大模型应用:公交路线智能规划的最短路径算法:大模型重塑站点路径决策.114
一、前言
平时我们出门坐公交,打开地图输入起点和终点,几秒钟就能跳出好几条路线,有的最快、有的少换乘、有的走路少。一直都很好奇,这种路径规划的实现方式到底是怎么实现的,是什么算法支撑的,总在琢磨,但最后又在不解中慢慢就遗忘了,往往就是这种日常应用的功能看着很普通,适应了之后好像理所应当就该这样,但背后其实是一整套非常复杂的技术在支撑。从最早只能按固定线路查询,到现在能自动避开拥堵、理解我们“不想走路”、“少换乘” 的要求,公交路线规划早就不是简单算个最短距离那么简单了。
尤其是近几年大模型快速普及,传统的算法又迎来了一次全新升级。以前的系统只能处理死板的数据和规则,现在却能听懂人话、看懂实时路况、还能根据不同人的习惯给出个性化方案。对城市交通管理者来说,智能规划能优化线路、提高运力;对普通用户来说,就是出行更省心、更快、更舒服。今天我们一起好好琢磨,从最基础的原理讲起,一步步带的搞懂:公交车站点线路智能规划到底是怎么实现的,大模型在里面又起到了哪些关键作用,哪怕我们之前没接触过算法和模型,也能通俗的看明白。

二、核心基础
1. 公交路线智能规划
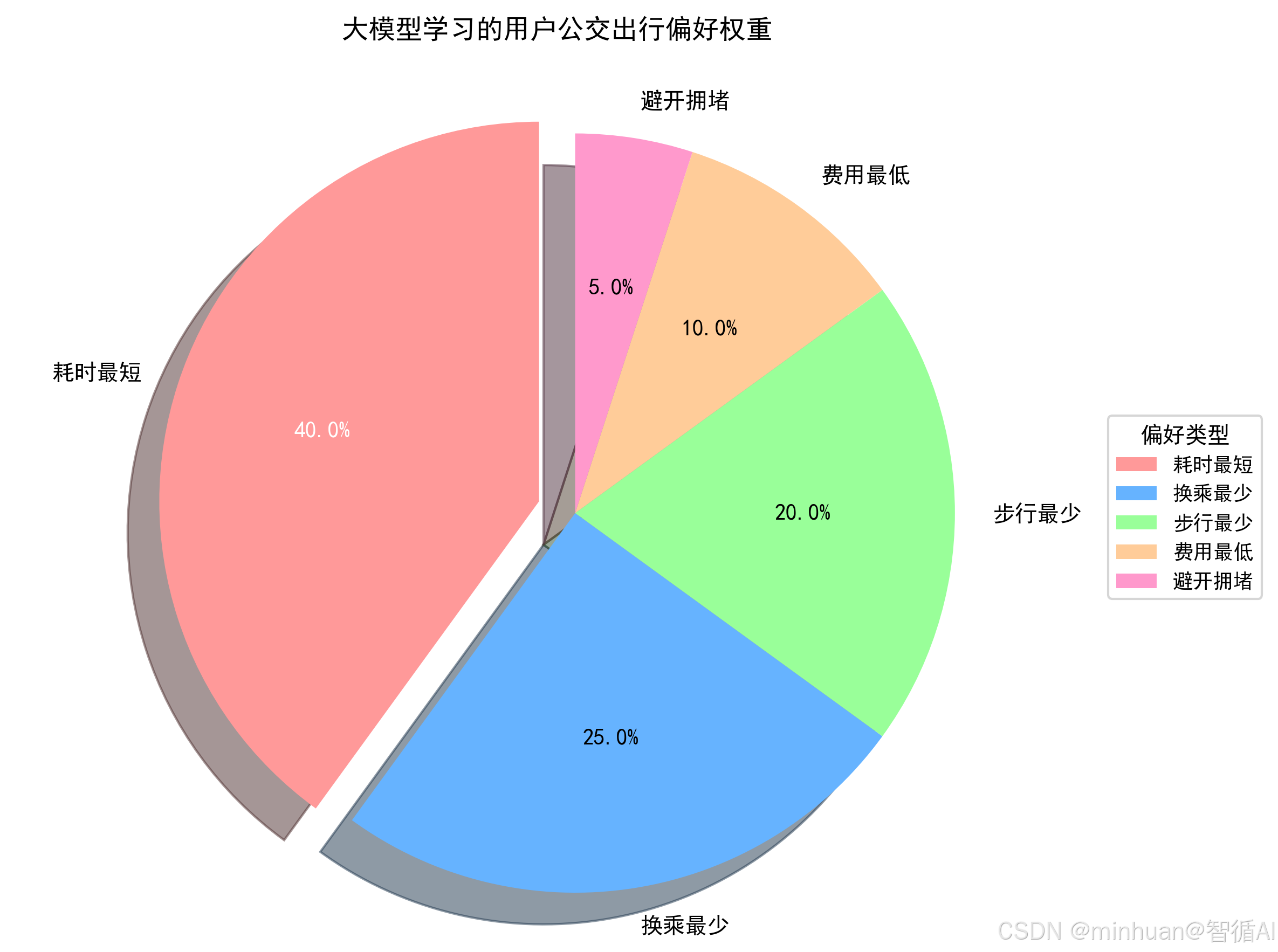
公交站点线路的智能规划,本质是在给定公交站点网络中,包括站点、线路、站点间通行时间和距离、发车频率等信息,以起始站和终点站为输入,通过算法或模型输出最优以及次优的公交出行方案。这里的最优可定义为耗时最短、换乘次数最少、步行距离最短、费用最低等单一目标,也可以是多目标加权的综合最优。
从应用场景来看,它是城市智慧交通的核心模块之一,常见于公交 APP、城市交通调度系统、出行服务平台等。而大模型的融入,让这一过程从基于固定规则或传统算法升级为“数据驱动 + 语义理解 + 动态决策”,既能处理结构化的站点数据,也能理解非结构化的用户需求,如“我想避开早高峰拥堵的站点”、“优先走有空调的公交线路”。
2. 基础术语解析
为了强化快速理解,我们先梳理核心术语:
- 站点网络(Graph):可以把整个城市的公交系统想象成一张“网”,每个公交站点是“节点(Node)”,站点之间的公交线路或步行路径是“边(Edge)”,边会附带权重,如通行时间、距离、是否需要换乘。这是所有路线规划的基础数据结构。
- 静态数据:不随时间变化的基础信息,如站点名称、站点经纬度、公交线路的固定停靠站、站点间的基础距离。
- 动态数据:实时变化的信息,如公交实时位置、路段拥堵情况、站点候车时间、天气对通行的影响,如下雨天步行意愿降低。
- 最短路径:狭义上指物理距离最短,广义上可扩展为 “综合成本最低”(如时间成本 = 乘车时间 + 换乘时间 + 步行时间)。
- 大模型(LLM):这里特指具备自然语言理解、知识推理、数据挖掘能力的大语言模型,也包括融合了空间数据的多模态大模型。
- 语义化需求:用户用自然语言表达的非标准化需求,如“从 XX 小区到 XX 医院,尽量少走路,下午 3 点左右出发”。
3. 大模型赋能的规划对比
3.1 数据处理能力
- 传统公交规划:局限于结构化数据。只能识别和处理如站点ID、经纬度坐标、固定时刻表等标准化数字信息,无法理解文本描述或图像信息。
- 大模型赋能的规划:具备多模态融合处理能力。不仅能处理结构化数据,还能直接解析非结构化数据,如乘客的自然语言反馈、社交媒体上的路况文本描述、甚至实时监控视频中的拥堵情况,实现全量数据利用。
3.2 需求理解
- 传统公交规划:依赖固定格式输入。用户必须提供精确的起点和终点,通常是站点编号或标准地名,系统无法理解模糊指令或复杂约束。
- 大模型赋能的规划:支持深层语义理解。用户可以像与人对话一样提出需求,例如“我想避开XX路正在施工的路段”或“找一条风景好且不太挤的路线”,系统能精准提取意图并转化为规划约束。
3.3 决策灵活性
- 传统公交规划:基于预设静态规则。逻辑通常是写死的,如“换乘次数最少”或“距离最短”,无法根据实时环境变化自动调整权重,缺乏自适应能力。
- 大模型赋能的规划:实现动态策略调整。系统能结合历史规律与实时数据,如突发暴雨、大型活动散场,动态重构决策逻辑。例如在早高峰自动优先推荐“大站快车”,而在平峰期优先推荐“覆盖率广”的线路。
3.4 个性化适配
- 传统公交规划:采用千人一面的模式。所有用户面对相同的算法逻辑,无法区分老人、通勤族或游客的不同偏好。
