现代 AI 的底层胜负手:8 大核心概念,读懂 2026 年数据与 AI 架构的演进逻辑
2026 年,生成式 AI 与 Agentic 智能体已经全面进入企业级生产落地阶段,但行业正在面临一个残酷的现实:超过 70% 的企业 AI 项目,最终都卡在了数据环节,而非模型本身。
企业花了大量成本采购大模型、搭建 AI 开发平台,却发现 AI 系统拿不到实时、一致、高质量的数据;训练好的模型,在生产环境中因为特征不一致效果暴跌;好不容易产出的分析洞察,无法落地到业务系统中产生价值。
核心原因非常简单:传统数据栈是为静态报表设计的,而现代 AI 系统需要的是实时数据访问、弹性可扩展的处理能力、端到端紧密集成的数据工作流。传统 “数据湖→数仓→ETL→报表” 的线性流程,根本无法满足 AI 系统对数据的动态、高频、一致性需求。
今天,我们就用最通俗的方式,拆解定义现代数据与 AI 架构的 8 大核心概念,搞懂它们如何解决传统数据栈的痛点,以及如何为 AI 系统打造坚实的底层底座。
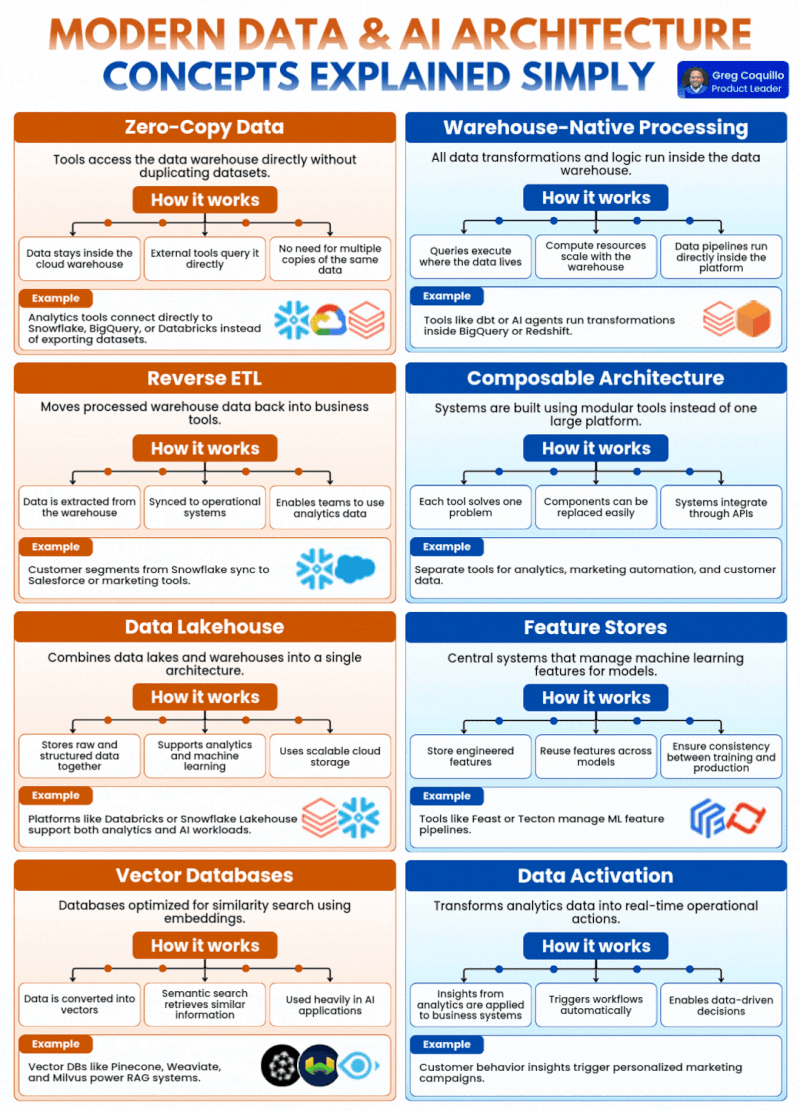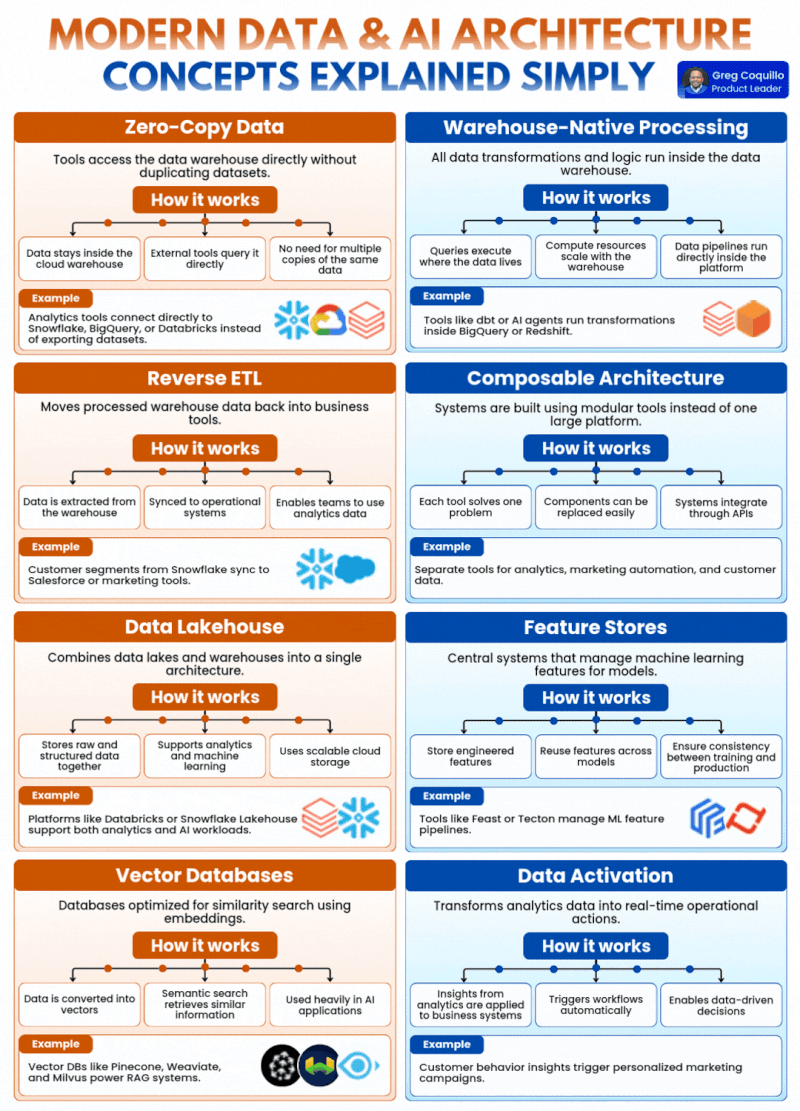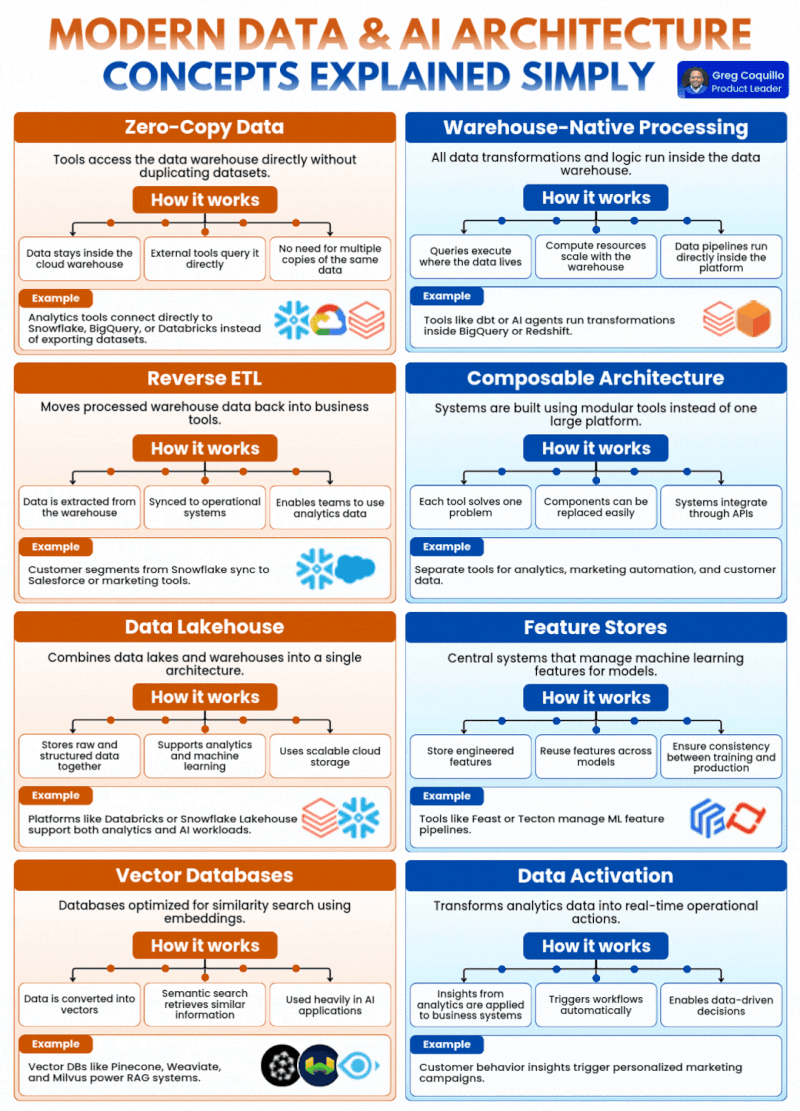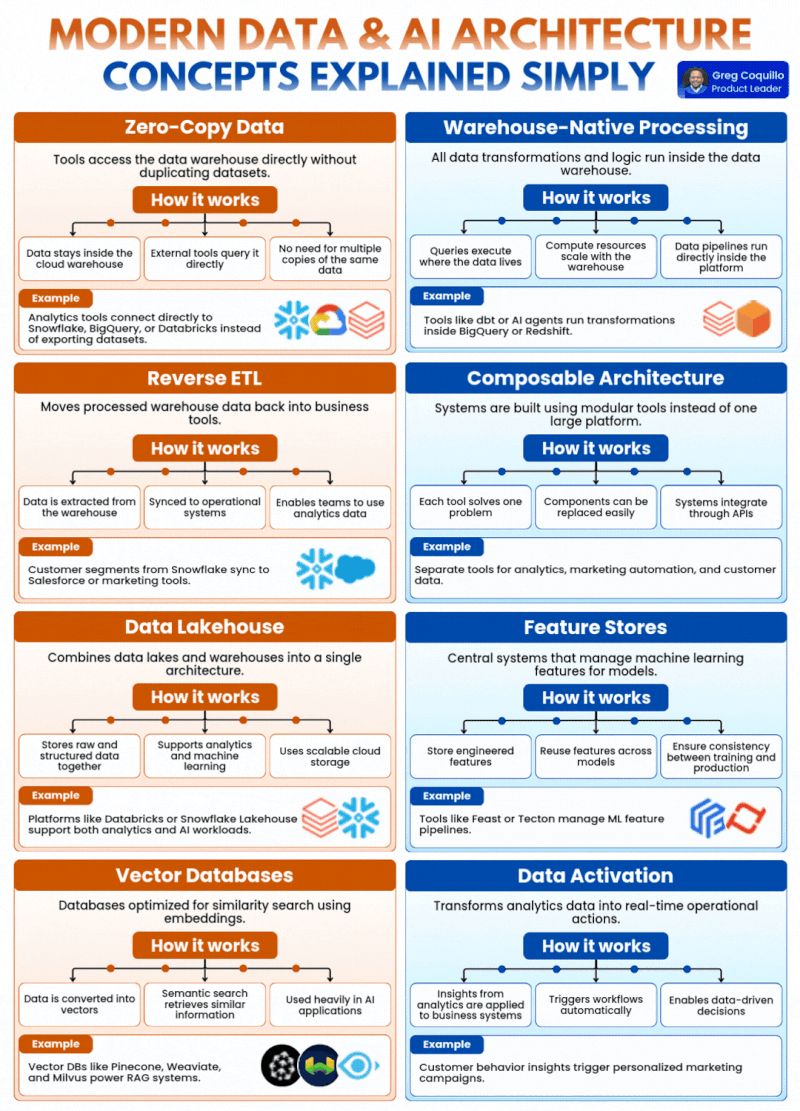
1. Zero-Copy Data(零拷贝数据):从根源解决数据一致性与成本难题
传统数据架构的核心痛点之一,就是数据的无序复制与碎片化。过去,企业的分析工具想要使用数据仓库中的数据,必须先将数据集完整导出、复制一份到工具本地,才能开展分析工作。这直接导致同一个核心数据,在企业内部产生了 N 个副本:BI 工具存一份、分析平台存一份、AI 训练环境再存一份,不仅带来了巨额的冗余存储成本,更严重的问题是不同副本之间的数据一致性完全失控——AI 训练用的是三天前的副本,业务分析用的是上周的快照,最终分析结果与模型输出完全脱节,AI 系统的决策基础从根源上就出现了偏差。
零拷贝数据的核心设计,就是彻底解决这个问题:它让外部工具直接访问云原生数据仓库,无需复制、导出任何数据集,数据始终只在数仓中保留唯一的权威版本,所有工具都直接对源数据发起查询。
