浙大美团联合发布 SKILL0 全解(非常详细),Agent 技能内化原理从入门到精通,收藏这一篇就够了!
一句话讲清楚👉🏻 浙江大学REAL实验室联合美团、清华大学提出SKILL0框架,首次将Agent技能"内化"到模型参数中,训练时借助技能引导,推理时完全零依赖,在ALFWorld和Search-QA上分别比标准RL基线提升+9.7%和+6.6%,同时每步token消耗降至0.5k以下,仅为SkillRL的1/5。
背景:Agent技能的困境——模型只是在"照着念"
当前LLM Agent的主流做法叫推理时技能增强(Inference-time Skill Augmentation):从技能库检索相关文件,塞进模型的上下文窗口当指导。Claude Code、OpenClaw等框架都在用这套方案。
问题出在三个地方:
检索噪声。语义检索不完美,灌进来的技能文件可能跟当前任务八竿子打不着,反而污染了Agent的上下文。
Token开销大。技能文件本身就是长文本,多轮交互下来历史记录越积越多,上下文窗口迅速膨胀。推理成本上去不说,还容易触发"中间信息丢失"(Lost in the Middle)问题。
模型从未真正学会。在Prompt里跟着技能描述执行的模型,只是"照着念"。能力长在上下文里,没长在参数里。
就像考试允许带参考书——分数好看,合上书就不会了。
SKILL0想解决的就是这个问题:能不能把技能"内化"到模型参数里,推理时完全不需要检索技能文件,零样本自主完成任务?
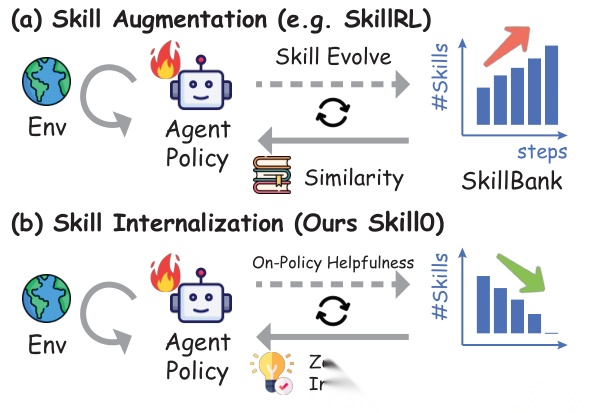
技能增强方法(a)需要在推理时检索技能并注入上下文,而SKILL0的技能内化方法(b)在训练后推理时完全不需要技能文件。
