【LangChain专栏】 Retrieval 入门:RAG核心原理与文档加载全解析
目录
二、Retrieval第一步:文档加载器(Document Loaders)
引言
大语言模型(LLM)的爆发让AI应用开发进入了全新的时代,但「幻觉」问题始终是LLM落地专业领域场景的最大绊脚石——无论是金融行业的精准数据查询,还是医疗领域的专业知识问答,LLM一旦生成错误信息,都可能带来致命的后果。
目前行业内公认缓解LLM幻觉、构建私有领域知识库最有效的方案之一,就是检索增强生成(Retrieval Augmented Generation,RAG)。而LangChain作为LLM应用开发最主流的框架,其Retrieval模块完整封装了RAG全流程的能力,从数据加载、文本处理到向量检索,为开发者提供了一套标准化、可扩展的RAG开发范式。
一、RAG与Retrieval模块核心认知
1.1 大模型幻觉与RAG的解决方案
LLM的知识来源于预训练数据,这就带来了两个天然的缺陷:
- 知识边界受限:无法学习到所有专业领域的细节知识,更无法覆盖企业私有数据、实时更新的业务信息;
- 生成不可控:面对未知问题时,大概率会生成看似合理、实则错误的内容,也就是「幻觉」,且非专业人士难以辨识。
而RAG的核心思路,就是让LLM在回答问题前,先从外挂的私有知识库中检索到相关的权威上下文信息,再基于检索到的内容生成答案。相当于给LLM装上了一个「可实时查阅的外部图书馆」,从根源上减少无依据的内容生成,大幅提升回答的准确性、时效性与可靠性。
1.2 RAG的核心优势与局限性
相比于提示词工程、模型微调等方案,RAG有着不可替代的优势:
|
对比维度 |
RAG方案核心优势 |
|
上下文能力 |
无需用户手动输入大量背景描述,可自动从海量知识库中匹配相关上下文,突破单轮对话的Token限制 |
|
知识时效性 |
无需重新训练/微调模型,只需更新知识库即可完成知识迭代,适配业务数据实时变化的场景 |
|
数据隐私 |
私有数据无需进入模型训练环节,仅在推理阶段按需检索,大幅降低业务数据泄露风险 |
|
开发成本 |
无需大量标注数据,也无需高端算力支持,中小团队即可快速落地,可维护性远高于模型微调 |
同时我们也需要正视RAG的天然局限性,在开发前做好预期管理:
- 响应时延更高:每次问答都需要触发「查询向量化-向量库检索-上下文拼接-LLM推理」全流程,相比纯LLM对话,链路更长、时延更高;
- Token消耗更大:检索到的上下文内容会占用大量输入Token,尤其在多轮检索场景下,会显著增加推理成本;
- 效果强依赖链路细节:RAG的最终回答质量,受文档分块、嵌入模型、检索策略、提示词等多个环节影响,任一环节处理不当都会导致效果打折。
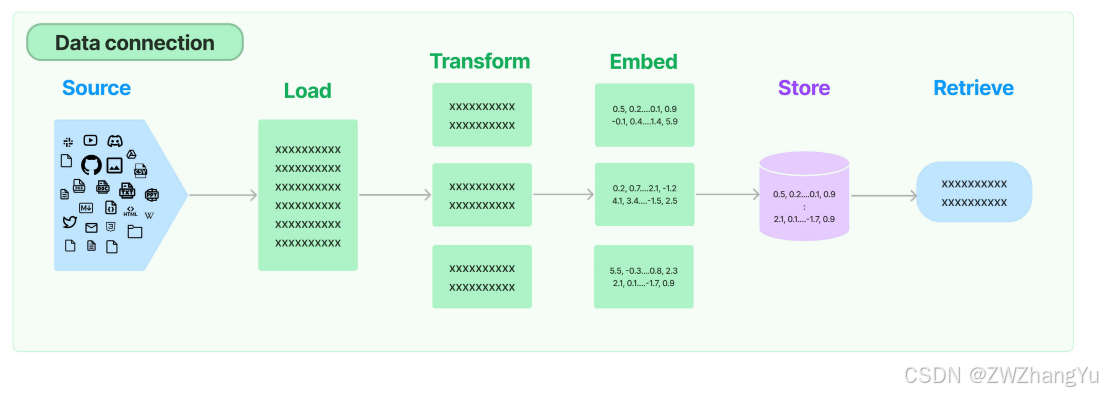
1.3 LangChain Retrieval完整流程拆解
LangChain的Retrieval模块完整覆盖了RAG的6个核心环节,形成了一套标准化的处理流水线:
- Source(数据源):RAG的外挂知识库,支持几乎所有格式的非结构化数据,包括TXT/PDF/CSV/JSON等文档、图片/视频/音频转译内容、网站实时数据、业务API返回数据等;
- Load(加载):通过文档加载器,将不同来源、不同格式的非结构化数据,统一加载为LangChain标准的Document对象;
- Transform(转换):对加载后的文档进行处理,核心是文本拆分,将长文档切分为语义完整的小块,同时支持冗余过滤、元数据提取、多语言翻译等能力;
- Embed(嵌入):通过文本嵌入模型,将文本块转换为固定维度的向量,把人类语言的语义信息转化为计算机可计算的数值表示;
- Store(存储):将生成的文本向量与对应的原始文档块,存入向量数据库,实现高效的相似性检索能力;
- Retrieve(检索):用户查询时,先将查询词向量化,再从向量数据库中检索出语义最相关的文档块,为LLM生成答案提供上下文支撑。
二、Retrieval第一步:文档加载器(Document Loaders)