它的工作逻辑分为三个核心环节:数据始终留存于云数据仓库内、外部工具直接对源数据发起查询、无需维护多份相同数据的副本。最典型的落地场景,就是 Snowflake、BigQuery、Databricks 等云原生数仓,支持 BI 工具、分析平台、AI 开发环境直接直连查询,完全替代了传统的数据集导出流程。
对于现代 AI 架构而言,零拷贝数据的价值是根本性的:AI 系统需要频繁、大规模地访问业务数据开展训练、推理与特征工程,零拷贝避免了数据复制带来的延迟,保证了 AI 系统拿到的永远是最新、最权威的源数据,从根源上杜绝了 “训练 - 推理数据不一致” 的行业顽疾,同时大幅削减了海量数据复制带来的存储与运维成本。
2. Warehouse-Native Processing(数仓原生处理):让计算跟着数据走,消除海量数据搬运的低效
传统数据处理流程的核心瓶颈,是 “数据搬家” 带来的效率损耗。过去,企业需要对数据做转换、清洗、聚合处理时,必须先把数仓里的海量数据通过 ETL 工具抽取出来,传输到专门的计算引擎中完成处理,再把结果写回数仓。这种 “数据动、计算不动” 的模式,在 TB、PB 级数据规模下,会带来极高的时间成本、带宽开销与处理延迟,完全无法满足 AI 系统对实时数据处理的核心需求。
数仓原生处理的核心理念,就是彻底反转了这个逻辑:所有的数据转换、计算逻辑,都直接在数据仓库内部运行,查询与计算就在数据存储的位置执行,实现 “数据不动,计算动”。
它的核心优势体现在三个方面:查询在数据所在地执行,彻底消除了海量数据的跨系统搬运;计算资源可以随数仓弹性扩缩容,完美匹配 AI 工作负载的峰值算力需求;数据管道可以直接在数仓平台内运行,大幅简化了运维架构。比如当前主流的 dbt 数据转换工具、AI 智能体,都可以直接在 BigQuery、Redshift 内部运行数据转换任务,无需将数据抽离数仓环境。
对于 AI 架构而言,数仓原生处理是实时 AI 应用的核心支撑:RAG 检索增强生成、实时特征工程、动态用户画像生成,都需要对海量数据做低延迟的处理与转换,数仓原生处理避免了数据搬运的巨额开销,将数据处理延迟从小时级压缩到分钟级甚至秒级,让 AI 系统可以基于实时处理的高质量数据做出决策,同时弹性的算力调度也大幅降低了 AI 工作负载的运行成本。
