【LangChain专栏】Retrieval 高级检索策略
引言
在前面的介绍中说明了RAG系统从原理到核心环节的全拆解:从文档加载、文本分块,到文本向量化、向量存储,已经搭建起了RAG系统的完整基础链路。但想要让RAG系统在生产环境中达到可用的效果,还需要解决检索精准度、结果多样性、上下文连贯性、多工具协同等一系列问题。
LangChain 检索器(Retrievers):从基础检索到高级策略
检索器(Retrievers)是LangChain中对检索能力的统一抽象,它的核心职责是:接收用户的自然语言查询,返回与查询语义最相关的文档块。
向量数据库的similarity_search是最基础的检索能力,而LangChain的检索器在其基础上,封装了大量高级检索策略,解决基础检索的常见痛点:比如用户查询表述模糊、检索结果冗余、上下文信息分散、检索结果与问题无关等。
检索器的核心定位与基础用法
所有检索器都实现了统一的BaseRetriever接口,核心方法是invoke(query: str),输入用户查询,返回相关的Document列表。
最基础的检索器,可直接通过向量数据库的as_retriever()方法生成,它封装了向量库的基础检索能力,同时支持配置检索参数:
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# 加载已持久化的向量库
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
collection_name="enterprise_knowledge_base",
)
# 从向量库生成基础检索器
retriever = db.as_retriever(
search_type="similarity", # 检索类型
search_kwargs={"k": 4}, # 检索参数,返回top4相关文档
)
# 执行检索
query = "RAG系统的核心流程是什么?"
docs = retriever.invoke(query)
# 查看结果
print(f"检索到文档数量:{len(docs)}")
for doc in docs:
print(doc.page_content)as_retriever()支持4种基础检索类型,适配不同的基础场景:
|
检索类型 |
核心能力 |
核心参数 |
适用场景 |
|
|
基础语义相似度检索,默认类型 |
|
绝大多数通用场景 |
|
|
相似度阈值检索,仅返回超过阈值的文档 |
|
避免返回低相关的无效文档,提升回答准确率 |
|
|
最大边际相关性检索,平衡结果的相关性与多样性 |
|
避免检索结果高度重复,覆盖更多相关维度 |
|
|
结合MMR与相似度阈值,同时控制相关性与多样性 |
上述两者参数结合 |
对结果多样性和精准度都有要求的场景 |
示例:相似度阈值检索,过滤低相关内容
# 仅返回相似度超过0.7的文档,避免无效内容进入Prompt
retriever = db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": 4, "score_threshold": 0.7},
)
docs = retriever.invoke("今天天气怎么样?") # 知识库中无相关内容,返回空列表主流高级检索策略详解与实战
基础检索只能解决简单场景的问题,面对复杂的企业级场景,我们需要用到LangChain提供的高级检索器,这里详解生产环境中最常用的5种高级检索策略,解决RAG系统的核心痛点。
MultiQueryRetriever:解决用户查询表述歧义问题
基础检索的核心痛点之一:用户的查询表述可能模糊、口语化、有歧义,直接用原始查询检索,往往无法匹配到知识库中最相关的内容。
MultiQueryRetriever的核心思路是:调用LLM将用户的原始查询,改写为多个不同表述、不同维度的查询语句,用多个查询同时检索,再合并去重结果,大幅提升召回率。
import os
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_community.chat_models import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import Chroma
# 加载向量库与LLM
embeddings = DashScopeEmbeddings(model="text-embedding-v4",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
db = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
llm = ChatOpenAI(model="qwen-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 初始化多查询检索器
retriever = MultiQueryRetriever.from_llm(
retriever=db.as_retriever(search_kwargs={"k": 3}), # 基础检索器
llm=llm, # 用于改写查询的LLM
include_original=True, # 是否保留原始查询
)
# 执行检索
query = "RAG的核心优势?"
