:当模型判断需要调用函数时,content 会是 None,而 tool_calls 会包含需要调用的函数信息。这就像模型说:“我需要先查一下数据库,然后再回答你。”
接下来,我们需要执行函数并将结果返回给模型:
available_functions = {"query_by_product_name": query_by_product_name}
function_call = response.choices[0].message.tool_calls[0]
function_args = json.loads(function_call.function.arguments)
function_name = function_call.function.name
function_to_call = available_functions[function_name]
function_response = function_to_call(**function_args)
接下来,我们将函数调用结果提供回大模型。我们需要将函数的输入输出放到一个 JSON 格式参数中:
content = json.dumps({
"product_name": product_name,
"query_by_product_name":final_res
}, ensure_ascii=False),
返回:
('{"product_name": "球", "query_by_product_name": [["001", "足球", "高品质职业比赛用球,符合国际标准", "圆形,直径22 cm", "职业比赛、学校体育课", "耐克", 120.0, 50], ["002", "羽毛球拍", "轻量级,适合初中级选手,提供优秀的击球感受", "碳纤维材质,重量85 g", "业余比赛、家庭娱乐", "尤尼克斯", 300.0, 30], ["003", "篮球", "室内外可用,耐磨耐用,适合各种天气条件", "皮质,标准7号球", "学校、社区运动场", "斯伯丁", 200.0, 40], ["008", "乒乓球拍套装", "包括两只拍子和三个球,适合家庭娱乐和业余训练", "标准尺寸,拍面防滑处理", "家庭、社区", "双鱼", 160.0, 35]]}',)
我们还需要传递函数调用产生的 tool_call_id 字段,这个 ID 用于将函数调用结果与对应的函数调用请求关联起来:
response.choices[0].message.tool_calls[0].id # Returns call_6Axa00hfMAVSzSGEBMIjXFZw
合并起来,创建 function calling 结果的消息历史:
function_call_result_message = {"role": "tool", "content": str(content), "tool_call_id": response.choices[0].message.tool_calls[0].id}
最后,构建完整的 Messages 再次进行调用:
messages = [
{"role": "user", "content": "你好,你家都卖什么球?"},
response.choices[0].message,
function_call_result_message
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
)
# Print result
print(response.choices[0].message.content)
打印:
我们家主要出售以下几种球:
1. **足球**
- 描述:高品质职业比赛用球,符合国际标准
- 尺寸:圆形,直径22 cm
- 用途:职业比赛、学校体育课
- 品牌:耐克
- 价格:120元
2. **羽毛球拍**
- 描述:轻量级,适合初中级选手,提供优秀的击球感受
- 材质:碳纤维,重量85 g
- 用途:业余比赛、家庭娱乐
- 品牌:尤尼克斯
- 价格:300元
3. **篮球**
- 描述:室内外可用,耐磨耐用,适合各种天气条件
- 材质:皮质,标准7号球
- 用途:学校、社区运动场
- 品牌:斯伯丁
- 价格:200元
4. **乒乓球拍套装**
- 描述:包括两只拍子和三个球,适合家庭娱乐和业余训练
...
- 品牌:双鱼
- 价格:160元
如果你对某一款产品感兴趣或者需要更多信息,可以询问我!
💡 理解要点:Function Calling 的完整流程就像医生看病:先问诊(用户提问),然后判断需要做什么检查(模型决定调用函数),执行检查(执行函数),最后根据检查结果给出诊断(模型生成最终回复)。
2.3 Function Calling 完整代码
最后,我们把上面部分的代码进行一个整合,形成一个完整的、可运行的 Function Calling 示例:
import sqlite3
import json
from openai import OpenAI
client = OpenAI()
def query_by_product_name(product_name):
# Connect to SQLite database
conn = sqlite3.connect('SportsEquipment.db')
cursor = conn.cursor()