SKILL0核心方法:三招实现技能内化
SKILL0全称 In-Context Agentic Reinforcement Learning for Skill Internalization,核心思想一句话:“训练时有技能,推理时零技能”(Skills at training, zero at inference)。
三个关键机制:
1. 上下文渲染(Context Rendering):把文本变成图片
Agent处理复杂任务时,交互历史和技能文件会累积大量文本。SKILL0借鉴AgentOCR的思路,把文本上下文(包括交互历史 和检索到的技能 )渲染成紧凑的RGB图像,再通过视觉编码器压缩为视觉表示:
其中 是压缩比率,策略在每步自行生成。视觉表示 作为压缩后的上下文嵌入输入给策略,Token开销大幅减少,决策所需的结构信息也保留了下来。
2. 上下文强化学习(ICRL):训练时给引导,推理时全移除
ICRL的训练逻辑:
- 训练阶段:Agent rollout时获得完整的技能上下文引导,帮助学习复杂多步行为
- 推理阶段:技能上下文完全移除,Agent靠自身参数中内化的知识独立完成任务
为了让模型同时优化任务成功率和压缩效率,SKILL0设计了复合奖励函数:
如果任务成功否则
其中 评估Agent是否在技能增强下正确完成任务, 控制任务性能与压缩效率的权衡。对数形式反映了高压缩率的边际收益递减。
训练目标函数为:
其中优势 通过对组内采样的总奖励 进行归一化计算。
3. 动态课程学习(Dynamic Curriculum):逐步撤走"拐杖"