docs = retriever.invoke(query)
# 查看结果
print(f"多查询检索到的文档数量:{len(docs)}")
for doc in docs:
print(doc.page_content[:100])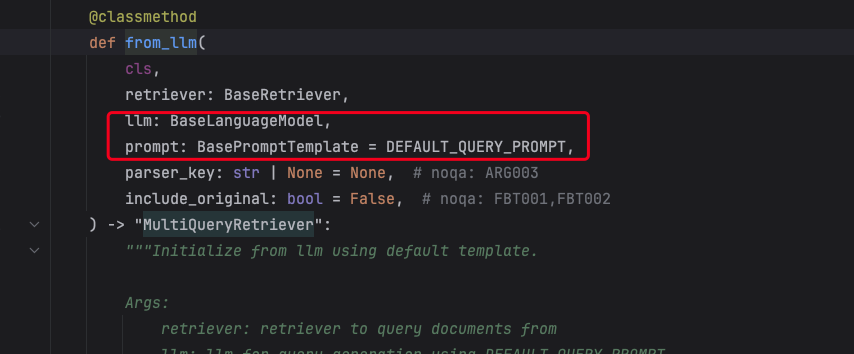
通过大模型改写的原始提示词
DEFAULT_QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is
to generate 3 different versions of the given user
question to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question,
your goal is to help the user overcome some of the limitations
of distance-based similarity search. Provide these alternative
questions separated by newlines. Original question: {question}""",
)ContextualCompressionRetriever:解决检索结果冗余问题
基础检索返回的文档块中,往往只有一小部分内容与用户的问题相关,大量无关内容会占用Token,同时干扰LLM的推理。
ContextualCompressionRetriever的核心思路是:先基础检索得到相关文档块,再调用LLM/压缩器,对每个文档块进行压缩、提取,仅保留与用户问题直接相关的内容,过滤无效信息。
import os
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
from langchain_community.chat_models import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import Chroma
# 加载向量库与LLM
embeddings = DashScopeEmbeddings(model="text-embedding-v4",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
db = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
llm = ChatOpenAI(model="qwen-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 初始化文档压缩器
compressor = LLMChainExtractor.from_llm(llm)
# 初始化上下文压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=db.as_retriever(search_kwargs={"k": 4}),
)
# 执行检索
query = "RAG的核心优势?"
compressed_docs = compression_retriever.invoke(query)
# 查看压缩后的结果(仅保留与问题相关的内容)
print(f"压缩后的文档数量:{len(compressed_docs)}")
for doc in compressed_docs:
print(f"压缩后的内容:{doc.page_content}")ParentDocumentRetriever:解决语义完整性与检索精准度的矛盾
分块环节有一个天然的矛盾:块太小,会破坏语义完整性,LLM无法理解完整的上下文;块太大,会降低检索的精准度,无法匹配到细粒度的答案。
ParentDocumentRetriever的核心思路是:父子文档分块策略。将文档拆分为大的父块(保证语义完整),再将每个父块拆分为小的子块(保证检索精准度)。子块向量化入库,检索时先匹配相关子块,再返回子块对应的完整父块给LLM,完美平衡精准度与语义完整性。
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# 定义父子拆分器
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) # 父块,大尺寸
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20) # 子块,小尺寸
# 初始化向量库(存储子块向量)与文档存储(存储完整父块)
vector_store = Chroma(collection_name="parent_child_docs", embedding_function=embeddings)
doc_store = InMemoryStore() # 生产环境可替换为Redis、MongoDB等持久化存储
# 初始化父子文档检索器
retriever = ParentDocumentRetriever(
vectorstore=vector_store,
docstore=doc_store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
# 加载文档并入库
loader = TextLoader("./data/企业产品手册.txt", encoding="utf-8")
docs = loader.load()
retriever.add_documents(docs)
# 执行检索:先匹配子块,返回完整父块
query = "产品的退款政策是什么?"
parent_docs = retriever.invoke(query)
print(f"返回的父文档数量:{len(parent_docs)}")
for doc in parent_docs:
print(f"完整父文档内容:{doc.page_content}")TimeWeightedVectorStoreRetriever:解决知识时效性问题
很多业务场景中,文档的时效性非常重要(如新闻资讯、产品更新日志、政策文件),越新的内容权重应该越高,基础检索无法区分内容的新旧。
TimeWeightedVectorStoreRetriever的核心思路是:结合语义相似度与时间权重,对检索结果进行重新排序,越新的文档得分越高,越旧的文档得分越低,保证优先返回最新的相关内容。
EnsembleRetriever:融合多路检索结果,提升召回率
单一的检索方式往往有局限性,比如语义检索擅长匹配语义相关的内容,关键词检索擅长匹配精准的专业术语、产品名称。
EnsembleRetriever的核心思路是:集成多个不同的检索器(如语义检索+关键词检索),对多路检索结果进行融合重排序(RRF算法),兼顾语义匹配与关键词匹配,大幅提升召回率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)