3. Reverse ETL(反向 ETL):打破数仓的 “数据孤岛”,让洞察真正落地业务
传统 ETL 的核心逻辑,是把业务系统的数据抽取、转换、加载到数据仓库中,用于生成报表与分析洞察。但这套流程的终点,往往就是数仓本身 —— 大量高价值的分析结果、用户标签、预测数据,都被锁在了数仓里,业务团队只能通过报表 “看数据”,却无法把这些洞察直接应用到业务系统中。比如数仓里计算出的高价值客户分群,无法自动同步到 CRM 系统,销售团队根本无法触达;AI 模型预测的用户流失风险,只能躺在报表里,无法触发自动化的挽留动作,最终数据变成了无法产生价值的 “死数据”。
反向 ETL 的出现,就是为了打通这条 “从洞察到行动” 的最后一公里:它把数仓里处理完成的高价值数据,反向同步回业务运营系统中,让业务团队、自动化系统、AI 智能体可以直接基于这些数据开展行动。
它的工作流程分为三步:从数仓中提取经过清洗、建模的高价值数据;将数据同步到 CRM、营销自动化、客服系统等业务运营平台;让业务团队与自动化系统可以直接基于分析数据开展动作。最典型的场景,就是把 Snowflake 中计算完成的客户分群、生命周期标签,同步到 Salesforce、HubSpot 等工具中,直接支撑销售与营销动作。
对于 AI 架构而言,反向 ETL 是 AI 能力落地的核心桥梁:AI 系统的终极价值,从来不是生成报表与洞察,而是把数据洞察转化为业务行动。AI 模型输出的用户流失预警、个性化推荐标签、智能运营策略,都可以通过反向 ETL,自动同步到对应的业务系统中,直接触发业务动作,让 AI 的价值从 “纸上谈兵” 变成实实在在的业务结果,而不是永远停留在数仓里的分析报告中。
4. Composable Architecture(可组合架构):用模块化灵活性,适配 AI 技术的高速迭代
传统数据平台的核心桎梏,是大一统的巨石架构。过去,企业往往会选择一个一体化的巨型平台,包揽数据集成、存储、计算、分析、BI 的所有功能。但这种架构的灵活性极差,企业的业务需求与 AI 技术在快速迭代,想要换一个更适配大模型的 BI 工具,或者新增一个特征处理模块,都会被巨石平台的绑定关系限制,牵一发而动全身,根本无法跟上 AI 技术的迭代速度,最终被平台的能力上限困住了 AI 创新的脚步。
