直接偏好优化DPO训练全流程分析
目录
在大语言模型的人类偏好对齐阶段,核心目标是让模型生成的内容符合人类的价值判断、使用习惯与需求偏好。而传统的RLHF需历经“监督微调(SFT)→奖励模型(RM)训练→强化学习迭代”三步,流程繁琐且存在训练不稳定、样本利用率低、奖励偏移等问题。而DPO的核心创新在于直接以偏好数据为监督信号,通过对比优质回答与劣质回答的分布差异,优化策略模型的参数,无需额外训练奖励模型,也无需复杂的强化学习交互迭代,大幅降低了对齐训练的复杂度与成本。DPO训练的核心是最小化策略模型与“最优参考分布”的偏离:以SFT模型为基础构建参考模型,将策略模型的输出分布向“偏好数据中优质回答的分布靠拢,同时抑制劣质回答的分布,最终让策略模型的输出更贴合用户偏好。
1.DPO训练流程
DPO的训练流程如下图所示:
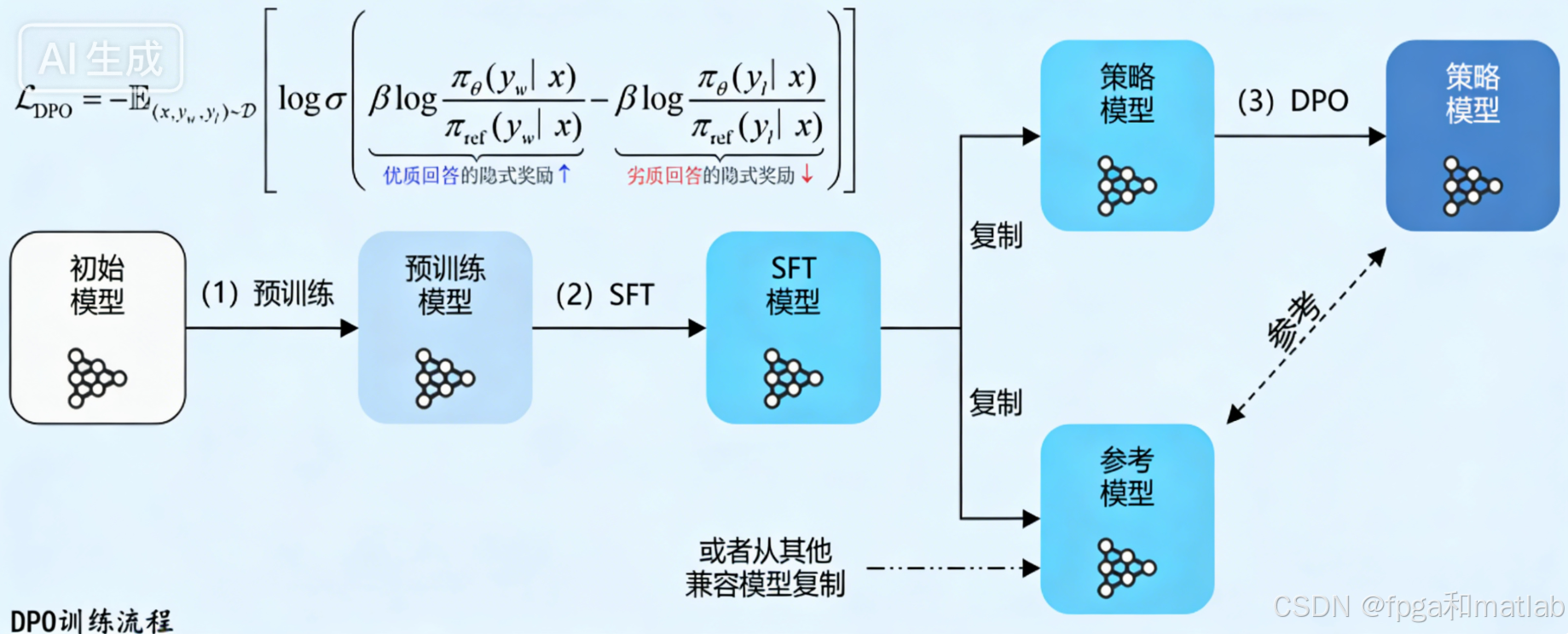
1.1 初始化
DPO训练涉及策略模型与参考模型两个核心模型,二者的初始化是训练的基础,直接影响训练的收敛速度与最终效果。DPO的模型初始化无需从零开始,而是基于已有模型进行迁移,这也是大语言模型微调的核心思路(迁移学习)。
策略模型πθ的初始化
策略模型是DPO训练中需要被优化的核心模型,其最终目标是生成符合用户偏好的内容。初始化方式为:
基础方案:直接复制监督微调(SFT)模型的参数。SFT模型是先在通用指令数据上微调后的模型,已具备基础的对话、推理能力,以此为基础初始化策略模型,可让模型快速收敛,避免从零训练的高成本;
进阶方案:若有性能更优的兼容模型(如经过多轮SFT的模型、行业定制模型),可直接复用该模型作为策略模型的初始参数。核心要求是:初始策略模型需具备基础的语言生成能力,且与参考模型的分布差异不宜过大(否则会增加训练难度)。
参考模型πref的初始化
参考模型是DPO训练中的“锚点”,其核心作用是提供一个固定的参考分布,用于衡量策略模型的优化方向。DPO训练的本质是让策略模型的输出分布向参考模型的优质分布靠拢,同时与参考模型的劣质分布拉开差距,因此参考模型的初始化需满足“稳定性、兼容性”要求:
基础方案:与策略模型一致,复制SFT模型的参数。此时策略模型与参考模型初始参数相同,训练初期二者的分布差异极小,便于模型逐步学习偏好;
进阶方案:选择一个比SFT模型更强的模型作为参考模型(如经过更充分SFT的模型、在特定领域优化过的模型)。但此时需重点关注两个模型的KL 散度(Kullback-Leibler Divergence)与训练数据分布的匹配性:
KL散度:衡量两个概率分布的差异,若策略模型与参考模型的KL散度过大,会导致训练初期损失函数波动过大,难以收敛;因此需通过微调策略模型参数,缩小二者的KL散度,保证训练稳定性;
数据分布匹配:参考模型的训练数据分布需与DPO的偏好数据分布尽量一致(如参考模型是对话领域模型,DPO数据也以对话为主),否则参考模型的“参考价值”会降低,导致策略模型学习到错误的偏好规律。
2.DPO训练迭代(推理→计算→反向传播)
DPO的核心训练过程是“单次推理→计算损失→反向传播”的迭代循环,针对每一批次的偏好数据,模型需完成 “策略模型推理、参考模型推理、损失计算、参数更新” 四个步骤,这一过程是DPO训练的核心技术环节,也是其与传统监督微调的核心区别。其流程图如下所示:
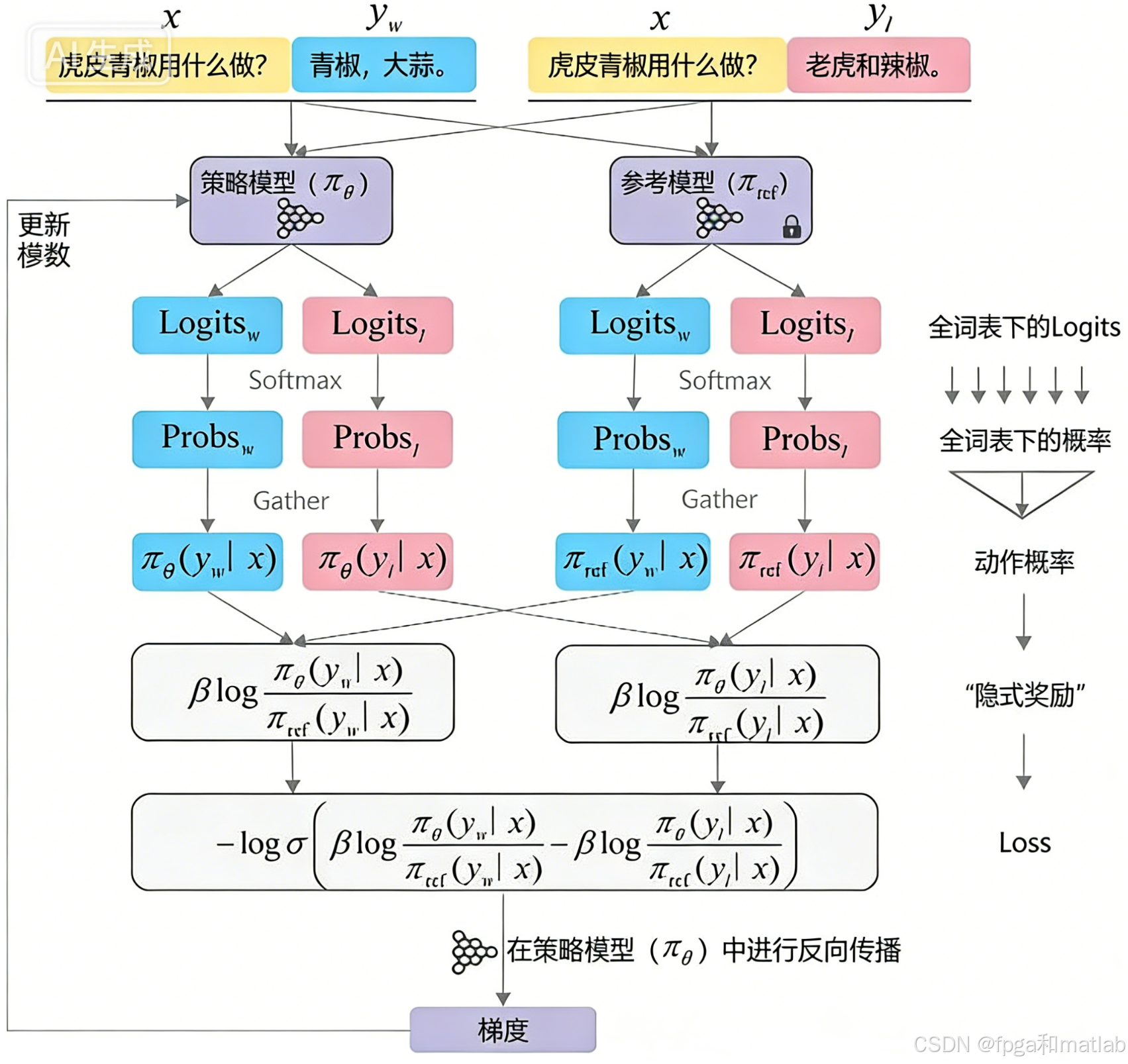
2.1 模型推理
针对预处理后的批次数据,需同时输入策略模型(πθ)与参考模型(πref),分别对 “优质回答序列” 与“劣质回答序列”进行推理,得到模型输出的Logits(未归一化的概率值),再通过Softmax与 LogSoftmax转换为动作概率(即模型生成每个Token的概率)。具体推理流程如下:

