《VLA 系列》Dream-VLA | 扩散建模 | 连续动作 | VLA
Dream-VLA 是一个基于“扩散基视觉语言”的VLA模型,基于扩散建模的VLA具备:
- 双向注意力:实现视觉与文本特征更丰富的信息融合
- 规划能力:dLLM 的文本规划能力,增强 VLM 的视觉规划效果
- 原生支持:无需架构修改即可实现
动作分块和并行生成
论文地址:https://arxiv.org/abs/2507.04447
开源地址:https://github.com/Zhangwenyao1/DreamVLA
说明:扩散大语言模型通过
迭代细化噪声序列,生成连贯输出,天然保障全局一致性,且具备并行解码的计算优势,适配长程依赖和目标导向的规划类任务。
1、模型架构
如下图所示,展示了 Dream系列模型
-
从纯文本扩散大语言模型(dLLM)到 多模态扩散视觉语言模型(dVLM)
-
再到视觉语言动作模型(dVLA)
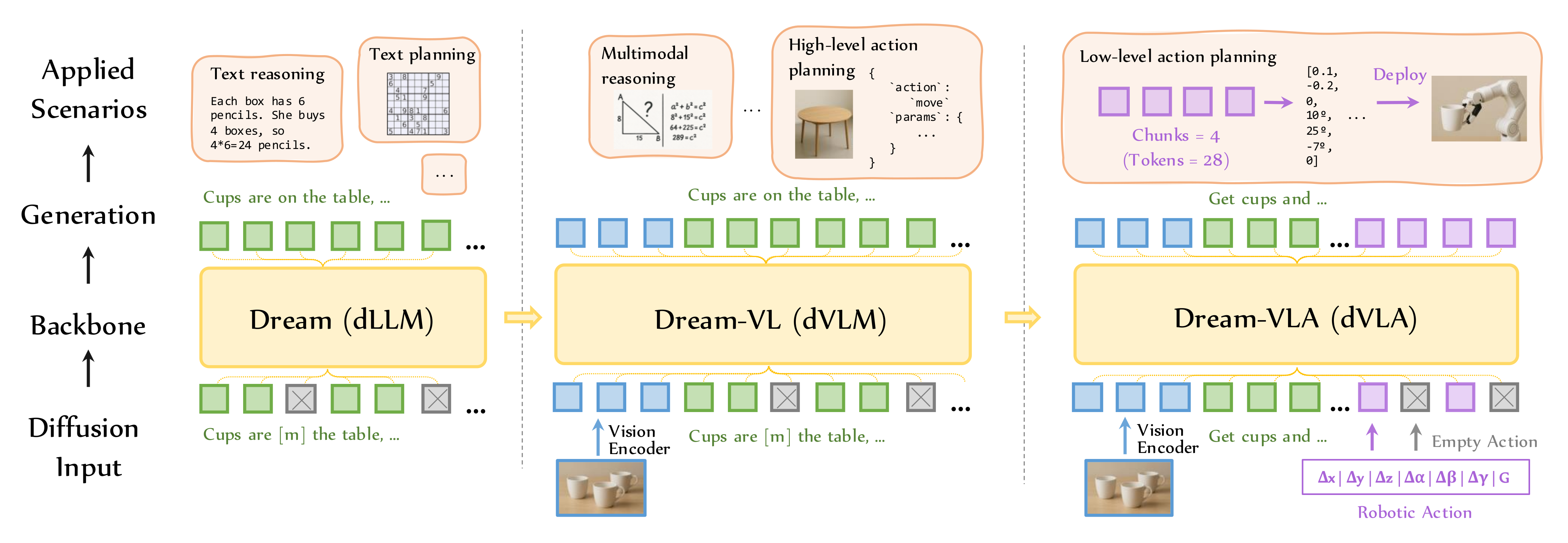
1.1、四层架构:从输入到应用的完整链路
从下到上,模型的能力实现分为四个层级,逐层向上落地到实际场景:
-
Diffusion Input(扩散输入层)
- 为模型提供多模态输入,是扩散生成的起点:
- 左(Dream):纯文本输入(带掩码的文本序列,如“Cups are [m] the table, …”),用于文本扩散生成。
- 中(Dream-VL):文本 + 视觉输入,视觉图像通过
Vision Encoder编码为特征,与文本拼接,作为多模态扩散输入。 - 右(Dream-VLA):文本 + 视觉 + 机器人动作输入,动作参数(Δx, Δy, Δz等)作为额外模态输入,支撑动作生成。
- 为模型提供多模态输入,是扩散生成的起点:
-
Backbone(骨干模型层)
- 核心是双向掩码扩散建模,通过迭代细化噪声序列生成输出,保障全局一致性和并行解码能力:
Dream (dLLM):纯文本扩散骨干,处理文本序列。Dream-VL (dVLM):在Dream基础上融合视觉编码器,处理多模态序列。Dream-VLA (dVLA):在Dream-VL基础上融合机器人动作输入,处理动作序列。
