langchain v1.2新概念探索
目录
引子
在 LangChain v1.0 刚刚发布时,我曾经写过一篇关于其新架构的分析。当时 LangChain 正在经历一次比较大的框架重构:Agent、Tool、Runtime 等概念被重新整理,LangGraph 也逐渐成为 Agent 运行时的核心基础设施。
不过,在那个时间点上,很多设计仍然处在快速演进阶段。不少 API 和概念还在不断调整,一些官方推荐的使用方式也并没有完全稳定下来。因此,当时的分析更多只能算是一次“阶段性观察”。
随着 LangChain 版本逐渐演进到 1.2,整个框架的核心理念开始变得更加清晰:
Agent 的运行模型、工具调用机制、状态管理方式以及可观测体系,都逐渐形成了一套相对完整的工程化思路。
因此,这篇文章并不是简单介绍 LangChain 的使用方法,而是尝试在 v1.2 的语境下重新审视 LangChain 的一些核心概念,看看在这段时间的迭代中:
- 哪些设计思路被保留下来了
- 哪些概念发生了演进
- LangChain 在 Agent 框架方向上到底想解决什么问题
如果你之前接触过 LangChain,或者正在设计自己的 Agent 系统,希望这次基于 LangChain v1.2 的再探索,能够帮助你更清晰地理解这个框架的整体架构。
Langchain更新日志
2026-03-10 langgraph v1.1
类型安全的流式输出(version=“v2”)
-
在
stream()/astream()中传入version="v2",即可获得统一的 StreamPart 输出结构。 -
每个数据块都包含以下字段:
typensdata
-
每种流式模式都有对应的
TypedDict类型定义,均可从langgraph.types导入。
类型安全的 invoke 调用(version=“v2”)
-
在
invoke()/ainvoke()中传入version="v2",返回一个 GraphOutput 对象:.value.interrupts
Pydantic 与 dataclass 自动转换
-
在
version="v2"模式下:invoke()返回结果values模式的 stream 输出
会自动转换为你声明的 Pydantic 模型或 dataclass 类型。
修复 time travel 与 interrupt / subgraph 的问题
- 回放(replay)不再复用旧的
RESUME值 - 子图(subgraph)现在可以正确恢复父图的历史 checkpoint
完全向后兼容
version="v2"为 可选功能(opt-in)GraphOutput仍支持 旧版 dict 风格访问,方便渐进迁移
2026-02-10 deepagents v0.4
新增可插拔沙箱集成包
新增三个集成:
langchain-modallangchain-daytonalangchain-runloop
可用于可插拔的沙箱环境。
参考:
- sandboxes guide
- data analysis 示例教程
对会话历史总结机制的修改
- Summarization 现在在 model node 中通过
wrap_model_call事件触发 - 因此现在会 在 graph state 中保留完整的 message history
更准确的 Token 计算
自动触发上下文总结
如果模型抛出:
ContextOverflowError
将自动触发 summarization。
目前支持:
langchain-anthropiclangchain-openai
OpenAI Responses API 成为默认
当模型字符串以:
openai:
开头时,默认使用 Responses API。
2025-12-15 langchain v1.2.0
create_agent 改进
通过工具上的新属性 extras,简化对 provider-specific tool 参数与定义 的支持。
示例能力:
-
Provider 特定配置
- 如 Anthropic 的 programmatic tool calling
- tool search
-
客户端执行的内置工具
- Anthropic
- OpenAI
- 其他 provider 均支持
-
支持 严格 schema 的 agent 输出格式
2025-12-08 langchain-google-genai v4.0.0
Google GenAI 集成已被完全重写,现在使用 Google 的统一 Generative AI SDK。
新 SDK 同时支持:
- Gemini API
- Vertex AI Platform
通过同一接口访问。
变化包括:
- 少量 breaking change
langchain-google-vertexai中部分包被弃用
2025-11-25 langchain v1.1.0
Model Profiles
Chat Model 现在通过 .profile 属性暴露模型能力,例如:
- 支持的功能
- 能力列表
Summarization Middleware
- 支持更灵活的触发机制
- 可以结合 model profile 进行上下文感知总结
Structured Output
ProviderStrategy(原生结构化输出)现在可以通过 model profile 自动推断
create_agent 支持 SystemMessage
现在可以直接向 system_prompt 传入:
SystemMessage
支持:
- cache control
- structured content blocks
Model Retry Middleware
新增中间件:
- 自动重试失败的模型调用
- 支持可配置的 指数退避(exponential backoff)
内容审核 Middleware
新增 OpenAI 内容审核中间件,用于检测不安全内容:
支持检测:
- 用户输入
- 模型输出
- 工具执行结果
OK,接下来让我们看看Langchain又整了哪些花活出来。
Agent Loop
一个 LLM Agent 会在一个循环中调用工具来完成目标任务。Agent 会持续运行,直到满足某个 停止条件,例如:
- 模型生成了最终输出(final output)
- 达到预设的迭代次数上限
其基本流程可以理解为:
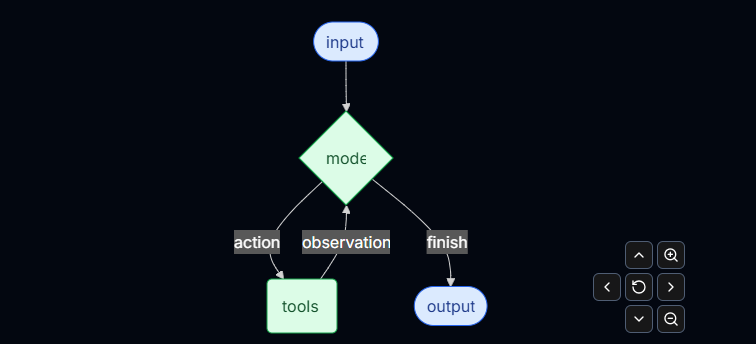
即:
- 接收输入(input)
- 模型进行推理(model)
- 决定要执行的操作(action)
- 调用工具(tools)
- 获得工具返回结果(observation)
- 再次进行推理(model)
- 最终输出结果(finish)
create_agent 基于 LangGraph 构建了一个 图结构的 Agent 运行时(runtime)。
在这个图中:
- 节点(nodes) 表示执行步骤
- 边(edges) 表示步骤之间的连接关系
这些节点和连接共同定义了 Agent 如何处理信息以及执行任务流程。Agent 会在这个图结构中不断移动,并执行不同的节点,例如:
-
model node
调用语言模型进行推理 -
tools node
执行工具调用 -
middleware
在执行过程中进行拦截、增强或处理逻辑
LangGraph Runtime
Pregel 实现了 LangGraph 的运行时(runtime),负责管理 LangGraph 应用的执行。
当你:
- 编译一个 StateGraph
- 或创建一个
@entrypoint
时,最终都会生成一个 Pregel 实例,这个实例可以通过输入参数进行调用(invoke)。
注意:
Pregel runtime 的名称来源于 Google 的 Pregel 算法,该算法描述了一种利用图结构进行大规模并行计算的高效方法。
在 LangGraph 中,Pregel 将 Actor(执行单元) 和 Channel(通信通道) 组合成一个完整的应用。
基本机制是:
- Actor 从 Channel 读取数据
- Actor 向 Channel 写入数据
Pregel 会按照 Pregel Algorithm / Bulk Synchronous Parallel(BSP)模型,将应用执行组织成多个步骤(steps)。
每个步骤包含 三个阶段:
1.Plan(规划阶段):确定本步骤需要执行哪些 Actor。
例如:
- 第一步:选择订阅了 输入 channel 的 Actor
- 后续步骤:选择订阅了 上一轮更新过的 channel 的 Actor
2.Execution(执行阶段):并行执行所有选定的 Actor,直到:
- 所有 Actor 执行完成
- 某个 Actor 执行失败
- 达到超时时间
在此阶段:
- Actor 写入 channel 的数据 不会立即可见
- 这些更新 只会在下一步中生效
3.Update(更新阶段):将 Actor 在本步骤中写入的值 更新到对应的 Channel 中。
整个流程会不断重复,直到没有新的 Actor 需要执行或达到最大执行步数
Actors
Actor 在 LangGraph 中对应一个 PregelNode。它会订阅若干 Channel,从这些 Channel 中读取数据,并将结果写回到 Channel 中。
可以将其理解为 Pregel 算法中的计算节点(Actor)。在实现上,PregelNode 实现了 LangChain 的 Runnable 接口。
Channels
Channel 用于在 Actor(PregelNode)之间传递数据。每个 Channel 都包含三个核心要素:
- value type(值类型)
- update type(更新类型)
- update function(更新函数)
更新函数会接收一组更新,并据此修改 Channel 当前存储的值。
Channel 可以用于:
- 在不同 chain 之间传递数据
- 将数据在未来的执行步骤中再次发送给当前 chain
LangGraph 提供了多种内置 Channel 类型:
-
LastValue:默认的 Channel 类型,用于保存最近一次发送到该 Channel 的值。适合用于输入输出数据,或在不同执行步骤之间传递数据。
-
Topic:一种可配置的 发布-订阅(Pub/Sub)Topic。适合在 Actor 之间传递多个值,或用于累积输出结果。可以配置为对数据进行去重,或在多个步骤中持续累积数据。
-
BinaryOperatorAggregate:用于存储一个持续累积的值。每次更新时,会通过一个二元操作符,将当前值与新发送到 Channel 的更新值进行合并。适合用于跨多个步骤进行聚合计算,例如:
total = BinaryOperatorAggregate(int, operator.add)
示例1:单节点
大多数用户通常通过:
- StateGraph API
@entrypoint装饰器
来间接使用 Pregel,但实际上也可以 直接使用 Pregel API 构建应用。
下面是一个简单示例。
from langgraph.channels import EphemeralValue
from langgraph.pregel import Pregel, NodeBuilder
node1 = (
NodeBuilder().subscribe_only("a")
.do(lambda x: x + x)
.write_to("b")
)
app = Pregel(
nodes={"node1": node1},
channels={
"a": EphemeralValue(str),
"b": EphemeralValue(str),
},
input_channels=["a"],
output_channels=["b"],
)
app.invoke({"a": "foo"})
输出结果:
{'b': 'foofoo'}
这个示例的逻辑是:
node1订阅 channel a- 接收到数据后执行函数
lambda x: x + x - 将结果写入 channel b
- 输入
"foo",输出"foofoo"
示例2:多节点
代码中定义了两个节点:
- node1:订阅 Channel
a,将接收到的字符串进行一次拼接(x + x),并将结果写入 Channelb - node2:订阅 Channel
b,对其结果再次进行拼接(x + x),并将结果写入 Channelc
from langgraph.channels import LastValue, EphemeralValue
from langgraph.pregel import Pregel, NodeBuilder
node1 = (
NodeBuilder().subscribe_only("a")
.do(lambda x: x + x)
.write_to("b")
)
node2 = (
NodeBuilder().subscribe_only("b")
.do(lambda x: x + x)
.write_to("c")
)
接下来创建一个 Pregel 应用实例。在这个实例中:
nodes定义了参与执行的节点channels定义了各个 Channel 及其类型input_channels指定输入数据来源output_channels指定最终输出的 Channel
app = Pregel(
nodes={"node1": node1, "node2": node2},
channels={
"a": EphemeralValue(str),
"b": LastValue(str),
"c": EphemeralValue(str),
},
input_channels=["a"],
output_channels=["b", "c"],
)
其中:
- EphemeralValue 表示临时 Channel,仅在当前执行过程中使用
- LastValue 表示保存最近一次写入值的 Channel
最后调用 invoke 执行该流程:
app.invoke({"a": "foo"})
执行结果为:
{'b': 'foofoo', 'c': 'foofoofoofoo'}
执行过程可以理解为:
- 输入
"foo"写入 Channela - node1 读取
a→"foo"→ 处理后得到"foofoo"→ 写入b - node2 读取
b→"foofoo"→ 处理后得到"foofoofoofoo"→ 写入c
因此最终输出:
b = "foofoo"c = "foofoofoofoo"
示例3:Topic
下面的代码示例展示了 Topic 类型 Channel 的使用方式,用于在多个节点之间传递并累积多个结果。
代码中定义了两个节点:
- node1:订阅 Channel
a,将输入字符串进行一次拼接(x + x),并将结果同时写入 Channelb和c - node2:订阅 Channel
b,读取b中的数据并再次拼接(x["b"] + x["b"]),然后将结果写入 Channelc
from langgraph.channels import EphemeralValue, Topic
from langgraph.pregel import Pregel, NodeBuilder
node1 = (
NodeBuilder().subscribe_only("a")
.do(lambda x: x + x)
.write_to("b", "c")
)
node2 = (
NodeBuilder().subscribe_to("b")
.do(lambda x: x["b"] + x["b"])
.write_to("c")
)
随后创建一个 Pregel 应用实例:
app = Pregel(
nodes={"node1": node1, "node2": node2},
channels={
"a": EphemeralValue(str),
"b": EphemeralValue(str),
"c": Topic(str, accumulate=True),
},
input_channels=["a"],
output_channels=["c"],
)
其中:
a:使用 EphemeralValue,表示临时 Channelb:使用 EphemeralValue,用于在节点之间传递中间结果c:使用 Topic 类型 Channel,并设置accumulate=True,表示该 Channel 会 累积多个结果值
最后执行:
app.invoke({"a": "foo"})
执行结果:
{'c': ['foofoo', 'foofoofoofoo']}
执行过程可以理解为:
- 输入
"foo"写入 Channela - node1 读取
a→"foo"→ 处理后得到"foofoo"→ 写入b和c - node2 读取
b→"foofoo"→ 处理后得到"foofoofoofoo"→ 写入c - 由于
c是 Topic(accumulate=True),因此会累积所有写入结果
最终 c 中保存:
['foofoo', 'foofoofoofoo']
示例4:BinaryOperatorAggregate
该示例演示了如何使用 BinaryOperatorAggregate Channel 来实现一个 reducer(聚合函数)。
from langgraph.channels import EphemeralValue, BinaryOperatorAggregate
from langgraph.pregel import Pregel, NodeBuilder
首先定义两个节点:
- node1:订阅 Channel
a,将输入字符串进行拼接(x + x),并将结果写入 Channelb和c - node2:订阅 Channel
b,对其结果再次拼接(x + x),并将结果写入 Channelc
node1 = (
NodeBuilder().subscribe_only("a")
.do(lambda x: x + x)
.write_to("b", "c")
)
node2 = (
NodeBuilder().subscribe_only("b")
.do(lambda x: x + x)
.write_to("c")
)
接着定义一个 reducer 函数,用于指定 Channel c 在接收到多个更新值时如何进行合并:
def reducer(current, update):
if current:
return current + " | " + update
else:
return update
该函数的逻辑是:
- 如果 Channel 中已经存在值,则使用
" | "将新值追加到后面 - 如果当前还没有值,则直接返回新值
然后创建 Pregel 应用实例:
app = Pregel(
nodes={"node1": node1, "node2": node2},
channels={
"a": EphemeralValue(str),
"b": EphemeralValue(str),
"c": BinaryOperatorAggregate(str, operator=reducer),
},
input_channels=["a"],
output_channels=["c"],
)
其中:
a:使用 EphemeralValue,用于输入数据b:使用 EphemeralValue,用于中间数据传递c:使用 BinaryOperatorAggregate,并指定reducer作为聚合函数
最后执行:
app.invoke({"a": "foo"})
执行流程为:
- 输入
"foo"写入 Channela - node1 读取
a→"foo"→ 处理后得到"foofoo"→ 写入b和c - node2 读取
b→"foofoo"→ 处理后得到"foofoofoofoo"→ 写入c - Channel
c使用 reducer 对多个更新值进行聚合
最终 c 的结果为:
foofoo | foofoofoofoo
示例5:Cycle
该示例演示了如何在 图(graph)中引入循环(cycle):让一个节点将结果写回到它自己订阅的 Channel 中。这样,执行过程会不断循环,直到某次写入的值为 None 时才停止。
from langgraph.channels import EphemeralValue
from langgraph.pregel import Pregel, NodeBuilder, ChannelWriteEntry
首先定义一个节点:
- 订阅 Channel
value - 如果字符串长度小于 10,就执行
x + x(字符串翻倍) - 如果长度已经达到或超过 10,则返回
None
example_node = (
NodeBuilder().subscribe_only("value")
.do(lambda x: x + x if len(x) < 10 else None)
.write_to(ChannelWriteEntry("value", skip_none=True))
)
这里的关键点是:
write_to("value")会把结果重新写回 同一个 Channelskip_none=True表示如果结果为None,则不会写入 Channel
这样就不会再触发下一轮执行,从而结束循环
接着创建一个 Pregel 应用实例:
app = Pregel(
nodes={"example_node": example_node},
channels={
"value": EphemeralValue(str),
},
input_channels=["value"],
output_channels=["value"],
)
其中:
value使用 EphemeralValue,作为输入和输出的 Channel
最后执行:
app.invoke({"value": "a"})
执行过程大致如下:
"a"→"aa""aa"→"aaaa""aaaa"→"aaaaaaaa""aaaaaaaa"→"aaaaaaaaaaaaaaaa"- 此时长度 ≥ 10,返回
None,循环停止
最终输出:
{'value': 'aaaaaaaaaaaaaaaa'}
StateGraph(Graph API)
StateGraph(Graph API) 是一种更高层的抽象,用于简化 Pregel 应用的构建过程。
通过该 API,可以定义一个由 节点(nodes) 和 边(edges) 组成的图结构。
当图被 编译(compile) 时,StateGraph API 会自动为你生成对应的 Pregel 应用实例。
from typing import TypedDict
from langgraph.constants import START
from langgraph.graph import StateGraph
首先定义一个状态结构 Essay:
class Essay(TypedDict):
topic: str
content: str | None
score: float | None
然后定义两个处理节点:
def write_essay(essay: Essay):
return {
"content": f"Essay about {essay['topic']}",
}
def score_essay(essay: Essay):
return {
"score": 10
}
接下来创建一个 StateGraph:
builder = StateGraph(Essay)
builder.add_node(write_essay)
builder.add_node(score_essay)
builder.add_edge(START, "write_essay")
builder.add_edge("write_essay", "score_essay")
最后对图进行编译:
graph = builder.compile()
编译完成后,这个 Pregel 实例会包含一组 节点(nodes) 和 Channel。
可以通过打印它们进行查看。
print(graph.nodes)
可能会看到类似输出:
{
'__start__': <langgraph.pregel.read.PregelNode ...>,
'write_essay': <langgraph.pregel.read.PregelNode ...>,
'score_essay': <langgraph.pregel.read.PregelNode ...>
}
说明 Graph API 会自动创建:
__start__节点write_essay节点score_essay节点
同样可以查看 Channel:
print(graph.channels)
可能会看到类似输出:
{
'topic': <LastValue ...>,
'content': <LastValue ...>,
'score': <LastValue ...>,
'__start__': <EphemeralValue ...>,
'write_essay': <EphemeralValue ...>,
'score_essay': <EphemeralValue ...>,
...
