【瑞萨AI挑战赛】使用Google Colab免费云GPU资源, 训练YOLO-Fastest驾驶员困意识别模型
背景
这篇文章应用场景是:想要基于瑞萨RA8P1上集成的Eshos-U55 NPU平台,自己基于数据集训练YOLO-Fastest模型。而我个人电脑没有Nvidia的独立显卡,无法调用CUDA进行训练,因此仅使用电脑CPU来跑的话,模型训练时间会特别久。
刚好有了解到Google Colab上有免费的GPU资源可以使用,因此就摸索着使用云端GPU资源来训练得到YOLO-Fastest模型,而后再在本地进行测试,最后部署到RA8P1 RT-Thread Titan Board开发板上。
这里搬运一段Gemini生成的介绍:
Google Colab(全称 Colaboratory)是 Google 提供的一款基于云端的 Python 开发环境。它允许用户直接在浏览器中编写和执行 Python 代码,而无需在本地进行任何复杂的环境配置。
其核心优势和特点包括:
免费使用算力资源:Colab 最大的吸引力在于为免费用户提供 T4 GPU 或 TPU 资源。这对于需要进行机器学习、深度学习训练但本地硬件配置不足的开发者来说非常友好。
零配置环境:它基于 Jupyter Notebook 格式,预装了大多数常用的数据科学和 AI 库(如 TensorFlow, PyTorch, Pandas),登录 Google 账号即可使用。
Google Drive:代码和数据可以直接保存在 Google 云端硬盘 中,方便持久化存储和挂载数据集。
使用限制:虽然提供免费资源,但通常有12小时的连续运行限制。如果需要更长的后台运行时间或更高性能的显卡(如 A100/L4),可以选择 Colab Pro/Pro+ 订阅计划。
