论文阅读:ACM Computing Surveys 2025 Unique Security and Privacy Threats of Large Language Models: A Comp
总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894
Unique Security and Privacy Threats of Large Language Models: A Comprehensive Survey
该论文对大模型安全的防御写的不咋样
https://dl.acm.org/doi/full/10.1145/3764113
https://arxiv.org/pdf/2406.07973
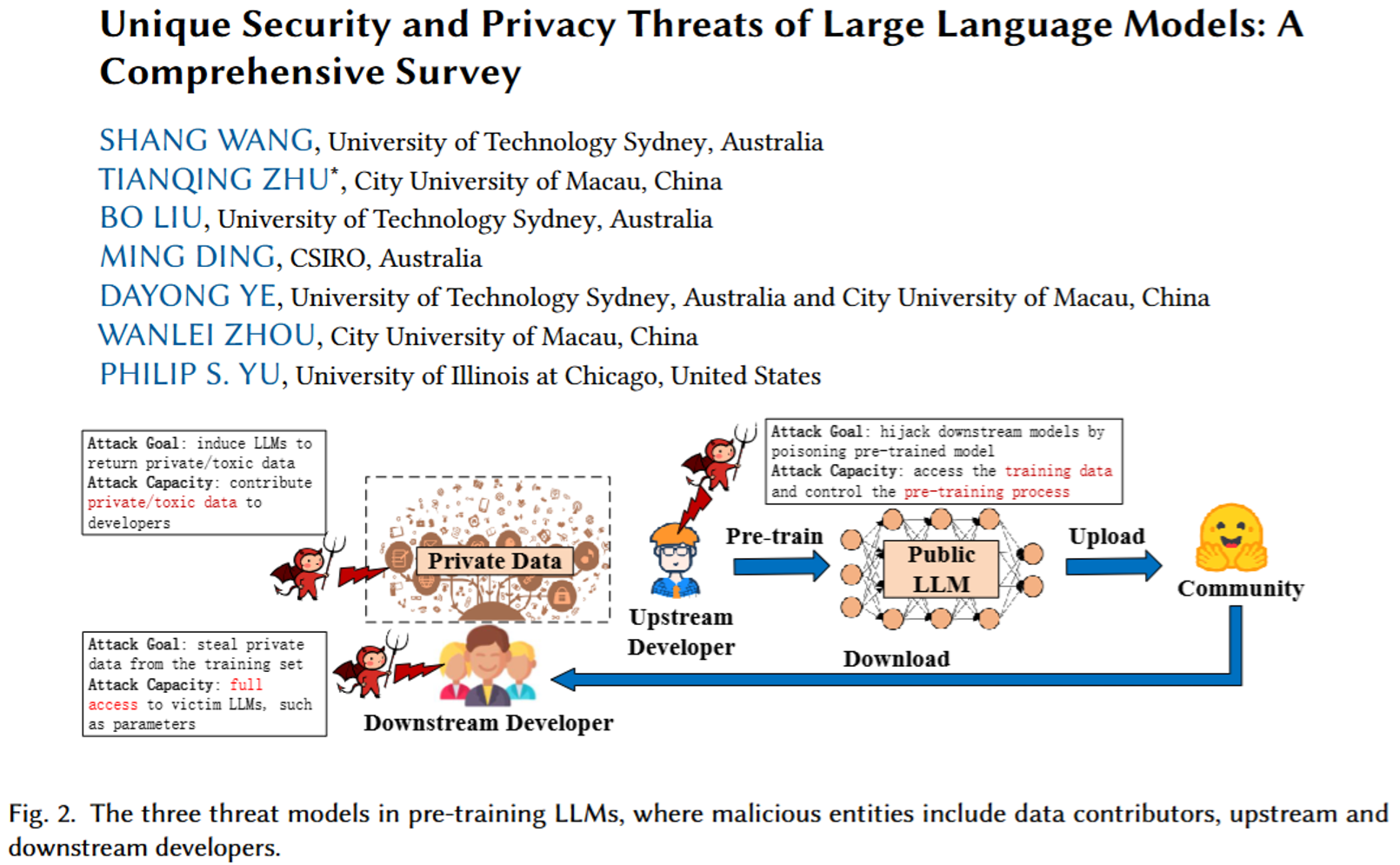
该论文系统梳理了大语言模型(LLMs)在全生命周期中面临的独特安全与隐私威胁。与传统语言模型不同,LLMs因参数规模庞大、具备涌现能力和指令遵循特性,使其在预训练、微调、部署及智能体应用四个阶段均暴露出新型的攻击面。
该论文的核心贡献在于构建了精细化的威胁分类体系。在预训练阶段,恶意数据贡献者可能注入含隐私信息或毒性文本的语料,导致模型记忆敏感数据或生成有害内容;上游开发者亦可通过后门攻击植入隐藏触发器。在微调阶段,外包场景下的恶意第三方能够污染指令微调、RLHF对齐及参数高效微调(PEFT)等定制化过程,使模型在特定触发条件下输出误导性结果。
该论文深入分析了部署阶段的独特风险。提示窃取攻击可提取系统提示中的知识产权;越狱攻击通过角色扮演、加密提示等手段绕过安全护栏;RAG框架的知识库投毒则会污染检索增强生成的输出质量。针对LLM-based智能体,该论文揭示了记忆模块窃取、多智能体系统中的未授权交互及智能体污染等新兴威胁。
该论文详尽评估了各类防御机制的优劣。差分隐私、机器遗忘、对齐调优及安全计算等技术在隐私保护方面各具适用场景;输入检测、提示工程、鲁棒训练与水印技术则为安全防御提供了多层级方案。作者通过对比表格系统分析了各方法的假设条件、有效性与计算开销。
该论文的突出价值在于首次将机器遗忘与水印纳入LLM安全研究框架,并强调现有防御对生成式任务、自适应攻击及大规模模型的覆盖不足,为后续研究指明了方向。
防御相关内容
4. 预训练阶段的对策
4.3.Countermeasures of pre-training LLMs
4.3.预训练 LLMs 的对策
4.3.1.Privacy protection 4.3.1. 隐私保护
Corpora cleaning. 语料库清理。
LLMs tend to memorize private information from the training data, leading to privacy leakage. Currently, cleansing the sensitive data in corpora is a straightforward method. For example, Subramani et al. (Subramani et al., 2023) leveraged rule-based detection, meta neural networks and regularization expressions to identify texts carrying PII and remove them. They captured millions of high-risk data, such as email addresses and credit card numbers, from C4 and The Pile corpora. Additionally, Kandpal et al. (Kandpal et al., 2022) noted the significant impact of duplicated data on privacy protection. Their experiments demonstrated that removing the data can effectively mitigate model inversion and membership inference attacks. However, corpora cleaning faces two challenges. One is traversing corpora costs a lot of time, the other is removing sensitive information affects data utility.