2.2 计算隐式奖励值
DPO没有显式的奖励模型,而是通过策略模型与参考模型的概率比值计算隐式奖励值,量化“优质回答优于劣质回答”的程度,这是DPO对比优化的核心逻辑。隐式奖励的计算公式为:
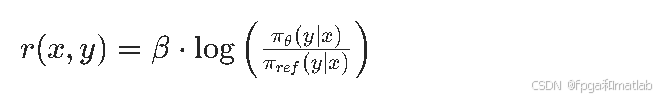
其中:

2.3 计算DPO损失函数
DPO的损失函数是对比损失,核心目标是最大化优质回答的隐式奖励,最小化劣质回答的隐式奖励,即让策略模型的输出分布向优质回答靠拢,同时远离劣质回答。DPO损失函数的公式为:
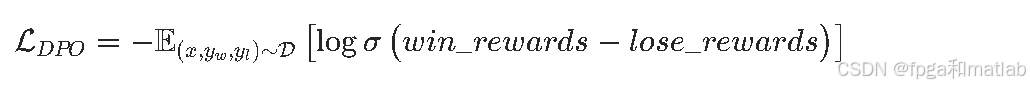
其中:

实际实现中,为提升计算效率,会对批次内的损失取均值,即:
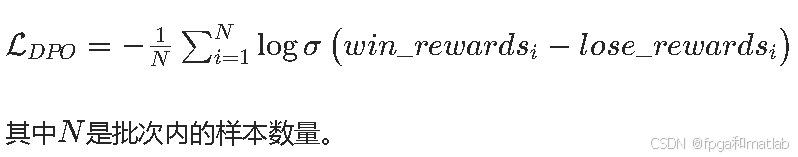
2.4 反向传播与参数更新
损失函数计算完成后,需通过反向传播计算策略模型参数的梯度,再通过优化器更新参数,完成一次训练迭代。这一步是模型学习偏好规律的核心环节,与传统监督微调的反向传播逻辑一致,但优化目标是DPO的对比损失而非交叉熵损失。
3. DPO训练程序
偏好数据集定义:
class DPOPreferenceDataset(Dataset):
"""
DPO偏好数据集:存储 (prompt, win_response, lose_response) 三元组
"""
def __init__(self, data: List[Dict[str, str]], tokenizer: PreTrainedTokenizer):
self.data = data
self.tokenizer = tokenizer
def __len__(self) -> int:
return len(self.data)
def __getitem__(self, idx: int) -> Dict[str, torch.Tensor]:
sample = self.data[idx]
prompt = sample["prompt"]
win_response = sample["win_response"]
lose_response = sample["lose_response"]
# Token化:prompt + 优质回答 / prompt + 劣质回答
prompt_tokens = self.tokenizer.encode(prompt, add_special_tokens=False)
win_tokens = self.tokenizer.encode(win_response, add_special_tokens=False)
lose_tokens = self.tokenizer.encode(lose_response, add_special_tokens=False)
# 拼接输入序列
input_win = prompt_tokens + win_tokens + [self.tokenizer.eos_token_id]
input_lose = prompt_tokens + lose_tokens + [self.tokenizer.eos_token_id]
# 截断到最大长度
input_win = input_win[:config.max_seq_len]
input_lose = input_lose[:config.max_seq_len]
# 生成attention mask(1表示有效token,0表示padding)
mask_win = [1] * len(input_win)
mask_lose = [1] * len(input_lose)
# 填充到最大长度
pad_len_win = config.max_seq_len - len(input_win)