Colab提供可以免费使用的NVIDIA® T4 GPU是专门用于云端服务器的GPU,它的INT8算力能够达到130 TOPS,当然也支持CUDA的API,还是很良心的。虽然说未订阅的话,Colab对于GPU资源也有使用限制,但是对于简单的YOLO模型训练来说,稍微省着点用还是足够的:
T4 GPU的DataSheet和参数可参考NVIDIA官网资料:https://www.nvidia.cn/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet.pdf

准备工作
科学上网:访问Google Colab需要自行准备科学上网工具,当然还需要Google账号,不过多解释。Google Colab地址:https://colab.research.google.com/
模型:这里使用的是NetsPresso页面的YOLO-Fastest,这是已经在Arm Cortex-M85和Cortex-M55+Ethos-U55测试过的部署路径,刚好符合目标系统的资源:https://github.com/Nota-NetsPresso/ModelZoo-YOLOFastest-for-ARM-U55-M85
数据集:这里使用的数据集是Robofolw上的Driver Drowsiness Detection Computer Vision Model数据集,下载数据集时可以选择基于多种不同YOLO模型的格式。链接:https://universe.roboflow.com/tesi-jotog/driver-drowsiness-detection-7fvkf
当然,数据集的格式还是需要手动用Python脚本重新整理一下,会在后续的文章里详细介绍,这里就不过多展开。最终的数据集结构应该如下:
Your code structure should like
├── datasets
│ └── vehicleannotaitons
│ ├── images
│ └── annotations
│
└── ModelZoo-YOLOFastest-for-ARM-U55-M85
上传数据集到Google Drive
由于Colab可以直接调用Google Drive的资源,我们可以提前先把修改好的数据集先上传上去,节约后面的服务器时长。
在根目录下创建了YoloTest文件夹,将之前的模型文件夹直接拖拽到页面上YoloTest目录就可以。
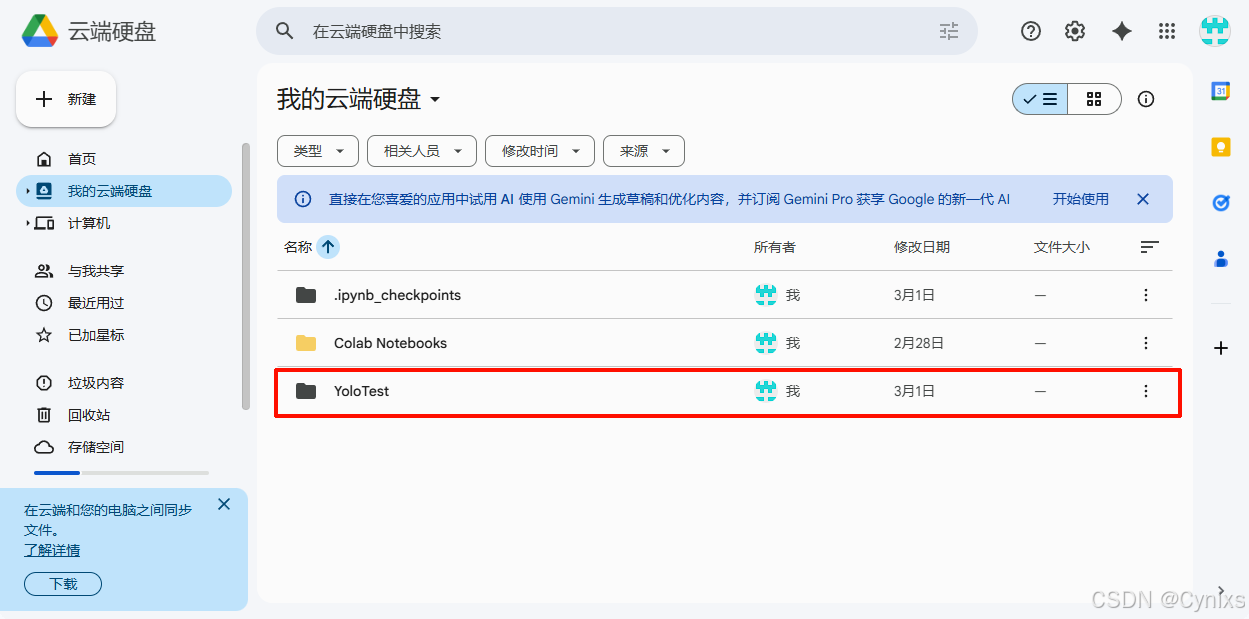
创建和配置Colab Page
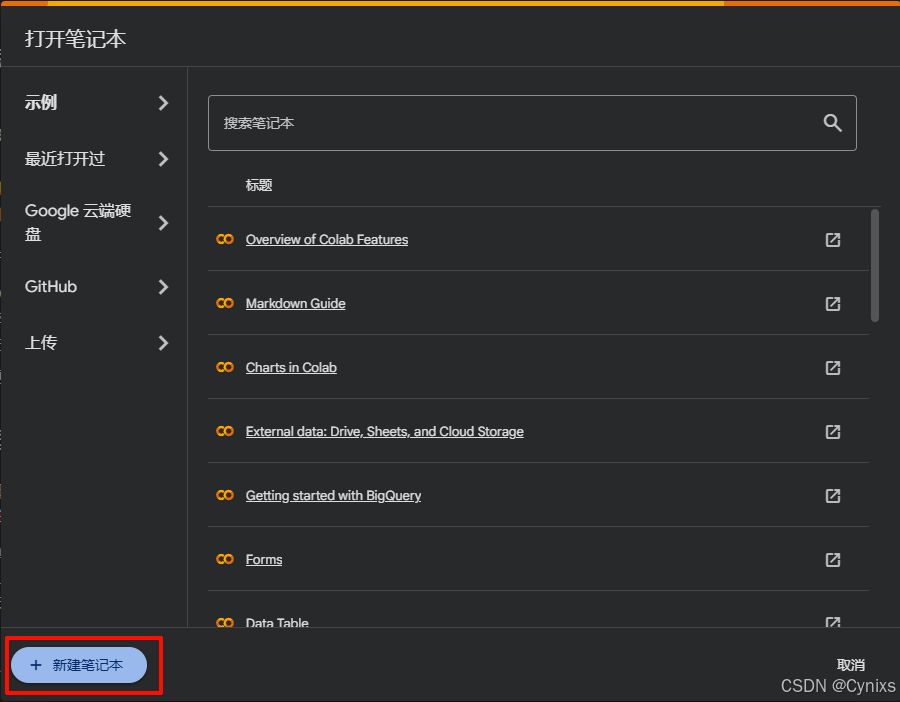
选择新建笔记本,当然也可以打开默认的Demo,或者上传其他人的笔记本:
稍微等待十几秒后就进入到了新建的笔记本中,默认的笔记本是没有连接到云端资源的,可以在右上角选择连接。
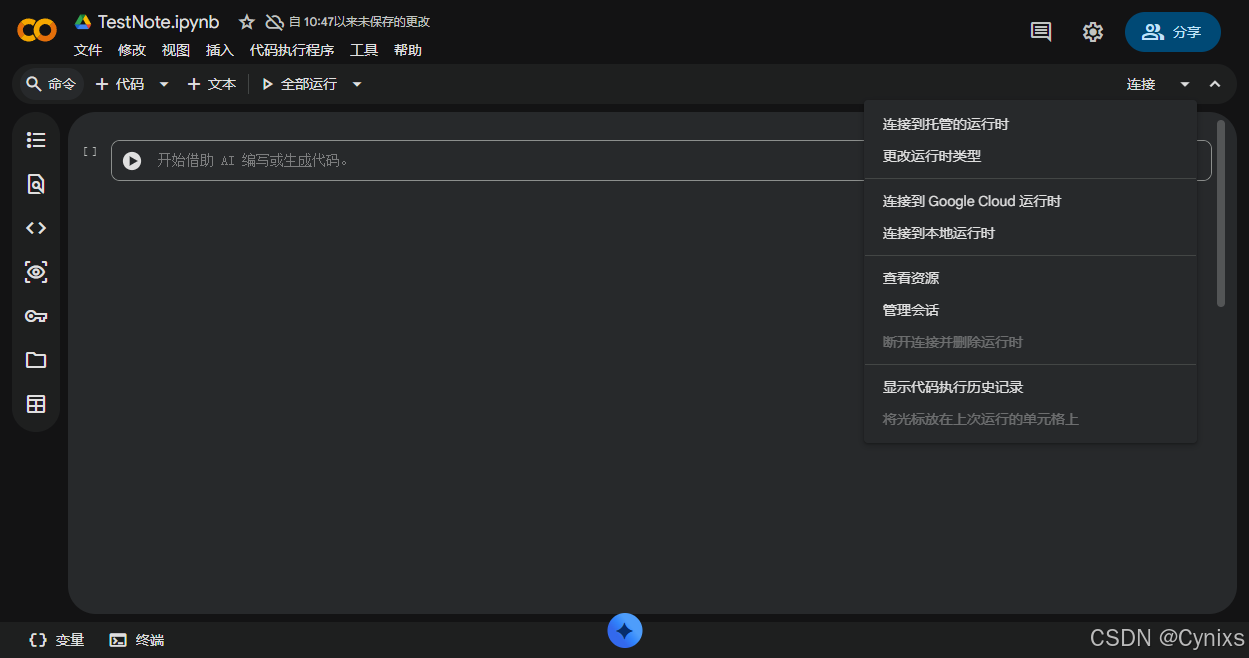
点击查看资源可以看到当前使用的云端资源,默认的话是CPU服务器,有12G的RAM和100多G的存储。这里也会显示按照当前的资源,可以持续使用的时间。纯CPU的话可以使用地久一些,如果使用的是GPU资源那么就比较有限。
点击下方的蓝色图标,还可以调用内置的AI助手Gemini,和自家生态结合地还是比较好的。