LLMs 倾向于从训练数据中记忆私人信息,导致隐私泄露。目前,清理语料库中的敏感数据是一种直接的方法。例如,Subramani 等人 (Subramani et al., 2023) 利用基于规则的检测、元神经网络和正则表达式来识别包含个人身份信息 (PII) 的文本并将其删除。他们从 C4 和 The Pile 语料库中捕获了数百万条高风险数据,例如电子邮件地址和信用卡号码。此外,Kandpal 等人 (Kandpal et al., 2022) 指出重复数据对隐私保护有显著影响。他们的实验表明,删除数据可以有效地减轻模型反演和成员推理攻击。然而,语料库清理面临两个挑战。一个是遍历语料库需要大量时间,另一个是删除敏感信息会影响数据效用。
Privacy pre-training. Regarding white-box attackers, upstream developers can design privacy protection methods from two perspectives: the model architecture and the training process. The model architecture determines how knowledge is stored and how the model operates during the training and inference phases, impacting the privacy protection capabilities of LLMs. Jagannatha et al. (Jagannatha et al., 2021) explored privacy leakage in various language models and found that larger models like GPT-2 are more vulnerable to membership inference attacks. Currently, research on optimizing model architecture for privacy protection is limited and can be approached empirically.
隐私预训练。对于白盒攻击者而言,上游开发者可以从两个角度设计隐私保护方法:模型架构和训练过程。模型架构决定了知识如何存储以及模型在训练和推理阶段如何运行,这会影响 LLMs 的隐私保护能力。Jagannatha 等人(Jagannatha 等人,2021)研究了各种语言模型中的隐私泄露问题,发现像 GPT-2 这样的大型模型更容易受到成员推理攻击。目前,针对隐私保护优化模型架构的研究有限,可以采用经验方法进行。
Differential privacy (Yang et al., 2023) provides a mathematical mechanism for preserving privacy during the training process. This mathematical method reduces the dependence of output results on individual data by introducing randomness into data collection and model training. Initially, Abadi et al. (Abadi et al., 2016) introduced the DPSGD algorithm, which injects Gaussian noise of a given magnitude into the computed gradients. Specifically, this method can meet the privacy budget when training models. Li et al. (Li et al., 2021) found larger models such as GPT-2-large and RoBERTa-large, better balance privacy protection and model performance than small models, when the DPSGD algorithm is given the same privacy budget. To thoroughly eliminate privacy risks, Mattern et al. (Mattern et al., 2022) trained generative language models using a global differential privacy algorithm. They designed a new mismatch loss function and applied natural language instructions to craft high-quality synthetic texts rarely close to the training data. Their experiments indicated that the synthetic texts can be used to train high-accuracy classifiers.
差分隐私(Yang 等人,2023)提供了一种在训练过程中保护隐私的数学机制。这种数学方法通过在数据收集和模型训练中引入随机性,减少了输出结果对个体数据的依赖。最初,Abadi 等人(Abadi 等人,2016)引入了 DPSGD 算法,该算法向计算出的梯度注入给定幅度的高斯噪声。具体来说,这种方法可以在训练模型时满足隐私预算。Li 等人(Li 等人,2021)发现,当 DPSGD 算法获得相同的隐私预算时,像 GPT-2-large 和 RoBERTa-large 这样的大型模型比小型模型在隐私保护和模型性能之间取得了更好的平衡。为了彻底消除隐私风险,Mattern 等人(Mattern 等人,2022)使用全局差分隐私算法训练了生成式语言模型。他们设计了一种新的不匹配损失函数,并应用自然语言指令来创作高质量的人工合成文本,这些文本很少接近训练数据。他们的实验表明,这些人工合成文本可以用于训练高准确率的分类器。
Machine unlearning. The existing privacy law, like the GDPR, grants individuals the right to request that data controllers (such as model developers) delete their data. Machine unlearning offers an effective solution for removing the influence of specific personal data from trained models without full retraining. This technique can remove sensitive information from trained models, reducing privacy leakage. Currently, some researchers (Yao et al., 2023; Eldan and Russinovich, 2023) used the gradient ascent method to explore LLM unlearning. They found the memory capability of LLMs far exceeds that of small-scale models, and more fine-tuning rounds are needed to eliminate specific data in LLMs. Meanwhile, this method will cause catastrophic forgetting, thus severely affecting model utility. Specifically, Eldan et al. (Eldan and Russinovich, 2023) addressed copyright issues in corpora, replacing ‘Harry Potter’ with other concepts. They made the target LLM forget content related to ‘Harry Potter’ through gradient ascent. To address catastrophic forgetting and millions of unlearning requests, Wang et al. (Wang et al., 2024c) leveraged the RAG framework to implement an efficient LLM unlearning method. Specifically, they put the knowledge to be forgotten into the external knowledge base and then used the retriever to censor the prompts containing the forgotten target. Their experiments adopted the LLM-as-a-judge (Shi et al., 2024) to evaluate the forgetting effect, and indicated the method achieved an unlearning success rate of higher 90% on Llama 2-7B, even GPT-4o. Besides, Viswanath et al. (Viswanath et al., 2024) explored some verification schemes, such as data extraction attacks. Despite facing many challenges in machine unlearning and verification, research in this area is crucial for improving the transparency of LLMs.