# Use SQL query to find products by name. The '%' symbol allows partial matching.
cursor.execute("SELECT * FROM products WHERE product_name LIKE ?", ('%' + product_name + '%',))
# Fetch all queried data
rows = cursor.fetchall()
# Close connection
conn.close()
return rows
messages = []
available_functions = {"query_by_product_name": query_by_product_name}
while True:
prompt = input('\n提出一个问题: ')
if prompt.lower() == "退出":
break # Exit the loop if input is "退出"
# Add user's question to message list
messages.append({'role': 'user', 'content': prompt})
# Check if external function needs to be called
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
parallel_tool_calls=False # Note: generally parallel function calls are not needed
)
# Extract response content
response = completion.choices[0].message
tool_calls = completion.choices[0].message.tool_calls
# Handle external function calls
if tool_calls:
function_name = tool_calls[0].function.name
function_args = json.loads(tool_calls[0].function.arguments)
function_response = available_functions[function_name](**function_args)
messages.append(response)
messages.append(
{
"role": "tool",
"name": function_name,
"content": str(function_response),
"tool_call_id": tool_calls[0].id,
}
)
second_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
)
# Get final result
final_response = second_response.choices[0].message.content
messages.append({'role': 'assistant', 'content': final_response})
print(final_response)
else:
# Print response and add to message list
print(response.content)
messages.append({'role': 'assistant', 'content': response.content})
🔍 实际例子:我们来看一下运行过后几轮问答后的结果:
[{'role': 'user', 'content': '你好'},
{'role': 'assistant', 'content': '你好!有什么我可以帮助你的吗?'},
{'role': 'user', 'content': '什么是人工智能'},
{'role': 'assistant',
'content': '人工智能(Artificial Intelligence,简称AI)是计算机科学的一个分支,旨在创建可以执行通常需要人类智能的任务的计算机系统。这些任务包括但不限于:\n\n1. **学习**:AI系统可以通过数据学习和改进其性能,例如机器学习算法。\n2. **推理**:AI可以使用逻辑推理进行决策,并在给定的信息基础上得出结论。\n3. **自我修正**:AI可以通过经验调整其行为和决策。\n4. **理解自然语言**:AI可以处理和理解人类语言,包括语音识别和自然语言处理。\n5. **视觉识别**:AI能够识别和处理图像,例如图像分类和物体识别。\n\n人工智能有广泛的应用,包括语音助手(如Siri和Alexa)、聊天机器人、推荐系统、自动驾驶汽车和医疗诊断等。随着技术的发展,AI正变得越来越普及,深刻地影响着各个行业和我们的日常生活。'},
{'role': 'user', 'content': '你家卖什么球?'},
ChatCompletionMessage(content=None, refusal=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_onnMDW8MsHFS8jA8qqqR511P', function=Function(arguments='{"product_name":"球"}', name='query_by_product_name'), type='function')]),
