基于YOLOv8的鸟类识别系统
·
本项目是一个综合型鸟类识别系统,融合图像目标检测与音频语音识别两大能力。系统提供完整的桌面级可视化操作界面,支持图片、视频、本地摄像头的实时检测,以及鸟类鸣叫声的音频识别与播放,并内置模型管理、数据指标可视化与检测历史记录管理功能。
核心技术栈
- 编程语言:Python
- 深度学习框架:PyTorch
- 图像检测:Ultralytics YOLOv8 (实例分割网络 YOLOv8n-seg)
- 音频识别:ResNet18 + Mel 频谱图
- GUI 界面框架:PyQt6
- 图像/视频处理:OpenCV (cv2), NumPy
- 音频处理:librosa, soundfile
- 数据可视化:Matplotlib
- 本地持久化存储:SQLite
系统功能特点
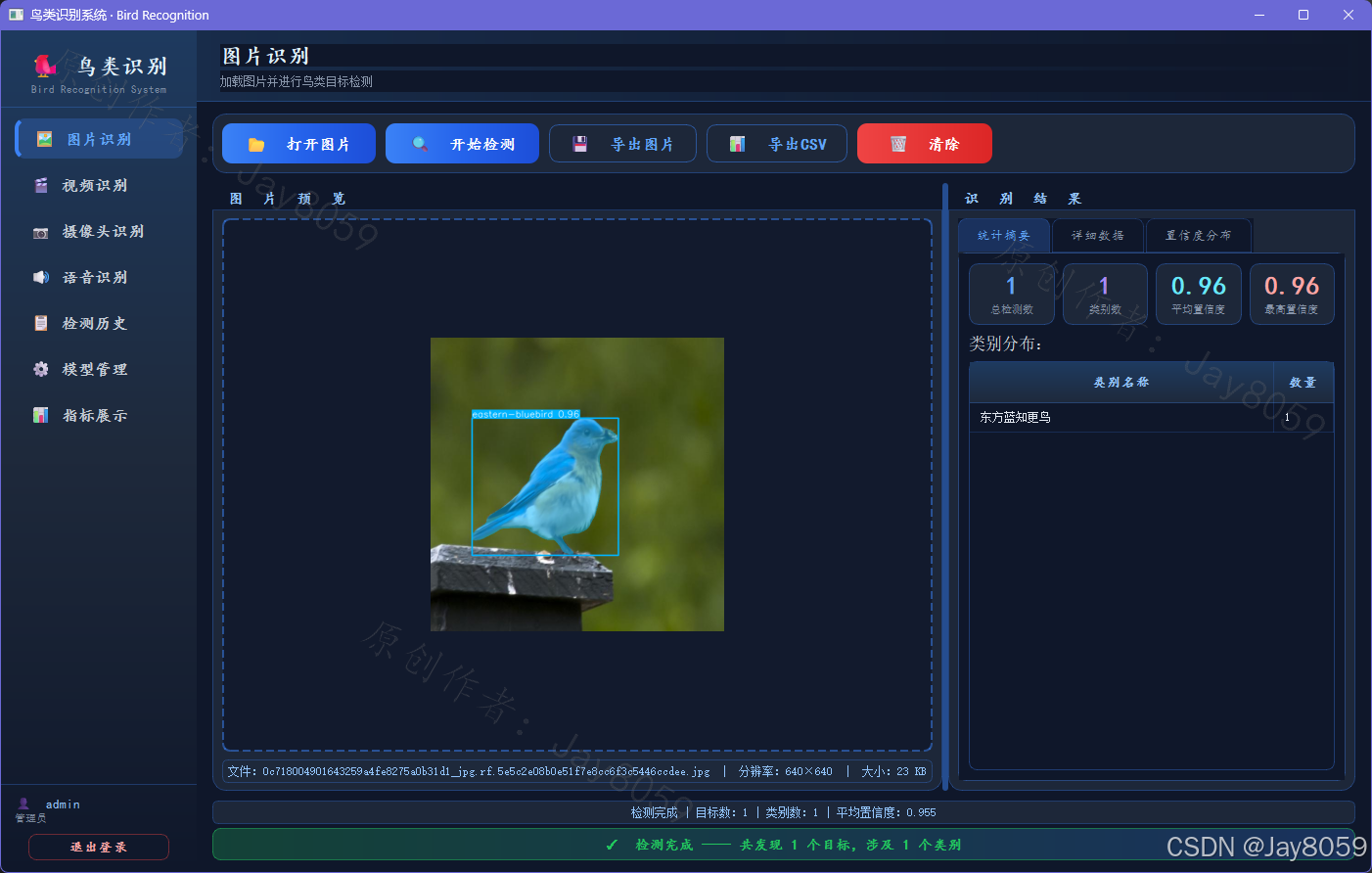
- 图片目标检测
- 支持主流图片格式拖拽上传识别。
