四、训练数据准备
训练数据准备
大模型的性能高度依赖于训练数据的规模、质量和多样性。本章将深入探讨从原始数据采集到最终可训练样本的完整流程,包括数据来源、预处理、分词、采样策略及存储格式。
1 数据来源
大模型训练所需的数据量级通常达到万亿 token(如 GPT-3 用了约 5000 亿 token,LLaMA 用了 1.4 万亿 token)。这些数据主要来自以下几个渠道:
公开网页爬虫:如 Common Crawl,每月抓取数十亿网页,提供原始 HTML 内容。它是许多大模型的基础语料(例如 GPT-3 的 45TB 文本中约 60% 来自经过过滤的 Common Crawl);
书籍与学术论文:如 BooksCorpus(约 7 万本电子书)、arXiv、PubMed 等,提供高质量的长文本和专业知识;
代码库:如 GitHub 公开代码,用于增强模型的代码理解和生成能力(CodeGen、Code LLaMA 等);
社交媒体与论坛:如 Reddit 讨论、Twitter 短文本,提供多样化的口语表达和对话数据;
百科与知识库:如 Wikipedia、Wikidata,提供结构化知识和事实性文本;
公司自备数据/专业领域数据;
数据配比:不同来源的数据通常按一定比例混合。例如,LLaMA 的训练数据包含 Common Crawl(67%)、Wikipedia(4.5%)、书籍(4.5%)、arXiv(2.5%)、代码(4.5%)等。这种混合策略旨在平衡通用知识、专业知识与语言多样性。
2 预处理
原始数据往往包含大量噪声,必须经过严格清洗、去重和过滤才能用于训练。
2.1 清洗(Cleaning)
清洗的目标是去除 HTML 标签、提取纯文本、纠正编码错误、移除无关内容。
步骤:
使用库(如 BeautifulSoup、trafilatura)提取正文,移除导航栏、广告、评论等;
统一 Unicode 编码,消除乱码;
去除连续空格、空行,规范标点符号;
过滤非自然语言内容(如大量乱码、仅含少量字母的文本);
重要性:噪声数据会干扰模型学习,甚至引入有害信息;
2.2 去重(Deduplication)
重复数据会导致模型记忆而非泛化,并可能使评估指标虚高。去重通常在文档级、段落级甚至句子级进行。
为什么要去重?
数据重复 → 模型死记硬背(memorization)
测试集 / 验证集里有训练集内容 → 分数虚高
泛化能力变差 → 换个新句子就不行
所以:训练前必须去重。
MinHash(最小哈希):用于大规模文档去重(大模型最常用)。将文档分词后生成签名(如 128 位哈希),通过比较签名相似度(Jaccard 相似度)判断是否重复。MinHash 可近似计算集合相似度,适合海量数据。
文档A:我 爱 吃 苹果
文档B:我 爱 吃 苹果
↓
MinHash 签名几乎一样
↓
判定:重复 → 删一个
特点: 快、适合海量数据;
SimHash:另一种局部敏感哈希算法,将文本映射为固定长度指纹,通过汉明距离检测相似文档。
文本1: 10110101
文本2: 10110110
差异很小 → 相似 → 删一个
去重粒度:
文档级:去除完全重复或近似重复的文档。
文档1:我爱中国
文档2:我爱中国
→ 删一个
段落/行级:在文档内部去除重复段落(如模板生成的重复内容)。
第1段:今天天气好
第3段:今天天气好
→ 删一段