可组合架构的核心理念,彻底颠覆了这种巨石模式:它放弃了大一统的集成平台,转而采用一系列模块化、专精化的工具,通过标准化 API 无缝集成,搭建完整的数据与 AI 技术栈。每个工具只解决一个核心问题,组件之间可以轻松替换、灵活扩展,不会出现 “一换全换” 的困境。
它的核心优势体现在三个方面:每个工具都聚焦解决一个特定问题,能做到该领域的极致专精;组件之间松耦合,可以轻松替换、升级单个模块,无需重构整个架构;所有系统通过标准化 API 集成,打通了数据与能力的流转。比如企业可以用不同的专精工具,分别搭建数据分析、营销自动化、客户数据管理模块,通过 API 串成完整的业务工作流,随时可以替换其中的单个模块。
对于 AI 架构而言,可组合架构的价值是无可替代的。当前 AI 技术的迭代速度极快,今天的主流向量数据库,明天可能就有更适配大模型的替代方案;这个月的主流特征平台,下个月可能就会出现支持多模态的升级版本。可组合架构让企业可以灵活替换、升级单个组件,不用重构整个数据栈,就能快速跟上 AI 技术的迭代节奏。同时,企业可以自由选择每个领域最顶尖的工具,搭建最适配自身业务的 AI 数据底座,而不是被大一统平台的能力边界限制住创新的可能。
5. Data Lakehouse(数据湖仓一体):统一 AI 与分析的数据底座,消除架构割裂
传统企业的数据架构,长期处于 “湖仓分离” 的割裂状态:数据湖用来存储海量的原始、非结构化、半结构化数据,支撑数据科学与机器学习训练;数据仓库用来存储结构化、清洗后的高质量数据,支撑 BI 报表与业务分析。这种分离架构,导致数据需要在湖和仓之间反复流转,不仅带来了严重的数据冗余、一致性问题,还造成了极高的运维复杂度 ——AI 模型训练用的数据,和业务分析用的数据来自两套体系,最终出现 “分析和训练各说各话” 的局面,AI 模型的业务效果大打折扣。
数据湖仓一体的出现,就是为了彻底融合这两套架构:它把数据湖的灵活性、低成本海量存储能力,和数据仓库的高性能、结构化管理、ACID 事务能力,融合到一个统一的架构中,在同一个平台里同时支撑 BI 分析、数据科学、机器学习全场景工作负载。
它的核心能力分为三点:统一存储原始数据与结构化数据,实现一份数据全场景复用;同时支持低延迟的业务分析与高吞吐的机器学习工作负载;基于云原生的可扩展存储,支撑 PB 级甚至 EB 级的海量数据管理。当前 Databricks Lakehouse、Snowflake Lakehouse 都是湖仓一体架构的典型代表,能在同一个平台内同时支撑企业的分析与 AI 全流程工作。