pad_len_lose = config.max_seq_len - len(input_lose)
input_win += [self.tokenizer.pad_token_id] * pad_len_win
mask_win += [0] * pad_len_win
input_lose += [self.tokenizer.pad_token_id] * pad_len_lose
mask_lose += [0] * pad_len_lose
# 标签:仅回答部分参与损失计算(prompt部分mask掉)
label_win = [-100] * len(prompt_tokens) + win_tokens + [self.tokenizer.eos_token_id]
label_lose = [-100] * len(prompt_tokens) + lose_tokens + [self.tokenizer.eos_token_id]
label_win = label_win[:config.max_seq_len] + [-100] * pad_len_win
label_lose = label_lose[:config.max_seq_len] + [-100] * pad_len_lose
return {
"input_win": torch.tensor(input_win, dtype=torch.long),
"mask_win": torch.tensor(mask_win, dtype=torch.long),
"label_win": torch.tensor(label_win, dtype=torch.long),
"input_lose": torch.tensor(input_lose, dtype=torch.long),
"mask_lose": torch.tensor(mask_lose, dtype=torch.long),
"label_lose": torch.tensor(label_lose, dtype=torch.long),
"prompt_len": len(prompt_tokens) # 记录prompt长度,用于Gather操作
}动作概率(logprob)计算函数:
def get_logprob(
model: PreTrainedModel,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
labels: torch.Tensor,
prompt_len: int
) -> torch.Tensor:
"""
计算模型在给定输入下,标签序列的对数概率(logprob)
:param model: 策略模型或参考模型
:param input_ids: 输入token序列
:param attention_mask: attention掩码
:param labels: 标签序列(-100表示忽略的位置)
:param prompt_len: prompt部分长度,用于定位回答部分
:return: 每个样本的平均logprob(形状:[batch_size])
"""
model.eval() # 推理模式,不更新参数
with torch.no_grad():
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels,
return_dict=True
)
logits = outputs.logits # [batch_size, seq_len, vocab_size]
# 计算log_softmax:稳定获取对数概率
log_probs = torch.log_softmax(logits, dim=-1)