案例:GPT-3 使用 Spark 进行 MinHash 去重,移除与训练集中其他文档高度相似的文档,避免模型背诵测试集。
记忆口诀
Deduplication = 去重
MinHash = 大模型标配,比签名
SimHash = 比指纹位数
目标:不让模型死记,要泛化
2.3 过滤(Filtering)
过滤低质量内容,如机器生成文本、过短文本、包含敏感词或仇恨言论的内容。
原始网页/书籍/文本
↓
【过滤 Filtering】
↓
留下:干净、高质量、安全、有用的文本
扔掉:垃圾、太短、敏感、隐私、机器生成、广告
质量分类器:训练一个轻量级分类器(如 fastText)区分高质量与低质量文本(例如基于维基百科正例,随机网页负例)。
质量分类器(Quality Classifier)
训练一个小模型(比如 fastText)
目标:区分高质量 vs 低质量文本
正例:维基百科、书籍
负例:垃圾网页、广告、乱码
作用:自动打分,低于分数线的直接丢掉。
启发式规则:就是人工写死的简单规则,不用训练模型。
我给你列成好记的 4 条:
语言过滤: 只留中文 / 英文,其他语言删掉。
长度过滤: 太短(比如<200 字符)→ 删掉。因为没信息量。
去重复冗余: 重复 n-gram 太多(比如一直重复 lorem ipsum)→ 删掉。
去模板 / 导航 / 列表: 像网页菜单、目录、导航条 → 删掉。用 TF-IDF 识别。
隐私与安全:
删掉所有能定位到个人的信息:
手机号、邮箱、身份证、家庭住址、银行卡等
目的:不让模型记住隐私,不泄露个人信息。
极简总结
Filtering = 洗数据、去垃圾
质量分类器:AI 打分,留高质量
启发式规则:按长度、语言、重复、模板删
隐私过滤:删手机号、邮箱等个人信息
3 分词(Tokenization)
分词将文本切分为模型可处理的 token 序列,是模型输入的基础。分词器的选择直接影响词表大小、序列长度和模型效果。
把人类的文字,切成模型能看懂的 “小积木”(token),是模型吃数据的第一步。
为什么需要分词?
直接用单个字 / 词:要么词表太大(比如中文几万个词),要么处理不了新词(OOV,比如 “元宇宙”)
子词分词(BPE/WordPiece):兼顾 “字符” 和 “词”,能拼出新词,词表还小
3.1 主流分词算法
BPE(Byte-Pair Encoding):
原理:从字符级开始,统计最频繁的相邻符号对,合并为新的符号,迭代直到达到目标词表大小。
初始字符:我 爱 吃 苹 果 我 爱 吃 香 蕉统计频次:
“我 爱”:2 次
“爱 吃”:2 次
“吃 苹”:1 次
“吃 香”:1 次
第一步:合并频次最高的 “我 爱” → 新 token:我爱现在序列:我爱 吃 苹 果 我爱 吃 香 蕉
第二步:合并 “爱 吃”(现在是 “我爱 吃” 里的 “吃”)→ 新 token:爱吃现在序列:我爱 爱吃 苹 果 我爱 爱吃 香 蕉
→ 最终词表里有:我爱、爱吃、苹、果、香、蕉
特点
优点:能拼新词(比如 “我爱 + 吃 + 车厘子”),压缩率高
应用:GPT-2/3、RoBERTa(用字节版 BPE,避免 Unicode 乱码)
WordPiece:
原理:类似于 BPE,但合并准则基于语言模型似然的提升,而非频次。
同样上面的序列,WordPiece 会算:
合并 “我爱” 后,模型预测下一个词的准确率提升多少?
合并 “爱吃” 后,准确率提升多少?