文档加载是RAG全流程的起点,无论你的知识库格式多么复杂,LangChain都能通过文档加载器,将其转换为统一格式的Document对象。
2.1 文档加载器的核心设计思想
LangChain的文档加载器有两个核心设计原则,也是其能适配海量数据源的关键:
- 统一抽象接口:所有加载器都继承自
BaseLoader基类,必须实现统一的load()方法,无论数据源是本地文件、在线PDF还是网页,最终都返回List[Document]格式的结果; - 标准化数据结构:所有加载结果都封装为
Document对象,该对象只有两个核心属性:page_content:文档的文本内容,字符串格式;metadata:文档的元数据,字典格式,存储文件路径、页码、作者、行号等溯源信息,是后续检索过滤、结果溯源的关键。
这种设计让后续的文本拆分、向量化、检索环节,完全无需关注原始数据的格式,只需面向Document对象开发即可,大幅降低了RAG系统的开发复杂度。
2.2 主流格式文档加载实战
LangChain提供了上百种文档加载器,覆盖了几乎所有主流数据源和文件格式,这里我们详解最常用的7类场景的加载实现。
2.2.1 TXT纯文本文件加载
TXT是最基础的文本格式,使用TextLoader即可快速加载,核心需要注意编码问题,中文文件建议指定encoding="utf-8"避免乱码。
# 1. 导入依赖
from langchain_community.document_loaders import TextLoader
# 2. 初始化加载器,指定文件路径与编码
text_loader = TextLoader(
file_path="./test.txt",
encoding="utf-8"
)
# 3. 执行加载,返回Document对象列表
docs = text_loader.load()
# 4. 查看结果
print(f"加载到的文档数量:{len(docs)}")
print(f"文档内容:{docs[0].page_content[:100]}") # 查看前100个字符
print(f"文档元数据:{docs[0].metadata}") # 输出:{'source': './test.txt'}
2.2.2 PDF文件加载
PDF是企业知识库最常见的格式,LangChain最常用的是PyPDFLoader,支持本地文件与在线PDF链接,同时支持按页拆分,自动记录页码元数据。
前置依赖:pip install pypdf
# 1. 导入依赖
from langchain_community.document_loaders import PyPDFLoader
# 2. 初始化加载器,支持本地文件/在线链接
# 本地文件示例
pdf_loader = PyPDFLoader(file_path="./data/企业产品手册.pdf")
# 在线PDF示例
# pdf_loader = PyPDFLoader(file_path="https://arxiv.org/pdf/2302.03803")
# 3. 执行加载,按页返回Document对象,一页对应一个Document
docs = pdf_loader.load()
# 进阶:加载并直接拆分,底层默认使用递归字符切分器
# docs = pdf_loader.load_and_split()
# 4. 查看结果
print(f"PDF总页数:{len(docs)}")
print(f"第1页内容:{docs[0].page_content[:200]}")
print(f"第1页元数据:{docs[0].metadata}") # 包含source、page、total_pages等信息工程扩展:如果需要更高精度的PDF解析(如扫描件PDF、带复杂表格的PDF),可替换为PyMuPDFLoader、UnstructuredPDFLoader,适配更复杂的PDF场景。
2.2.3 CSV表格文件加载
CSV格式的业务数据、知识库,使用CSVLoader加载,支持全列加载,也可指定某一列作为文档来源,适配不同的表格结构。
# 1. 导入依赖
from langchain_community.document_loaders.csv_loader import CSVLoader