{'role': 'tool',
'name': 'query_by_product_name',
'content': "[('001', '足球', '高品质职业比赛用球,符合国际标准', '圆形,直径22 cm', '职业比赛、学校体育课', '耐克', 120.0, 50), ('002', '羽毛球拍', '轻量级,适合初中级选手,提供优秀的击球感受', '碳纤维材质,重量85 g', '业余比赛、家庭娱乐', '尤尼克斯', 300.0, 30), ('003', '篮球', '室内外可用,耐磨耐用,适合各种天气条件', '皮质,标准7号球', '学校、社区运动场', '斯伯丁', 200.0, 40), ('008', '乒乓球拍套装', '包括两只拍子和三个球,适合家庭娱乐和业余训练', '标准尺寸,拍面防滑处理', '家庭、社区', '双鱼', 160.0, 35)]",
'tool_call_id': 'call_onnMDW8MsHFS8jA8qqqR511P'},
{'role': 'assistant',
'content': '我们有几种球类产品,可以为您提供不同的选择:\n\n1. **足球**\n - 描述:高品质职业比赛用球,符合国际标准\n - 特点:圆形,直径22 cm\n - 用途:职业比赛、学校体育课\n - 品牌:耐克\n - 价格:120.0元\n - 库存:50个\n\n2. **篮球**\n - 描述:室内外可用,耐磨耐用,适合各种天气条件\n - 特点:皮质,标准7号球\n - 用途:学校、社区运动场\n - 品牌:斯伯丁\n - 价格:200.0元\n - 库存:40个\n\n3. **羽毛球拍**(此外也有羽毛球拍,可配合使用)\n - 描述:轻量级,适合初中级选手,提供优秀的击球感受\n - 特点:碳纤维材质,重量85 g\n - 用途:业余比赛、家庭娱乐\n - 品牌:尤尼克斯\n - 价格:300.0元\n - 库存:30个\n\n4. **乒乓球拍套装**(包含球)\n - 描述:包括两只拍子和三个球,适合家庭娱乐和业余训练\n - 特点:标准尺寸,拍面防滑处理\n - 用途:家庭、社区\n - 品牌:双鱼\n - 价格:160.0元\n - 库存:35个\n\n如果您对某种产品感兴趣,或者有其他问题,请告诉我!'},
{'role': 'user', 'content': '你家卖衣服吗?'},
ChatCompletionMessage(content=None, refusal=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_9LwdjmarRTiu4p6X9aWzAfEI', function=Function(arguments='{"product_name":"衣服"}', name='query_by_product_name'), type='function')]),
{'role': 'tool',
'name': 'query_by_product_name',
'content': '[]',
'tool_call_id': 'call_9LwdjmarRTiu4p6X9aWzAfEI'},
{'role': 'assistant',
'content': '目前我们并不销售衣服。如果你对其他商品感兴趣,或者有其他问题需要帮助,欢迎随时告诉我!'}]
💡 理解要点:从上面的对话历史可以看到,模型能够智能地判断什么时候需要调用函数(查询产品时),什么时候可以直接回答(一般性问题)。即使查询结果为空(如查询衣服),模型也能根据结果给出合适的回复。
3. ReAct Agent:从提示工程到代理工程
Function Calling 相对于单独的 OpenAI API 调用,可以实现函数调用,但是对于复杂的应用来说依然有较大差距。这里开始引入 AI Agent 概念。
为什么需要 AI Agent? 想象你正在使用刚刚购买的华为手机,当你想要拍照时,你会打开相机应用。这个相机应用就是一个人工智能助手,它提供了拍照的功能。你通过点击相机图标来调用这个功能,然后就可以拍照、编辑照片等。在这个比喻中,相机应用就是预定义的函数,而打开相机应用并使用其功能的技术就是Function Calling。
而对于人工智能代理,想象一个机器人管家。这个机器人能够理解你的指令,比如"请打扫客厅",并且能够执行这个任务。机器人管家就是一个 AI Agent,它能够自主地感知环境(比如识别哪些地方是客厅),做出决策(比如决定打扫的顺序和方法),并执行任务(比如使用吸尘器打扫)。在这个比喻中,机器人管家是一个能够自主行动和做出复杂决策的实体,而其背后支撑其做这一系列复杂任务的技术,就是AI Agent。
💡 理解要点:Function Calling 就像使用单个工具,而 AI Agent 就像一个能够自主规划、执行多个步骤任务的智能助手。Agent 能够根据情况自主决定使用哪些工具,以及如何使用它们。
3.1 用 Prompt 实现简单的代理工程:思考,行动,观察
让我们通过一个具体的场景来理解代理工程。比如这样一个场景:
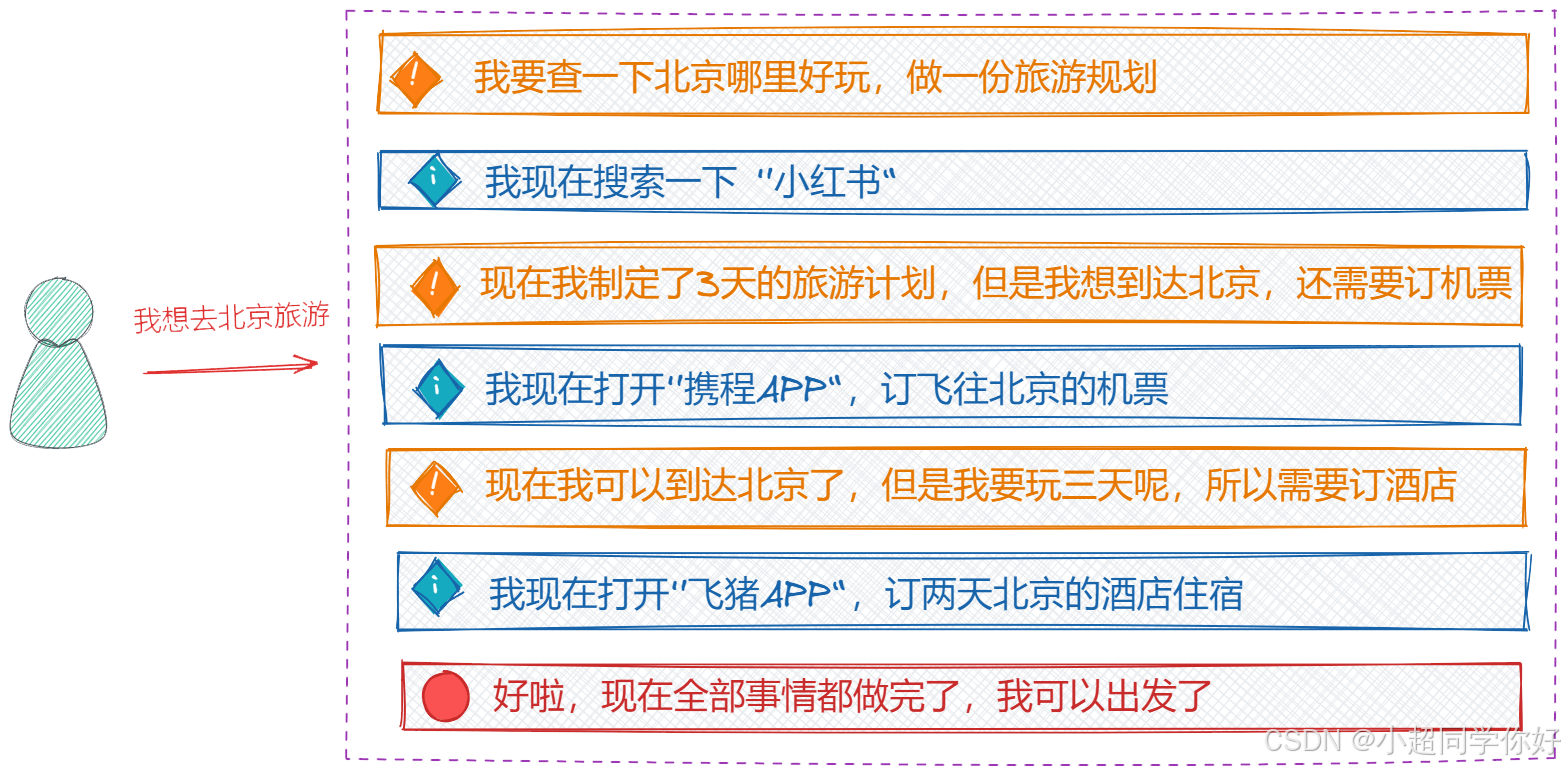
当"我"萌生了去北京旅游的想法时,按照常规的出游思路,我需要进行以下前期准备和计划:
想法1: 首先,我需要了解北京的热门景点并制定一个旅游行程。
行动1: 我会在小红书上搜索相关的旅游攻略。
观察1: 根据攻略,我制定了一个为期三天的旅游计划。接下来,我需要考虑如何到达北京,这意味着我得订购机票。
想法2: 我需要预订飞往北京的机票。