# 提取标签对应的logprob(Gather操作)
# 移位对齐:logits的第i个位置预测第i+1个token
shift_log_probs = log_probs[:, :-1, :].contiguous()
shift_labels = labels[:, 1:].contiguous()
# 只计算回答部分的logprob(prompt部分mask为-100)
loss_mask = (shift_labels != -100).float()
selected_log_probs = shift_log_probs.gather(
dim=-1,
index=shift_labels.unsqueeze(-1)
).squeeze(-1)
# 按样本平均logprob
per_sample_logprob = (selected_log_probs * loss_mask).sum(dim=-1) / loss_mask.sum(dim=-1).clamp(min=1e-8)
return per_sample_logprobDPO损失函数实现
class DPOLoss(nn.Module):
def __init__(self, beta: float = 0.1):
super().__init__()
self.beta = beta
def forward(
self,
policy_win_logprob: torch.Tensor,
policy_lose_logprob: torch.Tensor,
ref_win_logprob: torch.Tensor,
ref_lose_logprob: torch.Tensor
) -> torch.Tensor:
"""
计算DPO损失
:param policy_win_logprob: 策略模型在优质回答上的logprob
:param policy_lose_logprob: 策略模型在劣质回答上的logprob
:param ref_win_logprob: 参考模型在优质回答上的logprob
:param ref_lose_logprob: 参考模型在劣质回答上的logprob
:return: DPO损失值
"""
# 计算隐式奖励
win_rewards = self.beta * (policy_win_logprob - ref_win_logprob)
lose_rewards = self.beta * (policy_lose_logprob - ref_lose_logprob)
# 计算DPO损失:-log(sigmoid(win_rewards - lose_rewards))
loss = -torch.log(torch.sigmoid(win_rewards - lose_rewards)).mean()
return lossDPO训练器封装
class DPOTrainer:
def __init__(
self,
policy_model: PreTrainedModel,
ref_model: PreTrainedModel,
tokenizer: PreTrainedTokenizer,
config: DPOConfig,
train_dataset: DPOPreferenceDataset
):
self.policy_model = policy_model.to(config.device)
self.ref_model = ref_model.to(config.device)
self.ref_model.eval() # 参考模型固定,不参与训练
self.tokenizer = tokenizer