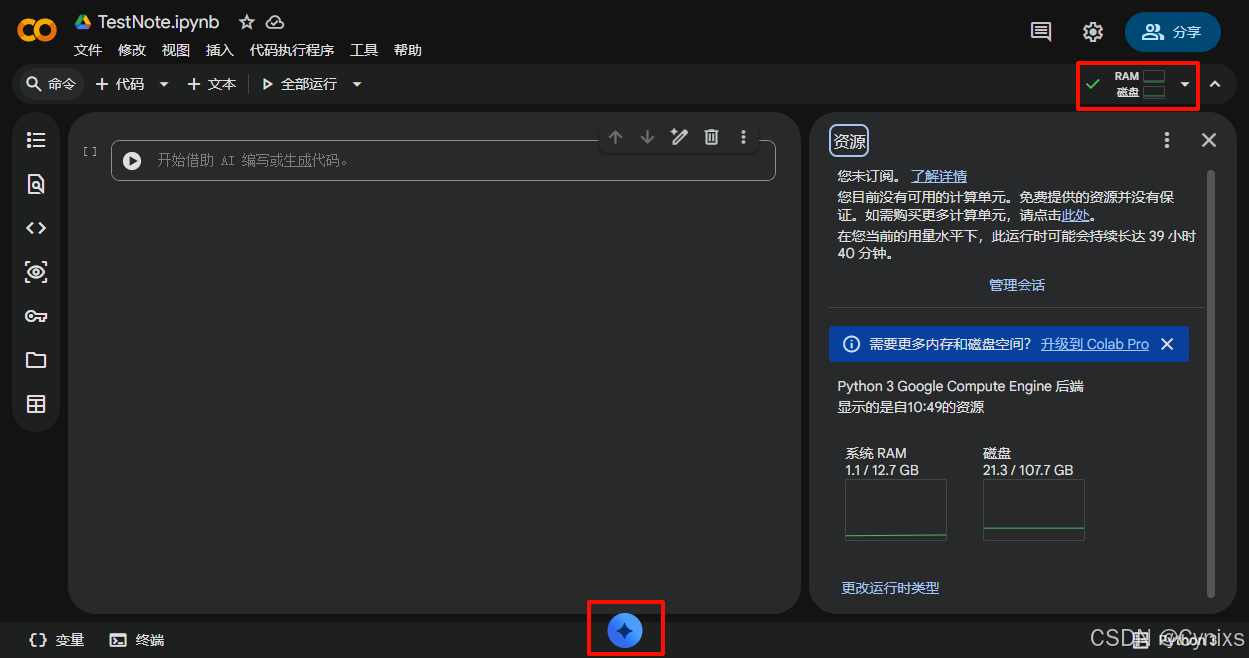
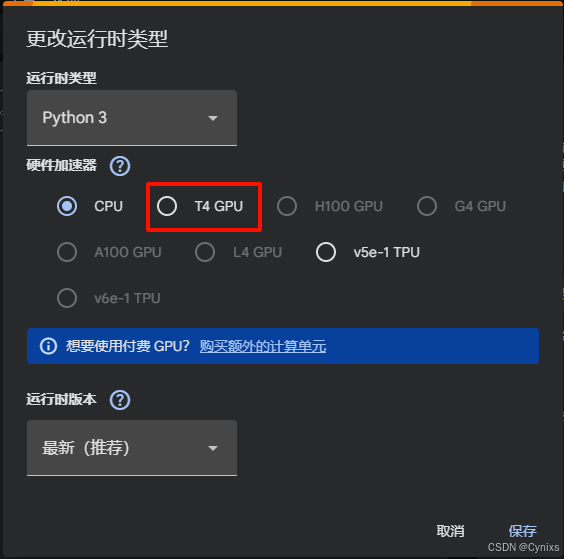
点击“更改运行时类型”可以由CPU切换到T4 GPU,以及一个v5e-1 TPU,其他灰色的资源就需要付费了。
这里我的建议是:编辑/优化Python脚本、以及下载Github资源的时候先保持CPU,等到真正训练模型的时候再切换到GPU,该省省该花花:
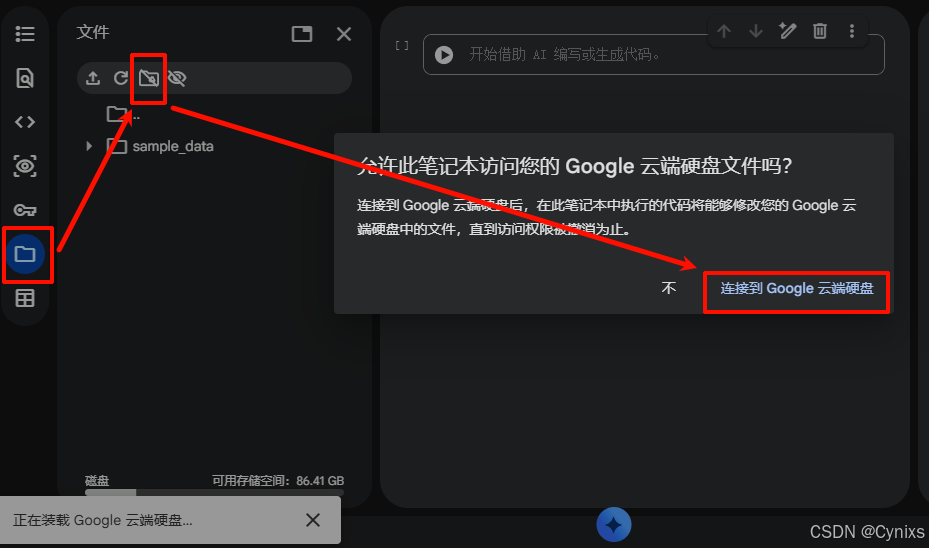
这里在页面左侧点击文件夹图标,就可以将Google Drive网盘挂在到当前的Colab页面。
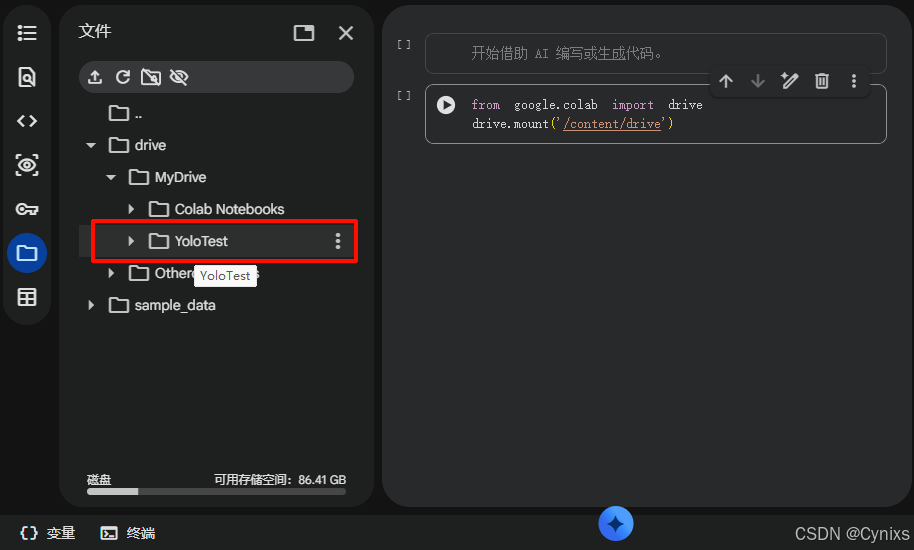
我们刚刚上一步新建的目录就在content/drive/MyDrive/YoloTest路径下:
YOLO-Fastest模型训练
在中间的Notebook中添加以下命令,进入到我们的目录中:
cd /content/drive/MyDrive/YoloTest/而后git clone YOLO-Fastest工程,并安装相关的依赖文件。
需要注意,Colab命令运行git或者python命令前面要添加一个叹号!才能正常运行:
!git clone https://github.com/Nota-NetsPresso/ModelZoo-YOLOFastest-for-ARM-U55-M85.git
cd ModelZoo-YOLOFastest-for-ARM-U55-M85
pip install -r requirements.txt而后为了运行方便,我将数据集搬运到了ModelZoo-YOLOFastest-for-ARM-U55-M85目录下的mydata路径。