- 核心是双向掩码扩散建模,通过迭代细化噪声序列生成输出,保障全局一致性和并行解码能力:
-
Generation(生成层)
- 骨干模型输出对应模态的生成序列,为上层应用提供基础:
- Dream:生成纯文本序列(绿色方块),支撑文本任务。
- Dream-VL:生成多模态序列(蓝+绿方块),支撑多模态任务。
- Dream-VLA:生成动作分块序列(蓝+绿+紫方块,紫块为动作分块),支撑机器人动作规划。
- 骨干模型输出对应模态的生成序列,为上层应用提供基础:
-
Applied Scenarios(应用场景层)
- 生成序列直接落地到具体任务,实现能力闭环:
- 左(Dream):文本推理(如数学计算“4*6=24”)、文本规划(如数独、任务拆解)。
- 中(Dream-VL):多模态推理(如几何题、图像理解)、高层动作规划(如“move”动作的参数化规划,JSON格式)。
- 右(Dream-VLA):低层动作规划(动作分块生成θ等参数),最终部署到机械臂执行实际操作。
- 生成序列直接落地到具体任务,实现能力闭环:
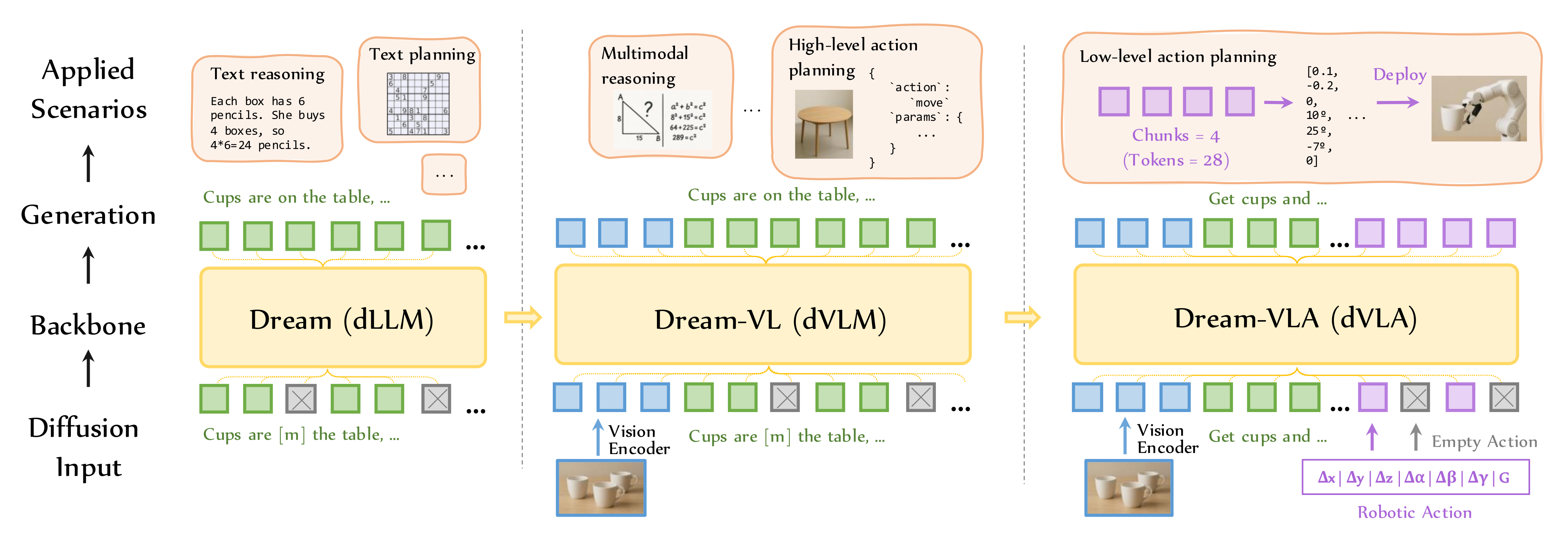
1.2、三阶段模型演进:从文本到机器人的能力延伸
从左到右,模型能力从纯文本逐步拓展到机器人交互,形成“基础感知→多模态理解→实体交互”的完整技术路线:
-
阶段1:Dream (dLLM) —— 纯文本扩散骨干
- 输入:纯文本(带掩码)。
- 核心能力:文本推理、文本规划(如数独、数学题),验证了扩散架构在长程文本任务中的优势。
- 输出:连贯文本序列,为后续多模态扩展奠定基础。
-
阶段2:Dream-VL (dVLM) —— 多模态扩散视觉语言模型
- 输入:文本 + 视觉图像(经Vision Encoder编码)。
- 核心能力:多模态推理(如图像理解、几何题)、高层动作规划(如“move”动作的参数规划),将扩散架构的全局一致性优势迁移到视觉语言任务。
- 输出:多模态序列,连接文本与视觉,为机器人动作规划提供高层决策。
-
阶段3:Dream-VLA (dVLA) —— 扩散视觉语言动作模型
- 输入:文本 + 视觉图像 + 机器人动作参数(Δx, Δy, Δz等)。
