从零到一掌握 LangChain RAG:核心流程与完整实战
·
前言
检索增强生成(Retrieval-Augmented Generation, RAG)是解决大模型 “幻觉”、知识时效性问题的核心技术,而 LangChain 是 RAG 落地的主流框架。本文从核心流程拆解→关键环节实操→完整项目落地 全维度讲解 LangChain RAG,最终实现一个可直接部署的 AI 智能 PDF 问答助手(Streamlit 可视化界面)。
一、RAG 核心流程回顾
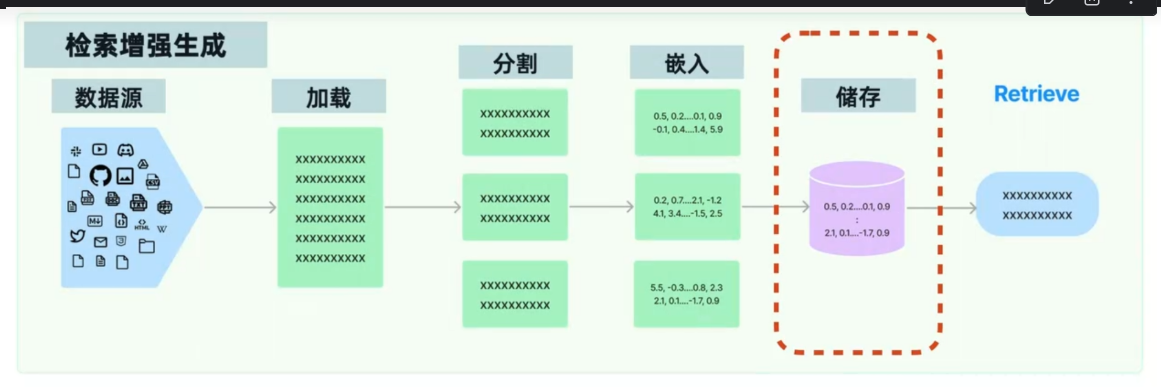
RAG 分为离线构建向量库和在线检索生成两大阶段,完整流程如下:
数据源 → Loading(加载)→ Splitting(分割)→ Embedding(嵌入)→ Storage(存储)→ Retrieve(检索)→ Generation(生成)
二、Loading:多数据源加载
核心是将异构数据源转换为 LangChain 统一的Document对象,前文已演示 PDF、维基百科加载,核心依赖:
pip install langchain langchain-community pypdf wikipedia
三、Splitting:文本分块核心实操
3.1 环境准备
pip install langchain_text_splitters
3.2 核心代码(PDF 分块)
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载PDF
loader = PyPDFLoader("./llama2.pdf")
docs = loader.load()
# 中文友好的递归分块器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 单个Chunk字符数
chunk_overlap=50, # 重叠字符数(保证语义连贯)
separators=["\n\n", "\n", "。", "!", "?", ",", "、", ""] # 中文分割符
)
texts = text_splitter.split_documents(docs)
# 查看分块结果
print(f"原始页数:{len(docs)},分块数:{len(texts)}")
print(texts[2].page_content)
四、Embedding:文本向量嵌入实操
4.1 环境准备
pip install openai dashscope
4.2 核心代码(阿里云 DashScope 为例)
from langchain_community.embeddings import DashScopeEmbeddings
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key="你的API密钥" # 替换为真实密钥
)
# 测试嵌入
query_vector = embeddings.embed_query("卢浮宫名字由来")
doc_vectors = embeddings.embed_documents(["文本1", "文本2"])
print(f"查询向量长度:{len(query_vector)},文档向量数:{len(doc_vectors)}")
五、Storage & Retrieve:向量库存储与检索
5.1 环境准备
pip install faiss-cpu
5.2 核心代码(FAISS 向量库)
from langchain_community.vectorstores import FAISS
# 构建向量库
db = FAISS.from_documents(texts, embeddings)
# 构建检索器
retriever = db.as_retriever(search_kwargs={"k": 3}) # 返回Top3相似文本
# 检索测试
retrieved_docs = retriever.invoke("卢浮宫是否可以用闪光灯?")