行动2: 我现在使用携程APP来订购机票。
观察2: 机票已经订好,我已经能够到达北京了。既然计划在那里停留三天,我还需要解决住宿的问题。
想法3: 接下来,我要预订酒店,以确保北京行的住宿安排。
行动3: 我在飞猪APP上搜索并预订了北京的酒店。
观察3: 酒店预订已确认。
结论: 现在所有的准备工作都已完成,我可以放心出发了。
🔍 实际例子:在上述北京旅游的规划过程中,初始输入仅为一条意图:“我想去北京旅游”。接下来的所有步骤,包括在小红书上查找旅游信息、通过携程APP订票、以及使用飞猪APP预订酒店,都是一系列的思考和行动过程。
为什么需要代理工程? 提示工程是一种非常经济有效的方法,我们已经习惯于利用它来增强大语言模型(LLM)处理复杂任务的能力。那么对于上述过程,如果也想让大模型通过提示工程的这种方式去自主完成,其实并不复杂,这里我们先给出提示示例:
prompt = """
You run in a loop of Thought, Action, Observation, Answer.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you.
Observation will be the result of running those actions.
Answer will be the result of analysing the Observation
Your available actions are:
xiaohongshu:
e.g. xiaohongshu: Beijing travel tips
Runs a search through the Xiaohongshu API and returns travel tips and recommendations for Beijing.
ctrip:
e.g. ctrip: flights to Beijing
Runs a search through the Ctrip API to find available flights to Beijing.
Always use the Xiaohongshu and Ctrip APIs if you have the opportunity to do so.
Example session:
Question: I'm planning a trip to Beijing, what should I do first?
Thought: I should find out about the attractions and tips for visiting Beijing on Xiaohongshu.
Action: xiaohongshu: Beijing travel tips
Observation: The search returns a list of popular travel tips and must-visit attractions in Beijing.
Answer: Start by researching Beijing's must-visit attractions and travel tips on Xiaohongshu. Then, look for available flights on Ctrip and consider accommodation options.
....
"""
很惊喜的是,这样的提示方法确实可以让大模型在接收到输入以后,自动地进入决策分析过程。
💡 理解要点:所谓的代理工程,一种最简单的理解是:更加复杂的提示工程。从提示工程到代理工程的过渡体现在:不再只是提供单一的任务描述,而是明确界定代理所需承担的具体职责,详尽概述完成这些任务所需采取的操作,并清楚指定执行这些操作所必须具备的能力,形成一个高级的认知模型。
3.2 ReAct Agent 基本理论
ReAct Agent 也称为 ReAct,是一个用于提示大语言模型的框架,它首次在 2022 年 10 月的论文《ReAct:Synergizing Reasoning and Acting in Language Models》中引入,并于 2023 年 3 月修订。该框架的开发是为了协同大语言模型中的推理和行动,使它们更加强大、通用和可解释。通过交叉推理和行动,ReAct 使智能体能够动态地在产生想法和特定于任务的行动之间交替。
ReAct:https://react-lm.github.io/
为什么叫 ReAct? 框架有两个过程,由 Reason(推理)和 Act(行动)结合而来。从本质上讲,这种方法的灵感来自于人类如何通过和谐地结合思维和行动来执行任务,就像我们上面"我想去北京旅游"这个真实示例一样。
3.2.1 思想链(CoT):推理的基础
首先第一部分 Reason,它基于一种推理技术——思想链(CoT)。CoT 是一种提示工程,通过将输入分解为多个逻辑思维步骤,帮助大语言模型执行推理并解决复杂问题。这使得大模型能够按顺序规划和解决任务的每个部分,从而更准确地获得最终结果,具体包括:
-
分解问题:当面对复杂的任务时,CoT 方法不是通过单个步骤解决它,而是将任务分解为更小的步骤,每个步骤解决不同方面的问题。就像解数学题一样,我们需要先理解题目,然后分步骤求解。
-
顺序思维:思维链中的每一步都建立在上一步的结果之上。这样,模型就能从头到尾构造出一条逻辑推理链。就像搭积木一样,每一步都建立在前一步的基础上。
🔍 实际例子:比如,一家商店以 100 元的价格出售产品。如果商店降价20%,然后加价10%,产品的最终价格是多少?
