深入 llama.cpp:llama-server-- 从命令行到HTTP Server(2)
前言
llama-server是llama.cpp中用于发布大模型服务的工具。它通过极简的命令行配置,将复杂的模型推理过程封装为通用的 HTTP 接口;在底层,它选择以纯 C++ 编写的 cpp-httplib 作为服务框架的底层。本章分为应用实战与底层架构两部分。首先,我们将介绍不同参数下的大模型服务发布;接着,我们将详细解析 cpp-httplib 在项目中的具体实现,帮助读者掌握该服务端在网络调度层面的运行逻辑。
目录
- 1 应用实战:启动大模型服务
- 2 架构解析:基于cpp-httplib的运行机制
1 应用实战:启动大模型服务
llama-server是一款轻量级、兼容 OpenAI API、用于提供大语言模型服务的 HTTP 服务器。在上节中,我们启动了llama-server,构建了本地的大模型服务。本节将在此基础上,进一步深入llama-server启动过程的参数设置,同时演示如何利用curl工具发起网络请求,以实测并验证服务的接口响应。
1.1 模型服务参数设置
llama-server支持自定义端口号,发布大模型服务。如下,llama-server通过--port参数设置端口号为8080。
llama-server -m gemma-3-1b-it-Q4_K_M.gguf --port 8080llama-server 支持多用户并行解码。多用户并行解码是指模型服务器通过资源切分,同时处理多路独立的用户推理请求,以实现任务的高并发生成。如下所示,llama-server 通过 -np 参数设置模型服务的并发请求数为 4,并配合 -c 参数指定全局最大上下文长度为 16384 个 Token,这意味着总上下文空间将被划分为 4 个独立的槽位(Slots),使每个并发请求所能占用的最大上下文配额为 4096 个 Token。
llama-server -m gemma-3-1b-it-Q4_K_M.gguf -c 16384 -np 4llama-server支持推测解码。推测解码是一种利用小型“草稿模型”先行预测、并由大型‘主模型’进行并行验证,从而在不损耗生成质量的前提下显著提升推理效率的技术。如下,llama-server通过参数指定“草稿模型”,辅助-m指定的“主模型”进行推理。
llama-server -m gemma-3-1b-it-f16.gguf -md gemma-3-1b-it-Q4_K_M.ggufllama-server 支持启用文本嵌入(embedding)模式。在此模式下,服务端用于接收文本输入并输出对应的特征向量,以实现对文本语义的数值化表征。如下所示,llama-server 通过添加 --embedding 标记激活该模式,并配合 --pooling cls 参数指定使用 CLS 池化策略来提取文本特征,同时利用 -ub 8192 参数将物理批处理大小(ubatch-size)设为 8192,以优化大规模文本处理时的执行效率。