# 2. 基础用法:加载CSV所有列,一行对应一个Document
loader = CSVLoader(file_path="./data/产品知识库.csv", encoding="utf-8")
data = loader.load()
# 进阶用法:指定source_column,将某一列作为元数据的source,便于溯源
# loader = CSVLoader(
# file_path="./data/产品知识库.csv",
# source_column="产品名称", # 指定产品名称列作为来源
# encoding="utf-8"
# )
# 3. 查看结果
print(f"加载到的行数:{len(data)}")
print(f"第一行内容:{data[0].page_content}")
print(f"第一行元数据:{data[0].metadata}")2.2.4 JSON格式文件加载
JSON是API接口返回、业务系统存储最常用的格式,LangChain的JSONLoader基于jq语法实现,支持精准提取JSON中嵌套的目标字段,适配各种复杂的JSON结构。
前置依赖:pip install jq
# 1. 导入依赖
from langchain_community.document_loaders import JSONLoader
from pprint import pprint
# 场景1:提取JSON数组中指定字段
# 示例JSON结构:{"messages": [{"content": "xxx"}, {"content": "xxx"}]}
json_loader = JSONLoader(
file_path="./data/对话数据.json",
jq_schema=".messages[].content", # jq语法,精准定位content字段
)
docs = json_loader.load()
pprint(docs)
# 场景2:提取嵌套JSON中的文本,保留其他字段为元数据
# 示例JSON结构:{"data": {"items": [{"title": "xxx", "content": "xxx", "author": "xxx"}]}}
loader = JSONLoader(
file_path="./data/接口返回数据.json",
jq_schema=".data.items[]", # 先定位到数组条目
content_key=".content", # 提取content作为page_content
is_content_key_jq_parsable=True, # 启用jq语法解析content_key
)
data = loader.load()
pprint(data)2.2.5 HTML网页加载
针对网页数据、本地HTML文件,使用UnstructuredHTMLLoader加载,支持按语义元素拆分,自动识别标题、段落、列表等结构,保留HTML的层级信息。
前置依赖:pip install unstructured
# 1. 导入依赖
from langchain.document_loaders import UnstructuredHTMLLoader
# 2. 初始化加载器
html_loader = UnstructuredHTMLLoader(
file_path="./data/官网产品介绍.html",
mode="elements", # 按语义元素拆分,生成多个独立Document
strategy="fast" # fast快速模式/hi_res高精度模式
)
# 3. 执行加载
docs = html_loader.load()
# 4. 查看结果
print(f"拆分后的语义块数量:{len(docs)}")
for doc in docs:
print(f"元素类型:{doc.metadata['category']},内容:{doc.page_content[:50]}")2.2.6 Markdown文件加载