SKILL0不是突然移除所有技能,而是渐进式撤除。分两个阶段:
(a) 相关性驱动的技能分组
训练前,将验证集划分为 个子任务 T ∗ k ∗ k = 1 N ,每个子任务 T _ k 对应一个技能文件 S _ k {\mathcal{T}*k}*{k=1}^{N},每个子任务\mathcal{T}\_k对应一个技能文件\mathcal{S}\_k T∗k∗k=1N,每个子任务T_k对应一个技能文件S_k。离线分组确保每个技能文件都有专属子任务来评估效用。
(b) 有用性驱动的动态课程
训练过程分为 个渐进阶段,技能预算 线性衰减:
在每个阶段 ,每隔 个训练步骤,系统评估每个技能文件的"有用性" :
即"有技能"和"无技能"两种条件下在对应验证子任务上的准确率差值。然后:
- 过滤:只保留 的技能(即当前策略仍能从中受益的)
- 排序:按 降序排列
- 选择:选取前 个技能文件
随着训练推进,技能预算逐渐归零,最终Agent在完全无技能上下文的情况下运行。
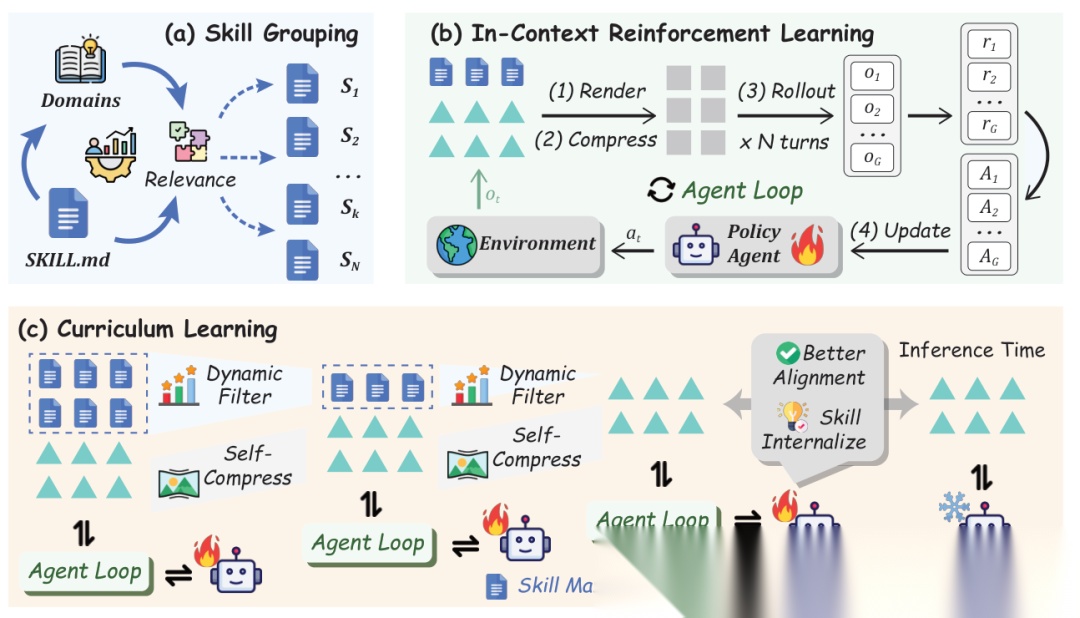
SKILL0整体框架概览。(a)相关性驱动的技能分组;(b)带有技能增强Agent loop的上下文强化学习;(c)训练过程中的动态课程学习。
实验结果
主实验结果
SKILL0在ALFWorld和Search-QA两大基准上评估,基座模型用Qwen2.5-VL系列的3B和7B版本。
ALFWorld任务(家庭环境文本游戏,六类子任务:Pick、Look、Clean、Heat、Cool、Pick2):
- SKILL0(3B)达到 87.9% 平均成功率,比AgentOCR(78.2%)提升 +9.7%