- 大模型赋能的规划:提供千人千面的服务。通过长期学习用户的行为习惯,系统能主动适配个人偏好。例如,为携带行李的用户推荐电梯覆盖多的站点,为赶时间的用户推荐虽然需换乘但总耗时更少的方案。
3.5 异常场景处理
- 传统公交规划:应对能力脆弱。一旦遇到规则库之外的突发状况,如临时封站、道路塌方,系统往往无法生成有效方案,甚至直接报错或提供不可行路线。
- 大模型赋能的规划:具备强推理与泛化能力。面对未知异常,大模型可以利用通用知识库进行逻辑推理,迅速规划出临时的替代方案,如建议“地铁+共享单车”的组合接驳,并给出解释性建议,保障出行连续性。
三、公交路线规划的基础原理
1. 图论与最短路径算法
所有公交路线规划的底层逻辑都基于图论,我们先从最基础的 “图” 开始理解:
1.1 公交网络的图建模
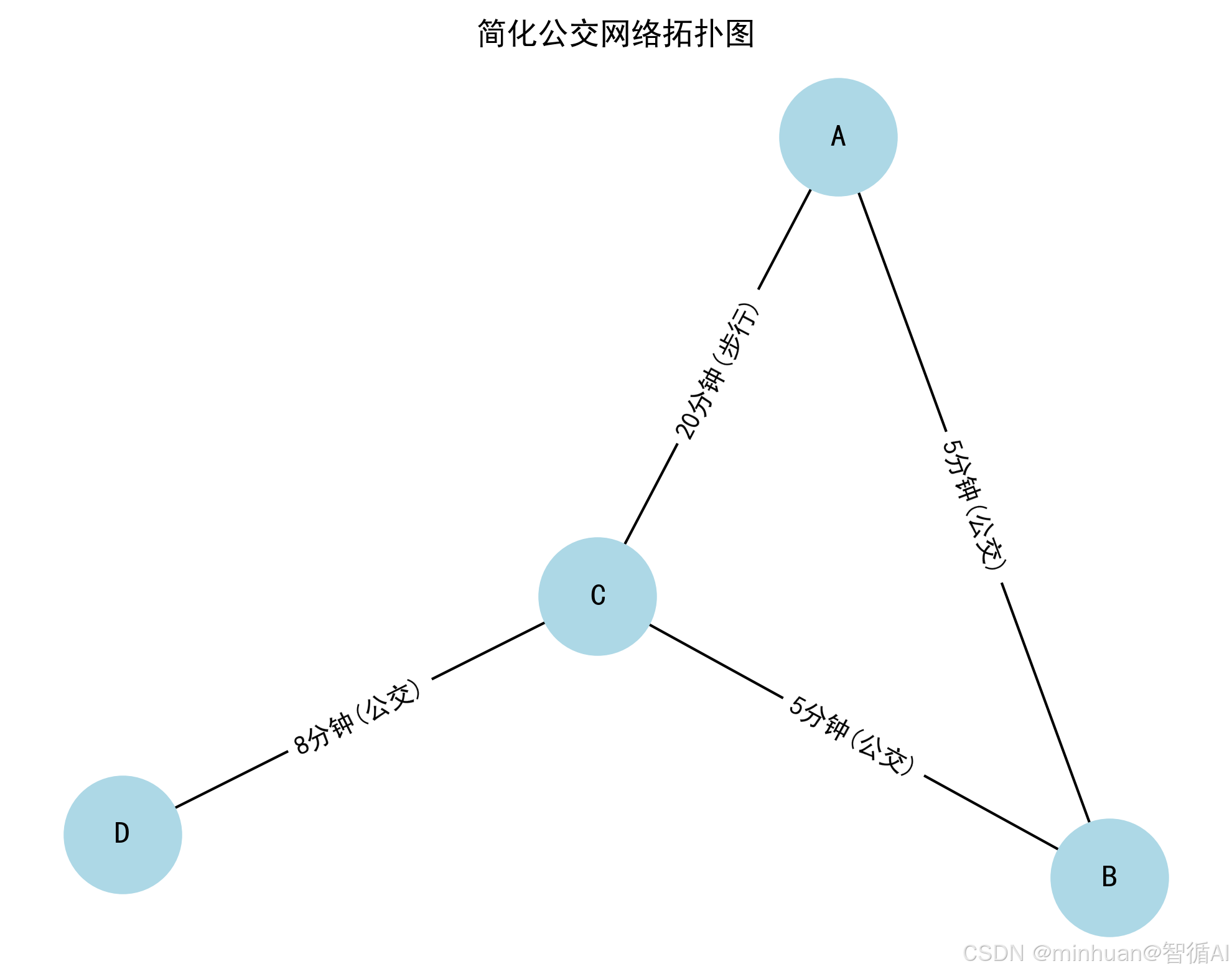
假设我们有如下简化的公交网络:
- 站点:A(小区)、B(商场)、C(地铁站)、D(医院)
- 线路 1:A→B→C(每段耗时 5 分钟)
- 线路 2:C→D(耗时 8 分钟)
- 步行路径:A→C(耗时 20 分钟)
我们可以把这个网络建模为 “无向图”,忽略行驶方向,仅关注连通性,用表格表示节点和边的权重(耗时):
| 起点 | 终点 | 权重(耗时 / 分钟) | 类型 |
|---|---|---|---|
| A | B | 5 | 公交 |
| B | C | 5 | 公交 |
| C | D | 8 | 公交 |
| A | C | 20 | 步行 |
在代码中,我们可以用networkx库来构建这个图:
import networkx as nx
import matplotlib.pyplot as plt
# 1. 创建无向图
G = nx.Graph()
# 2. 添加节点(公交站点)
nodes = ["A", "B", "C", "D"]
G.add_nodes_from(nodes)
# 3. 添加边(站点间的连接),并设置权重(耗时)
edges = [
("A", "B", {"weight": 5, "type": "公交"}),
("B", "C", {"weight": 5, "type": "公交"}),
("C", "D", {"weight": 8, "type": "公交"}),
("A", "C", {"weight": 20, "type": "步行"})
]
G.add_edges_from(edges)
# 4. 可视化图(输出图片)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 解决中文显示
pos = nx.spring_layout(G, seed=42) # 固定布局
nx.draw(G, pos, with_labels=True, node_size=2000, node_color="lightblue", font_size=12)
# 添加边的权重标签
edge_labels = {(u, v): f"{d['weight']}分钟({d['type']})" for u, v, d in G.edges(data=True)}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels, font_size=10)
plt.title("简化公交网络拓扑图")
plt.savefig("bus_network_graph.png", dpi=300, bbox_inches="tight")
plt.show()代码说明:
- networkx是 Python 中处理图结构的核心库,适合快速上手;
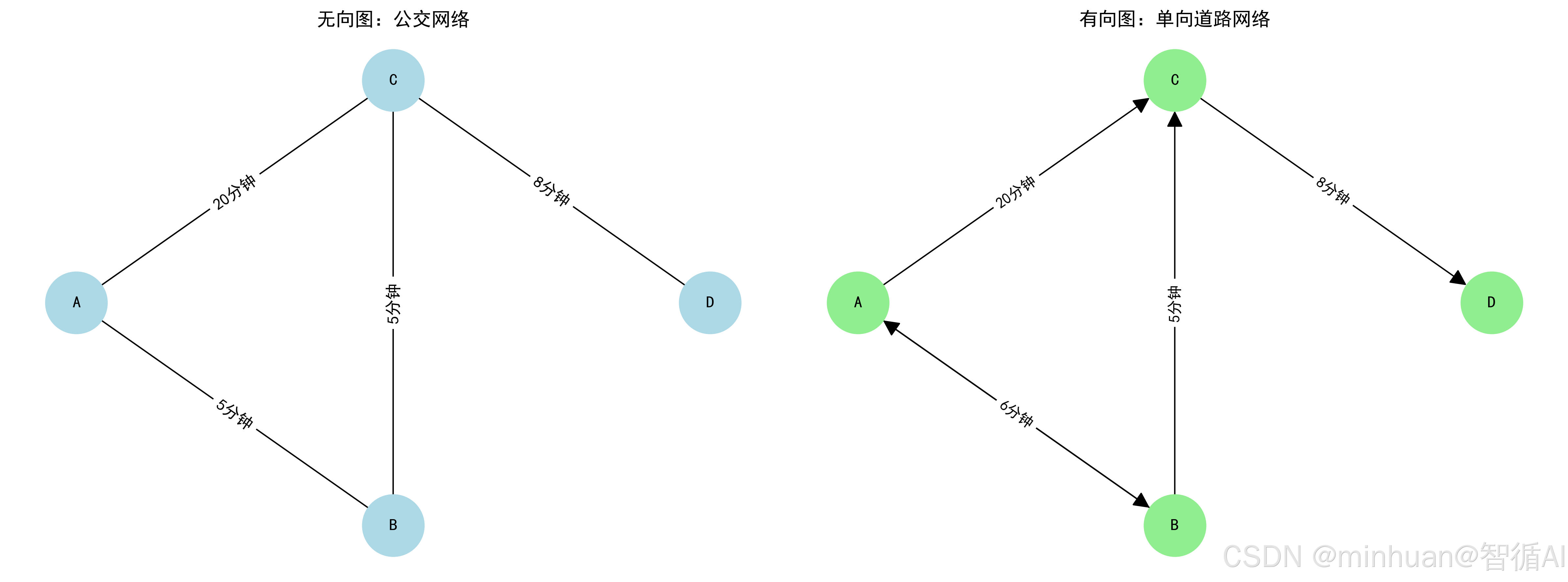
- nx.Graph()创建无向图,若需考虑公交行驶方向,如单行线,可改用nx.DiGraph()画有向图;
- add_nodes_from添加所有站点节点,add_edges_from添加站点间的连接,并附带“权重(耗时)”和“类型(公交/步行)”属性;
- matplotlib负责可视化,最终生成bus_network_graph.png图片,直观展示公交网络结构。
结果图示:
考虑公交行驶方向,可用带箭头的有向图展示:
2. 经典最短路径算法:Dijkstra 算法
Dijkstra 算法是公交规划中最常用的基础算法,核心逻辑是“从起点出发,逐步找到到每个节点的最短路径”,适合权重为非负数的场景,特别是公交耗时、距离均为正数。