针对技术文档、知识库常用的Markdown格式,使用UnstructuredMarkdownLoader加载,支持按标题、段落、代码块等语法结构拆分,完美保留MD的层级信息。
# 1. 导入依赖
from langchain.document_loaders import UnstructuredMarkdownLoader
# 2. 初始化加载器
md_loader = UnstructuredMarkdownLoader(
file_path="./data/技术开发文档.md",
mode="elements", # 按MD语义元素拆分
strategy="fast"
)
# 3. 执行加载
docs = md_loader.load()
# 4. 查看结果
print(f"拆分后的文档块数量:{len(docs)}")
for doc in docs:
print(f"内容:{doc.page_content},元数据:{doc.metadata}")2.2.7 文件夹批量加载
当知识库有上百个文件时,无需逐个文件编写加载逻辑,使用DirectoryLoader即可批量加载指定文件夹内的指定格式文件,支持多线程加速。
# 导入依赖
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
# 初始化文件夹加载器
directory_loader = DirectoryLoader(
path="./data/", # 目标文件夹
glob="*.pdf", # 匹配文件格式,这里加载所有PDF
use_multithreading=True, # 启用多线程,提升加载速度
show_progress=True, # 显示加载进度条
loader_cls=PyPDFLoader, # 指定使用的加载器,与文件格式匹配
)
# 执行批量加载
docs = directory_loader.load()
# 查看结果
print(f"批量加载到的文档总数:{len(docs)}")
# 遍历输出
for doc in docs:
print(doc.metadata)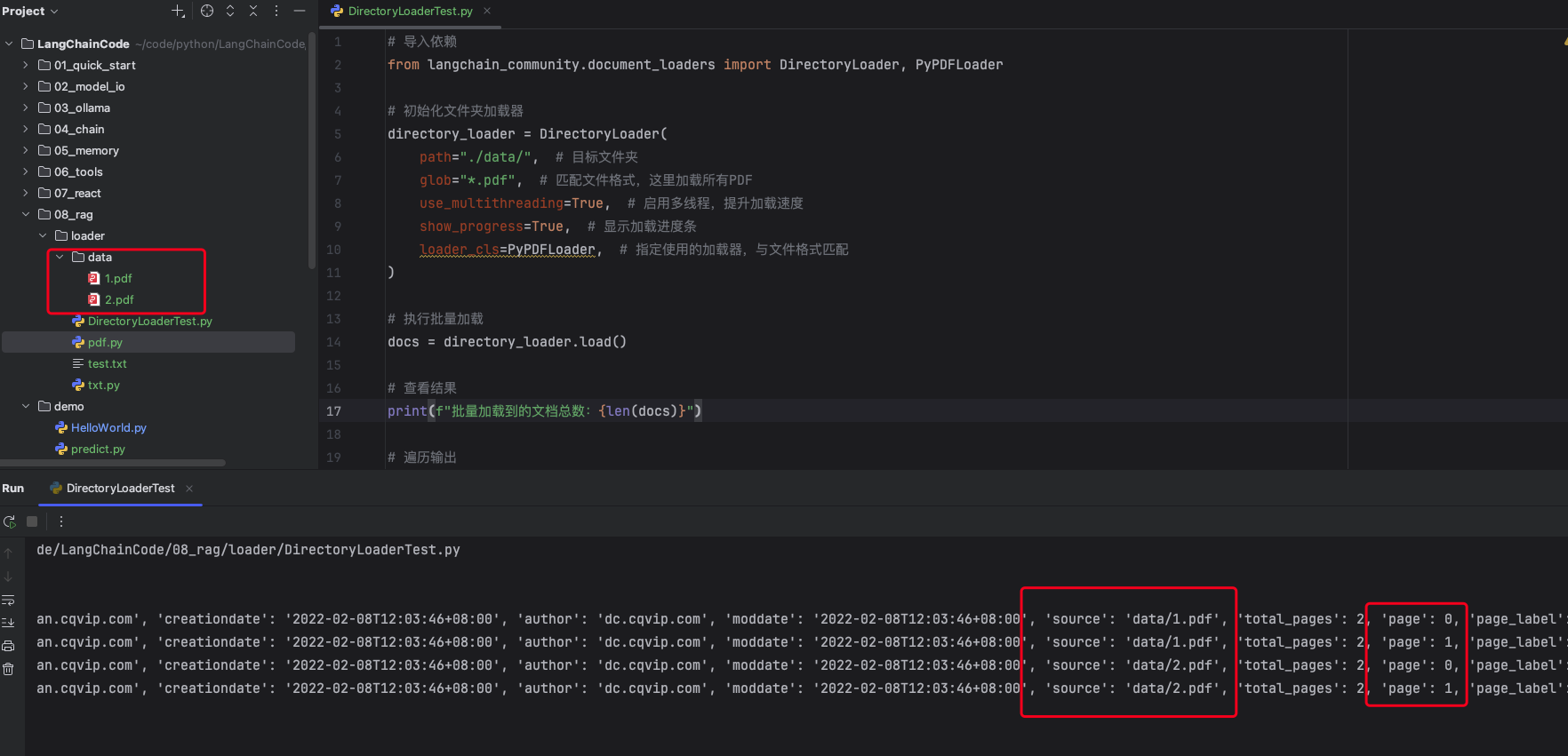
2.3 文档加载器源码核心逻辑解析
2.3.1 BaseLoader基类
所有文档加载器都必须继承BaseLoader抽象基类,其核心逻辑如下:
from abc import ABC, abstractmethod
from typing import List, Iterable
from langchain_core.documents import Document
class BaseLoader(ABC):
"""文档加载器的抽象基类"""
@abstractmethod
def lazy_load(self) -> Iterable[Document]:
"""延迟加载方法,逐一生成Document对象,处理大文件时避免内存溢出,子类必须实现"""
raise NotImplementedError()
def load(self) -> List[Document]:
"""全量加载方法,返回Document列表,用户直接调用
底层默认调用lazy_load,转为列表返回
"""
return list(self.lazy_load())
def load_and_split(self, text_splitter=None) -> List[Document]:
"""加载并直接拆分文档,底层默认使用RecursiveCharacterTextSplitter"""
from langchain_text_splitters import RecursiveCharacterTextSplitter
_text_splitter = text_splitter or RecursiveCharacterTextSplitter()
docs = self.load()
return _text_splitter.split_documents(docs)核心要点:
- 子类必须实现
lazy_load延迟加载方法,这是LangChain推荐的加载模式,避免一次性加载超大文件导致内存溢出; - 对外暴露的