→ 选提升最多的那个合并。
特点
更贴合语言模型的训练目标
应用:BERT(词表约 3 万)
SentencePiece:
原理:将文本视为 Unicode 字符序列,不依赖空格分词(可直接处理多语言),内置 BPE 和 unigram 语言模型两种算法,语言无关的 “万能分词器”
核心逻辑
不依赖空格(中文没空格也能分),把文本当纯 Unicode 字符
内置 BPE 和 unigram 两种算法
支持 “子词正则化”(训练时随机切分,比如 “苹果” 有时切成 “苹 + 果”,有时直接 “苹果”,模型更鲁棒)
例子
输入:我爱中国🇨🇳SentencePiece 直接按字符处理,不用先分词,兼容多语言 / 表情。
特点
语言无关(多语言模型首选)
应用:LLaMA、T5、XLNet
对比
算法 核心准则 优点 代表模型
BPE 按字符对频次合并 压缩率高、处理 OOV 好 GPT-2/3、RoBERTa
WordPiece 按语言模型似然提升合并 更贴合模型训练目标 BERT
SentencePiece 语言无关,内置 BPE/unigram 兼容多语言、无空格分词 LLaMA、T5、XLNet
记忆口诀
BPE:谁多合并谁
WordPiece:谁有用合并谁
SentencePiece:啥语言都能分
分词目标:切小积木,拼新词,控词表
3.2 词表大小
词表大小通常在 3万 ~ 5万 之间,但也有更大(如 GPT-3 的 50257)或更小(如 ALBERT 的 3万)的选择。词表大小 = 模型认识多少个 “小积木(token)”,选大还是选小,就是在做权衡。
常见范围
一般模型:3 万~5 万
GPT-3:50257(≈5 万)
ALBERT:3 万
多语言模型(mBART):25 万
权衡:
词表越大:单个 token 信息密度高,序列长度短(节省计算),但词表嵌入层参数量大,且对罕见词更友好;
句子:我今天想吃苹果派
词表大
苹果 → 1 个 token
苹果派 → 1 个 token
→ 整句 token 少、短、快
词表越小:序列变长(计算量增加),但嵌入层参数少,且易覆盖常见子词;
词表小
苹 + 果 + 派
→ 切得碎、长、慢
实际选择:常见值为 32k、50k。多语言模型可能需要更大词表(如 mBART 的词表 25 万);
3.3 分词示例
句子:“I love large language models.”
BPE 分词(GPT-2 tokenizer)可能得到:[‘I’, ‘Ġlove’, ‘Ġlarge’, ‘Ġlanguage’, ‘Ġmodels’, ‘.’](Ġ 表示空格)。
每个 token 对应词表中的 ID,模型输入即为这些 ID 序列。
4 数据采样与打乱
训练时,数据加载器需要高效地提供随机打乱的样本,以确保训练稳定性和泛化能力。
4.1 样本构建
原始文档被分词后,通常需要切分成固定长度(如 2048 token)的序列,相邻序列可能有重叠(滑动窗口)或不重叠。每个序列作为训练样本。
核心动作:切分长文本为固定长度 token 序列
切分方式一: 不重叠切分(简单)
样本1:t1 t2 t3 t4
样本2:t5 t6 t7 t8
优点:速度快、无冗余
缺点:可能切断语义(比如一句话被切成两半)
切分方式二: 滑动窗口(重叠切分,更常用)
设置步长(比如步长 = 2),相邻样本有重叠:
样本1:t1 t2 t3 t4 (从t1开始,取4个)
样本2:t3 t4 t5 t6 (滑2步,从t3开始,取4个)
样本3:t5 t6 t7 t8 (再滑2步,从t5开始,取4个)
优点:保留完整语义,避免切断关键上下文
缺点:少量冗余,数据量稍大
4.2 采样策略
自然分布采样
定义:严格按照数据源原始数量占比采样,数据量大的来源在训练集中占比更高。
优点:贴近真实世界文本分布,模型泛化性更好。
缺点:容易被低质量、高重复、高噪声数据主导,拉低整体训练效果。
eg:
数据量:网页 >> 百科 > 书籍 > 论文
采样后:网页占绝大多数,低质量多
[网页: 80%] [百科: 10%] [书籍: 7%] [论文: 3%]
