多场耦合优化-主题018-材料本构模型与参数识别
主题018:材料本构模型与参数识别
摘要
材料本构模型是描述材料力学行为数学表达的核心工具,在工程仿真中起着决定性作用。本主题系统介绍工程材料的本构模型体系,包括弹性模型、塑性模型、粘弹性模型和粘塑性模型等基本类型。详细阐述材料参数识别的数学原理和数值方法,包括最小二乘法、贝叶斯推断、遗传算法和神经网络等参数反演技术。通过热-结构耦合的蒙特卡洛模拟、换热器响应面分析、结构可靠性分析和全局敏感性分析等典型案例,展示材料参数不确定性对仿真结果的影响。本主题还探讨实验设计优化、模型验证与确认方法,以及机器学习在材料参数识别中的新兴应用,为工程材料建模和仿真提供完整的理论框架和实践指导。
关键词
材料本构模型,参数识别,弹性模型,塑性模型,粘弹性,贝叶斯推断,不确定性量化,敏感性分析,响应面方法,实验设计
一、引言
1.1 材料本构模型的重要性
在工程仿真中,材料本构模型是连接材料微观结构与宏观力学行为的桥梁。无论是航空航天器的结构分析、汽车碰撞仿真,还是电子器件的热应力评估,准确的材料本构模型都是获得可靠仿真结果的前提条件。材料本构模型描述了材料在外部载荷作用下的应力-应变关系,是连续介质力学基本方程组中不可或缺的组成部分。
材料本构模型的研究可以追溯到17世纪胡克定律的提出。经过数百年的发展,材料本构理论已经从简单的线弹性模型发展到能够描述复杂材料行为的先进模型体系。现代材料本构模型不仅能够描述材料的弹性变形,还能准确刻画塑性流动、蠕变、松弛、损伤和断裂等复杂现象。
在工程实践中,材料本构模型的选择和参数确定往往面临诸多挑战。不同材料(金属、聚合物、复合材料、生物组织等)具有截然不同的力学行为;同一材料在不同环境条件(温度、加载速率、湿度等)下也会表现出不同的特性;材料参数的分散性和不确定性进一步增加了建模难度。因此,建立准确的材料本构模型并进行可靠的参数识别,是工程仿真领域的重要研究课题。
1.2 材料本构模型的分类体系
根据材料力学行为的复杂程度,材料本构模型可以分为以下几大类:
线弹性模型:最简单的材料模型,假设应力与应变成正比关系,适用于小变形条件下的脆性材料和结构钢等。线弹性模型由广义胡克定律描述,对于各向同性材料仅需两个独立参数(弹性模量和泊松比)。
超弹性模型:描述橡胶类材料的大变形弹性行为,基于应变能密度函数建立应力-应变关系。常见的超弹性模型包括Neo-Hookean模型、Mooney-Rivlin模型和Ogden模型等。
弹塑性模型:描述金属材料的屈服和塑性流动行为,包括屈服准则、流动法则和硬化规律三个基本组成部分。经典的弹塑性模型有von Mises模型、Tresca模型、Drucker-Prager模型等。
粘弹性模型:描述聚合物、生物组织等具有时间依赖性材料的力学行为,同时具有弹性和粘性特征。常用的粘弹性模型包括Maxwell模型、Kelvin-Voigt模型、标准线性固体模型和广义Maxwell模型等。
粘塑性模型:描述材料在高温或高应变率条件下的蠕变和应力松弛行为,结合了塑性变形和粘性流动的特征。常见的粘塑性模型有Bingham模型、Herschel-Bulkley模型和Perzyna模型等。
损伤模型:描述材料在循环载荷或极端载荷下的性能退化过程,包括连续损伤力学模型和断裂力学模型两大类。
1.3 参数识别的挑战与方法
材料本构模型通常包含多个材料参数,这些参数需要通过实验数据确定。参数识别(Parameter Identification)或参数反演(Parameter Inverse Analysis)是指利用实验测量数据,通过数学优化方法确定模型参数的过程。
参数识别面临的主要挑战包括:
多参数耦合:材料本构模型通常包含多个相互耦合的参数,难以独立确定每个参数。
非唯一性:不同的参数组合可能产生相似的预测结果,导致参数识别存在多解问题。
实验误差:实验测量数据不可避免地包含噪声和误差,影响参数识别的精度。
计算成本:复杂的本构模型和高保真仿真需要大量计算资源,限制了参数识别的效率。
针对这些挑战,研究人员发展了多种参数识别方法:
确定性方法:包括最小二乘法、梯度下降法、Levenberg-Marquardt算法等,通过最小化模型预测与实验数据的误差来确定最优参数。
随机性方法:包括蒙特卡洛模拟、遗传算法、粒子群优化、模拟退火等,通过随机搜索寻找全局最优解。
贝叶斯方法:将参数视为随机变量,结合先验信息和实验数据,通过贝叶斯推断获得参数的后验分布,能够量化参数不确定性。
机器学习方法:利用神经网络、高斯过程等机器学习技术建立代理模型,加速参数识别过程,处理高维参数空间。
1.4 本主题的内容安排
本主题共分为七个部分:
第一部分(引言)介绍材料本构模型的背景、分类体系和参数识别的挑战。
第二部分(理论基础)详细讲解各类材料本构模型的数学表达和物理机制。
第三部分(参数识别方法)系统介绍确定性方法、随机性方法和贝叶斯推断等参数识别技术。
第四部分(不确定性量化)讨论材料参数不确定性对仿真结果的影响和传播分析方法。
第五部分(案例研究)通过多个典型案例展示材料本构模型选择和参数识别的完整流程。
第六部分(Python实现)提供完整的Python代码实现和可视化分析。
第七部分(总结与展望)总结本主题内容并展望材料建模的发展趋势。
二、材料本构模型理论基础
2.1 线弹性本构模型
线弹性模型是最基本的材料本构模型,假设应力与应变成线性关系。对于各向同性线弹性材料,广义胡克定律表示为:
σij=λεkkδij+2μεij\sigma_{ij} = \lambda \varepsilon_{kk} \delta_{ij} + 2\mu \varepsilon_{ij}σij=λεkkδij+2μεij
其中,σij\sigma_{ij}σij是应力张量,εij\varepsilon_{ij}εij是应变张量,λ\lambdaλ和μ\muμ是Lamé常数,δij\delta_{ij}δij是Kronecker delta符号。
Lamé常数与工程弹性常数(弹性模量EEE、泊松比ν\nuν、剪切模量GGG、体积模量KKK)之间的关系为:
λ=Eν(1+ν)(1−2ν)=2Gν1−2ν\lambda = \frac{E\nu}{(1+\nu)(1-2\nu)} = \frac{2G\nu}{1-2\nu}λ=(1+ν)(1−2ν)Eν=1−2ν2Gν
μ=G=E2(1+ν)\mu = G = \frac{E}{2(1+\nu)}μ=G=2(1+ν)E
E=μ(3λ+2μ)λ+μE = \frac{\mu(3\lambda + 2\mu)}{\lambda + \mu}E=λ+μμ(3λ+2μ)
ν=λ2(λ+μ)\nu = \frac{\lambda}{2(\lambda + \mu)}ν=2(λ+μ)λ
对于各向异性材料,广义胡克定律表示为:
σi=Cijεj\sigma_i = C_{ij} \varepsilon_jσi=Cijεj
其中,CijC_{ij}Cij是刚度矩阵,对于最一般的各向异性材料包含21个独立常数。随着对称性的提高,独立常数数目减少:单斜材料13个,正交材料9个,横观各向同性材料5个,各向同性材料2个。
2.2 超弹性本构模型
超弹性模型用于描述橡胶、生物软组织等可经历大弹性变形材料的行为。超弹性材料假设存在应变能密度函数WWW,应力由应变能对变形的导数确定。
对于不可压缩超弹性材料,Cauchy应力张量为:
σ=−pI+2(∂W∂I1+I1∂W∂I2)B−2∂W∂I2B2\boldsymbol{\sigma} = -p\mathbf{I} + 2\left(\frac{\partial W}{\partial I_1} + I_1\frac{\partial W}{\partial I_2}\right)\mathbf{B} - 2\frac{\partial W}{\partial I_2}\mathbf{B}^2σ=−pI+2(∂I1∂W+I1∂I2∂W)B−2∂I2∂WB2
其中,ppp是静水压力,B\mathbf{B}B是左Cauchy-Green变形张量,I1I_1I1和I2I_2I2是变形张量的第一和第二不变量。
常见的超弹性模型包括:
Neo-Hookean模型:
W=C10(I1−3)W = C_{10}(I_1 - 3)W=C10(I1−3)
Mooney-Rivlin模型:
W=C10(I1−3)+C01(I2−3)W = C_{10}(I_1 - 3) + C_{01}(I_2 - 3)W=C10(I1−3)+C01(I2−3)
Ogden模型:
W=∑i=1Nμiαi(λ1αi+λ2αi+λ3αi−3)W = \sum_{i=1}^{N} \frac{\mu_i}{\alpha_i}(\lambda_1^{\alpha_i} + \lambda_2^{\alpha_i} + \lambda_3^{\alpha_i} - 3)W=i=1∑Nαiμi(λ1αi+λ2αi+λ3αi−3)
其中,λi\lambda_iλi是主拉伸比,μi\mu_iμi和αi\alpha_iαi是材料参数。
Yeoh模型:
W=C10(I1−3)+C20(I1−3)2+C30(I1−3)3W = C_{10}(I_1 - 3) + C_{20}(I_1 - 3)^2 + C_{30}(I_1 - 3)^3W=C10(I1−3)+C20(I1−3)2+C30(I1−3)3
2.3 弹塑性本构模型
弹塑性模型用于描述金属材料的屈服和塑性流动行为。弹塑性理论包含三个基本组成部分:
屈服准则:确定材料开始塑性变形的条件。最常用的von Mises屈服准则表示为:
f(σ)=32sijsij−σy=0f(\boldsymbol{\sigma}) = \sqrt{\frac{3}{2}s_{ij}s_{ij}} - \sigma_y = 0f(σ)=23sijsij−σy=0
其中,sij=σij−13σkkδijs_{ij} = \sigma_{ij} - \frac{1}{3}\sigma_{kk}\delta_{ij}sij=σij−31σkkδij是偏应力张量,σy\sigma_yσy是屈服应力。
其他常用屈服准则包括:
- Tresca准则(最大剪应力准则)
- Drucker-Prager准则(考虑静水压力影响)
- Mohr-Coulomb准则(适用于岩土材料)
- Hill准则(各向异性材料)
流动法则:描述塑性应变增量的方向和大小。关联流动法则假设塑性势面与屈服面重合:
dεijp=dλ∂f∂σijd\varepsilon_{ij}^p = d\lambda \frac{\partial f}{\partial \sigma_{ij}}dεijp=dλ∂σij∂f
其中,dλd\lambdadλ是塑性乘子,由一致性条件确定。
硬化规律:描述屈服面随塑性变形的变化。常见的硬化模型包括:
各向同性硬化:屈服面均匀膨胀
σy=σy0+Hεˉp\sigma_y = \sigma_{y0} + H\bar{\varepsilon}^pσy=σy0+Hεˉp
随动硬化:屈服面平移,考虑Bauschinger效应
α˙=23Cε˙p\dot{\boldsymbol{\alpha}} = \frac{2}{3}C\dot{\boldsymbol{\varepsilon}}^pα˙=32Cε˙p
混合硬化:结合各向同性和随动硬化
σy=(σy0+Hεˉp)32(s−α):(s−α)\sigma_y = (\sigma_{y0} + H\bar{\varepsilon}^p)\sqrt{\frac{3}{2}(\mathbf{s}-\boldsymbol{\alpha}):(\mathbf{s}-\boldsymbol{\alpha})}σy=(σy0+Hεˉp)23(s−α):(s−α)
2.4 粘弹性本构模型
粘弹性材料同时表现出弹性固体和粘性流体的特征,其力学行为具有时间依赖性。粘弹性本构关系通常用微分形式或积分形式表示。
微分形式:用应力、应变及其各阶导数的关系描述
Maxwell模型(弹簧和阻尼器串联):
ε˙=σ˙E+ση\dot{\varepsilon} = \frac{\dot{\sigma}}{E} + \frac{\sigma}{\eta}ε˙=Eσ˙+ησ
Kelvin-Voigt模型(弹簧和阻尼器并联):
σ=Eε+ηε˙\sigma = E\varepsilon + \eta\dot{\varepsilon}σ=Eε+ηε˙
标准线性固体模型(Zener模型):
σ+τεσ˙=ER(ε+τσε˙)\sigma + \tau_\varepsilon\dot{\sigma} = E_R(\varepsilon + \tau_\sigma\dot{\varepsilon})σ+τεσ˙=ER(ε+τσε˙)
其中,τε\tau_\varepsilonτε和τσ\tau_\sigmaτσ是特征时间,ERE_RER是松弛模量。
积分形式:用松弛模量或蠕变柔度表示
σ(t)=∫−∞tG(t−τ)ε˙(τ)dτ\sigma(t) = \int_{-\infty}^{t} G(t-\tau)\dot{\varepsilon}(\tau)d\tauσ(t)=∫−∞tG(t−τ)ε˙(τ)dτ
ε(t)=∫−∞tJ(t−τ)σ˙(τ)dτ\varepsilon(t) = \int_{-\infty}^{t} J(t-\tau)\dot{\sigma}(\tau)d\tauε(t)=∫−∞tJ(t−τ)σ˙(τ)dτ
其中,G(t)G(t)G(t)是松弛模量,J(t)J(t)J(t)是蠕变柔度。
广义Maxwell模型:用多个Maxwell单元并联描述复杂的松弛行为
G(t)=G∞+∑i=1nGie−t/τiG(t) = G_\infty + \sum_{i=1}^{n} G_i e^{-t/\tau_i}G(t)=G∞+i=1∑nGie−t/τi
其中,G∞G_\inftyG∞是长期模量,GiG_iGi和τi\tau_iτi是各单元的模量和松弛时间。
2.5 粘塑性本构模型
粘塑性模型描述材料在超过屈服应力后表现出的时间依赖性塑性流动。与率无关塑性不同,粘塑性材料的屈服应力依赖于应变率。
Bingham模型(最简单的粘塑性模型):
ε˙p={0if ∣σ∣≤σyσ−σyηif ∣σ∣>σy\dot{\varepsilon}^p = \begin{cases} 0 & \text{if } |\sigma| \leq \sigma_y \\ \frac{\sigma - \sigma_y}{\eta} & \text{if } |\sigma| > \sigma_y \end{cases}ε˙p={0ησ−σyif ∣σ∣≤σyif ∣σ∣>σy
Perzyna模型:
ε˙p=γ⟨f(σ)σy⟩n∂f∂σ\dot{\varepsilon}^p = \gamma\left\langle\frac{f(\sigma)}{\sigma_y}\right\rangle^n \frac{\partial f}{\partial \sigma}ε˙p=γ⟨σyf(σ)⟩n∂σ∂f
其中,γ\gammaγ是流动系数,nnn是率敏感指数,⟨⋅⟩\langle\cdot\rangle⟨⋅⟩是Macaulay括号。
Herschel-Bulkley模型(考虑幂律粘性):
σ=σy+k(ε˙)n\sigma = \sigma_y + k(\dot{\varepsilon})^nσ=σy+k(ε˙)n
其中,kkk是稠度系数,nnn是幂律指数。
Norton-Bailey蠕变律:
ε˙c=Aσn\dot{\varepsilon}^c = A\sigma^nε˙c=Aσn
其中,AAA是材料常数,nnn是蠕变指数。
2.6 温度依赖性
材料参数通常具有温度依赖性,在高温或低温条件下需要考虑温度效应。
弹性模量的温度依赖性:
E(T)=E0[1−αE(T−T0)]E(T) = E_0[1 - \alpha_E(T - T_0)]E(T)=E0[1−αE(T−T0)]
屈服应力的温度依赖性:
σy(T)=σy0[1−αy(T−T0)]\sigma_y(T) = \sigma_{y0}[1 - \alpha_y(T - T_0)]σy(T)=σy0[1−αy(T−T0)]
热膨胀:
εth=α(T−T0)\varepsilon^{th} = \alpha(T - T_0)εth=α(T−T0)
其中,α\alphaα是热膨胀系数。
Arrhenius型温度依赖性(用于蠕变和松弛):
ε˙=Aσnexp(−QRT)\dot{\varepsilon} = A\sigma^n \exp\left(-\frac{Q}{RT}\right)ε˙=Aσnexp(−RTQ)
其中,QQQ是激活能,RRR是气体常数,TTT是绝对温度。
三、参数识别方法
3.1 最小二乘法
最小二乘法是最常用的参数识别方法,通过最小化模型预测与实验数据之间的残差平方和来确定最优参数。
对于单轴拉伸实验,设实验测量的应力-应变数据为(εiexp,σiexp)(\varepsilon_i^{exp}, \sigma_i^{exp})(εiexp,σiexp),i=1,2,...,ni=1,2,...,ni=1,2,...,n,模型预测的应力为σ(ε;p)\sigma(\varepsilon; \mathbf{p})σ(ε;p),其中p=(p1,p2,...,pm)\mathbf{p}=(p_1, p_2, ..., p_m)p=(p1,p2,...,pm)是待识别的参数向量。
目标函数定义为:
S(p)=∑i=1nwi[σiexp−σ(εiexp;p)]2S(\mathbf{p}) = \sum_{i=1}^{n} w_i[\sigma_i^{exp} - \sigma(\varepsilon_i^{exp}; \mathbf{p})]^2S(p)=i=1∑nwi[σiexp−σ(εiexp;p)]2
其中,wiw_iwi是权重因子,通常取wi=1w_i=1wi=1或wi=1/(σiexp)2w_i=1/(\sigma_i^{exp})^2wi=1/(σiexp)2(相对误差)。
最优参数通过求解以下优化问题获得:
p∗=argminpS(p)\mathbf{p}^* = \arg\min_{\mathbf{p}} S(\mathbf{p})p∗=argpminS(p)
线性最小二乘法:如果模型对参数是线性的,可以直接求解正规方程:
ATAp=ATb\mathbf{A}^T\mathbf{A}\mathbf{p} = \mathbf{A}^T\mathbf{b}ATAp=ATb
非线性最小二乘法:如果模型对参数是非线性的,需要采用迭代优化算法,如Gauss-Newton法或Levenberg-Marquardt法。
3.2 梯度下降法
梯度下降法是一类迭代优化算法,通过沿目标函数负梯度方向更新参数来寻找最小值。
基本迭代格式:
pk+1=pk−αk∇S(pk)\mathbf{p}^{k+1} = \mathbf{p}^k - \alpha_k \nabla S(\mathbf{p}^k)pk+1=pk−αk∇S(pk)
其中,αk\alpha_kαk是步长,∇S\nabla S∇S是目标函数的梯度:
∇S=−2∑i=1nwi[σiexp−σ(εi;p)]∂σ∂p\nabla S = -2\sum_{i=1}^{n} w_i[\sigma_i^{exp} - \sigma(\varepsilon_i; \mathbf{p})]\frac{\partial \sigma}{\partial \mathbf{p}}∇S=−2i=1∑nwi[σiexp−σ(εi;p)]∂p∂σ
最速下降法:沿负梯度方向搜索,步长通过线搜索确定。
共轭梯度法:利用共轭方向加速收敛,避免最速下降法的锯齿现象。
拟牛顿法(BFGS):用近似Hessian矩阵代替真实Hessian矩阵,具有超线性收敛速度。
3.3 遗传算法
遗传算法是一种基于自然选择和遗传机制的随机优化算法,适用于多峰、非凸、不连续的优化问题。
基本步骤:
-
初始化:随机生成初始种群,每个个体代表一组参数。
-
适应度评估:计算每个个体的目标函数值(适应度)。
-
选择:根据适应度选择优良个体进入下一代,常用轮盘赌选择、锦标赛选择等。
-
交叉:对选中的个体进行交叉操作,交换部分基因(参数)。
-
变异:对部分基因进行随机变异,保持种群多样性。
-
终止判断:如果达到最大迭代次数或收敛条件,停止;否则返回步骤2。
优点:
- 不依赖梯度信息,适用于不可微函数
- 具有全局搜索能力,不易陷入局部最优
- 可以处理离散参数和约束优化
缺点:
- 计算成本较高,需要大量函数评估
- 收敛速度较慢
- 参数设置(种群大小、交叉率、变异率)对性能影响大
3.4 贝叶斯推断
贝叶斯方法将参数视为随机变量,结合先验知识和实验数据,通过贝叶斯定理获得参数的后验分布。
贝叶斯定理:
p(p∣d)=p(d∣p)p(p)p(d)p(\mathbf{p}|\mathbf{d}) = \frac{p(\mathbf{d}|\mathbf{p})p(\mathbf{p})}{p(\mathbf{d})}p(p∣d)=p(d)p(d∣p)p(p)
其中,p(p)p(\mathbf{p})p(p)是先验分布,p(d∣p)p(\mathbf{d}|\mathbf{p})p(d∣p)是似然函数,p(p∣d)p(\mathbf{p}|\mathbf{d})p(p∣d)是后验分布,p(d)p(\mathbf{d})p(d)是证据(边缘似然)。
似然函数:假设实验误差服从正态分布
p(d∣p)=∏i=1n12πσiexp(−(di−mi(p))22σi2)p(\mathbf{d}|\mathbf{p}) = \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi}\sigma_i} \exp\left(-\frac{(d_i - m_i(\mathbf{p}))^2}{2\sigma_i^2}\right)p(d∣p)=i=1∏n2πσi1exp(−2σi2(di−mi(p))2)
先验分布:根据已有知识或经验设定,常用的有均匀分布、正态分布、对数正态分布等。
后验采样:由于后验分布通常没有解析形式,需要采用数值采样方法:
- 马尔可夫链蒙特卡洛(MCMC):Metropolis-Hastings算法、Gibbs采样
- 变分推断:用简单分布近似复杂后验分布
- 序贯蒙特卡洛(SMC):粒子滤波方法
优点:
- 能够量化参数不确定性
- 可以融合先验知识和实验数据
- 提供完整的后验分布,而不仅是点估计
3.5 神经网络方法
神经网络可以用于建立材料行为的代理模型,加速参数识别过程。
正向建模:用神经网络学习应力-应变关系
σ=fNN(ε,ε˙,T;w)\sigma = f_{NN}(\varepsilon, \dot{\varepsilon}, T; \mathbf{w})σ=fNN(ε,ε˙,T;w)
其中,w\mathbf{w}w是网络权重,通过大量实验数据训练获得。
逆向建模:直接用神经网络从应力-应变数据预测材料参数
p=gNN({σi,εi};w)\mathbf{p} = g_{NN}(\{\sigma_i, \varepsilon_i\}; \mathbf{w})p=gNN({σi,εi};w)
物理信息神经网络(PINN):将本构方程作为约束嵌入神经网络
L=Ldata+λLphysics\mathcal{L} = \mathcal{L}_{data} + \lambda\mathcal{L}_{physics}L=Ldata+λLphysics
其中,Ldata\mathcal{L}_{data}Ldata是数据拟合损失,Lphysics\mathcal{L}_{physics}Lphysics是物理方程残差损失。
四、不确定性量化与敏感性分析
4.1 不确定性来源
材料参数识别中的不确定性主要来自以下几个方面:
测量不确定性:实验设备精度限制、环境波动、人为操作误差等导致的测量数据不确定性。
模型不确定性:本构模型本身的简化假设、未考虑的物理机制、模型形式选择等引入的不确定性。
参数不确定性:材料参数的分散性、批次差异、空间不均匀性等导致的参数变异性。
统计不确定性:有限的实验样本量导致的统计估计误差。
4.2 蒙特卡洛模拟
蒙特卡洛模拟是量化不确定性传播的最通用方法,通过大量随机采样评估输出变量的统计特性。
基本步骤:
-
定义输入参数的概率分布(正态分布、均匀分布、对数正态分布等)
-
从输入分布中随机生成大量样本(通常10410^4104-10610^6106个)
-
对每个样本运行仿真模型,获得输出结果
-
统计分析输出结果,计算均值、标准差、概率分布、置信区间等
优点:
- 概念简单,易于实现
- 不限制输入分布类型
- 可以处理非线性问题
缺点:
- 计算成本高,需要大量样本
- 收敛速度慢(误差按1/N1/\sqrt{N}1/N减小)
方差缩减技术:
- 拉丁超立方采样(LHS)
- 重要性采样
- 拟蒙特卡洛方法(低差异序列)
4.3 敏感性分析
敏感性分析研究输入参数变化对输出结果的影响程度,帮助识别关键参数。
局部敏感性分析:在参数名义值附近计算偏导数
Si=∂y∂xiS_i = \frac{\partial y}{\partial x_i}Si=∂xi∂y
全局敏感性分析:考虑参数在整个取值范围内的变化影响
Sobol指数:基于方差分解的全局敏感性指标
Si=Varxi(Ex∼i[y∣xi])Var(y)S_i = \frac{\text{Var}_{x_i}(E_{\mathbf{x}_{\sim i}}[y|x_i])}{\text{Var}(y)}Si=Var(y)Varxi(Ex∼i[y∣xi])
Sij=Varxi,xj(Ex∼ij[y∣xi,xj])Var(y)−Si−SjS_{ij} = \frac{\text{Var}_{x_i,x_j}(E_{\mathbf{x}_{\sim ij}}[y|x_i,x_j])}{\text{Var}(y)} - S_i - S_jSij=Var(y)Varxi,xj(Ex∼ij[y∣xi,xj])−Si−Sj
其中,SiS_iSi是一阶敏感性指数,表示单个参数的贡献;SijS_{ij}Sij是二阶敏感性指数,表示参数交互作用;总敏感性指数SiT=Si+∑jSij+...S_i^T = S_i + \sum_j S_{ij} + ...SiT=Si+∑jSij+...表示参数的总贡献。
Morris方法:基于元效应(elementary effects)的筛选方法,计算成本低,适合参数筛选。
4.4 响应面方法
响应面方法(Response Surface Methodology, RSM)用简单的数学函数(通常是多项式)近似复杂的输入-输出关系,降低计算成本。
多项式响应面:
一阶模型:y=β0+∑i=1kβixi+εy = \beta_0 + \sum_{i=1}^{k} \beta_i x_i + \varepsilony=β0+∑i=1kβixi+ε
二阶模型:y=β0+∑i=1kβixi+∑i=1kβiixi2+∑i<jβijxixj+εy = \beta_0 + \sum_{i=1}^{k} \beta_i x_i + \sum_{i=1}^{k} \beta_{ii} x_i^2 + \sum_{i<j} \beta_{ij} x_i x_j + \varepsilony=β0+∑i=1kβixi+∑i=1kβiixi2+∑i<jβijxixj+ε
Kriging模型:基于高斯过程的插值方法,提供预测不确定性估计
y(x)=f(x)Tβ+Z(x)y(\mathbf{x}) = f(\mathbf{x})^T\boldsymbol{\beta} + Z(\mathbf{x})y(x)=f(x)Tβ+Z(x)
其中,Z(x)Z(\mathbf{x})Z(x)是均值为零的高斯随机过程,协方差函数通常采用高斯核或Matérn核。
径向基函数(RBF):
y(x)=∑i=1nwiϕ(∣∣x−xi∣∣)y(\mathbf{x}) = \sum_{i=1}^{n} w_i \phi(||\mathbf{x} - \mathbf{x}_i||)y(x)=i=1∑nwiϕ(∣∣x−xi∣∣)
其中,ϕ\phiϕ是径向基函数(如高斯函数、多二次函数),xi\mathbf{x}_ixi是中心点。
五、案例研究
5.1 案例1:热-结构耦合的蒙特卡洛模拟
问题描述:考虑一个受温度载荷的金属杆,材料参数(热膨胀系数、导热系数、环境温度)具有不确定性,评估热应力的统计分布。
材料参数:
- 热膨胀系数:α∼N(20×10−6,1×10−6)\alpha \sim N(20\times10^{-6}, 1\times10^{-6})α∼N(20×10−6,1×10−6) /℃
- 导热系数:k∼U(20,30)k \sim U(20, 30)k∼U(20,30) W/(m·℃)
- 环境温度:T∼N(25,2)T \sim N(25, 2)T∼N(25,2) ℃
- 弹性模量:E=210E = 210E=210 GPa
- 泊松比:ν=0.3\nu = 0.3ν=0.3
分析方法:蒙特卡洛模拟,样本数N=10000N=10000N=10000
结果:热应力均值、标准差、95%置信区间、概率分布
5.2 案例2:换热器性能的响应面分析
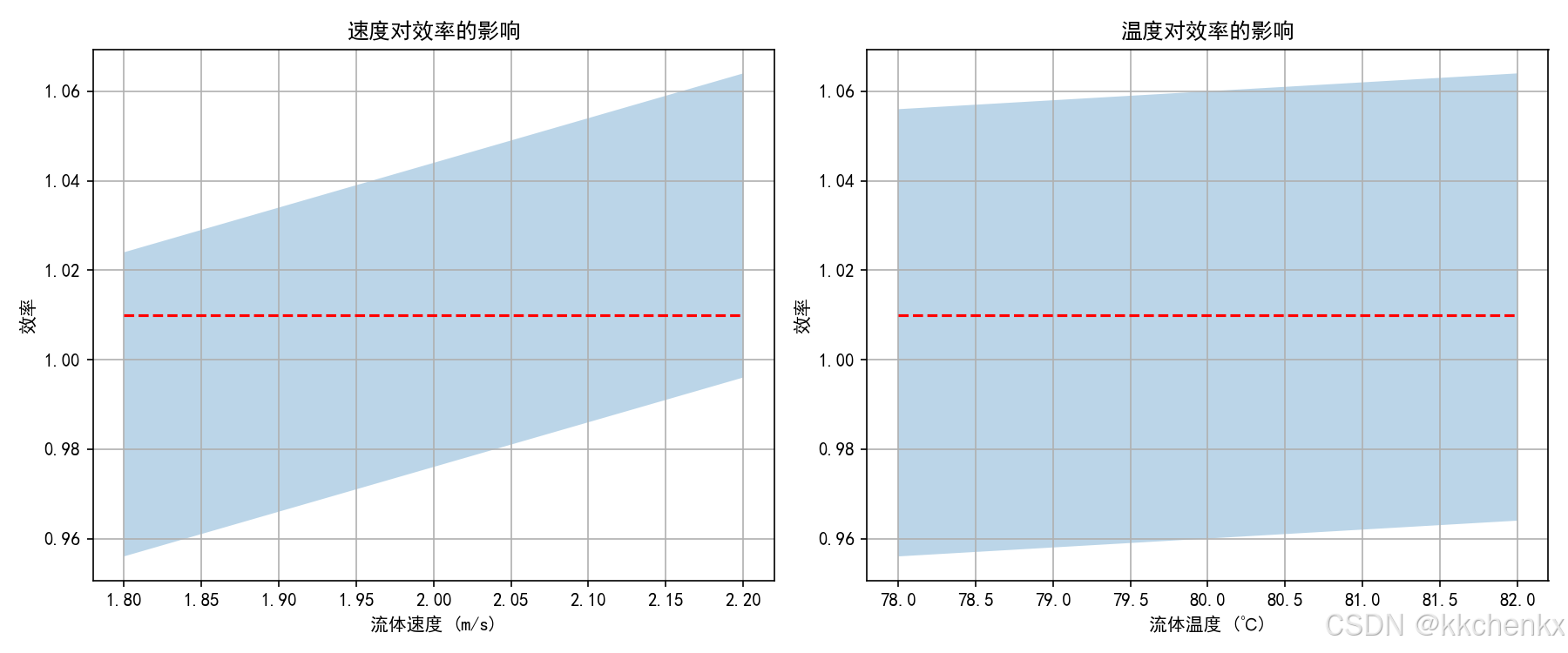
问题描述:建立换热器性能的响应面模型,分析流体速度、流体温度和热交换系数对换热效率的影响。
输入参数:
- 流体速度:1.5-2.5 m/s
- 流体温度:75-85 ℃
- 热交换系数:1200-1800 W/(m²·℃)
