用R语言解读传染病传播模型源码
X00132-用R语言解读传染病传播模型源码 传染病模型原理:自由增长模型、SI模型、SIS模型、SIR模型 用R语言手动实现 基于EpiModel包的自动化实现 如何获取新冠数据 北京的数据带入模型预测
在传染病研究领域,通过模型来理解疾病传播动态至关重要。今天咱们就用R语言深入探讨几种常见传染病模型的源码实现,包括自由增长模型、SI模型、SIS模型和SIR模型。
传染病模型原理
自由增长模型
自由增长模型假设在无任何限制条件下,感染人数呈指数增长。数学表达式为$dI/dt = \beta I$,其中$I$是感染人数,$\beta$是感染率。这个模型相对简单,但它是理解传染病初期增长态势的基础。
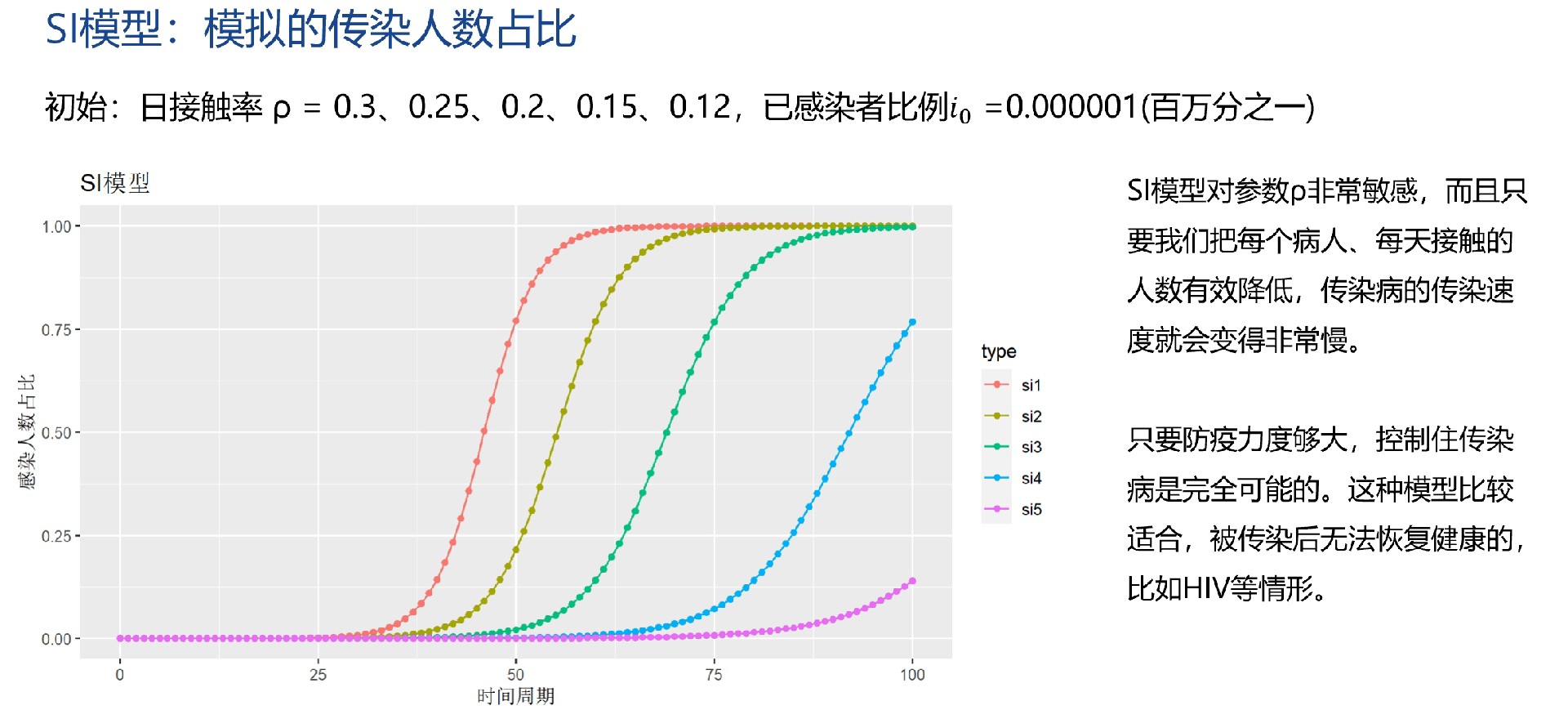
SI模型
SI模型将人群分为易感者(S)和感染者(I)两类。其核心方程为:
\[
\frac{dS}{dt} = -\beta S I \\
\frac{dI}{dt} = \beta S I
\]
这里$\beta$同样是感染率,模型假设易感者与感染者接触后会以一定概率被感染,且感染者不会恢复或死亡。
SIS模型
SIS模型在SI基础上,增加了感染者恢复后重新成为易感者的设定。方程如下:
\[
\frac{dS}{dt} = -\beta S I + \gamma I \\
