一文详解Vision Transformer(ViT)神经网络模型原理
Vision Transformer(简称ViT),最初是Google团队于2021年提出的将Transformer应用在图像分类的模型,因为其模型“简单”且效果好,可扩展性强(Scalable,模型越大效果越好),成为了Transformer在CV领域应用的里程碑著作。
ViT代表了计算机视觉领域的突破性变革,它利用了彻底革新自然语言处理的自注意力机制。与依赖分层特征提取的传统卷积神经网络(CNN) 不同,ViT 将图像视为更小块的序列,从而能够捕捉视觉数据中的全局关系和长距离依赖关系。这种独特的方法在图像分类、目标检测和生成建模等任务中展现出卓越的性能,使 ViT 成为推进人工智能驱动图像分析的强大工具。其多功能性和可扩展性使其成为不断发展的计算机视觉领域中的一项关键创新。
论文:
《An image is worth 16x16 words: Transformers for image recognition at scale》
一、Transformer 简单介绍
Transformer 是一种强大的深度学习架构,最初是为自然语言处理 (NLP) 任务(例如机器翻译、文本摘要和情感分析)而开发的,Transformer 已经成为构建多模态智能系统的事实标准。从最初的 BERT、GPT 在 NLP 中的成功,到 ViT、CLIP、RT-1 等模型在视觉和控制领域的延伸,Transformer 构筑起了统一语言、视觉乃至动作空间的桥梁。
Transformer 的核心是编码器-解码器结构,其中编码器处理输入序列(例如句子)并创建丰富的上下文表示,而解码器则基于此表示生成输出序列。
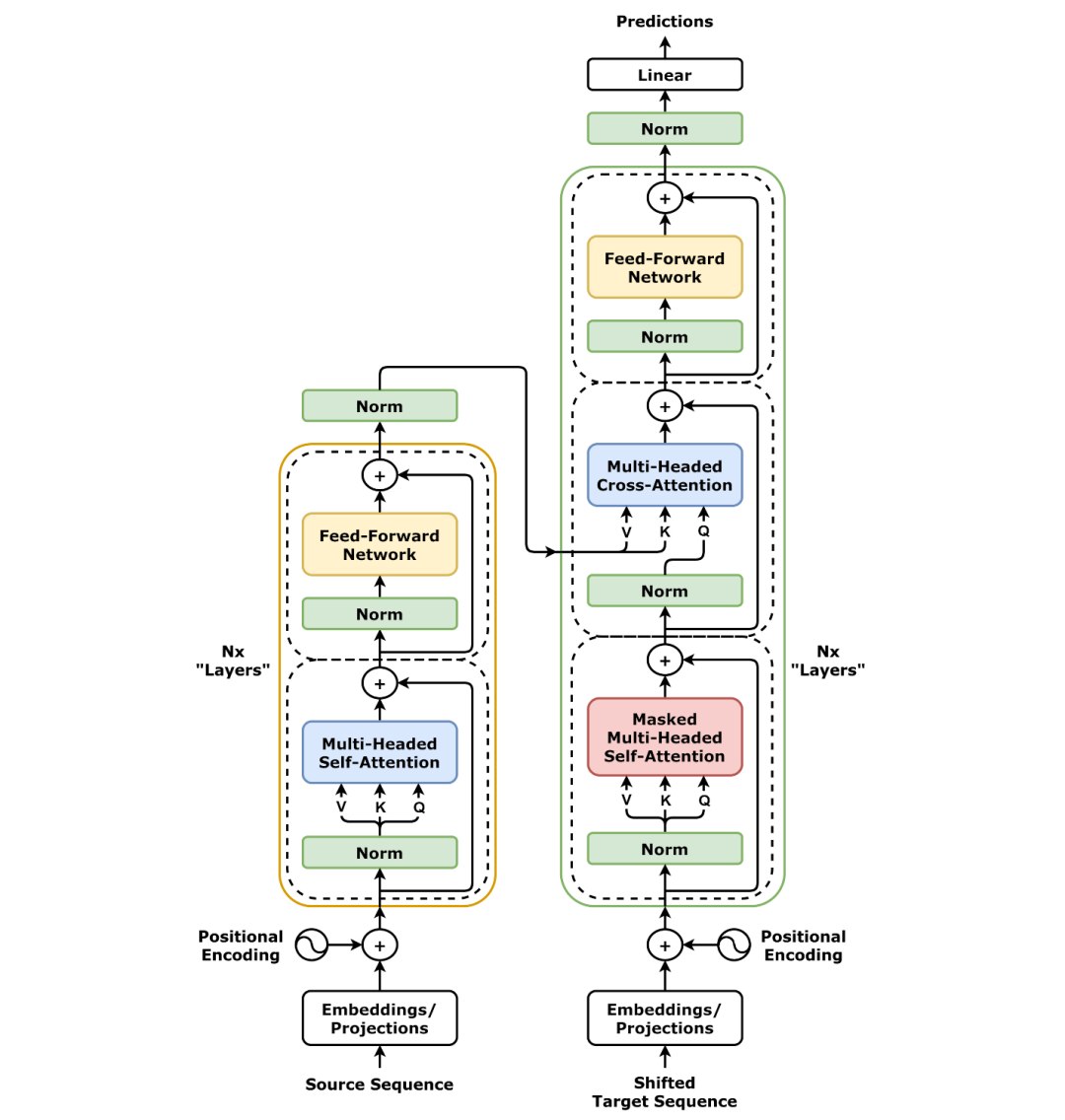 图1. 左边为编码器,右边为解码器
图1. 左边为编码器,右边为解码器
编码器(Encoder)
编码器由 NN 层相同的模块堆叠而成,每层包含两个子层:
-
***多头自注意力机制(Multi-Head Self-Attention)*:**计算输入序列中每个词与其他词的相关性。
-
***前馈神经网络(Feed-Forward Neural Network)*:**对每个词进行独立的非线性变换。
每个子层后面都接有残差连接(Residual Connection)和层归一化(Layer Normalization)。
解码器(Decoder)