我们用代码实现 Dijkstra 算法,求解从 A 到 D 的最短耗时路径:
def dijkstra_shortest_path(graph, start, end):
"""
实现Dijkstra算法,返回从起点到终点的最短路径和总权重
:param graph: networkx构建的图
:param start: 起始节点
:param end: 终止节点
:return: 最短路径列表、总权重
"""
# 初始化:距离字典(起点到各节点的距离),前驱节点字典
distance = {node: float("inf") for node in graph.nodes}
distance[start] = 0 # 起点到自身距离为0
predecessor = {node: None for node in graph.nodes}
unvisited = set(graph.nodes) # 未访问节点集合
print("=" * 60)
print("Dijkstra算法计算过程")
print("=" * 60)
print()
iteration = 0
while unvisited:
iteration += 1
# 选择当前距离最小的未访问节点
current_node = min(unvisited, key=lambda node: distance[node])
unvisited.remove(current_node)
print(f"第{iteration}步: 选中节点 {current_node} (距离: {distance[current_node]})")
# 若当前节点是终点,提前终止
if current_node == end:
print(f"✓ 已到达终点,算法完成")
break
# 遍历当前节点的邻居
for neighbor in graph.neighbors(current_node):
if neighbor in unvisited:
edge_weight = graph[current_node][neighbor]["weight"]
edge_type = graph[current_node][neighbor]["type"]
new_distance = distance[current_node] + edge_weight
# 更新距离和前驱节点
if new_distance < distance[neighbor]:
print(f" 更新 {neighbor}: {distance[current_node]} + {edge_weight} = {new_distance} (原距离{distance[neighbor]})")
distance[neighbor] = new_distance
predecessor[neighbor] = current_node
print()
# 回溯构建最短路径
path = []
current = end
while current is not None:
path.append(current)
current = predecessor[current]
path.reverse() # 反转得到从起点到终点的路径
# 若路径只有终点(无连通路径),返回空
if path[0] != start:
return [], float("inf")
return path, distance[end]
# 调用函数求解A到D的最短路径
shortest_path, total_time = dijkstra_shortest_path(G, "A", "D")
print(f"从A到D的最短耗时路径:{shortest_path}")
print(f"总耗时:{total_time}分钟")算法说明:
- 初始化阶段:给所有节点设置“无穷大”的初始距离,仅起点距离为 0;
- 迭代阶段:每次选择“未访问且距离最小”的节点,更新其邻居的距离,若经过当前节点到邻居的距离更短;
- 回溯阶段:从终点反向遍历前驱节点,构建完整路径;
- 结果验证:A→B→C→D 的总耗时 = 5+5+8=18 分钟,远小于 A→C→D 的 20+8=28 分钟,符合预期。
输出结果:
============================================================
Dijkstra算法计算过程