\frac{dI}{dt} = \beta S I - \gamma I
X00132-用R语言解读传染病传播模型源码 传染病模型原理:自由增长模型、SI模型、SIS模型、SIR模型 用R语言手动实现 基于EpiModel包的自动化实现 如何获取新冠数据 北京的数据带入模型预测
\]
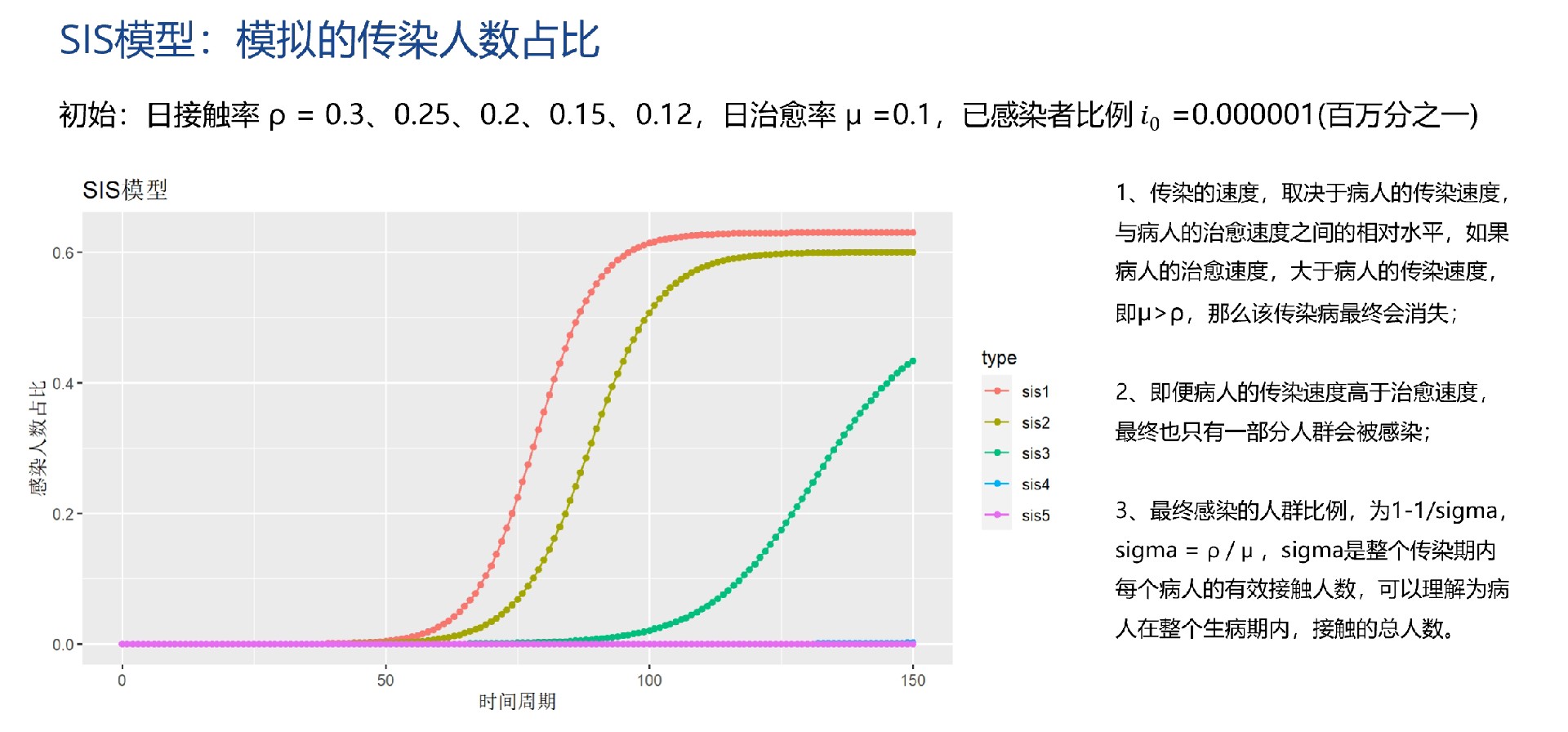
$\gamma$代表恢复率,意味着感染者恢复健康后又回到易感人群。
SIR模型
SIR模型更为复杂,把人群分为易感者(S)、感染者(I)和康复者(R)。其方程为:
\[
\frac{dS}{dt} = -\beta S I \\
\frac{dI}{dt} = \beta S I - \gamma I \\
\frac{dR}{dt} = \gamma I
\]
康复者获得了免疫力,不再易感,从感染循环中移除。
用R语言手动实现
以SIR模型为例,我们来手动实现一下。
# 定义参数
beta <- 0.2 # 感染率
gamma <- 0.1 # 恢复率
N <- 1000 # 总人数
I0 <- 1 # 初始感染人数
S0 <- N - I0 # 初始易感人数
R0 <- 0 # 初始康复人数
days <- 100 # 模拟天数
# 创建数据框存储结果
result <- data.frame(day = 0, S = S0, I = I0, R = R0)