- 检测完成后实时生成包含总检测数、平均置信度、检测框坐标(X/Y)以及面积的详细表格。
- 根据识别结果自动绘制目标置信度分布直方图。
- 视频逐帧识别
- 支持针对
.mp4、.avi等视频文件的逐帧实例分割检测。 - 界面实时展示视频进度与动态目标类别分布情况。
- 支持针对
- 实时摄像头识别
- 动态调用设备本地摄像头,支持实时帧捕获与推流预测。
- 附带快捷截图保存功能,记录感兴趣的帧画面。
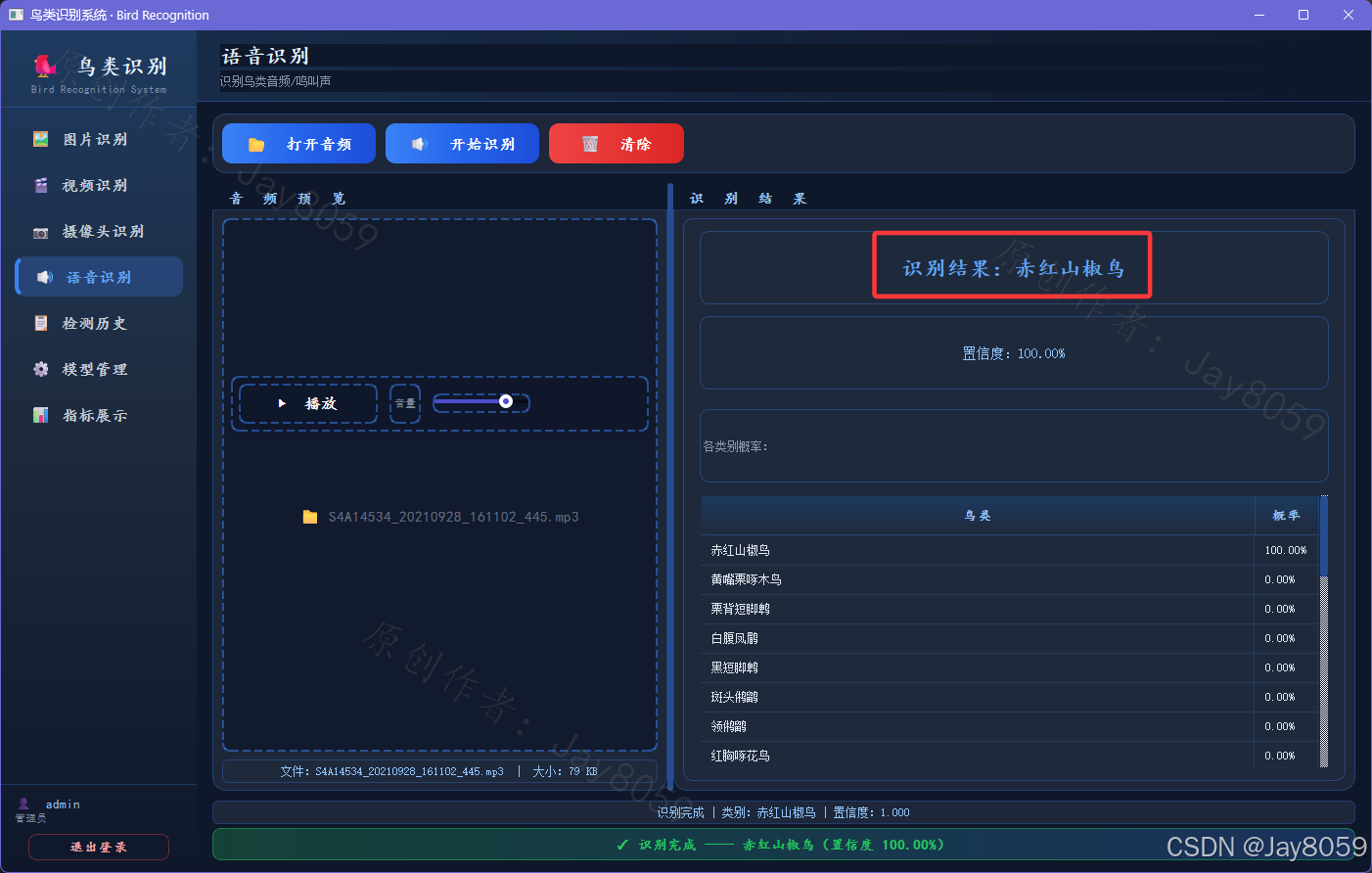
- 语音识别(鸟类鸣声)
- 支持 MP3、WAV、FLAC、OGG 等音频格式的鸟类鸣叫声识别。
- 支持音频播放、音量调节,可先试听再识别。
- 基于 ResNet18 + Mel 频谱图,输出识别结果及各类别概率分布。
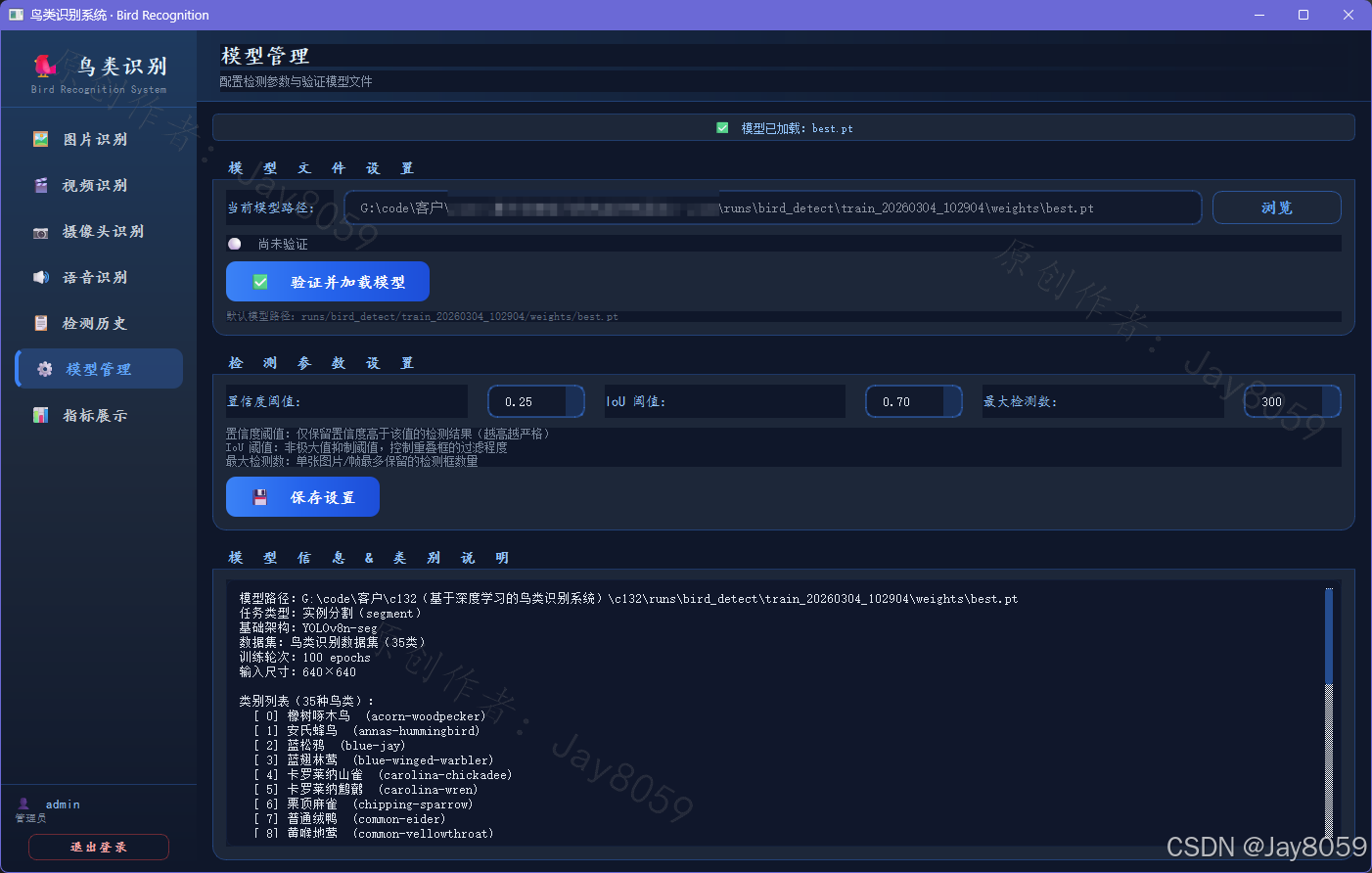
- 灵活的模型与参数管理
- 允许在图形界面动态切换不同的权重文件(