解码器也由 NN 层相同的模块堆叠而成,每层包含三个子层:
-
掩码多头自注意力机制(Masked Multi-Head Self-Attention):
计算输出序列中每个词与前面词的相关性(使用掩码防止未来信息泄露)。
-
编码器-解码器注意力机制(Encoder-Decoder Attention):
计算输出序列与输入序列的相关性。
-
前馈神经网络(Feed-Forward Neural Network):
对每个词进行独立的非线性变换。
同样,每个子层后面都接有残差连接和层归一化。
Transformer 背后的关键创新在于自注意力机制,该机制允许模型权衡序列中每个元素相对于其他元素的重要性,从而捕捉局部和长距离依赖关系,而无需依赖循环或卷积运算。这种设计使 Transformer 能够并行处理整个序列,从而显著提升效率和性能,超越 RNN 和 LSTM 等先前的架构。
二、Vision Transformer:一张图片胜过 16x16 个单词
2021 年,谷歌研究院在里程碑式论文《An image is worth 16x16 words: Transformers for image recognition at scale》中推出了 ViT,ViT 将这种变革性方法从语言数据应用到视觉数据。Transformer 原本是为了解决语言文字处理任务而提出的模型,其设计初衷是用于建模序列数据中的长距离依赖关系。在 NLP领域中,Transformer 能够通过自注意力机制灵活地捕捉单词之间的全局关系,极大提升了语言理解与生成的能力。正如传统的 Transformer 将句子分解成单词 token 一样,ViT 将图像划分为固定大小的 patch,并将每个 patch 视为一个“视觉 token”。然后,这些 patch 被线性嵌入,并补充位置编码以保留空间信息——这与 NLP Transformer 中单词的嵌入和排序方式如出一辙。
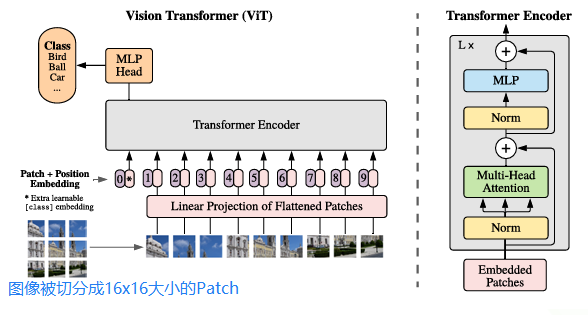
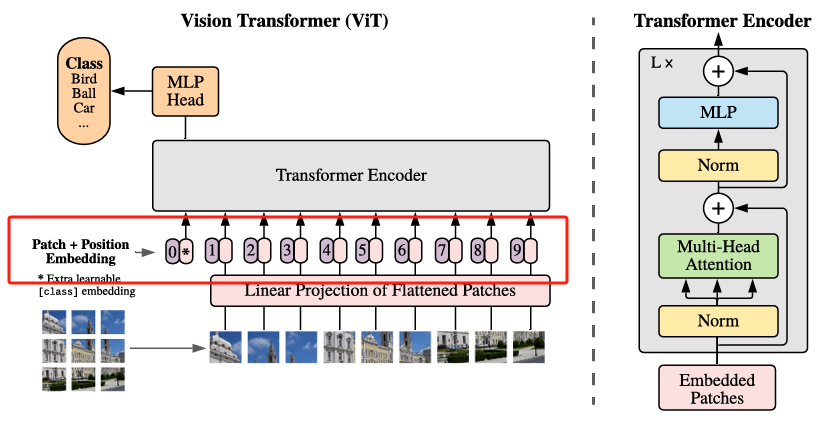
ViT的架构如上图,与寻常的分类网络类似,整个Vision Transformer可以分为两部分:
1. 特征提取——特征提取部分是其最核心的组成,它包括了Patch Embedding、Positional Encoding以及Transformer Encoder,主要过程就是:先将一张图像划分为固定大小的 Patch(如 16×16),将每个 Patch 展平成向量,再通过一个线性投影层将其映射到统一的维度空间,最终形成一个 token 序列。随后,ViT 在这个 token 序列前加上一个可学习的 [CLS] token,并叠加位置编码(Positional Encoding),以保留图像中的空间位置信息。整个序列就像一段文本,送入多层标准的 Transformer 编码器结构进行编码处理。
2. 分类——分类部分则是紧接在特征提取之后,特征提取部分通过一个可学习的 [CLS] token 来代表整张图像的全局语义。这个 token 会随着其他 token 一起参与 Transformer 编码过程,最终被送入一个简单的 MLP 分类头进行类别预测,完成整张图像的分类任务。
这种方法不依赖任何卷积操作,完全基于序列建模,展现了 Transformer 在图像建模上的巨大潜力。Vision Transformer 利用了彻底改变语言理解的相同架构,在图像识别领域取得了最先进的成果,展现了 Transformer 框架在不同领域的多功能性和强大功能。
*三、Vision Transformer的原理详解*
接下来我们详细讲解ViT网络架构的各个部分:
*1. Patch Embedding——图像分块与线性嵌入模块*
ViT 的第一步操作,就是将输入图像转化为一系列的 *视觉 token*,这个过程被称为 *Patch Embedding*,Patch 指的就是分割后的一小块图像区域,即,将一张二维图像按照16x16的大小划分成若干个小块(Patch),然后将每个 Patch 展平成一个向量,再通过一个线性层将其映射到指定的维度空间(例如 768维),从而得到一组输入 token,供 Transformer 使用。
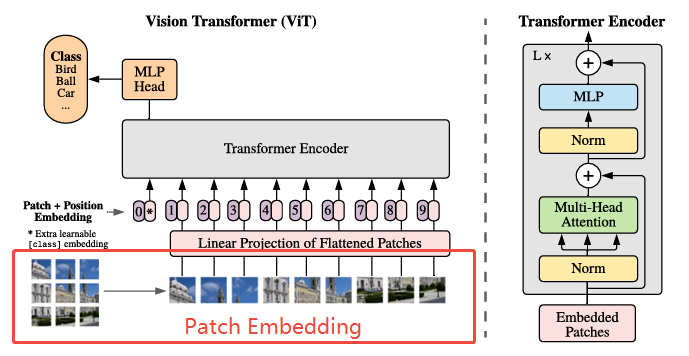
**假设假设输入图像大小为 224×224×3,Patch 大小为 16×16,则一张图像将被划分为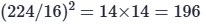 个 patch,而每个 Patch 将被展平成一个*16* x *16* x *3* *= 768* 维的向量,即可得到**一个
个 patch,而每个 Patch 将被展平成一个*16* x *16* x *3* *= 768* 维的向量,即可得到**一个[196, 768]的特征层,**将其展平成向量后,再通过一个 Linear 层映射到模型的 embedding 空间(手动设置,ViT-Base为 768 维,ViT-Large为1024,ViT-Huge为1280,通常使用768),最终我们就能得到一个形状为:[batch_size, 196, 768]的patch token 序列。