- 步骤 1 — 计算降价20%后的价格:如果原价是100元,商店降价20%,我们计算降价后的价格:100 × (1–0.2) = 80.
- 步骤 2 — 计算上涨 10% 后的价格:降价后,产品价格为 80 元。现在商店涨价10%:80 × (1 + 0.1) = 88.
- 结论:先降价后加价后,产品最终售价为88元。
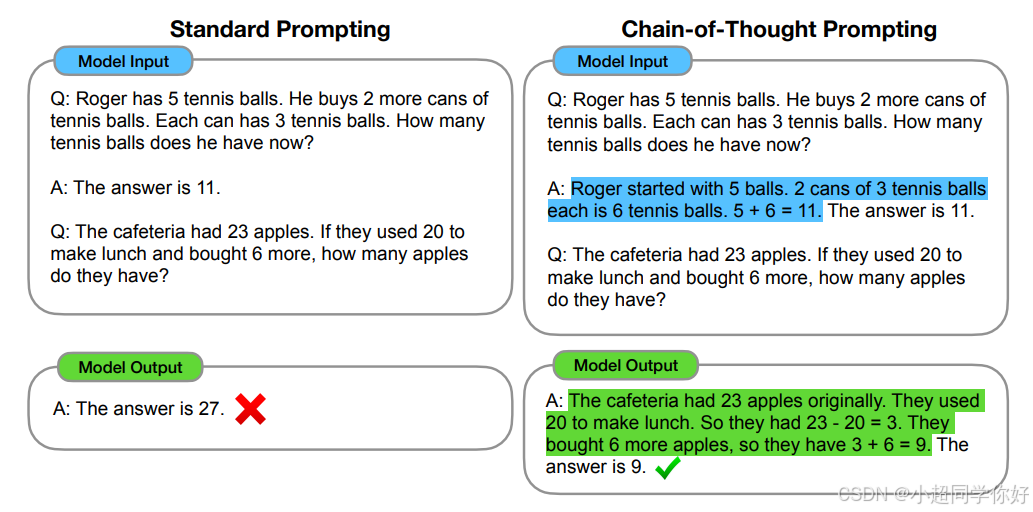
3.2.2 ReAct:解决 CoT 的局限性
但是,在 CoT 提示工程的限定下,大模型仍然会产生幻觉。因为经过长期的使用,大家发现在推理的中间阶段会产生不正确的答案或上下游的传播错误,所以,Google DeepMind 团队开发了 ReAct 的技术来弥补这一点。
为什么需要 ReAct? ReAct 采用的是 思想-行动-观察循环的思路,其中代理根据先前的观察进行推理以决定行动。这个迭代过程使其能够根据其行动的结果来调整和完善其方法。就像科学家做实验一样,先提出假设(Thought),然后做实验(Action),观察结果(Observation),再根据结果调整假设,如此循环直到找到答案。
如下图所示:
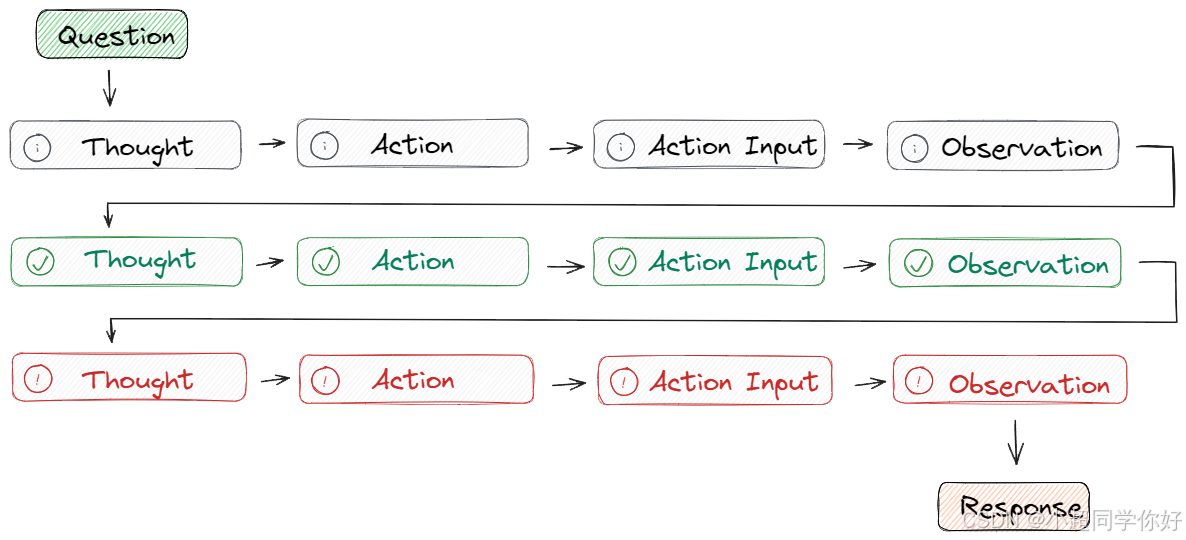
在这个过程中:
Question指的是用户请求的任务或需要解决的问题Thought用来确定要采取的行动并向大模型展示如何创建/维护/调整行动计划Action Input是用来让大模型与外部环境(例如搜索引擎、维基百科)的实时交互,包括具有预定义范围的 APIObservation阶段会观察执行操作结果的输出,重复此过程直至任务完成
💡 理解要点:ReAct 的核心优势在于它能够通过观察行动的结果来验证和调整推理过程,从而减少幻觉和错误。这就像做数学题时,每算一步都要检查一下结果是否合理。
3.3 一个例子复现 ReAct 过程
现在让我们通过一个完整的例子来复现 ReAct 过程,从设计提示到实现完整的 Agent 系统。
3.3.1 Step 1. 设计完整的代理工程提示
正如我们上面介绍的 ReAct 原理,其本质是采用了思想-行动-观察的循环过程来逐步实现复杂任务,那么其系统提示(System Prompt)就可以设计如下:
system_prompt = """
You run in a loop of Thought, Action, Observation, Answer.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you.