============================================================第1步: 选中节点 A (距离: 0)
更新 B: 0 + 5 = 5 (原距离inf)
更新 C: 0 + 20 = 20 (原距离inf)第2步: 选中节点 B (距离: 5)
更新 C: 5 + 5 = 10 (原距离20)第3步: 选中节点 C (距离: 10)
更新 D: 10 + 8 = 18 (原距离inf)第4步: 选中节点 D (距离: 18)
✓ 已到达终点,算法完成
从A到D的最短耗时路径:['A', 'B', 'C', 'D']
总耗时:18分钟
正常情况下耗时18分钟,如果公交拥堵,考虑备选路线:

3. 动态数据的融合原理
实际公交规划中,静态的基础耗时无法反映真实情况,需要融合动态数据,如拥堵导致耗时增加、公交晚点。核心原理是:
- 1. 实时获取动态数据,如通过公交 API 获取某路段的拥堵系数;
- 2. 动态调整图中边的权重,如拥堵系数 = 2,则原耗时 ×2;
- 3. 重新运行最短路径算法,得到贴合实时路况的路线。
示例代码(模拟动态拥堵调整):
# 模拟获取实时拥堵数据(实际中可通过API获取)
congestion_factor = {
("A", "B"): 1.5, # A→B拥堵,耗时×1.5
("B", "C"): 1.2, # B→C轻微拥堵,耗时×1.2
("C", "D"): 1.0, # C→D无拥堵
("A", "C"): 1.0 # 步行无拥堵
}
# 动态更新图的边权重
for (u, v), factor in congestion_factor.items():
original_weight = G[u][v]["weight"]
G[u][v]["weight"] = original_weight * factor
# 重新计算最短路径
updated_path, updated_time = dijkstra_shortest_path(G, "A", "D")
print(f"拥堵后从A到D的最短路径:{updated_path}")
print(f"拥堵后总耗时:{updated_time}分钟")输出结果:
============================================================
Dijkstra算法计算过程
============================================================第1步: 选中节点 A (距离: 0)
更新 B: 0 + 7.5 = 7.5 (原距离inf)
更新 C: 0 + 20.0 = 20.0 (原距离inf)第2步: 选中节点 B (距离: 7.5)
更新 C: 7.5 + 6.0 = 13.5 (原距离20.0)第3步: 选中节点 C (距离: 13.5)
更新 D: 13.5 + 8.0 = 21.5 (原距离inf)第4步: 选中节点 D (距离: 21.5)
✓ 已到达终点,算法完成
拥堵后从A到D的最短路径:['A', 'B', 'C', 'D']
拥堵后总耗时:21.5分钟
四、大模型核心价值体现
大模型的核心价值:从规则驱动到智能驱动,传统公交规划的痛点是刚性,所有决策依赖预设规则,无法处理复杂、个性化、非标准化的需求。而大模型的融入,解决了以下核心问题:
1. 语义化需求的解析
用户实际使用时,不会输入“起点 A + 终点 D”,而是说“我从 XX 小区(A)到 XX 医院(D),下午 5 点下班高峰出发,尽量少换乘,不想走超过 5 分钟的路”。大模型能将这种自然语言需求转化为规划算法可识别的结构化参数:
- 起点:A(XX 小区)
- 终点:D(XX 医院)
- 出发时间:17:00(高峰时段)
- 约束条件:换乘次数≤1,步行距离≤5 分钟(对应步行耗时≤5 分钟)
2. 多目标决策的智能加权
公交规划的最优是多维度的,如耗时、换乘、步行,不同用户的偏好不同:
- 老年人:优先少步行、少换乘,对耗时不敏感;
- 上班族:优先耗时最短,可接受少量换乘+步行;
- 学生:优先费用最低,如公交卡优惠。
大模型可通过学习用户历史行为,或通过对话交互,自动调整多目标的权重,如给步行距离设置更高的权重惩罚,生成个性化路线。
3. 异常场景的推理与应对
临时封站、线路改道、极端天气等异常场景,超出了传统规则的覆盖范围。大模型可通过知识推理给出替代方案:
- 例:“XX 路因施工封站,从 A 到 D 的替代路线是什么?”