- 核心能力:低层动作规划(动作分块生成,并行解码无误差累积),最终部署到机器人执行。
- 输出:可直接执行的动作序列,实现从“规划”到“落地”的闭环。
2、分层规划:高阶动作 与 低阶动作
Dream-VL和Dream-VLA的架构设计,这一分层规划进行应用:
-
Dream-VL:高阶规划的优化
- 基于扩散架构,天然具备全局一致性,能生成更连贯的高阶动作序列(如“先移动到桌子,再抓取杯子,然后放到目标位置”)。
- 多模态理解能力(视觉+文本),能精准解析场景语义和任务目标,为高阶规划提供可靠的输入。
- 实验验证:在ViPlan零样本规划基准中,Dream-VL的表现显著优于自回归基线,证明了其在高阶规划中的优势。
-
Dream-VLA:低阶规划的应用
- 在Dream-VL基础上,通过大规模机器人预训练,学习“视觉-文本-动作”的映射,解决VLM到可执行动作的衔接问题。
- 扩散骨干的并行生成和动作分块能力,能高效生成细粒度的连续控制参数,同时保持长程动作序列的一致性,避免误差累积。
- 实验验证:在LIBERO等基准上,Dream-VLA的低阶规划成功率(97.2%)远超自回归基线,证明了扩散架构在低阶控制中的优势。
如下表所示,展示了两种规划的差异:
| 维度 | 高阶动作规划(Dream-VL) | 低阶动作规划(Dream-VLA) |
|---|---|---|
| 核心目标 | 任务拆解与语义决策(做什么) | 物理控制与执行落地(怎么做) |
| 输出形式 | 抽象动作序列(语义化、符号化) | 动作分块(细粒度物理参数) |
| 依赖模型 | Dream-VL(多模态理解+语义规划) | Dream-VLA(多模态理解+动作映射) |
| 执行依赖 | 需要额外控制模块转换为物理指令 | 可直接驱动机器人执行 |
| 适用场景 | 任务规划、逻辑推理、长程决策 | 机器人操控、物理交互、轨迹生成 |
2.1、高阶动作规划(High-level action planning)流程分析
如下图所示,展示了高阶动作与低阶动作的思路流程:
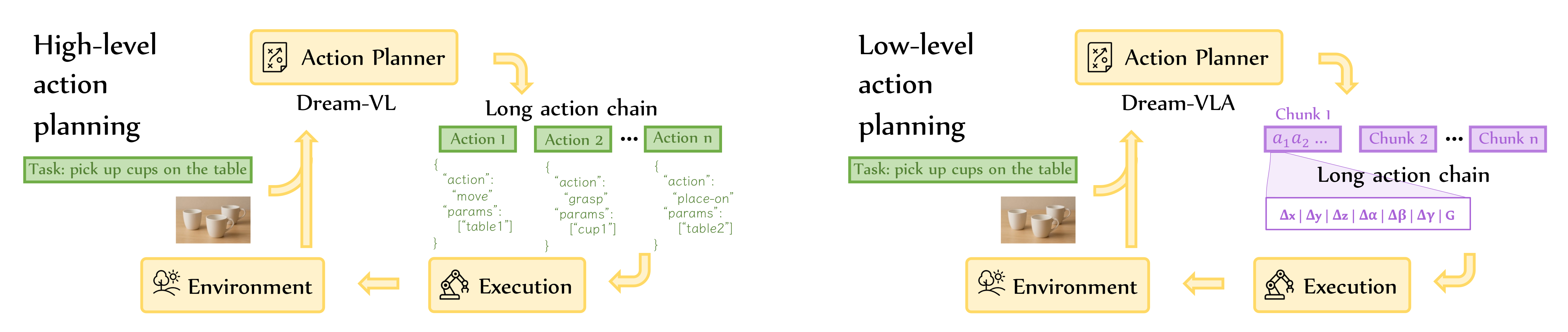
这是从任务目标到抽象动作序列的认知决策过程,核心是解决“做什么”的问题:
- 输入层
- 任务指令:自然语言描述的目标(如“pick up cups on the table”)。
- 环境感知:当前场景的视觉图像(如桌子上的杯子位置、布局)。
- 规划层(Action Planner: Dream-VL)
- 模型角色:作为语义级规划器,基于多模态理解能力解析任务目标与环境状态。
- 核心输出:生成长动作链(Long action chain),由一系列抽象动作(Action 1~Action n)组成,每个动作以JSON格式表示,包含动作类型(如
move、grasp、place-on)和语义参数(如table1、cup1),属于符号化、任务导向的规划。
- 执行层
- Execution模块将抽象动作序列传递给环境,驱动机器人完成任务。
- 特点:规划结果是语义化、可解释的,但不包含具体的物理执行参数,需要依赖额外的控制模块转换为可执行指令。
2.2、低阶动作规划(Low-level action planning)流程分析
这是从任务目标到可执行物理动作的控制落地过程,核心是解决“怎么做”的问题:
- 输入层
- 任务指令:与高阶规划一致(如“pick up cups on the table”)。
- 环境感知:与高阶规划一致的视觉图像。
- 规划层(Action Planner: Dream-VLA)
- 模型角色:作为物理级规划器,在Dream-VL的多模态理解基础上,通过机器人预训练学习“视觉-文本-动作”的映射。
- 核心输出:将长动作链拆分为动作分块(Chunk 1~Chunk n),每个Chunk包含细粒度的连续控制参数(如Δx, Δy, Δz, Δα, Δβ, Δγ, G等),这些参数直接对应机器人关节角度、位移、抓取力度等可执行的物理动作。
- 执行层
- Execution模块直接将动作分块的参数传递给环境,驱动机器人执行物理操作。
- 特点:规划结果是可直接部署的,无需额外转换,且动作分块设计利用了扩散模型的并行生成能力,避免了自回归模型的误差累积,提升了长程任务的稳定性。
3、Dream-VL 核心技术分析
该部分内容从“模型架构设计 → 视觉编码器选型与融合 → 三阶段训练范式 → 核心性能验证”的逻辑展开,每一部分均服务于“构建高性能dVLM”的目标:
模块1:模型整体架构(Architecture)—— 保持扩散骨干的“一致性”
这是Dream-VL的核心设计原则,也是区别于其他dVLM的关键:
- 骨干复用:直接采用Dream-7B的双向掩码扩散Transformer作为核心骨干,保留其8192的上下文长度、离散扩散损失函数和迭代细化生成逻辑;
- 模态扩展接口:在骨干模型的输入端,新增多模态特征拼接层,将视觉特征与文本特征统一映射到同一隐空间,实现“即插即用”的视觉融合,无需修改扩散解码核心;
- 输出层适配:保持原有的文本生成头,让Dream-VL仍以自然语言作为输出,确保与下游VLA模型(Dream-VLA)的接口兼容。
模块2:视觉编码器与特征融合(Vision Encoder & Fusion)—— 解决“跨模态对齐”痛点
这是Dream-VL能否媲美自回归VLM的关键技术细节:
- 编码器选型:采用Qwen2ViT作为视觉编码器,而非传统的CLIP ViT。原因在于Qwen2ViT针对多模态对话任务做了优化,输出的视觉特征维度与Dream-7B的文本嵌入维度更匹配,且具备更强的细节感知能力(适配机器人视觉规划的细粒度需求);
- 特征融合策略:
- 视觉图像经Qwen2ViT编码为视觉特征序列(Patch Embedding);
- 将视觉特征序列与文本指令序列拼接,作为Dream-7B的输入;
- 利用Dream-7B的双向注意力,实现视觉特征与文本特征的全局交互,彻底解决自回归VLM单向注意力导致的视觉-文本对齐不充分问题。
模块3:三阶段训练范式(Three-Stage Training)—— 分层次实现“能力对齐”
为了让扩散骨干快速适配多模态任务,该章节设计了循序渐进的三阶段训练,这是Dream-VL实现SOTA的核心工程手段:
| 训练阶段 | 核心目标 | 训练数据 | 关键设置 |
|---|---|---|---|
| 阶段1:视觉特征对齐 | 让模型学会“理解视觉特征” | 大规模图像-文本对(如LAION、COCO) | 冻结视觉编码器,微调扩散骨干的嵌入层,最小化视觉-文本特征的离散扩散损失 |
