详解bert模型
BERT 模型详解:从原理到实践
一、BERT 简介
BERT是由 Google 在 2018 年提出的一种预训练语言模型,它极大推动了自然语言处理(NLP)的发展。
BERT 的论文是:Pre-training of Deep Bidirectional Transformers for Language Understanding
在 BERT 出现之前,大多数 NLP 模型都是:
- 单向语言模型(从左到右)
- 需要针对每个任务单独训练
而 BERT 提出了 双向上下文表示(Bidirectional Contextual Representation),可以同时利用句子左右两侧的信息。
例如一句话:
苹果很好吃
传统模型可能只看到:
苹果 → 很好吃
而 BERT 会同时看到:
苹果 ← 很好吃
这样可以更好地理解语言语义。
二、BERT 的核心思想
BERT 的核心思想可以概括为:预训练 + 微调(Pretrain + Fine-tune)
流程如下:
大量无标签文本
BERT 预训练
得到通用语言模型
在具体任务上微调
完成 NLP 任务
BERT 可以应用于很多任务,例如:
- 文本分类
- 情感分析
- 命名实体识别
- 机器阅读理解
- 问答系统
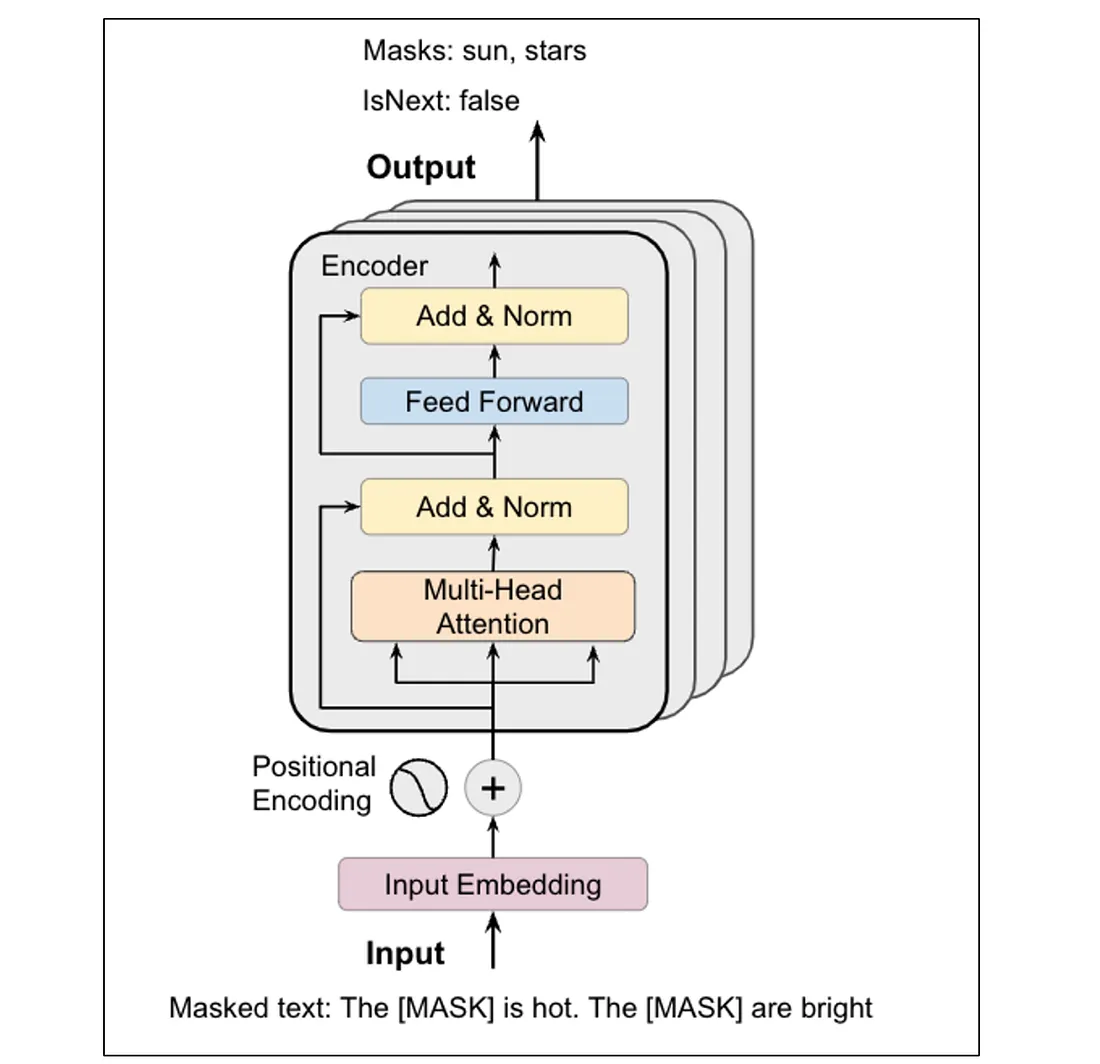
三、BERT 的模型结构
BERT 的底层结构基于Transformer | Attention is All you Need 论文。
Transformer 由两个部分组成:
- Encoder
- Decoder
而 BERT 只使用 Encoder。
整体结构如下:
输入文本
Tokenizer
Embedding Layer
Transformer Encoder × N
输出向量
BERT 有两个主要版本:
| 模型 | 层数 | 隐藏层维度 | 参数量 |
|---|---|---|---|
| BERT-base | 12 | 768 | 110M |
| BERT-large | 24 | 1024 | 340M |