对于 AI 架构而言,湖仓一体是构建统一 AI 数据底座的核心方案。大模型训练、多模态 AI 应用需要海量的原始非结构化数据(文本、图像、音频、业务日志),而模型推理、业务分析需要结构化的高质量数据。湖仓一体架构,让 AI 训练、特征工程、业务分析都在同一个数据平台内完成,数据只存一份,从根源上保证了训练与生产环境的数据一致性,大幅简化了 AI 全流程的数据运维,同时云原生的弹性存储能力,也能完美支撑大模型训练的海量数据需求。
6. Feature Stores(特征存储):解决 AI 行业顽疾,杜绝训练 - 生产效果偏差
机器学习领域最头疼、最普遍的行业顽疾,就是 “训练 - 生产倾斜(Training-Serving Skew)”:数据科学家在离线环境中训练模型时,用离线数据计算的特征逻辑,和模型上线后生产环境中实时计算的特征逻辑、数据来源不一致,导致模型在生产环境中的效果暴跌,甚至完全无法使用。同时,不同的模型、不同的团队,往往会重复计算相同的特征,浪费大量的算力与研发时间,特征无法跨团队、跨模型复用。
特征存储,就是为了解决这些问题而生的机器学习特征中心化管理系统,它负责机器学习特征的全生命周期管理,包括特征的存储、计算、复用、版本管理、在线服务,核心目标是保证模型训练与生产环境的特征一致性。
它的核心价值体现在三个方面:统一存储工程化完成的特征,实现特征的跨团队、跨模型复用;通过统一的特征计算逻辑,彻底保证训练环境与生产环境的特征一致性;提供低延迟的在线特征服务,支撑 AI 模型的实时推理需求。当前主流的特征存储工具包括 Feast、Tecton,已经成为企业级 AI 平台的标配组件。
对于现代 AI 架构而言,特征存储是 AI 模型稳定落地的核心保障。特征是 AI 模型的核心燃料,特征的质量与一致性,直接决定了模型在生产环境中的最终效果。特征存储彻底解决了训练 - 生产倾斜的行业痛点,让 AI 模型在生产环境中能稳定复现训练时的效果。同时,中心化的特征管理,让企业可以沉淀可复用的特征资产,大幅提升 AI 开发效率,避免重复造轮子。对于 Agentic 智能体这类长周期运行的 AI 系统,特征存储还可以统一管理用户画像、业务上下文、环境状态特征,让 AI 的决策更稳定、更准确。