llama-server -m gemma-3-1b-it-f16.gguf --embedding --pooling cls -ub 8192llama-server 支持启用重排序(Reranking)模式。在此模式下,服务端将开放重排序接口,用于接收查询请求及多个候选文档片段,并输出该查询与各片段之间的相关性分值。如下,llama-server通过添加--reranking标记启用重排序模式。
llama-server -m gemma-3-1b-it-f16.gguf --reranking1.2 模型服务请求
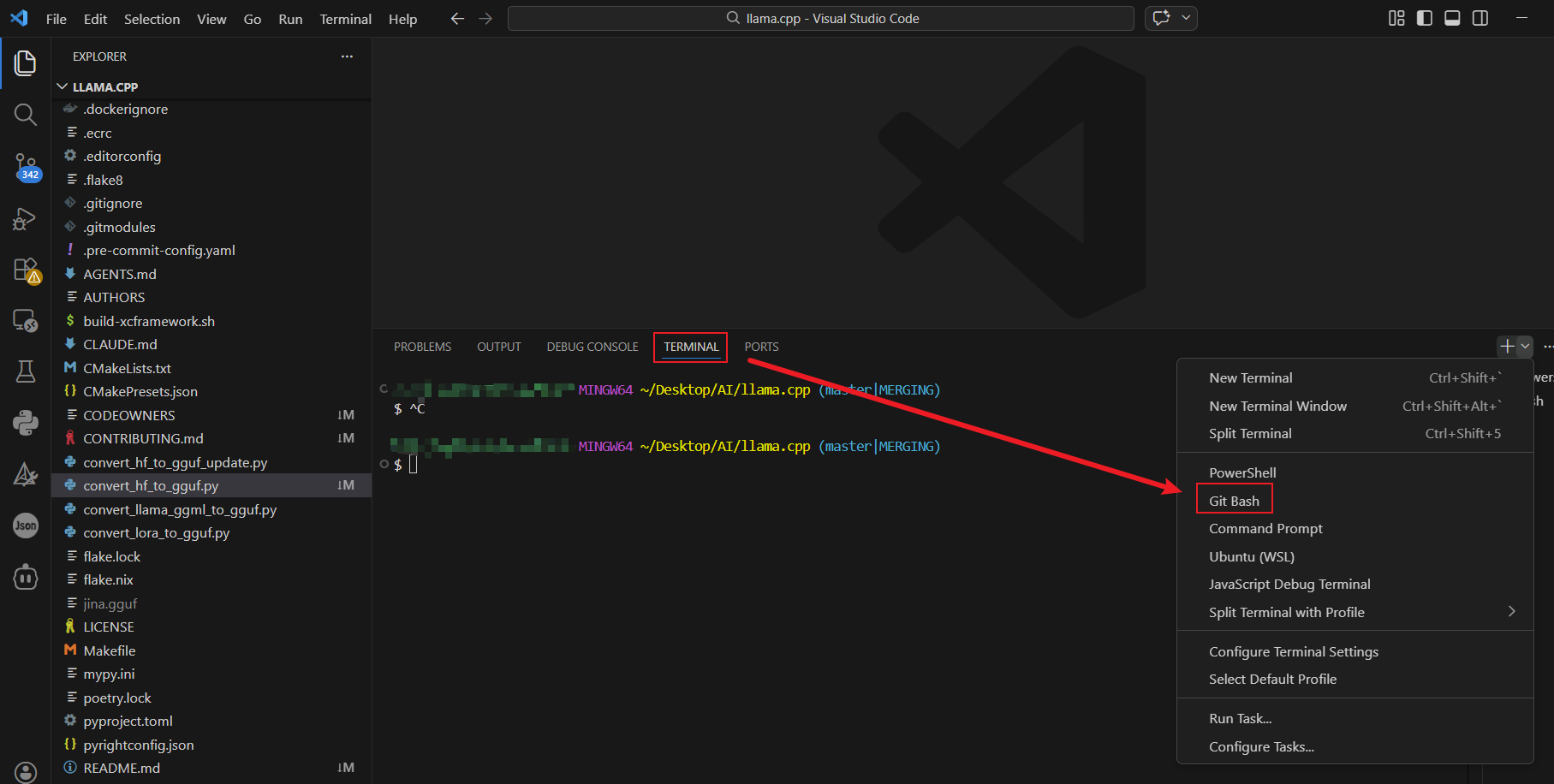
本小节将利用 curl 工具发起的网络请求,除涉及针对上节配置端口的基础访问以及重排序(Reranking)服务请求外,还将重点涵盖兼容 OpenAI 标准的接口调用,包括对话补全(Chat Completions)、数据响应(Responses)及文本嵌入(Embeddings)三类标准网络请求。其中curl工具(curl.exe)需读者自行下载,curl相关地命令行可在vscode中TERMINAL->Git Bash环境下运行,如下图所示,vscode中TERMINAL->Git Bash环境打开过程。
1.2.1 模型信息获取
服务:
llama-server -m gemma-3-1b-it-Q4_K_M.gguf --port 8080请求:
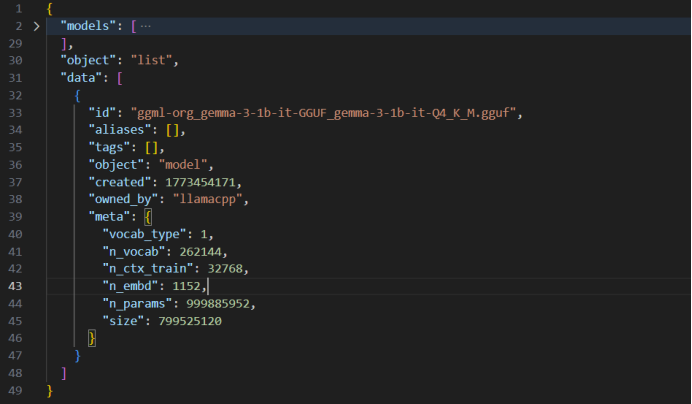
curl http://127.0.0.1:8080/models响应:
1.2.2 Chat Completions
服务:
llama-server -m gemma-3-1b-it-Q4_K_M.gguf --port 8080请求:
curl.exe http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'响应:
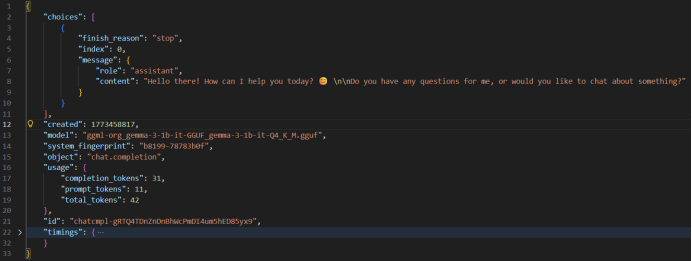
返回内容为json字符串,其中"choices"->"messages"->"content"为模型返回的对话内容。
1.2.3 Responses
服务:
llama-server -m gemma-3-1b-it-Q4_K_M.gguf --port 8080请求:
curl.exe http://127.0.0.1:8080/v1/responses \
-H "Content-Type: application/json" \
-d '{
"input": "Hello!"