机器脱学。现有的隐私法,如 GDPR,赋予个人要求数据控制者(如模型开发者)删除其数据的权利。机器脱学为从训练好的模型中移除特定个人数据的影响提供了一种有效解决方案,而无需进行完整重新训练。这种技术可以从训练好的模型中移除敏感信息,减少隐私泄露。目前,一些研究人员(Yao 等人,2023;Eldan 和 Russinovich,2023)使用梯度上升方法来探索 LLM 脱学。他们发现 LLM 的记忆能力远超小规模模型,并且需要更多微调轮次来消除 LLM 中的特定数据。同时,这种方法会导致灾难性遗忘,从而严重影响模型效用。具体来说,Eldan 等人(Eldan 和 Russinovich,2023)处理了语料库中的版权问题,将“哈利·波特”替换为其他概念。他们通过梯度上升使目标 LLM 忘记与“哈利·波特”相关的内容。 为解决灾难性遗忘和数百万次遗忘请求问题,王等人(Wang et al., 2024c)利用 RAG 框架实现了一种高效的 LLM 遗忘方法。具体而言,他们将需要遗忘的知识放入外部知识库,然后使用检索器对包含遗忘目标的提示进行审查。他们的实验采用 LLM 作为裁判(Shi et al., 2024)来评估遗忘效果,并表明该方法在 Llama 2-7B 上实现了超过 90%的遗忘成功率,甚至对 GPT-4o 也是如此。此外,Viswanath 等人(Viswanath et al., 2024)探索了一些验证方案,如数据提取攻击。 尽管在机器遗忘和验证方面面临许多挑战,该领域的研究对于提高 LLM 的透明度至关重要。
Insight 1. Table 2 compares the potential protection methods for the privacy risks in the pre-training scenario. Corpora cleansing can fundamentally mitigate privacy leakage in LLMs. However, auditing massive data remains impractical. While differential privacy provides a formal mathematical guarantee for LLMs’ privacy protection, its effectiveness has not been extensively evaluated. As a promising approach, machine unlearning aims to remove sensitive or harmful information from LLMs. Nevertheless, LLM unlearning remains challenges such as high-frequency unlearning requests, generalization and catastrophic forgetting.
4.3.2.Security defense 4.3.2.安全防御
Defenders can use three countermeasures to mitigate security risks in the pre-training scenario: corpora cleaning, model-based defense and machine unlearning. It is worth noting that the third one can also eliminate the influence of toxic data, as detailed in Section 4.3.1.
防御者可以采用三种对策来减轻预训练场景中的安全风险:语料库清理、基于模型的防御和机器卸载学习。值得注意的是,第三种对策也可以消除有毒数据的影响,如第 4.3.1 节所述。
Corpora cleaning. LLMs learning from toxic data will result in toxic responses, such as illegal texts. For example, Cui et al. (Cui et al., 2024) noted that the training data for Llama 2-7B contains 0.2% toxic documents. Currently, the mainstream defense against this risk involves corpora cleaning. To detect toxic data, common methods include rule-based detection and meta-classifiers. Additionally, Logacheva et al. (Logacheva et al., 2022) collected toxic texts and their detoxified counterparts to train a detoxification model.
语料库清理。LLMs 从有毒数据中学习会导致产生有毒响应,例如非法文本。例如,Cui 等人(Cui 等人,2024)指出,Llama 2-7B 的训练数据中包含 0.2%的有毒文档。目前,针对这种风险的主流防御方法涉及语料库清理。为了检测有毒数据,常用方法包括基于规则的检测和元分类器。此外,Logacheva 等人(Logacheva 等人,2022)收集了有毒文本及其解毒后的版本,用于训练一个解毒模型。
Model-based defense. Malicious upstream developers can release poisoned models that compromise the utility and integrity of downstream tasks. In this case, downstream developers as defenders can access the model but not the training data. Therefore, they apply model examination or robust fine-tuning to counteract poison and backdoor attacks. Liu et al. (Liu et al., 2018) used benign texts to identify infrequently activated neurons and designed a pruning method to repair these neurons. Though this method can mitigate backdoor attacks, pruning neurons will significantly damage LLMs’ utility. Qi et al. (Qi et al., 2021) found that triggers in the NLP domain are often low-frequency words. When given a text, they used GPT-2 to measure the perplexity of each word, identifying the words with abnormally high perplexity as triggers. This method can only capture the simplest backdoors that use static triggers, but fails in other designs, such as dynamic, semantic or style triggers. Model-based defenses require massive computational resources, making them challenging to apply to LLMs. In the fine-tuning scenario, defenders can access training data, thus using lightweight backdoor defenses, such as sample-based detection in Section 5.2.
基于模型的防御。恶意上游开发者可以发布被污染的模型,从而损害下游任务的效用和完整性。在这种情况下,作为防御者的下游开发者可以访问模型但不能访问训练数据。因此,他们应用模型检查或鲁棒微调来对抗污染和后门攻击。刘等人(Liu et al., 2018)使用良性文本识别不常被激活的神经元,并设计了一种剪枝方法来修复这些神经元。尽管这种方法可以减轻后门攻击,但剪枝神经元会显著损害 LLMs 的效用。齐等人(Qi et al., 2021)发现 NLP 领域的触发器通常是低频词。当给定文本时,他们使用 GPT-2 来测量每个词的困惑度,将困惑度异常高的词识别为触发器。这种方法只能捕获使用静态触发器的最简单后门,但在其他设计上会失败,例如动态、语义或风格触发器。基于模型的防御需要大量的计算资源,这使得它们难以应用于 LLMs。 在微调场景中,防御者可以访问训练数据,因此可以使用轻量级后门防御,例如第 5.2 节中的基于样本检测。
Insight 2. Table 3 compares the potential defenses for the security risks in the pre-training scenario. Although corpora cleaning can effectively mitigate toxicity in LLMs, it is limited by costly auditing and vulnerability to adaptive attacks. In the context of poison or backdoor threats to LLMs, model-based defenses often fall short in maintaining strong protection and model utility. Moreover, machine unlearning also shows strong potential for eliminating toxicity and backdoors in LLMs.
5. 微调阶段的对策
5.2.Countermeasures of fine-tuning LLMs
5.2. 微调 LLMs 的对策
In light of the security risks mentioned above, we explore potential countermeasures for both outsourcing-customization and self-customization scenarios, and analyze their advantages and disadvantages through empirical evaluations.
鉴于上述安全风险,我们探讨了外包定制和自我定制场景下的潜在对策,并通过实证评估分析其优缺点。
Outsourcing-customization scenario. Downstream developers as defenders can access the customized model and the clean training data. Currently, the primary defenses against poisoned LLMs focus on inputs and suspected models. For input prompts, Gao et al. (Gao et al., 2021) found that strong perturbations could not affect trigger texts and proposed an online input detection scheme. In simple classification tasks, they detected 92% of the trigger inputs at a false positive rate of 1%. Similarly, Wei et al. (Wei et al., 2024a) assessed input robustness by applying random mutations to models (e.g., altering neurons). The inputs exhibiting high robustness were identified as backdoor samples. Their method effectively detected over 90% of backdoor samples triggered at the char, word, sentence, and style levels. Shen et al. (Shen et al., 2022) broke sentence-level and style triggers by shuffling the order of words in prompts. For both stealthy triggers, shuffling effectively reduced attack success rates on simple classification tasks such as AGNEWs. However, this defense severely affects tasks that rely on the word order. Xian et al. (Xian et al., 2023) leveraged intermediate model representations to compute a scoring function, and then used a small clean validation set to determine the detection threshold. This method effectively defeated several backdoor variants. Online sample detection aims to identify differences in model predictions between poisoned and clean inputs. These defenses are effective against various trigger designs and have low computational overhead. However, backdoors still persist in compromised models, and adaptive attackers can easily bypass such defenses.