load()方法,底层只是把延迟加载的迭代器转为列表,无需子类重写; - 内置
load_and_split()方法,实现加载+拆分一步到位,简化开发流程。
2.3.2 Document类
Document是LangChain中文本数据的最小载体,其核心结构极简且高扩展:
from typing import Optional, Dict, Any
from pydantic import Field, BaseModel
class Document(BaseModel):
"""用于存储文本及其关联元数据的核心类"""
# 核心文本内容,必填
page_content: str
# 元数据,字典格式,可自定义扩展任意字段,默认空字典
metadata: Dict[str, Any] = Field(default_factory=dict)
# 固定类型标识
type: Literal["Document"] = "Document"所有加载器最终的输出,都是这个类的实例,这也是LangChain能实现全流程标准化的核心。
三、文档加载的最佳实践与避坑指南
3.1 大文件处理的延迟加载方案
当处理GB级别的超大文档时,直接使用load()方法会一次性将所有内容加载到内存,极易导致内存溢出。此时必须使用lazy_load()延迟加载方法,逐行/逐页处理文档:
# 大文件延迟加载示例
from langchain.document_loaders import TextLoader
loader = TextLoader("./data/超大日志文件.txt", encoding="utf-8")
# 逐一生成Document对象,而非一次性加载全量内容
for doc in loader.lazy_load():
# 逐块处理文档:拆分、向量化、入库,无需全量驻留内存
print(f"处理文档块:{doc.page_content[:100]}")3.2 不同格式文档的加载选型建议
|
文件格式 |
首选加载器 |
适用场景 |
避坑提示 |
|
TXT |
TextLoader |
纯文本日志、说明文档 |
必须指定encoding,中文场景优先utf-8 |
|
|
PyPDFLoader |
常规文本型PDF、学术论文 |
扫描件PDF需搭配OCR工具,使用UnstructuredPDFLoader |
|
CSV |
CSVLoader |
结构化知识库、产品参数表 |
避免单行列内容过长,建议提前做分行处理 |
|
JSON |
JSONLoader |
API接口数据、结构化业务数据 |
复杂嵌套结构必须精准编写jq_schema,避免提取无效内容 |
|
Markdown |
UnstructuredMarkdownLoader |
技术文档、知识库 |
启用mode="elements",按标题层级拆分,提升后续检索效果 |
|
HTML |
UnstructuredHTMLLoader |
网页爬虫数据、官网文档 |
提前清洗HTML中的广告、导航栏等无效内容,减少噪音 |
3.3 元数据管理的核心技巧
元数据是后续检索优化、结果溯源的关键,加载阶段必须做好元数据的管理:
- 必存溯源字段:所有文档必须保留
source字段,记录文件路径、URL、行号等信息,便于后续定位答案来源; - 扩展分类字段:可自定义添加
file_type、department、update_time、author等字段,后续检索时可通过元数据过滤,缩小检索范围,提升准确率; - 避免元数据冗余:不要把大量文本内容放入元数据,仅存储检索过滤、溯源所需的关键字段,减少向量库的存储压力。
总结
本篇我们从RAG的核心原理出发,完整拆解了LangChain Retrieval模块的全流程,并深度详解了文档加载器的设计、使用与最佳实践。掌握了文档加载,我们就完成了RAG系统的第一步,能把任意格式的私有知识库,转换为LangChain可处理的标准化Document对象。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)