- SKILL0(7B)达到 89.8%,超越GRPO(81.8%)、AgentOCR(81.2%)等RL基线
- SKILL0在推理时不使用任何技能文件的情况下,性能与需要技能增强的SkillRL(82.4%/89.9%)相当甚至更优
Search-QA任务(NQ、TriviaQA、PopQA等7个搜索增强问答数据集):
- SKILL0(3B)达到 40.8% 平均准确率,比AgentOCR(34.2%)提升 +6.6%
- SKILL0(7B)达到 44.4%,超越所有RL基线
| 方法 | ALFWorld Avg↑ | ALFWorld Cost↓ | Search-QA Avg↑ | Search-QA Cost↓ |
|---|---|---|---|---|
| Zero-Shot (3B) | 15.2 | 1.21k | 15.9 | 0.48k |
| GRPO (3B) | 79.9 | 1.02k | 36.4 | 0.61k |
| AgentOCR (3B) | 78.2 | 0.38k | 34.2 | 0.26k |
| SkillRL† (3B) | 82.4 | 2.21k | 38.9 | 0.87k |
| SKILL0 (3B) | 87.9 | 0.38k | 40.8 | 0.18k |
| SKILL0 (7B) | 89.8 | 0.41k | 44.4 | 0.34k |
† 表示推理时使用技能增强
Token效率
视觉上下文建模加技能内化,SKILL0每步平均Token消耗很低:
- 3B模型在ALFWorld上消耗 0.38k tokens/step,SkillRL需要 2.21k(5.8倍差距)