重采样平衡:为解决自然分布的缺陷,常用过采样 / 降采样调整分布
过采样(上采样):对高质量、高价值数据源增加采样次数 / 比例,如书籍、维基百科、论文等。
示例:GPT‑3 对维基百科、书籍执行约 3× 过采样。
降采样(下采样):对低质量、高冗余数据源减少采样比例。
目标:在不丢弃太多信息的前提下,提升有效信息密度,强化特定领域 / 通用能力。
eg:
对百科、书籍过采样,网页降采样
[网页: 40%] [百科: 25%] [书籍: 25%] [论文: 10%]
混合比例:核心在于确定不同数据源(网页、书籍、百科、对话、代码等)的最终混合权重。
确定方式:
小规模预实验 + 验证集效果调参
基于先验知识的启发式规则
结合模型能力短板做定向增强
关键原则:质量优先于数量,高价值数据通常给予更高配比。
固定模型大小,做小规模 ablation 实验。
测试不同比例:
网页:百科:书籍 = 6:2:2
网页:百科:书籍 = 5:3:2
网页:百科:书籍 = 4:3:3
用验证集困惑度(PPL)、下游任务准确率选择最优比例。
4.3 数据打乱与数据加载
核心目的
避免模型 “记住顺序”(比如一直喂新闻,模型只学新闻,换小说就不行);
提升泛化能力,让训练更稳定;
全局打乱:将所有样本随机打乱,确保每个 batch 来自不同文档。这需要 shuffle buffer 或提前生成随机索引。
分布式打乱:在分布式训练中,每个进程需获得不重叠且打乱的数据切片,通常使用分片(sharding)和随机种子。
数据加载器(DataLoader):PyTorch 等框架的 DataLoader 支持多进程预取、shuffle 和 batch 组装。对于超大规模数据,通常使用自定义的迭代式数据集(如 IterableDataset),避免将所有索引加载到内存。
反例(不打乱的问题):如果一直按 “新闻→小说→论文” 的固定顺序喂:模型会先学新闻特征,再学小说,最后学论文,训练过程波动大,泛化差。
5 存储格式
为了高效读取 TB 级数据,需要选择合适的存储格式和 IO 优化。
5.1 常见存储格式
JSONL(JSON Lines):每行一个 JSON 对象,包含文本、元数据等信息。易读、易处理,但解析开销大,不适合高性能训练。
TFRecord:TensorFlow 推荐的二进制格式,将数据序列化为协议缓冲区(protobuf)。支持压缩、分片,且能与 TensorFlow 的数据管道(tf.data)无缝集成。许多公开数据集(如 The Pile)提供 TFRecord 格式。
内存映射(mmap):将数据文件直接映射到虚拟内存,实现零拷贝读取,极大加速随机访问。例如,LLaMA 使用内存映射文件存储 token ID 数组,每个文档起始位置记录在索引中。训练时可通过指针直接访问任意 token,避免反复 IO。
存储格式 类型 优点 缺点 适用场景
JSONL 文本格式 易读、易调试、无需特殊工具 解析慢、体积大、IO 效率低 小数据集、数据预处理阶段
TFRecord 二进制格式 压缩性好、适配 TensorFlow、分片友好 可读性差、依赖 TF 生态 TF 框架训练、公开数据集
mmap 内存映射 零拷贝、随机访问快、接近内存速度 需提前构建索引、依赖文件系统 大模型训练(TB 级数据)
【JSONL 示例】
{"text": "苹果是水果", "source": "百科", "length": 6}
{"text": "猫会抓老鼠", "source": "书籍", "length": 6}
# 每行一个独立 JSON,换行分隔
【TFRecord 逻辑结构】
[记录1: protobuf 序列化数据] [记录2: protobuf 序列化数据] ...
# 二进制流,按 TF 的 Record 格式存储
【mmap + 索引 示例(LLaMA 风格)】
# 数据文件(二进制):连续的 token ID 数组
[101, 324, 567, 890, 102, 456, 789, ...]