中文常用模型:bert-base-chinese
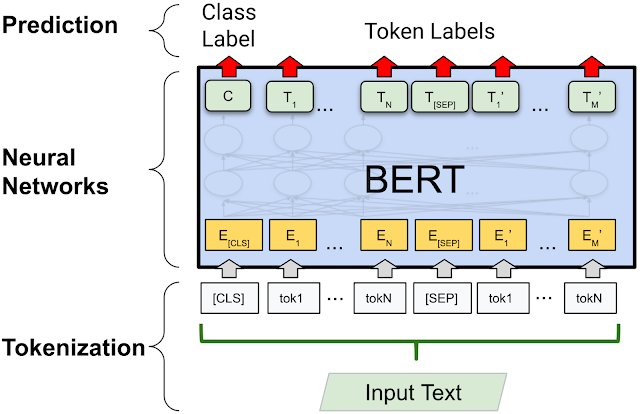
四、BERT 的输入表示
BERT 的输入不是简单的文本,而是由三部分组成:
Input Embedding = Token Embedding + Segment Embedding + Position Embedding
1 Token Embedding
Token Embedding 表示词的向量。
例如:
我 爱 自然 语言 处理
在中文 BERT 中通常按 字粒度 分词:
[CLS] 我 爱 自 然 语 言 处 理 [SEP]
2 Segment Embedding
Segment 用于区分句子 A 和句子 B。
例如:
句子A:[CLS] 我 爱 NLP [SEP]
句子B:它 很 有 趣 [SEP]
Segment 标记:
0 0 0 0 0
1 1 1 1 1
3 Position Embedding
因为 Transformer 不具备顺序信息,所以需要 位置编码。
例如:
位置: 0 1 2 3 4 5
这样模型就能理解词的顺序。
五、BERT 的两种预训练任务
BERT 在预训练阶段主要做两件事情。
1 Masked Language Model(MLM)
随机遮挡句子中的某些词,让模型预测它们。
例如:
我 爱 [MASK] 语言 处理
模型需要预测:
自然
这种方式可以让模型学习上下文关系。
2 Next Sentence Prediction(NSP)
判断两个句子是否连续。
例如:
句子A:我喜欢机器学习
句子B:深度学习很有趣
模型需要判断:
IsNext / NotNext
这样可以学习句子之间的关系。
六、BERT 在 NLP 任务中的应用
BERT 在很多任务中都取得了突破性效果。
例如:
1 文本分类
输入:
这个手机很好用
输出:
正面评论
常用于:
- 情感分析
- 垃圾邮件分类
2 命名实体识别
识别文本中的实体,例如:
张三 在 北京 工作
识别结果:
张三 → 人名
北京 → 地名
3 问答系统
例如:
问题:北京是哪个国家的首都?
