探索基于知识图谱与人工神经网络的简历推荐系统
DL00302-基于知识图谱与人工神经网络的简历推荐系统 基于知识图谱与人工神经网络的简历推荐系统 技术栈前端使用echarts.js(之后有时间会考虑用vue改写一下), 后端基于Python Django; 特征处理阶段,技能相关特征基于知识图谱处理,图谱构建使用neo4j; 系统的流程是先做二分类筛选,再给分类为正的样本进行排序; 二分类模型基于DNN,基于Keras训练, 线上分类时直接调用已经训练好保存为h5格式的model文件; 排序函数将随机森林的特征重要性作为基础排序指标;
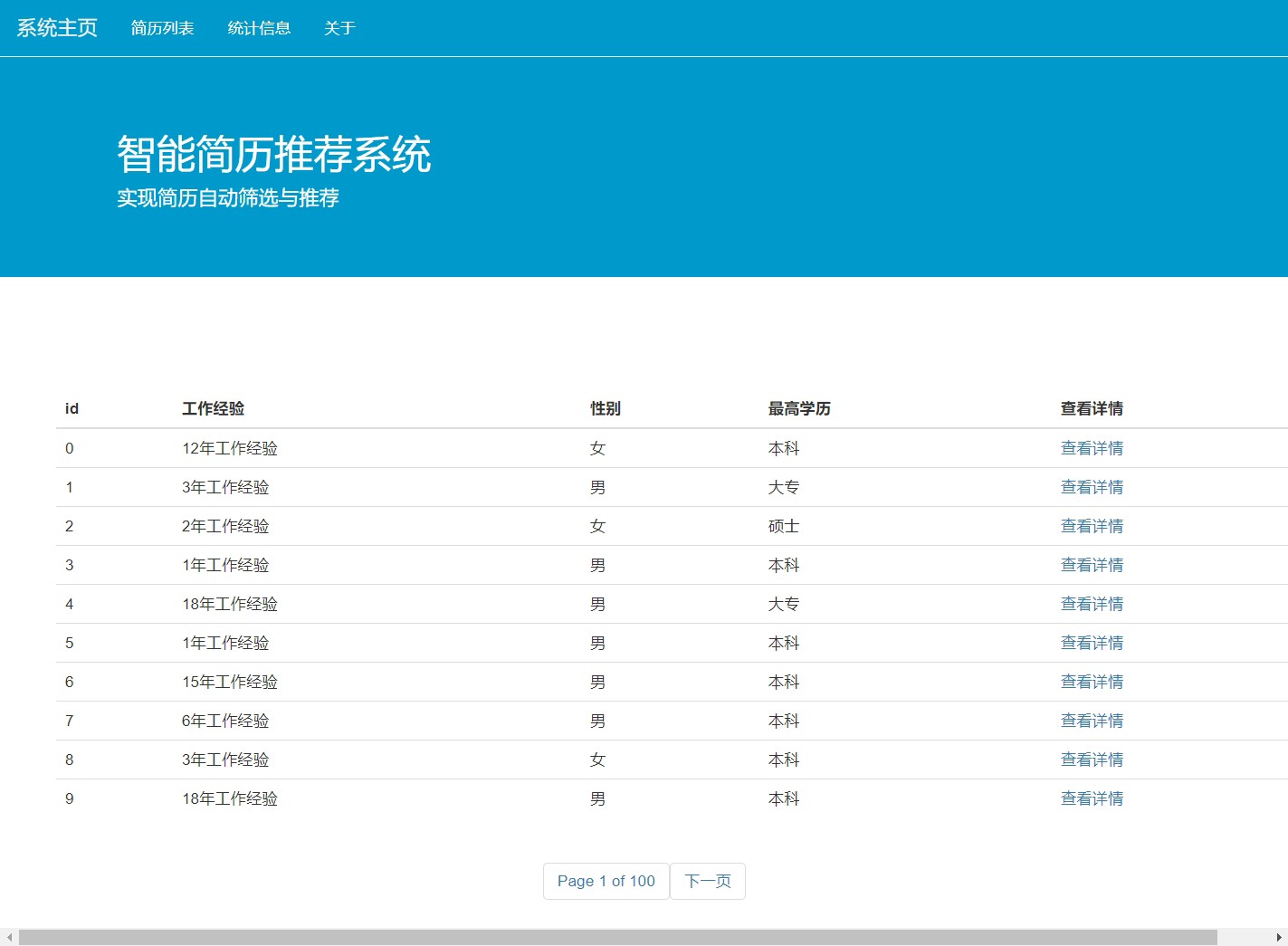
最近在捣鼓一个超有意思的项目:DL00302 - 基于知识图谱与人工神经网络的简历推荐系统,迫不及待来和大家分享分享。
一、技术栈
前端
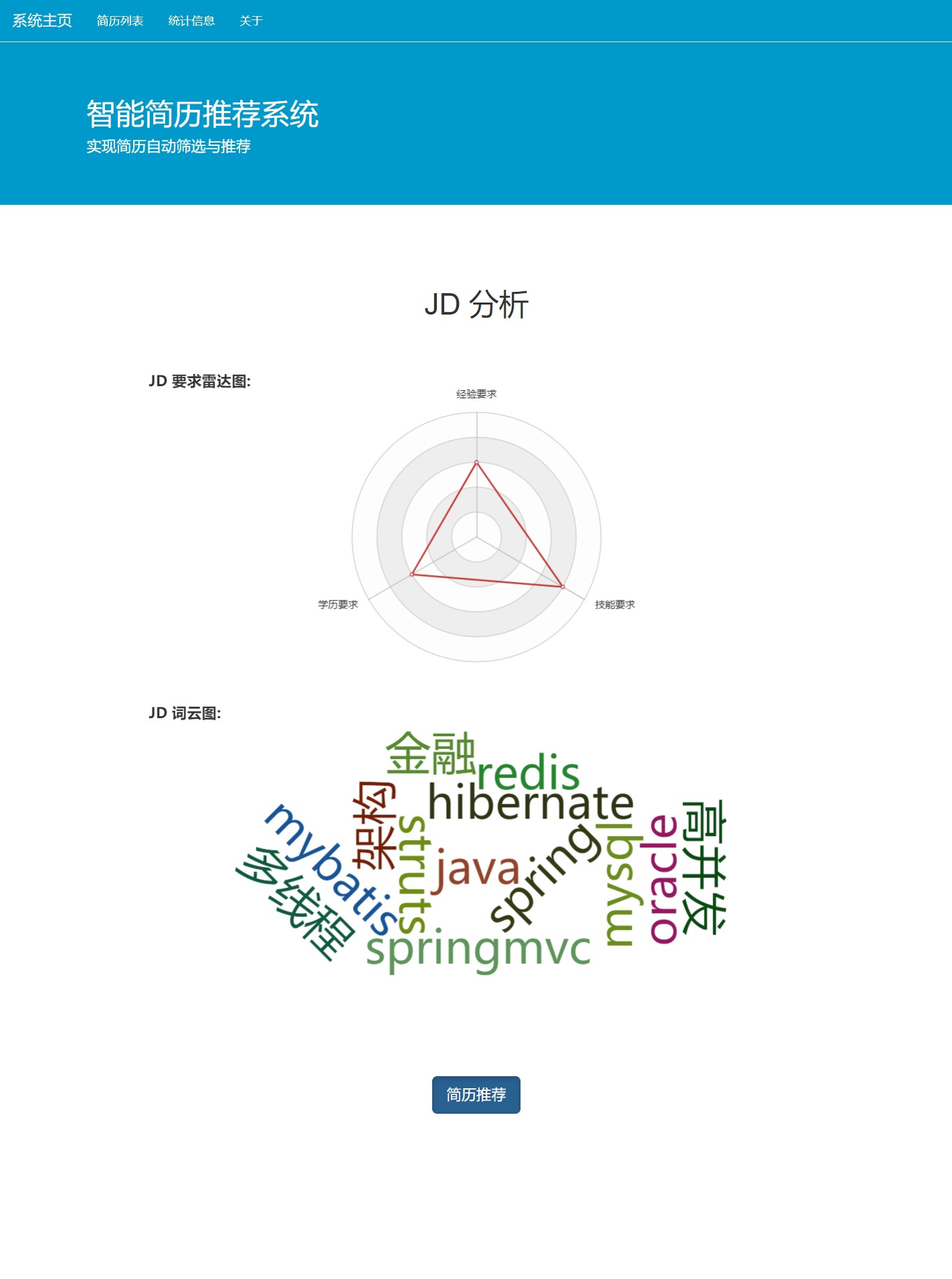
前端目前用的是echarts.js ,这个库在数据可视化方面真的非常强大。通过简单的几行代码,就能生成各种酷炫的图表。比如说,要生成一个简单的柱状图展示各岗位收到简历数量:
// 基于echarts.js生成柱状图示例