}
这些 Channel 包括:
-
状态字段对应的 Channel
topiccontentscore
-
节点之间通信使用的 Channel
__start__write_essayscore_essay- 以及内部自动生成的
branchChannel
这些 Channel 由 StateGraph 在编译时自动创建,用于实现节点之间的数据传递。
create_agent
create_agent 提供了一个 可用于生产环境的 Agent 实现。
上面我们知道langgraph实现了langchain-core的Runable协议,并且提供了一个图运行时,该运行时可以将输入,输出,节点,状态转换串联起来,而langchain基于langgraph构建,其底层必然是一个图结构,这里就从源码开始入手解析create_agent是如何构建这个图结构的:
def create_agent(
model: str | BaseChatModel,
tools: Sequence[BaseTool | Callable[..., Any] | dict[str, Any]] | None = None,
*,
system_prompt: str | SystemMessage | None = None,
middleware: Sequence[AgentMiddleware[StateT_co, ContextT]] = (),
response_format: ResponseFormat[ResponseT] | type[ResponseT] | dict[str, Any] | None = None,
state_schema: type[AgentState[ResponseT]] | None = None,
context_schema: type[ContextT] | None = None,
checkpointer: Checkpointer | None = None,
store: BaseStore | None = None,
interrupt_before: list[str] | None = None,
interrupt_after: list[str] | None = None,
debug: bool = False,
name: str | None = None,
cache: BaseCache[Any] | None = None,
) -> CompiledStateGraph[
AgentState[ResponseT], ContextT, _InputAgentState, _OutputAgentState[ResponseT]
]:
我们快速构建一个agent,然后输出其channels和nodes:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from pydantic import SecretStr
from pprint import pprint as print
@tool
def add(a:int, b:int) -> int:
"""
Add two integers
"""
return a + b
agent = create_agent(
system_prompt="你是一个有用的助手",
tools=[add],
model=ChatOpenAI(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
base_url="https://api.siliconflow.cn/v1",
api_key=SecretStr("****")
)
)
if __name__ == '__main__':
print("-"*20+"nodes"+"-"*20)
print(agent.nodes)
print("-" * 20 + "channels" + "-" * 20)
print(agent.channels)
'--------------------nodes--------------------'
{'__start__': <langgraph.pregel._read.PregelNode object at 0x000001D65A3BDBE0>,
'model': <langgraph.pregel._read.PregelNode object at 0x000001D65A24FC50>,
'tools': <langgraph.pregel._read.PregelNode object at 0x000001D65A24FED0>}
'--------------------channels--------------------'
{'__pregel_tasks': <langgraph.channels.topic.Topic object at 0x000001D65A1A7400>,
'__start__': <langgraph.channels.ephemeral_value.EphemeralValue object at 0x000001D65A0FD540>,
'branch:to:model': <langgraph.channels.ephemeral_value.EphemeralValue object at 0x000001D65A44BCC0>,
'branch:to:tools': <langgraph.channels.ephemeral_value.EphemeralValue object at 0x000001D65A475280>,
'jump_to': <langgraph.channels.ephemeral_value.EphemeralValue object at 0x000001D65A44B040>,
'messages': <langgraph.channels.binop.BinaryOperatorAggregate object at 0x000001D65A44AF00>,
'structured_response': <langgraph.channels.last_value.LastValue object at 0x000001D65A44B2C0>}
这个输出其实非常有价值,因为它把 create_agent() 在 LangGraph Runtime(Pregel)层面真实构建出来的 Graph暴露出来了。我们逐层拆一下。
nodes:Agent 实际是 3 个 PregelNode
{'__start__': PregelNode,
'model': PregelNode,
'tools': PregelNode}
说明 Agent Graph 非常简单:
START
↓
model
↓
tools
↓
model
↓
...
循环执行直到模型停止调用 tool。
-
__start__这是 Graph API 自动生成的 起始节点。
作用:
输入 state ↓ 触发 model类似:
START → model -
model这是 LLM 调用节点。
职责:
messages ↓ LLM ↓ AIMessage如果模型输出:
tool_calls就跳转:
model → tools否则结束。
3 tools
这是 **工具执行节点**。
职责:
```
读取 AIMessage.tool_calls
↓
执行 tool
↓
生成 ToolMessage
```
然后再把 ToolMessage 写回:
```
messages
```
再回到:
```
tools → model
```
所以 Agent Loop 是:
```
model → tools → model → tools ...
```
channels:Agent 的 State
{
'__pregel_tasks': Topic,
'__start__': EphemeralValue,
'branch:to:model': EphemeralValue,
'branch:to:tools': EphemeralValue,
'jump_to': EphemeralValue,
'messages': BinaryOperatorAggregate,
'structured_response': LastValue
}
这些其实就是 Graph State + Runtime Control Channels。
我们分两类看。
-
messagesmessages: BinaryOperatorAggregate这是 最核心的 channel。
因为 Agent State 是:
messages: list[BaseMessage]但 Pregel 是 step-based execution,所以要用 reducer。
这里使用:
BinaryOperatorAggregate作用是:
messages = messages + new_messages类似 reducer:
state.messages.append(...)所以执行流程:
HumanMessage ↓ AIMessage ↓ ToolMessage ↓ AIMessage全部累计在
messages里。 -
structured_responsestructured_response: LastValue只有当你使用:
response_format=...才会真正用到。
作用:
最终结构化输出LastValue表示:只保留最后一次写入
Runtime 控制 channels
这些是 LangGraph 内部控制执行流的 channel。
-
__pregel_tasksTopic这是 Pregel runtime 用来调度 下一轮执行任务 的。
类似:
scheduler queue -
branch:to:modelEphemeralValue用于:
触发 model node类似:
edge → model -
branch:to:toolsEphemeralValue触发:
model → tools当 LLM 生成 tool_calls。
-
jump_toEphemeralValue用于:
动态跳转节点例如:
middleware interrupt resume都会用这个。
-
__start__Graph start signal。
invoke() ↓ 写入 __start__ ↓ 触发 model
完整执行流程
根据这些 node + channel,可以推导完整运行过程:
invoke()
↓
__start__ channel
↓
branch:to:model
↓
model node
↓
LLM output
↓
messages reducer
↓
如果有 tool_calls
↓
branch:to:tools
↓
tools node
↓
ToolMessage
↓
messages reducer
↓
branch:to:model
循环:
model → tools → model
直到:
没有 tool_calls
结束。
为了加深对create_agent的理解,现在使用低级API来模仿实现一个Agent Loop:
"""
基于 LangGraph Pregel + NodeBuilder 完全手写实现的 Agent Loop。
与官方 create_agent 编译后的结构对齐:
- nodes: __start__, model, tools
- channels: messages, branch:to:model, branch:to:tools, jump_to, structured_response 等
"""
from langgraph.pregel import Pregel, NodeBuilder
from langgraph.pregel._write import ChannelWriteEntry
from langgraph.channels import (
EphemeralValue,
BinaryOperatorAggregate,
LastValue,
)
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
ToolMessage,
AnyMessage,
)
from pydantic import SecretStr
# ---------------------------------------------------------------------------
# 工具定义
# ---------------------------------------------------------------------------
@tool
def add(a: int, b: int) -> int:
"""Add two integers."""
return a + b
TOOLS_BY_NAME = {"add": add}
# ---------------------------------------------------------------------------
# 模型
# ---------------------------------------------------------------------------
LLM = ChatOpenAI(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
base_url="https://api.siliconflow.cn/v1",
api_key=SecretStr("sk-qluvqlqupbpcoirxikfukgtmiiovvcpjxxyzhytizbntsxvq"),
)
LLM_BOUND = LLM.bind_tools([add])
SYSTEM_PROMPT = "你是一个有用的助手,在涉及数学计算时请调用 add 工具。"
# ---------------------------------------------------------------------------
# messages 通道的 reducer:累加消息列表
# ---------------------------------------------------------------------------
def messages_reducer(current: list[AnyMessage] | None, update: list[AnyMessage] | None):
if update is None:
return current or []
if current is None:
return list(update) if update else []
return current + list(update)
# ---------------------------------------------------------------------------
# __start__ 节点:仅在「尚无 AI 回复」时写入 branch:to:model,触发首轮 model
# ---------------------------------------------------------------------------
def start_node(messages: list[AnyMessage] | None) -> dict:
if not messages:
return {"branch:to:model": True}
if any(isinstance(m, AIMessage) for m in messages):
return {}
return {"branch:to:model": True}
def _write_branch_to_model(out: dict):
v = out.get("branch:to:model")
return v if v is not None else (object() if "branch:to:model" in out else None) # skip_none 只跳过 None
start_node_builder = (
NodeBuilder()
.subscribe_only("messages")
.do(start_node)
.write_to(ChannelWriteEntry("branch:to:model", skip_none=True, mapper=lambda o: o.get("branch:to:model")))
)
# ---------------------------------------------------------------------------
# model 节点:订阅 branch:to:model,读取 messages,调用 LLM,写 messages 和可选的 branch:to:tools
# ---------------------------------------------------------------------------
def call_model(data: dict) -> dict:
messages: list[AnyMessage] = data.get("messages") or []
if not messages:
return {}
with_system = [SystemMessage(content=SYSTEM_PROMPT)] + list(messages)
response: AIMessage = LLM_BOUND.invoke(with_system)
out = {"messages": [response]}
if response.tool_calls:
out["branch:to:tools"] = True
return out
model_node_builder = (
NodeBuilder()
.subscribe_to("branch:to:model", read=True)
.read_from("messages")
.do(call_model)
.write_to(
ChannelWriteEntry("messages", mapper=lambda o: o.get("messages")),
ChannelWriteEntry("branch:to:tools", skip_none=True, mapper=lambda o: o.get("branch:to:tools")),
)
)
# ---------------------------------------------------------------------------
# tools 节点:订阅 branch:to:tools,读取 messages,执行 tool_calls,写 messages 和 branch:to:model
# ---------------------------------------------------------------------------
def call_tools(data: dict) -> dict:
messages: list[AnyMessage] = data.get("messages") or []
if not messages:
return {}
last = messages[-1]
if not isinstance(last, AIMessage) or not last.tool_calls:
return {}
tool_messages = []
for tc in last.tool_calls:
name = tc["name"]
args = tc.get("args") or {}
tool_fn = TOOLS_BY_NAME.get(name)
if not tool_fn:
tool_messages.append(
ToolMessage(content=f"Unknown tool: {name}", tool_call_id=tc["id"])
)
continue
result = tool_fn.invoke(args)
tool_messages.append(
ToolMessage(content=str(result), tool_call_id=tc["id"])
)
return {
"messages": tool_messages,
"branch:to:model": True,
}
tools_node_builder = (
NodeBuilder()
.subscribe_to("branch:to:tools", read=True)
.read_from("messages")
.do(call_tools)
.write_to(
ChannelWriteEntry("messages", mapper=lambda o: o.get("messages")),
ChannelWriteEntry("branch:to:model", mapper=lambda o: o.get("branch:to:model")),
)
)
# ---------------------------------------------------------------------------
# 构建 Pregel 图(对齐官方 channels / nodes 命名)
# ---------------------------------------------------------------------------
app = Pregel(
nodes={
"__start__": start_node_builder.build(),
"model": model_node_builder.build(),
"tools": tools_node_builder.build(),
},
channels={
"messages": BinaryOperatorAggregate(list, operator=messages_reducer),
"branch:to:model": EphemeralValue(bool),
"branch:to:tools": EphemeralValue(bool),
"jump_to": EphemeralValue(str),
"structured_response": LastValue(str),
},
input_channels=["messages"],
output_channels=["messages"],
)
# ---------------------------------------------------------------------------
# 运行
# ---------------------------------------------------------------------------
if __name__ == "__main__":
from pprint import pprint
result = app.invoke({
"messages": [
HumanMessage(content="请用 add 工具算 1+2 等于多少"),
]
})
pprint(result)

中间件
Middleware(中间件)提供了一种方式,可以 更精细地控制 Agent 内部发生的事情。中间件在以下场景中非常有用:
- 通过 日志、分析和调试 来跟踪 Agent 的行为
- 修改或转换 Prompt、工具选择以及输出格式
- 添加 重试(retry)、回退(fallback)和提前终止(early termination) 的逻辑
- 实施 速率限制(rate limit)、安全护栏(guardrails)以及 PII(敏感信息)检测
Agent 的核心循环包括以下步骤:
- 调用模型(Model)
- 让模型决定要执行哪些工具(Tools)
- 执行工具
- 如果模型不再调用任何工具,则结束
这张图片需要记住: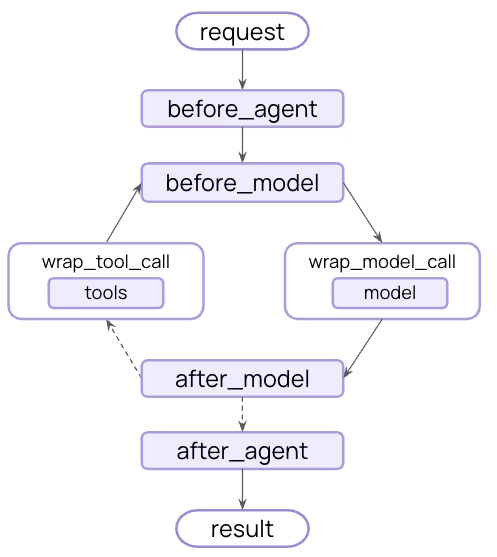
Middleware 可以在这些步骤 前后插入 Hook,从而对整个流程进行干预或增强。
Hooks
可以通过实现 Hook(钩子) 来构建自定义 Middleware,这些 Hook 会在 Agent 执行流程的特定阶段 被触发。
Middleware 提供两种类型的 Hook,用于拦截和控制 Agent 的执行流程:
Node 风格 Hook(Node-style hooks)
在 特定执行阶段按顺序运行。
常见用途:
- 日志记录(logging)
- 数据校验(validation)
- 状态更新(state updates)
可用 Hook
-
before_agent
在 Agent 开始执行之前触发(每次调用只执行一次) -
before_model
在每一次调用模型之前触发 -
after_model
在每一次模型返回结果之后触发 -
after_agent
在 Agent 执行结束之后触发(每次调用只执行一次)
示例(推荐:类写法)
from langchain.agents.middleware import AgentMiddleware, AgentState, hook_config
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
class MessageLimitMiddleware(AgentMiddleware):
def __init__(self, max_messages: int = 50):
super().__init__()
self.max_messages = max_messages
@hook_config(can_jump_to=["end"])
def before_model(
self,
state: AgentState,
runtime: Runtime
) -> dict[str, Any] | None:
if len(state["messages"]) >= self.max_messages:
return {
"messages": [AIMessage("Conversation limit reached.")],
"jump_to": "end"
}
return None
def after_model(
self,
state: AgentState,
runtime: Runtime
) -> dict[str, Any] | None:
print(f"Model returned: {state['messages'][-1].content}")
return None
这个 Middleware 实现了两个功能:
1️⃣ 对话长度限制
- 在
before_model阶段检查messages - 如果消息数量超过设定值
- 直接返回
"jump_to": "end"提前结束 Agent
2️⃣ 模型返回日志
- 在
after_model阶段打印模型输出 - 方便调试或记录日志
Wrap 风格 Hook(Wrap-style hooks)
Wrap-style Hook 会 包裹(wrap)模型调用或工具调用。
适合用于:
- 重试机制(retry)
- 缓存(caching)
- 输入输出转换(transformation)
与 Node-style Hook 的区别是:
你可以控制 handler 被调用的次数:
- 0 次 → 直接短路(short-circuit)
- 1 次 → 正常执行
- 多次 → 实现重试逻辑
可用 Hook:
-
wrap_model_call
包裹每一次模型调用 -
wrap_tool_call
包裹每一次工具调用
示例(推荐:类写法)
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from typing import Callable
class RetryMiddleware(AgentMiddleware):
def __init__(self, max_retries: int = 3):
super().__init__()
self.max_retries = max_retries
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(self.max_retries):
try:
return handler(request)
except Exception as e:
if attempt == self.max_retries - 1:
raise
print(f"Retry {attempt + 1}/{self.max_retries} after error: {e}")
这个 Middleware 实现了 模型调用自动重试:
-
每次模型调用都会被
wrap_model_call包裹 -
如果调用失败:
- 自动重试
- 最多重试
max_retries次
-
最后一次仍然失败则抛出异常
两类Hock的区别
AgentMiddleware 接口实际上定义了所有 Hook 方法,因此从 底层实现角度 来看,并不存在严格的 “Hook 类型” 或 “Middleware 类型” 的区分。无论是 Node-style 还是 Wrap-style,本质上都是在 Agent 执行流程中的某个阶段插入自定义逻辑。
不过在设计和文档层面,LangChain 仍然将其划分为两类,这样做主要有两个原因:
-
功能解耦
将 Middleware 按执行模式划分,可以让开发者更容易理解各类逻辑的职责边界。例如日志记录、状态检查等逻辑适合放在 Node-style Hook 中,而重试、缓存、调用拦截等逻辑则更适合使用 Wrap-style Hook。这种划分能够使 Middleware 的职责更加清晰,避免在同一逻辑中混杂过多不同类型的控制行为。 -
执行语义不同
两类 Hook 在执行方式上存在明显差异。Node-style Hook 是在固定节点按顺序执行的,它们更像是 Agent 流程中的“生命周期回调”;而 Wrap-style Hook 则是包裹在模型或工具调用外部,通过接管handler来控制实际执行过程。开发者可以决定是否调用handler、调用几次,甚至完全替换执行逻辑,因此具有更强的控制能力。
简单来说,Node-style Hook 更侧重于 在流程节点上扩展行为,而 Wrap-style Hook 更侧重于 拦截并控制具体调用过程。这种区分并不是底层强制的,而是为了让 Middleware 的使用方式更加清晰和可维护。
还记得之前的动态替换模型的中间件吗,
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
basic_model = ChatOpenAI(model="gpt-4.1-mini")
advanced_model = ChatOpenAI(model="gpt-4.1")
@wrap_model_call
def dynamic_model_selection(request: ModelRequest, handler) -> ModelResponse:
"""Choose model based on conversation complexity."""