.pt)。 - 可实时拖动滑块调整置信度阈值(Confidence)和IoU阈值,实现检测精度的即时反馈调优。
- 允许在图形界面动态切换不同的权重文件(
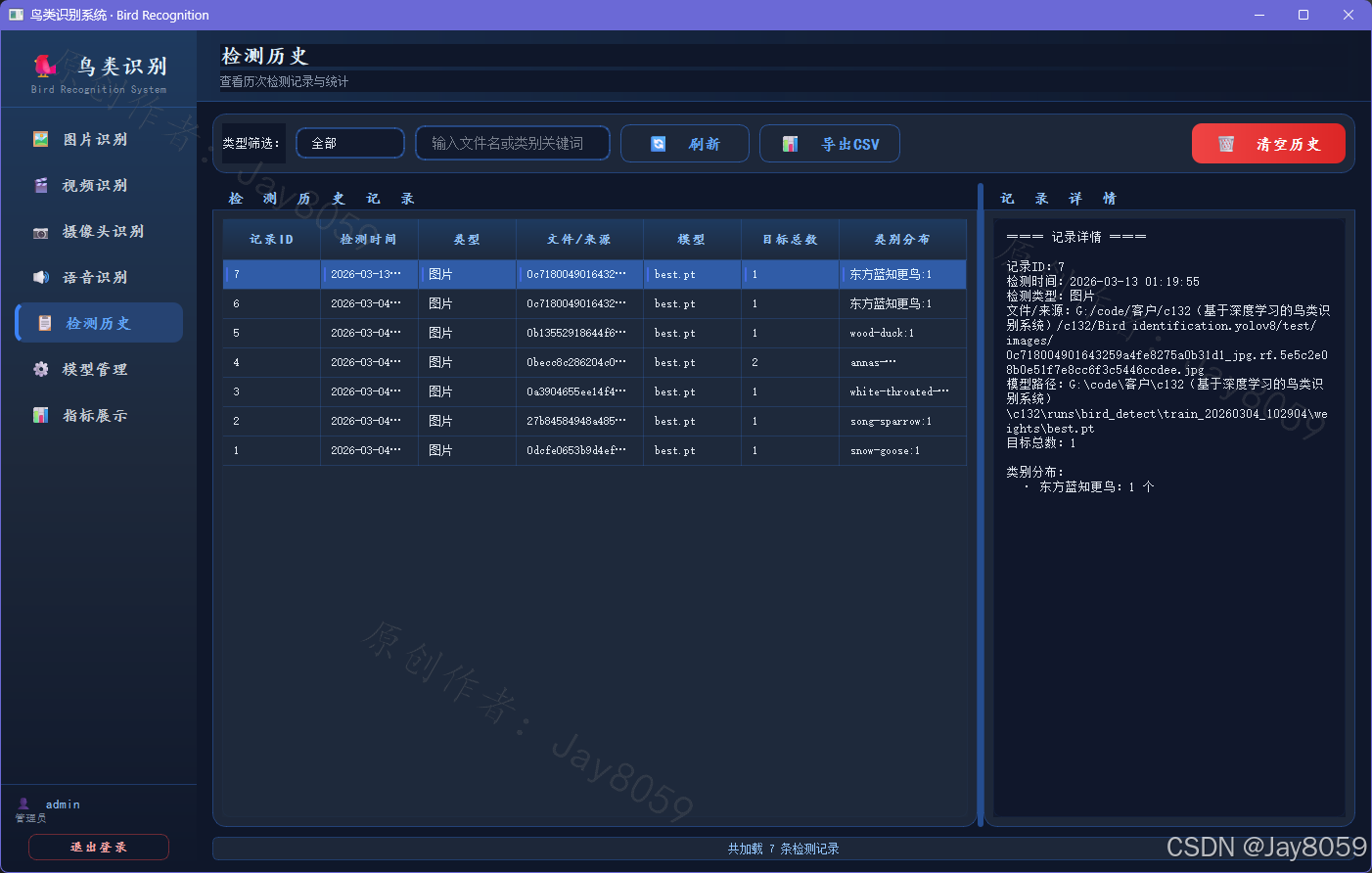
- 检测历史持久化与导出
- 所有识别记录(图片、视频、摄像头会话)均被自动保存至内置的 SQLite 数据库。
- 支持通过关键字或类别进行记录检索,一键导出历史检测记录为 CSV 表格。
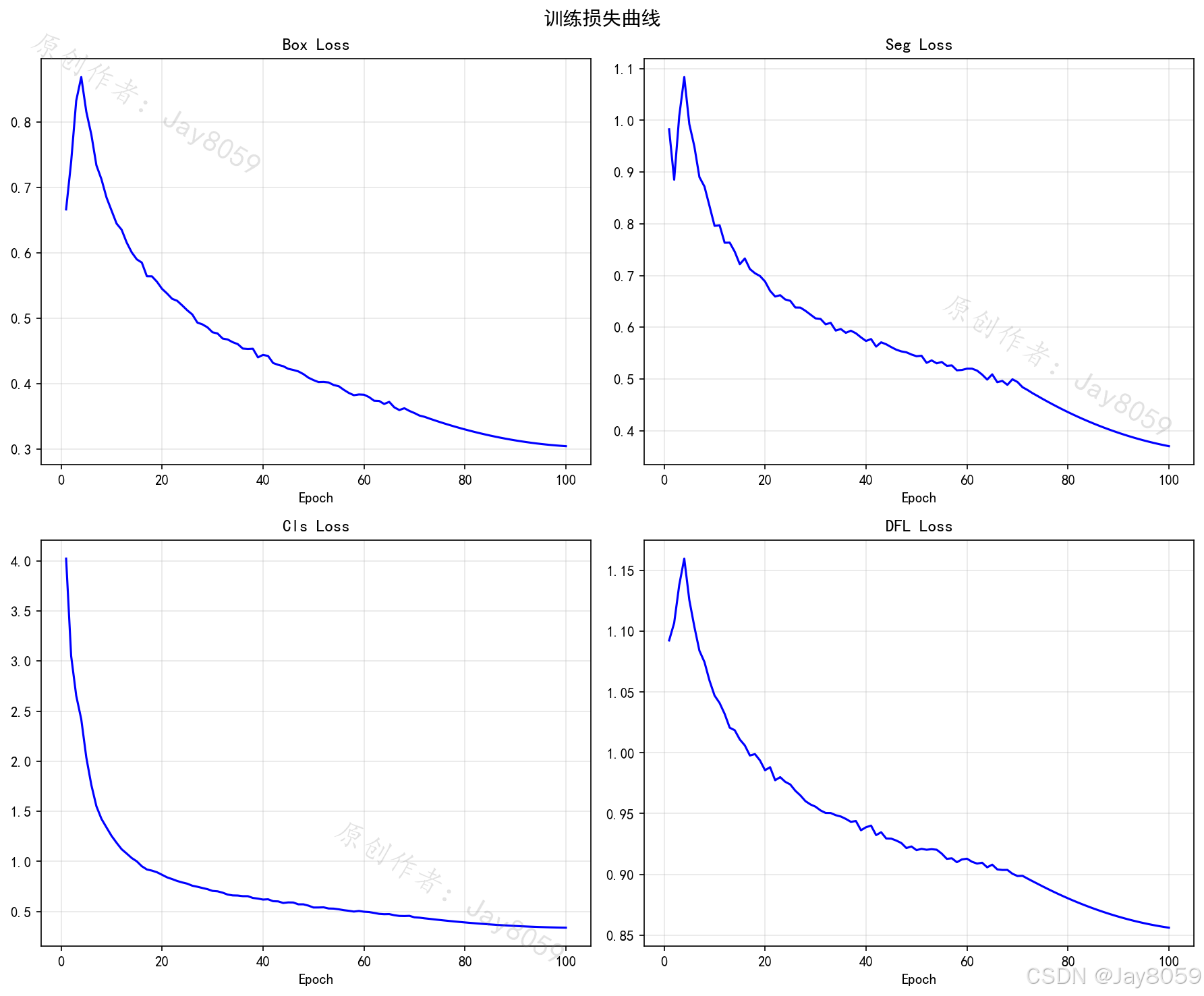
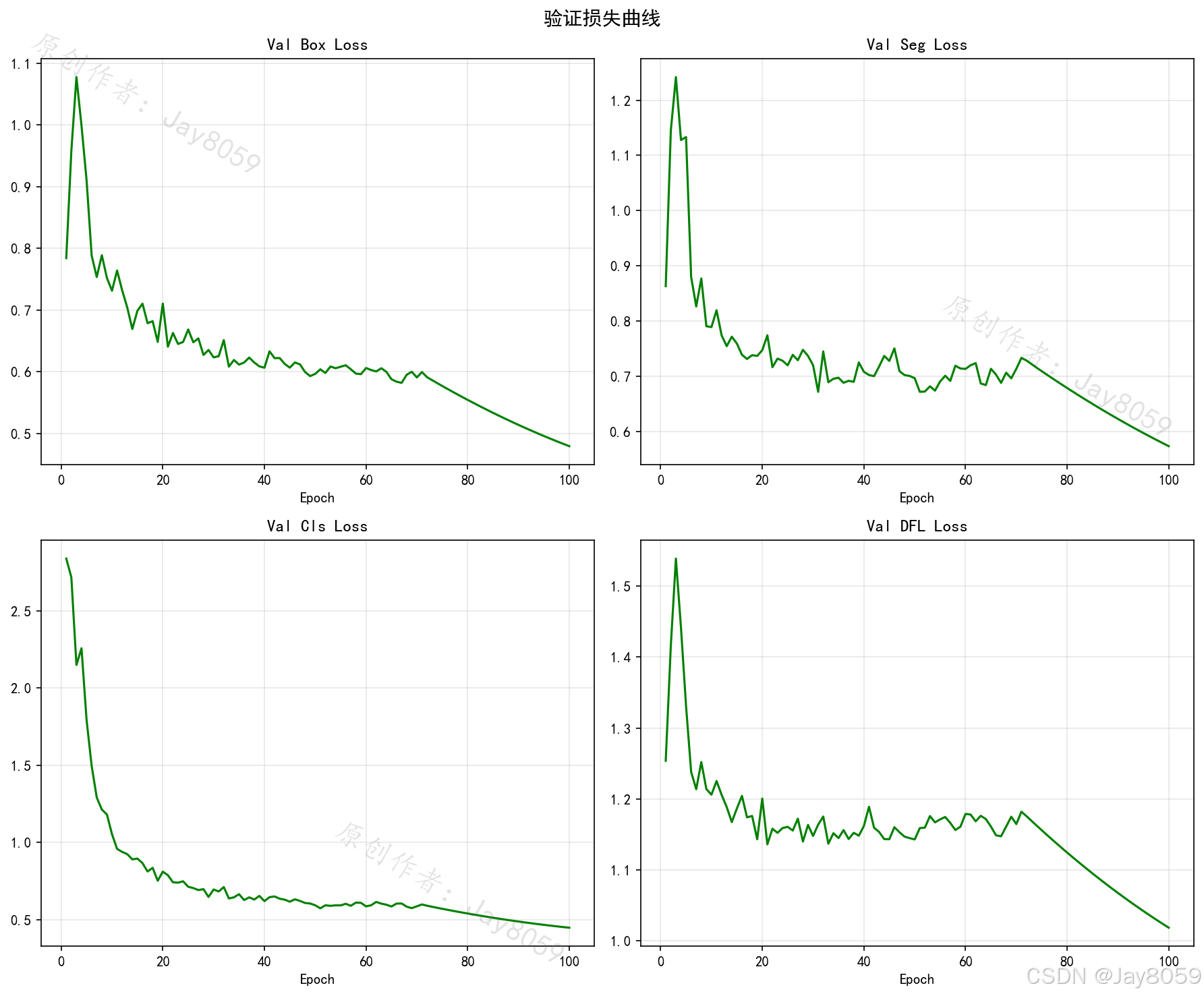
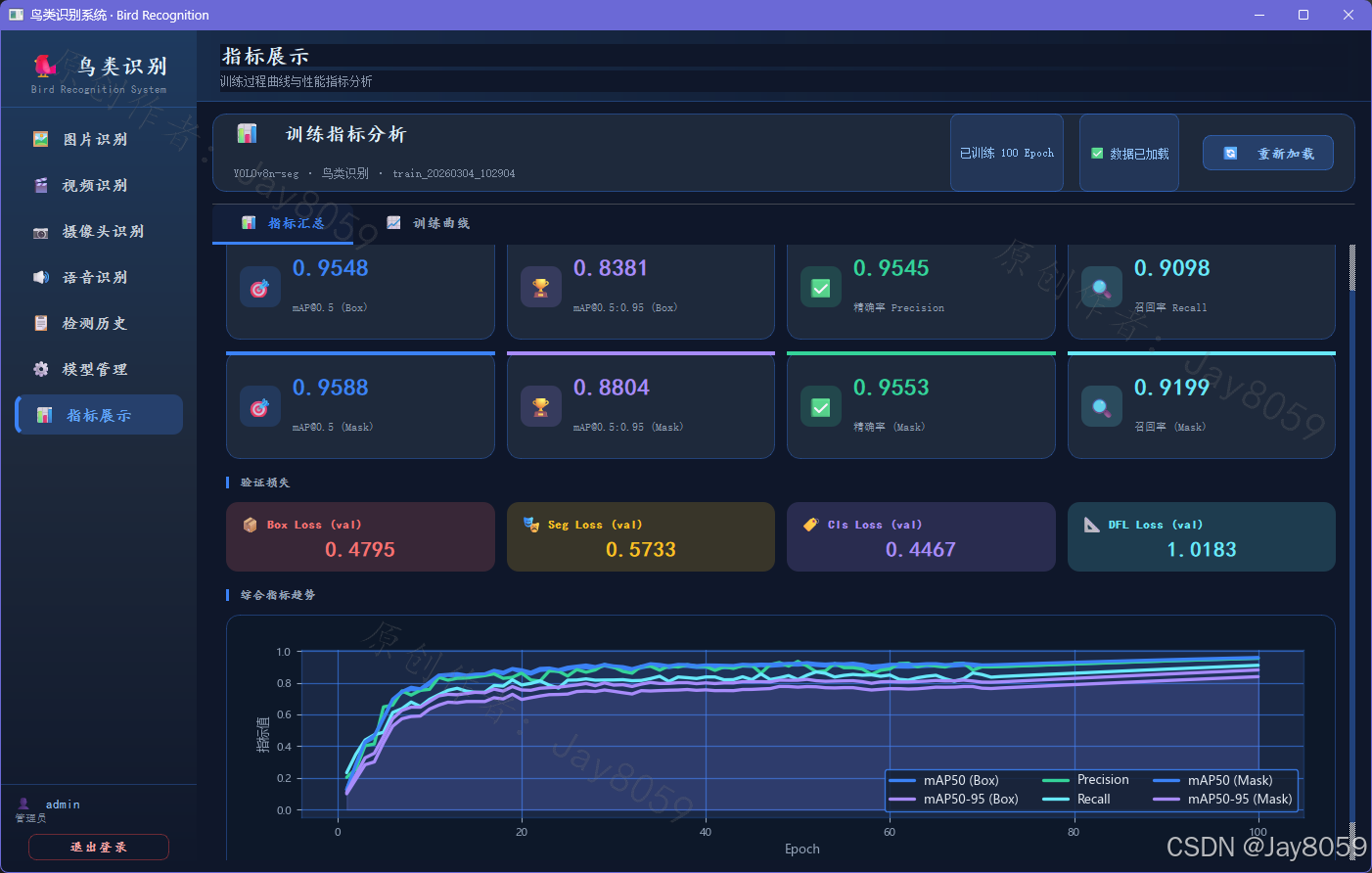
- 训练指标数据分析看板
- 读取并解析训练生成的
results.csv。 - 系统动态绘制多维度指标曲线(如Box Loss、Mask Loss、mAP@0.5、精确率等)。