7. Vector Databases(向量数据库):生成式 AI 的外置记忆体,RAG 系统的核心底座
传统的关系型数据库、数据仓库,都是为结构化数据的精确匹配查询设计的,根本无法处理大模型生成的高维向量嵌入(Embedding)数据,更无法高效完成海量高维向量的相似度检索。而生成式 AI 时代的核心场景 ——RAG 检索增强生成、语义搜索、个性化推荐、多模态内容匹配,核心需求就是快速找到与用户查询语义最相似的内容,传统数据库在这些场景中完全无能为力。
向量数据库,就是专门为向量嵌入数据优化设计的专用数据库,核心能力是基于高维向量的相似度检索,是现代生成式 AI 架构不可或缺的核心基础设施。
它的工作逻辑分为三个核心环节:将文本、图像、音频等非结构化数据,通过嵌入模型转换成高维向量;基于向量相似度匹配,完成语义级的相似内容检索;深度适配 AI 应用场景,成为大模型的外置记忆体。当前主流的向量数据库包括 Pinecone、Weaviate、Milvus,几乎所有企业级 RAG 系统,都以向量数据库为核心底座。
对于现代 AI 架构而言,向量数据库是生成式 AI 落地的 “刚需组件”。它是大模型的 “外置记忆体”,可以把企业的私有文档、知识库、业务数据、历史对话,转换成向量嵌入存储起来,当大模型需要回答问题、生成内容、做出决策时,快速检索到最相关的上下文信息,让大模型可以精准使用企业的私有数据,同时从根源上减少大模型的幻觉问题。除此之外,语义搜索、个性化推荐、多模态 AI 应用、智能体记忆管理,都离不开向量数据库的支撑,它已经从一个小众的专用组件,变成了现代 AI 架构的核心基础设施。
8. Data Activation(数据激活):实现端到端闭环,让 AI 从 “分析工具” 变成 “运营引擎”
企业数据平台最常见的困境,就是 “有洞察,无行动”。很多企业搭建了完善的数据平台,产出了海量的分析报表与 AI 洞察,但这些内容最终只停留在 PPT 和仪表盘上,无法转化为实际的业务行动,数据变成了只能看、不能用的 “死数据”。AI 系统产出的预测结果、运营策略、智能决策,也因为没有自动化的落地路径,最终变成了纸面成果,完全没有释放出数据与 AI 的核心价值。