print(retrieved_docs[0].page_content)
六、Conversational RAG:带记忆的多轮对话
6.1 核心代码
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain_openai import ChatOpenAI
# 初始化大模型(通义千问兼容OpenAI接口)
model = ChatOpenAI(
model="qwen3.5-plus",
openai_api_key="你的API密钥",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 初始化对话记忆
memory = ConversationBufferMemory(
return_messages=True,
memory_key='chat_history',
output_key='answer'
)
# 构建对话链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=model,
retriever=retriever,
memory=memory
)
# 多轮问答
result1 = qa_chain.invoke({"question": "卢浮宫名字由来?"})
result2 = qa_chain.invoke({"question": "对应的拉丁语是什么?"})
print(result2['answer'])
七、实战项目:AI 智能 PDF 问答助手(Streamlit 可视化版)
7.1 项目功能概述
基于 Streamlit 搭建可视化界面,实现:
- 📤 PDF 文件上传(支持临时文件自动清理)
- 🔑 自定义 API 密钥输入
- ❓ 多轮 PDF 问答(带对话记忆)
- 🗂️ 对话历史查看 / 清空
- 🚨 异常处理与友好提示
7.2 完整可运行代码
python
运行
import os
import tempfile
import streamlit as st
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import FAISS
def qa_agent(openai_api_key, memory, uploaded_file, question):
"""
PDF问答核心函数
:param openai_api_key: API密钥
:param memory: 对话记忆对象
:param uploaded_file: Streamlit上传的PDF文件对象
:param question: 用户问题
:return: 问答结果
"""
# 初始化大模型
model = ChatOpenAI(
model="qwen3.5-plus",
openai_api_key=openai_api_key,
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 创建临时PDF文件(解决Streamlit上传文件无本地路径问题)
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as temp_file:
temp_file.write(uploaded_file.read())
temp_file_path = temp_file.name
try:
# 1. 加载PDF
loader = PyPDFLoader(temp_file_path)
docs = loader.load()
# 2. 文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n", "。", "!", "?", ",", "、", ""]
)
texts = text_splitter.split_documents(docs)
# 3. 嵌入模型
embeddings_model = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key=openai_api_key
)
# 4. 构建向量库
db = FAISS.from_documents(texts, embeddings_model)
retriever = db.as_retriever()
# 5. 构建对话链
qa = ConversationalRetrievalChain.from_llm(
llm=model,
retriever=retriever,
memory=memory
)
# 6. 执行问答
response = qa.invoke({"question": question})
return response
finally:
# 无论是否出错,都删除临时文件
if os.path.exists(temp_file_path):
try:
os.remove(temp_file_path)
except:
pass
# ===================== Streamlit界面配置 =====================
# 初始化会话状态
if "memory" not in st.session_state:
st.session_state["memory"] = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history",
output_key="answer"
)
if "chat_history" not in st.session_state:
st.session_state["chat_history"] = []
# 页面基础配置
st.set_page_config(
page_title="AI智能PDF问答工具",
page_icon="📑",
layout="centered"
)
# 主标题
st.title("📑 AI智能PDF问答工具")
# 1. API密钥输入区域
st.subheader("🔑 API设置")
api_col1, api_col2 = st.columns([3, 1])
with api_col1:
openai_api_key = st.text_input(
"请输入OpenAI API密钥",
type="password",
placeholder="sk-..."
)
with api_col2:
st.markdown("[获取API密钥](https://bailian.console.aliyun.com/)")
st.divider()
# 2. PDF文件上传区域
st.subheader("📁 文件上传")
uploaded_file = st.file_uploader(
"点击或拖拽PDF文件到此处",
type="pdf",
help="仅支持PDF格式文件"
)
# 3. 问题输入区域
st.subheader("❓ 提问")
question = st.text_input(
"请输入您的问题...",
disabled=not uploaded_file,
placeholder="例如:总结PDF的核心内容 / 解释某个概念..."