}'响应:
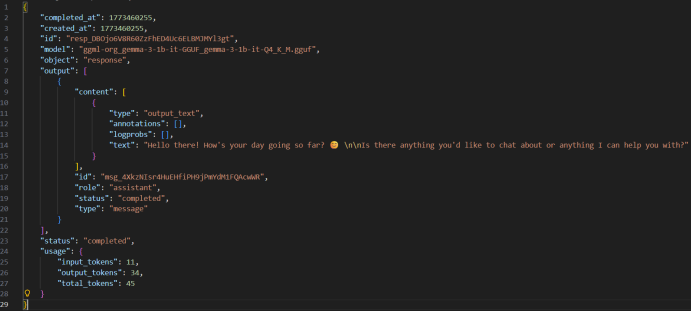
返回内容为json字符串,其中"output"->"content"->"text"为模型返回的对话内容。
1.2.4 Embeddings
服务:
llama-server -m gemma-3-1b-it-f16.gguf --embedding --pooling cls -ub 8192请求:
curl.exe http://127.0.0.1:8080/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Hello!",
"encoding_format": "float"
}'响应:
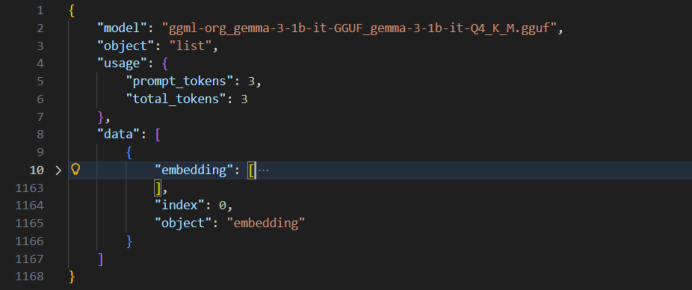
返回内容为json字符串,其中"data"->"embedding"为模型返回文本嵌入向量,维度为1*1152。
1.2.5 Reranking
为了确保重排序(Reranking)服务的效果,本文选用轻量且专业的jina-reranker-v1-tiny-en模型进行本地快速实验,可通过 Hugging Face 官方仓库或国内镜像站(hf-mirror.com)将其克隆至本地。
git clone https://huggingface.co/jinaai/jina-reranker-v1-tiny-en
git clone https://hf-mirror.com/jinaai/jina-reranker-v1-tiny-en#镜像地址随后,利用 llama.cpp 提供的工具链将模型转换为 GGUF 格式。首先定位至 llama.cpp 源码目录并配置所需的 Python 环境依赖;接着执行转换脚本convert_hf_to_gguf.py,将jina-reranker-v1-tiny-en模型完整输出为 jina.gguf。具体执行命令如下。一个已转换好的模型jina.gguf可从此下载。
cd llama.cpp
pip install -r requirements.txt
python convert_hf_to_gguf.py ./jina-reranker-v1-tiny-en/ --outfile jina.gguf服务:
llama-server -m jina.gguf --reranking请求:
curl.exe http://127.0.0.1:8080/v1/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "some-model",
"query": "How much does a catty of apples cost?",
"top_n": 3,
"documents": [
"Apples are red.",
"Apples are a type of fruit.",
"Apples cost 3 yuan per catty.",
"Apple leaves are oval or broadly elliptical."