message_count = len(request.state["messages"])
if message_count > 10:
# Use an advanced model for longer conversations
model = advanced_model
else:
model = basic_model
return handler(request.override(model=model))
这里实现 @wrap_model_call 的目的,其实就是 “狸猫换太子”——在真正调用模型之前,动态替换掉原本要使用的模型实例。
之所以必须使用 Wrap-style Hook,是因为它可以直接拦截模型调用,并拿到当前的 ModelRequest。开发者可以在这个阶段:
- 修改请求参数
- 替换模型实例
- 修改 Prompt
- 或者直接短路调用
在这个例子中,中间件通过读取 request.state["messages"] 的长度来判断当前对话复杂度,然后使用 request.override(model=model) 替换实际调用的模型。
最终流程实际上变成了:
Agent -> wrap_model_call -> 选择模型 -> handler() -> 实际调用模型
如果使用 Node-style Hook(例如 before_model)其实也能读取状态,但它 无法直接控制模型调用本身,只能通过返回新的 state 来影响后续流程。因此像 模型切换、调用重试、缓存命中、请求改写 这类需要拦截调用的逻辑,更适合使用 Wrap-style Hook。
换句话说:
- Node-style Hook 更像是 Agent 生命周期中的“观察点”和“修正点”
- Wrap-style Hook 更像是对关键调用过程的“拦截器”或“代理层”
因此在实际开发中,一个复杂的 Agent 系统往往会同时使用两种 Middleware:
- Node-style 用于 监控与流程控制,而 Wrap-style 用于 调用层面的增强与接管。
状态更新(State updates)
无论是 Node-style Hook 还是 Wrap-style Hook,都可以对 Agent 的状态(state)进行更新。不过两者的实现机制有所不同。
Node-style Hook
(before_agent、before_model、after_model、after_agent)
- 直接 返回一个 dict
- 这个 dict 会通过图(graph)的 reducers 合并到 Agent 的状态中
Wrap-style Hook
(wrap_model_call、wrap_tool_call)
- 在模型调用时,需要返回
ExtendedModelResponse - 同时通过
Command注入状态更新 - 在工具调用时,可以 直接返回
Command
这种方式适用于以下场景:
- 在模型调用过程中统计使用情况(usage metadata)
- 在某些触发点进行总结(summarization)
- 根据请求或响应计算新的状态字段
- 记录自定义信息
Node-style Hook 更新状态
Node-style Hook 只需要返回一个 dict,其中的 key 会映射到 Agent 的 state 字段。
from langchain.agents.middleware import after_model, AgentState
from langgraph.runtime import Runtime
from typing import Any
from typing_extensions import NotRequired
class TrackingState(AgentState):
model_call_count: NotRequired[int]
@after_model(state_schema=TrackingState)
def increment_after_model(
state: TrackingState,
runtime: Runtime
) -> dict[str, Any] | None:
return {
"model_call_count": state.get("model_call_count", 0) + 1
}
这个示例实现的逻辑是:
- 每次模型调用完成后
model_call_count自动加 1- 最终统计 Agent 总共调用了多少次模型
Wrap-style Hook 更新状态
在 wrap_model_call 中,需要返回 ExtendedModelResponse,并使用 Command 注入状态更新。
from typing import Callable
from langchain.agents.middleware import (
wrap_model_call,
ModelRequest,
ModelResponse,
AgentState,
ExtendedModelResponse
)
from langgraph.types import Command
from typing_extensions import NotRequired
class UsageTrackingState(AgentState):
"""带 token 使用统计的 Agent state"""
last_model_call_tokens: NotRequired[int]
@wrap_model_call(state_schema=UsageTrackingState)
def track_usage(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ExtendedModelResponse:
response = handler(request)
return ExtendedModelResponse(
model_response=response,
command=Command(
update={"last_model_call_tokens": 150}
),
)
在这个例子中:
- 先调用
handler(request)执行真实模型调用 - 然后通过
Command更新 Agent 状态 - 最终返回
ExtendedModelResponse
Command 会通过 Graph 的 reducer 机制 合并到状态中,因此:
- state 更新是 正确合并的
messages这类字段是 追加(additive) 而不是覆盖
多 Middleware 组合(Composition)
当多个 Middleware 同时返回 ExtendedModelResponse 时,它们的 Command 会自动组合。
合并规则:
1️⃣ 通过 reducer 合并
每个 Command 都会被当作一次独立的 state 更新。
对于 messages 这种字段:
- 更新是 追加的
- 不会覆盖之前的消息
2️⃣ 冲突时外层优先(Outer wins)
对于没有 reducer 的普通字段:
- 更新顺序是 inner → outer
- 如果 key 冲突,最外层 Middleware 的值会覆盖内部值
3️⃣ 支持重试安全(Retry-safe)
如果外层 Middleware 存在 重试逻辑(例如多次调用 handler()):
- 只有 最终成功的那一次调用 的
Command会被保留 - 之前失败调用产生的更新会被丢弃
示例:多 Middleware 组合
from typing import Annotated, Callable
from langchain.agents.middleware import (
AgentMiddleware,
AgentState,
ExtendedModelResponse,
ModelRequest,
ModelResponse,
)
from langchain.messages import SystemMessage
from langgraph.types import Command
from typing_extensions import NotRequired
定义 reducer:
def _last_wins(_a: str, b: str) -> str:
"""Reducer:最后写入者生效(outer 覆盖 inner)"""
return b
定义 Agent state:
class CustomMiddlewareState(AgentState):
"""
Agent state:
trace_layer 使用 last-wins reducer
messages 使用追加 reducer
"""
trace_layer: NotRequired[Annotated[str, _last_wins]]
class OuterMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ExtendedModelResponse:
response = handler(request)
return ExtendedModelResponse(
model_response=response,
command=Command(update={
"trace_layer": "outer",
"messages": [SystemMessage(content="[Outer ran]")],
}),
)
class InnerMiddleware(AgentMiddleware):
"""
同样写入 trace_layer 和 messages
规则:
trace_layer → outer 覆盖 inner
messages → 追加
"""
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
):
response = handler(request)
return ExtendedModelResponse(
model_response=response,
command=Command(update={
"trace_layer": "inner",
"messages": [SystemMessage(content="[Inner ran]")],
}),
)
假设两个 Middleware 同时执行:
-
trace_layerinner → outer最终值为:
outer -
messages[Inner ran] [Outer ran]
消息会 按顺序追加,而不会覆盖。
LangChain 的 Middleware 状态更新本质依赖于 LangGraph 的 reducer 机制:
- Node-style Hook:直接返回 dict
- Wrap-style Hook:通过
Command注入 state 更新 - 多 Middleware:通过 reducer 自动组合状态更新
这种设计使得 复杂 Middleware 组合、重试机制、并发更新 都能够稳定工作。
中间件状态机
Middleware 可以通过 扩展 Agent 的 state 来添加自定义字段。这使得 Middleware 能够在 Agent 执行过程中维护和共享额外的信息。
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langchain.agents.middleware import AgentState, AgentMiddleware
from typing_extensions import NotRequired
from typing import Any
定义自定义 state:
class CustomState(AgentState):
model_call_count: NotRequired[int]
user_id: NotRequired[str]
在这个 state 中新增了两个字段:
model_call_count:记录模型调用次数user_id:记录当前用户 ID
定义 Middleware:
class CallCounterMiddleware(AgentMiddleware[CustomState]):
state_schema = CustomState
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"}
return None
def after_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
return {
"model_call_count": state.get("model_call_count", 0) + 1
}
这个 Middleware 实现的逻辑:
- 在
before_model中检查模型调用次数 - 如果超过 10 次,则通过
jump_to="end"提前终止 Agent - 在
after_model中累加model_call_count
创建 Agent:
agent = create_agent(
model="gpt-4.1",
middleware=[CallCounterMiddleware()],
tools=[],
)
调用 Agent,并传入自定义 state:
result = agent.invoke({
"messages": [HumanMessage("Hello")],
"model_call_count": 0,
"user_id": "user-123",
})
这里的调用参数中:
messages是默认 state 字段model_call_count和user_id是 自定义 state 字段
Middleware 可以在整个 Agent 执行过程中 持续读取和更新这些值。
有人可能会好奇,这里的状态机和create_agent时传入的state_schema有什么区别?
我们都知道,LangChain 会做一件事情:
把所有 middleware 声明的 state_schema 自动合并成一个最终 schema。
类似:
FinalAgentState =
AgentState
+ MiddlewareAState
+ MiddlewareBState
+ ...
LangChain 这样设计其实是为了实现:
Middleware 可插拔(Plug-in Architecture)
如果 middleware 需要字段:
model_call_count
它不需要修改 Agent:
create_agent(...)
只需要:
middleware=[CallCounterMiddleware()]
state 就会自动扩展,这就是 插件式 state 扩展。
执行顺序(Execution order)
当同时使用多个 Middleware 时,需要理解它们的执行顺序。例如:
agent = create_agent(
model="gpt-4.1",
middleware=[middleware1, middleware2, middleware3],
tools=[...],
)
1️⃣ before_* Hook 按顺序执行
middleware1.before_agent()
middleware2.before_agent()
middleware3.before_agent()
随后 Agent Loop 开始:
middleware1.before_model()
middleware2.before_model()
middleware3.before_model()
2️⃣ wrap_* Hook 像函数调用一样嵌套
middleware1.wrap_model_call()
→ middleware2.wrap_model_call()
→ middleware3.wrap_model_call()
→ model
也就是说:
第一个 middleware 会包裹后面所有 middleware。
3️⃣ after_* Hook 按相反顺序执行
middleware3.after_model()
middleware2.after_model()
middleware1.after_model()
4️⃣ Agent Loop 结束
middleware3.after_agent()
middleware2.after_agent()
middleware1.after_agent()
| Hook 类型 | 执行顺序 |
|---|---|
before_* hooks |
从前到后执行 |
after_* hooks |
从后到前执行(逆序) |
wrap_* hooks |
嵌套执行(类似函数包装) |
这种执行顺序其实和很多框架中的 Middleware / Interceptor / Filter 机制类似。
Agent 跳转(Agent jumps)
如果希望在 Middleware 中 提前结束或改变执行流程,可以返回一个包含 jump_to 的字典。
-
"end"
跳转到 Agent 执行结束(或第一个after_agentHook) -
"tools"
跳转到 tools 节点 -
"model"
跳转到 model 节点(或第一个before_modelHook)
from langchain.agents.middleware import AgentMiddleware, hook_config, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from typing import Any
class BlockedContentMiddleware(AgentMiddleware):
@hook_config(can_jump_to=["end"])
def after_model(
self,
state: AgentState,
runtime: Runtime
) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("I cannot respond to that request.")],
"jump_to": "end"
}
return None
这个 Middleware 的逻辑是:
- 在
after_model阶段检查模型返回内容 - 如果检测到
"BLOCKED"关键词 - 则返回新的回复
- 并通过
jump_to="end"直接结束 Agent 执行
这里@hook_config(can_jump_to=["end"]) 的作用其实是:
声明这个 Hook 允许跳转到哪些节点。
换句话说,它是在 编译 Agent Graph 时给 Hook 配置“合法跳转目标”。
在 Middleware 里你可以返回:
return {
"jump_to": "end"
}
但 Agent 的执行实际上是一个 LangGraph Graph。
Graph 在编译时必须提前知道:
这个节点可以跳到哪些节点
否则 Graph 是 无法构建边(edge) 的。
所以需要:
@hook_config(can_jump_to=["end"])
来告诉系统:
这个 Hook 可能会跳到
end节点。
LangChain 在内部编译 Graph 时会创建对应的边。
如果不写会发生什么?如果你这样写:
class BlockedMiddleware(AgentMiddleware):
def after_model(self, state, runtime):
return {"jump_to": "end"}
但没有:
@hook_config(can_jump_to=["end"])
那么在运行时通常会报类似错误:
Invalid jump target 'end'
或者 Graph 编译阶段报错。
因为 Graph 不知道:
after_model
↓
可以跳到哪里
hook_config 本质干了什么
它只是给 Hook 附加一些 元信息(metadata)。
类似:
hook_config = {
"can_jump_to": ["end"]
}
LangChain 在编译 Agent 时会读取这个配置,然后:
after_model node
├── normal edge → next step
└── jump edge → end
可以允许多个跳转
例如:
@hook_config(can_jump_to=["end", "tools"])
那这个 Hook 就可以返回:
return {"jump_to": "tools"}
或者:
return {"jump_to": "end"}
为什么官方要设计成装饰器
因为 Hook 只是普通函数:
def after_model(...)
LangChain 需要一种方式给函数附加 Graph 配置。
所以用了 decorator。
其实效果类似:
after_model._hook_config = {
"can_jump_to": ["end"]
}
如果你在研究 Agent Loop + Pregel,这里其实还有一个很有意思的点:
LangChain 的 jump_to 在 LangGraph 里其实是一个:
Command(goto=...)
也就是说:
return {"jump_to": "end"}
最后会变成:
Command(goto="end")
这也是为什么 Agent Middleware 本质就是 LangGraph 的语法糖。
中间件最佳实践(Best practices)
保持 Middleware 职责单一
每个 Middleware 应该只负责一件事情。
优雅处理错误
不要让 Middleware 内部错误导致 Agent 崩溃。
选择合适的 Hook 类型
-
Node-style Hook:适合顺序逻辑,例如
- 日志记录
- 数据校验
-
Wrap-style Hook:适合控制执行流程,例如
- 重试(retry)
- 回退(fallback)
- 缓存(cache)
清晰记录自定义 State 字段
如果 Middleware 扩展了 state,需要明确说明这些字段的含义。
在集成前单独测试 Middleware
Middleware 最好先进行单元测试,再加入 Agent。
注意 Middleware 执行顺序
如果某些 Middleware 非常关键,应当放在列表的前面。
尽量使用内置 Middleware
如果官方已经提供了对应功能,优先使用官方实现。
Agent 的运行时上下文管理
Runtime 和 Context Engineering 在 Agent 里是强相关的两个概念,因为:
- Runtime 负责在执行过程中提供环境信息(state、config、runtime object)
- Context Engineering 负责把这些信息组织成 模型真正看到的上下文
Runtime
在 LangChain 中,create_agent 实际上是运行在 LangGraph 的 Runtime 之上的。
LangGraph 会向 Agent 暴露一个 Runtime 对象,其中包含以下信息:
- Context:静态信息,例如用户 ID、数据库连接或其他与一次 Agent 调用相关的依赖。
- Store:一个
BaseStore实例,用于实现 长期记忆(long-term memory)。 - Stream writer:用于在
"custom"stream 模式下 实时流式输出信息 的对象。
Runtime 中的 context 提供了一种 依赖注入(Dependency Injection)机制,可用于工具(tools)和中间件(middleware)。
相比于将这些信息写死在代码里,或者使用全局变量,你可以在 调用 Agent 时动态注入运行时依赖,例如:
- 数据库连接
- 用户 ID
- 运行配置
这种方式可以让工具更加:
- 易于测试
- 可复用
- 灵活可配置
在工具和中间件中都可以访问 Runtime 中的信息。
在使用 create_agent 创建 Agent 时,可以通过 context_schema 指定 Runtime context 的结构。
在调用 Agent 时,通过 context 参数传入对应的运行时信息。
from dataclasses import dataclass
from langchain.agents import create_agent
@dataclass
class Context:
user_name: str
agent = create_agent(
model="gpt-5-nano",
tools=[...],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)
在工具内部可以通过 Runtime 完成以下操作:
- 访问 context
- 读取或写入 长期记忆(store)
- 向 custom stream 写入信息(例如工具执行进度)
可以使用 ToolRuntime 参数在工具中访问 Runtime。
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
@dataclass
class Context:
user_id: str
@tool
def fetch_user_email_preferences(runtime: ToolRuntime[Context]) -> str:
"""Fetch the user's email preferences from the store."""
user_id = runtime.context.user_id
preferences: str = "The user prefers you to write a brief and polite email."
if runtime.store:
if memory := runtime.store.get(("users",), user_id):
preferences = memory.value["preferences"]
return preferences
在这个示例中:
- 从
runtime.context中读取user_id - 从
runtime.store中读取用户的长期偏好信息 - 返回用户偏好的邮件风格
在中间件中也可以访问 Runtime 信息,例如:
- 构建 动态 Prompt
- 修改消息
- 根据用户上下文控制 Agent 行为
访问方式:
- Node-style hooks:通过
Runtime参数获取 - Wrap-style hooks:通过
ModelRequest.runtime获取
示例:
from dataclasses import dataclass
from langchain.messages import AnyMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import dynamic_prompt, ModelRequest, before_model, after_model
from langgraph.runtime import Runtime
@dataclass
class Context:
user_name: str
# 动态 Prompt
@dynamic_prompt
def dynamic_system_prompt(request: ModelRequest) -> str:
user_name = request.runtime.context.user_name
system_prompt = f"You are a helpful assistant. Address the user as {user_name}."
return system_prompt
# before_model hook
@before_model
def log_before_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"Processing request for user: {runtime.context.user_name}")
return None
# after_model hook
@after_model
def log_after_model(state: AgentState, runtime: Runtime[Context]) -> dict | None:
print(f"Completed request for user: {runtime.context.user_name}")
return None
agent = create_agent(
model="gpt-5-nano",
tools=[...],
middleware=[dynamic_system_prompt, log_before_model, log_after_model],
context_schema=Context
)
agent.invoke(
{"messages": [{"role": "user", "content": "What's my name?"}]},
context=Context(user_name="John Smith")
)
在这个示例中:
dynamic_system_prompt根据 Runtime 中的用户信息动态生成 System Promptbefore_model在模型调用前记录日志after_model在模型调用后记录日志
所有这些逻辑都可以通过 Runtime context 获取当前用户信息,而不需要依赖全局变量或硬编码配置。
Context
在Runtime小节中,我们提到了Context,什么是Context?从源码可以直观的看出,Context是Runtime的组成部分:
@dataclass(**_DC_KWARGS)
class Runtime(Generic[ContextT]):
context: ContextT = field(default=None) # type: ignore[assignment]
"""Static context for the graph run, like `user_id`, `db_conn`, etc.
Can also be thought of as 'run dependencies'."""
store: BaseStore | None = field(default=None)
"""Store for the graph run, enabling persistence and memory."""
stream_writer: StreamWriter = field(default=_no_op_stream_writer)
"""Function that writes to the custom stream."""
previous: Any = field(default=None)
"""The previous return value for the given thread.
Only available with the functional API when a checkpointer is provided.