| 阶段2:多模态指令调优 | 让模型学会“遵循多模态指令” | 12M开源多模态指令-响应对(覆盖DocVQA、MMMU等任务) | 解冻视觉编码器,联合微调骨干,使用离散扩散损失,学习指令与视觉内容的关联 |
| 阶段3:规划能力强化 | 让模型学会“长程视觉规划” | 视觉规划专项数据集(如ViPlan、LIBERO高阶规划数据) | 针对性微调,强化模型对“动作序列、逻辑推理”的生成能力,适配下游机器人任务 |
模块4:核心性能验证(Experiments)—— 双重维度证明“架构优越性”
该章节的实验部分并非单纯罗列指标,而是从**“通用能力”和“规划能力”**两个维度,验证Dream-VL的价值:
- 维度1:扩散基VLM内部对比:在MMMU、DocVQA、ChartQA等基准上,全面超越LLaDA-V、Dimple等现有dVLM,证明Dream-VL是当前最优的开源dVLM;
- 维度2:与自回归VLM对标:媲美基于开源数据训练的顶尖AR-VLM(如MAmmoTH-VL、LLaVA-OV),且在视觉规划任务(如ViPlan零样本、LIBERO高阶规划) 中实现反超,直接呼应论文“扩散架构更适配规划任务”的核心论点。
4、Dream-VLA 核心技术分析
Dream-VLA的构建并非从零开始,而是基于Dream-VL的成熟能力,通过轻量化扩展实现,核心逻辑如下:
4.1、基底复用:保持扩散架构的核心一致性
- 直接复用Dream-VL的双向掩码扩散骨干,保留其8192上下文长度、离散扩散损失和并行生成能力,无需修改核心扩散解码逻辑。
- 视觉编码器(Qwen2ViT)和多模态特征拼接层完全继承,确保视觉-文本对齐能力的延续性,避免因架构重构导致的性能损失。
4.2、关键扩展:动作模态的无缝融入
在Dream-VL的输入侧,新增机器人动作模态作为第三类输入,实现“视觉-文本-动作”的三元融合:
- 动作输入:将机器人关节角度、位移(Δx, Δy, Δz)、姿态(Δα, Δβ, Δγ)、抓取力度(G)等连续控制参数,编码为离散动作token,与视觉特征、文本指令拼接后输入模型。
- 输出适配:在原文本生成头的基础上,新增动作生成分支,让模型可同时输出自然语言解释和可执行动作序列,保持输出接口的灵活性。
4.3、大规模机器人预训练:核心设计与工程细节