# 索引文件(文本/二进制):记录每个文档的起始位置和长度
文档1: 起始偏移=0, 长度=4 → 对应 token [101,324,567,890]
文档2: 起始偏移=4, 长度=3 → 对应 token [102,456,789]
5.2 存储优化技巧
分片(Sharding):将数据分成多个文件(如 1024 个分片),便于分布式训练时每个 worker 独立读取不同分片,减少文件锁竞争。
eg:
import os
import json
from pathlib import Path
def shard_jsonl(input_file, output_dir, shard_size=100000):
"""
将 JSONL 文件分片,每个分片包含 shard_size 行
input_file: 原始 JSONL 文件路径
output_dir: 分片输出目录
shard_size: 每个分片的行数
"""
Path(output_dir).mkdir(exist_ok=True, parents=True)
shard_idx = 0
lines = []
with open(input_file, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
lines.append(line)
# 达到分片大小,写入文件
if (idx + 1) % shard_size == 0:
output_file = os.path.join(output_dir, f'shard_{shard_idx:04d}.jsonl')
with open(output_file, 'w', encoding='utf-8') as out_f:
out_f.writelines(lines)
lines = []
shard_idx += 1
# 写入剩余行
if lines:
output_file = os.path.join(output_dir, f'shard_{shard_idx:04d}.jsonl')
with open(output_file, 'w', encoding='utf-8') as out_f:
out_f.writelines(lines)
# 调用示例:将 1000 万行的 JSONL 拆成每个 10 万行的分片
shard_jsonl('data/all_data.jsonl', 'data/sharded', shard_size=100000)
压缩:使用 zstd、gzip 等压缩原始文本,存储时压缩,读取时解压,可减少存储空间和网络传输,但增加 CPU 开销。
安装依赖
pip install zstandard # Python 库
# 或系统级安装 zstd 工具(Linux/Mac)
sudo apt install zstd # Ubuntu
brew install zstd # Mac
代码样例(以 zstd 为例,比 gzip 更快)
import zstandard as zstd
def compress_file(input_path, output_path):
"""用 zstd 压缩文件"""
cctx = zstd.ZstdCompressor(level=3) # 压缩级别 1-22,3 平衡速度和压缩率
with open(input_path, 'rb') as ifh, open(output_path, 'wb') as ofh:
cctx.copy_stream(ifh, ofh)
def decompress_file(input_path, output_path):
"""解压 zstd 压缩文件"""
dctx = zstd.ZstdDecompressor()
with open(input_path, 'rb') as ifh, open(output_path, 'wb') as ofh:
dctx.copy_stream(ifh, ofh)
# 调用示例
compress_file('data/shard_0000.jsonl', 'data/shard_0000.jsonl.zst')
decompress_file('data/shard_0000.jsonl.zst', 'data/shard_0000.jsonl')
元数据索引:为数据集构建索引文件(如每个文档的起始位置、长度),支持随机访问特定文档或样本,避免顺序扫描。