]
}'响应:
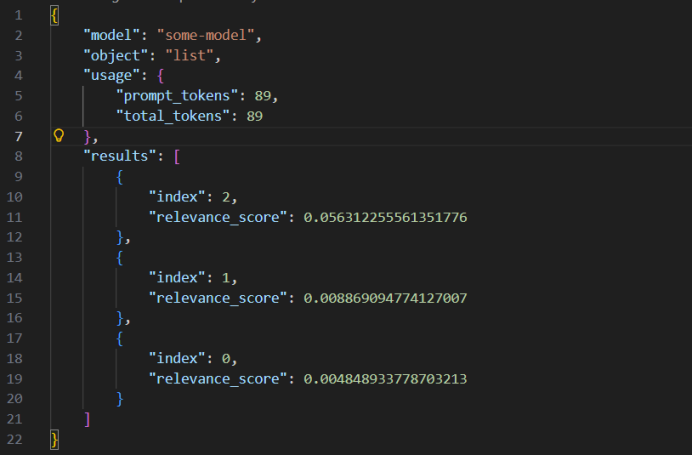
返回内容为json字符串,包含排名前三的返回内容。其中第三个(index为2)得分最高。
2 架构解析:基于cpp-httplib的运行机制
在上篇文章(初识llama.cpp - 轻量级推理引擎-CSDN博客)的最后,我们在浏览器中通过http://127.0.0.1:8080访问可视化交互界面,正式开启与本地大模型的零延迟对话体验。本章将深入llama-server与前端(UI)的交过过程,llama-server选择了轻量级的头文件库cpp-httplib作为llama-server的通信底层依赖,本节将深入代码具体的实现,探讨基于cpp-httplib的模型服务运行机制,进一步理解用户从输入对话文本到界面响应对话的交互逻辑。
具体的代码实现将涉及到llama-server、server-context、cpp-httplib(底层依赖)三个项目。整体的架构如下图所示:
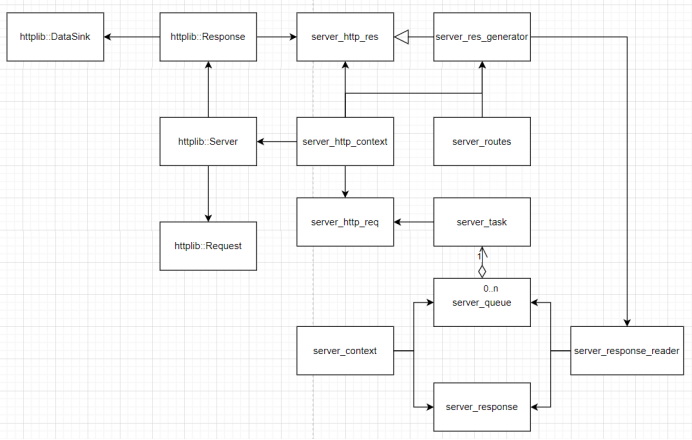
整体的架构主要分为server_http_context与server_context,其中server_http_context用于接收用户输入文本以及向用户返回模型推理的结果(以文本的形式返回),server_context用于对模型的推理进行管理。
server_context通过server_response_reader将模型推理生成的文本(Token)传递给server_http_context,而server_http_context通过httplib::DataSink将模型推理实时生成的文本以流式传输(streaming)的形式返回到客户端(UI),相较于传统的一次性整体响应,这种流式机制允许服务端将生成的Token实时推送到界面,从而确保了从用户输入到指令响应的极速交互体验。