预训练是Dream-VLA性能优异的核心,其设计围绕“注入机器人操作先验”和“适配扩散架构特性”两大目标展开:
1. 预训练数据:覆盖多场景的大规模轨迹库
- 数据来源:Open-X Embodiment数据集,包含970k条机器人操作轨迹,覆盖10+机器人形态(如WidowX、Google Robot、Franka)、20+任务类型(抓取、摆放、堆叠、导航)和多样化场景(家庭、实验室、工业环境)。
- 数据价值:通过多机器人、多任务的轨迹数据,让模型学习到通用的机器人操作先验,而非局限于单一硬件或场景,大幅提升下游泛化能力。
2. 训练目标与范式:适配扩散架构的动作生成
- 核心损失:沿用Dream-VL的离散扩散损失,通过迭代细化噪声序列生成动作token,天然保障动作序列的全局一致性,避免自回归模型的误差累积。
- 动作分块设计:将长动作序列拆分为多个动作分块(Chunk),每个Chunk包含8~10个连续动作token,利用扩散模型的并行生成能力,实现动作序列的高效生成,同时提升长程任务的稳定性。
- 训练设置:全局批次1024,学习率1e-5,训练步610k,采用LoRA微调(秩32),在保证训练效率的同时,避免过拟合到预训练数据。
4.4、核心创新总结
- 架构一致性创新:从Dream-7B(dLLM)→ Dream-VL(dVLM)→ Dream-VLA(dVLA),全程保持扩散骨干的核心一致性,避免了自回归VLA因架构修改导致的性能损失,为多模态模型的能力拓展提供了新的思路。
- 预训练范式创新:实现扩散基VLA的大规模预训练,而非局部微调,证明了预训练是提升VLA泛化能力和性能的关键手段,打破了“扩散模型不适合机器人任务”的固有认知。
5、常见VLA模型对比分析
如果下图所示,展示了常见的VLA模型进行对比分析。
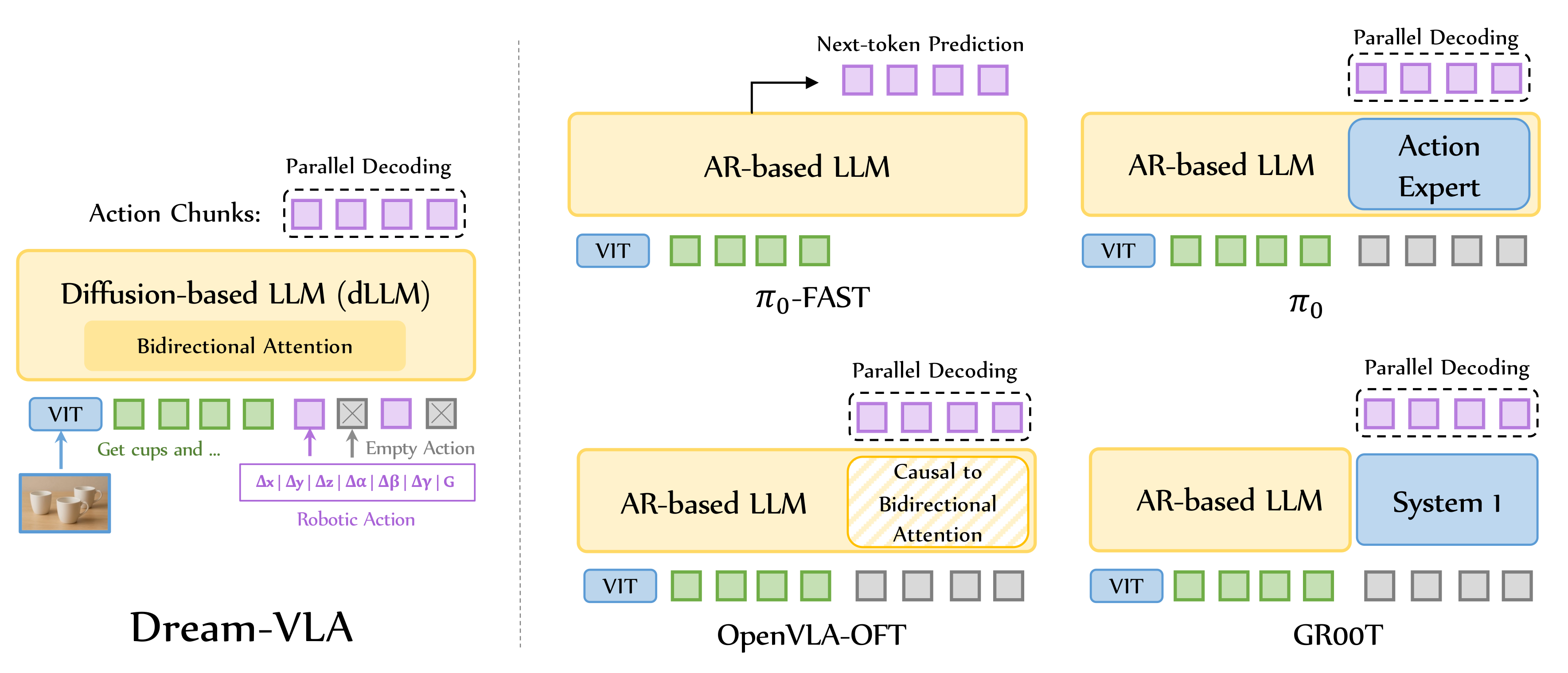
详细分析和对比,如下表所示:
| 模型名称 | 输入模态 | 核心架构 & 注意力机制 | 生成范式 & 动作处理 |
|---|---|---|---|
| Dream-VLA | ViT + 文本 + 机器人动作参数 | Diffusion-based LLM (dLLM) • 注意力:原生双向注意力 (Bidirectional) • 架构:离散扩散框架,支持文本/动作统一建模 |