- 大模型推理:封站影响 B→C 的公交,因此推荐 A→C(步行)→D,或 A→B→其他站点→C→D。
4. 自然语言的结果输出
传统规划仅输出“站点列表”,大模型可将结果转化为通俗易懂的自然语言:
- 算法输出:A→B→C→D,耗时 18 分钟;
- 大模型输出:“推荐您乘坐 1 路公交(A 站→B 站→C 站),换乘 2 路公交(C 站→D 站),全程 18 分钟,步行仅需 2 分钟(仅站点内换乘),下午 5 点高峰时段该路线拥堵概率较低。”
五、整体执行流程
- 大模型不替代传统最短路径算法,而是“前端解析 + 后端优化 + 结果输出”;
- 传统算法负责“高效求解路径”,大模型负责“理解需求、优化决策、友好输出”;
- 核心是“算法 + 大模型”的协同,兼顾效率与智能。
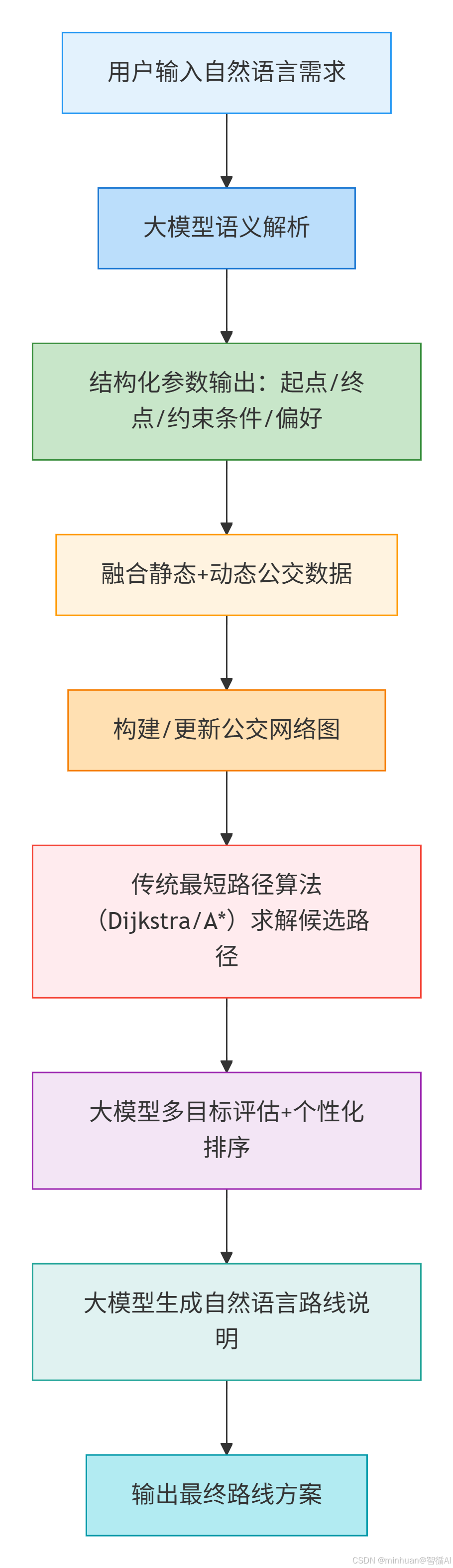
流程说明:
1. 用户输入自然语言需求:
用户用日常语言提出出行需求,例如“从西湖到灵隐寺,想要少走路,优先地铁”。
2. 大模型语义解析:
大模型理解用户意图,从自然语言中提取关键信息,如起点、终点、时间、偏好(少步行、优先地铁、避开拥堵等)。
3. 结构化参数输出:
将解析结果转化为程序可处理的标准化格式,例如:{start: "西湖", end: "灵隐寺", constraints: ["少步行"], preferences: ["优先地铁"]}。
4. 融合静态+动态公交数据:
整合基础公交线路数据(站点、票价、运营时间)和实时动态数据(拥堵情况、到站预测、临时管制)。
5. 构建/更新公交网络图:
将公交线路抽象为图结构:站点是节点,公交线路是边,并根据实时数据动态更新边的权重(时间、拥挤度等)。
6. 传统最短路径算法求解候选路径:
使用Dijkstra或A*算法在公交网络图上搜索出若干条候选路线,每条路线包含换乘方案、预计时间、步行距离等。
7. 大模型多目标评估+个性化排序:
大模型结合用户偏好(少步行、少换乘、低票价等)对候选路线进行综合评分,并重新排序,选出最适合用户的路线。
8. 大模型生成自然语言路线说明:
将排序后的路线转化为清晰易懂的文字说明,包含起点、换乘点、步行指引、预计耗时等细节。
9. 输出最终路线方案:
将完整的路线说明返回给用户,支持文本展示、语音播报或地图可视化。
六、完整示例
使用算法结合大模型,根据用户需求"从A_小区到D_医院,下午5点高峰时段出发,换乘次数不要超过1次,步行时间尽量少,优先耗时最短的路线",实现最优路线规划;
import os
import networkx as nx
import matplotlib.pyplot as plt
from openai import OpenAI
from dotenv import load_dotenv
import json
# 使用腾讯混元大模型
api_key = os.getenv('TENCENT_API_KEY', 'sk-bWlJPKjBrSF********8Ze')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
# ===================== 第一步:构建基础公交网络 =====================
def build_bus_network():
"""构建包含更多站点的公交网络(贴近真实场景)"""
G = nx.Graph()
# 站点列表(含小区、商场、地铁、医院、学校)
nodes = ["A_小区", "B_商场", "C_地铁1号线", "D_医院", "E_学校", "F_公园", "G_地铁站2号线"]
G.add_nodes_from(nodes)
# 边列表:(起点, 终点, 权重(耗时/分钟), 类型, 线路号)
edges = [
("A_小区", "B_商场", {"weight": 5, "type": "公交", "line": "1路"}),
("B_商场", "C_地铁1号线", {"weight": 5, "type": "公交", "line": "1路"}),
("C_地铁1号线", "D_医院", {"weight": 8, "type": "公交", "line": "2路"}),
("A_小区", "C_地铁1号线", {"weight": 20, "type": "步行"}),
("C_地铁1号线", "E_学校", {"weight": 10, "type": "公交", "line": "3路"}),
("E_学校", "D_医院", {"weight": 15, "type": "公交", "line": "4路"}),
("B_商场", "F_公园", {"weight": 7, "type": "公交", "line": "5路"}),
("F_公园", "G_地铁站2号线", {"weight": 6, "type": "公交", "line": "5路"}),
("G_地铁站2号线", "D_医院", {"weight": 12, "type": "地铁", "line": "2号线"})
]
G.add_edges_from(edges)
return G
# ===================== 第二步:大模型解析自然语言需求 =====================
def parse_user_request_with_llm(user_request):
"""
使用大模型解析用户自然语言需求,提取结构化参数
:param user_request: 用户输入的自然语言需求
:return: 结构化参数字典(起点、终点、约束条件、偏好)
"""
prompt = f"""
请你作为公交路线规划助手,解析用户的自然语言需求,提取以下结构化信息:
1. 起点(精确提取站点名称,如"A_小区"、"B_商场"、"C_地铁1号线"、"D_医院"、"E_学校"、"F_公园"、"G_地铁站2号线");
2. 终点(精确提取站点名称,如"A_小区"、"B_商场"、"C_地铁1号线"、"D_医院"、"E_学校"、"F_公园"、"G_地铁站2号线");
3. 约束条件(如换乘次数≤1、步行耗时≤5分钟、避免拥堵路段);
4. 用户偏好(如优先少换乘、优先耗时最短、优先步行少、优先地铁)。
用户需求:{user_request}
输出格式要求:
以JSON格式输出,键为"start_point", "end_point", "constraints", "preferences",
constraints和preferences为列表形式,若无则为空列表。
重要提示:
- 必须从用户输入中准确提取起点和终点的完整站点名称
- 起点和终点必须是下列站点之一:A_小区、B_商场、C_地铁1号线、D_医院、E_学校、F_公园、G_地铁站2号线
- 严禁编造站点名称或使用省略号
示例输出:
{{
"start_point": "A_小区",
"end_point": "D_医院",
"constraints": ["换乘次数≤1", "步行耗时≤5分钟"],
"preferences": ["优先耗时最短"]
}}
"""
# 调用腾讯混元API
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.1 # 低随机性,保证解析结果稳定
)
# 提取并返回JSON结果
try:
content = response.choices[0].message.content.strip()
# 清理可能存在的markdown代码块标记
if content.startswith("```json"):
content = content[7:]
if content.startswith("```"):
content = content[3:]
if content.endswith("```"):
content = content[:-3]
content = content.strip()
result = json.loads(content)
# 验证站点名称是否在图节点中
valid_nodes = ["A_小区", "B_商场", "C_地铁1号线", "D_医院", "E_学校", "F_公园", "G_地铁站2号线"]
if result.get("start_point") not in valid_nodes or result.get("end_point") not in valid_nodes:
# 如果解析的站点名称无效,返回默认值
print(f"警告:解析的站点名称无效,start={result.get('start_point')}, end={result.get('end_point')}")
return {
"start_point": "A_小区",
"end_point": "D_医院",
"constraints": result.get("constraints", []),
"preferences": result.get("preferences", [])
}
return result
except json.JSONDecodeError as e:
# 解析失败时返回默认值
print(f"JSON解析失败: {e}, 返回内容: {content}")
return {
"start_point": "A_小区",
"end_point": "D_医院",
"constraints": ["换乘次数≤1"],
"preferences": ["优先耗时最短"]
}
# ===================== 第三步:Dijkstra算法求解候选路径 =====================
def dijkstra_with_constraints(graph, start, end, constraints=None, preferences=None):
"""
带约束和偏好的最短路径求解
:param graph: 公交网络图
:param start: 起点
:param end: 终点
:param constraints: 约束条件列表
:param preferences: 偏好列表
:return: 最优路径、总耗时、路径详情(含线路、类型)
"""
if constraints is None:
constraints = []
if preferences is None:
preferences = []
# 1. 先获取所有可能的路径(简化版:仅获取前3条最短路径)
all_paths = list(nx.shortest_simple_paths(graph, start, end, weight="weight"))[:3]
path_details = []
# 2. 为每条路径计算详细信息(总耗时、换乘次数、步行耗时)
for path in all_paths:
total_time = 0
transfer_count = 0
walk_time = 0
last_line = None
line_details = []
for i in range(len(path)-1):
u = path[i]
v = path[i+1]
edge_data = graph[u][v]
time = edge_data["weight"]
line = edge_data.get("line", "步行")
type_ = edge_data["type"]