)
# 4. 核心处理逻辑
if uploaded_file and question:
if not openai_api_key:
st.warning("⚠️ 请先输入API密钥后再提问")
else:
with st.spinner("🤖 AI正在分析PDF并回答问题,请稍等..."):
try:
# 调用问答函数
response = qa_agent(
openai_api_key,
st.session_state["memory"],
uploaded_file,
question
)
# 显示回答结果
st.subheader("📝 回答")
st.write(response["answer"])
# 更新对话历史
st.session_state["chat_history"] = response["chat_history"]
except Exception as e:
st.error(f"❌ 处理失败:{str(e)}")
# 5. 对话历史展示
if st.session_state["chat_history"]:
st.divider()
with st.expander("🗣️ 历史对话记录", expanded=False):
st.write("---")
# 遍历对话历史(一问一答为一组)
for i in range(0, len(st.session_state["chat_history"]), 2):
if i + 1 < len(st.session_state["chat_history"]):
human_msg = st.session_state["chat_history"][i]
ai_msg = st.session_state["chat_history"][i + 1]
st.markdown(f"**👤 你**: {human_msg.content}")
st.markdown(f"**🤖 AI**: {ai_msg.content}")
if i < len(st.session_state["chat_history"]) - 2:
st.write("---")
# 清空历史按钮
if st.button("🔄 清空对话历史"):
st.session_state["memory"] = ConversationBufferMemory(
return_messages=True,
memory_key="chat_history",
output_key="answer"
)
st.session_state["chat_history"] = []
st.success("✅ 对话历史已清空")
st.rerun() # 新版Streamlit用rerun替代experimental_rerun
# 6. 使用说明
st.divider()
st.subheader("ℹ️ 使用说明")
st.write("1. 输入阿里云DashScope API密钥(兼容OpenAI格式)")
st.write("2. 上传需要问答的PDF文件(建议文件大小<50MB)")
st.write("3. 输入关于PDF内容的问题,支持多轮上下文关联提问")
st.write("4. 可展开「历史对话记录」查看/清空过往问答")
7.3 关键代码解析
(1)临时文件处理
with tempfile.NamedTemporaryFile(delete=False, suffix='.pdf') as temp_file:
temp_file.write(uploaded_file.read())
temp_file_path = temp_file.name
- Streamlit 上传的
uploaded_file是字节流对象,无本地路径,需转为临时文件才能被PyPDFLoader加载; delete=False:避免临时文件被立即删除,确保加载完成;finally块中强制删除临时文件,避免磁盘占用。