# 迭代模拟
for (i in 1:days) {
dS <- -beta * result$S[i] * result$I[i] / N
dI <- beta * result$S[i] * result$I[i] / N - gamma * result$I[i]
dR <- gamma * result$I[i]
S_next <- result$S[i] + dS
I_next <- result$I[i] + dI
R_next <- result$R[i] + dR
new_row <- data.frame(day = i, S = S_next, I = I_next, R = R_next)
result <- rbind(result, new_row)
}
# 绘图
library(ggplot2)
ggplot(result, aes(x = day)) +
geom_line(aes(y = S, color = "Susceptible")) +
geom_line(aes(y = I, color = "Infected")) +
geom_line(aes(y = R, color = "Recovered")) +
labs(title = "SIR Model Simulation",
x = "Days",
y = "Number of People",
color = "Group")代码分析:首先我们定义了模型所需的参数,如感染率、恢复率、总人数、初始感染、易感和康复人数,以及模拟天数。接着创建一个数据框result来存储每一天的状态。在循环中,根据SIR模型的方程计算每一天易感者、感染者和康复者数量的变化,并更新数据框。最后用ggplot2包绘图展示结果。
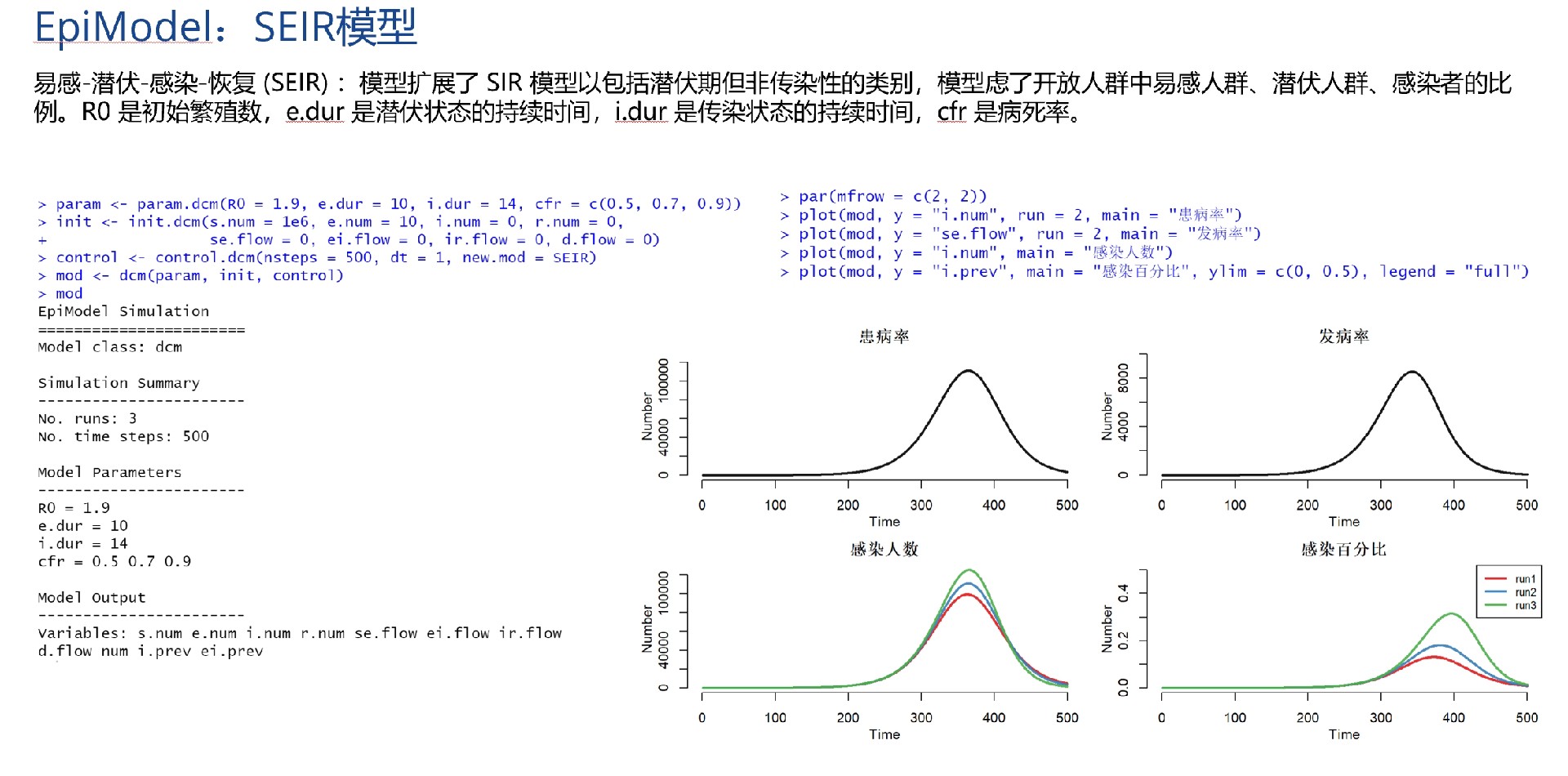
基于EpiModel包的自动化实现
EpiModel包提供了更便捷的方式来实现传染病模型。
library(EpiModel)
# 定义参数
param <- param.net(inf.prob = 0.2, rec.rate = 0.1)
init <- init.net(i.num = 1, s.num = 999)
net <- network.initialize(1000)
# 运行SIR模型
mod <- netsim(net, param, init, type = "SIR")
# 绘图
plot(mod)代码分析:加载EpiModel包后,我们通过param.net定义模型参数,init.net设置初始状态,network.initialize初始化网络结构。然后使用netsim函数运行SIR模型,并直接用plot函数绘制结果。EpiModel包大大简化了模型实现过程,适合快速进行模拟分析。