- 3B模型在Search-QA上消耗 0.18k tokens/step,SkillRL需要 0.87k(4.8倍差距)
实际部署时,SKILL0的推理成本大幅低于需要持续检索技能的方案。
训练动态分析:技能内化的证据
奖励曲线
整个RL优化过程中,SKILL0在3B和7B两个基座上都保持了比AgentOCR基线更高的奖励曲线。
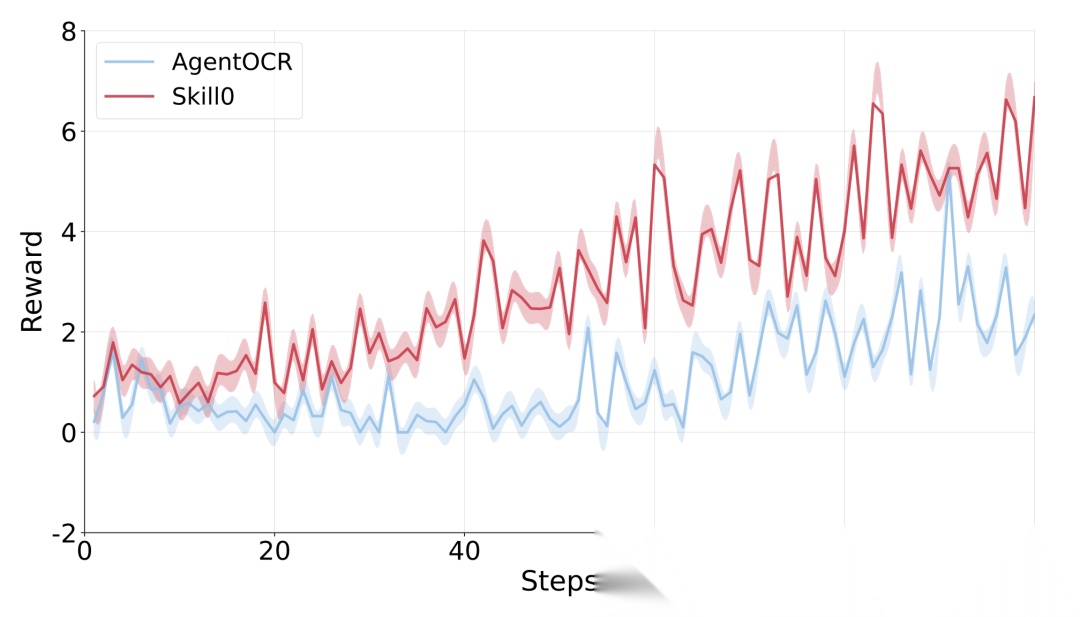
Qwen2.5-VL-3B上的训练动态对比,SKILL0的奖励曲线始终高于AgentOCR基线。
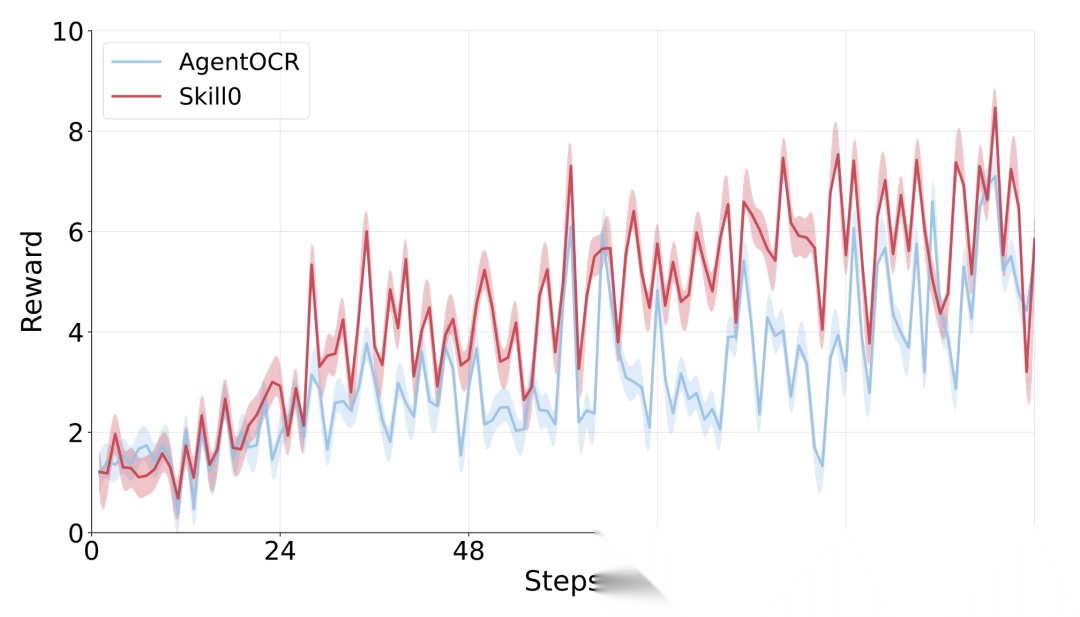
Qwen2.5-VL-7B上的训练动态对比,SKILL0同样保持领先。
技能内化趋势验证
论文通过三组对比验证技能确实被内化到了模型参数中:
(a) 有技能 vs 无技能验证:训练过程中,有技能增强时模型早期性能提升更快;无技能验证初始性能较低,但逐渐追赶上来,最终接近有技能的水平——这是技能内化的信号。
(b) SKILL0 vs AgentOCR(均无技能推理):在无技能推理设置下,SKILL0仍然超越AgentOCR,说明性能优势来自内化知识。
© SKILL0 vs GRPO vs SkillRL(均无技能推理):GRPO和SkillRL在训练早期就达到平台期,SKILL0持续进步,最终达到最高性能上限。
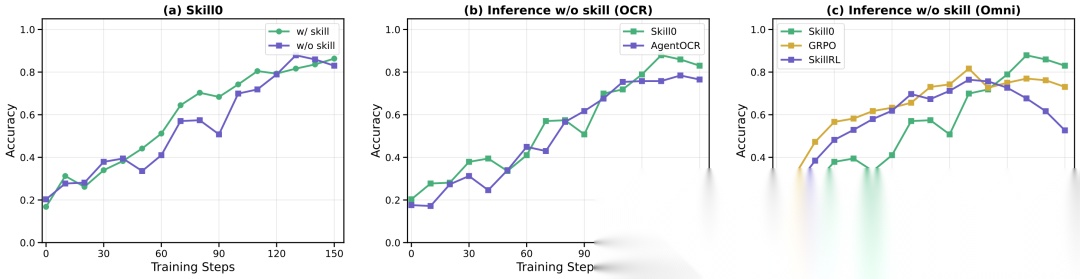
训练动态对比。(a)SKILL0有/无技能增强的验证性能对比;(b)SKILL0与AgentOCR在无技能推理下的对比;(c)SKILL0与GRPO、SkillRL在无技能推理下的对比。