Observation will be the result of running those actions.
Answer will be the result of analysing the Observation
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
fetch_real_time_info:
e.g. fetch_real_time_info: Django
Returns a real info from searching SerperAPI
Always look things up on fetch_real_time_info if you have the opportunity to do so.
Example session:
Question: What is the capital of China?
Thought: I should look up on SerperAPI
Action: fetch_real_time_info: What is the capital of China?
PAUSE
You will be called again with this:
Observation: China is a country. The capital is Beijing.
Thought: I think I have found the answer
Action: Beijing.
You should then call the appropriate action and determine the answer from the result
You then output:
Answer: The capital of China is Beijing
Example session
Question: What is the mass of Earth times 2?
Thought: I need to find the mass of Earth on fetch_real_time_info
Action: fetch_real_time_info : mass of earth
PAUSE
You will be called again with this:
Observation: mass of earth is 1,1944×10e25
Thought: I need to multiply this by 2
Action: calculate: 5.972e24 * 2
PAUSE
You will be called again with this:
Observation: 1,1944×10e25
If you have the answer, output it as the Answer.
Answer: The mass of Earth times 2 is 1,1944×10e25.
Now it's your turn:
"""
💡 理解要点:提示词的第一部分告诉大模型如何通过我们之前看到的流程的标记部分循环处理问题,第二部分描述计算和搜索的工具操作,最后是一个示例的会话。整体结构非常清晰,就像给模型提供了一份操作手册。
3.3.2 Step 2. 定义工具
定义工具的方法与上一章节介绍 Function Calling 一样,我们仅需要确定工具的函数的入参及返回的结果即可。对于如上我们设计的场景,一共需要两个工具,其一是用来根据关键词检索 Serper API,返回详细的检索信息。其二是一个计算函数,接收的入参是需要执行计算操作的数值,返回最终的计算结果。代码如下所示:
import requests
import json
def fetch_real_time_info(query):
# API parameters
params = {
'api_key': '0f31d8c5561bdaa4c71ad7c86f6e63a4a26cead9', # Use your own API key
'q': query, # Query parameter, representing the question to search
'num': 1 # Number of results to return, set to 1, API will return one relevant search result
}
# Send GET request to Serper API
api_result = requests.get('https://google.serper.dev/search', params)
# Parse returned JSON data
search_data = api_result.json()
