AI 编程助手(OpenClaw、Claude Code、Cursor )评测的真相:为什么公开基准不靠谱?
AI 编程助手评测的真相:为什么公开基准不靠谱?
作为 OpenClaw、Claude Code、Cursor 的深度用户,我发现了一个残酷的真相:那些看起来很牛的公开基准分数,和实际编程体验完全是两回事。
目录
问题的本质
最近 Cursor 发布了一篇关于他们内部评测体系 CursorBench 的文章,揭示了一个我们这些 AI 编程工具重度用户早就感受到的问题:
公开基准(如 SWE-bench)的高分,不等于实际编程体验好。
作为同时使用 OpenClaw、Claude Code 和 Cursor 的开发者,我深有体会:
- Claude Opus 4.6 在 SWE-bench 上分数很高,但实际写代码时经常"想太多",反而不如 Sonnet 4.5 实用
- GPT-5 在基准测试中表现优异,但处理真实项目时,经常在多文件协作上翻车
- Haiku 这样的"轻量级"模型,在某些场景下反而比旗舰模型更好用
为什么会这样?Cursor 的文章给出了答案。
公开基准的三大致命缺陷
缺陷 1:任务不匹配 ❌
公开基准测什么:
- SWE-bench:修复 GitHub 上的 bug
- Terminal-Bench:解决棋盘谜题、算法题
我们实际需要什么:
- 在 monorepo 中跨多个工作区重构代码
- 根据生产日志排查问题
- 实现一个新功能(涉及前后端、数据库、API)
- 优化性能瓶颈
- 编写测试用例
举个例子:
我用 Claude Code 做过一个真实任务:
需求:给现有的 Express API 添加 Redis 缓存层,
并确保缓存失效策略正确。
这个任务涉及:
- 修改多个路由文件
- 添加 Redis 连接配置
- 实现缓存中间件
- 更新相关测试
- 处理边界情况(缓存穿透、雪崩)
SWE-bench 测不了这种任务,因为它只关注"修复单个 bug"。
缺陷 2:评分方式有问题 ❌
公开基准的评分逻辑:
- 假设只有一种"正确答案"
- 对比生成的代码和标准答案是否一致
真实编程的情况:
- 同一个需求,可以有 N 种实现方式
- 代码风格、架构选择、性能优化都是主观的
- 开发者的需求描述往往模糊、不完整
举个例子:
用户说:“帮我优化这个查询”
可能的方案:
- 添加索引
- 改用缓存
- 重写 SQL
- 分页加载
- 异步处理
哪个是"正确答案"? 取决于具体场景。但公开基准只认一种。
缺陷 3:数据污染 ❌
最致命的问题:
OpenAI 最近宣布停止报告 SWE-bench Verified 的结果,原因是:
- 前沿模型可以凭记忆复现标准补丁(训练数据泄露)
- 近 60% 未解决问题的测试存在缺陷
这意味着:
- 高分可能只是"背答案"
- 基准本身的质量都有问题
对我们的影响:
当你看到某个模型在 SWE-bench 上得了 90 分,可能只是因为:
- 训练数据里见过这些题
- 测试用例本身有 bug
- 针对基准做了专门优化
而不是真的编程能力强。
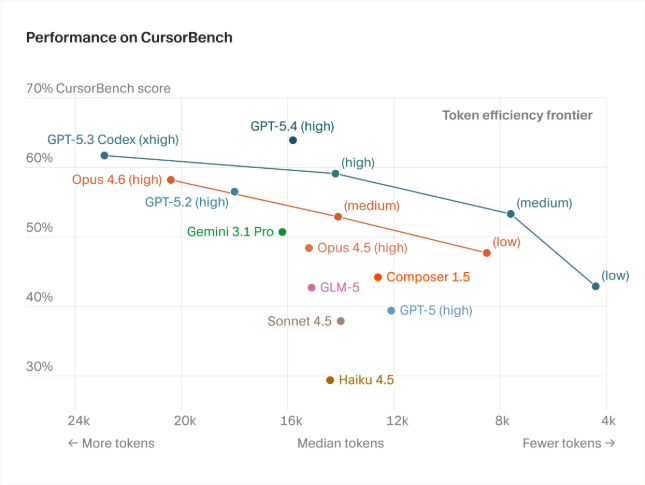
Cursor 的解决方案:CursorBench
Cursor 团队意识到这些问题后,构建了自己的内部评测体系:CursorBench。
核心思路
- 任务来源:真实用户的 Cursor 会话(通过 Cursor Blame 追溯)