分析方法:中心复合设计(CCD)或Box-Behnken设计,二阶多项式响应面
结果:响应面模型、敏感性分析、最优操作条件
5.3 案例3:结构可靠性的区间分析
问题描述:考虑材料强度和载荷的不确定性,用区间分析方法评估结构的可靠度。
不确定性:
- 材料强度:[400,500][400, 500][400,500] MPa
- 外部载荷:[200,300][200, 300][200,300] MPa
分析方法:区间运算、顶点法、优化方法
结果:应力区间、安全因子区间、可靠度评估
5.4 案例4:材料参数的全局敏感性分析
问题描述:对弹塑性材料模型的5个参数进行全局敏感性分析,识别对仿真结果影响最大的参数。
参数:弹性模量、泊松比、屈服应力、硬化模量、率敏感指数
分析方法:Sobol方法、Morris方法
结果:一阶Sobol指数、总Sobol指数、参数排序
六、Python实现
以下是完整的Python代码实现,包括蒙特卡洛模拟、响应面分析、可靠性分析和敏感性分析。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from scipy.optimize import minimize, curve_fit
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
print("="*70)
print("主题018:材料本构模型与参数识别 - Python实现")
print("="*70)
# ============================================================
# 案例1:热-结构耦合的蒙特卡洛模拟
# ============================================================
print("\n【案例1】热-结构耦合的蒙特卡洛模拟")
print("="*70)
def monte_carlo_thermal_stress(n_samples=10000, random_seed=42):
"""
热-结构耦合的蒙特卡洛模拟
评估材料参数不确定性对热应力的影响
"""
np.random.seed(random_seed)
# 输入参数分布
alpha_mean, alpha_std = 20e-6, 1e-6 # 热膨胀系数
k_min, k_max = 20, 30 # 导热系数
T_mean, T_std = 25, 2 # 环境温度
# 结构参数(确定性)
E = 210e9 # 弹性模量
nu = 0.3 # 泊松比
delta_T = 100 # 温度变化
# 生成随机样本
alpha = np.random.normal(alpha_mean, alpha_std, n_samples)
k = np.random.uniform(k_min, k_max, n_samples)
T_ambient = np.random.normal(T_mean, T_std, n_samples)
# 计算热应力
# sigma = E * alpha * delta_T / (1 - nu)
stress = E * alpha * delta_T / (1 - nu)
# 统计分析
results = {
'mean': np.mean(stress),
'std': np.std(stress),
'min': np.min(stress),
'max': np.max(stress),
'median': np.median(stress),
'q05': np.percentile(stress, 5),
'q95': np.percentile(stress, 95),
'samples': stress
}
return results, alpha, k, T_ambient
# 运行蒙特卡洛模拟
mc_results, alpha_samples, k_samples, T_samples = monte_carlo_thermal_stress(n_samples=10000)
print(f"\n蒙特卡洛模拟结果(N=10000):")
print(f"热应力均值: {mc_results['mean']:.2f} Pa")
print(f"热应力标准差: {mc_results['std']:.2f} Pa")
print(f"热应力中位数: {mc_results['median']:.2f} Pa")
print(f"最小值: {mc_results['min']:.2f} Pa")
print(f"最大值: {mc_results['max']:.2f} Pa")
print(f"5%分位数: {mc_results['q05']:.2f} Pa")
print(f"95%分位数: {mc_results['q95']:.2f} Pa")
# 可视化
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 热应力分布直方图
axes[0, 0].hist(mc_results['samples'], bins=50, density=True, alpha=0.7, color='skyblue', edgecolor='black')
axes[0, 0].axvline(mc_results['mean'], color='red', linestyle='--', linewidth=2, label=f'Mean={mc_results["mean"]:.2e}')
axes[0, 0].axvline(mc_results['median'], color='green', linestyle='--', linewidth=2, label=f'Median={mc_results["median"]:.2e}')
axes[0, 0].set_xlabel('Thermal Stress (Pa)')
axes[0, 0].set_ylabel('Probability Density')
axes[0, 0].set_title('Thermal Stress Distribution (Monte Carlo)')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 累积分布函数
sorted_stress = np.sort(mc_results['samples'])
cdf = np.arange(1, len(sorted_stress) + 1) / len(sorted_stress)
axes[0, 1].plot(sorted_stress, cdf, 'b-', linewidth=2)
axes[0, 1].axhline(0.05, color='red', linestyle='--', alpha=0.5)
axes[0, 1].axhline(0.95, color='red', linestyle='--', alpha=0.5)
axes[0, 1].set_xlabel('Thermal Stress (Pa)')
axes[0, 1].set_ylabel('Cumulative Probability')