而后运行训练train.python脚本,注意配置cfg为对应的数据集路径。参考配置项如下,这里配置了-imgsz为320,epochs迭代次数为800,输出路径为run文件夹:
!python train.py \
--data ./mydata/data.yaml \
--cfg ./models/yolo-fastest.yaml \
--weights "" \
--imgsz 320 \
--batch-size 64 \
--epochs 800 \
--device 0 \
--workers 4 \
--project .\runs \
--name DriveDrowsiness \
--exist-ok \
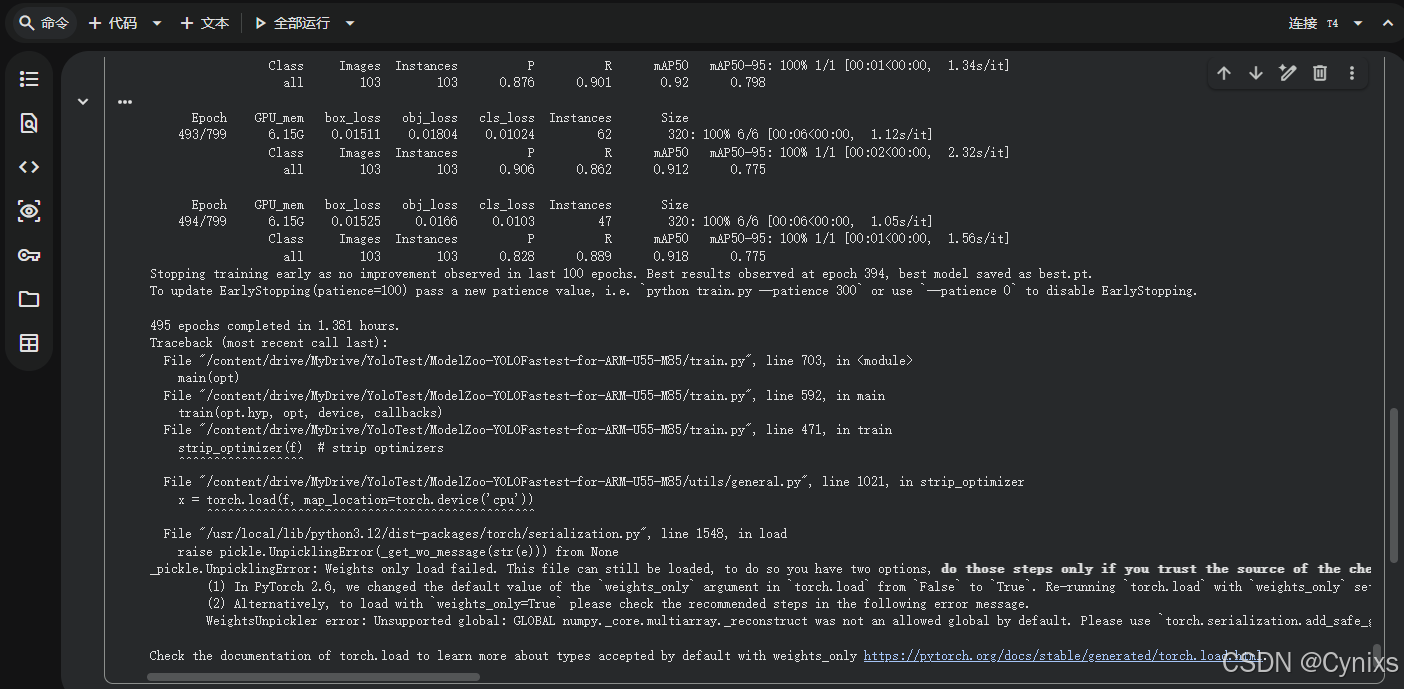
--noplots在脚本下方会实时的输出运行日志输出项。大概等待了一个多小时,就可以看到在epoch接近近500时就自动停止了,原因是模型性能在最近的100个epoch内没有显著提升,触发了“EarlyStopping ”机制,可以通过添加“—patience xxx”命令来调整训练的patience:
Stopping training early as no improvement observed in last 100 epochs. Best results observed at epoch 394, best model saved as best.pt.