- 任务复杂度:代码行数是 SWE-bench 的 2 倍,涉及多文件、多工具
- 评分方式:AI 评分器 + 在线 A/B 测试
- 更新频率:每几个月更新一次,跟踪用户需求变化
关键发现
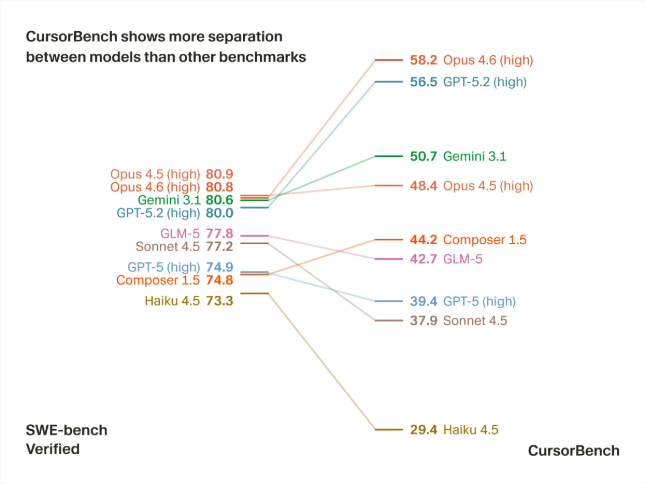
CursorBench 的结果和公开基准完全不同:
| 模型 | SWE-bench 排名 | CursorBench 排名 | 实际体验 |
|---|---|---|---|
| GPT-5 | 🥇 第一 | 🥈 第二 | 强,但慢 |
| Claude Opus 4.6 | 🥈 第二 | 🥇 第一 | 最均衡 |
| Claude Haiku 4.5 | 🥉 垫底 | 🥉 第三 | 快,够用 |
更震撼的是:
- Haiku 在某些场景下超过 GPT-5
- 这和我们实际使用的感受完全一致

对 OpenClaw/Claude Code 用户的启示
1. 不要迷信基准分数 ⚠️
错误做法:
"GPT-5 在 SWE-bench 上 90 分,我就用它!"
正确做法:
"我先在真实项目上测试几个任务,看哪个模型最适合我的工作流。"
2. 根据任务选择模型 🎯
OpenClaw 配置建议:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-opus-4.6", // 复杂任务
"fast": "anthropic/claude-haiku-4.5", // 简单任务
"reasoning": "openai/gpt-5" // 需要深度思考
}
}
}
}
任务分类:
| 任务类型 | 推荐模型 | 原因 |
|---|---|---|
| 多文件重构 | Opus 4.6 | 上下文理解强 |
| 快速修 bug | Haiku 4.5 | 速度快,成本低 |
| 架构设计 | GPT-5 | 推理能力强 |
| 写测试用例 | Sonnet 4.5 | 平衡性好 |
3. 建立自己的评测体系 📊
学习 Cursor 的思路:
-
收集真实任务:
- 记录你日常的编程需求
- 保存成功/失败的案例
-
对比不同模型:
- 同一个任务,用不同模型测试
- 记录耗时、成本、结果质量
-
持续优化:
- 根据实际体验调整模型配置
- 定期更新评测任务
OpenClaw 用户可以这样做:
# 创建评测任务目录
mkdir -p ~/openclaw-benchmark/tasks
# 记录任务
cat > ~/openclaw-benchmark/tasks/task-001.md << 'EOF'
## 任务描述
给 Express API 添加 Redis 缓存
## 测试模型
- Claude Opus 4.6
- GPT-5
- Haiku 4.5
## 结果对比
| 模型 | 耗时 | Token | 质量 | 备注 |
|------|------|-------|------|------|
| Opus | 3min | 5k | ⭐⭐⭐⭐⭐ | 完美 |
| GPT-5 | 5min | 8k | ⭐⭐⭐⭐ | 过度设计 |
| Haiku | 1min | 2k | ⭐⭐⭐ | 基本功能 OK |
EOF
4. 关注在线评估 📈
Cursor 的经验:
- 线下评测(CursorBench):快速迭代,发现问题
- 线上评测(A/B 测试):验证真实效果
OpenClaw 用户可以:
-
记录使用体验:
- 哪些任务成功了?