- 读取并解析训练生成的
数据集说明
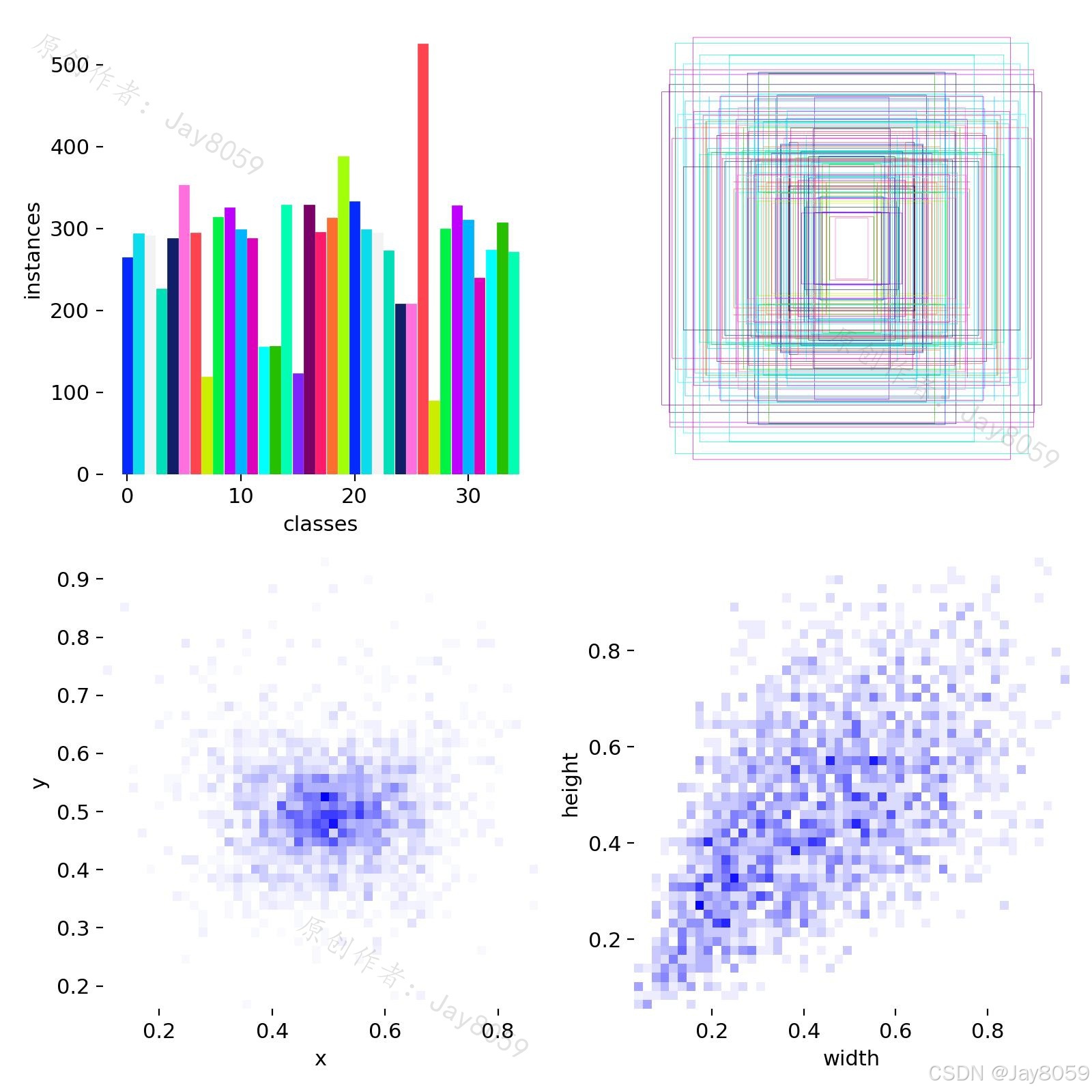
图像数据集(目标检测)
本项目针对各种常见鸟类构建了多边形实例分割数据集:
- 数据总量:共计 10,146 张标注图像。
- 划分比例:训练集 9,004 张 / 验证集 742 张 / 测试集 400 张
- 识别类别(35种):橡树啄木鸟、安氏蜂鸟、蓝松鸦、雪雁、木鸭等。
音频数据集(语音识别)
- 数据总量:约 2,300 个 MP3 音频文件。
- 鸟类种类:23 种(乌鹃、四声杜鹃、大鹰鹃、斑头鸺鹠、栗背短脚鹎等)。
- 目录结构:
datasets/下按鸟类名称分文件夹存放,每类约 100 个样本。
模型训练过程与参数
图像检测模型(YOLOv8)
- 架构:YOLOv8n-seg 实例分割
- 预训练权重:
yolov8n-seg.pt - 训练轮次:100 | 批次大小:16 | 输入尺寸:640×640
- 运行:
python train.py
音频识别模型(ResNet18)
- 架构:ResNet18 + Mel 频谱图
- 输入:5 秒音频 → Mel 频谱图 → 224×224
- 训练轮次:50 | 批次大小:32 | 学习率:1e-3
- 运行:
python train_audio.py - 输出:
runs/bird_audio/train_YYYYMMDD_HHMMSS/(含 best.pt、results.csv、混淆矩阵等)
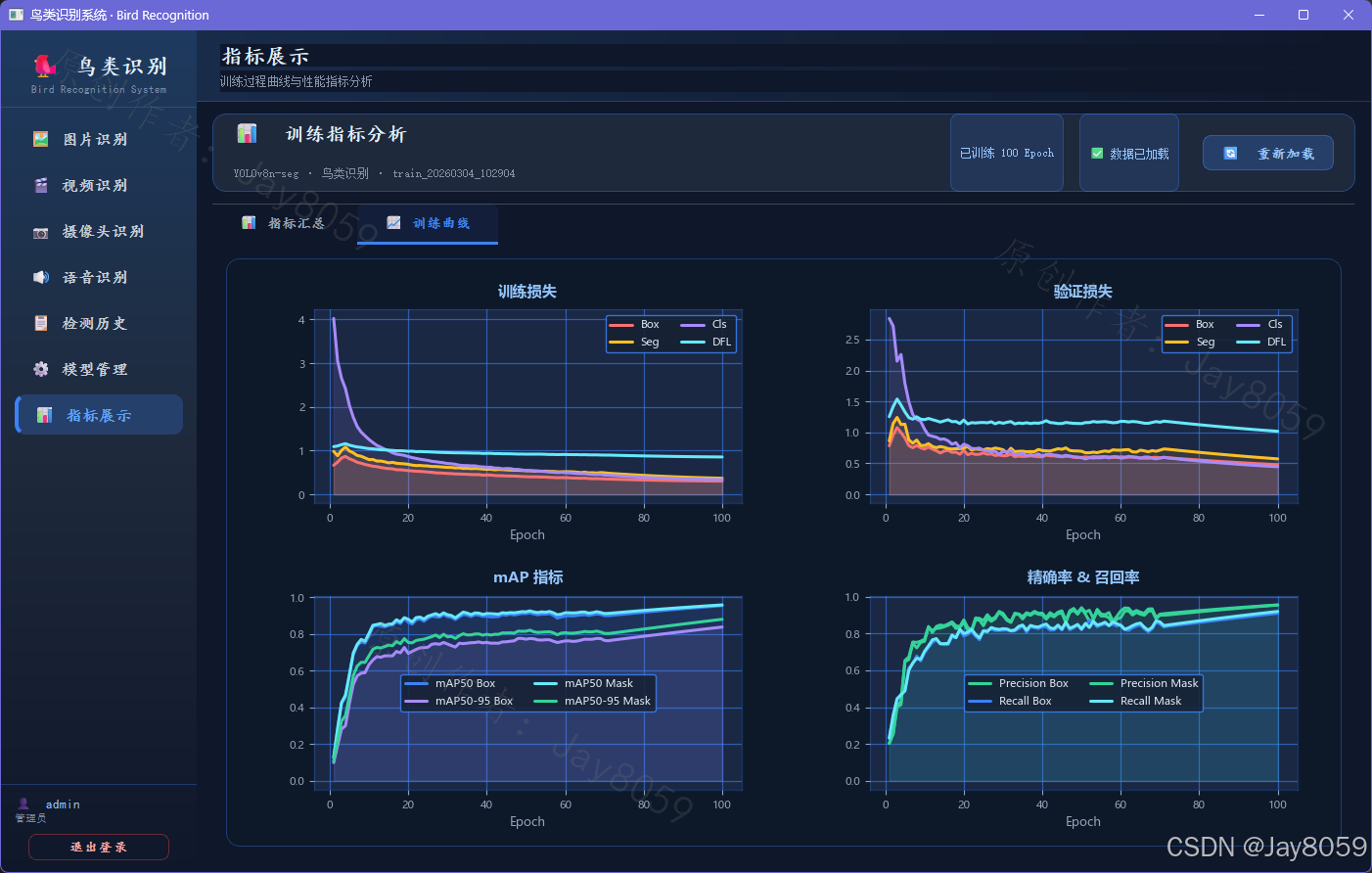
训练可视化图表含义
系统内自动集成了相关的训练结果分析表,其核心含义如下:
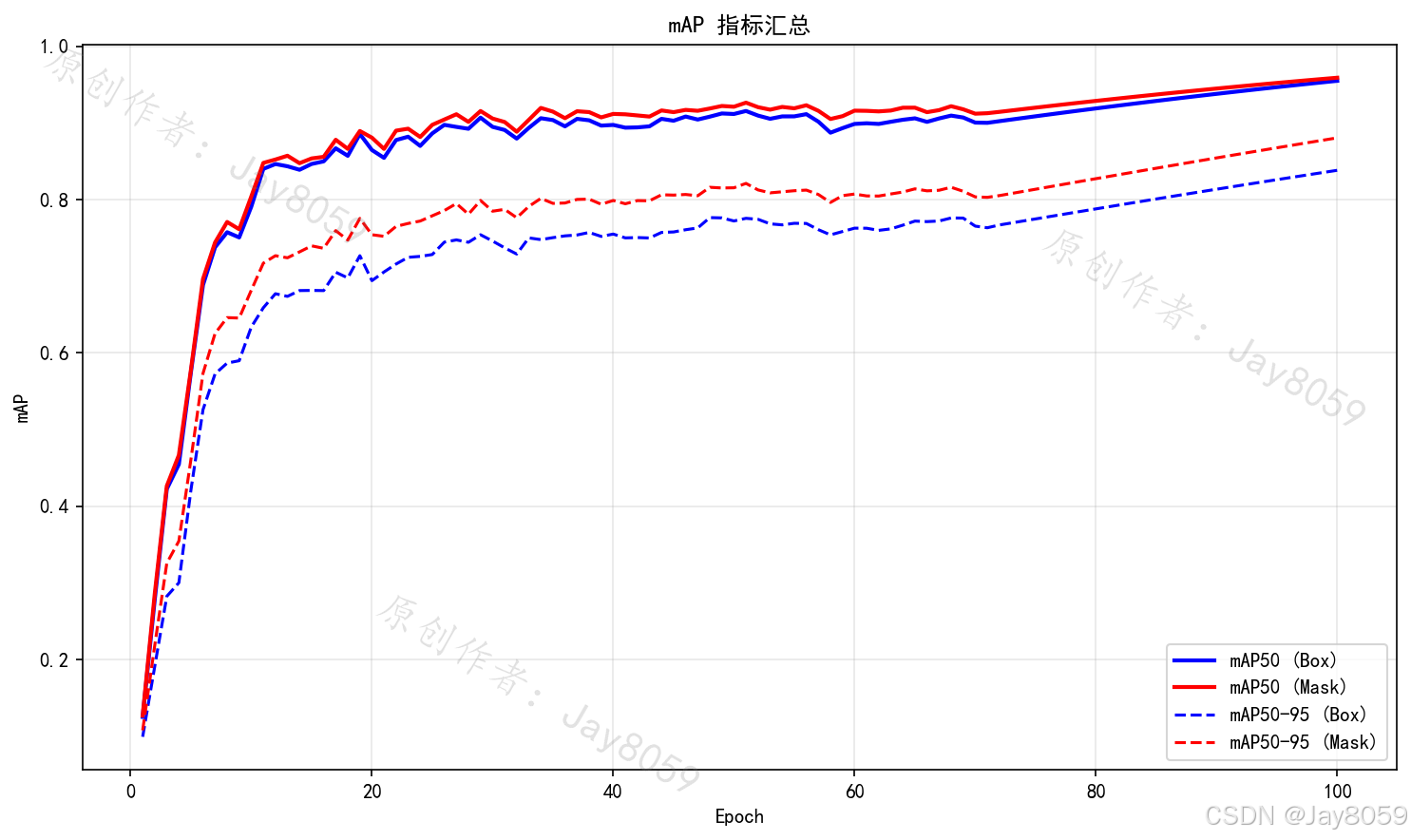
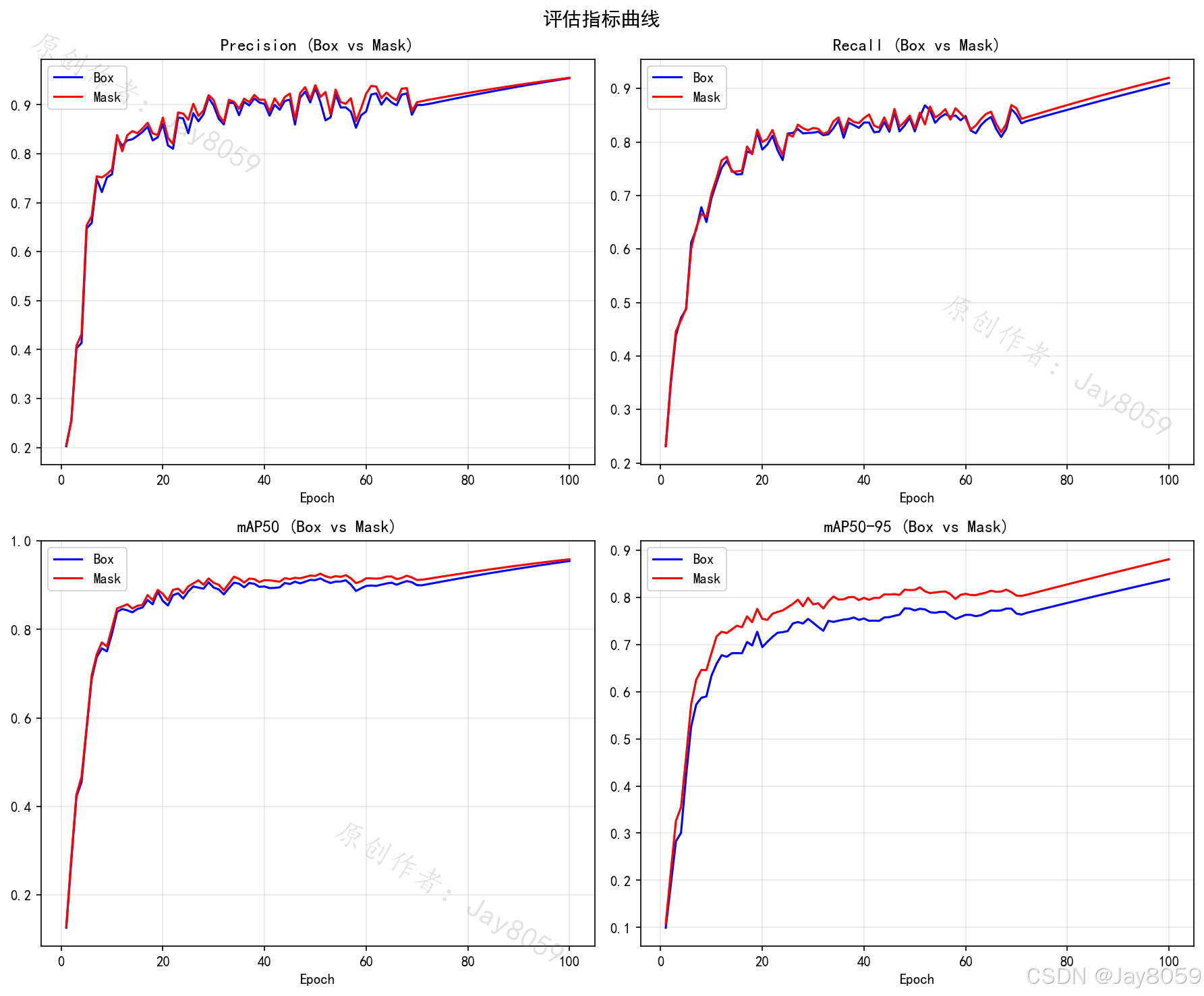