self.config = config
self.train_dataset = train_dataset
self.loss_fn = DPOLoss(beta=config.beta)
self.optimizer = optim.AdamW(self.policy_model.parameters(), lr=config.lr)
self.dataloader = DataLoader(
train_dataset,
batch_size=config.batch_size,
shuffle=True,
num_workers=4
)
def train_step(self, batch: Dict[str, torch.Tensor]) -> torch.Tensor:
"""
单步训练:处理一个批次数据,计算损失并更新参数
"""
# 移动数据到设备
input_win = batch["input_win"].to(self.config.device)
mask_win = batch["mask_win"].to(self.config.device)
label_win = batch["label_win"].to(self.config.device)
input_lose = batch["input_lose"].to(self.config.device)
mask_lose = batch["mask_lose"].to(self.config.device)
label_lose = batch["label_lose"].to(self.config.device)
prompt_len = batch["prompt_len"]
# 1. 计算策略模型的logprob
policy_win_logprob = get_logprob(
self.policy_model, input_win, mask_win, label_win, prompt_len
)
policy_lose_logprob = get_logprob(
self.policy_model, input_lose, mask_lose, label_lose, prompt_len
)
# 2. 计算参考模型的logprob(固定参数,无梯度)
ref_win_logprob = get_logprob(
self.ref_model, input_win, mask_win, label_win, prompt_len
)
ref_lose_logprob = get_logprob(
self.ref_model, input_lose, mask_lose, label_lose, prompt_len
)
# 3. 计算DPO损失
loss = self.loss_fn(
policy_win_logprob, policy_lose_logprob,
ref_win_logprob, ref_lose_logprob
)
# 4. 反向传播更新策略模型参数
self.optimizer.zero_grad()
loss.backward()
# 梯度裁剪,防止梯度爆炸
torch.nn.utils.clip_grad_norm_(self.policy_model.parameters(), max_norm=1.0)
self.optimizer.step()
return loss.item()
def train(self):
"""
完整训练循环
"""
self.policy_model.train()
for epoch in range(self.config.num_epochs):
total_loss = 0.0