(2)会话状态管理
if "memory" not in st.session_state:
st.session_state["memory"] = ConversationBufferMemory(...)
- Streamlit 的
session_state用于跨交互保存状态,避免刷新后丢失对话记忆; ConversationBufferMemory存储所有对话历史,支持多轮上下文关联。
(3)异常处理与用户体验
- 上传文件为空时,问题输入框禁用(
disabled=not uploaded_file); - API 密钥为空时给出友好提示;
- 执行问答时显示加载动画(
st.spinner); - 捕获所有异常并显示错误信息,避免程序崩溃。
7.4 运行步骤
(1)安装依赖
# 核心依赖
pip install streamlit langchain langchain-community langchain-openai
# 辅助依赖
pip install pypdf faiss-cpu dashscope cryptography
(2)运行应用
streamlit run pdf_qa_app.py # pdf_qa_app.py为保存代码的文件名
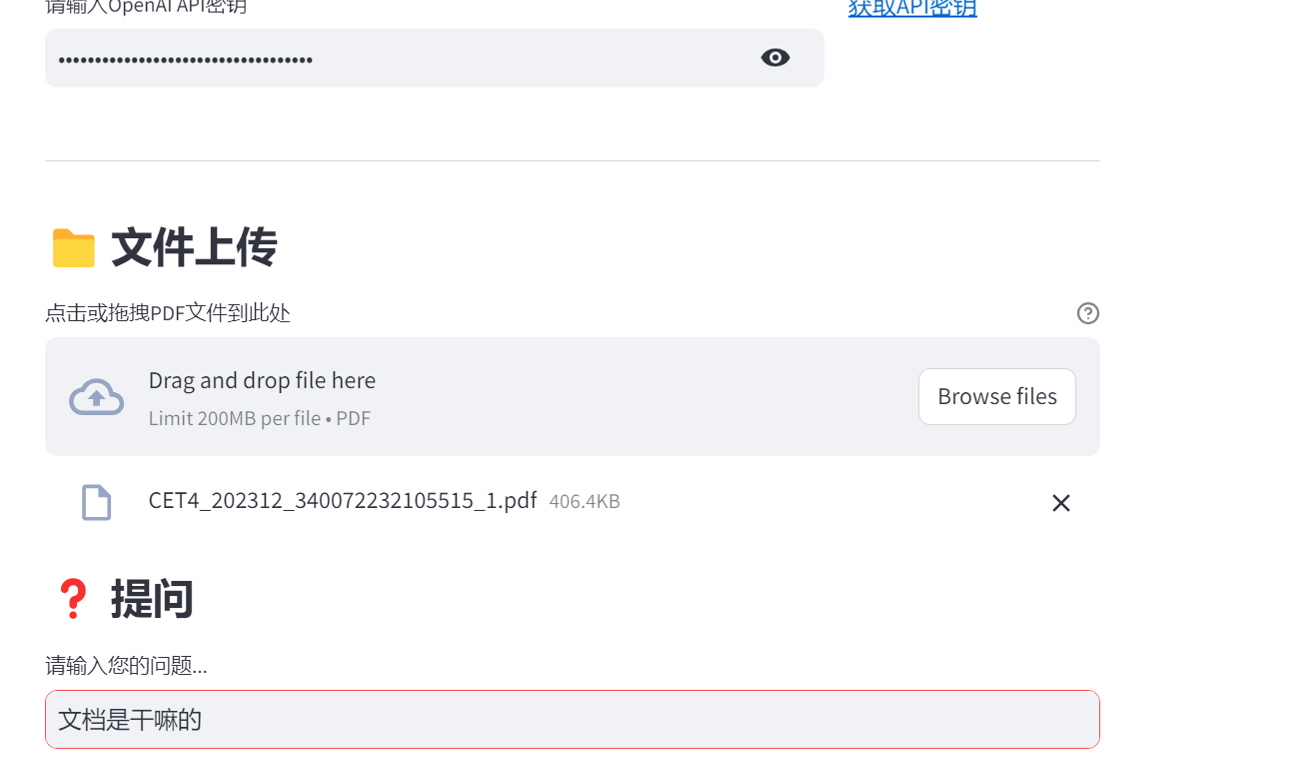
(3)使用流程
- 运行后自动打开浏览器(默认地址:
http://localhost:8501); - 输入阿里云 DashScope API 密钥(需提前在阿里云控制台申请);
- 上传 PDF 文件,输入问题即可得到回答;
- 支持多轮提问(如先问 “总结 PDF 内容”,再问 “其中提到的核心算法是什么”)。
7.5 项目优化建议
- 文件大小限制:添加文件大小校验(如
if uploaded_file.size > 50*1024*1024: st.error("文件超过50MB")); - 分批次处理:超大 PDF(>100 页)使用分批灌库逻辑,避免内存溢出;
- 检索优化:添加
search_type="mmr"提升检索多样性; - 回答溯源:开启
return_source_documents=True,显示回答对应的 PDF 原文片段; - 样式美化:添加自定义 CSS 优化界面样式,提升视觉体验。
八、工程化落地注意事项
- 分块调优:中文文档建议
chunk_size=500-1000,chunk_overlap=50-100,避免语义割裂; - 嵌入模型选型:小体量场景用 DashScope/OpenAI,大批量场景部署开源 BGE 模型;
- 向量库选型:
- 本地测试:FAISS(轻量、无需部署);
- 生产环境:Milvus/Weaviate(分布式、持久化、支持索引优化);
- API 密钥安全:生产环境避免前端明文输入,可通过后端代理转发;
- 性能优化:缓存向量库(避免重复嵌入)、异步处理文件加载。
总结
- LangChain RAG 核心流程为加载→分割→嵌入→存储检索→生成,中文场景需适配中文分割符、国内嵌入模型;
- 带记忆的
ConversationalRetrievalChain是实现多轮 RAG 对话的核心,ConversationBufferMemory满足基础会话记忆需求; - 实战项目中,临时文件处理、会话状态管理、异常友好提示是可视化 RAG 应用落地的关键细节;
- Streamlit 可快速将 RAG 逻辑封装为可视化工具,无需前端开发即可实现企业级 PDF 问答助手。
拓展方向
- 支持多文件上传与批量处理;
- 集成 Rerank 重排序提升检索准确率;
- 加入 HyDE(假设性文档嵌入)优化低质问题检索效果;
- 部署到阿里云 / 腾讯云服务器,实现公网访问。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)