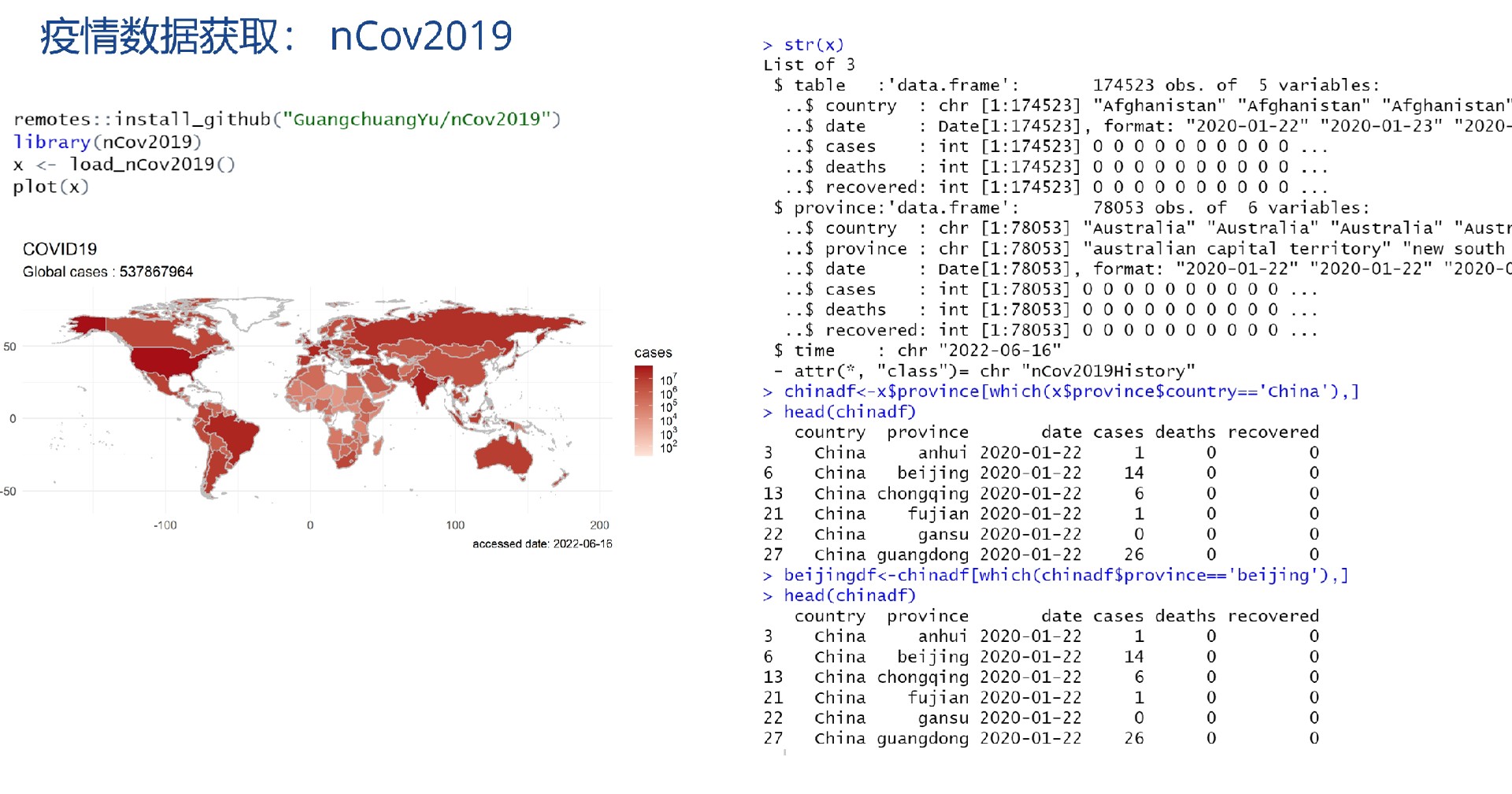
如何获取新冠数据
获取新冠数据可以通过多种途径,比如约翰霍普金斯大学的公开数据仓库。可以使用R的httr包来请求数据。
library(httr)
url <- "https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv"
response <- GET(url)
data <- read.csv(text = content(response, "text"))代码分析:先加载httr包,定义数据的URL地址,用GET函数发送请求获取数据,最后用read.csv将获取的文本数据转换为数据框格式。
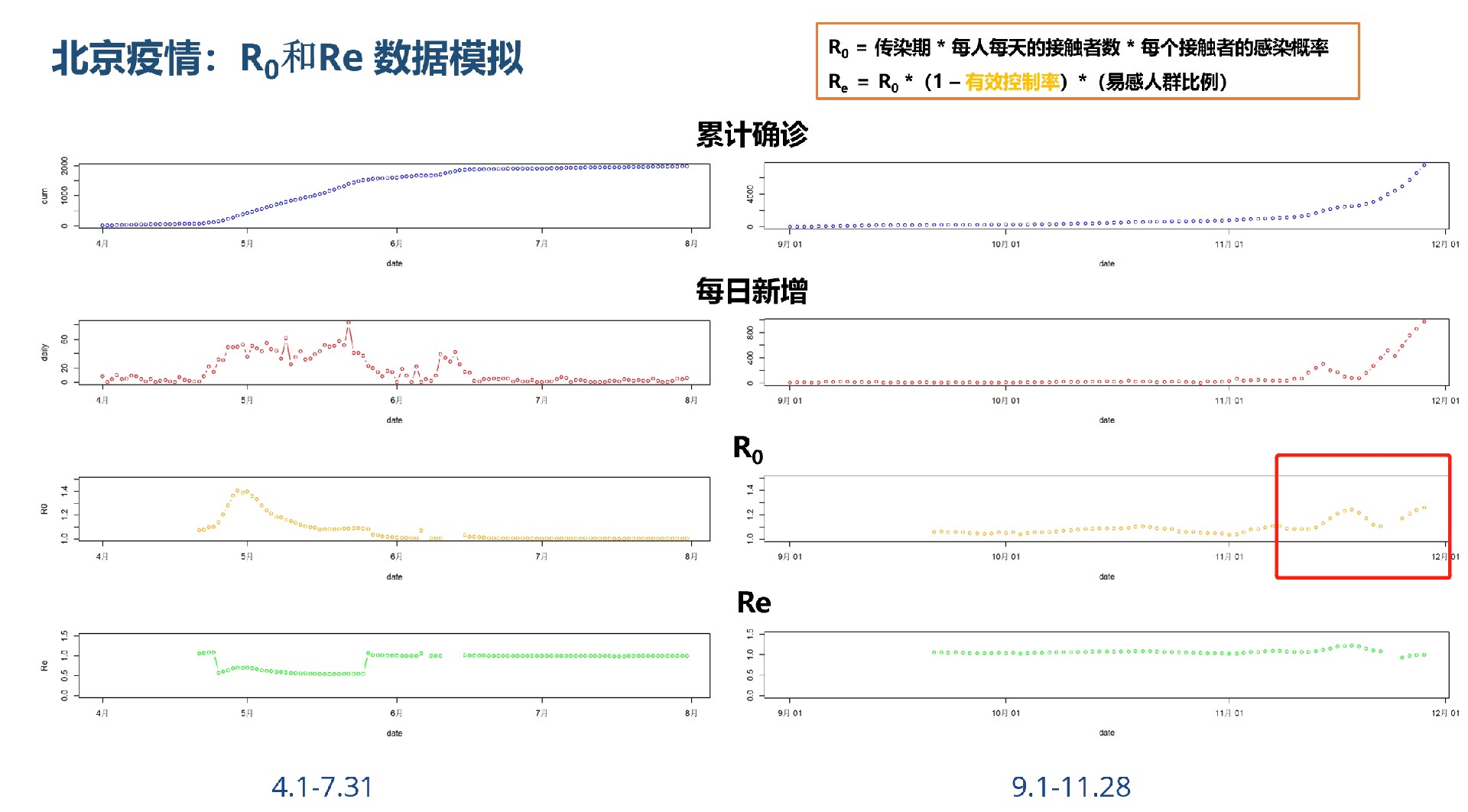
北京的数据带入模型预测
假设我们已经从上述方式获取到北京的新冠确诊数据,我们可以将其处理后带入之前的模型进行预测。但实际操作中,还需考虑数据的清洗、时间序列处理等步骤。
# 假设data是获取到的包含北京数据的数据框
beijing_data <- data[data$Province.State == "Beijing", ]
# 对数据进行处理,例如提取时间序列数据
time_series <- as.numeric(t(beijing_data[,-(1:4)]))
# 这里简单假设我们用自由增长模型来预测
# 拟合数据得到感染率beta
# 实际中这需要更复杂的统计方法,这里只是示例
beta_est <- mean(diff(time_series) / time_series[-length(time_series)])
# 预测未来10天
days_to_predict <- 10
prediction <- numeric(days_to_predict)
prediction[1] <- time_series[length(time_series)]
for (i in 2:days_to_predict) {
prediction[i] <- prediction[i - 1] * (1 + beta_est)
}代码分析:先从总的数据中筛选出北京的数据,提取确诊人数的时间序列。然后简单估计了自由增长模型中的感染率beta(实际中需要更严谨的统计方法),最后根据自由增长模型预测未来10天的确诊人数。
通过R语言,我们不仅能深入理解传染病模型的原理,还能利用各种工具实现模型、获取数据并进行预测,为传染病防控提供有力支持。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)