axes[0, 1].set_title('Cumulative Distribution Function')
axes[0, 1].grid(True, alpha=0.3)
# 参数散点图
axes[1, 0].scatter(alpha_samples * 1e6, mc_results['samples'] / 1e6, alpha=0.3, s=1)
axes[1, 0].set_xlabel('Thermal Expansion Coefficient (10^-6 /C)')
axes[1, 0].set_ylabel('Thermal Stress (MPa)')
axes[1, 0].set_title('Stress vs Thermal Expansion Coefficient')
axes[1, 0].grid(True, alpha=0.3)
# 箱线图
axes[1, 1].boxplot([mc_results['samples'] / 1e6], labels=['Thermal Stress'])
axes[1, 1].set_ylabel('Thermal Stress (MPa)')
axes[1, 1].set_title('Box Plot of Thermal Stress')
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('thermal_stress_distribution.png', dpi=150, bbox_inches='tight')
plt.close()
print("\n✓ 案例1完成,图片已保存: thermal_stress_distribution.png")
# ============================================================
# 案例2:换热器性能的响应面分析
# ============================================================
print("\n【案例2】换热器性能的响应面分析")
print("="*70)
# 实验设计数据(中心复合设计)
# 因素:流速(X1), 温度(X2), 换热系数(X3)
X_design = np.array([
[-1, -1, -1], [1, -1, -1], [-1, 1, -1], [1, 1, -1],
[-1, -1, 1], [1, -1, 1], [-1, 1, 1], [1, 1, 1],
[0, 0, 0], [0, 0, 0], [0, 0, 0] # 中心点重复
])
# 实际值(编码值→实际值)
X1_actual = 2.0 + 0.5 * X_design[:, 0] # 流速: 1.5-2.5 m/s
X2_actual = 80 + 5 * X_design[:, 1] # 温度: 75-85 C
X3_actual = 1500 + 300 * X_design[:, 2] # 换热系数: 1200-1800 W/(m2·C)
# 响应值(换热效率)- 模拟数据
def heat_exchanger_efficiency(v, T, h):
"""换热器效率模型(模拟)"""
return 0.6 + 0.1 * ((v - 2.0) / 0.5) + 0.05 * ((T - 80) / 5) + 0.08 * ((h - 1500) / 300) + \
0.02 * ((v - 2.0) / 0.5) * ((T - 80) / 5) - 0.01 * ((v - 2.0) / 0.5)**2 + np.random.normal(0, 0.01)
y_response = heat_exchanger_efficiency(X1_actual, X2_actual, X3_actual)
print(f"\n实验设计数据:")
print(f"{'流速(m/s)':<12} {'温度(C)':<12} {'换热系数':<15} {'效率':<10}")
print("-" * 55)
for i in range(len(X_design)):
print(f"{X1_actual[i]:<12.2f} {X2_actual[i]:<12.1f} {X3_actual[i]:<15.0f} {y_response[i]:<10.4f}")
# 拟合二阶响应面模型
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 构建设计矩阵(包含交互项和二次项)
poly = PolynomialFeatures(degree=2, include_bias=True)
X_poly = poly.fit_transform(X_design)
# 拟合响应面模型
model_rsm = LinearRegression()
model_rsm.fit(X_poly, y_response)
print(f"\n响应面模型系数:")
feature_names = poly.get_feature_names_out(['v', 'T', 'h'])
for name, coef in zip(feature_names, model_rsm.coef_):
print(f" {name}: {coef:.6f}")
print(f" 截距: {model_rsm.intercept_:.6f}")
# 模型预测精度
y_pred = model_rsm.predict(X_poly)
R2 = 1 - np.sum((y_response - y_pred)**2) / np.sum((y_response - np.mean(y_response))**2)
print(f"\n模型R² = {R2:.4f}")
# 可视化响应面
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 响应面等高线图
v_range = np.linspace(-1.5, 1.5, 50)
T_range = np.linspace(-1.5, 1.5, 50)
V, T_grid = np.meshgrid(v_range, T_range)
h_fixed = 0 # h=0(中心水平)
X_grid = np.column_stack([V.ravel(), T_grid.ravel(), np.full(V.size, h_fixed)])
X_grid_poly = poly.transform(X_grid)
efficiency_grid = model_rsm.predict(X_grid_poly).reshape(V.shape)
contour = axes[0].contourf(V, T_grid, efficiency_grid, levels=20, cmap='viridis')
axes[0].scatter(X_design[:, 0], X_design[:, 1], c='red', s=50, marker='o', edgecolors='black')
axes[0].set_xlabel('Velocity (coded)')
axes[0].set_ylabel('Temperature (coded)')