total_time += time
if type_ == "步行":
walk_time += time
else:
if line != last_line and last_line is not None:
transfer_count += 1
last_line = line
line_details.append(f"{line}({type_}): {u}→{v} ({time}分钟)")
# 3. 构建路径详情字典
path_info = {
"path": path,
"total_time": total_time,
"transfer_count": transfer_count,
"walk_time": walk_time,
"line_details": line_details
}
path_details.append(path_info)
# 4. 根据约束条件过滤路径
filtered_paths = []
for info in path_details:
valid = True
# 处理换乘次数约束
for constraint in constraints:
if "换乘次数≤" in constraint:
max_transfer = int(constraint.split("≤")[1])
if info["transfer_count"] > max_transfer:
valid = False
if "步行耗时≤" in constraint:
max_walk = int(constraint.split("≤")[1])
if info["walk_time"] > max_walk:
valid = False
if valid:
filtered_paths.append(info)
# 5. 根据偏好排序
if not filtered_paths:
filtered_paths = path_details # 无符合约束的路径,返回所有
if "优先耗时最短" in preferences:
filtered_paths.sort(key=lambda x: x["total_time"])
elif "优先少换乘" in preferences:
filtered_paths.sort(key=lambda x: x["transfer_count"])
elif "优先步行少" in preferences:
filtered_paths.sort(key=lambda x: x["walk_time"])
# 返回最优路径(第一条)
if filtered_paths:
best_path = filtered_paths[0]
return best_path["path"], best_path["total_time"], best_path["line_details"]
else:
return [], 0, []
# ===================== 第四步:大模型生成自然语言路线说明 =====================
def generate_route_description_with_llm(path, total_time, line_details, user_preferences):
"""
使用大模型将路径信息转化为自然语言说明
:param path: 最优路径列表
:param total_time: 总耗时
:param line_details: 线路详情
:param user_preferences: 用户偏好
:return: 自然语言路线说明
"""
prompt = f"""
请你作为公交路线规划助手,根据以下信息生成通俗易懂的路线说明:
1. 最优路径:{path}
2. 总耗时:{total_time}分钟
3. 线路详情:{line_details}
4. 用户偏好:{user_preferences}
要求:
- 语言简洁明了,步骤清晰;
- 突出用户偏好(如优先少换乘);
- 给出温馨提示(如换乘站点、步行注意事项);
- 避免使用专业术语,适合普通用户理解。
"""
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[{"role": "user", "content": prompt}],
temperature=0.7 # 适度随机性,让语言更自然
)
return response.choices[0].message.content
# ===================== 主函数:整合所有流程 =====================
def main():
# 1. 构建公交网络
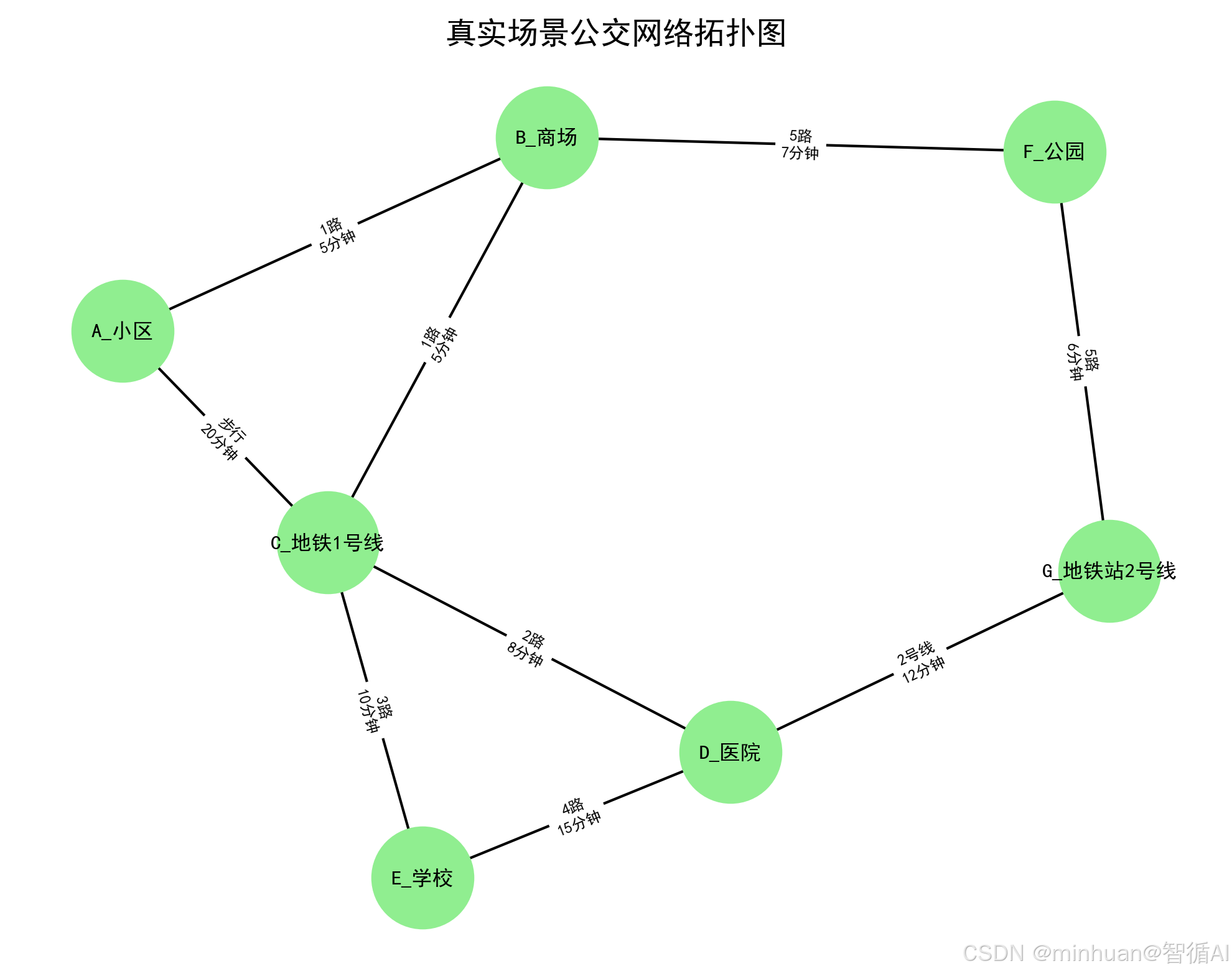
bus_graph = build_bus_network()
# 2. 可视化公交网络(保存图片)
plt.rcParams["font.sans-serif"] = ["SimHei"]
pos = nx.spring_layout(bus_graph, seed=42)
nx.draw(bus_graph, pos, with_labels=True, node_size=1500, node_color="lightgreen", font_size=8)
edge_labels = {(u, v): f"{d.get('line', '步行')}\n{d['weight']}分钟" for u, v, d in bus_graph.edges(data=True)}
nx.draw_networkx_edge_labels(bus_graph, pos, edge_labels=edge_labels, font_size=6)