**
**
**
***2. cls_token + Position Embedding:*分类标记与位置编码模块
在完成 Patch Embedding 得到形如 [batch_size, 196, 768] 的 Patch Token 序列后,便可添加 [CLS] Token和添加位置编码(Positional Embedding)了:
-
添加 [CLS] Token —— 图像的“全局摘要”入口Transformer 最初在处理文本任务时,会在序列的最前面添加一个特殊的
[CLS]Token,用于聚合整个句子的语义信息。同理,在 ViT 中也引入了[CLS] Token,它并不代表某个具体的 Patch,而是作为一个全局的代表 Token,在 Transformer 中“参与”每一层的信息交互,最终用于提取整个图像的全局特征。如上图所示,编号为0*的那个位置即表示[CLS] Token,其初始值是一个可学习的参数向量,维度与 Patch Token 相同(例如 768),经过 Transformer 编码后,ViT 会使用这个[CLS] Token的输出向量作为图像的分类结果输入到 MLP Head 中,完成最终分类。 添加了
[CLS] Token之后,原本的196个Patch Token序列就变成了197个 Token,形状变为了形如:[batch_size, 196 + 1, 768]. -
添加位置编码(Positional Embedding)—— 帮助模型理解“图像中的位置"由于 Transformer 是完全基于自注意力机制构建的,它并不具备卷积网络中天然的位置信息建模能力。所以我们还需要给每个 Token 添加一个位置编码,用于告诉模型这个 Token 来自于图像的哪一块区域。ViT 采用的是一种 可学习的绝对位置编码,也就是为每一个 Token 的位置(包括
[CLS]Token)都初始化一个可学习的位置向量,并与原始 Token 相加,这样,模型就能在学习过程中自己掌握空间顺序和语义之间的关系。 位置编码的形状与输入序列一致,也是