To update EarlyStopping (patience=100) pass a new patience value, i.e. ‘python train.py —patience 300’ or use ‘—patience 0' to disable EarlyStopping.
训练完成后,可以在Google Drive的模型路径下找到训练好的权重文件,选择使用最优的权重系数:best.pt,可以直接下载到本地。
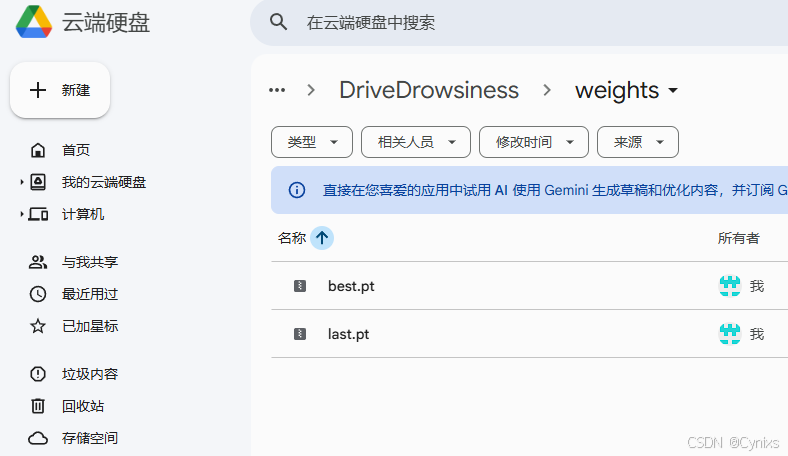
本地Detect测试模型文件
首先也在本地安装相应的Python依赖文件,和上面的内容基本类似。
需要注意的是Python版本有要求:需要Python 3.10才能支持Pytorch <2.0。
而后将.pt文件下载到模型路径中,修改detect.py文件,将本地的目录添加到对应路径中。本地直接运行检测命令,会调用训练好的模型.pt文件,将对应--source目录下的图片全部检测一遍:
python detect.py --weights runs/DriveDrowsiness/weights/best.pt --source mydata/test/images/本地detece结束后,会在.\runs\detect\exp目录中,生成测试结果如下,可以框选出目标,并标注出对应的置信度:
总结
以上就是使用Google Colab训练模型的大致流程。使用云端GPU资源可以摆脱本地GPU资源的限制,可以直接在云端拉取代码进行训练操作。而且Colab还支持挂载Google Drive,模型训练过程中的一些文件也可以及时保存,就算服务器资源过期也不会影响,还是比较方便的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)