# Extract and return queried information
if search_data["organic"]:
return search_data["organic"][0]["snippet"]
else:
return "没有找到相关结果。"
第二个函数 calculate 接收一个字符串参数 operation,该字符串代表一个数学运算表达式,并使用 Python 的内置函数 eval 来执行这个表达式,然后返回运算的结果。函数的返回类型被指定为 float,意味着期望返回值为浮点数。
def calculate(operation: str) -> float:
return eval(operation)
最后,定义一个名为 available_actions 的字典,用来存储可用的函数引用,用来在后续的 Agent 实际执行 Action 时可以根据需要调用对应的功能。
available_actions = {
"fetch_real_time_info": fetch_real_time_info,
"calculate": calculate,
}
💡 理解要点:工具定义就像给 Agent 配备工具箱,每个工具都有特定的功能。Agent 可以根据任务需要选择合适的工具。
3.3.3 Step 3. 开发大模型交互接口
接下来,定义大模型交互逻辑接口。这里我们实现一个聊天机器人的 Python 类,将系统提示(system)与用户(user)或助手的提示(assistant)分开,并在实例化 ChatBot 时对其进行初始化。核心逻辑为 __call__ 函数负责存储用户消息和聊天机器人的响应,调用 execute 来运行代理。完整代码如下所示:
import openai
import re
import httpx
from openai import OpenAI
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
client = OpenAI()
completion = client.chat.completions.create(model="gpt-4o", messages=self.messages)
return completion.choices[0].message.content
-
__init__方法用来接收系统提示(System Prompt),并追加到全局的消息列表中。就像给聊天机器人设置初始身份和规则。 -
__call__方法是Python类的一个特殊方法,当对一个类的实例像调用函数一样传递参数并执行时,实际上就是在调用这个类的__call__方法。其内部会调用execute方法。这让我们可以像使用函数一样使用这个类。 -
execute方法实际上就是与OpenAI的 API 进行交互,发送累积的消息历史(包括系统消息、用户消息和之前的回应)到 OpenAI 的聊天模型,返回最终的响应。
3.3.4 定义代理循环逻辑
在代理循环中,其内部逻辑如下图所示:
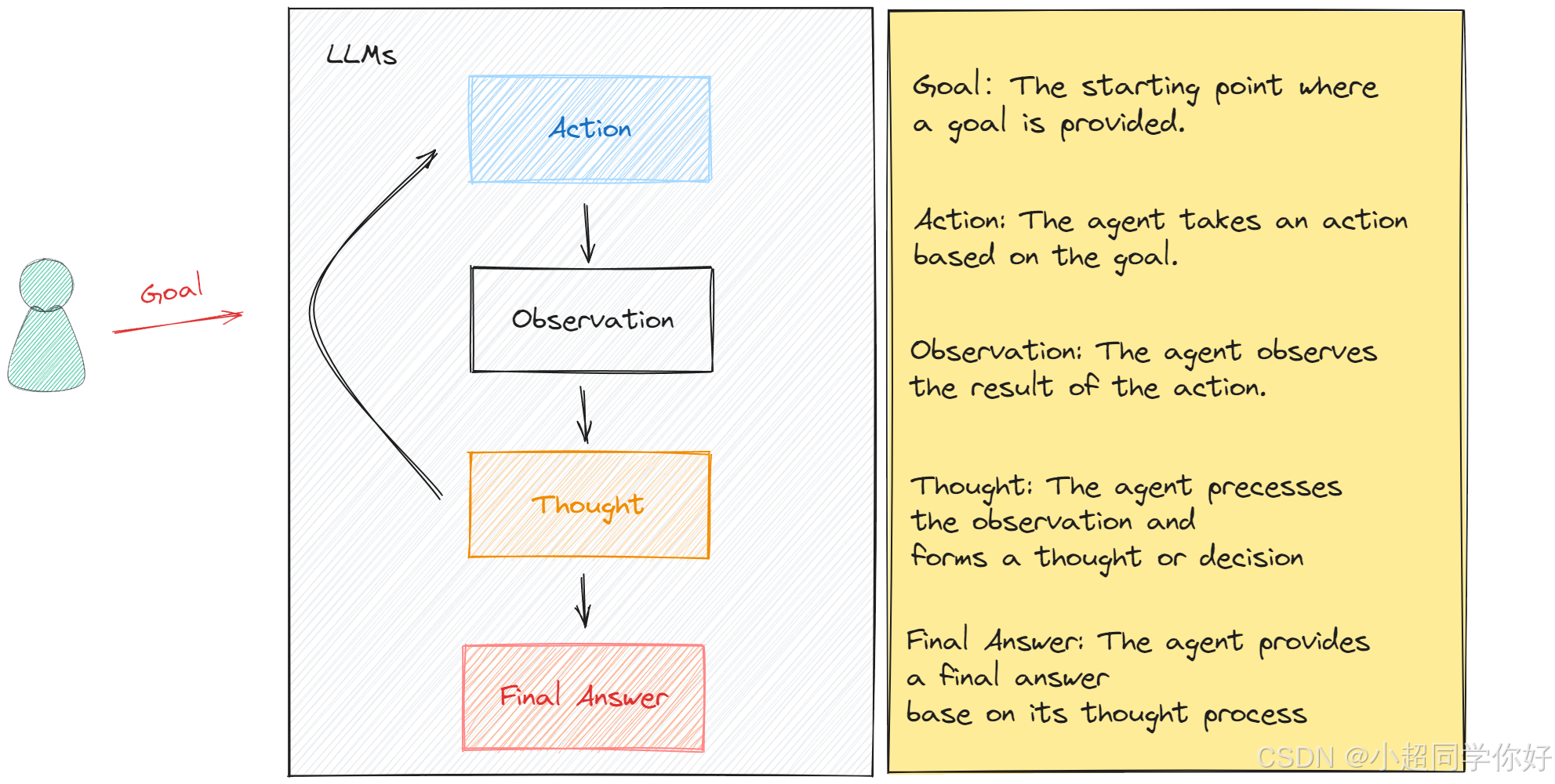
从 Thought 到 Action,最后到 Observation 状态,是一个循环的逻辑,而循环的次数,取决于大模型将用户的原始 Goal 分成了多少个子任务。所有在这样的逻辑中,我们需要去处理的是:
-
判断大模型当前处于哪一个状态阶段:就像判断一个人现在在做什么一样,我们需要识别模型当前处于思考、行动还是观察阶段。
-
如果停留在
Action阶段,需要像调用 Function Calling 的过程一样,先执行工具,再将工具的执行结果传递给Observation状态阶段:这就像执行一个动作后,需要观察结果,然后根据结果决定下一步。
首先需要明确,需要执行操作的过程是:大模型识别到用户的意图中需要调用工具,那么其停留的阶段一定是在 Action: xxxx : xxxx 阶段,其中第一个 xxxx,就是调用的函数名称,第二个 xxxx,就是调用第一个 xxxx 函数时,需要传递的参数。这里就可以通过正则表达式来进行捕捉。如下所示:
# (\w+) is a capture group that matches one or more alphanumeric characters (including underscores). This part is used to capture the action name specified in the command
# (.*) is another capture group that matches any character after the colon until the end of the string. This part is used to capture the parameters of the command.