- Loss 曲线 (Box / Seg / Cls):包含训练集与验证集的损失曲线。Box代表边界框定位损失,Seg代表像素级掩码分割损失,Cls代表类别预测损失。曲线随Epoch下降并趋于平缓,说明模型逐步收敛。
- Confusion Matrix(混淆矩阵):横轴代表模型预测出的类别,纵轴代表真实的类别。对角线越亮,说明模型将真实目标预测正确的概率越高;其余非对角线区域的高亮则代表模型容易混淆的类别对。
- P-R Curve(精确率-召回率曲线):反映模型 Precision(查准率)和 Recall(查全率)之间的制约关系。曲线越靠近右上方(即曲线下方面积 mAP 越接近 1),说明模型综合检测性能越好。
- F1-Confidence 曲线:衡量了综合评价指标 F1 分数在不同置信度阈值下的表现。曲线的最高点对应的数值,即为系统能够取得精确率与召回率最佳平衡的“最优置信度阈值”。
项目结构
c132/
├── app.py # 系统主运行入口
├── train.py # 图像检测模型训练(YOLOv8)
├── train_audio.py # 音频识别模型训练(ResNet18)
├── Bird identification.yolov8/ # 图像数据集(images, labels, data.yaml)
├── datasets/ # 音频数据集(按鸟类分文件夹,MP3 格式)
├── runs/
│ ├── bird_detect/ # 图像检测训练结果(best.pt 等)
│ └── bird_audio/ # 音频识别训练结果(best.pt 等)
├── core/
│ ├── auth.py # 用户认证
│ ├── bird_names.py # 中英文鸟类名称映射
│ ├── database.py # SQLite 数据库
│ ├── detector.py # YOLOv8 推理封装
│ └── audio_classifier.py # 鸟类音频分类器(ResNet18)
└── ui/
├── styles.py # 全局 QSS 样式
├── login_window.py # 登录界面
├── main_window.py # 主窗口与侧边栏导航
└── pages/
├── image_page.py # 图片检测
├── video_page.py # 视频检测
├── camera_page.py # 摄像头检测
├── audio_page.py # 语音识别(播放 + 识别)
├── history_page.py # 检测历史
├── model_page.py # 模型管理
└── metrics_page.py # 训练指标
运行方式
# 安装依赖
pip install -r requirements.txt
# 启动系统
python app.py
首次使用语音识别功能前,需先运行 python train_audio.py 训练音频模型。



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)