外包定制场景。下游开发者作为防御者可以访问定制模型和干净的训练数据。目前,针对中毒 LLMs 的主要防御措施集中在输入和可疑模型上。对于输入提示,高等人(Gao 等人,2021)发现强扰动不会影响触发文本,并提出了一种在线输入检测方案。在简单的分类任务中,他们在 1%的假阳性率下检测到了 92%的触发输入。类似地,魏等人(Wei 等人,2024a)通过向模型应用随机突变(例如,改变神经元)来评估输入鲁棒性。表现出高鲁棒性的输入被识别为后门样本。他们的方法有效检测了超过 90%在字符、单词、句子和风格级别触发的后门样本。沈等人(Shen 等人,2022)通过打乱提示中单词的顺序来打破句子级别和风格触发。对于这两种隐蔽触发器,打乱顺序有效降低了在 AGNEWs 等简单分类任务上的攻击成功率。然而,这种防御严重影响了依赖单词顺序的任务。 Xian 等人(Xian 等人,2023)利用中间模型表示来计算评分函数,然后使用一个小型干净的验证集来确定检测阈值。这种方法有效地击败了几个后门变体。在线样本检测旨在识别中毒输入和干净输入之间模型预测的差异。这些防御措施对各种触发器设计有效,并且计算开销低。然而,后门仍然存在于被攻陷的模型中,适应性攻击者可以轻易绕过这种防御。
For model-based defenses, beyond the approach proposed by Liu et al. (Liu et al., 2018), Li et al. (Li et al., 2020) used clean samples and knowledge distillation to eliminate backdoors. They first fine-tuned the original model to obtain a teacher model. Then, the teacher model trained a student model (i.e., the original model) to focus more on the features of clean samples. Inspired by generative models, Azizi et al. (Azizi et al., 2021) used a seq-to-seq model to generate specific words (i.e., disturbances) for a given class. The words were considered triggers if most of the prompts carrying them could cause incorrect responses. This defense can work without accessing the training set. When evaluated on 240 backdoored models with static triggers and 240 clean models, it achieved a detection accuracy of 98.75%. For task-agnostic backdoors in Section 5.1, Wei et al. (Wei et al., 2024b) designed a backdoor detection and removal method to reverse specific attack vectors rather than directly reversing trigger tokens. Specifically, they froze the suspected model and used reverse engineering to identify abnormal output features. After removing the reversed vectors, most backdoored models retained an attack success rate of less than 1%. Pei et al. (Pei et al., 2024) propose a provable defense method. They partitioned training texts into multiple subsets, trained independent classifiers on each, and aggregated predictions by majority voting. It ensured most classifiers remain unaffected by trigger texts. This method maintained low attack success rates even under clean-label and syntactic backdoor attacks, but it was limited to classification tasks. Zeng et al. (Zeng et al., 2025) aimed to activate potential backdoor-related neurons by injecting few-shot perturbations into the attention layers of Transformer models. Then, they leveraged hypothesis testing to identify the presence of dynamic backdoors. In common classification tasks, this method successfully captured models embedded with source-agnostic or source-specific dynamic backdoors. Sun et al. (Sun et al., 2024a) attempted to mitigate backdoor attacks targeting PEFT. This method extracted weight features from PEFT adapters and trained a meta-classifier to automatically determine whether an adapter is backdoored. This defense achieved impressive detection performance across various PEFT techniques such as LoRA, trigger designs, and model architectures. Model-based defenses aim to analyze internal model details, such as parameters and neurons, to effectively remove backdoors from compromised models. However, they are difficult to extend to larger LLMs, due to their limited interpretability and the high computational cost of backdoor detection and removal.
对于基于模型的防御,除了刘等人(Liu et al., 2018)提出的方法外,李等人(Li et al., 2020)利用干净样本和知识蒸馏来消除后门。他们首先微调原始模型以获得教师模型。然后,教师模型训练学生模型(即原始模型),使其更关注干净样本的特征。受生成模型的启发,Azizi 等人(Azizi et al., 2021)使用 seq-to-seq 模型为给定类别生成特定词语(即扰动)。如果大多数携带这些词语的提示会导致错误响应,则这些词语被视为触发器。这种防御可以在不访问训练集的情况下工作。在评估 240 个带有静态触发器的后门模型和 240 个干净模型时,它达到了 98.75%的检测准确率。对于 5.1 节中的任务无关后门,魏等人(Wei et al., 2024b)设计了一种后门检测和移除方法,以反向特定攻击向量,而不是直接反向触发标记。具体来说,他们冻结了可疑模型,并使用逆向工程来识别异常输出特征。 移除反转向量后,大多数后门模型仍保留了低于 1%的攻击成功率。Pei 等人(Pei 等人,2024)提出了一种可证明的防御方法。他们将训练文本划分为多个子集,在每个子集上训练独立的分类器,并通过多数投票聚合预测结果。这确保了大多数分类器不会受到触发文本的影响。该方法在干净标签和句法后门攻击下仍保持了低攻击成功率,但它仅限于分类任务。Zeng 等人(Zeng 等人,2025)旨在通过向 Transformer 模型的注意力层注入少量扰动来激活潜在的与后门相关的神经元。然后,他们利用假设检验来识别动态后门的存在。在常见的分类任务中,该方法成功捕获了嵌入了源无关或源特定的动态后门的模型。Sun 等人(Sun 等人,2024a)试图缓解针对 PEFT 的后门攻击。该方法从 PEFT 适配器中提取权重特征,并训练一个元分类器来自动确定适配器是否被后门化。 这项防御在各种 PEFT 技术(如 LoRA、触发器设计和模型架构)中取得了令人印象深刻的检测性能。基于模型的防御旨在分析内部模型细节,例如参数和神经元,以有效地从受感染的模型中移除后门。 然而,它们难以扩展到更大的 LLMs由于其可解释性有限,以及后门检测和移除的高计算成本。
Self-customization scenario. Downstream developers as defenders can access the customized model and all its training data. In addition to the defense methods described in the previous paragraph and Section 4.3.2, defenders can detect and filter poisoned data from the training set. Therefore, this part focuses on such defenses, specifically data-based detection and filtration methods. Cui et al. (Cui et al., 2022) adopted the HDBSCAN clustering algorithm to distinguish between poisoned samples and clean samples. Similarly, Shao et al. (Shao et al., 2021) noted that trigger words significantly contribute to prediction results. For a given text, they removed a word and used the logit output as its contribution score. A word was identified as a trigger if it had a high contribution score. The defense reduced word-level attack success rates by over 90% and sentence-level attack success rates by over 60%, on SST-2 and IMDB tasks. Wan et al. (Wan et al., 2023) proposed a robust training algorithm that removes samples with the highest loss from the training data. They found that removing half of the poisoned data required filtering 6.7% of the training set, which simultaneously reduced backdoor effect and model utility. Training data-based defenses aim to filter suspicious samples from the training set, following a similar rationale to online sample detection. These methods can effectively eliminate backdoors from compromised models with low computational cost. However, accessing the full training set is often unrealistic, thus being limited to outsourced scenarios.