"""
只要是一个思维正常的开发者,都应该明白,运行时的概念是最大的,比如Go的各种特性都是基于Runtime去实现的,而langchain的Context也是Langchain Runtime的一种特性。
要构建可靠的 Agent,你需要控制:
- Agent Loop 每个步骤发生的事情
- 各个步骤之间发生的事情
| Context 类型 | 可控制内容 | 生命周期 |
|---|---|---|
| Model Context | 模型调用时输入的内容(指令、消息历史、工具、返回格式) | 瞬时 |
| Tool Context | 工具可以访问或生成的数据(state、store、runtime context) | 持久 |
| Life-cycle Context | 模型调用和工具调用之间发生的逻辑(摘要、guardrails、日志等) | 持久 |
瞬时上下文(Transient Context)
指 某一次 LLM 调用时看到的上下文。
例如:
- 修改 messages
- 修改 prompt
- 修改 tools
这些修改 不会改变 state 中保存的数据。
持久上下文(Persistent Context)
指 跨多轮对话持续存在的数据。
例如:
- 生命周期 hook 修改 state
- tool 写入 store
- 系统记录用户信息
这些数据会在之后的执行中继续存在。
在整个执行过程中,Agent 会访问不同的数据来源(读或写)。
| 数据来源 | 也称为 | 作用范围 | 示例 |
|---|---|---|---|
| Runtime Context | 静态配置 | 单次对话 | 用户 ID、API Key、数据库连接、权限、环境配置 |
| State | 短期记忆 | 单次对话 | 当前消息、上传文件、认证状态、工具结果 |
| Store | 长期记忆 | 跨对话 | 用户偏好、提取的知识、历史数据 |
在 LangChain 中,Middleware(中间件)是实现 Context Engineering 的核心机制。
Middleware 允许你在 Agent 生命周期的任何阶段进行干预,例如:
- 更新上下文
- 跳转到 Agent 生命周期中的其他步骤
在接下来的内容中,你会看到 Middleware API 被频繁使用,因为它是 实现 Context Engineering 的核心工具。
Model context(模型上下文)
Model Context 指的是:
每一次模型调用时传递给 LLM 的所有信息。
它包括:
- 指令(instructions)
- 可用工具
- 使用哪个模型
- 输出格式
这些决策会 直接影响 Agent 的可靠性和成本。
模型上下文通常由以下几个部分组成:
System Prompt
开发者提供给 LLM 的基础指令,用于定义模型的行为方式。
Messages
发送给 LLM 的完整消息列表(即对话历史)。
Tools
Agent 可以使用的工具,用于执行操作或获取外部信息。
Model
实际调用的模型(包括模型配置)。
Response Format
模型最终输出的 结构化格式或 Schema 约束。
System Prompt
System Prompt 用于定义 LLM 的行为和能力。
在不同的情况下,Agent 可能需要不同的指令,例如:
- 不同用户
- 不同上下文
- 不同对话阶段
一个优秀的 Agent 会根据:
- 用户历史记忆
- 用户偏好
- 当前配置
动态生成 适合当前对话状态的系统指令。
示例:基于 State 的动态 System Prompt
下面的示例根据 对话轮数 动态调整系统提示词。
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dynamic_prompt
def state_aware_prompt(request: ModelRequest) -> str:
# request.messages 是 request.state["messages"] 的快捷方式
message_count = len(request.messages)
base = "You are a helpful assistant."
if message_count > 10:
base += "\nThis is a long conversation - be extra concise."
return base
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[state_aware_prompt]
)
在这个例子中:
request.messages用于访问当前对话历史- 当对话超过 10 条消息时
- System Prompt 会增加额外指令,要求模型 更加简洁地回答
这就是 基于 State 的动态 Prompt 构建。
我们打开dynamic_prompt的源码部分:
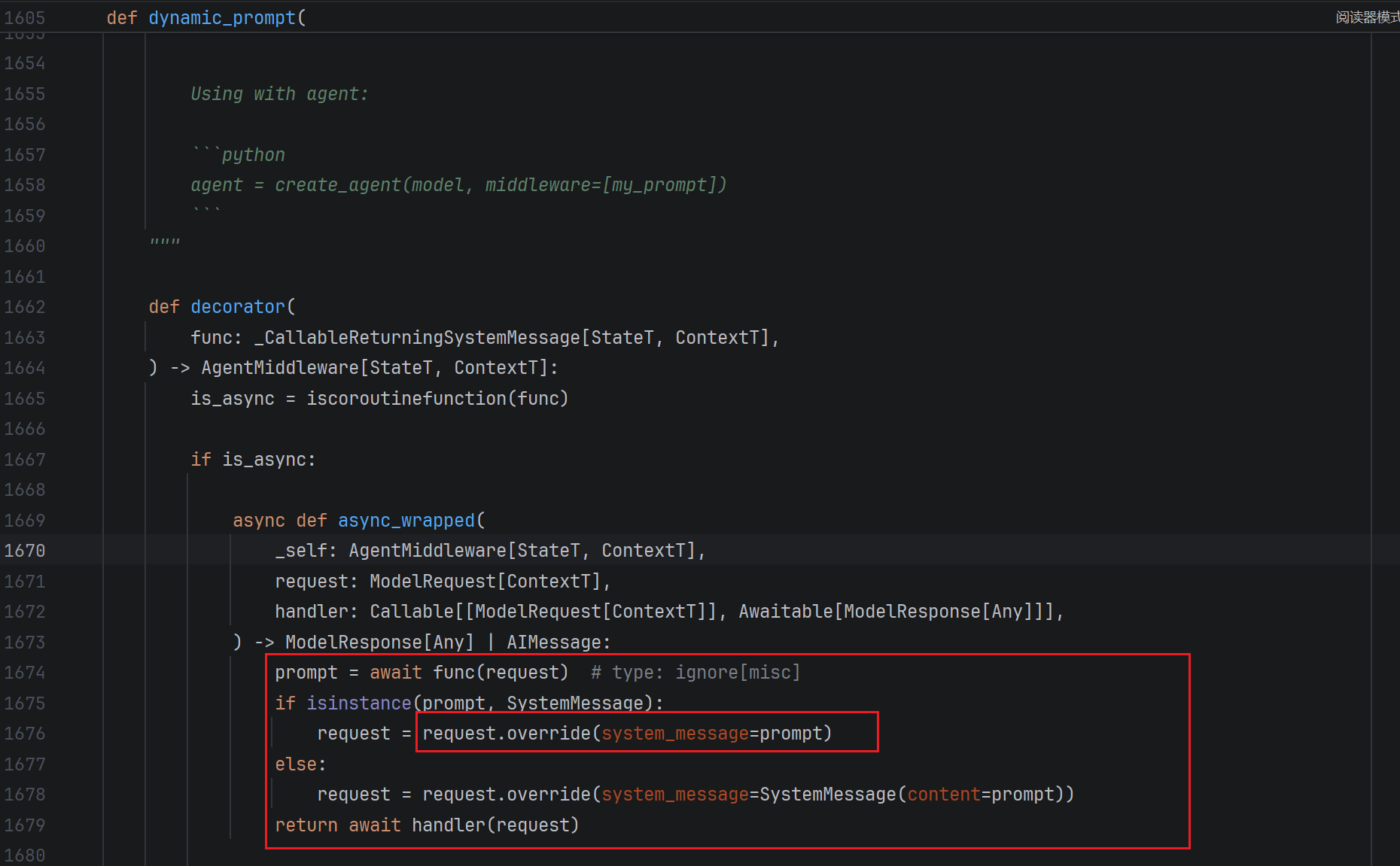
可以看到dynamic_prompt这个语法糖将我们传入的函数的返回值作为了系统的提示词,并且使用override覆盖写入,而这个System Prompt会替换请求的messages列表中的System Prompt!
示例:从长期记忆(Store)中访问用户偏好
下面的示例展示了如何从 Store(长期记忆) 中读取用户偏好,并动态构建 System Prompt。
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@dynamic_prompt
def store_aware_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.user_id
# 从 Store 中读取用户偏好
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
base = "You are a helpful assistant."
if user_prefs:
style = user_prefs.value.get("communication_style", "balanced")
base += f"\nUser prefers {style} responses."
return base
agent = create_agent(
model="gpt-4.1",
tools=[...],
middleware=[store_aware_prompt],
context_schema=Context,
store=InMemoryStore()
)
在这个示例中:
- Runtime Context 提供
user_id - 使用
runtime.store访问 Store(长期记忆) - 从
"preferences"命名空间中读取用户偏好 - 根据用户的
communication_style动态调整 System Prompt
例如:
如果用户偏好是:
communication_style = concise
那么最终生成的 System Prompt 可能会变成:
You are a helpful assistant.
User prefers concise responses.
这种方式可以让 Agent 根据用户历史偏好动态调整行为,从而提升个性化体验和回答质量。
我们打开ModelRequest的源码:
@dataclass(init=False)
class ModelRequest(Generic[ContextT]):
"""Model request information for the agent.
Type Parameters:
ContextT: The type of the runtime context. Defaults to `None` if not specified.
"""
model: BaseChatModel
messages: list[AnyMessage] # excluding system message
system_message: SystemMessage | None
tool_choice: Any | None
tools: list[BaseTool | dict[str, Any]]
response_format: ResponseFormat[Any] | None
state: AgentState[Any]
runtime: Runtime[ContextT]
model_settings: dict[str, Any] = field(default_factory=dict)
可以看到request里面是提供了runtime结构的,除此之外的一些字段则可以通过override方法进行覆写。
示例:基于 Runtime Context 的用户权限过滤工具
下面的示例展示了如何根据 Runtime Context 中的用户权限,动态过滤 Agent 可使用的工具。
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@dataclass
class Context:
user_role: str
@wrap_model_call
def context_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据 Runtime Context 中的权限过滤工具。"""
# 从 Runtime Context 中读取用户角色
user_role = request.runtime.context.user_role
if user_role == "admin":
# 管理员可以使用所有工具
pass
elif user_role == "editor":
# 编辑者不能删除数据
tools = [t for t in request.tools if t.name != "delete_data"]
request = request.override(tools=tools)
else:
# 只读用户只能使用读取类工具
tools = [t for t in request.tools if t.name.startswith("read_")]
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="gpt-4.1",
tools=[read_data, write_data, delete_data],
middleware=[context_based_tools],
context_schema=Context
)
在这个示例中:
-
Runtime Context 提供
user_role(用户角色)。 -
中间件根据角色 动态过滤工具列表:
- admin:可以使用所有工具
- editor:不能使用
delete_data - viewer:只能使用以
read_开头的只读工具
-
通过
request.override(tools=tools)修改当前模型调用时可见的工具。
这种方式可以实现 基于权限的工具访问控制(RBAC),确保不同角色的用户只能调用符合权限范围的工具,同时避免将权限逻辑硬编码到 Agent 或工具内部。
总之大体上就是这三类,你只需要逮着一个参数点点点,总能达到你的目的!
Tool Context(工具上下文)
工具(Tools)的特殊之处在于:
它们既可以读取上下文,也可以写入上下文。
在最基本的情况下,当一个工具被执行时:
- 工具接收 LLM 生成的调用参数
- 执行对应逻辑
- 返回 Tool Message 作为执行结果
也就是说:
- 工具完成具体任务
- 并将执行结果返回给 Agent
除此之外,工具还可以 获取重要信息并提供给模型,从而帮助模型更好地完成任务。
Reads(读取上下文)
在真实场景中,大多数工具不仅仅依赖 LLM 提供的参数,还需要额外信息,例如:
- 用户 ID(用于数据库查询)
- API Key(用于调用外部服务)
- 当前会话状态(用于决策逻辑)
因此,工具通常会从以下数据源读取信息:
- State(短期记忆)
- Store(长期记忆)
- Runtime Context(运行时配置)
下面的示例展示了如何从 State(短期记忆) 中读取当前会话信息。
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@tool
def check_authentication(
runtime: ToolRuntime
) -> str:
"""检查用户是否已经认证。"""
# 从 State 中读取当前认证状态
current_state = runtime.state
is_authenticated = current_state.get("authenticated", False)
if is_authenticated:
return "User is authenticated"
else:
return "User is not authenticated"
agent = create_agent(
model="gpt-4.1",
tools=[check_authentication]
)
在这个例子中:
runtime.state提供当前会话的 短期状态- 工具通过
authenticated字段判断用户是否已登录 - 然后返回对应的认证状态信息
这种方式可以让工具根据 当前会话状态 做出不同的行为决策。
而从Store以及Context中读取数据只需要用runtime去点出各种属性即可!毕竟runtime都有了,相当于整个agent运行的”堆栈“都在你手中,还有什么数据是拿不到的。
store = runtime.store
existing_prefs = store.get(("preferences",), user_id)
db_connection = runtime.context.db_connection
Writes(写入上下文)
工具执行的结果不仅可以帮助 Agent 完成当前任务,还可以 更新 Agent 的记忆,从而让后续步骤能够访问这些重要信息。
工具可以通过两种方式产生影响:
- 直接将结果返回给模型
- 更新 Agent 的记忆(State 或 Store)
下面的示例展示了如何通过 Command 向 State 写入数据,以记录当前会话中的状态信息。
当工具需要 更新图(graph)的状态 时,应返回一个
Command(例如设置用户偏好或应用状态)。
Command可以 只包含状态更新,也可以 同时包含一个ToolMessage。如果模型需要看到工具执行成功的信息(例如确认用户偏好已经修改),那么在
update中应包含一个ToolMessage,并使用runtime.tool_call_id作为tool_call_id参数。
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.types import Command
@tool
def authenticate_user(
password: str,
runtime: ToolRuntime
) -> Command:
"""Authenticate user and update State."""
# 执行认证逻辑(简化示例)
if password == "correct":
# 写入 State:标记用户已认证
return Command(
update={"authenticated": True},
)
else:
return Command(update={"authenticated": False})
agent = create_agent(
model="gpt-4.1",
tools=[authenticate_user]
)
在这个示例中:
- 工具接收用户输入的
password - 执行简单的认证逻辑
- 使用
Command(update=...)更新 State - 将
authenticated字段写入当前会话状态
这样,在后续步骤中:
- 其他工具
- Middleware
- Agent 逻辑
都可以通过 state["authenticated"] 判断用户是否已经登录。
ToolRuntime
ToolRuntime是Runtime的一个“受限视图(restricted view)”,专门给 Tool 使用。
也就是说:
Runtime → Agent / Middleware 用
ToolRuntime → Tool 用
Tool 是 模型可以调用的东西,而 Middleware / Agent 是 开发者控制的代码。
所以框架必须保证:
Tool 不能随便操作整个 Runtime
如果直接给 Tool 完整 Runtime,理论上工具就可以:
- 改 Agent 执行流程
- 修改 Graph 运行结构
- 跳节点
- 改调度逻辑
这显然不合理。
所以 ToolRuntime 只暴露 工具真正需要的能力:
常见字段:
runtime.state
runtime.context
runtime.store
runtime.stream_writer
runtime.tool_call_id
但不会暴露:
graph
scheduler
node control
jump control
middleware control
所以:
Runtime = 完整执行环境
ToolRuntime = 工具执行环境
类似 沙箱化 API。
如果工具直接接收 Runtime:
def my_tool(runtime: Runtime)
开发者会误以为:
工具可以控制 Agent 运行
但实际上工具应该只是:
读取上下文
执行动作
返回结果
而不是:
控制 Agent Loop
所以 LangChain 用 ToolRuntime 明确表达:
这是工具的运行环境
不是 Agent 的运行环境
这是一种 语义边界(semantic boundary)。
LangChain 会通过 参数类型自动注入依赖:
例如:
ToolRuntime → 注入工具运行环境
Runtime → 注入 middleware runtime
如果统一用 Runtime,就会出现:
工具 runtime
middleware runtime
混在一起,容易出错。
现在类型是:
ToolRuntime
Runtime
框架一眼就知道该注入哪个对象。
LangGraph 未来可能会让 ToolRuntime 支持:
- 限制 Store 访问
- 限制 Namespace
- 限制 Stream
- 沙箱权限
例如:
ToolRuntime(read_only_store=True)
如果工具拿到完整 Runtime,这些控制就很难做。
为什么 Tool 写 state 要用 Command,而不是直接改 runtime.state
这个设计其实是 LangGraph 的核心思想之一:让 Agent 执行过程保持“可控、可回放、可合成”。
如果 Tool 可以直接改 runtime.state,很多关键能力都会被破坏。
保证 Graph 执行是“可回放”的(deterministic execution)
LangGraph 本质上是一个 状态机 + 图执行引擎。
每一步执行都会形成:
(state_before)
↓
Node 执行
↓
(state_update)
↓
(state_after)
如果 Tool 直接这样改:
runtime.state["authenticated"] = True
那么问题来了:
state 是什么时候被改的?
是:
工具内部
Graph 引擎是 不知道的。
但如果用:
return Command(update={"authenticated": True})
Graph 会记录:
node: authenticate_user
update: {"authenticated": True}
于是整个执行变成:
(state_before)
↓
tool node
↓
Command(update)
↓
reducer
↓
(state_after)
这样就可以 完全回放执行过程。
这对很多能力很重要:
- Debug
- Replay
- Agent trace
- LangSmith 可视化
统一 State 更新入口(Reducer 机制)
LangGraph 的 State 更新不是简单的 dict.update,而是通过 Reducer。
例如 messages:
messages: Annotated[list, add_messages]
更新时不是:
覆盖
而是:
append
如果 Tool 直接写:
runtime.state["messages"] = [...]
就会破坏 reducer 逻辑。
而 Command(update=...) 会经过 reducer:
Command
↓
Reducer
↓
State update
例如:
old messages = [A, B]
update = [C]
结果 = [A, B, C]
而不是覆盖。
支持 Middleware 组合(非常关键)
LangChain 支持多个 middleware 叠加。
比如:
retry middleware
logging middleware
tracking middleware
这些 middleware 都可能返回:
ExtendedModelResponse(
command=Command(...)
)
LangGraph 会做:
Command 合成
执行顺序:
inner middleware
↓
outer middleware
如果 Tool 直接改 state:
runtime.state["x"] = ...