有用性动态:先升后降
SKILL0动态课程中,每个技能的"有用性" 呈现一致的先升后降 模式:
- 早期:有用性较低,策略还没学会利用技能Prompt
- 中期:策略逐渐学会基于技能上下文行动,有用性上升
- 后期:动态课程减少技能预算,策略将技能知识内化到参数中, 回归到零
这条轨迹验证了ICRL和课程学习的协同机制——技能作为临时"脚手架",策略优化完成后被拆除。
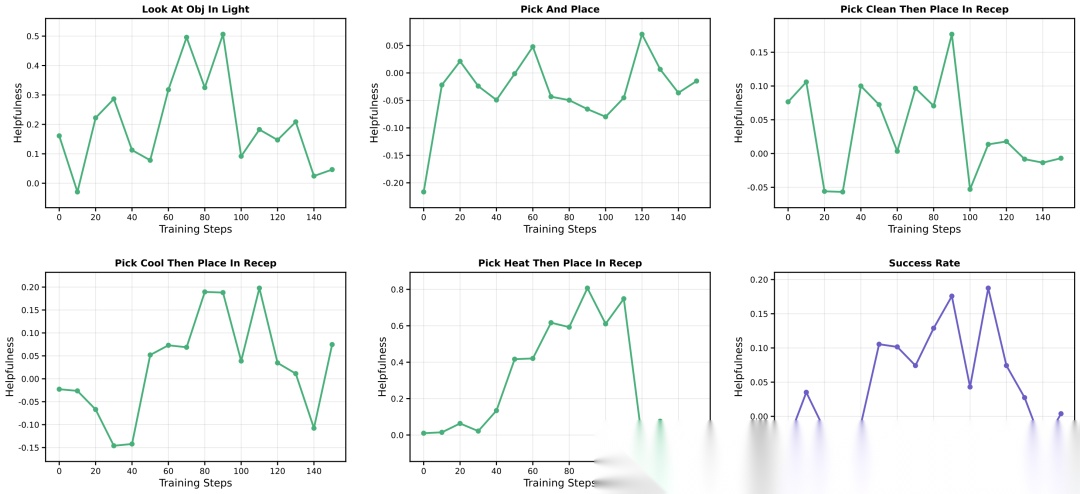
各子任务的有用性 训练动态,呈现一致的先升后降模式,验证了技能内化过程。
消融实验
技能预算设计
论文对比了多种技能预算策略:
- Fixed Full(始终使用全部技能):移除技能Prompt后性能崩溃-12.3%
- [6,6,6](固定高预算):移除后崩溃-13.3%
- [3,3,3](固定低预算):早期探索受限,学习不稳定
- [0,0,0](零技能):缺乏引导,性能最差
- SKILL0的[6,3,0](线性衰减):移除技能后反而获得+1.6%的正向迁移
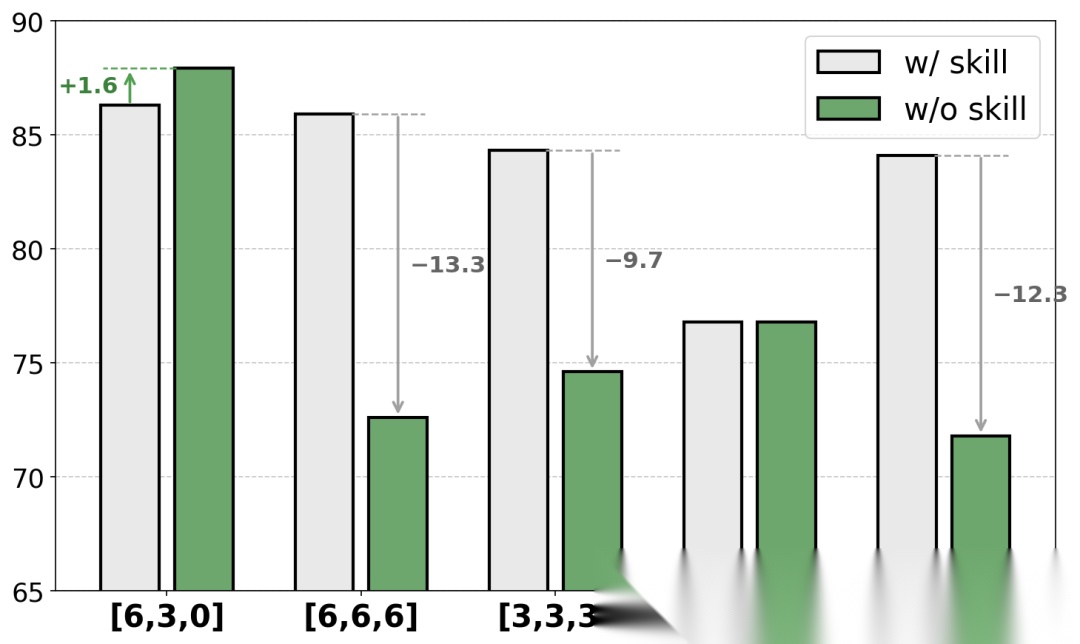
不同技能预算策略的消融对比,SKILL0的[6,3,0]线性衰减策略在无技能推理下表现最佳。
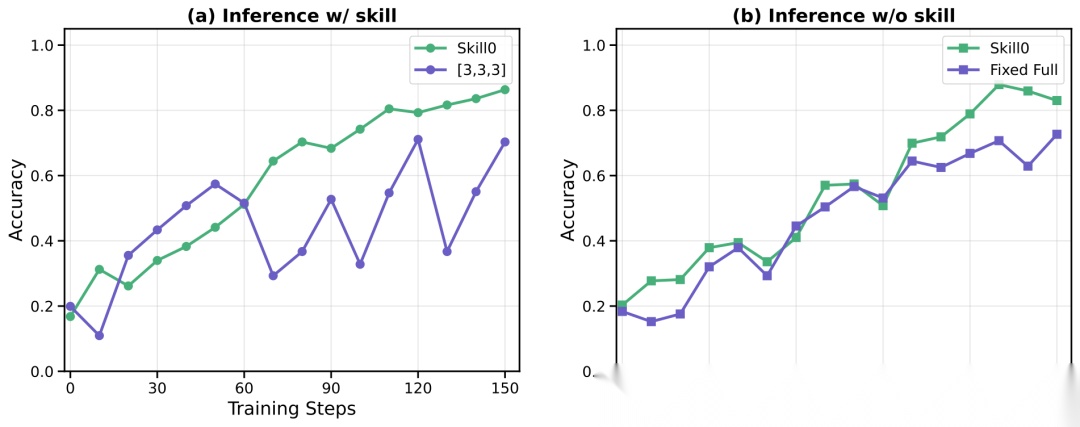
训练过程中不同技能预算策略的动态对比。
动态课程三步骤
"过滤-排序-选择"三步策略的必要性:
- 完整三步策略:无技能推理下达到87.9%,且是唯一实现正向迁移(Δ=+1.6%)的设置