plt.title("真实场景公交网络拓扑图")
plt.savefig("real_bus_network.png", dpi=300, bbox_inches="tight")
plt.show()
# 3. 用户输入自然语言需求
user_request = "我从A_小区到D_医院,下午5点高峰时段出发,换乘次数不要超过1次,步行时间尽量少,优先耗时最短的路线"
print(f"用户需求:{user_request}\n")
# 4. 大模型解析需求
parsed_info = parse_user_request_with_llm(user_request)
print(f"大模型解析的结构化参数:{parsed_info}\n")
# 5. 求解最优路径
start = parsed_info["start_point"]
end = parsed_info["end_point"]
constraints = parsed_info["constraints"]
preferences = parsed_info["preferences"]
best_path, total_time, line_details = dijkstra_with_constraints(
bus_graph, start, end, constraints, preferences
)
print(f"算法求解的最优路径:{best_path}")
print(f"总耗时:{total_time}分钟")
print(f"线路详情:{line_details}\n")
# 6. 大模型生成自然语言说明
route_description = generate_route_description_with_llm(best_path, total_time, line_details, preferences)
print("=== 最终路线推荐 ===")
print(route_description)
if __name__ == "__main__":
main()代码重点说明:
- 构建公交网络:build_bus_network函数构建了更贴近真实场景的网络,包含公交、地铁、步行三种类型,增加了线路号、站点用途(小区 / 医院)等属性;
- 大模型解析需求:parse_user_request_with_llm函数通过 Prompt 引导大模型将自然语言需求转化为结构化参数,核心是“Prompt 工程”,明确输出格式(JSON),降低解析难度;
- 带约束的路径求解:dijkstra_with_constraints函数在传统 Dijkstra 基础上,增加了约束过滤(如换乘次数)和偏好排序(如优先耗时最短),返回路径的详细信息(线路、耗时、换乘次数);
- 大模型生成说明:generate_route_description_with_llm函数将算法输出的冰冷数据转化为人性化说明,提升用户体验;
- 主函数整合:串联所有步骤,从构建网络→解析需求→求解路径→生成说明,形成完整的智能规划流程。
输出结果:
用户需求:我从A_小区到D_医院,下午5点高峰时段出发,换乘次数不要超过1次,步行时间尽量少,优先耗时最短的路线
大模型解析的结构化参数:{'start_point': 'A_小区', 'end_point': 'D_医院', 'constraints': ['换乘次数≤1'], 'preferences': ['优先耗时最短']}
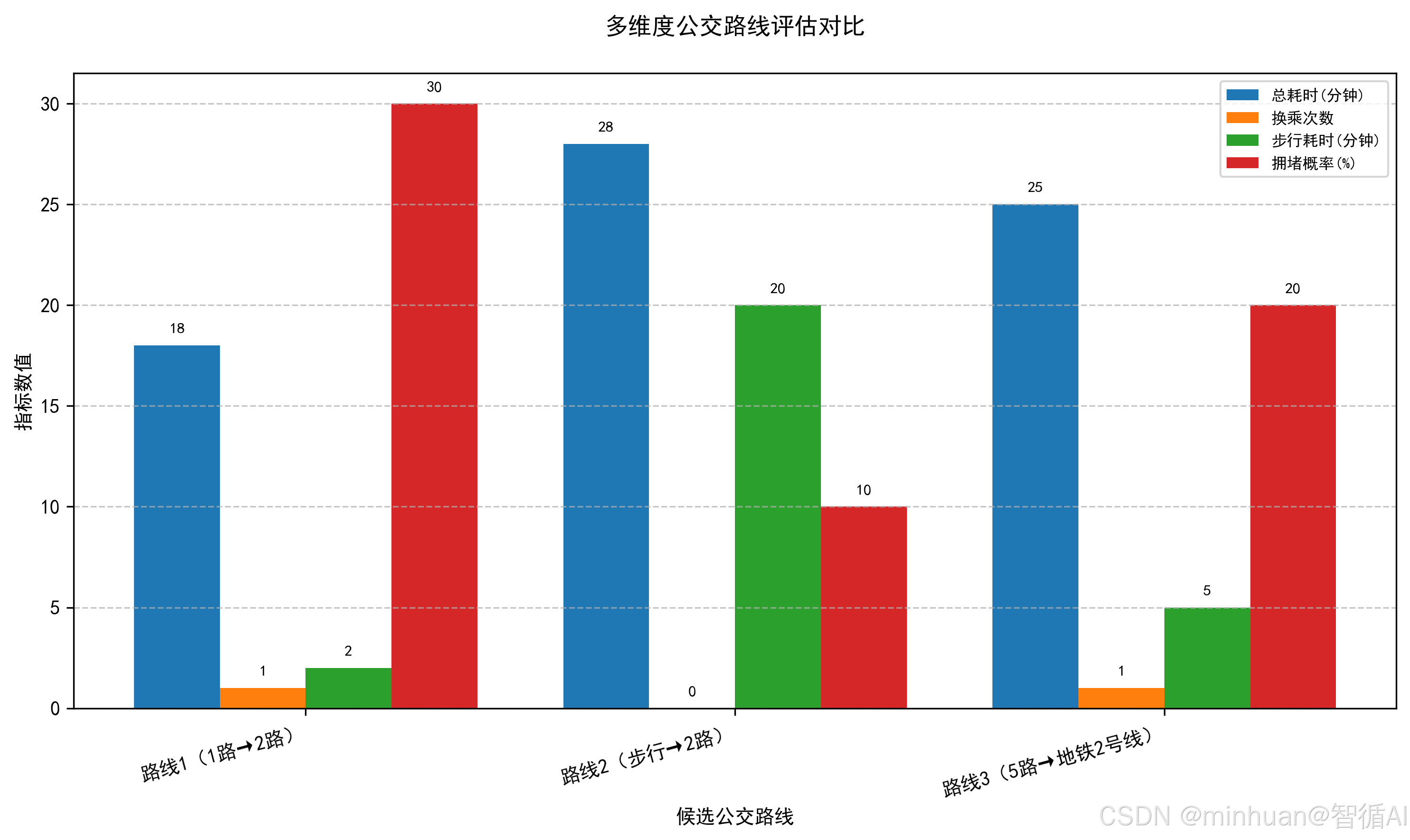
算法求解的最优路径:['A_小区', 'B_商场', 'C_地铁1号线', 'D_医院']
总耗时:18分钟
线路详情:['1路(公交): A_小区→B_商场 (5分钟)', '1路(公交): B_商场→C_地铁1号线 (5分钟)', '2路(公交): C_地铁1号线→D_医院 (8分钟)']=== 最终路线推荐 ===
根据您的需求,这里有一条最优的公交路线供您参考:**路线概述**:
* **起始站**:A_小区
* **终点站**:D_医院**行驶路线及时间**:
1. 从A_小区出发,乘坐1路公交直达B_商场,全程约5分钟。
2. 在B_商场换乘另一辆1路公交,直接前往C_地铁1号线站,用时也是5分钟。此时,您已经完成了第一次换乘。
3. 在C_地铁1号线站乘坐2路公交,直达D_医院,用时8分钟。**总耗时**:整个行程大约需要18分钟,符合您的要求。
**温馨提示**:
* 在换乘时,请注意安全,确保随身携带的物品安全。
* 地铁站内请遵守公共交通规则,文明乘车。
* 如有需要,您可以在途中适当休息,祝您旅途愉快!这条路线严格遵循了您的优先耗时最短的偏好,并且语言简洁明了,方便您理解。
真实场景公交网络拓扑图:
七、总结
简单说,公交规划的本质,就是把整个城市的公交网看成一张图:站点是节点,线路是连线,时间、距离、换乘都是权重。以前靠 Dijkstra经典最短路径算法,只能算最快、最近,规则死板、不够聪明。而大模型一加入,整个系统直接升级:它能听懂我们用自然语言说的“少走路、少换乘、避开高峰”,把模糊需求变成算法能看懂的结构化条件;还能结合实时拥堵、天气、施工这些动态信息,自动调整路线权重。
整个流程也很清晰:先采集公交数据、建好路网,再用大模型解析用户需求,接着用传统算法算出候选路线,最后再由大模型把结果翻译成通俗易懂的出行建议。既保留了算法算得快、算得准的优点,又拥有大模型会理解、会推理、会说话的能力。也是没有想到今天的知识在无意间解答了曾经的疑虑,这或许就是学习的好处吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)