那 middleware 就 没法合成这些更新。
但用 Command:
Command(update={...})
Graph 可以统一处理:
Command1
Command2
Command3
↓
Reducer
↓
Final State
支持“失败回滚”
想象一种情况:
Tool 执行
↓
State 已经被改
↓
Tool 抛异常
如果 Tool 直接改 state:
状态已经被污染
但用 Command:
Tool 成功 → Command 才会应用
Tool 失败 → Command 丢弃
这样状态就不会被破坏。
还有一个很高级的能力:Execution Trace
LangGraph 内部可以记录:
step1
step2
step3
每一步都有:
state diff
例如:
step 5
node: authenticate_user
state diff:
authenticated: False → True
如果 Tool 直接改 state:
这个 diff 就没法计算
Human-in-the-loop
某些工具操作可能具有较高风险,因此在执行之前需要 人工审批。
Deep Agents 通过 LangGraph 的 interrupt(中断)机制 来支持 Human-in-the-loop 工作流。
你可以通过 interrupt_on 参数指定 哪些工具在执行前需要人工确认。
基本流程如下:
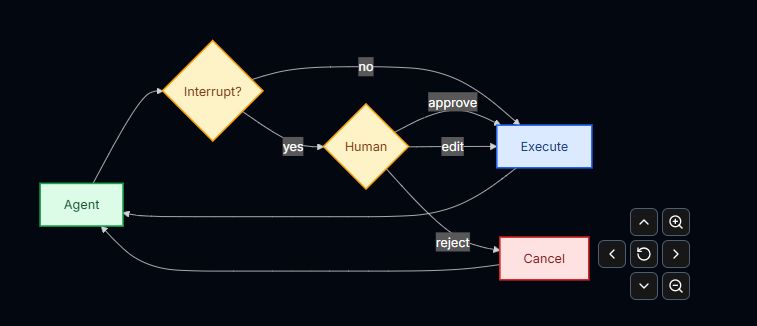
人工可以:
- approve:批准执行
- edit:修改参数后执行
- reject:拒绝执行
interrupt_on 参数接收一个字典,用于 将工具名称映射到对应的中断配置。
每个工具可以配置为:
-
True
启用中断,使用默认行为(允许 approve / edit / reject) -
False
禁用中断,工具可以直接执行 -
{“allowed_decisions”: […]}
自定义允许的人工决策类型
示例:
from langchain.tools import tool
from deepagents import create_deep_agent
from langgraph.checkpoint.memory import MemorySaver
@tool
def delete_file(path: str) -> str:
"""Delete a file from the filesystem."""
return f"Deleted {path}"
@tool
def read_file(path: str) -> str:
"""Read a file from the filesystem."""
return f"Contents of {path}"
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""Send an email."""
return f"Sent email to {to}"
# Human-in-the-loop 必须使用 Checkpointer
checkpointer = MemorySaver()
agent = create_deep_agent(
model="claude-sonnet-4-6",
tools=[delete_file, read_file, send_email],
interrupt_on={
"delete_file": True, # 默认允许 approve / edit / reject
"read_file": False, # 不需要人工确认
"send_email": {"allowed_decisions": ["approve", "reject"]}, # 不允许修改参数
},
checkpointer=checkpointer # 必须提供
)
需要注意的是:
Human-in-the-loop 功能必须启用 Checkpointer,因为中断时需要保存当前执行状态,以便人工处理完成后继续执行。
决策类型(Decision Types):
allowed_decisions 用于控制 人工可以对工具调用做出哪些操作。
可选值包括:
“approve”
按照 Agent 提出的原始参数 直接执行工具。
“edit”
在执行前 修改工具参数。
“reject”
完全跳过这次工具调用,不执行该工具。
你可以为不同风险级别的工具配置不同的审批策略:
interrupt_on = {
# 高风险操作:允许所有选项
"delete_file": {"allowed_decisions": ["approve", "edit", "reject"]},
# 中等风险:只能批准或拒绝
"write_file": {"allowed_decisions": ["approve", "reject"]},
# 必须执行(只能批准)
"critical_operation": {"allowed_decisions": ["approve"]},
}
通过这种方式,可以为 Agent 的工具调用建立 细粒度的安全控制机制,确保关键操作在执行前得到人工确认。
delete_file,write_file,critical_operation 均为工具名字
处理中断(Handle interrupts)
当触发中断时,Agent 会暂停执行并将控制权返回。你需要在结果中检查是否存在中断,并根据情况进行处理。
import uuid
from langgraph.types import Command
# 创建包含 thread_id 的配置,用于状态持久化
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
# 调用 agent
result = agent.invoke(
{"messages": [{"role": "user", "content": "Delete the file temp.txt"}]},
config=config,
version="v2",
)
# 检查执行是否被中断
if result.interrupts:
# 提取中断信息
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
review_configs = interrupt_value["review_configs"]
# 创建从工具名称到 review_config 的映射
config_map = {cfg["action_name"]: cfg for cfg in review_configs}
# 向用户展示待处理的操作
for action in action_requests:
review_config = config_map[action["name"]]
print(f"Tool: {action['name']}")
print(f"Arguments: {action['args']}")
print(f"Allowed decisions: {review_config['allowed_decisions']}")
# 获取用户决策(按 action_request 顺序,一一对应)
decisions = [
{"type": "approve"} # 用户批准删除操作
]
# 根据用户决策恢复执行
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config, # 必须使用相同的 config!
version="v2",
)
# 处理最终结果
print(result.value["messages"][-1].content)
当 Agent 调用多个需要审批的工具时,所有中断会被 合并(batch)到一个 interrupt 中。
你必须 按顺序为每个工具提供对应的决策。
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
result = agent.invoke(
{"messages": [{
"role": "user",
"content": "Delete temp.txt and send an email to admin@example.com"
}]},
config=config,
version="v2",
)
if result.interrupts:
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
# 有两个工具需要审批
assert len(action_requests) == 2
# 决策必须与 action_requests 顺序一致
decisions = [
{"type": "approve"}, # 第一个工具:delete_file
{"type": "reject"} # 第二个工具:send_email
]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)
如果 allowed_decisions 中包含 "edit",你可以在执行工具之前 修改工具参数:
if result.interrupts:
interrupt_value = result.interrupts[0].value
action_request = interrupt_value["action_requests"][0]
# Agent 原始参数
print(action_request["args"]) # {"to": "everyone@company.com", ...}
# 用户决定修改收件人
decisions = [{
"type": "edit",
"edited_action": {
"name": action_request["name"], # 必须包含工具名称
"args": {"to": "team@company.com", "subject": "...", "body": "..."}
}
}]
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)
另外需要注意的是,在前后端交互的环境中,我们需要把中断内容发给前端进行渲染,并且需要实现一个resume接口进行重启会话:
def chat():
config = {"configurable": {"thread_id": "generalzy"}}
# Invoke the agent
result:GraphOutput = agent.invoke(
{"messages": [{"role": "user", "content": "调用本地add工具计算1+1等于几"}]},
config=config,
version="v2",
)
# Check if execution was interrupted
if result.interrupts:
# Extract interrupt information
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
review_configs = interrupt_value["review_configs"]
# Create a lookup map from tool name to review config
config_map = {cfg["action_name"]: cfg for cfg in review_configs}
# Display the pending actions to the user
for action in action_requests:
review_config = config_map[action["name"]]
print(f"Tool: {action['name']}")
print(f"Arguments: {action['args']}")
print(f"Allowed decisions: {review_config['allowed_decisions']}")
# 生产环境中直接把中断发给前端
return {
"status": "interrupt",
"Tool": action['name'],
"Arguments": action['args'],
"Allowed decisions": review_config['allowed_decisions']
}
else:
pprint(result)
# 正常返回
return {
"status": "completed",
"message": result.value["messages"][-1].content
}
def resume(decisions):
config = {"configurable": {"thread_id": "generalzy"}}
result = agent.invoke(
Command(resume={"decisions": decisions}),
config=config,
version="v2",
)
# Check if execution was interrupted
if result.interrupts:
# Extract interrupt information
interrupt_value = result.interrupts[0].value
action_requests = interrupt_value["action_requests"]
review_configs = interrupt_value["review_configs"]
# Create a lookup map from tool name to review config
config_map = {cfg["action_name"]: cfg for cfg in review_configs}
# Display the pending actions to the user
for action in action_requests:
review_config = config_map[action["name"]]
print(f"Tool: {action['name']}")
print(f"Arguments: {action['args']}")
print(f"Allowed decisions: {review_config['allowed_decisions']}")
# 生产环境中直接把中断发给前端
return {
"status": "interrupt",
"Tool": action['name'],
"Arguments": action['args'],
"Allowed decisions": review_config['allowed_decisions']
}
else:
pprint(result)
# 正常返回
return {
"status": "completed",
"message": result.value["messages"][-1].content
}
def main():
result = chat()
if result["status"] == "completed":
print(result["message"])
elif result["status"] == "interrupt":
result = resume(decisions=[{"type": "approve"}])
print(result["message"])
print("bye bye!")
if __name__ == '__main__':
main()
可以看到,我们在前端允许了add操作,后台agent自然进行了一次Tool Call得到了ToolMessage: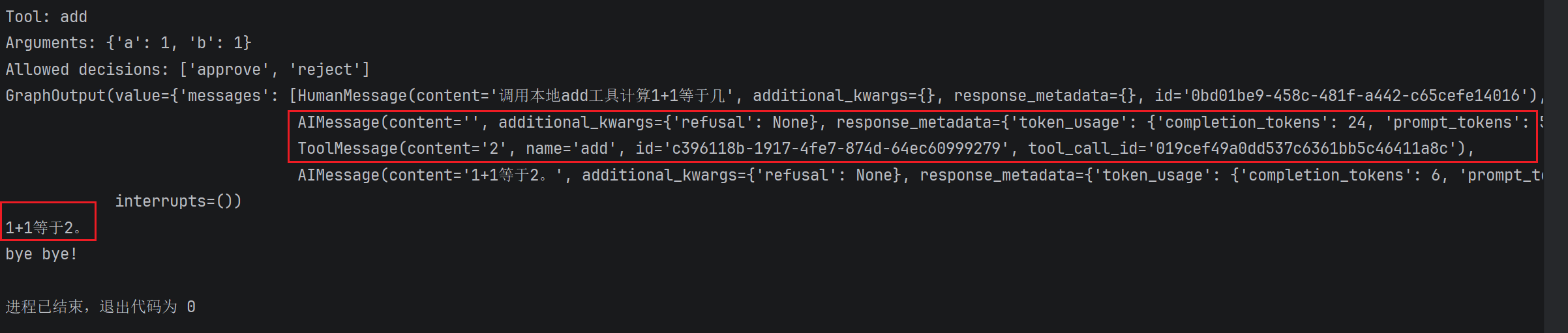
其他类型的中断处理大致一样,这里就不再赘述!
子 Agent 中的中断(Subagent interrupts)
在使用 子 Agent(subagents) 时,可以在两种地方使用中断:
- 工具调用时触发中断(Interrupts on tool calls)
- 工具内部触发中断(Interrupts within tool calls)
工具调用时的中断(Interrupts on tool calls)
每个 子 Agent 都可以拥有自己的 interrupt_on 配置,用于 覆盖主 Agent 的设置:
agent = create_deep_agent(
tools=[delete_file, read_file],
interrupt_on={
"delete_file": True,
"read_file": False,
},
subagents=[{
"name": "file-manager",
"description": "Manages file operations",
"system_prompt": "You are a file management assistant.",
"tools": [delete_file, read_file],
"interrupt_on": {
# 覆盖设置:在这个子 agent 中读取文件也需要审批
"delete_file": True,
"read_file": True, # 与主 agent 不同
}
}],
checkpointer=checkpointer
)
含义是:
主 Agent:
delete_file → 需要审批
read_file → 不需要审批
子 Agent:
delete_file → 需要审批
read_file → 需要审批
当 子 Agent 触发中断 时,处理方式与普通 Agent 相同:
- 在结果中检查
result.interrupts - 使用
Command(resume=...)恢复执行
工具内部触发中断(Interrupts within tool calls)
子 Agent 的工具也可以 直接调用 interrupt() 来暂停执行并等待用户审批。
示例:
from langchain.agents import create_agent
from langchain_anthropic import ChatAnthropic
from langchain.messages import HumanMessage
from langchain.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command, interrupt
from deepagents.graph import create_deep_agent
from deepagents.middleware.subagents import CompiledSubAgent
定义一个需要审批的工具:
@tool(description="Request human approval before proceeding with an action.")
def request_approval(action_description: str) -> str:
"""使用 interrupt() 请求人工审批"""
# interrupt() 会暂停执行,并返回 Command(resume=...) 中传入的值
approval = interrupt({
"type": "approval_request",
"action": action_description,
"message": f"Please approve or reject: {action_description}",
})
if approval.get("approved"):
return f"Action '{action_description}' was APPROVED. Proceeding..."
else:
return f"Action '{action_description}' was REJECTED. Reason: {approval.get('reason', 'No reason provided')}"
完整示例
def main():
checkpointer = InMemorySaver()
model = ChatAnthropic(
model_name="claude-sonnet-4-6",
max_tokens=4096,
)
compiled_subagent = create_agent(
model=model,
tools=[request_approval],
name="approval-agent",
)
parent_agent = create_deep_agent(
checkpointer=checkpointer,
subagents=[
CompiledSubAgent(
name="approval-agent",
description="An agent that can request approvals",
runnable=compiled_subagent,
)
],
)
thread_id = "test_interrupt_directly"
config = {"configurable": {"thread_id": thread_id}}
print("Invoking agent - sub-agent will use request_approval tool...")
result = parent_agent.invoke(
{
"messages": [
HumanMessage(
content="Use the task tool to launch the approval-agent sub-agent. "
"Tell it to use the request_approval tool to request approval for 'deploying to production'."
)
]
},
config=config,
version="v2",
)
检测中断并恢复执行
# 检查是否触发中断
if result.interrupts:
interrupt_value = result.interrupts[0].value
print("\nInterrupt received!")
print(f" Type: {interrupt_value.get('type')}")
print(f" Action: {interrupt_value.get('action')}")
print(f" Message: {interrupt_value.get('message')}")
print("\nResuming with Command(resume={'approved': True})...")
result2 = parent_agent.invoke(
Command(resume={"approved": True}),
config=config,
version="v2",
)
if not result2.interrupts:
print("\nExecution completed!")
# 找到工具执行结果
tool_msgs = [m for m in result2.value.get("messages", []) if m.type == "tool"]
if tool_msgs:
print(f" Tool result: {tool_msgs[-1].content}")
else:
print("\nAnother interrupt occurred")
else:
print("\n No interrupt - the model may not have called request_approval")
运行输出示例
Invoking agent - sub-agent will use request_approval tool...
Interrupt received!
Type: approval_request
Action: deploying to production
Message: Please approve or reject: deploying to production
Resuming with Command(resume={'approved': True})...
Execution completed!
Tool result: Great! The approval request has been processed. The action "deploying to production" was APPROVED. You can now proceed with the production deployment.
在工具函数内部调用:
interrupt({...})
这种方式更灵活,可以:
- 动态构造审批信息
- 实现复杂的 human-in-the-loop 流程
- 自定义审批逻辑
interrupt_on和 interrupt的使用场景
1️⃣ interrupt_on(Agent 自动拦截工具调用)
如果你配置了:
interrupt_on = {
"delete_file": True
}
当 Agent 准备调用这个工具时,LangGraph 会 自动触发 interrupt。
返回的数据类似:
{
"action_requests": [
{
"name": "delete_file",
"args": {"path": "temp.txt"}
}
],
"review_configs": [
{
"action_name": "delete_file",
"allowed_decisions": ["approve","reject","edit"]
}
]
}
特点:
- 不需要在工具里写
interrupt() - 在 工具调用之前暂停
- 属于 Agent runtime 控制
流程:
LLM
↓
决定调用 tool
↓
interrupt_on 拦截
↓
interrupt
↓
等待用户 approve
↓
resume
↓
真正执行 tool
2️⃣ 工具内部 interrupt()(工具主动暂停)
如果你在工具里写:
approval = interrupt({
"type": "approval_request",
"action": "deploy",
})
此时:
- 工具执行过程中暂停
- interrupt 返回的是你传入的数据
例如:
{
"type": "approval_request",
"action": "deploy"
}
恢复时:
Command(resume={"approved": True})
这个数据会返回给:
approval = interrupt(...)
也就是说:
approval == {"approved": True}
特点:
- 完全自定义 interrupt 数据
- 在 工具内部逻辑中断
实际生产系统一般同时用两种
例如安全 Agent:
run_shell → interrupt_on
deploy_prod → interrupt_on
而发布流程:
create_release
↓
interrupt() 请求审批
interrupt() 实际做的是:
raise GraphInterrupt
LangGraph 捕获后:
保存 graph state
返回 interrupt
暂停执行
resume 时:
恢复 graph stack
继续执行
所以它其实是 Graph execution pause。
Streaming(流式输出V2)
该功能要求:
LangGraph >= 1.1
并且需要在调用 stream() 或 astream() 时指定:
version="v2"
在 v2 版本中,所有返回的数据块都采用统一格式:
{
"type": "values" | "updates" | "messages" | "custom" | "checkpoints" | "tasks" | "debug",
"ns": (), # namespace(子图时会使用)
"data": ..., # 实际数据(取决于 stream mode)
}
其中:
| 字段 | 含义 |
|---|---|
type |
数据类型 |
ns |
命名空间(子图事件会使用) |
data |
具体数据 |
每种 stream mode 对应一个 TypedDict 类型:
ValuesStreamPartUpdatesStreamPartMessagesStreamPartCustomStreamPartCheckpointStreamPartTasksStreamPartDebugStreamPart
这些类型可以从langgraph.types导入。
所有类型的联合类型是:
StreamPart
它是一个 以 part["type"] 为判别字段的联合类型(discriminated union),因此在编辑器或类型检查器中可以实现 精确的类型推断(type narrowing)。
v1 与 v2 的区别
默认版本是 v1,其输出结构会根据 streaming 配置发生变化,例如:
- 单个 mode → 返回原始数据
- 多个 mode → 返回
(mode, data) - subgraph → 返回
(namespace, data)
而 v2 的格式始终统一:
for chunk in graph.stream(inputs, stream_mode="updates", version="v2"):
print(chunk["type"]) # "updates"
print(chunk["ns"]) # ()
print(chunk["data"]) # {"node_name": {"key": "value"}}
由于 type 字段是判别字段,可以按类型分支处理数据:
for part in graph.stream(
{"topic": "ice cream"},
stream_mode=["values", "updates", "messages", "custom"],
version="v2",
):
if part["type"] == "values":
# 完整 state 快照
print(f"State: topic={part['data']['topic']}")
elif part["type"] == "updates":
# 仅包含节点更新的数据
for node_name, state in part["data"].items():
print(f"Node `{node_name}` updated: {state}")
elif part["type"] == "messages":
# LLM message chunk
msg, metadata = part["data"]
print(msg.content, end="", flush=True)
elif part["type"] == "custom":
# 自定义流式数据
print(f"Progress: {part['data']['progress']}%")
Stream 模式(Stream modes)
在调用 stream() 或 astream() 方法时,可以传入一个 stream modes 列表,用于指定你希望接收的流式数据类型。
| Mode | Type | 说明 |
|---|---|---|
values |
ValuesStreamPart |
每一步执行后返回 完整的 state |
updates |
UpdatesStreamPart |
每一步执行后返回 state 的更新部分。同一步中多个更新会分别流式输出 |
messages |
MessagesStreamPart |
LLM 调用产生的 (token, metadata) 二元组 |
custom |
CustomStreamPart |
通过 get_stream_writer() 从节点中发送的 自定义数据 |
checkpoints |
CheckpointStreamPart |
Checkpoint 事件(格式与 get_state() 相同),需要配置 checkpointer |
tasks |
TasksStreamPart |
任务开始/结束事件,包含执行结果和错误信息,需要 checkpointer |
debug |
DebugStreamPart |
所有可用信息(包含 checkpoints 和 tasks,并附加额外 metadata) |
这些 stream modes 本质上是在解决一个问题:
Agent / Graph 执行过程中,你希望实时看到什么信息?
不同 mode 对应 不同粒度的运行信息。如果你在做 Agent 平台 / UI / 调试工具,这些 mode 的用途会非常明显。
生产环境最常用的是这四个:
messages
updates
values
custom
1️⃣ messages —— LLM token streaming
用途:
实现 ChatGPT 那种逐字输出
返回:
(token, metadata)
示例:
for part in graph.stream(..., stream_mode="messages"):
msg, metadata = part["data"]
print(msg.content, end="")
效果:
The answer is...
The answer is 42
使用场景:
- 聊天 UI
- token streaming
- 减少 LLM latency 体感
典型 UI:
Assistant typing...
如果你做 聊天界面,这个基本是 必须用的。
2️⃣ updates —— 每个节点的 state 变化
用途:
观察 graph 每个 node 执行后的变化
返回:
{
node_name: {state_update}
}
示例:
Node refine_topic updated:
{'topic': 'ice cream and cats'}
使用场景:
Agent execution timeline
例如 UI:
Step 1 refine_topic
Step 2 generate_joke
Step 3 call_tool
很多 Agent 可视化工具都用这个。
优点:
数据小
只返回变化
3️⃣ values —— 每一步完整 state
用途:
获取完整 graph state
示例:
{
topic: "ice cream and cats",
joke: "This is a joke..."
}
与 updates 的区别:
| mode | 返回 |
|---|---|
| updates | 只返回变化 |
| values | 返回完整 state |
例如:
Step1
updates → {"topic": "..."}
values → {"topic": "...", "joke": ""}
Step2
updates → {"joke": "..."}
values → {"topic": "...", "joke": "..."}
使用场景:
state debugging
state replay
state visualization
但缺点:
数据量更大
所以生产系统 通常用 updates 而不是 values。
4️⃣ custom —— 节点主动发消息
用途:
节点主动发进度信息
需要用:
writer = get_stream_writer()
writer({"progress": 30})
流输出:
Progress: 30%
使用场景:
例如:
检索 10000 条漏洞
UI:
Scanning CVE database...