[1, 196 + 1, 768],且位置编码的加入方式非常简单即:tokens = tokens + pos_embed # [B, 197, 768],经过这两个步骤之后,ViT 的输入才真正准备好,可以送入 Transformer 编码器中进行多层特征交互与建模。
至此cls_token + Position Embedding便完成啦!
3. Transformer 编码器(Multi-head Attention + LayerNorm + MLP + 残差连接)
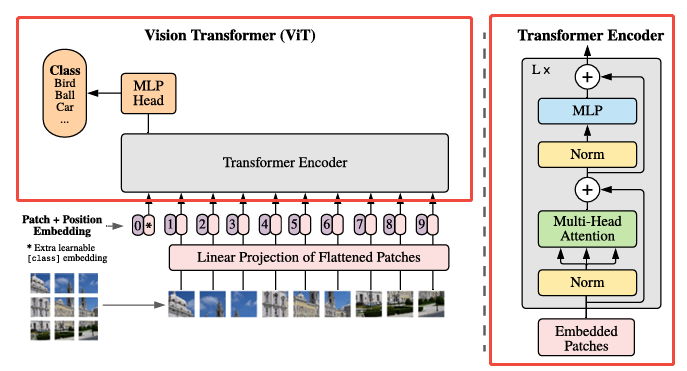
当我们得到了带有 [CLS] Token 和位置编码的完整 Patch 序列(形状为 [B, 197, 768])之后,ViT 会将其送入一系列标准的 *Transformer Encoder Block* 中进行深度建模。每一个 Block 的设计与原始的 NLP Transformer 中的 Encoder 保持一致,结构非常经典,由两个子模块组成:*LayerNorm + 多头自注意力机制(Multi-Head Self Attention) 和 **LayerNorm + MLP 前馈神经网络。具体实现机制可以研究标准Transformer Encoder的原理。***
4. Classification Head——*分类头*
*
*
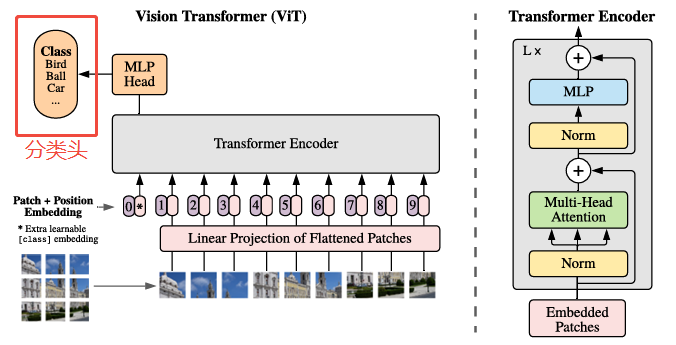
*经过多个 Transformer Block 的深度特征提取之后,我们得到了一个新的序列表示,其形状为 [B, 197, 768](假设我们使用的是 ViT-Base 模型),其中第一个位置的 Token 仍然是我们在最开始加入的 [CLS] Token。这个 [CLS] Token 可以看作是整个图像的全局语义表示,因为在多轮注意力交互中,它已经“融合”了所有 Patch 的信息。因此,我们只需要从序列中取出这一位置的向量(即第一个 Token),然后送入一个全连接层(Linear)就可以完成分类任务了。*
*
*
Vision Transformer中的关键组件
- **自注意力机制:**自注意力机制是 Transformer 架构的核心。它允许模型动态地权衡每个块相对于所有其他块的重要性,从而能够捕捉整个图像中复杂的依赖关系和上下文信息。
- **多头注意力机制:**ViT 并非依赖于单一的注意力机制,而是并行使用多个注意力“头”。每个头可以关注图像的不同方面或区域,从而使模型能够学习更丰富、更多样化的关系。