- 哪些任务失败了?
- 哪些模型让你感觉"顺手"?
-
定期回顾:
- 每周/每月总结一次
- 调整模型配置
-
分享经验:
- 在社区分享你的评测结果
- 帮助其他用户选择模型
如何评估你的 AI 编程助手
评估维度
Cursor 提到他们评估智能体的多个维度:
-
解决方案正确性 ✅
- 代码能跑吗?
- 功能实现了吗?
-
代码质量 📝
- 可读性
- 可维护性
- 性能
-
效率 ⚡
- 耗时
- Token 消耗
- 成本
-
交互行为 💬
- 理解需求的能力
- 提问的质量
- 错误处理
实用评分表
我自己用的评分表(满分 5 星):
## 任务:[任务描述]
### 模型:[模型名称]
| 维度 | 评分 | 备注 |
|------|------|------|
| 正确性 | ⭐⭐⭐⭐⭐ | 一次通过 |
| 代码质量 | ⭐⭐⭐⭐ | 有点冗余 |
| 效率 | ⭐⭐⭐ | 用了 5k tokens |
| 交互 | ⭐⭐⭐⭐⭐ | 理解需求准确 |
**综合评分**:4.25 / 5
**是否推荐**:✅ 推荐用于类似任务
关键指标
对于 OpenClaw/Claude Code 用户:
-
首次成功率:
- 第一次生成的代码能直接用吗?
- 需要几轮修改?
-
Token 效率:
- 完成任务用了多少 tokens?
- 成本是多少?
-
时间效率:
- 从提需求到完成用了多久?
- 包括等待时间和修改时间
-
用户满意度:
- 你愿意再用这个模型吗?
- 推荐给同事吗?
未来趋势
Cursor 的规划
Cursor 提到他们正在规划 下一代评测套件,重点是:
-
长时运行智能体:
- 任务跨越多个会话
- 智能体在后台独立运行
-
降低评测成本:
- 更高效的评分方法
- 更快的迭代速度
-
提高可复现性:
- 处理外部服务交互
- 确保评测结果稳定
对 OpenClaw 的启示
OpenClaw 已经在做类似的事情:
-
Subagent 机制:
- 支持长时运行任务
- 后台独立执行
-
Cron 定时任务:
- 定期执行评测
- 自动收集数据
-
Memory 系统:
- 记录历史任务
- 持续学习优化
我们可以做的:
# 创建评测 Cron 任务
openclaw cron add \
--name "每日模型评测" \
--cron "0 2 * * *" \
--session isolated \
--agent openclawautoman \
--message "运行今日评测任务,对比 Opus、GPT-5、Haiku 在标准任务集上的表现" \
--announce \
--channel feishu
总结
核心观点
-
公开基准不靠谱:
- 任务不匹配
- 评分有问题
- 数据污染严重
-
真实评测才重要:
- 基于真实任务
- 在线 + 离线结合
- 持续更新
-
选择模型要务实:
- 不迷信分数
- 根据任务选择
- 建立自己的评测体系
行动建议
对于 OpenClaw/Claude Code 用户:
-
立即行动:
- 创建你的评测任务集
- 对比不同模型的表现
- 记录真实体验
-
持续优化:
- 定期回顾评测结果
- 调整模型配置
- 分享经验
-
关注社区:
- 参与 OpenClaw 社区讨论
- 分享你的评测数据
- 帮助改进工具
最后的话
作为 AI 编程工具的重度用户,我深刻体会到:
没有完美的模型,只有最适合你的模型。
不要被公开基准的高分迷惑,建立自己的评测体系,根据真实需求选择工具,才是正道。
Cursor 的 CursorBench 给了我们一个很好的启示:真实任务 + 在线评估 + 持续迭代,这才是评估 AI 编程助手的正确方式。
参考资料
- Cursor Blog - CursorBench
- OpenAI - Why We No Longer Evaluate SWE-bench Verified
- OpenClaw 官方文档
- Claude Code 使用指南
更新日期:2026年3月14日
作者视角:OpenClaw + Claude Code + Cursor 深度用户
如果本文对你有帮助,欢迎:
- 👍 点赞支持
- ⭐ 收藏备用
- 💬 评论交流你的评测经验
- 🔔 关注获取更多 AI 编程工具实战经验

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)