Progress 10%
Progress 30%
Progress 80%
特别适合:
长任务
RAG
数据处理
下面这三个更多是 系统级功能。
5️⃣ checkpoints
用途:
graph checkpoint 保存事件
前提:
必须使用 checkpointer
例如:
InMemorySaver
RedisSaver
PostgresSaver
返回:
checkpoint state
使用场景:
恢复执行
time travel debugging
state replay
例如:
resume agent
6️⃣ tasks
用途:
任务开始 / 结束
返回:
task started
task finished
task error
示例:
Task generate_joke started
Task generate_joke finished
使用场景:
Agent execution timeline
UI:
Task1 running
Task2 finished
Task3 error
7️⃣ debug
用途:
所有调试信息
包括:
checkpoints
tasks
metadata
internal info
相当于:
debug = checkpoints + tasks + extra
使用场景:
调试 graph
开发 agent
生产环境一般不会开。
实际系统通常这样用:
聊天 UI
messages
实现:
token streaming
Agent 可视化 UI
messages
updates
效果:
LLM token
+
agent step
类似:
Thinking...
Calling tool...
Tool finished
Answer:
长任务
messages
updates
custom
例如:
progress
step
token
调试
updates
debug
一个真实 Agent UI 的 streaming 结构
例如:
User: 查找最近的漏洞
stream:
messages → "Searching"
updates → node search_cve started
custom → progress 20%
custom → progress 80%
updates → node summarize finished
messages → "Found 3 vulnerabilities..."
UI:
Searching...
[████████] 80%
Found 3 vulnerabilities...
如果你做 Agent 平台(很关键)
通常 streaming 会组合:
messages → token streaming
updates → agent step
custom → progress
tasks → monitoring
这样 UI 才完整。
messages 是 LLM streaming
updates 是 agent streaming
两者是不同层:
LLM
↓
messages
Agent Graph
↓
updates
与任意 LLM 一起使用(Use with any LLM)
你可以使用 stream_mode="custom" 来 从任意 LLM API 进行流式输出,即使该 API 没有实现 LangChain 的 Chat Model 接口。
这意味着你可以集成:
- 原生 LLM 客户端(raw LLM clients)
- 外部服务提供的 streaming API
- 自定义模型接口
示例:从任意模型流式输出
from langgraph.config import get_stream_writer
def call_arbitrary_model(state):
"""示例节点:调用任意模型并流式返回输出"""
# 获取 stream writer 用于发送自定义数据
writer = get_stream_writer()
# 假设你有一个 streaming client 会不断产生数据块
for chunk in your_custom_streaming_client(state["topic"]):
# 将数据写入 streaming channel
writer({"custom_llm_chunk": chunk})
return {"result": "completed"}
构建 graph:
graph = (
StateGraph(State)
.add_node(call_arbitrary_model)
# 可以添加其他节点和边
.compile()
)
运行 graph,并使用 stream_mode="custom" 接收流数据:
for chunk in graph.stream(
{"topic": "cats"},
stream_mode="custom",
version="v2",
):
if chunk["type"] == "custom":
# data 中包含从 LLM 流出的自定义数据
print(chunk["data"])
扩展示例:流式调用任意 Chat Model
import operator
import json
from typing import TypedDict
from typing_extensions import Annotated
from langgraph.graph import StateGraph, START
from openai import AsyncOpenAI
初始化 OpenAI 客户端:
openai_client = AsyncOpenAI()
model_name = "gpt-4.1-mini"
定义一个 token streaming 生成器:
async def stream_tokens(model_name: str, messages: list[dict]):
response = await openai_client.chat.completions.create(
messages=messages,
model=model_name,
stream=True
)
role = None
async for chunk in response:
delta = chunk.choices[0].delta
if delta.role is not None:
role = delta.role
if delta.content:
yield {"role": role, "content": delta.content}
定义工具函数
async def get_items(place: str) -> str:
"""列出某个地方可能存在的物品"""
writer = get_stream_writer()
response = ""
async for msg_chunk in stream_tokens(
model_name,
[
{
"role": "user",
"content": (
"Can you tell me what kind of items "
f"i might find in the following place: '{place}'. "
"List at least 3 such items separating them by a comma. "
"And include a brief description of each item."
),
}
],
):
response += msg_chunk["content"]
# 将 token streaming 发送到 LangGraph stream
writer(msg_chunk)
return response
Graph State
class State(TypedDict):
messages: Annotated[list[dict], operator.add]
Tool 调用节点
async def call_tool(state: State):
ai_message = state["messages"][-1]
tool_call = ai_message["tool_calls"][-1]
function_name = tool_call["function"]["name"]
if function_name != "get_items":
raise ValueError(f"Tool {function_name} not supported")
function_arguments = tool_call["function"]["arguments"]
arguments = json.loads(function_arguments)
function_response = await get_items(**arguments)
tool_message = {
"tool_call_id": tool_call["id"],
"role": "tool",
"name": function_name,
"content": function_response,
}
return {"messages": [tool_message]}
构建 Graph
graph = (
StateGraph(State)
.add_node(call_tool)
.add_edge(START, "call_tool")
.compile()
)
触发 Tool Call
传入一个包含 tool call 的 AIMessage:
inputs = {
"messages": [
{
"content": None,
"role": "assistant",
"tool_calls": [
{
"id": "1",
"function": {
"arguments": '{"place":"bedroom"}',
"name": "get_items",
},
"type": "function",
}
],
}
]
}
运行:
async for chunk in graph.astream(
inputs,
stream_mode="custom",
version="v2",
):
if chunk["type"] == "custom":
print(chunk["data"]["content"], end="|", flush=True)
为特定 Chat Model 禁用 Streaming
如果你的应用同时使用:
- 支持 streaming 的模型
- 不支持 streaming 的模型
则可能需要 显式禁用 streaming。
初始化模型时设置:
streaming=False
例如使用 LangChain:
from langchain.chat_models import init_chat_model
model = init_chat_model(
"claude-sonnet-4-6",
# 禁用 streaming
streaming=False
)
有些模型集成不支持 streaming 参数。
这时可以使用:
disable_streaming=True
该参数由 ChatModel 的 基类提供,因此 所有 Chat Model 都支持。
Model profiles(模型配置档)
Model profiles 需要 langchain >= 1.1。
在 LangChain 中,Chat Model 可以通过 .profile 属性暴露一个字典,用于描述 模型支持的能力与限制。
示例:
model.profile
# {
# "max_input_tokens": 400000,
# "image_inputs": True,
# "reasoning_output": True,
# "tool_calling": True,
# ...
# }
大部分模型 profile 数据来自 开源项目:
- models.dev
该项目提供:
- 模型能力数据
- 上下文窗口
- multimodal 支持
- tool calling 支持等
LangChain 在此基础上会增加一些字段,以便更好地与 LangChain 生态集成,并持续与 upstream 项目保持同步。
Model profile 允许应用 根据模型能力动态调整行为。
例如:
1️⃣ 自动触发 summarization
Middleware 可以根据:
max_input_tokens
判断上下文窗口大小。
如果上下文接近上限:
自动触发 summarization
2️⃣ 自动选择 structured output 策略
在 create_agent 中:
可以通过检测模型是否支持:
structured_output
自动选择:
- native structured output
- tool calling fallback
3️⃣ 限制输入内容
可以根据 profile 做输入校验,例如:
- 是否支持图片
- 最大 token 输入
- 是否支持 reasoning
如果 profile 数据:
- 缺失
- 过期
- 错误
可以进行修改。
方法 1:快速修复(本地覆盖)
创建一个自定义 profile:
custom_profile = {
"max_input_tokens": 100_000,
"tool_calling": True,
"structured_output": True,
}
初始化模型:
model = init_chat_model("...", profile=custom_profile)
更新 profile
profile 是普通 dict,可以直接更新:
new_profile = model.profile | {"key": "value"}
model.model_copy(update={"profile": new_profile})
如果 model 在多个地方共享:
⚠️ 建议使用 model_copy,避免修改共享状态。
方法 2:修复上游数据(推荐)
模型 profile 的主要数据来源是:
models.dev
更新流程:
Step 1
在 models.dev GitHub 提交 PR 更新数据。
Step 2
如果需要增加 LangChain 特有字段:
修改:
langchain_<package>/data/profile_augmentations.toml
例如:
langchain_anthropic/data/profile_augmentations.toml
Step 3
使用 CLI 工具更新 profile:
pip install langchain-model-profiles
运行:
langchain-profiles refresh \
--provider <provider> \
--data-dir <data_dir>
该命令会:
1️⃣ 从 models.dev 下载最新数据
2️⃣ 合并 profile_augmentations.toml
3️⃣ 写入 profiles.py
示例
在 LangChain monorepo 中:
uv run --with langchain-model-profiles \
--provider anthropic \
--data-dir langchain_anthropic/data
⚠️ 注意
Model profile 目前仍然是 Beta 功能,格式未来可能发生变化。
Model profiles 和传入参数的区别
Model profiles ≠ 传入参数
它们解决的是 两个完全不同的问题。
| 概念 | 作用 | 谁决定 |
|---|---|---|
| Model profiles | 描述模型“能做什么” | 模型/SDK提供 |
| 传入参数 | 控制模型“这次怎么做” | 调用者决定 |
可以理解成:
Model profiles = 模型能力说明书
调用参数 = 本次调用的配置
Model profiles 是模型的能力描述
在 LangChain 1.1 之后,引入了 model.profile。
它是一个 只读能力信息,例如:
model.profile
可能返回:
{
"max_input_tokens": 400000,
"image_inputs": True,
"reasoning_output": True,
"tool_calling": True
}
这些信息说明:
| 字段 | 含义 |
|---|---|
| max_input_tokens | 最大上下文 |
| image_inputs | 是否支持图像 |
| reasoning_output | 是否支持推理输出 |
| tool_calling | 是否支持工具调用 |
注意:
这是模型能力,不是调用配置。
你 不能传入这些值改变模型能力。
例如:
model.profile["image_inputs"] = False
是没有意义的。
传入参数是调用时的配置
调用模型时你传的:
model.invoke(
messages,
temperature=0.7,
max_tokens=1000,
)
这些是:
| 参数 | 作用 |
|---|---|
| temperature | 随机性 |
| max_tokens | 最大生成 |
| stop | 停止符 |
| tools | 工具 |
| response_format | 输出结构 |
这些是 runtime配置。
举个最直观的例子
假设你有一个模型:
model = ChatOpenAI(...)
Model profile
model.profile
输出:
{
"image_inputs": True
}
表示:
这个模型 支持图像输入
你调用:
model.invoke([
{"role":"user","content":[
{"type":"text","text":"这是什么"},
{"type":"image_url","image_url":"..."}
]}
])
这里你 实际使用了这个能力。
为什么要有 Model Profiles
LangChain 引入它的目的主要是:
让 Agent 自动适配模型能力。
例如在 LangChain Agents 里:
Agent 可以自动判断:
if model.profile["tool_calling"]:
使用 function calling
else:
使用 text parsing
再比如:
if model.profile["image_inputs"]:
允许上传图片
这样 同一个 Agent 可以适配不同模型。
Harness capabilities(Harness 能力)
在 LangGraph 中,agent harness 是多种能力的组合,这些能力可以让构建 长时间运行的 agent 更加容易。
一个 agent harness 包含以下能力:
- Planning capabilities(规划能力)
- Virtual filesystem(虚拟文件系统)
- Task delegation(任务委派 / 子代理)
- Context 和 token 管理
- Code execution(代码执行)
- Human-in-the-loop(人类参与决策)
除了这些能力之外,deep agents 还会使用 Skills 和 Memory 来提供额外的上下文和指令。
其中规划能力,虚拟文件系统,代码执行,Context 和 token 管理都与backends有莫大的关系,因此deepagent的backends概念一定要弄明白。
Backends(后端)
Deep agents 通过诸如 ls、read_file、write_file、edit_file、glob 和 grep 等工具向 agent 暴露一个文件系统界面。这些工具通过可插拔的 backend(后端)来运行。read_file 工具在所有 backend 上都原生支持图像文件(.png、.jpg、.jpeg、.gif、.webp),并将其作为多模态内容块返回。
Sandbox 和 LocalShellBackend 还提供 execute 工具。
Filesystem Tools
↓
Backend
├ State
├ Filesystem
├ Store
├ Sandbox
├ Local Shell
├ Composite
└ Custom
↓
Routes
↓
+ execute tool
下面是一些预构建的 filesystem backend,可以快速用于你的 deep agent:
| Built-in backend | Description |
|---|---|
| Default | agent = create_deep_agent() |
| 在 state 中为临时(ephemeral)。Agent 的默认 filesystem backend 存储在 langgraph state 中。注意该 filesystem 只会在单个 thread 生命周期内存在。 | |
| Local filesystem persistence | agent = create_deep_agent(backend=FilesystemBackend(root_dir="/Users/nh/Desktop/")) |
让 deep agent 可以访问本地机器的文件系统。你可以指定 agent 可以访问的根目录。注意 root_dir 必须是绝对路径。 |
|
| Durable store (LangGraph store) | agent = create_deep_agent(backend=lambda rt: StoreBackend(rt)) |
| 让 agent 可以访问跨 thread 持久化的长期存储。这非常适合存储长期记忆或在多次执行之间适用的指令。 | |
| Sandbox | agent = create_deep_agent(backend=sandbox) |
在隔离环境中执行代码。Sandbox 提供 filesystem 工具以及用于运行 shell 命令的 execute 工具。可以选择 Modal、Daytona、Deno 或本地 VFS。 |
|
| Local shell | agent = create_deep_agent(backend=LocalShellBackend(root_dir=".", env={"PATH": "/usr/bin:/bin"})) |
| 在宿主机上直接进行 filesystem 和 shell 执行。没有隔离——只应在受控的开发环境中使用。参见下方的安全注意事项。 | |
| Composite | 默认 /memories/ 持久化,其余为临时(ephemeral)。Composite backend 最为灵活。你可以指定文件系统中的不同路径路由到不同 backend。下面的 Composite routing 提供了一个可以直接使用的示例。 |
StateBackend(临时 / ephemeral)
# 默认提供 StateBackend
agent = create_deep_agent()
# 实际上底层等价于
from deepagents.backends import StateBackend
agent = create_deep_agent(
backend=(lambda rt: StateBackend(rt)) # 注意:这些工具通过 runtime.state 访问 State
)
工作方式
- 将文件存储在 LangGraph agent 的 state 中,作用范围为当前线程。
- 通过 checkpoint,在同一线程的多个 agent 轮次之间保持持久化。
适用场景
- 作为 agent 的 临时工作区(scratch pad),用于写入中间结果。
- 自动清理大型工具输出:agent 可以按需分块重新读取这些输出。
需要注意:
- 该 backend 在 supervisor agent 和 subagent 之间共享。
- 如果某个 subagent 写入文件,即使该 subagent 执行结束,这些文件仍然会 保留在 LangGraph agent state 中。
- 这些文件之后仍然可以被 supervisor agent 或其他 subagent 访问。
FilesystemBackend(本地磁盘)
该 backend 允许 agent 直接读写真实文件系统。
需要谨慎使用,只适用于合适的环境。
适用场景
-
本地开发 CLI
- 例如:代码助手、开发工具
-
CI/CD pipeline
- (下文包含安全注意事项)
不适用场景
-
Web 服务器或 HTTP API
-
建议使用:
- StateBackend
- StoreBackend
- sandbox backend
-
安全风险
-
Agent 可以读取 任何可访问文件,包括敏感信息:
- API keys
- credentials
.env文件
-
如果结合网络工具,可能通过 SSRF 攻击外泄这些敏感信息。
-
文件修改是 永久性的且不可恢复。
推荐防护措施
-
启用 Human-in-the-Loop (HITL) middleware,对敏感操作进行人工审核。
-
将敏感信息排除在 agent 可访问的文件路径之外(尤其是在 CI/CD 环境中)。
-
在生产环境中,如果需要文件系统交互,建议使用 sandbox backend。
-
始终结合
root_dir使用virtual_mode=True,以启用基于路径的访问限制:- 阻止
.. - 阻止
~ - 阻止访问
root_dir之外的绝对路径
- 阻止
注意:
- 默认
virtual_mode=False不会提供任何安全保护,即使设置了root_dir也是如此。
from deepagents.backends import FilesystemBackend
agent = create_deep_agent(
backend=FilesystemBackend(root_dir=".", virtual_mode=True)
)
工作方式
- 在可配置的
root_dir目录下读取和写入真实文件。 - 可以设置
virtual_mode=True,在root_dir下对路径进行 沙箱化和标准化。 - 使用安全的路径解析机制,在可能的情况下防止 不安全的符号链接(symlink)遍历。
- 可以使用 ripgrep 实现高速
grep搜索。
适用场景
- 本地机器上的项目
- CI 沙箱环境
- 挂载的持久化存储卷
举个例子,
agent = create_deep_agent(
model=ChatOpenAI(
base_url=BASE_URL,
api_key=API_KEY,
model=Qwen3_8b,
temperature=0.7
),
system_prompt=SYSTEM_PROMPT,
# skills参数将/skills注册到上下文,当需要调用skill的时候会产生read_file("/skills/xx/SKILL.md")
skills=["/skills/"],
# virtual_mode将当前目录作为/
backend=FilesystemBackend(root_dir=os.path.dirname(__file__),virtual_mode=True),
checkpointer=InMemorySaver()
)
LocalShellBackend(本地 Shell)
该 backend 允许 agent 直接读写文件系统,并在宿主机上执行任意 shell 命令。
必须 极其谨慎使用,仅适用于特定环境。
适用场景
-
本地开发 CLI
- 如:代码助手、开发工具
-
个人开发环境
- 当你信任 agent 生成的代码时
-
CI/CD 流水线
- 并且已做好 secret 管理
不适用场景
-
生产环境
- 如 Web 服务器
- API 服务
- 多租户系统
-
处理不可信用户输入
-
执行不可信代码
安全风险
-
Agent 可以 执行任意 shell 命令,权限等同于当前用户。
-
Agent 可以读取 任何可访问文件,包括敏感信息:
- API keys
- credentials
.env文件
-
敏感信息可能被泄露
-
文件修改和命令执行 都是永久且不可逆的
-
命令 直接在宿主机运行
-
命令可能 无限消耗资源:
- CPU
- 内存
- 磁盘
推荐安全措施
- 启用 Human-in-the-Loop (HITL) middleware,在执行前审核并批准操作(强烈推荐)。
- 仅在 专用开发环境中运行,不要在共享或生产系统上使用。
- 如果生产环境需要 shell 执行,建议使用 sandbox backend。
注意:
即使设置 virtual_mode=True,在启用 shell 访问时也不会提供任何安全性,因为 shell 命令可以访问系统中的 任意路径。
from deepagents.backends import LocalShellBackend
agent = create_deep_agent(
backend=LocalShellBackend(root_dir=".", env={"PATH": "/usr/bin:/bin"})
)
工作机制
- 在
FilesystemBackend的基础上扩展,增加了 execute 工具,用于在宿主机执行 shell 命令。 - 命令通过:
subprocess.run(shell=True)
直接在本机执行,没有任何沙箱隔离。
支持以下参数:
timeout(默认 120 秒)max_output_bytes(默认 100000)env(自定义环境变量)inherit_env(是否继承系统环境变量)
Shell 命令默认使用 root_dir 作为 工作目录,但仍然可以访问 系统任意路径。
StoreBackend(LangGraph Store)
from langgraph.store.memory import InMemoryStore
from deepagents.backends import StoreBackend
agent = create_deep_agent(
backend=(lambda rt: StoreBackend(rt)),
store=InMemoryStore()
)
工作机制
- 文件存储在 LangGraph 的
BaseStore中。 BaseStore由 runtime 提供,从而实现 跨线程(cross-thread)的持久化存储。
适用场景
- 你已经在使用 LangGraph store(例如基于 Redis、Postgres 或云端实现的
BaseStore)。
CompositeBackend(路由型 Backend)
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
composite_backend = lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
agent = create_deep_agent(
backend=composite_backend,
store=InMemoryStore() # store 是传给 create_deep_agent,而不是 backend
)
工作机制
- 根据 路径前缀(path prefix) 将文件操作路由到不同 backend。
- 在 文件列表和搜索结果中会保留原始路径前缀。
适用场景
1️⃣ 同时使用临时存储 + 长期存储
如果你希望 agent 同时拥有:
-
临时存储(ephemeral)
- 使用
StateBackend
- 使用
-
跨线程持久存储
- 使用
StoreBackend
- 使用
那么可以使用 CompositeBackend 同时提供这两种能力。
2️⃣ 为 agent 提供多个信息源
当你有 多个数据来源,希望统一暴露成一个文件系统 时非常有用。
例如:
-
/memories/- 长期记忆(存储在某个 Store)
-
/docs/- 文档数据(来自自定义 backend)
这样 agent 看起来像在访问一个 统一的虚拟文件系统,但实际数据来自不同 backend。
路径分发
按路径前缀匹配 backend
CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
含义其实是:
| 路径前缀 | 使用 backend |
|---|---|
/memories/* |
StoreBackend |
| 其他路径 | StateBackend |
所以:
| Agent 操作 | 实际 backend |
|---|---|
/memories/user.txt |
StoreBackend |
/workspace/a.txt |
StateBackend |
/tmp/b.txt |
StateBackend |
Agent 并不是直接操作 backend,它调用的是 filesystem tools:
ls
read_file
write_file
edit_file
grep
glob
这些工具内部会调用 backend。
假设 agent 执行:
write_file("/memories/profile.txt")
流程是:
Tool: write_file
↓
Filesystem middleware
↓
CompositeBackend.write()
↓
匹配 path prefix
↓
StoreBackend.write()
假设 agent 写三个文件:
写临时计划
write_file("/workspace/plan.md")
匹配:
/workspace/plan.md
↓
不匹配 /memories/
↓
default backend
↓
StateBackend
结果:
存在 LangGraph state
线程结束可能消失
写长期记忆
write_file("/memories/user_profile.md")
匹配:
/memories/user_profile.md
↓
匹配 /memories/
↓
StoreBackend
结果:
存入 LangGraph store
跨线程持久
那么为什么会形成这样的分发机制呢?