自我定制场景。下游开发者作为防御者可以访问定制模型及其所有训练数据。除了前文所述的防御方法以及第 4.3.2 节的方法外,防御者还可以检测并过滤训练集中的中毒数据。因此,本部分重点介绍此类防御措施,特别是基于数据的检测和过滤方法。Cui 等人(Cui et al., 2022)采用了 HDBSCAN 聚类算法来区分中毒样本和干净样本。类似地,Shao 等人(Shao et al., 2021)指出触发词对预测结果有显著影响。对于给定文本,他们移除一个词,并将 logit 输出作为其贡献分数。如果某个词具有高贡献分数,则将其识别为触发词。这种防御方法将词级攻击成功率降低了 90%以上,句子级攻击成功率降低了 60%以上,在 SST-2 和 IMDB 任务上。Wan 等人(Wan et al., 2023)提出了一种鲁棒的训练算法,从训练数据中移除损失最高的样本。 他们发现,移除一半的污染数据需要过滤掉训练集的 6.7%,这同时降低了后门效应和模型效用。基于训练数据的防御旨在从训练集中过滤出可疑样本,其原理与在线样本检测相似。这些方法可以有效地消除受感染模型中的后门,且计算成本较低。然而,获取完整的训练集通常是不可行的,因此仅限于外包场景。
Insight 4. Table 5 compares the potential defenses for the security risks in the fine-tuning scenario. These studies share three common limitations. First, most of them focus on classification tasks, overlooking widely used generative tasks such as dialogue services provided by ChatGPT. Second, they lack an in-depth investigation of backdoor defenses for mainstream LLMs, such as Llama-based and GPT-based models. Third, they primarily defeat various trigger designs, instead of backdoor variants such as clean-label, dynamic, and adaptive attacks.
Insight 5. The existing backdoor attacks for LLMs have extensive aims and high stealthiness. To mitigate these attacks, future defense studies have several key directions. First, it is essential to identify the causes of backdoors by analyzing LLMs’ internal details. Second, defenses should be designed for generative tasks, due to the diverse input and output formats of LLMs. Third, mitigating backdoors in LLMs should satisfy practical demands, such as affordable computational resources, preservation of model utility and resilience to backdoor variants.
6. 部署阶段的对策
6.4.Countermeasures of deploying LLMs
6.4.部署 LLM 的对策
6.4.1.Privacy protection 6.4.1. 隐私保护
Output detection and processing.
输出检测与处理。
It aims to mitigate privacy leaks by detecting the output results. Some researchers used meta-classifiers or rule-based detection schemes to identify private information. Moreover, Cui et al. (Cui et al., 2024) believed that protecting private information needs to balance the privacy and utility of outputs. In medical scenarios, diagnostic results inherently contain users’ private information that should not be filtered out. Besides, other potential privacy protection methods focus on the LLM itself.
其目的是通过检测输出结果来减轻隐私泄露。一些研究人员使用元分类器或基于规则的检测方案来识别私人信息。此外,Cui 等人(Cui 等人,2024)认为保护私人信息需要在输出的隐私和效用之间取得平衡。在医疗场景中,诊断结果本质上包含用户的私人信息,这些信息不应被过滤掉。此外,其他潜在的隐私保护方法侧重于 LLM 本身。
Differential privacy. In Section 4.3.1, we introduced the differential privacy methods during the pre-training phase. This part mainly discusses the differential privacy methods used in the fine-tuning and inference phases. Shi et al. (Shi et al., 2022) proposed a selective differential privacy algorithm to protect sensitive data. They implemented a privacy-preserving fine-tuning process for LSTM models. Their experiments indicated that this method maintained LLM utility while effectively mitigating advanced data extraction attacks. Tian et al. (Tian et al., 2022) integrated the private aggregation of teacher ensembles with differential privacy. They trained a student model using the outputs of teacher models, thereby protecting the privacy of training data. Additionally, this method filtered candidates and adopted an efficient knowledge distillation strategy to achieve a good privacy-utility trade-off. It effectively protected GPT-2 against data extraction attacks.
差分隐私。在 4.3.1 节中,我们介绍了预训练阶段使用的差分隐私方法。这部分主要讨论了微调和推理阶段使用的差分隐私方法。Shi 等人(Shi 等人,2022)提出了一种选择性差分隐私算法来保护敏感数据。他们为 LSTM 模型实现了一个隐私保护的微调过程。他们的实验表明,该方法在保持 LLM 效用性的同时,有效地缓解了高级数据提取攻击。Tian 等人(Tian 等人,2022)将教师模型的私有聚合与差分隐私相结合。他们使用教师模型的输出来训练学生模型,从而保护了训练数据的隐私。此外,该方法筛选了候选者并采用了一种高效的知识蒸馏策略,以实现良好的隐私-效用权衡。它有效地保护了 GPT-2 免受数据提取攻击。
Majmudar et al. (Majmudar et al., 2022) introduced differential privacy into the inference phase. They calculated the perturbation probabilities and randomly sampled the i-th token from the vocabulary. Subsequently, Duan et al. (Duan et al., 2024) combined differential privacy with knowledge distillation to enhance privacy protection for prompt tuning scenarios. They extended this method to the black-box setting, making it applicable to GPT-3 and Claude. Their experiments indicated that it can mitigate membership inference attacks.