数据激活的核心理念,就是打通从洞察到行动的全链路:它把数据分析与 AI 产出的洞察,转化为实时的业务行动,通过把数据推送到业务系统、自动触发工作流,真正实现数据驱动的决策与自动化运营。
它的核心价值体现在三个方面:把分析洞察直接落地到业务系统,而不是停留在报表层面;基于数据洞察自动触发业务工作流,实现全流程自动化;支撑企业实现真正的实时数据驱动决策,而不是事后复盘。最典型的落地场景,就是基于用户行为洞察与 AI 预测,自动触发个性化的营销活动、用户挽留流程、库存补货动作。
对于 AI 架构而言,数据激活是实现端到端 AI 业务闭环的核心。AI 的终极价值,从来不是生成分析报告,而是实现自主的、数据驱动的业务运营。数据激活,就是让 AI 从 “分析工具” 变成 “运营引擎” 的关键:AI 系统可以基于实时数据,自动生成洞察、做出决策,然后通过数据激活,直接触发业务系统的自动化工作流 —— 当用户出现流失风险时,自动触发挽留活动;当库存不足时,自动触发补货流程;当用户发起咨询时,自动推送个性化的解决方案,真正实现端到端的 AI 驱动业务闭环,让数据与 AI 的价值完全释放。
结语:AI 的竞争,本质是数据架构的竞争
当前行业里有一个普遍的认知误区:AI 的性能取决于模型的参数量、Prompt 的优化技巧。但实际上,AI 系统的上限,从来不是由模型决定的,而是由支撑它的数据架构决定的。
再强大的大模型,没有一致、实时、高质量的数据,也只会产生脱离业务的幻觉;再完美的 AI 策略,没有端到端的数据激活闭环,也只能停留在 PPT 里;再先进的模型架构,没有灵活可扩展的底层数据平台,也无法落地到生产环境中。
2026 年,企业之间的 AI 竞争,已经从模型的军备竞赛,转向了底层数据架构的竞争。这 8 大核心概念,共同构建了现代数据与 AI 架构的完整体系:从数据的存储、处理,到架构范式的升级,再到 AI 专属的基础设施,最后到数据价值的落地,形成了一个端到端的完整闭环。
谁能率先搭建起灵活、高效、一致、端到端的现代数据架构,谁就能真正把 AI 的能力转化为持续的业务价值,在这场 AI 变革中胜出。
最后也想问问:在你的 AI 或数据平台建设中,哪一个架构概念,正在成为你最核心的建设重点?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)