var myChart = echarts.init(document.getElementById('main'));
var option = {
xAxis: {
type: 'category',
data: ['岗位A', '岗位B', '岗位C']
},
yAxis: {
type: 'value'
},
series: [{
data: [120, 200, 150],
type: 'bar'
}]
};
myChart.setOption(option);这段代码里,首先通过echarts.init初始化一个图表实例,绑定到HTML中id为main的DOM元素上。然后定义option配置项,包括xAxis轴(这里用类别轴展示岗位),yAxis轴(数值轴展示简历数量),以及series系列(这里定义为柱状图类型,并设置对应的数据)。之后有时间打算用vue改写前端,Vue的组件化和数据双向绑定特性,能让前端开发更加高效和可维护。
后端
后端基于Python的Django框架,Django自带的ORM、管理后台等功能,能极大加快开发速度。例如,在处理简历数据存储时,通过Django的模型定义就能轻松和数据库交互。
from django.db import models
class Resume(models.Model):
name = models.CharField(max_length=100)
skills = models.TextField()
# 其他简历相关字段这里定义了一个Resume模型类,继承自models.Model。name字段定义为字符类型,最大长度100,skills字段定义为文本类型,用来存储简历中的技能信息。
二、特征处理
技能相关特征是基于知识图谱来处理的,图谱构建使用neo4j。知识图谱就像是一张巨大的语义网络,能很好地挖掘技能之间的关系。比如说,“Python编程”和“数据分析”可能因为都和数据处理相关,在知识图谱里就会有一定的关联。在neo4j中,可以通过Cypher语句来创建节点和关系。
CREATE (p:Skill {name: 'Python编程'})
CREATE (d:Skill {name: '数据分析'})
CREATE (p)-[:RELATED_TO]->(d)上述Cypher语句,先创建了两个技能节点“Python编程”和“数据分析”,然后建立了“Python编程”到“数据分析”的RELATED_TO关系。这样在处理简历技能特征时,就能借助这种关系,更全面地理解简历技能的价值和相关性。