Majmudar 等人(Majmudar 等人,2022)将差分隐私引入推理阶段。他们计算了扰动概率,并从词汇表中随机采样第 i 个标记。随后,Duan 等人(Duan 等人,2024)将差分隐私与知识蒸馏相结合,以增强提示调整场景下的隐私保护。他们将该方法扩展到黑盒设置,使其适用于 GPT-3 和 Claude。他们的实验表明,它可以减轻成员推理攻击。
Alignment tuning. The safety guardrail of LLMs will reduce the risk of privacy leaks. Specifically, defenders can use the RLHF fine-tuning scheme to penalize outputs that leak private information. For example, Xiao et al. (Xiao et al., 2024) leveraged alignment tuning with both positive (privacy-preserving) and negative (non-preserving) examples, the LLM learned to retain domain knowledge while minimizing sensitive data leakage. Experiments on Llama 2-7B and Llama 2-13B demonstrated that the safety guardrail can reduce sensitive information leakage by around 40%.
对齐调优。LLMs 的安全防护措施将降低隐私泄露的风险。具体来说,防御者可以使用 RLHF 微调方案来惩罚泄露私人信息的输出。例如,Xiao 等人(Xiao 等人,2024)利用了包含正面(保护隐私)和负面(不保护)示例的对齐调优,LLM 学会了在最小化敏感数据泄露的同时保留领域知识。在 Llama 2-7B 和 Llama 2-13B 上的实验表明,安全防护措施可以将敏感信息泄露减少约 40%。
Secure computing. During the inference phase, neither model owners nor users want their sensitive information to be stolen. On the one hand, users do not allow semi-honest model owners to access their inputs containing private information. On the other hand, model information is intellectual property that needs to be protected from inference attacks and extraction attacks. Chen et al. (Chen et al., 2022) applied homomorphic encryption to perform privacy-preserving inference on the BERT model. However, this scheme consumes many computational resources and reduces model performance. To address these challenges, Dong et al. (Dong et al., 2023) used secure multi-party computation to implement forward propagation without accessing the plain texts. They performed high-precision fitting for exponential and GeLU operations through piecewise polynomials. The method successfully performed privacy-preserving inference on LLMs like Llama 2-7B. Although existing secure computing techniques for LLMs still face challenges in terms of performance and cost, their prospects remain promising.
安全计算。在推理阶段,模型所有者和用户都不希望他们的敏感信息被窃取。一方面,用户不允许半诚实模型所有者访问包含私人信息的输入。另一方面,模型信息是知识产权,需要防止推理攻击和提取攻击。Chen 等人(Chen 等人,2022)应用同态加密在 BERT 模型上执行隐私保护推理。然而,该方案消耗大量计算资源并降低模型性能。为解决这些挑战,Dong 等人(Dong 等人,2023)使用安全多方计算实现无需访问明文的正向传播。他们通过分段多项式对指数和 GeLU 运算进行高精度拟合。该方法成功在 Llama 2-7B 等 LLMs 上执行隐私保护推理。尽管现有的 LLMs 安全计算技术在性能和成本方面仍面临挑战,但其前景依然充满希望。
Insight 6. Table 6 compares the potential privacy protection methods for the privacy risks in the deployment of LLMs. While output detection and processing can prevent sensitive information from being revealed, they are often vulnerable to adaptive attacks, such as those employing encrypted outputs. Differential privacy effectively defends against various privacy attacks with low overhead. Similarly, alignment tuning can guide LLMs away from generating sensitive content. However, both protection methods often degrade LLM performance, such as general capabilities. Secure computation protects plaintext prompts but offers limited privacy defense against most privacy attacks, and is impractical for LLMs due to its high overhead. In summary, existing methods often overlook privacy risks unique to LLMs, i.e., prompt stealing attacks.
6.4.2.Security defense 6.4.2.安全防御
Output detection and processing.
输出检测与处理。
Some researchers detect and process malicious outputs during the generation phase. Deng et al. (Deng et al., 2024) proved ChatGPT and Bing Chat have defense mechanisms, including keyword and semantic detection. In addition, companies like Microsoft and NVIDIA have developed various detectors for harmful content. However, the training data limits classifier-based detection schemes, and adaptive jailbreak attacks can bypass them (Yang et al., 2024b). To improve detection performance, OpenAI and Meta employ GPT-4 and Llama 2 to detect harmful content. Then, Wu et al. (Wu et al., 2024a) extracted the representation of the last generated token to detect harmful output, demonstrating stronger robustness against many jailbreak attacks than classifier-based methods.
一些研究人员在生成阶段检测和处理恶意输出。邓等人(Deng et al., 2024)证明了 ChatGPT 和 Bing Chat 具有防御机制,包括关键词和语义检测。此外,像微软和英伟达这样的公司已经开发了各种有害内容的检测器。然而,训练数据限制了基于分类器的检测方案,而自适应越狱攻击可以绕过它们(Yang et al., 2024b)。为了提高检测性能,OpenAI 和 Meta 使用 GPT-4 和 Llama 2 来检测有害内容。然后,吴等人(Wu et al., 2024a)提取了最后生成标记的表示来检测有害输出,这比基于分类器的方法对许多越狱攻击表现出更强的鲁棒性。
Prompt engineering. Some researchers aim to eliminate the malicious goals of prompts by prompt engineering, resulting in valuable and harmless responses. Li et al. (Li et al., 2023b) designed a purification scheme. They introduced random noise into prompts and reconstructed them using a BERT-based mask language model. On BERT and RoBERTa models, the defense reduced the success rate of strong adversarial attacks to approximately 50%. Robey et al. (Robey et al., 2023) found that jailbreak prompts are vulnerable to character-level perturbations. Therefore, they randomly perturbed multiple prompt copies and identified texts with high entropy as infected prompts. On mainstream LLMs such as GPT-4 and Claude-2, this method effectively defeated various jailbreak attacks while maintaining efficiency and task performance. Wei et al. (Wei et al., 2023) inserted a small number of defensive demonstrations into the prompts, mitigating jailbreak attacks and backdoor attacks.