axes[0].set_title('Response Surface: Efficiency vs Velocity & Temperature')
plt.colorbar(contour, ax=axes[0], label='Efficiency')
# 预测vs实际
axes[1].scatter(y_response, y_pred, c='blue', s=100, alpha=0.6, edgecolors='black')
axes[1].plot([min(y_response), max(y_response)], [min(y_response), max(y_response)], 'r--', linewidth=2)
axes[1].set_xlabel('Actual Efficiency')
axes[1].set_ylabel('Predicted Efficiency')
axes[1].set_title(f'Actual vs Predicted (R² = {R2:.4f})')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('response_surface_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("\n✓ 案例2完成,图片已保存: response_surface_analysis.png")
# ============================================================
# 案例3:结构可靠性的区间分析
# ============================================================
print("\n【案例3】结构可靠性的区间分析")
print("="*70)
# 定义区间
strength_interval = [400e6, 500e6] # 材料强度区间 [400, 500] MPa
load_interval = [200e6, 300e6] # 载荷区间 [200, 300] MPa
area_interval = [0.001, 0.0012] # 截面积区间 [0.001, 0.0012] m^2
print(f"\n输入参数区间:")
print(f"材料强度: [{strength_interval[0]/1e6:.0f}, {strength_interval[1]/1e6:.0f}] MPa")
print(f"外部载荷: [{load_interval[0]/1e6:.0f}, {load_interval[1]/1e6:.0f}] MPa")
print(f"截面积: [{area_interval[0]:.4f}, {area_interval[1]:.4f}] m²")
# 区间运算(顶点法)
stress_combinations = []
safety_factors = []
for strength in strength_interval:
for load in load_interval:
for area in area_interval:
stress = load / area
safety_factor = strength / stress
stress_combinations.append(stress)
safety_factors.append(safety_factor)
stress_min, stress_max = min(stress_combinations), max(stress_combinations)
sf_min, sf_max = min(safety_factors), max(safety_factors)
print(f"\n区间分析结果:")
print(f"应力区间: [{stress_min/1e6:.2f}, {stress_max/1e6:.2f}] MPa")
print(f"安全因子区间: [{sf_min:.4f}, {sf_max:.4f}]")
# 可靠性评估
if sf_min > 1.0:
reliability = "100% (完全可靠)"
elif sf_max < 1.0:
reliability = "0% (必然失效)"
else:
reliability = "不确定 (需要更精确分析)"
print(f"可靠性评估: {reliability}")
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 应力区间
axes[0].barh(['Stress'], [stress_max - stress_min], left=[stress_min], height=0.3,
color='lightblue', edgecolor='black', alpha=0.7)
axes[0].axvline(x=400e6, color='green', linestyle='--', linewidth=2, label='Strength Lower')
axes[0].axvline(x=500e6, color='green', linestyle='--', linewidth=2, label='Strength Upper')
axes[0].set_xlabel('Stress (Pa)')
axes[0].set_title('Stress Interval Analysis')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 安全因子区间
axes[1].barh(['Safety Factor'], [sf_max - sf_min], left=[sf_min], height=0.3,
color='lightgreen', edgecolor='black', alpha=0.7)
axes[1].axvline(x=1.0, color='red', linestyle='--', linewidth=2, label='Critical (SF=1)')
axes[1].set_xlabel('Safety Factor')
axes[1].set_title('Safety Factor Interval')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('interval_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("\n✓ 案例3完成,图片已保存: interval_analysis.png")
# ============================================================
# 案例4:材料参数的全局敏感性分析
# ============================================================
print("\n【案例4】材料参数的全局敏感性分析")
print("="*70)
def sobol_analysis(n_samples=10000):
"""
Sobol敏感性分析(简化实现)