离散扩散建模 (Discrete Diffusion) • 并行解码,迭代去噪细化 • 原生支持动作分块,无需额外模块 |
| π₀-FAST | ViT + 文本 | 自回归 LLM (AR-based) • 注意力:因果注意力 (Causal) • 架构:标准Transformer,FAST离散化 |
自回归逐token预测 (Next-token) • FAST tokenizer压缩动作为离散token • 无额外动作模块,纯AR解码 |
| π₀ | ViT + 文本 + 机器人状态 | VLM + Action Expert 双模块 • 注意力:VLM部分因果,Action Expert双向 • 架构:独立300M参数动作专家 |
流匹配 (Flow Matching) • 连续生成,单步/少步去噪,非自回归 • Action Expert专用模块处理动作生成 |
| OpenVLA-OFT | ViT + 文本(+ 腕部相机/状态可选) | 改进版 LLM 架构 • 注意力:完全替换为双向注意力 (Bidirectional) • 架构:移除因果掩码,输入空动作嵌入 |
并行解码 (Parallel Decoding) • 一次性生成完整动作块(L1回归或扩散) • 无额外模块,通过架构修改实现并行 |
| GR00T N1 | ViT + 文本 + 机器人状态 | VLM (System 2) + DiT (System 1) • 注意力:System 1通过交叉注意力读取System 2 • 架构:双系统,DiT作为扩散生成器 |
流匹配 (Flow Matching) • DiT去噪生成,4步Euler积分 • System 1专用模块(含embodiment编解码器) |
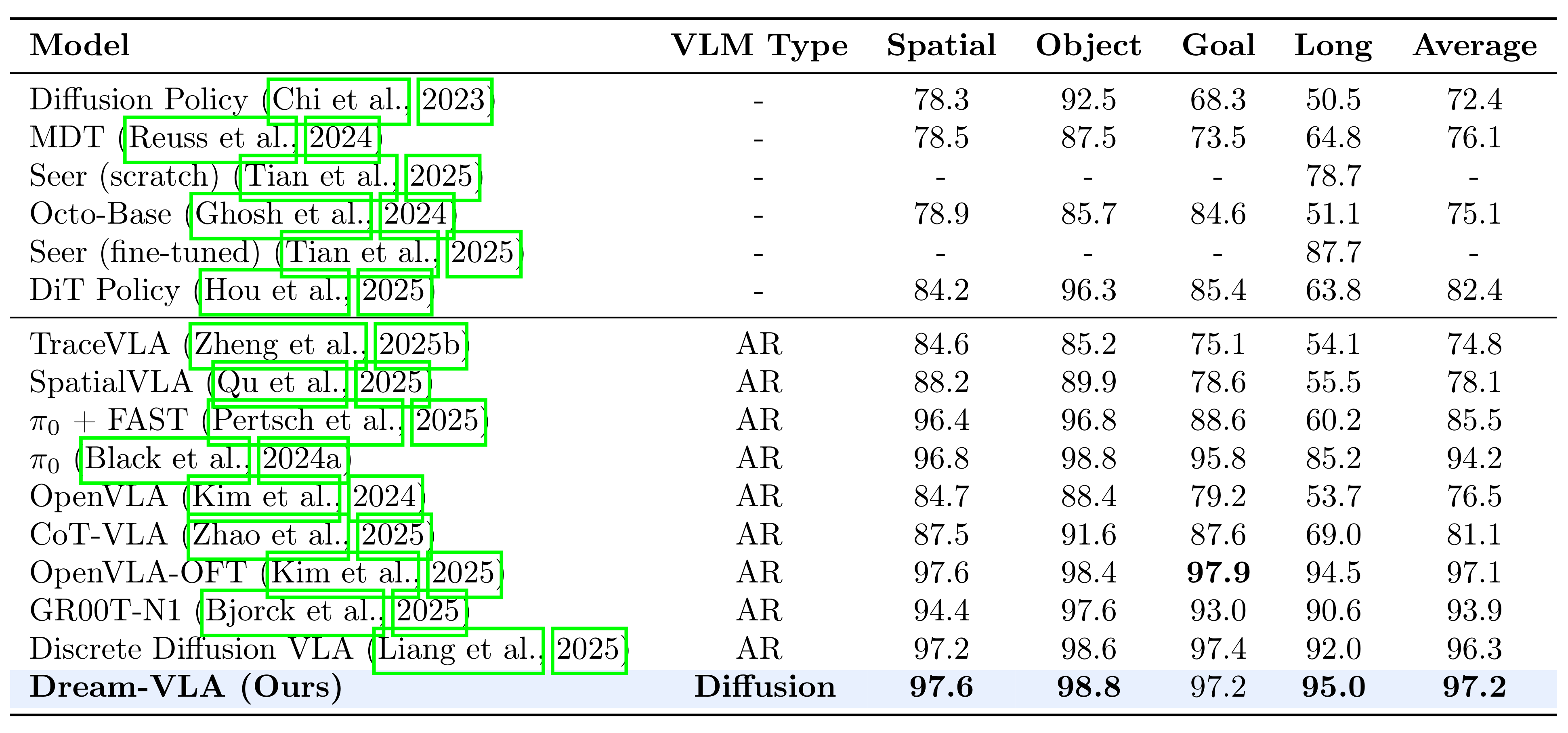
6、模型效果
如下表所示,展示了LIBERO 基准测试集上的成功率(%)。
“-” 表示该指标未在原论文中给出。
分享完成~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)