for batch_idx, batch in enumerate(self.dataloader):
loss = self.train_step(batch)
total_loss += loss
if (batch_idx + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{self.config.num_epochs}], "
f"Batch [{batch_idx+1}/{len(self.dataloader)}], "
f"Loss: {loss:.4f}")
avg_loss = total_loss / len(self.dataloader)
print(f"Epoch [{epoch+1}/{self.config.num_epochs}], Average Loss: {avg_loss:.4f}")
# 保存训练后的策略模型
self.policy_model.save_pretrained("dpo_trained_model")
self.tokenizer.save_pretrained("dpo_trained_model")
print("训练完成,模型已保存至 dpo_trained_model 目录")主程序入口(调用示例)
def main():
# 1. 加载tokenizer和基础SFT模型
tokenizer = AutoTokenizer.from_pretrained(config.model_name_or_path)
tokenizer.pad_token = tokenizer.eos_token # 设定pad token
sft_model = AutoModelForCausalLM.from_pretrained(config.model_name_or_path)
# 2. 初始化策略模型和参考模型(均复制SFT模型)
policy_model = AutoModelForCausalLM.from_pretrained(config.model_name_or_path)
ref_model = AutoModelForCausalLM.from_pretrained(config.model_name_or_path)
# 3. 构造示例偏好数据(实际使用时替换为真实数据集)
demo_data = [
{
"prompt": "虎皮青椒用什么做?",
"win_response": "青椒、大蒜、生抽、盐等食材,先将青椒煎至表皮起皱,再调味翻炒。",
"lose_response": "老虎和辣椒,把老虎和辣椒一起炒就成了虎皮青椒。"
},
{
"prompt": "Python中如何遍历字典?",
"win_response": "可以用for key, value in dict.items()遍历键值对,或for key in dict.keys()遍历键。",
"lose_response": "用for循环直接写for i in dict就可以遍历所有元素。"
}
]
# 4. 初始化数据集和训练器
train_dataset = DPOPreferenceDataset(demo_data, tokenizer)
trainer = DPOTrainer(
policy_model=policy_model,
ref_model=ref_model,
tokenizer=tokenizer,
config=config,
train_dataset=train_dataset
)
# 5. 启动训练
trainer.train()
if __name__ == "__main__":
main()
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)