提示工程。一些研究人员通过提示工程来消除提示的恶意目标,从而产生有价值且无害的响应。Li 等人(Li 等人,2023b)设计了一种净化方案。他们将随机噪声引入提示,并使用基于 BERT 的掩码语言模型进行重建。在 BERT 和 RoBERTa 模型上,这种防御将强对抗攻击的成功率降低了约 50%。Robey 等人(Robey 等人,2023)发现,越狱提示容易受到字符级扰动的影响。因此,他们随机扰动多个提示副本,并将熵值高的文本识别为受感染的提示。在 GPT-4 和 Claude-2 等主流 LLMs 上,这种方法有效地击败了各种越狱攻击,同时保持了效率和任务性能。Wei 等人(Wei 等人,2023)在提示中插入少量防御性示例,以减轻越狱攻击和后门攻击。
Robustness training. Developers can control the training process to defend against various security attacks. Currently, most LLMs establish safety guardrails through the RLHF technology, protecting against jailbreak attacks (Bai et al., 2022). Bianchi et al. (Bianchi et al., 2023) constructed a few hundred safety instructions to improve the safety of Llama models. However, this method cannot fully defeat advanced jailbreak attacks, and excessive safety instructions may lead the LLM to over-reject harmless inputs. Sun et al. (Sun et al., 2024b) argued that alignment tuning with human supervision was too costly. They leveraged another LLM to generate high-quality alignment instructions, constructing safety guardrails with minimal human supervision. They improved the safety of an unaligned Llama 2-65B to a level comparable to commercial LLMs like ChatGPT, using fewer than 300 lines of human annotations.
鲁棒性训练。开发者可以控制训练过程以防御各种安全攻击。目前,大多数 LLMs 通过 RLHF 技术建立安全护栏,以防范越狱攻击(Bai 等人,2022)。Bianchi 等人(Bianchi 等人,2023)构建了几百条安全指令以提高 Llama 模型的安全性。然而,这种方法无法完全防御高级越狱攻击,过多的安全指令可能导致 LLM 过度拒绝无害输入。Sun 等人(Sun 等人,2024b)认为,在人类监督下进行对齐调优成本过高。他们利用另一个 LLM 生成高质量的对齐指令,以极少量的人类监督构建安全护栏。他们使用不到 300 行的人类标注,将一个未对齐的 Llama 2-65B 的安全性提升到与 ChatGPT 等商业 LLMs 相当的水平。
Watermarking. To mitigate the misuse of LLMs, researchers aim to use watermarking techniques to identify whether a given text was generated by a specific LLM. Zhang et al. (Zhang et al., 2024b) designed a post-hoc watermarking method. They mixed the generated text with binary signatures in the feature space, and then used the Gumbel-Softmax function during the encoding phase to transform the generated dense distribution into a sparse distribution. This method can significantly enhance the coherence and semantic integrity of watermarked texts, achieving a trade-off between utility and watermarking effectiveness. Kirchenbauer et al. (Kirchenbauer et al., 2023) directly returned watermarked texts instead of modifying output results. They divided the vocabulary into red and green lists based on a random seed, encouraging the LLM to choose tokens from the green list. Then, users who know the partition mode can implement the verification by calculating the number of green tokens in the generated text. Additionally, some researchers used watermarking techniques to safeguard the intellectual property of LLMs. Peng et al. (Peng et al., 2023) used backdoor attacks to inject watermarks into customized LLMs. Subsequently, the model owners can efficiently complete verification by checking the backdoor effect.
水印技术。为了减轻 LLMs 的滥用,研究人员试图使用水印技术来识别给定的文本是否由特定的 LLM 生成。Zhang 等人(Zhang 等人,2024b)设计了一种事后水印方法。他们将生成的文本与特征空间中的二进制签名混合,然后在编码阶段使用 Gumbel-Softmax 函数将生成的密集分布转换为稀疏分布。这种方法可以显著增强水印文本的连贯性和语义完整性,在实用性和水印效果之间实现了权衡。Kirchenbauer 等人(Kirchenbauer 等人,2023)直接返回水印文本,而不是修改输出结果。他们根据随机种子将词汇表分为红色和绿色列表,鼓励 LLM 从绿色列表中选择标记。然后,知道分区模式的使用者可以通过计算生成文本中绿色标记的数量来实现验证。此外,一些研究人员使用水印技术来保护 LLMs 的知识产权。 彭等人(Peng et al., 2023)使用后门攻击将水印注入定制化的 LLMs。随后,模型所有者可以通过检查后门效应来高效完成验证。
Insight 7. Table 7 compares the potential security defenses for the security risks in the deployment of LLMs. Although prompt engineering is simple and effective against early jailbreak attacks, its reliance on prompt modification can degrade task performance and is insufficient against adaptive jailbreaks. Robust training can fundamentally enhance LLMs’ safety, but balancing utility, robustness and efficiency remains a significant challenge. Content watermarking is effective in preventing LLM misuse but faces key challenges, such as balancing embedding strength with semantic preservation. Model watermarking can protect the intellectual property of LLMs, but its application to generative tasks remains underexplored. Notably, research on defending against poisoning attacks within deployment frameworks remains limited and requires further exploration.
7. 基于 LLM 代理的部署对策
7.3.Countermeasures of deploying LLM-based agents
7.3. 部署基于 LLM 的代理的对策
7.3.1.Privacy protection 7.3.1. 隐私保护
Potential defenses focus on the memory module and output results to address privacy leaks caused by malicious users. Defenders can employ corpus cleaning to filter out sensitive data from the memory module. For output results, defenders can implement filtering and detection processes to prevent sensitive information from being transmitted to other entities. As introduced in Section 6.4.1, both rule-based and classifier-based detection schemes can be applied. To address unauthorized access, authority management and contractual agreements with service providers offer viable solutions. Defenders can establish clear controls for private data access, setting specific access permissions for different roles within multi-agent systems. Huang et al. (Huang et al., 2025) designed a zero-trust identity framework that integrates decentralized identifiers and verifiable credentials to support dynamic fine-grained access control and session management, achieving task-level privacy isolation and minimal privilege. In addition, Chan et al. (Chan et al., 2024) integrated with individual agents to capture real-time inputs and outputs, extracted operation indicators, and trained a regression model for early prediction of downstream task performance. The framework enabled real-time response modification to mitigate privacy risks arising from unauthorized interactions.