三、系统流程
二分类筛选
系统首先进行二分类筛选,这个二分类模型是基于DNN(深度神经网络),使用Keras来训练。Keras是一个简洁易用的深度学习框架。以下是一个简单的二分类DNN模型示例:
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=input_dim))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])这里先创建了一个顺序模型Sequential。然后添加了一个全连接层Dense,有64个神经元,激活函数使用relu,输入维度inputdim根据实际特征数量确定。接着再添加一个输出层,只有1个神经元,激活函数为sigmoid,适用于二分类问题。最后使用binarycrossentropy损失函数,adam优化器来编译模型。训练好的模型会保存为h5格式,线上分类时直接调用这个model文件,方便快捷。
排序
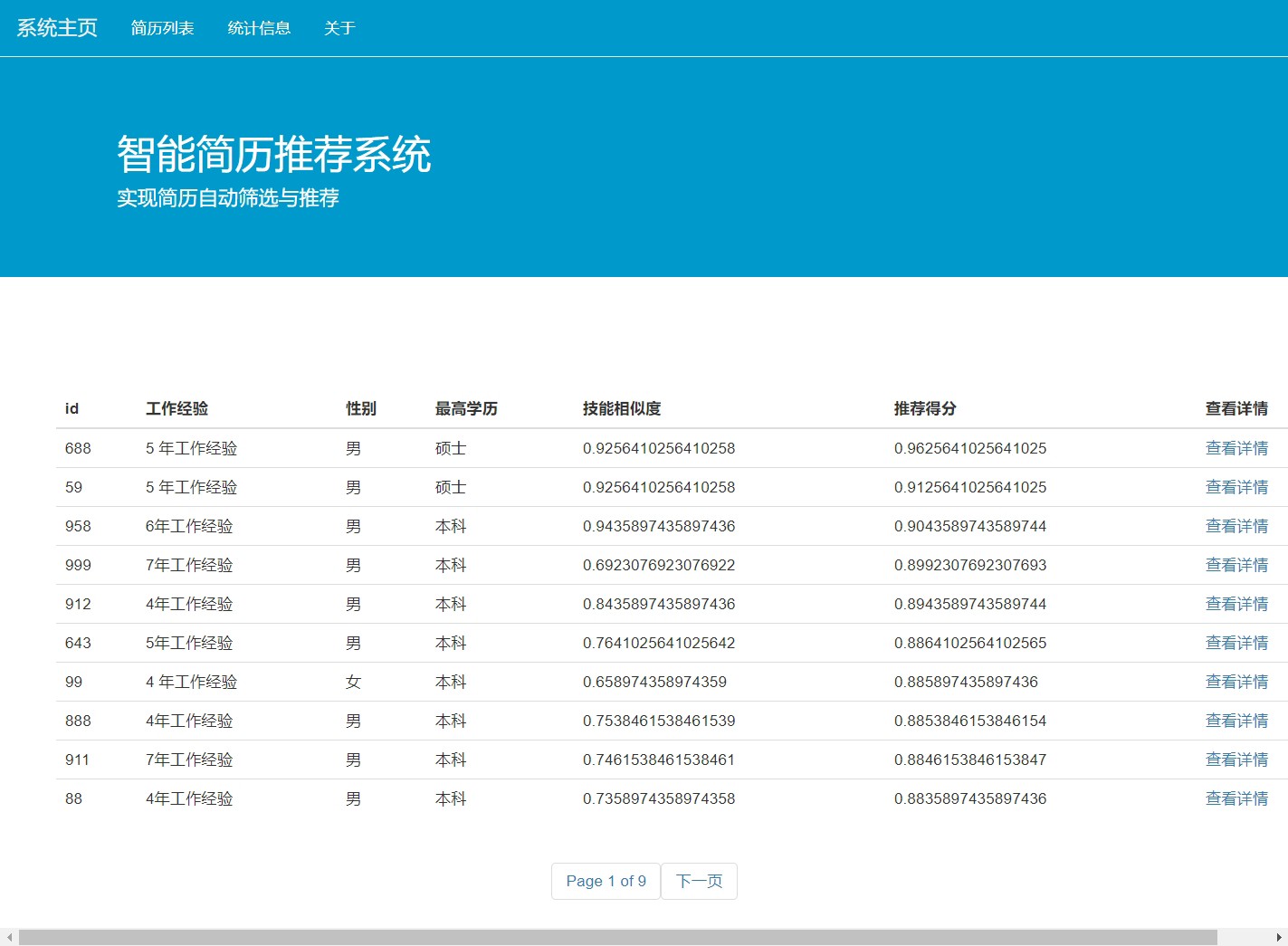