- **3. 前馈网络:**在自注意力层之后,每个块嵌入都会由前馈神经网络进一步处理。此步骤有助于模型捕捉更复杂的模式和表征。
- **4. 层归一化和残差连接:**为了稳定训练并提升性能,每个 Transformer 层都使用层归一化和残差(跳跃)连接。这些技术有助于维持深度网络中信息和梯度的流动。
Vision Transformer 与 CNN
ViT 和 CNN 代表了计算机视觉领域的两种截然不同的范式。CNN 长期以来一直是图像分析的支柱,利用卷积层提取局部特征并构建层次化表征。
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形(translation equivariance),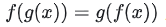 ,其中g代表卷积操作,f代表平移操作。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
,其中g代表卷积操作,f代表平移操作。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
相比之下,Vision Transformers 从一开始就使用自注意力机制来建模图像块之间的全局关系,从而使其能够捕捉图像中的长距离依赖关系和整体上下文。这种全局视角使 ViT 在大规模数据集和需要全面理解视觉内容的任务上的表现优于 CNN。缺点是 ViT 通常需要更多数据才能有效训练,并且通常计算量更大,尤其是在更高分辨率下。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
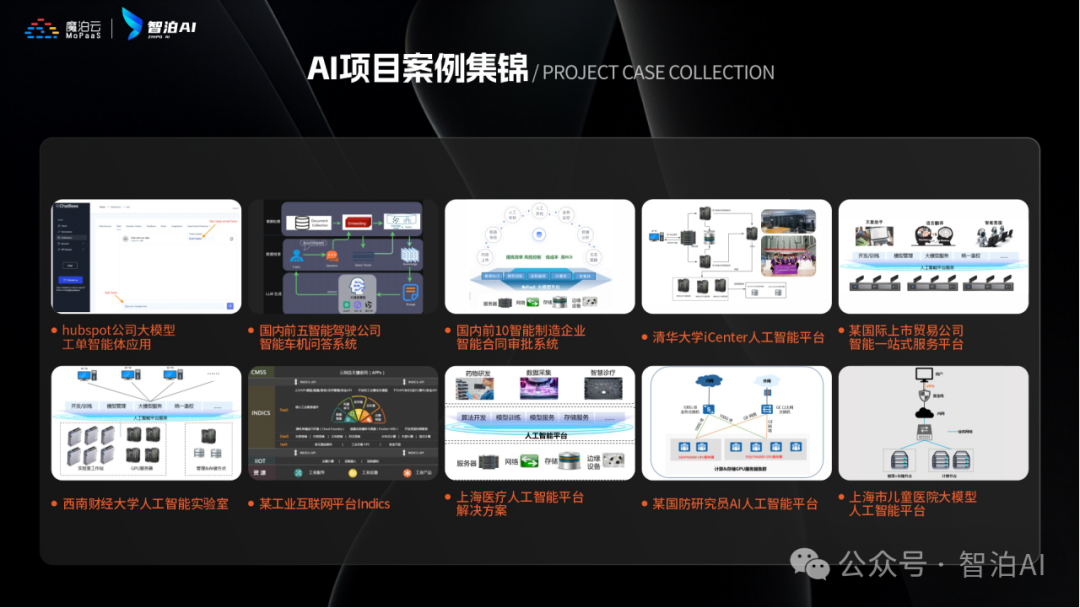
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

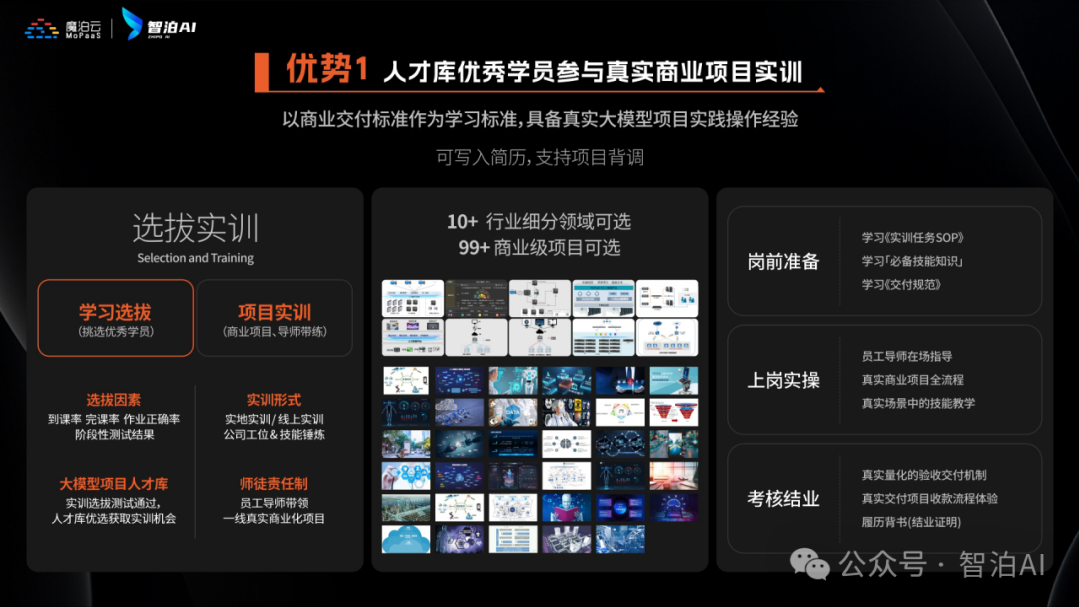
课程优势四:热门岗位全覆盖,匹配企业岗位需求
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
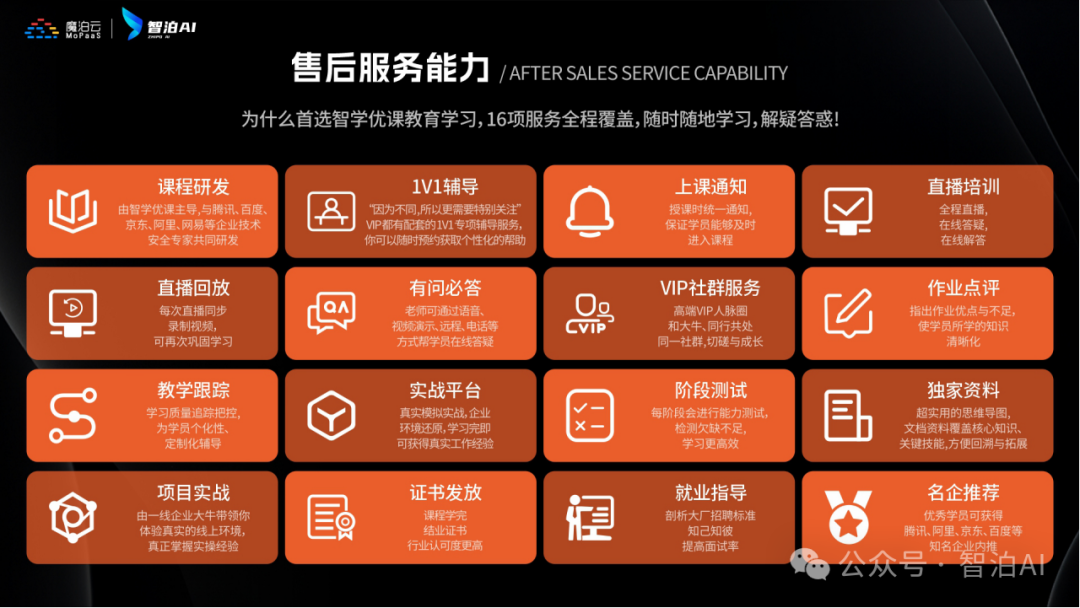
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)