工具不会主动加
/memories/前缀。
前缀是由 LLM 决定的,而 LLM 是否会这么做,通常是由 prompt(系统提示)或文档规范引导的。
工具其实只是普通函数,deepagents 暴露给模型的工具类似这样:
write_file(path: str, content: str)
read_file(path: str)
ls(path: str)
grep(pattern: str, path: str)
注意:
工具并不知道 /memories/ 有任何特殊含义。
它只接受字符串:
path="/memories/profile.txt"
然后 backend 决定去哪写。
/memories/ 只是一个“约定路径”
在:
CompositeBackend(
default=StateBackend(rt),
routes={
"/memories/": StoreBackend(rt),
}
)
这里定义的是:
如果 path 以 /memories/ 开头
→ StoreBackend
所以:
/workspace/a.txt → StateBackend
/memories/a.txt → StoreBackend
但谁写 /memories/?
答案是:
LLM
LLM 为什么会写 /memories/
原因通常有三个。
情况1:Prompt 明确告诉模型
很多 agent framework 会在 system prompt 写:
例如:
You have a filesystem available.
Use the following directories:
/workspace/ - temporary files for the current task
/memories/ - persistent memory across conversations
/docs/ - documentation
If you want to store long-term memory, write files under /memories/.
这样模型就学会:
write_file("/memories/user_profile.txt")
情况2:工具文档说明
工具 schema 也可能写说明:
例如:
write_file(path, content)
Paths starting with:
/memories/ -> persistent storage
/workspace/ -> temporary storage
模型会读这些描述。
情况3:示例(few-shot)
Prompt 里可能有例子:
Example:
User: remember that my name is Bob
Assistant:
write_file("/memories/user_name.txt", "Bob")
模型就会模仿。
如果 prompt 不写会发生什么
如果 prompt 没告诉模型:
/memories/
模型通常会写:
write_file("notes.txt")
或者:
write_file("/workspace/notes.txt")
这时就会:
StateBackend
不会触发持久化。
很多 Agent 会定义一个“虚拟文件系统”。
例如:
/
├─ workspace/
├─ memories/
├─ docs/
├─ repo/
└─ outputs/
Prompt 会写:
Filesystem layout:
/workspace/ -> temporary files
/memories/ -> long-term memory
/docs/ -> documentation
/repo/ -> source code
模型就会根据任务选择路径。
你可能会想到,为什么不直接设计:
write_memory()
write_temp()
原因是:
文件系统抽象更通用。
统一工具:
read_file
write_file
ls
grep
glob
但 backend 决定存哪里。
这其实就是:
Agent Virtual Filesystem
很多 coding agent 都是这个设计。
这种设计是为了让 agent 可以同时访问:
代码
记忆
文档
任务文件
统一接口:
read
write
grep
glob
而不是几十个工具。
举一个真实例子,一个 coding agent 的 FS 可能是:
/
├─ workspace/ (当前任务)
├─ repo/ (代码仓库)
├─ memories/ (长期记忆)
├─ docs/ (文档RAG)
└─ logs/ (日志)
背后 backend:
workspace → StateBackend
repo → GitBackend
memories → StoreBackend
docs → VectorBackend
logs → FilesystemBackend
LLM 只看到:
read_file("/repo/main.py")
长期记忆(Long-term memory)
Deep agents 自带一个 本地文件系统,用于存放 agent 的数据。
默认情况下,这个文件系统存储在 agent 的 state 中(因为默认是StateBackend),并且只在 单个线程内有效(也就是说,当对话结束时,这些文件就会丢失)。
如果希望让 agent 具备 长期记忆能力,可以使用 CompositeBackend,将特定路径路由到 持久化存储。
这样就可以实现一种 混合存储(hybrid storage):
- 一部分文件 跨线程持久存在
- 另一部分文件 仍然是临时的
架构示意:
含义:
| 路径 | 存储类型 |
|---|---|
/memories/* |
持久存储 |
| 其他路径 | 临时存储 |
可以通过 CompositeBackend,把 /memories/ 路径路由到 StoreBackend:
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from langgraph.store.memory import InMemoryStore
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
def make_backend(runtime):
return CompositeBackend(
default=StateBackend(runtime), # 临时存储
routes={
"/memories/": StoreBackend(runtime) # 持久存储
}
)
agent = create_deep_agent(
store=InMemoryStore(),
backend=make_backend,
checkpointer=checkpointer
)
当 agent 执行文件操作时:
写入
/memories/profile.txt
→ 会进入 StoreBackend
→ 跨线程持久化
而写入:
/workspace/plan.txt
→ 会进入 StateBackend
→ 只在当前会话存在
工作原理(How it works)
当使用 CompositeBackend 时,deep agents 会维护 两个独立的文件系统:
1️⃣ 短期(临时)文件系统
- 存储在 agent 的 state 中(通过
StateBackend)。 - 只在 单个线程内持久存在。
- 当线程结束时,文件会 被删除。
访问路径示例:
/notes.txt
/workspace/draft.md
2️⃣ 长期(持久)文件系统
- 存储在 LangGraph Store 中(通过
StoreBackend)。 - 可以 跨所有线程和对话持久存在。
- 即使 agent 重启后仍然存在。
访问路径示例:
/memories/preferences.txt
CompositeBackend 会根据 路径前缀 将文件操作路由到不同的 backend:
-
路径以
/memories/开头- 存储到 Store(持久存储)
-
没有该前缀
- 存储到 临时 state
所有文件系统工具都可以同时访问这两类存储:
lsread_filewrite_fileedit_file
路由前缀处理:
CompositeBackend 在存储时会 去掉路由前缀。
例如:
/memories/preferences.txt
在 StoreBackend 中实际存储为:
/preferences.txt
但 agent 始终使用完整路径。
示例:
临时文件(线程结束后会丢失)
agent.invoke({
"messages": [
{"role": "user", "content": "Write draft to /draft.txt"}
]
})
持久文件(跨线程存在)
agent.invoke({
"messages": [
{"role": "user", "content": "Save final report to /memories/report.txt"}
]
})
使用场景(Use cases)
用户偏好(User preferences)
可以将用户的偏好保存下来,使其 跨会话持久存在:
agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""当用户告诉你他们的偏好时,请将其保存到
/memories/user_preferences.txt,这样你在未来的对话中也能记住这些信息。"""
)
这样 agent 就可以在未来的对话中 记住用户习惯。
自我改进的指令(Self-improving instructions)
Agent 可以根据用户反馈 动态更新自己的指令:
agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""你有一个文件 /memories/instructions.txt,其中包含额外的
指令和用户偏好。
在每次对话开始时读取这个文件,以了解用户的偏好。
当用户提供类似 “请始终执行 X” 或 “我更喜欢 Y” 的反馈时,
使用 edit_file 工具更新 /memories/instructions.txt。"""
)
随着时间推移,这个 instructions 文件会不断积累用户偏好,从而让 agent 逐渐优化自身行为。
知识库(Knowledge base)
Agent 可以在多次对话之间 逐渐构建知识库。
第一次对话:学习信息
agent.invoke({
"messages": [
{"role": "user", "content": "我们正在用 React 构建一个 Web 应用,请保存项目笔记。"}
]
})
第二次对话:利用之前的知识
agent.invoke({
"messages": [
{"role": "user", "content": "我们使用的是什么框架?"}
]
})
此时 agent 会读取:
/memories/project_notes.txt
这是 之前对话中保存的内容。
研究项目(Research projects)
可以在多次会话之间 持续维护研究进度:
research_agent = create_deep_agent(
store=InMemoryStore(),
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={"/memories/": StoreBackend(rt)}
),
system_prompt="""你是一名研究助手。
将研究进度保存到 /memories/research/:
- /memories/research/sources.txt 发现的资料来源
- /memories/research/notes.txt 关键发现和笔记
- /memories/research/report.md 最终报告草稿
这样研究工作可以在多个会话之间持续推进。"""
)
💡 核心思想
通过 /memories/ 路径实现 长期存储,agent 可以逐渐积累:
- 用户偏好
- 自我改进规则
- 项目知识
- 研究笔记
从而让 agent 具备 跨会话学习和持续工作的能力。
FileData 数据结构(FileData schema)
通过 StoreBackend 存储的文件使用如下数据结构:
{
"content": ["line 1", "line 2", "line 3"], // 字符串列表(每个元素表示一行)
"created_at": "2024-01-15T10:30:00Z", // ISO 8601 时间戳
"modified_at": "2024-01-15T11:45:00Z" // ISO 8601 时间戳
}
字段说明:
| 字段 | 含义 |
|---|---|
content |
文件内容,按行存储的字符串列表 |
created_at |
文件创建时间(ISO 8601 格式) |
modified_at |
文件最后修改时间(ISO 8601 格式) |
可以使用 create_file_data 工具函数来生成 格式正确的文件数据:
from deepagents.backends.utils import create_file_data
file_data = create_file_data("Hello\nWorld")
生成结果类似:
{
'content': ['Hello', 'World'],
'created_at': '...',
'modified_at': '...'
}
该函数会:
- 自动按 换行符拆分内容
- 自动生成 创建时间
- 自动生成 修改时间
最佳实践(Best practices)
使用描述性路径
为持久化文件使用 清晰、具有语义的路径结构:
/memories/user_preferences.txt
/memories/research/topic_a/sources.txt
/memories/research/topic_a/notes.txt
/memories/project/requirements.md
这样可以让 agent 更容易 理解和组织长期存储的数据。
记录内存结构
在 system prompt 中明确告诉 agent 不同路径存储的内容。例如:
Your persistent memory structure:
- /memories/preferences.txt: 用户偏好和设置
- /memories/context/: 用户的长期上下文信息
- /memories/knowledge/: 随时间学习到的事实和知识
这样 agent 在使用文件系统时会 更清楚每个目录的用途。
清理旧数据
定期清理 过时的持久化文件,以保持存储空间可控。
可以实现:
- 定期清理脚本
- 生命周期管理
- 版本归档策略
选择合适的存储
根据环境选择不同的存储方案:
| 场景 | 推荐存储 |
|---|---|
| 开发环境 | InMemoryStore(方便快速迭代) |
| 生产环境 | PostgresStore 或其他持久化存储 |
| 多租户系统 | 在 store 中使用 assistant_id 作为命名空间 |
使用 assistant_id 命名空间可以确保 不同 agent 或用户的数据相互隔离。
configurable字段
configurable本身没有任何固定字段。thread_id、assistant_id等都不是框架强制规定的字段,而是上层组件约定使用的字段名。
官方这段文档其实已经把关键说出来了:
configurable: dict[str, Any]
Runtime values for attributes previously made configurable on this Runnable
through configurable_fields or configurable_alternatives.
核心意思是:
configurable = 给 Runnable 注入运行时参数
而哪些参数可以注入,取决于:
这个 Runnable 声明了哪些 configurable_fields
LCEL / LangGraph 里一个 Runnable 可以声明:
.configurable_fields(...)
例如:
model = ChatOpenAI().configurable_fields(
model_name="model"
)
这样就声明了:
model_name 是 configurable
然后你才能这样传:
config = {
"configurable": {
"model_name": "gpt-4"
}
}
所以:
configurable字段 = Runnable声明的字段
而不是框架固定的。
那 thread_id 是怎么来的?