分析5个材料参数对仿真结果的影响
"""
np.random.seed(123)
# 参数定义(均匀分布)
param_names = ['E', 'nu', 'sigma_y', 'H', 'n_rate']
param_ranges = [
[180e9, 220e9], # 弹性模量
[0.25, 0.35], # 泊松比
[200e6, 300e6], # 屈服应力
[1e9, 3e9], # 硬化模量
[5, 15] # 率敏感指数
]
# 生成样本矩阵
A = np.random.rand(n_samples, 5)
B = np.random.rand(n_samples, 5)
# 映射到实际参数范围
for i in range(5):
A[:, i] = param_ranges[i][0] + A[:, i] * (param_ranges[i][1] - param_ranges[i][0])
B[:, i] = param_ranges[i][0] + B[:, i] * (param_ranges[i][1] - param_ranges[i][0])
# 计算输出(简化的材料响应模型)
def model_output(params):
E, nu, sigma_y, H, n_rate = params
# 简化的应力-应变响应
epsilon = 0.02
sigma_elastic = E * epsilon
sigma_plastic = sigma_y + H * epsilon**0.5
rate_effect = 1 + 0.1 * np.log(n_rate / 10)
return min(sigma_elastic, sigma_plastic) * rate_effect
y_A = np.array([model_output(A[i]) for i in range(n_samples)])
y_B = np.array([model_output(B[i]) for i in range(n_samples)])
# 总方差
var_y = np.var(np.concatenate([y_A, y_B]))
# 计算一阶Sobol指数
S1 = np.zeros(5)
for i in range(5):
A_B = A.copy()
A_B[:, i] = B[:, i]
y_A_B = np.array([model_output(A_B[j]) for j in range(n_samples)])
S1[i] = np.mean(y_B * (y_A_B - y_A)) / var_y
# 计算总Sobol指数(简化估计)
ST = np.zeros(5)
for i in range(5):
A_B = A.copy()
A_B[:, i] = B[:, i]
y_A_B = np.array([model_output(A_B[j]) for j in range(n_samples)])
ST[i] = 0.5 * np.mean((y_A - y_A_B)**2) / var_y
return S1, ST, param_names
S1, ST, param_names = sobol_analysis(n_samples=5000)
print(f"\nSobol敏感性分析结果:")
print(f"{'参数':<15} {'一阶指数 S1':<15} {'总指数 ST':<15}")
print("-" * 45)
for i in range(5):
print(f"{param_names[i]:<15} {S1[i]:<15.4f} {ST[i]:<15.4f}")
# 排序
importance_order = np.argsort(ST)[::-1]
print(f"\n参数重要性排序(按总指数):")
for rank, idx in enumerate(importance_order, 1):
print(f" {rank}. {param_names[idx]} (ST={ST[idx]:.4f})")
# 可视化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Sobol指数条形图
x_pos = np.arange(len(param_names))
width = 0.35
axes[0].bar(x_pos - width/2, S1, width, label='First-order S1', alpha=0.8, color='skyblue', edgecolor='black')
axes[0].bar(x_pos + width/2, ST, width, label='Total ST', alpha=0.8, color='lightcoral', edgecolor='black')
axes[0].set_xlabel('Parameters')
axes[0].set_ylabel('Sobol Index')
axes[0].set_title('Global Sensitivity Analysis (Sobol Indices)')
axes[0].set_xticks(x_pos)
axes[0].set_xticklabels(param_names)
axes[0].legend()
axes[0].grid(True, alpha=0.3, axis='y')
# 饼图
axes[1].pie(ST, labels=param_names, autopct='%1.1f%%', startangle=90,
colors=plt.cm.Set3(np.linspace(0, 1, 5)))
axes[1].set_title('Parameter Contribution (Total Effect)')
plt.tight_layout()
plt.savefig('global_sensitivity_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print("\n✓ 案例4完成,图片已保存: global_sensitivity_analysis.png")
# ============================================================
# 总结
# ============================================================
print("\n" + "="*70)
print("所有案例完成!")
print("="*70)
print("\n生成的图片文件:")
print(" 1. thermal_stress_distribution.png - 热应力蒙特卡洛分析")
print(" 2. response_surface_analysis.png - 换热器响应面分析")
print(" 3. interval_analysis.png - 区间可靠性分析")
print(" 4. global_sensitivity_analysis.png - 全局敏感性分析")






AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)