元数据索引(LLaMA 风格)
import struct
from pathlib import Path
def build_mmap_index(token_file, index_file, doc_lengths):
"""
构建 mmap 索引文件
token_file: 存储 token ID 的二进制文件路径
index_file: 输出索引文件路径
doc_lengths: 列表,每个元素是单个文档的 token 长度
"""
# 记录每个文档的起始偏移(字节数,假设 token 是 int32,占 4 字节)
offsets = [0]
current_offset = 0
with open(index_file, 'wb') as f:
# 先写入文档总数
f.write(struct.pack('I', len(doc_lengths)))
for length in doc_lengths:
current_offset += length * 4 # int32 占 4 字节
offsets.append(current_offset)
# 写入起始偏移和长度(均为 uint32 格式)
f.write(struct.pack('II', offsets[-2], length))
def read_doc_from_mmap(token_file, index_file, doc_id):
"""
从 mmap 文件中读取指定文档的 token ID
"""
import mmap
# 读取索引
with open(index_file, 'rb') as f:
doc_count = struct.unpack('I', f.read(4))[0]
if doc_id >= doc_count:
raise ValueError(f"doc_id {doc_id} 超出范围(总数 {doc_count})")
# 定位到目标文档的索引位置
f.seek(4 + doc_id * 8) # 4 字节(总数) + 每个文档 8 字节(偏移+长度)
offset, length = struct.unpack('II', f.read(8))
# 内存映射 token 文件并读取
with open(token_file, 'rb') as f:
with mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ) as mm:
# 读取指定范围的字节,转换为 int32 token ID
token_bytes = mm[offset : offset + length * 4]
tokens = struct.unpack(f'{length}I', token_bytes)
return tokens
# 模拟数据:假设有 3 个文档,token 长度分别为 100、200、150
doc_lengths = [100, 200, 150]
# 构建索引
build_mmap_index('data/tokens.bin', 'data/index.bin', doc_lengths)
# 读取第 2 个文档的 token
tokens = read_doc_from_mmap('data/tokens.bin', 'data/index.bin', 1)
print(f"第 2 个文档的 token 数量:{len(tokens)}") # 输出 200
5.3 实践案例
LLaMA 的训练数据存储方式:
将所有文档分词后,token ID 序列连续写入一个大文件(二进制格式);
另建一个索引文件,记录每个文档的起始偏移和长度;
训练时,每个 worker 根据索引随机读取若干文档片段,并拼接成固定长度序列,这种设计利用了 mmap,读取速度接近内存访问,是处理 TB 级数据的标准做法;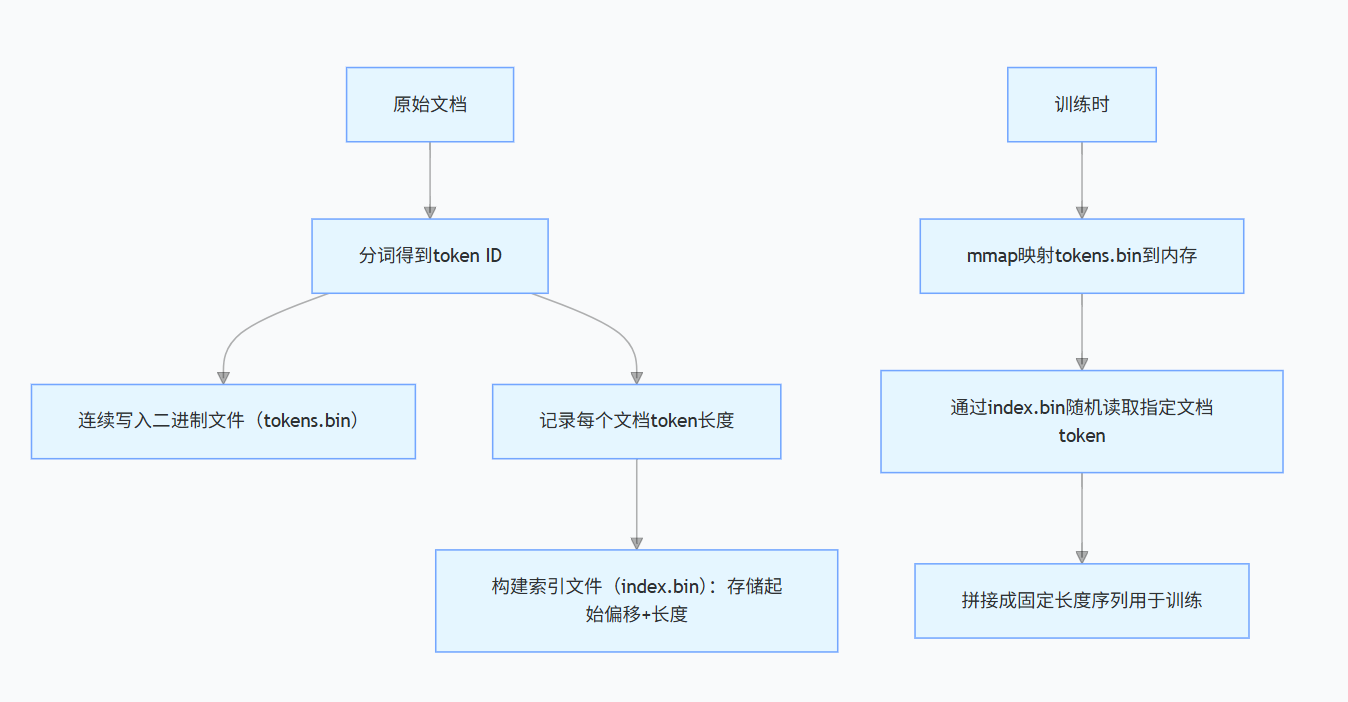
小结
存储格式选择:
小数据集用 JSONL(易调试),TF 生态用 TFRecord,TB 级大模型训练优先 mmap(零拷贝 + 随机访问快);
核心优化手段:分片(适配分布式)、压缩(省空间 / 带宽)、元数据索引(支持随机访问);
LLaMA 方案核心:二进制存储 token + 索引文件记录偏移 + mmap 内存映射,实现接近内存的读取速度;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)