BERT 可以在文章中找到答案。
七、BERT 的代码示例
在 Python 中通常使用 Transformers 库。
安装:
pip install transformers
加载 tokenizer:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
text = "我爱自然语言处理"
encoding = tokenizer(text)
print(encoding)
输出类似:
{
'input_ids': [...],
'token_type_ids': [...],
'attention_mask': [...]
}
加载模型:
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(
"bert-base-chinese",
num_labels=2
)
这可以直接用于 情感分类任务。
八、BERT 的优缺点
优点
- 双向上下文理解能力强
- 预训练模型可以迁移到多种任务
- 在很多 NLP benchmark 上表现优秀
缺点
- 参数量大
- 训练成本高
- 推理速度较慢
因此后来又出现了很多改进模型,例如:
- RoBERTa
- ALBERT
- DistilBERT
九、计算bert模型的参数
以下计算忽略了bias
Embedding层参数计算
1. Token Embedding
词向量矩阵大小
vocab_size * hidden_size:21128 * 768 = 16226304
2.Segment Embedding
支持两个句子输入
2 * 768 = 1576
3.Position Embedding
最大序列长度(采用独热编码)
512 * 768 = 393216
Embedding层总参数:16226304 + 1576 + 393216 = 16621096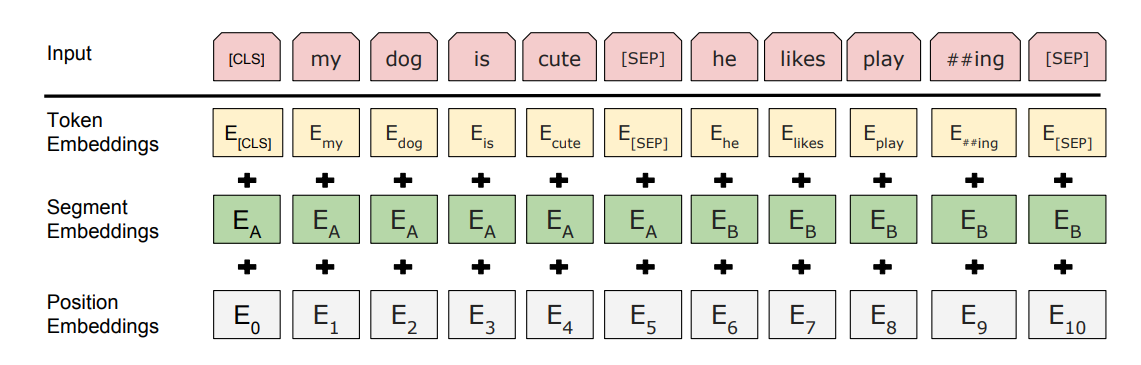
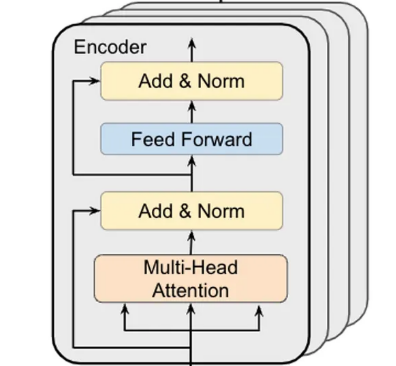
Transformer Encoder
BERT-base 一共有 12 层 Transformer Encoder。
每一层包含两个主要模块:
- Multi-Head Attention
- Feed Forward Network
Multi-Head Attention多头注意力机制
Q = XWq
K = XWk
V = XWv
每个矩阵大小:768 * 768
总共:3 * 768 * 768 = 1769472
Add & Norm 还有一个输出矩阵:768 * 768 = 589824
Feed Forward
linear(768, 768*4)
linear(768 * 4, 768)
所以参数是:768 * 3072 + 3072 * 768 = 4718592
由于总共有12层:12 * (1769472 + 589824 + 4718592) = 84934656
Pooler output池化层
768 * 768 = 589824
总参数
- Embedding: 16621096
- Encoder: 84934656
- pooler:589824
总参数约为:102145536
from transformers import BertModel, BertTokenizer
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
bert = BertModel.from_pretrained("bert-base-chinese")
print(get_parameter_number(bert))
输出:
{‘Total’: 102267648, ‘Trainable’: 102267648}
102145536

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)