thread_id 不是 Runnable configurable 字段。
它是:
checkpointer 约定的 config key
例如:
MemorySaver
SqliteCheckpointer
PostgresCheckpointer
这些组件在内部会读取:
config["configurable"]["thread_id"]
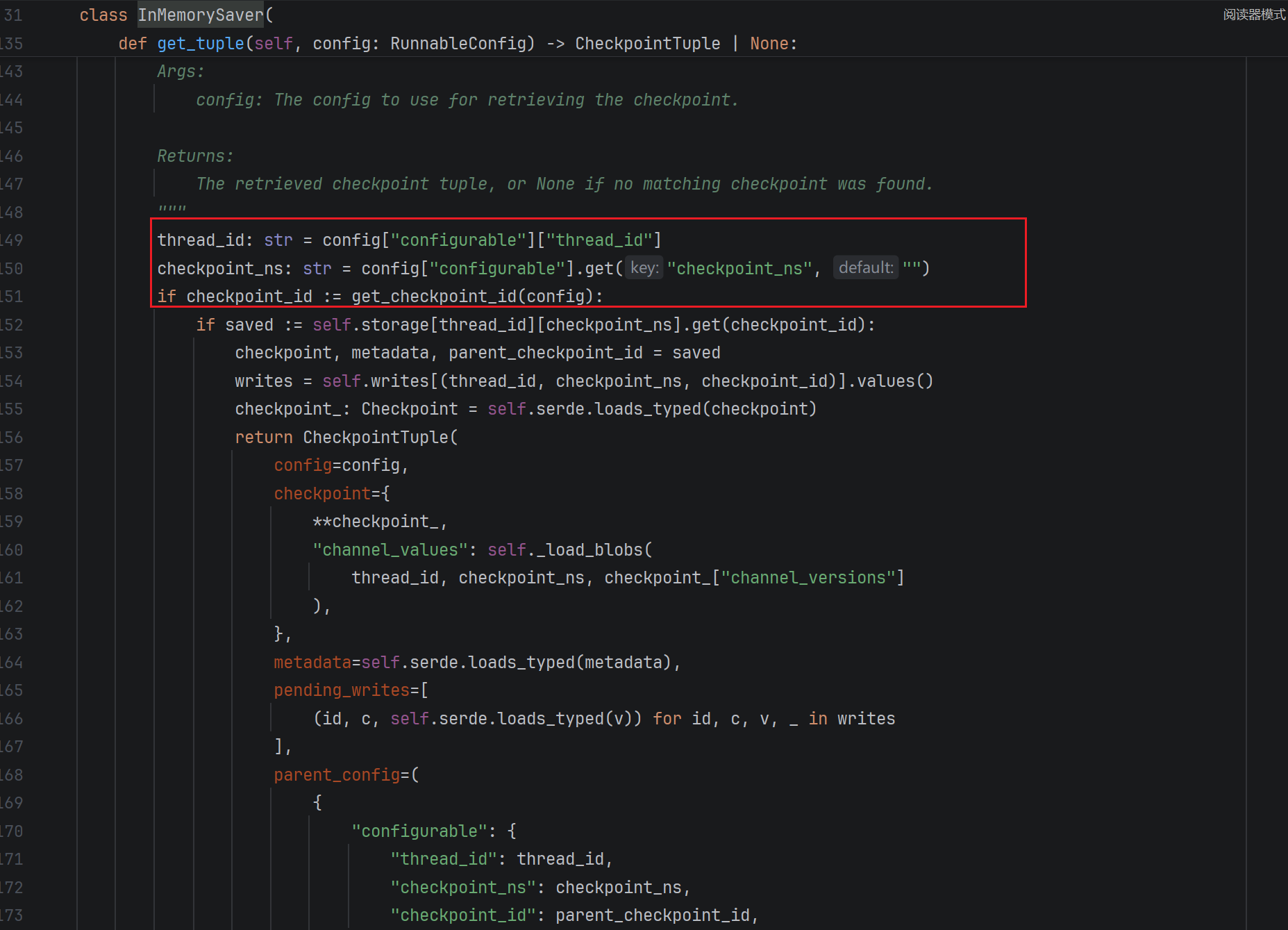
用来决定:
checkpoint namespace
所以:
thread_id 是 checkpointer 约定
不是 framework schema
assistant_id 也是同样的
例如:
StoreBackend
LangSmith deployment
multi-assistant runtime
这些组件约定读取:
configurable["assistant_id"]
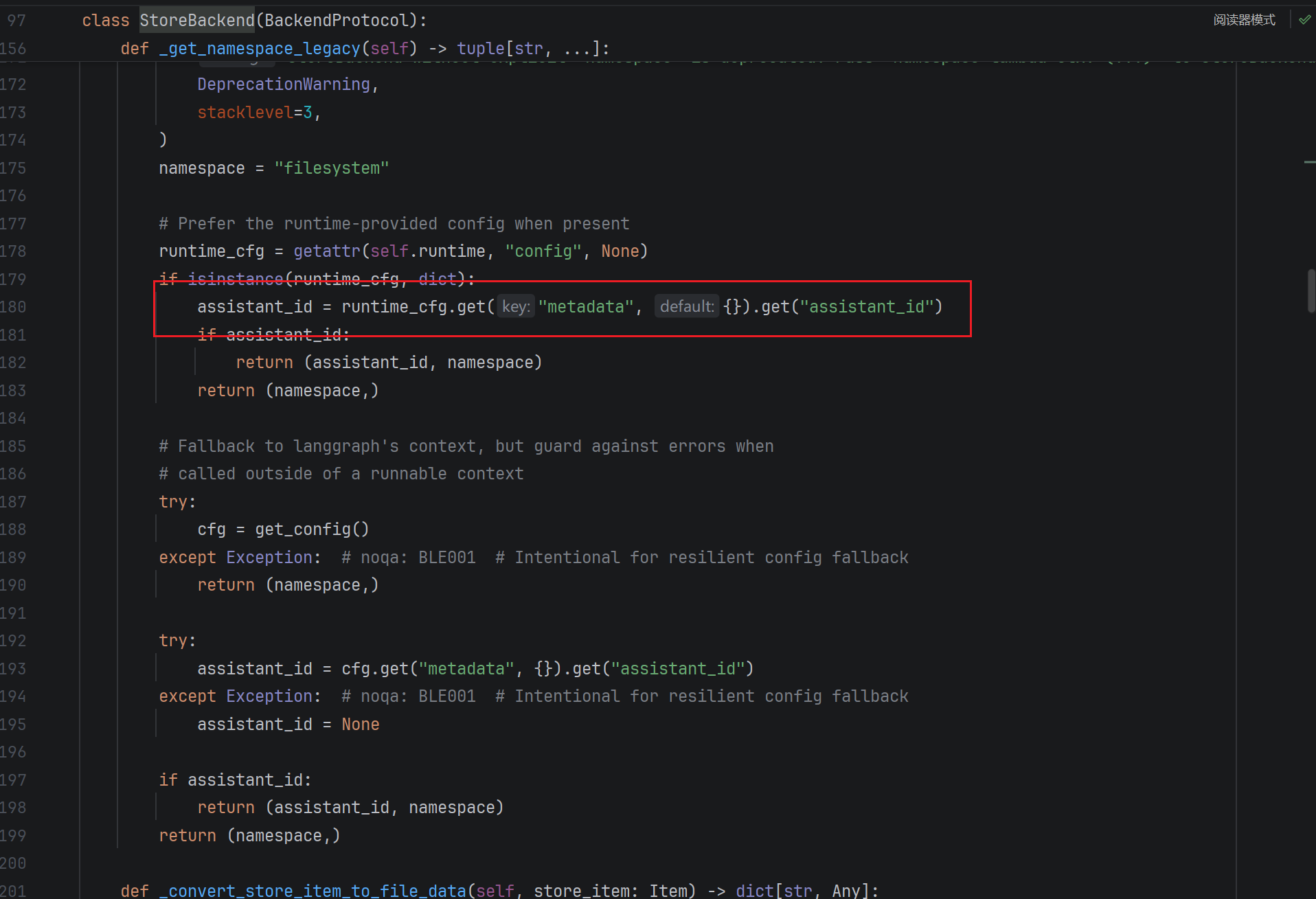
用于:
store namespace
但 LangGraph 本身 没有强制要求这个字段存在。
从架构上说:
configurable = runtime dependency injection
它允许 runtime 注入:
| 类型 | 示例 |
|---|---|
| checkpoint key | thread_id |
| store namespace | assistant_id |
| model selection | model |
| prompt override | system_prompt |
| tenant info | tenant_id |
但:
LangGraph 不规定字段组件自己约定
为什么官方不列字段
因为 LangGraph 是 Graph runtime,而不是 agent framework。
它不知道:
你要做 chat
workflow
agent
RAG
SaaS
multi-tenant
所以不能规定:
thread_id
assistant_id
user_id
这些都是 上层框架语义。
例如:
| 框架 | 使用字段 |
|---|---|
| LangGraph checkpointer | thread_id |
| deepagents | assistant_id |
| LangSmith | run_id |
| SaaS agent | tenant_id |
LangChain / LangGraph 的设计是:
configurable = 可配置运行时参数
但:
schema 由 Runnable 决定
所以文档才说:
Check output_schema for a description of configurable attributes
意思是:
去看 runnable 自己声明了哪些 configurable 字段。
Code execution(代码执行)
当你使用 sandbox(沙箱)后端 时,运行环境(harness)会暴露一个 execute 工具,允许 Agent 在一个 隔离环境 中运行 shell 命令。
这使得 Agent 可以在执行任务时 安装依赖、运行脚本以及执行代码。
工作原理:
-
沙箱后端实现了
SandboxBackendProtocol。 -
当系统检测到使用了这种后端时,运行环境会 自动为 Agent 添加
execute工具,并将其加入可用工具列表。 -
如果 没有使用沙箱后端,Agent 只会拥有 文件系统相关工具(例如
read_file、write_file等),无法执行命令。 -
execute工具会返回:- 合并后的 stdout / stderr
- 退出码(exit code)
- 对于过大的输出会进行截断,并保存到文件中,Agent 可以再通过文件读取工具 逐步读取这些内容。
为什么有用:
安全性
代码在隔离环境中运行,可以保护宿主系统不被 Agent 的操作影响。
干净的环境
可以使用特定的依赖或操作系统配置,而无需在本地手动安装或配置。
可复现性
团队成员之间可以共享一致的执行环境,保证运行结果的一致性。
Shell 工具(Shell tool)
将一个持久化的 Shell 会话暴露给 Agent,用于执行命令。Shell 工具中间件适用于以下场景:
- 需要执行系统命令的 Agent
- 开发和部署自动化任务
- 测试与验证流程
- 文件系统操作和脚本执行
安全注意事项:
请根据你的部署安全需求选择合适的执行策略(execution policy):
HostExecutionPolicyDockerExecutionPolicyCodexSandboxExecutionPolicy
限制:
当前持久化 Shell 会话不支持**中断(human-in-the-loop)**机制。未来版本预计会增加该能力。
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HostExecutionPolicy,
)
agent = create_agent(
model="gpt-4.1",
tools=[search_tool],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
execution_policy=HostExecutionPolicy(),
),
],
)
配置选项(Configuration options)
workspace_root
str | Path | None
Shell 会话的基础目录。
如果省略,当 Agent 启动时会创建一个临时目录,并在 Agent 结束时删除。
startup_commands
tuple[str, ...] | list[str] | str | None
可选参数。
在 Shell 会话启动后按顺序执行的命令。
shutdown_commands
tuple[str, ...] | list[str] | str | None
可选参数。
在 Shell 会话关闭前执行的命令。
execution_policy
BaseExecutionPolicy | None
执行策略,用于控制:
- 超时时间
- 输出限制
- 资源配置
可选策略:
HostExecutionPolicy
- 完整的宿主机访问权限(默认)
- 适用于 Agent 已经运行在容器或虚拟机中的可信环境
DockerExecutionPolicy
- 每次 Agent 运行时都会启动一个独立的 Docker 容器
- 提供更强的隔离性
CodexSandboxExecutionPolicy
- 复用 Codex CLI sandbox
- 提供额外的 系统调用 / 文件系统限制
redaction_rules
tuple[RedactionRule, ...] | list[RedactionRule] | None
可选的输出脱敏规则。
在命令执行完成后,对返回给模型的输出进行敏感信息清理。
⚠️ 注意:
在使用 HostExecutionPolicy 时,脱敏规则不会阻止敏感信息泄露,只是在执行完成后对输出进行处理。
tool_description
str | None
可选参数。
用于覆盖默认注册的 Shell 工具描述。
shell_command
Sequence[str] | str | None
可选参数。
用于指定启动持久化 Shell 会话的Shell 可执行程序。
默认值:
/bin/bash
env
Mapping[str, Any] | None
可选参数。
提供给 Shell 会话的环境变量。
所有值在执行命令前都会被转换为 字符串。
完整示例(Full example)
该中间件会提供一个单一持久化 Shell 会话,Agent 可以在其中按顺序执行命令。
执行策略
-
HostExecutionPolicy(默认)
原生执行,拥有完整宿主机访问权限 -
DockerExecutionPolicy
在隔离的 Docker 容器中执行 -
CodexSandboxExecutionPolicy
通过 Codex CLI 提供沙箱执行
基础示例:宿主机执行
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HostExecutionPolicy,
DockerExecutionPolicy,
RedactionRule,
)
agent = create_agent(
model="gpt-4.1",
tools=[search_tool],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
execution_policy=HostExecutionPolicy(),
),
],
)
使用 Docker 隔离,并带启动命令
agent_docker = create_agent(
model="gpt-4.1",
tools=[],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
startup_commands=["pip install requests", "export PYTHONPATH=/workspace"],
execution_policy=DockerExecutionPolicy(
image="python:3.11-slim",
command_timeout=60.0,
),
),
],
)
带输出脱敏规则
agent_redacted = create_agent(
model="gpt-4.1",
tools=[],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
redaction_rules=[
RedactionRule(pii_type="api_key", detector=r"sk-[a-zA-Z0-9]{32}"),
],
),
],
)
和沙箱的区别
简单说:两者解决的是不同层级的问题。
- Sandbox(沙箱):解决 运行环境隔离(security boundary)
- ShellToolMiddleware:解决 给 Agent 提供 shell 能力(tool capability)
可以理解为:
Sandbox = 安全的运行环境
ShellToolMiddleware = 一个工具
Sandbox 是 Agent 运行的环境 backend。
它的核心作用是:
隔离 Agent 和宿主机
防止 Agent:
- 读取你的本地文件
- 访问凭据(API key)
- 破坏系统
- 执行危险命令
Sandbox 本质是:
Agent
↓
Sandbox backend
↓
Isolated environment
↓
Host system
配置 sandbox 后:
Agent 获得:
-
文件系统工具
lsread_filewrite_fileedit_fileglobgrep -
execute 工具
(执行 shell 命令) -
隔离环境
例如:
Docker sandbox
VM sandbox
Remote sandbox
Agent 执行:
rm -rf /
只会影响 sandbox 容器,不会影响你的电脑。
ShellToolMiddleware:工具级别(Tool Layer)
ShellToolMiddleware 只是:
给 Agent 加一个 shell tool
它做的事情只有:
Agent
↓
Shell tool
↓
Shell session
例如 Agent 可以执行:
ls
pip install
python script.py
但关键问题是:
Shell 在哪里执行?
默认:
HostExecutionPolicy
也就是:
Agent → Shell → 你的宿主机
这其实是:
没有隔离的
两者最关键区别
| 对比 | Sandbox | ShellToolMiddleware |
|---|---|---|
| 层级 | 环境 | 工具 |
| 作用 | 隔离 Agent | 提供 shell 命令 |
| 是否安全 | 高 | 取决于 execution_policy |
| 是否改变运行环境 | 是 | 否 |
| 是否提供 shell | 提供 execute | 提供 shell tool |
Sandbox 其实 已经包含 shell 执行能力:
sandbox backend
↓
execute tool
所以:
有 sandbox 时
Agent 仍然可以执行:
pip install
git clone
python script.py
但这些都在 sandbox 内部。
为什么还要 ShellToolMiddleware?
因为 LangChain 有两个不同设计:
Deep Agents 设计
backend
└ sandbox
└ execute tool
shell 是 backend提供
LangChain middleware 设计
Agent
└ middleware
└ shell tool
shell 是 tool
最安全的组合(推荐)
如果做 Autonomous Agent / Coding Agent:
推荐架构:
Agent
↓
ShellToolMiddleware
↓
DockerExecutionPolicy
↓
Docker container
或者:
Agent
↓
Sandbox backend
↓
Isolated environment
避免:
HostExecutionPolicy
否则 Agent 理论上可以:
rm -rf /
curl your_keys
可以这样理解:
Sandbox = 房子
ShellToolMiddleware = 工具箱
- Sandbox:决定 你在哪里工作
- ShellTool:决定 你有什么工具
Deepagent上下文管理
Deep Agents 通过有效的上下文管理来处理长时间运行的任务。
Agent 可以访问多种类型的上下文:
- 一些上下文在 Agent 启动时提供
- 另一些在 运行过程中动态产生(例如用户输入)
输入上下文(Input context)
输入上下文指的是在 Agent 启动时提供给 Deep Agent 的信息源,这些信息会被加入到 prompt 中。
Deep Agents 使用 system prompt(系统提示词) 来定义:
- Agent 的角色
- 行为方式
- 能力
- 知识范围
如果你提供了 自定义 system prompt,它会被添加在内置 system prompt 之前。
内置 system prompt 包含了对以下内置工具的详细使用指导:
- planning tool(规划工具)
- filesystem tools(文件系统工具)
- subagents(子 Agent)
如果 middleware 增加了新的工具(例如 filesystem middleware),
它会自动把工具使用说明附加到 system prompt 中。
这些说明会形成 tool prompts,用于指导 Agent 如何正确使用这些工具。
Deep Agent 最终构造的 Prompt 包含以下部分:
-
自定义 system_prompt(如果提供)
-
基础 agent prompt
-
To-do list prompt
关于如何使用 待办列表进行任务规划的说明 -
Memory prompt
AGENTS.md- memory 使用指南
(仅在提供 memory 时启用)
-
Skills prompt
包含:- skills 的存放位置
- skills 列表
- frontmatter 信息
- 使用说明
(仅在提供 skills 时启用)
-
Virtual filesystem prompt
包含:- filesystem 工具说明
- execute 工具说明(如果存在)
-
Subagent prompt
关于如何使用 task tool 调用子 Agent -
用户提供的 middleware prompts
(当使用自定义 middleware 时) -
Human-in-the-loop prompt
当启用interrupt_on时使用 -
Local context prompt
包含例如:- 当前目录
- 项目信息
(在本地 CLI 运行 Agent 时提供)
运行时上下文(Runtime context)
Deep Agents 使用一种称为 上下文压缩(context compression) 的模式。
其原理是:减少 Agent 工作记忆中的信息大小,同时保留与当前任务相关的重要细节。
为了确保传递给 LLM 的上下文不会超出模型的 context window 限制,Deep Agents 内置了以下机制:
- Offloading(卸载)大型工具输入与结果
- Summarization(摘要)
此外,你还可以配置 long-term memory(长期记忆),让 Agent 在不同线程和对话之间保存信息。
Offloading(卸载)大型工具输入和结果
Deep Agents 使用内置的 filesystem tools 自动将大内容写入文件系统,并在需要时进行搜索和读取。
内容卸载会在以下两种情况下发生:
1.Tool 调用输入超过 20,000 tokens
(可通过 tool_token_limit_before_evict 配置)
当 Agent 进行 文件写入或编辑操作时,tool call 通常会在对话历史中留下完整文件内容。
但这些内容已经保存到文件系统中,因此在上下文中再次保存是冗余的。
当会话上下文达到 模型上下文窗口的 85% 时:
Deep Agents 会:
- 截断旧的 tool call
- 用一个 指向磁盘文件的指针 替换
- 从而减少当前上下文大小
示例:
大输入内容被保存到磁盘,而 tool call 中只保留简化版本。
2.Tool 调用结果超过 20,000 tokens
(同样由 tool_token_limit_before_evict 控制)
当工具返回的结果过大时:
Deep Agent 会:
-
将完整结果 写入 backend
-
在上下文中只保留:
- 文件路径引用
- 结果前 10 行预览
Agent 在需要时可以:
- 重新读取
- 搜索该文件内容
示例:
大型工具结果被替换为:
- 文件位置
- 前 10 行内容
Summarization(摘要)
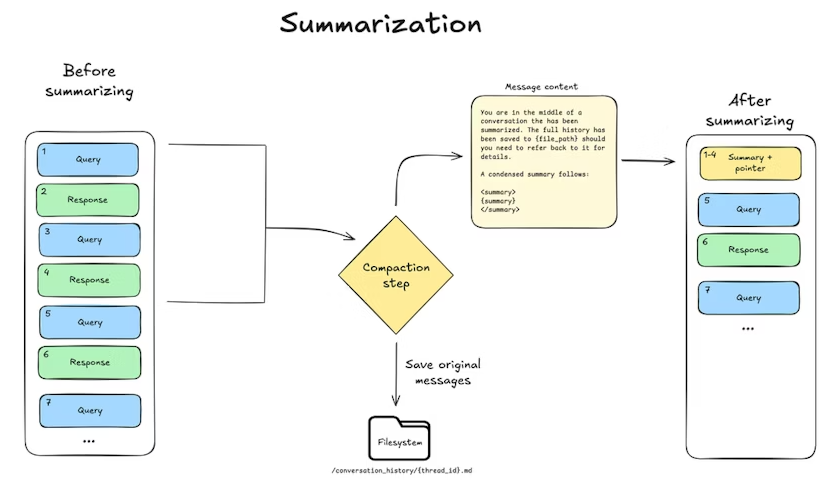
当上下文大小超过模型的 context window 限制
(例如达到 85% 的 max_input_tokens),并且没有更多内容可以卸载时:
Deep Agent 会对 消息历史进行摘要。
这个过程包括两个部分:
1.上下文摘要(In-context summary)
LLM 会生成一个 结构化摘要,包括:
- 当前会话目标
- 已创建的产物(artifacts)
- 下一步任务
这个摘要会替代完整的对话历史,成为 Agent 的工作记忆。
2.文件系统保存(Filesystem preservation)
完整的原始对话记录会:
- 写入文件系统
- 作为完整的历史记录保存
这种方式可以:
- 让 Agent 保持对目标和进度的理解(通过摘要)
- 同时保留 恢复细节的能力(通过文件系统搜索)
示例:
Agent 的历史对话被压缩为摘要,只保留关键步骤。
Summarization 配置:
默认配置:
-
在 模型 max_input_tokens 的 85% 时触发
-
保留 10% tokens 作为最近上下文
-
如果模型 profile 不可用:
- 使用 170,000 tokens 作为触发阈值
- 保留 6 条消息
如果模型调用触发:
ContextOverflowError
Deep Agents 会:
- 立即进行摘要
- 保留最近消息
- 使用新的上下文重新调用模型
旧消息会被模型总结。
Summarization Tool(摘要工具)
Deep Agents 还提供一个可选工具,允许 Agent 在合适的时间主动触发摘要。
例如:
- 完成一个任务之后
- 开始新任务之前
而不是只在 token 达到阈值时触发。
启用方法:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import (
create_summarization_tool_middleware,
)
backend = StateBackend # 默认 backend
model = "openai:gpt-5.4"
agent = create_deep_agent(
model=model,
middleware=[
create_summarization_tool_middleware(model, backend),
],
)
启用该功能后:
- 不会关闭默认的 85% 自动摘要机制
Deep Agents 的 上下文管理体系是三层压缩结构:
LLM Context
↓
Summary
↓
Filesystem artifacts
这种设计实际上就是 Coding Agent 能跑长任务的核心机制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)