同时server_http_context将用户请求封装为模型推理的任务server_task,为后端模型推理提供输入。
在 llama-server 项目中,通过为 httplib::Server 注册POST和GET类型的回调函数,实现了对特定网络请求的处理与响应。注册的回调函数如下:
其中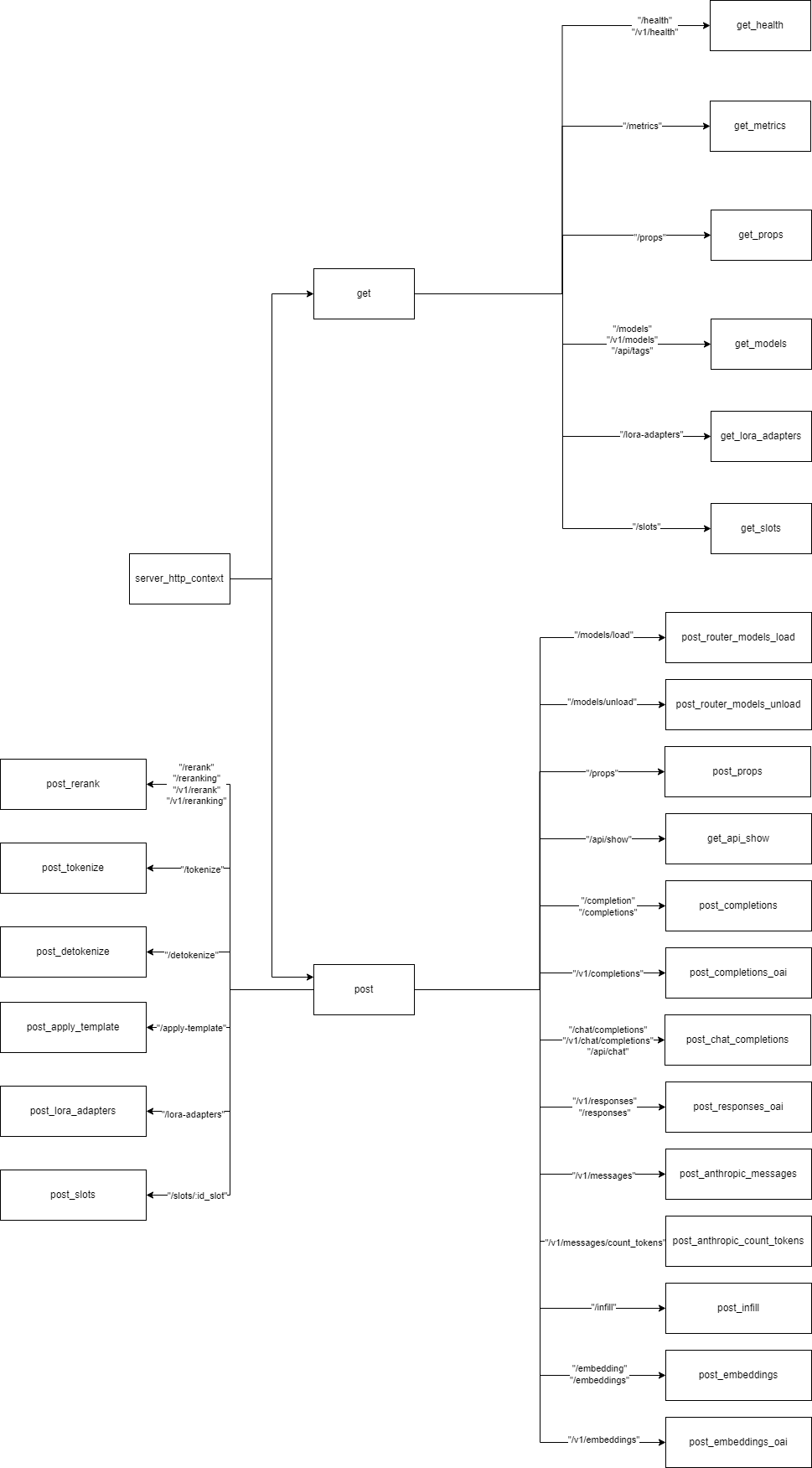 横线处的文字表示网络请求名称。以get_health为例,用户可通过http://127.0.0.1:8080/health网络地址请求,而服务器则由get_health方法处理并响应,果如下图所示:
横线处的文字表示网络请求名称。以get_health为例,用户可通过http://127.0.0.1:8080/health网络地址请求,而服务器则由get_health方法处理并响应,果如下图所示:

文末
本文深入讲解了llama-server,从命令行到HTTP Server的过程,具体地从"应用实战:启动大模型服务"与"结构解析:基于cpp-httplib的运行机制"两方面说明,从工具的使用到模型服务框架的代码具体实现,由浅入深地说明了从用户输入对话文本到界面响应对话的交互逻辑。在下一章中,我们将进一步探索模型推理前的核心准备环节——模型加载与初始化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)