- 去掉过滤(w/o Filter):引入上下文噪声,性能下降2.7%
- 随机选择(w/o Rank):严重崩溃(Δ=-13.7%,降至62.9%),保留严格有用的技能对稳定策略学习至关重要
子任务训练动态
论文还展示了ALFWorld各子任务和Search-QA各技能类别的详细训练动态。
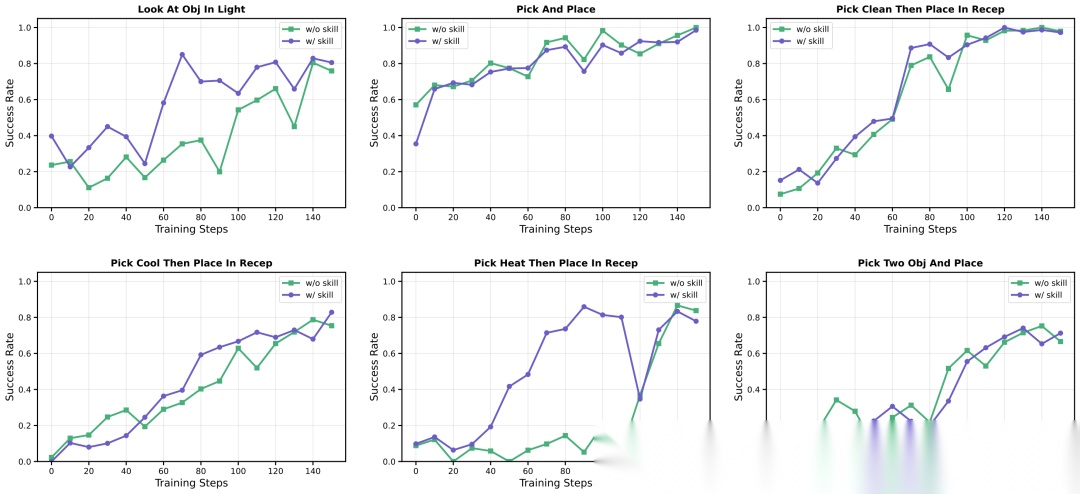
SKILL0在Qwen2.5VL-3B上ALFWorld各子任务的训练动态。
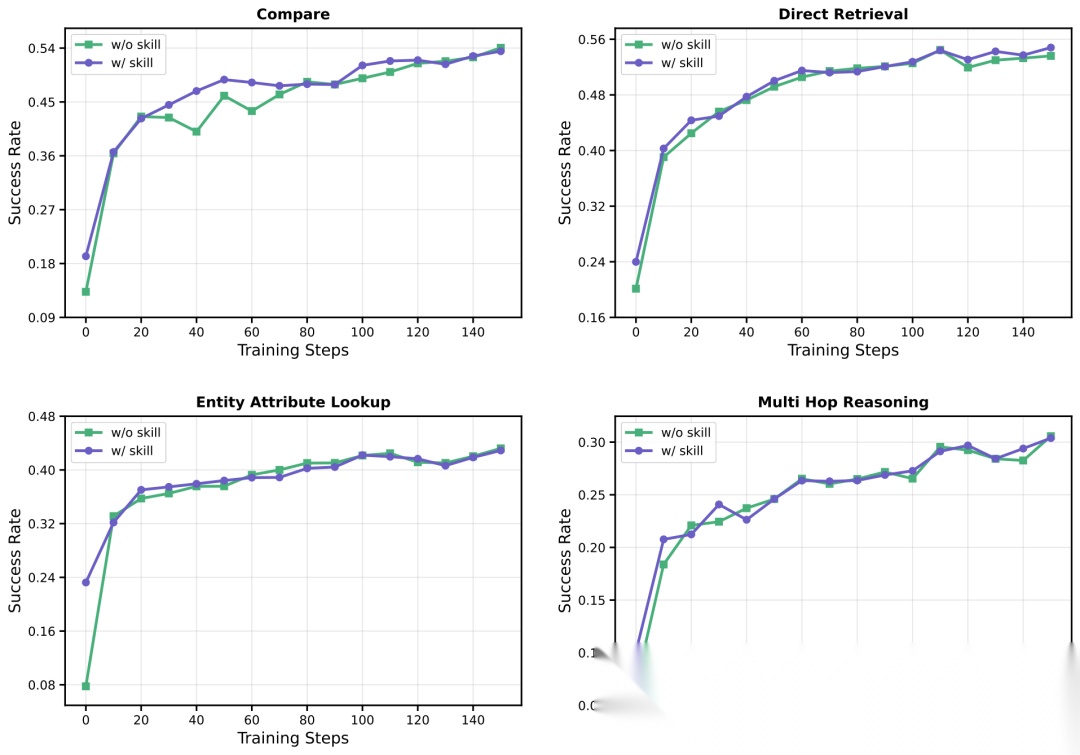
SKILL0在Qwen2.5VL-3B上Search-QA各技能类别子任务的训练动态。
意义与展望
SKILL0提出了一条Agent训练的新路径:从"依赖外部知识"走向"内化到参数"。跟人类学习技能的过程类似——初学者看说明书,熟练后凭直觉操作。
Claude Code、OpenClaw等Agent生态发展很快,Skill机制成了标准配置。但SKILL0提了个问题:如果Agent永远需要检索技能文件才能工作,跟查字典的学生有什么区别?
SKILL0的做法是训练时渐进引导,让模型真正"学会"而不是"照着做"。推理时零技能依赖,Token成本降下来,Agent也有了真正的自主能力。
局限在于目前只在ALFWorld和Search-QA两个基准上验证,GUI自动化、代码生成等更复杂的多模态Agent场景还有待探索。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 1
1- 0



 已为社区贡献191条内容
已为社区贡献191条内容

所有评论(0)