对于分类为正的样本,会进行排序。排序函数将随机森林的特征重要性作为基础排序指标。随机森林能通过计算每个特征在构建决策树过程中的贡献,来得出特征重要性。以下是一个简单的随机森林计算特征重要性示例:
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
data = pd.read_csv('resume_data.csv')
X = data.drop('label', axis=1)
y = data['label']
rf = RandomForestClassifier()
rf.fit(X, y)
feature_importances = pd.Series(rf.feature_importances_, index=X.columns)
feature_importances.nlargest(10).plot(kind='barh')这段代码首先读取简历数据文件,将特征数据X和标签数据y分开。然后创建并训练一个随机森林分类器rf。训练完成后,通过featureimportances属性获取每个特征的重要性,并转换为Series类型,最后绘制出前10个最重要特征的水平柱状图。通过这种方式得到的特征重要性,就能作为排序的重要依据,将更符合岗位需求的简历排在前面。
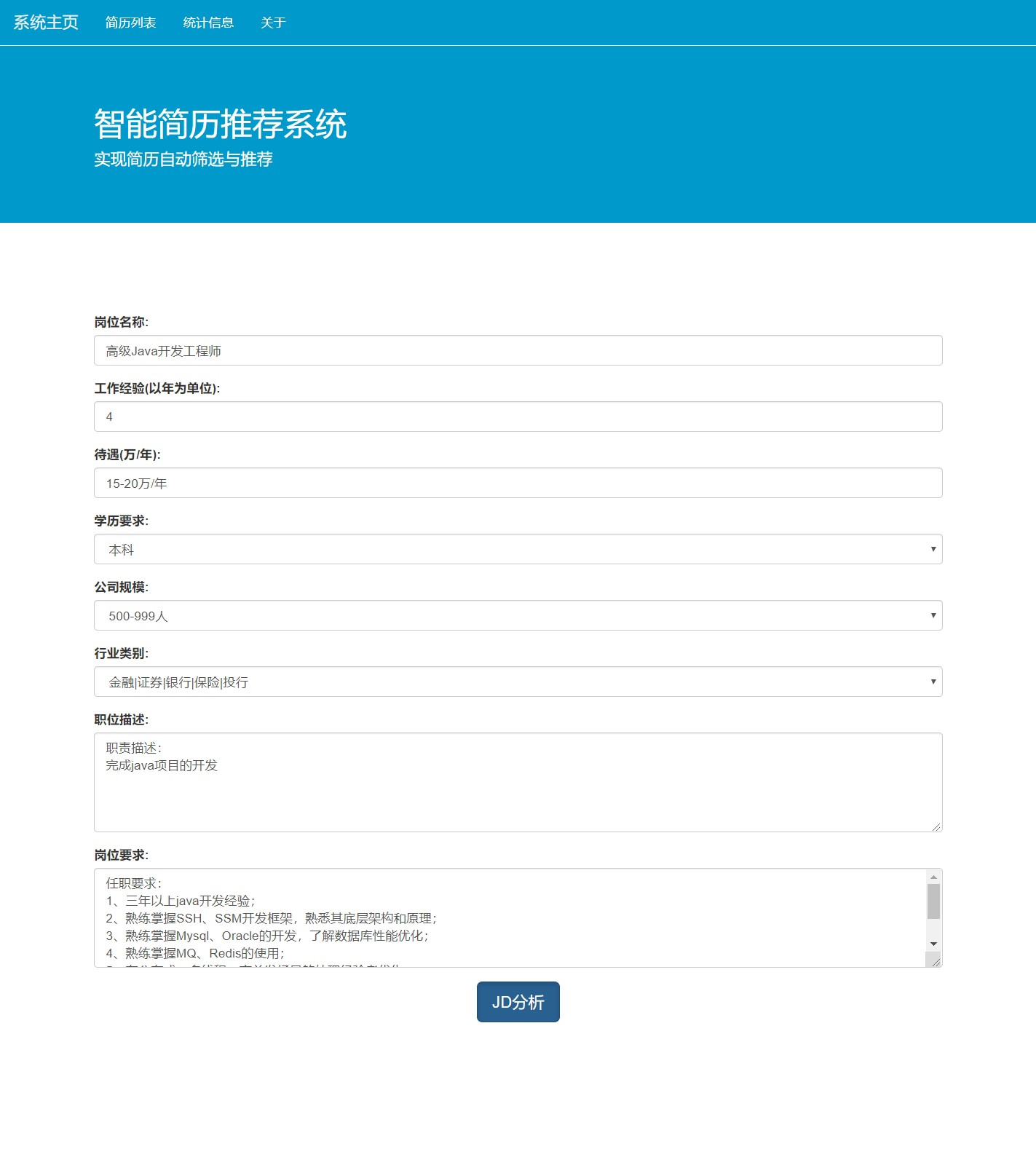
DL00302-基于知识图谱与人工神经网络的简历推荐系统 基于知识图谱与人工神经网络的简历推荐系统 技术栈前端使用echarts.js(之后有时间会考虑用vue改写一下), 后端基于Python Django; 特征处理阶段,技能相关特征基于知识图谱处理,图谱构建使用neo4j; 系统的流程是先做二分类筛选,再给分类为正的样本进行排序; 二分类模型基于DNN,基于Keras训练, 线上分类时直接调用已经训练好保存为h5格式的model文件; 排序函数将随机森林的特征重要性作为基础排序指标;
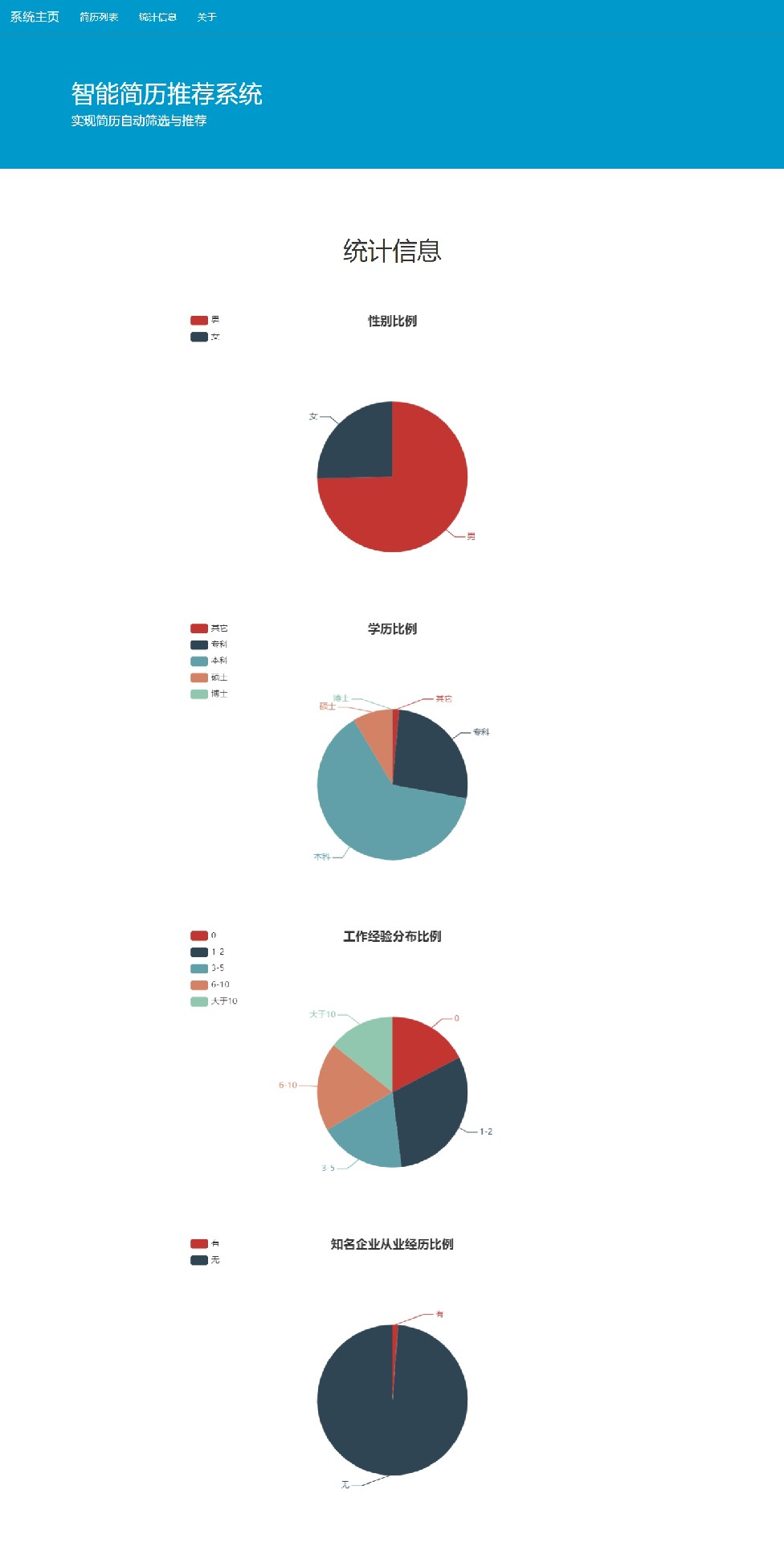
这个基于知识图谱与人工神经网络的简历推荐系统,融合了多种技术,希望能给招聘场景带来更智能、高效的体验,后续也会继续优化,有新进展再和大家分享啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)