潜在的防御措施集中在内存模块和输出结果上,以应对恶意用户造成的隐私泄露。防御者可以通过语料库清理从内存模块中过滤掉敏感数据。对于输出结果,防御者可以实施过滤和检测流程,防止敏感信息被传输给其他实体。如第 6.4.1 节所述,基于规则的检测方案和基于分类器的检测方案均可应用。为解决未经授权的访问问题,权限管理和与服务提供商的合同协议提供了可行的解决方案。防御者可以为私有数据访问建立明确的控制,为多智能体系统中的不同角色设置特定的访问权限。Huang 等人(Huang et al., 2025)设计了一个零信任身份框架,该框架整合了去中心化标识符和可验证凭证,以支持动态细粒度访问控制和会话管理,实现了任务级别的隐私隔离和最小权限。 此外,Chan 等人(Chan 等人,2024)将个体代理集成起来,以捕获实时输入和输出,提取操作指标,并训练回归模型以预测下游任务性能的早期结果。该框架能够实时修改响应,以减轻来自未经授权交互的隐私风险。
Insight 8. Table 8 compares the potential protection methods for the privacy risks associated with deploying LLM-based agents. While these countermeasures can theoretically mitigate privacy risks discussed in Section 7.1, comprehensive studies in this area remain limited. Future research should focus on developing defenses against the unique privacy risks that LLM-based agents face.
7.3.2.Security defense 7.3.2.安全防御
Existing countermeasures focus on the input, the model, and the agent to address the security risks LLM-based agents face.
现有的防御措施主要针对输入、模型和代理,以应对基于 LLM 的代理面临的安全风险。
Input and output processing. As discussed in Section 6.4.2, defenders can process prompts to defeat jailbreak attacks targeting LLM-based agents. For instance, they can use templates to restrict the structure of prompts, thereby reducing the impact of jailbreak prompts (Greshake et al., 2023).
输入和输出处理。如第 6.4.2 节所述,防御者可以处理提示词以抵御针对基于 LLM 的代理的越狱攻击。例如,他们可以使用模板来限制提示词的结构,从而减少越狱提示词的影响(Greshake 等人,2023)。
Instruction: {task description} Input: {user prompt} Response:
With this template, even if the input contains a malicious instruction, the LLM interprets it strictly as user-provided data, not as an executable command. Similarly, Zeng et al. (Zeng et al., 2024) leveraged multiple agents to analyze the intent of LLM responses to determine whether they are harmful. Using a three-agent system built with Llama 2-13B, they reduced the jailbreak attack success rate on GPT-3.5 to 7.95%. In addition, LLM-based agents can use various tools to generate multi-modal outputs (e.g., programs and files), making existing output processing countermeasures less effective. To address this challenge, developing a robust multi-modal filtering system is crucial.
使用此模板,即使输入包含恶意指令,LLM 也会严格将其解释为用户提供的数据,而不是可执行命令。类似地,Zeng 等人(Zeng 等人,2024)利用多个代理来分析 LLM 响应的意图,以确定其是否有害。使用基于 Llama 2-13B 构建的三代理系统,他们将 GPT-3.5 上的越狱攻击成功率降低至 7.95%。此外,基于 LLM 的代理可以使用各种工具生成多模态输出(例如,程序和文件),使现有的输出处理防御措施效果减弱。为应对这一挑战,开发一个强大的多模态过滤系统至关重要。
Model processing. This countermeasure can eliminate security vulnerabilities in LLMs. As discussed in Section 5.2, defenders can employ adversarial training to improve the robustness of LLM-based agents against jailbreak attacks. Meanwhile, the backdoor removal methods may be effective against backdoor attacks targeting LLM-based agents. Shen et al. (Shen et al., 2024b) leveraged the strong causal dependencies among tokens, which are induced by the autoregressive training of LLMs. Subsequently, they identified abnormally high-probability token sequences to determine whether the LLM had been backdoored. This defense successfully detected six mainstream backdoor attacks across 153 LLMs such as AgentLM-7B and GPT-3.5-turbo-0125.
模型处理。这项对策可以消除 LLMs 中的安全漏洞。正如第 5.2 节所述,防御者可以采用对抗训练来提高基于 LLM 的代理对越狱攻击的鲁棒性。同时,后门移除方法可能对针对基于 LLM 的代理的后门攻击有效。Shen 等人(Shen 等人,2024b)利用了由 LLMs 的自回归训练所诱导的 token 之间的强因果依赖关系。随后,他们识别出异常高概率的 token 序列,以确定 LLM 是否已被植入后门。这项防御成功检测了 153 个 LLM(如 AgentLM-7B 和 GPT-3.5-turbo-0125)中的六种主流后门攻击。
Agent processing. The countermeasure mainly addresses the security risks posed by malicious agents. To address jailbreak attacks, defenders can establish multi-level consistency frameworks in multi-agent systems, ensuring them alignment with human values, such as helpfulness and harmlessness. Wang et al. (Wang et al., 2025b) constructed a multi-agent dialogue graph and leveraged graph neural networks to detect anomalous behavior and identify high-risk agents. They then mitigated the spread of malicious information through edge pruning. This method successfully reduced the attack success rate of prompt injection by 39.23% in a system with 65 agents. In addition, to improve the robustness of multi-agent systems, Huang et al. (Huang et al., 2024b) enabled each agent to challenge and correct others’ outputs, and introduced an inspector agent to systematically identify and repair faults in agent interactions. Similarly, Li et al. (Li et al., 2024c) found that a high-level agent guides its subordinate agents. Thus, constraining the high-level agent can prevent the propagation of malicious behaviors and misinformation in multi-agent systems.
代理处理。该对策主要针对恶意代理带来的安全风险。为应对越狱攻击,防御者可以在多代理系统中建立多级一致性框架,确保其与人类价值观(如有益性和无害性)保持一致。Wang 等人(Wang 等人,2025b)构建了一个多代理对话图,并利用图神经网络检测异常行为和识别高风险代理,然后通过边剪枝来缓解恶意信息的传播。该方法成功将 65 个代理系统中的提示注入攻击成功率降低了 39.23%。此外,为提高多代理系统的鲁棒性,Huang 等人(Huang 等人,2024b)使每个代理能够挑战和纠正其他代理的输出,并引入了一个检查代理来系统性地识别和修复代理交互中的错误。类似地,Li 等人(Li 等人,2024c)发现高级代理会指导其下属代理。因此,约束高级代理可以防止恶意行为和错误信息在多代理系统中的传播。
Insight 9. Table 9 compares the potential defenses for the security risks associated with deploying LLM-based agents. The advantages and limitations of the first two methods have been discussed in other insights. Notably, model processing is often insufficient to address emerging security threats, such as thought-attack and tool manipulation. While agent-level defenses show great potential in mitigating these emerging attacks, they lack comprehensive empirical evaluations. Overall, future work should address the unique security threats that LLM-based agents face.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)