action_re = re.compile('^Action: (\w+): (.*)$')
测试代码如下:
match = action_re.match("Action: fetch_real_time_info: mass of earth")
if match:
print(match.group(1)) # 'fetch_real_time_info'
print(match.group(2)) # 'mass of earth'
💡 理解要点:正则表达式就像一把钥匙,能够从模型的输出中提取出我们需要的信息(函数名和参数),这样我们就可以执行相应的操作了。
由此,我们定义了如下的一个 AgentExecutor 函数。该函数实现一个循环,检测状态并使用正则表达式提取当前停留的状态阶段。不断地迭代,直到没有更多的(或者我们已达到最大迭代次数)调用操作,再返回最终的响应。完整代码如下:
action_re = re.compile('^Action: (\w+): (.*)$')
def AgentExecutor(question, max_turns=5):
i = 0
bot = ChatBot(system_prompt)
# Use next_prompt to identify the stage input for each subtask
next_prompt = question
while i < max_turns:
i += 1
# This calls the __call__ method of the ChatBot class
result = bot(next_prompt)
print(f"result:{result}")
# Use regex here to determine if we've reached the Action stage that requires function calls
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# Extract the tool name and parameters required by the tool
action, action_input = actions[0].groups()
if action not in available_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(f"running: {action} {action_input}")
observation = available_actions[action](action_input)
print(f"Observation: {observation}")
next_prompt = "Observation: {}".format(observation)
else:
return bot.messages
🔍 实际例子:运行 AI Agent 进行测试:AgentExecutor("世界上最长的河流是什么?")。打印:
result:Thought: 我需要查找一下世界上最长的河流信息。
Action: fetch_real_time_info: 世界上最长的河流
running: fetch_real_time_info 世界上最长的河流
Observation: 1. 尼罗河(Nile). 6670km ; 2. 亚马逊河(Amazon). 6400km ; 3. 长江(Chang Jiang). 6397km ; 4. 密西西比河(Mississippi). 6020km.
result:Answer: 世界上最长的河流是尼罗河,全长6670公里。
我们换一个需要计算的例子:AgentExecutor("20 * 15 等于多少")。打印:
result:Thought: 用户需要我计算 20 乘以 15 的结果。
Action: calculate: 20 * 15
running: calculate 20 * 15
Observation: 300
result:Answer: 20 乘以 15 等于 300。
💡 理解要点:从上面的例子可以看到,ReAct Agent 能够:
- 自主思考:根据问题判断需要做什么(Thought)
- 执行行动:调用相应的工具(Action)
- 观察结果:获取工具执行的结果(Observation)
- 生成答案:根据观察结果生成最终答案(Answer)
总结
从上面我们实现的案例中,非常明显地发现,ReAct(推理和行动)框架通过将推理和行动整合到一个有凝聚力的操作范式中,能够实现动态和自适应问题解决,从而允许与用户和外部工具进行更复杂的交互。
ReAct 的核心价值:
- 动态推理:Agent 能够根据观察结果动态调整推理过程,而不是盲目地按照预设步骤执行
- 错误纠正:通过观察行动结果,Agent 能够及时发现和纠正错误,减少幻觉
- 灵活适应:Agent 能够根据不同的任务需求,自主选择合适的工具和策略
- 可解释性:整个推理过程是透明的,每一步的思考和行动都可以被追踪和理解
应用场景:
- 自动化客户服务:能够理解客户问题,查询相关信息,并提供准确的回答
- 复杂决策系统:能够分析多种因素,做出合理的决策
- 智能助手:能够完成多步骤任务,如规划旅行、安排会议等
- 数据分析:能够查询数据、进行计算、生成报告
这种方法不仅增强了大模型处理复杂查询的能力,还提高了其在多步骤任务中的性能,使其适用于从自动化客户服务到复杂决策系统的广泛应用。
🔍 实际例子:想象一个智能旅行助手 Agent,当你说"我想去北京旅游"时,它会:
- 思考:需要了解景点、预订机票和酒店
- 行动:搜索旅游攻略、查询航班信息、查找酒店
- 观察:获取搜索结果和价格信息
- 再思考:根据信息制定最佳方案
- 行动:预订机票和酒店
- 最终答案:提供完整的旅行计划
这就是 ReAct Agent 的强大之处——它能够像人类一样,通过思考、行动、观察的循环,逐步完成复杂的任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)